
By Alexandre Robin
Why did I do this?
My girlfriend is writing a paper about the perception of French Hip-Hop music through time. To do that, she would like to text-mine articles from LeMonde.fr, a French mainstream newspaper.
Problem: there have been more than 7,000 articles talking about hip-hop music since the 80s.
 My girlfriend’s reaction — Memegenerator.net
My girlfriend’s reaction — Memegenerator.net
Let’s code!
For this program I will use:
- Local NodeJS Script
- fs: to write a JSON file
- Request: to make POST and GET requests
- Cheerio: to load HTML and be able to interact with it
//To install cheerio :npm i --save cheerio
Be sure you have all of it in your package.json, and everything should be fine :)
What did I want?
In the end, I wanted to have an Excel file organized like this :
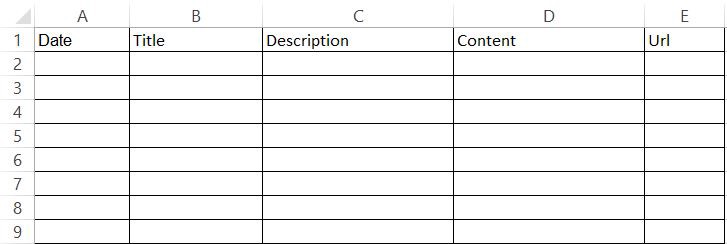 My Goal
My Goal
Therefore, I had to use a JSON structured like this. I’ll show you at the end of this article how to convert JSON to Excel.
[
{
date:,
title:,
description:,
text:,
url:,
},
]
First step: get all articles’ URLs
The first step was quite easy. Thanks to the advanced search feature, I just had to get the URL link of the result page and tell my code how to:
- Look for the number of results
- Calculate the number of pages, knowing that there are 30 articles per page
- Get the title, the description, the date, and the URL of the 30 articles for each page
Here is the code to do so:
const fs = require("fs");
const request = require("request");
const cheerio = require("cheerio");
const jsonTab = []; // We create our table
function writeFile() {
// Will write the json file
fs.writeFile("output.json", JSON.stringify(jsonTab, null, 4), (err) => {
console.log("File successfully written!");
});
}
// The URL of the advanced search feature with our keywords
const url = 'http://www.lemonde.fr/recherche/?keywords="Rap+"+"hip-hop"+"hip%20hop"+"rappeur"+"rappeurs"+"raps"+"rappers"&page_num=1&operator=or&exclude_keywords=&qt=recherche_texte_title&author=&period=custom_date&start_day=01&start_month=01&start_year=1970&end_day=20&end_month=09&end_year=2017&sort=asc';
/* The first request call, our goal here is to get the number of results and then
to calculate the number of pages */
request(url, (error, response, html) => {
const $ = cheerio.load(html);
// All the variables we will use later
let number;
let description;
let date;
let title;
let link;
if (!error) {
$(".bg_gris_clair").filter(() => {
/* We want to select all the HTML
elements with the class ".bg_gris_clair" (and we already know there is
only one) */
const data = $(this);
const str = data.children("strong").text().trim();
number = parseInt(str.substring(0, str.indexOf("e")).replace(/\s/g, ""), 10);
});
}
let count = 1;
for (let i = 1; i <= number / 10; i++) {
const urlPerPage = 'http://www.lemonde.fr/recherche/?keywords="Rap+"+"hip-hop"+"hip%20hop"+"rappeur"+"rappeurs"+"raps"+"rappers"&page_num=' + i + "&operator=or&exclude_keywords=&qt=recherche_texte_title&author=&period=custom_date&start_day=01&start_month=01&start_year=1970&end_day=20&end_month=09&end_year=2017&sort=asc";
request(urlPerPage, (err, response2, html2) => {
if (!err) {
const $ = cheerio.load(html2);
$(".grid_11.omega.resultat").filter(() => {
const json = {
date: "",
title: "",
description: "",
url: ""
};
const data = $(this);
title = data.children("h3").children("a").text().trim();
link = "http://lemonde.fr" + data.children("h3").children("a").attr("href").trim();
description = data.children("p").text().trim();
const dateStr = data.children("span").text();
date = dateStr.replace(/.+?(?=\d)/, "");
json.title = title;
json.url = link;
json.description = description;
json.date = date;
jsonTab.push(json);
});
} else if (err) {
console.log(err);
}
count += 1;
// Write the file once we iterated through all the pages.
if (count === parseInt(number / 10, 10)) {
writeFile();
}
});
}
});
Once I did that, I had a JSON file with more than 7,000 entries. For each of them, I had:
- A Date
- A Title
- A Description
- A URL
I was just lacking the content…
“Okay, I just have to use the same code and run it for the 7000 URLs I have to get the content !”
 Image Credit : Gemma Correll
Image Credit : Gemma Correll
I have been actively learning to code for one year now… And one of the first thing I learned was: nothing is ever simple in code. Ever. But for every problem you will struggle with, there is a question you can Google ;-).
I discovered that a huge part of the articles were not available without a premium account. So I had to be connected to view the content and scrape it.
Fortunately, we managed to get a premium account. I just had to find a way to tell my code how to:
- Authenticate to lemonde.fr
- Stay connected while scraping
Step Two : How to authenticate to a website
To do so, I needed to understand how a website works when I am clicking on “Log In.” The good news is: we have the developer tools.
I just needed to find out how the website sends the password and the username to the server and reproduce the pattern.
Here is the authentication page of LeMonde.fr (As this is a French platform, I have translated some words to help you understand):
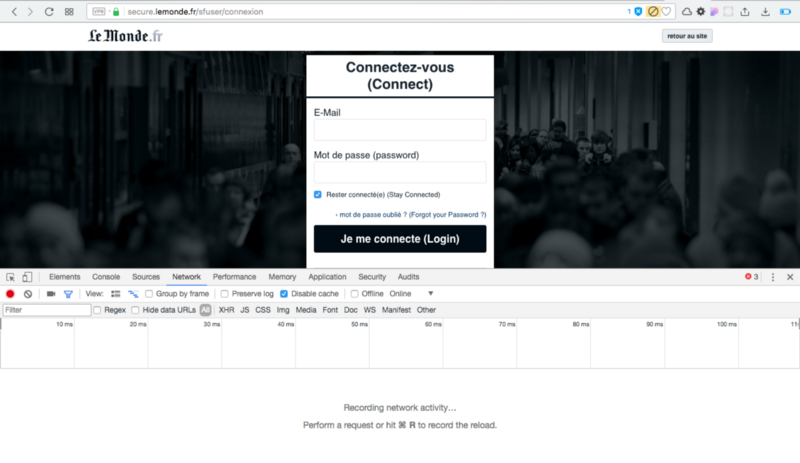 Screenshot of lemonde.fr
Screenshot of lemonde.fr
Now, what’s going on when we try to login ?
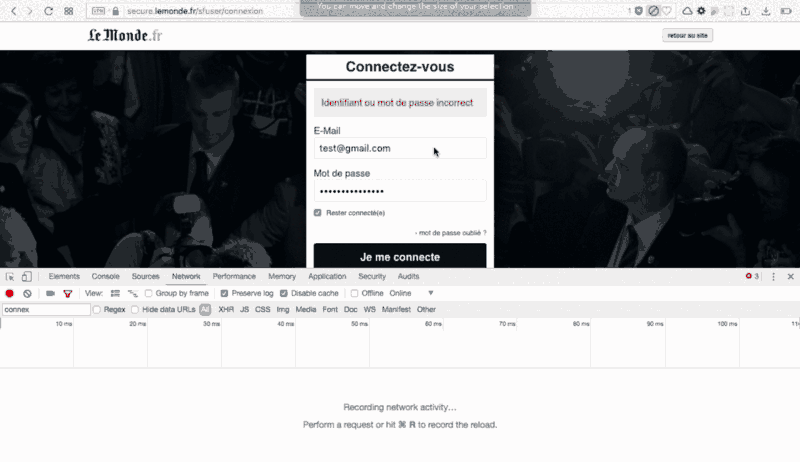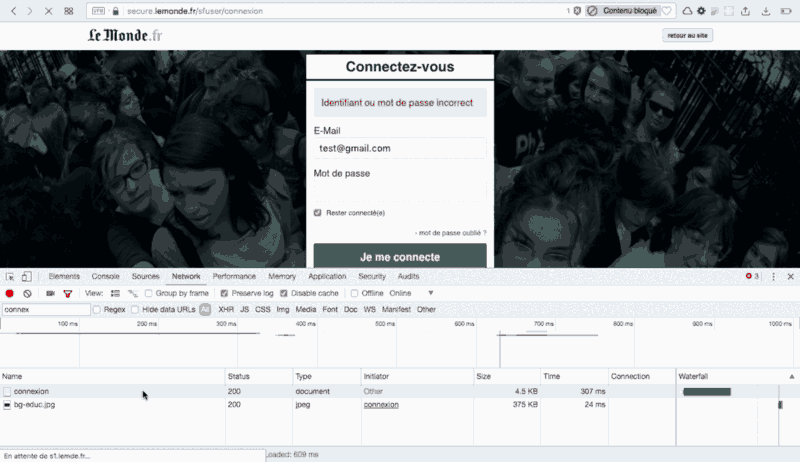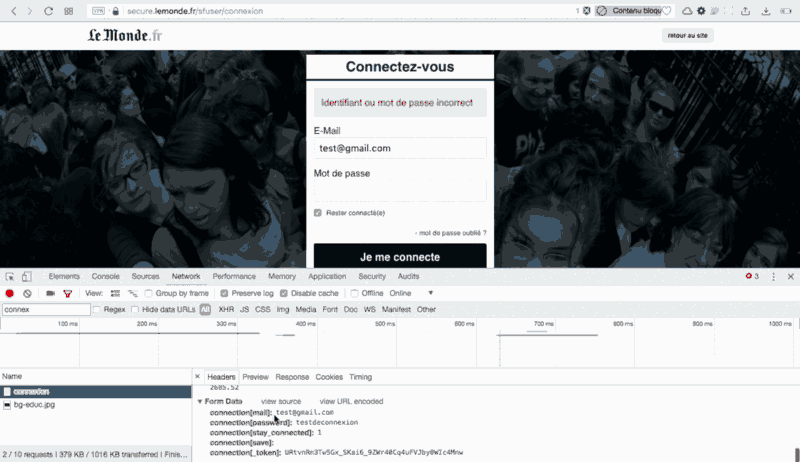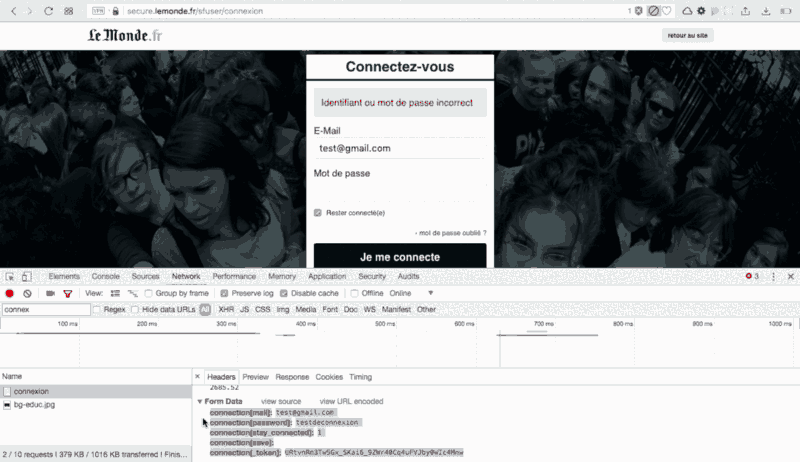
Did you see that? I clicked on “Login” and lemonde.fr sends a POST request with a simple form containing five bits of information:
- connection[mail] = ‘your username’
- connection[password] = ‘your password’
- connection[stay_connected] = boolean : 1 for true, 0 for false (HINT : you want it to be true)
- connection[save] = nothing needed here
- connection[token] = this is the tricky part
We already know four bits of info out of five. We just have to find from where the “token” is coming.
Fortunately, lemonde.fr is nice to us ☺️:
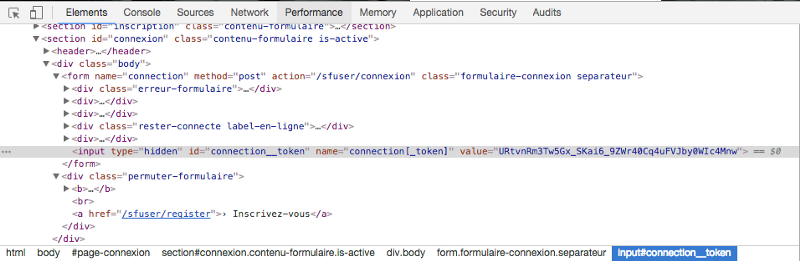
The connection token is automatically generated in a hidden input when you load the page for the first time. You just have to know it and get it before trying to log in.
Well we are now ready to move on to step 3!
Step three: Gotta catch ’em all!
 Credit : Giphy.com
Credit : Giphy.com
Here is the complete code to authenticate, retrieve, and keep the cookies and finally collect all the articles.
const fs = require("fs");
const request = require("request");
const cheerio = require("cheerio");
// Prepare all the variables needed later
let count = 0;
let timeout = 0;
const id = "myusername";
const mdp = "mypassword";
let obj;
// The URLs we will scrape from
const connexionUrl = "https://secure.lemonde.fr/sfuser/connexion";
// Will write an "output.json" file
function writeFile() {
fs.writeFile("output.json", JSON.stringify(obj, null, 4), (err) => {
console.log(
"File successfully written! - Check your project directory for the output.json file"
);
});
}
// creating a clean jar to store the cookies
const j = request.jar();
// First Get Request Call
request(
{
url: connexionUrl,
jar: j
},
(err, httpResponse, html) => {
const $ = cheerio.load(html);
// We use Cheerio to load the HTML and be able to find the connection__token
const token = $("#connection__token")[0].attribs.value; // here is the connection__token
// Construction of the form required in the POST request to login
const form = {
"connection[mail]": id,
"connection[password]": mdp,
"connection[stay_connected]": 1,
"connection[save]": "",
"connection[_token]": token
};
// POST REQUEST to Log IN. Same url with "request headers" and the complete form.
request.post(
{
url: connexionUrl,
jar: j,
headers: {
Accept:
"text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8",
"Accept-Encoding": "gzip, deflate, br",
"Accept-Language": "fr-FR,fr;q=0.8,en-US;q=0.6,en;q=0.4",
"Cache-Control": "no-cache",
"Content-Type": "application/x-www-form-urlencoded",
Origin: "http://secure.lemonde.fr/",
Host: "secure.lemonde.fr",
"Upgrade-Insecure-Requests": 1,
"User-Agents":
"Mozilla/5.0 (Macintosh; Intel Mac OS X x.y; rv:42.0) Gecko/20100101 Firefox/42.0",
Connection: "keep-alive",
Pragma: "no-cache",
Referer: "https://secure.lemonde.fr/sfuser/connexion"
},
form: form
},
(error, response, body) => {
// WE ARE CONNECTED :D
/* Second GET request call : this time, we use the response of the POST
request to request the right URL */
request(
{
url: response.headers.location,
jar: j
},
(err, httpResponse, html2) => {
const json = fs.readFileSync("./firstStep.json"); // Load the JSON created in step one
obj = JSON.parse(json); // We create our JSON in a usable javascript object
// forEach loop to iterate through all the object and request each link
obj.forEach((e) => {
let articleUrl = e.url;
/* We use a setTimeout to be sure that all the requests are performed
one by one and not all at the same time */
setTimeout(() => {
request(
{
url: articleUrl,
jar: j
},
(error1, httpResponse, html3) => {
if (!error1) {
const $ = cheerio.load(html3); // load the HTML of the article page
$(".contenu_article.js_article_body").filter(() => {
const data = $(this);
// get the content, remove all the new lines (better for Excel)
let text = data
.text()
.trim()
.replace(/\n/g, "\t");
e.text = text; // push the content in the table
});
$(".txt3.description-article").filter(() => {
const data = $(this);
const description = data
.text()
.trim()
.replace(/\n/g, "\t");
e.description = description;
});
}
}
);
count += 1;
// Write a new JSON file once we get the content of all the articles
if (count === obj.length) {
writeFile();
}
}, timeout);
timeout += 50; // increase the timeout length each time
});
}
);
}
);
}
);
I have now a JSON file with all the articles and their content. The last step is to convert it into an actual Excel table.
Bonus Step Four : From .JSON to .CSV
Here is a simple code to convert your “output.json” file to “output.csv” (You can thank my friend @jvdsande):
const fs = require('fs');
let jsonstring = fs.readFileSync('output.json') // load the output.json file
let json = JSON.parse(jsonstring)
function JSONtoCSV(JSON) {
let CSV = ''
Object.keys(JSON[0]).forEach((key) => {
CSV += key + '§'
})
CSV += '\r\n'
JSON.forEach((obj) => {
Object.keys(obj).forEach((key) => {
CSV += obj[key] + '§'
})
CSV += '\r\n'
})
return CSV
}
fs.writeFileSync('output.csv', JSONtoCSV(json))
And that is it. I can import my ‘output.csv’ file into Excel and I have what I wanted : 7,000+ rows filled with articles from LeMonde.fr
 Mission accomplished
Mission accomplished
Do you want to know the best part? I am pretty sure this logic is easily reusable for all the newspaper websites in the world!
If you are wanting to create a database or scrape a website, do not hesitate to contact me via Twitter or LinkedIN, I’d be happy to help you.
Oh! and I am working on a side project to reuse everything I learned here with LinkedIN to improve sourcing speed for recruiters :)
Thanks for reading, this is my first story on Medium and I would be thrilled to know your opinion about it!