By Jeffrey Flynt
How it started
I was in a week-long humanities intensive learning workshop at the University of Texas at Austin, in a Text Analysis session. One of the participants asked:
“Why doesn’t a software developer make this easier instead of us having to know R or Python?”
I felt comfortable in the session, as I had previous experience with both. But I could definitely understand the sentiment coming from users not comfortable writing commands to view quick outputs.
I am a research associate with the Quantitative Criticism Lab (QCL) at UT Austin. The principal investigators suggested I take the course. This course definitely helped me refine and discover new skills in natural language processing (NLP).
Inadvertently, I put this issue on the back burner while I focused on other toolkits and projects. While attending a classical studies workshop in Boston, I noticed many showed frustration at the lack of simpler tools for text analysis and visualization.
The team I am on at UT Austin was developing a web-based stylometric toolkit for multiple languages, but there currently was not a full-featured option for the English language.
Granted there are options like Voyant. But there are no readily available solutions that offer features such as named entity extraction, part-of-speech (POS) tagging, word segmentation from noisy text, and sentiment analysis to people without prior programming knowledge. Coupled with this and the above, it reinforced the idea to roll out a simpler app for NLP.
Where do I start?
While waiting to board the plane, my mind started reeling with where I should start. I ended up settling on creating the User Interface. My reasoning for this was that it would make it easier to create the functions after I figured out the workflow for the user.
Once the captain said it was alright for portable electronics, I pulled out my laptop and got to work. I’m sure the guy sitting next to me was probably thinking I was hacking something with all of my time in the console.
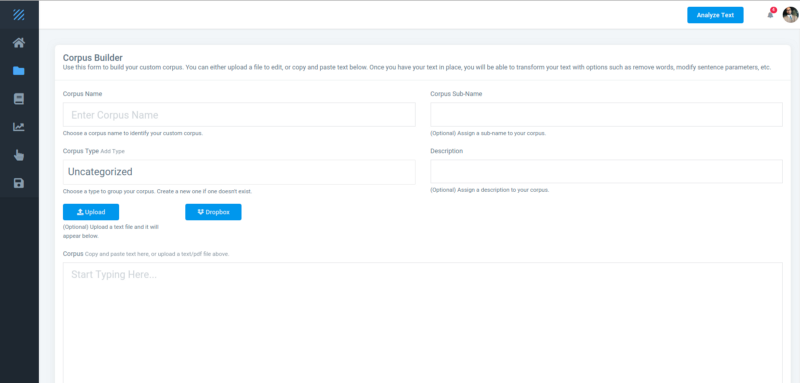
By the time I landed from the five hour flight, I had finished the Login, Registration, Forgot Password, and the Corpus Builder screens.
You might ask how is it possible to finish all of that with the corresponding JavaScript functions and testing. A good practice I learned early on to reduce development time is to keep boiler plate code just for these situations.
My drop in code usually consists of:
- Registration / Login
- Notifications
- Visualization (Chart.js, Bootstrap Tables, Handsontable.js)
- Routing
Another approach to reduce development time, especially when you are working on a project solo, is to use pre-made admin templates for the UI. The Themeforest Admin Website Templates section has some great UI elements that I use in my projects. I shaved more than 50% off of usual development time by using pre-built assets.
Granted I had to know my way around HTML, CSS, and jQuery. But having these assets already designed, I only had to worry about placement and data integration.
My framework of choice is Meteor.js. Meteor is a JavaScript framework that sits on top of Node.js. I am using MongoDB as my database and Python for the heavy NLP tasks.
For those of you who are familiar with Meteor, I opted not to include publications and subscriptions only methods and calls, and instead utilized dynamic imports for all third party libraries running on the client. This helped boost performance. I also employed the use of workers for any client code that needs to manipulate strings. This got me down to around a 500kb bundle size.
I settled on Textalytic for the name and secured the website.
Oh, you thought it would be simple?
I assumed this would all be pretty straightforward with my previous experience working on NLP related toolkits with the QCL Lab. But, there are always those gotcha moments.
I wanted users to be able to view highlighted named entities within their corpus. I first had to obtain a fast JavaScript compatible library to extract named entities.
At first I used compromise.js. This worked pretty well to an extent, but the speed on relatively large text was something to be desired.
I then settled on SpaCy, but this was in Python. I had never had to integrate two different languages before, so it was off to Stack Overflow for some learning.
After getting SpaCy working with JavaScript, I encountered two issues with SpaCy. The first was that SpaCy would not return accurate counts.
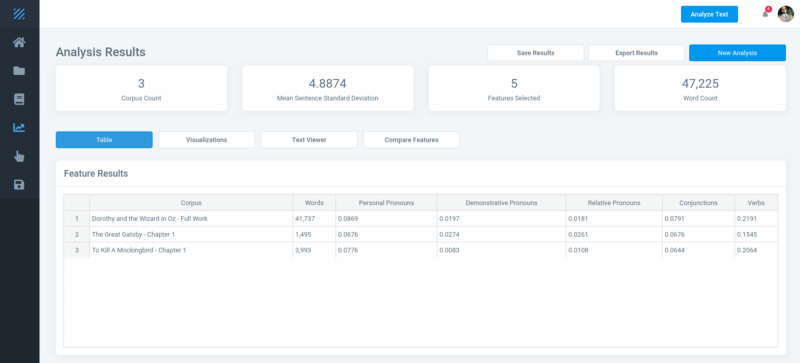
Users were able to view frequency of nouns, adjectives, verbs, and so on. SpaCy would return 31 instances of “car” but when doing a manual count, I would get 44.
At first I had Python handle returning the frequency of nouns:
I ended up opting to just return the raw noun array and have JavaScript return the top 10 nouns.
This led to accurate counts for nouns:
The second issue was with named entities. Most text analysis models, if not all, will not get 100% accuracy on named entities. To supplement SpaCy, I imported a large list of named entities taken from WikiData into MongoDB.
The text is run through SpaCy which returns an array of found entities. MongoDB then produces a large array of around 150k entities, which is sent along with the text to a function that performs a match against word boundaries. Regex accounting for punctuation and boundaries will cause many headaches.
These two arrays are filtered and duplicate entries removed to produce a final array of entities. This method seemed to be the fastest, returning results in ~5 seconds.
This method provided better coverage in obtaining greater accuracy than SpaCy’s 85.85%.
Can it be simpler, please?
Many of the tutorials for NLP tasks call for users to pre-process the text before analyzing. I wanted users to have a simpler approach.
With the Corpus Builder, users are able to type or copy and paste text or select a file from their computer or Dropbox.
Pre-processing
I now had to account for parsing different file types, sanitizing user input, and offering point and click options for pre-processing.
For pre-processing, users can remove blank lines, stop words, duplicate lines, punctuation, extra spaces, line breaks, and lines containing a user-selected word.
To keep in line with making text analysis easier, the user doesn’t have to do any of this. Depending upon the feature selected at run time, the back-end decides how to best handle the text.
Text Transformation
When taking the text analysis class, it seemed we did a lot of text transforming before starting to test various models.
I first tried integrating the Dropbox API into the app. I had assumed this was the only way to get this functionality. I was wrong, as Dropbox has a component called Chooser which allows the user to bring in their documents into the app without me spending more time adding in API calls.
While in the text analysis class, users had to download text files from someone’s Google Drive or download ready-made corpora from NLTK. This took up quite a bit of time while waiting for everyone to have the files downloaded and imported.
For users only wanting to test out features or get an understanding of how text analysis works, I opted to include a library of public domain literary works that they could add to their corpora to choose from. I am hopeful that this will provide a relaxed barrier to entry for beginning users.
For advanced users, I wanted them to have options and not be tied down to a default configuration. I implemented custom stop words, custom top occurring word lists, and more. Some users may want to search for frequency of words that end in “-ing”, so I threw that in too.
While adding these options, I had to account for those extra spaces, transforming their input into a usable array, setting limits on how big their custom list could, get and so forth.
Do Not Block the Loop!
I didn’t want users to be able to only view normalized frequency of nouns and verbs. So I ended up adding relative and subordinate clauses.
I’m currently testing more complex cases such as dangling modifiers, direct objects, and parallel structures.
Performance
I was excited to have this in place and that the results were returning pretty quick. Then I started thinking about performance. I brought up the site on my laptop and desktop, and then proceeded to run an analysis on some very large corpora. As you might expect, my results weren’t returning as fast when I was running searches with just me.
The issue was that my long running functions were blocking the main event loop. I needed to offload these tasks to a separate process to keep Node responsive. I tried for hours to get functions running on another process.
Finally I found Napa.js from Microsoft. It was really simple to integrate and I didn’t have to change any of my functions.
The app was now running smoothly with large corpora analyzed by multiple users. However, there is always a “but”!
When running searches with corpora that consisted of a very large body of ~500k words, Python would throw a ValueError. SpaCy has a set limit of 1,000,000 characters in a single string, which is modifiable. Naturally, I split the corpus into chunks.
Since this is a free app supported by myself — and server resources could get expensive — I opted to set hard limits for accounts of 1,000,000 corpus words per account and 50,000 words per corpus. A user can run an analysis over a group of corpora, but each corpus is analyzed individually. This should help prevent the server maxing out on computationally intensive functions.
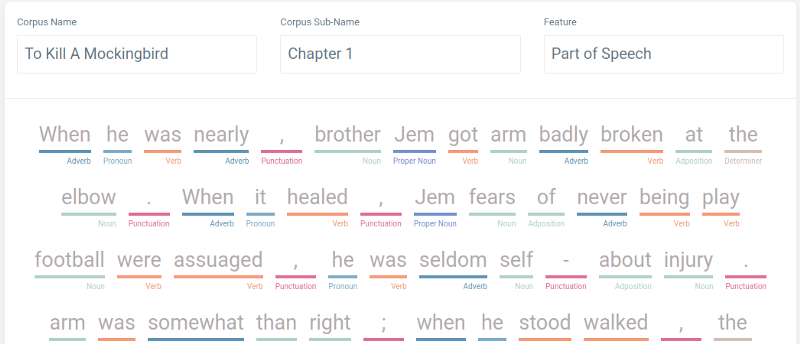
POS Tagging
Part of Speech tagging that was visualized in a meaningful way was something I knew I had to have in the app. SpaCy returned the POS tags for each word in a large array of objects without issue, but this wasnt helpful for the user. I had to manage to transform this array into a visually pleasing format for the user.
Compromise.js has a nice format for doing this, which I got the inspiration from.
I placed that array into a loop that added color tags based on the POS and transformed the new array into a string and updated the page to this:
Conclusion
In the span of a month, the app was in good shape to be released. I have since made various changes for optimization and other tweaks. I’m trying to stay away from adding npm modules unless I have to. Everything was written in vanilla JavaScript with the exception of the visualization libraries and toastr notifications. By doing this, the codebase is leaner and I don’t have to worry about when the maintainer of said project is going to do x.
Towards the end of this project, I started thinking:
“Who would use this?”
“Is this app actually good enough?”
“Did I mess up somewhere and it’ll be forever tarnished?”
I suppressed those thoughts and figured if it fails, I learned a heck of a lot, which I probably wouldn’t have learned doing something else.
You can waste a lot of time trying to optimize every function. I learned quickly to abandon the notion of trying to write functions in the latest ES syntax. I did, however, focus on the performance of various functions, more so for user experience.
One of the best time saving strategies was to use Gitlab’s CI/CD pipeline — and it’s free!
Instead of manually building the bundle, stopping the service, uploading and so forth, I just did one commit in GitKraken. GitLab handles everything else on the server.
There was a learning curve with getting NGINX setup with multiple instances, load balancing, and sticky sessions. But there are so many resources out there to help you along the way such as freeCodeCamp, Stack Overflow, and Digital Ocean’s blog section.
I am constantly thinking of new features to add that may be of use to users. Document summarization, custom machine learning models, and argument/stance detection are a few features I plan to add over the summer. If you’re interested in an NLP feature that might be useful, please let me know in the comments section. Thanks for reading!