
By Jess Wilk
In today’s world of technology, we get more recommendations from Artificial Intelligence models than from our friends.
Surprised? Think of the content you see and the apps you use daily. We get product recommendations on Amazon, clothing recommendations on Myntra, and movie suggestions on Netflix based on our past preferences, purchases, and so on.
Have you ever wondered what’s under the hood? The answer is machine learning-powered Recommender systems. Recommender systems are machine learning algorithms developed using historical data and social media information to find products personalized to our preferences.
In this article, I’ll walk you through the different types of ML methods for building a recommendation system and focus on the collaborative filtering method. We will obtain a sample dataset and create a collaborative filtering recommender system step by step.
Make sure to grab a cup of cappuccino (or whatever is your beverage of choice) and get ready!
Prerequisites
Before we embark on this journey, you should have a basic understanding of machine learning concepts and familiarity with Python programming. Knowledge of data processing and experience with libraries like Pandas, NumPy, and Scikit-learn will also be beneficial.
If you're new to these topics, you can check out the Introduction to Data Science course on Hyperskill, where I contribute as an expert.
Different Types of Recommendation Systems
You'll probably agree that there is more than one way to decide what to suggest or recommend when a friend asks our opinion. This applies to AI, too!
In machine learning, two primary methods of building recommendation engines are Content-based and Collaborative filtering methods.
When using the content-based filter method, the suggested products or items are based on what you liked or purchased. This method feeds the machine learning model with historical data such as customer search history, purchase records, and items in their wishlists. The model finds other products that share features similar to your past preferences.
Let’s understand this better with an example of a movie recommendation. Let’s say you saw Inception and gave it a five-star rating. Finding movies of similar themes and genres, like Interstellar and Matrix, and recommending them is called content-based filtering.
Imagine if all the recommendation systems just suggested things based on what you have seen. How would you discover new genres and movies? That’s where the Collaborative filtering method comes in. So what is it?
Rather than finding similar content, the Collaborative filtering method finds other users and customers similar to you and recommends their choices. The algorithm doesn’t consider the product features as in the case of content-based filtering.
To understand how it works, let’s go back to our example of movie recommendations. The system looks at the movies you've enjoyed and finds other users who liked the same movies. Then, it sees what else these similar users enjoyed and suggests those movies to you.
For example, if you and a friend both love The Shawshank Redemption, and your friend also loves Forrest Gump, the system will recommend Forrest Gump to you, thinking you might share your friend's taste.
In the upcoming sections, I’ll show you how to build a movie recommendation engine using Python based on collaborative filtering.

How to Prepare and Process the Movies Dataset
The first step of any machine learning project is collecting and preparing the data. As our goal is to build a movie recommendation engine, I have chosen a movie rating dataset. The dataset is publicly available for free on Kaggle.
The dataset has two main files in the format of CSV:
- Ratings.csv: Contains the rating given by each user to each movie they watched
- _Moviesmetadata.csv: Contains information on genre, budget, release date, revenue, and so on for all the movies in the dataset.
Let’s first import the Python packages needed to read the CSV files.
import os
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
Next, read the Ratings file into Pandas dataframes and look at the columns.
user_ratings_df = pd.read_csv("../input/the-movies-dataset/ratings.csv")
user_ratings_df.head()
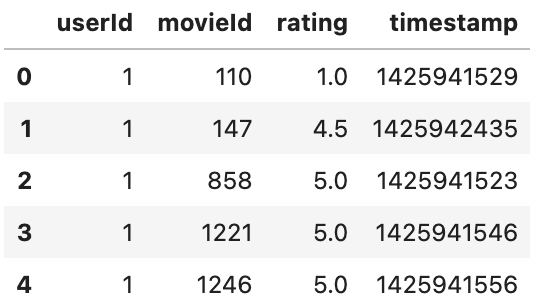
The UserId column has the unique ID for every customer, and movieId has the unique identification number for every movie. The rating column contains the rating given by the particular user to the movie out of 5. The timestamp column can be dropped, as we won’t need it for our analysis.
Next, let’s read the movie metadata information into a dataframe. Let’s keep only the relevant columns of Movie Title and genre for each MovieID.
movie_metadata = pd.read_csv("../input/the-movies-dataset/movies_metadata.csv")
movie_metadata = movie_names[['title', 'genres']]
movie_metadata.head()

Next, combine these dataframes on the common column movieID.
movie_data = user_ratings_df.merge(movie_metadata, on='movieId')
movie_data.head()
This dataset can be used for Exploratory Data Analysis. You can find the movie with the top number of ratings, the best rating, and so on. Try it out to better grasp the data you are dealing with.
How to Build the User-Item Matrix
Now that our dataset is ready, let's focus on how collaborative-based filtering works. The machine learning algorithm aims to discover user preference patterns used to make recommendations.
One common approach is to use a user-item matrix. It involves a large spreadsheet where users are listed on one side and movies on the other. Each cell in the spreadsheet shows if a user likes a particular movie. The system then uses various algorithms to analyze this matrix, find patterns, and generate recommendations.
This matrix leads us to one of the advantages of collaborative filtering: it's excellent at discovering new and unexpected recommendations. Since it's based on user behavior, it can suggest a movie you might never have considered but will probably like.
Let’s create a user-movie rating matrix for our dataset. You can do this using the built-in pivot function of a Pandas dataframe, as shown below. We also use the fillna() method to impute missing or null values with 0.
user_item_matrix = ratings_data.pivot(index=['userId'], columns=['movieId'], values='rating').fillna(0)
user_item_matrix
Here’s our output matrix:
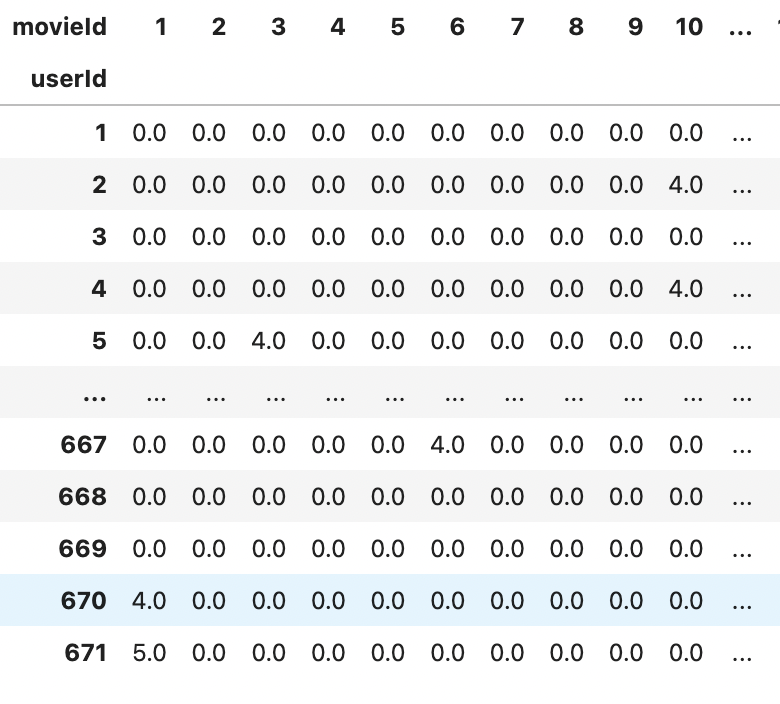
Sometimes, the matrix can be sparse. Sparsity refers to null values. It could significantly increase the amount of computation resources needed. Compressing the sparse matrixes using the scipy Python package is recommended when working with a large dataset.
How to Define and Train the Model
You can use multiple machine learning algorithms for collaborative filtering, like K-nearest neighbors (KNN) and SVD. I’ll be using a KNN model here.
KNN is super straightforward. Picture a giant, colorful board with dots representing different items (like movies). Each dot is close to others that are similar. When you ask KNN for recommendations, it finds the spot of your favorite item on this board and then looks around to see the nearest dots—these are your recommendations.
Now, the metric parameter in KNN is crucial. It's like the ruler the system uses to measure the distance between these dots. The metric used here is Cosine similarity.
What is cosine similarity?
It is a metric that measures how similar two entities are (like documents or vectors in a multi-dimensional space), irrespective of size. Cosine similarity is widely used in NLP to find similar context words.
Follow the snippet below to define a KNN model, the metric, and other parameters. The model is fit on the user-item matrix created in the previous section.
# Define a KNN model on cosine similarity
cf_knn_model= NearestNeighbors(metric='cosine', algorithm='brute', n_neighbors=10, n_jobs=-1)
# Fitting the model on our matrix
cf_knn_model.fit(user_item_matrix)
Next, let's define a function to provide the desired number of movie recommendations, given a movie title as input. The code below finds the closest neighbor data, and points to the input movie name using the KNN algorithm. The input parameters for the function are:
**n_recs**:Controls the number of final recommendations that we would get as output**Movie_name**:Input movie name, based on which we find new recommendations**Matrix**:The User-Movie Rating matrix
def movie_recommender_engine(movie_name, matrix, cf_model, n_recs):
# Fit model on matrix
cf_knn_model.fit(matrix)
# Extract input movie ID
movie_id = process.extractOne(movie_name, movie_names['title'])[2]
# Calculate neighbour distances
distances, indices = cf_model.kneighbors(matrix[movie_id], n_neighbors=n_recs)
movie_rec_ids = sorted(list(zip(indices.squeeze().tolist(),distances.squeeze().tolist())),key=lambda x: x[1])[:0:-1]
# List to store recommendations
cf_recs = []
for i in movie_rec_ids:
cf_recs.append({'Title':movie_names['title'][i[0]],'Distance':i[1]})
# Select top number of recommendations needed
df = pd.DataFrame(cf_recs, index = range(1,n_recs))
return df
How to Get Recommendations from the Model
Let's call our defined function to get movie recommendations. For instance, we can obtain a list of the top 10 recommended movies for someone who is a fan of Batman.
n_recs = 10
movie_recommender_engine('Batman', user_rating_matrix, cf_knn_model, n_recs)
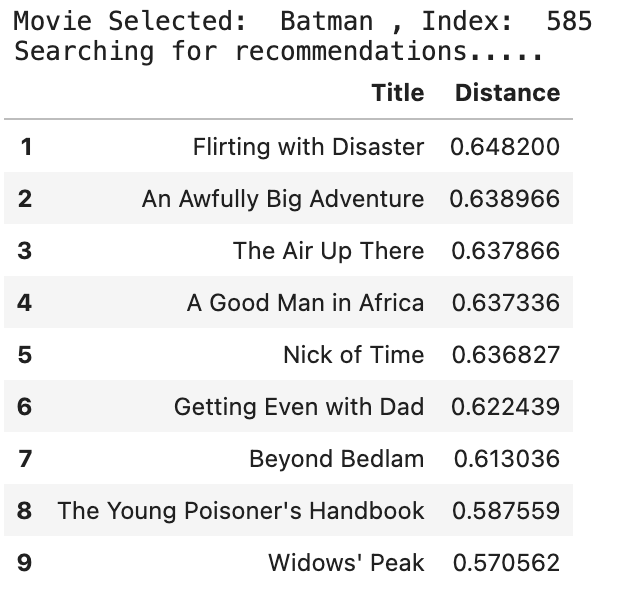
Hurray! We have got the result we needed.
Advantages and Limitations of Collaborative Filtering
The advantages of this method include:
- Personalized Recommendations: Offers tailored suggestions based on user behavior, leading to highly customized experiences.
- Diverse Content Discovery: Capable of recommending a wide range of items, helping users discover content they might not find on their own. It gives diverse content discovery the edge over content-based filtering.
- Community Wisdom: Leverages the collective preferences of users, often leading to more accurate recommendations than individual or content-based analysis alone.
- Dynamic Adaptation: The model continuously gets updated with user interactions, keeping the recommendations relevant and up-to-date.
It’s not all sunshine, though. One big challenge is the cold start problem. For example, this happens when new movies or users are added to the system. The system struggles to make accurate recommendations since there's not enough data on these new entries.
Another issue is popularity bias. Popular movies get recommended a lot, overshadowing lesser-known gems. There are also scalability issues that come with managing such a large dataset.
While developing collaborative filtering-based engines, computational expenses and data sparsity must be kept in mind for an efficient process. It’s also recommended to take action to ensure data privacy and security.
Conclusion
Using Collaborative Filtering to build a movie recommendation system significantly advances digital content personalization. This system reflects our preferences and exposes us to a broader range of choices based on similar users' tastes.
Despite its challenges, such as the cold start problem and popularity bias, the benefits of personalized recommendations make it a powerful tool in the machine learning industry. As technology advances, these systems will become even more sophisticated, offering refined and enjoyable user experiences in the digital world.
Thank you for reading! I'm Jess, and I'm an expert at Hyperskill. You can check out an Introduction to Data Science course on the platform.