
By Chuks Opia
“In this 10-year time frame, I believe that we’ll not only be using the keyboard and the mouse to interact but during that time we will have perfected speech recognition and speech output well enough that those will become a standard part of the interface.” — Bill Gates, 1 October 1997
Technology has come a long way, and with each new advancement, the human race becomes more attached to it and longs for these new cool features across all devices.
With the advent of Siri, Alexa, and Google Assistant, users of technology have yearned for speech recognition in their everyday use of the internet. In this post, I’ll be covering how to integrate native speech recognition and speech synthesis in the browser using the JavaScript WebSpeech API.
According to the Mozilla web docs:
The Web Speech API enables you to incorporate voice data into web apps. The Web Speech API has two parts: SpeechSynthesis (Text-to-Speech), and SpeechRecognition (Asynchronous Speech Recognition.)
Requirements we will need to build our application
For this simple speech recognition app, we’ll be working with just three files which will all reside in the same directory:
index.htmlcontaining the HTML for the app.style.csscontaining the CSS styles.index.jscontaining the JavaScript code.
Also, we need to have a few things in place. They are as follows:
- Basic knowledge of JavaScript.
- A web server for running the app. The Web Server for Chrome will be sufficient for this purpose.
Setting up our speech recognition app
Let’s get started by setting up the HTML and CSS for the app. Below is the HTML markup:
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<meta http-equiv="X-UA-Compatible" content="ie=edge">
<title>Speech Recognition</title>
<link rel="stylesheet" href="style.css">
<link href="https://fonts.googleapis.com/css?family=Shadows+Into+Light" rel="stylesheet">
<!-- load font awesome here for icon used on the page -->
</head>
<body>
<div class="container"> <!--page container -->
<div class="text-box" contenteditable="true"></div> <!--text box which will contain spoken text -->
<i class="fa fa-microphone"></i> <!-- microphone icon to be clicked before speaking -->
</div>
<audio class="sound" src="chime.mp3"></audio> <!-- sound to be played when we click icon => http://soundbible.com/1598-Electronic-Chime.html -->
<script src="index.js"></script> <!-- link to index.js script -->
</body>
</html>
Here is its accompanying CSS style:
body {
background: #1e2440;
color: #f2efe2;
font-size: 16px;
font-family: 'Kaushan Script', cursive;
font-family: 'Shadows Into Light', cursive;
}
.container {
position: relative;
border: 1px solid #f2efe2;
width: 40vw;
max-width: 60vw;
margin: 0 auto;
border-radius: 0.1rem;
background: #f2efe2;
padding: 0.2rem 1rem;
color: #1e2440;
overflow: scroll;
margin-top: 10vh;
}
.text-box {
max-height: 70vh;
overflow: scroll;
}
.text-box:focus {
outline: none;
}
.text-box p {
border-bottom: 1px dotted black;
margin: 0px !important;
}
.fa {
color: white;
background: #1e2440;
border-radius: 50%;
cursor: pointer;
margin-top: 1rem;
float: right;
width: 2rem;
height: 2rem;
display: flex !important;
align-items: center;
justify-content: center;
}
@media (max-width: 768px) {
.container {
width: 85vw;
max-width: 85vw;
}
.text-box {
max-height: 55vh;
}
}
Copying the code above should result in something similar to this:
 Web interface for the simple speech recognition app
Web interface for the simple speech recognition app
Powering up our speech recognition app with the WebSpeech API
As of the time of writing, the WebSpeech API is only available in Firefox and Chrome. Its speech synthesis interface lives on the browser’s window object as speechSynthesis while its speech recognition interface lives on the browser’s window object as SpeechRecognition in Firefox and as webkitSpeechRecognition in Chrome.
We are going to set the recognition interface to SpeechRecognition regardless of the browser we’re on:
window.SpeechRecognition = window.webkitSpeechRecognition || window.SpeechRecognition;
Next we’ll instantiate the speech recognition interface:
const recognition = new SpeechRecognition();
const icon = document.querySelector('i.fa.fa-microphone')
let paragraph = document.createElement('p');
let container = document.querySelector('.text-box');
container.appendChild(paragraph);
const sound = document.querySelector('.sound');
In the code above, apart from instantiating speech recognition, we also selected the icon, text-box, and sound elements on the page. We also created a paragraph element which will hold the words we say, and we appended it to the text-box.
Whenever the microphone icon on the page is clicked, we want to play our sound and start the speech recognition service. To achieve this, we add a click event listener to the icon:
icon.addEventListener('click', () => {
sound.play();
dictate();
});
const dictate = () => {
recognition.start();
}
In the event listener, after playing the sound, we went ahead and created and called a dictate function. The dictate function starts the speech recognition service by calling the start method on the speech recognition instance.
To return a result for whatever a user says, we need to add a result event to our speech recognition instance. The dictate function will then look like this:
const dictate = () => {
recognition.start();
recognition.onresult = (event) => {
const speechToText = event.results[0][0].transcript;
paragraph.textContent = speechToText;
}
}
The resulting event returns a SpeechRecognitionEvent which contains a results object. This in turn contains the transcript property holding the recognized speech in text. We save the recognized text in a variable called speechToText and put it in the paragraph element on the page.
If we run the app at this point, click the icon and say something, it should pop up on the page.
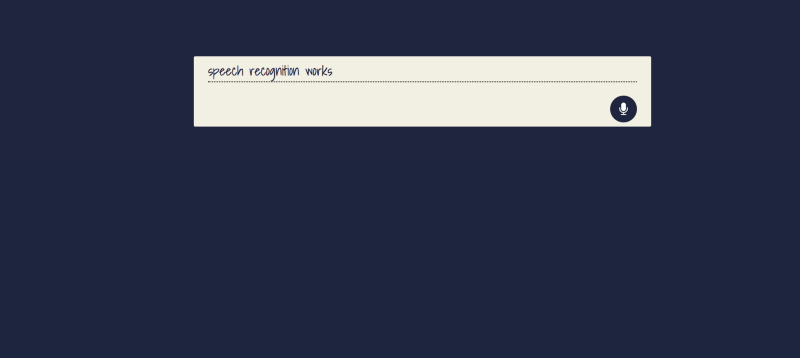 Speech to text in full effect
Speech to text in full effect
Wrapping it up with text to speech
To add text to speech to our app, we’ll make use of the speechSynthesis interface of the WebSpeech API. We’ll start by instantiating it:
const synth = window.speechSynthesis;
Next, we will create a function speak which we will call whenever we want the app to say something:
const speak = (action) => {
utterThis = new SpeechSynthesisUtterance(action());
synth.speak(utterThis);
};
The speak function takes in a function called the action as a parameter. The function returns a string which is passed to SpeechSynthesisUtterance. SpeechSynthesisUtterance is the WebSpeech API interface that holds the content the speech recognition service should read. The speechSynthesis speak method is then called on its instance and passed the content to read.
To test this out, we need to know when the user is done speaking and says a keyword. Luckily there is a method to check that:
const dictate = () => {
...
if (event.results[0].isFinal) {
if (speechToText.includes('what is the time')) {
speak(getTime);
};
if (speechToText.includes('what is today\'s date
')) {
speak(getDate);
};
if (speechToText.includes('what is the weather in')) {
getTheWeather(speechToText);
};
}
...
}
const getTime = () => {
const time = new Date(Date.now());
return `the time is ${time.toLocaleString('en-US', { hour: 'numeric', minute: 'numeric', hour12: true })}`
};
const getDate = () => {
const time = new Date(Date.now())
return `today is ${time.toLocaleDateString()}`;
};
const getTheWeather = (speech) => {
fetch(`http://api.openweathermap.org/data/2.5/weather?q=${speech.split(' ')[5]}&appid=58b6f7c78582bffab3936dac99c31b25&units=metric`)
.then(function(response){
return response.json();
})
.then(function(weather){
if (weather.cod === '404') {
utterThis = new SpeechSynthesisUtterance(`I cannot find the weather for ${speech.split(' ')[5]}`);
synth.speak(utterThis);
return;
}
utterThis = new SpeechSynthesisUtterance(`the weather condition in ${weather.name} is mostly full of ${weather.weather[0].description} at a temperature of ${weather.main.temp} degrees Celcius`);
synth.speak(utterThis);
});
};
In the code above, we called the isFinal method on our event result which returns true or false depending on if the user is done speaking.
If the user is done speaking, we check if the transcript of what was said contains keywords such as what is the time , and so on. If it does, we call our speak function and pass it one of the three functions getTime, getDate or getTheWeather which all return a string for the browser to read.
Our index.js file should now look like this:
window.SpeechRecognition = window.webkitSpeechRecognition || window.SpeechRecognition;
const synth = window.speechSynthesis;
const recognition = new SpeechRecognition();
const icon = document.querySelector('i.fa.fa-microphone')
let paragraph = document.createElement('p');
let container = document.querySelector('.text-box');
container.appendChild(paragraph);
const sound = document.querySelector('.sound');
icon.addEventListener('click', () => {
sound.play();
dictate();
});
const dictate = () => {
recognition.start();
recognition.onresult = (event) => {
const speechToText = event.results[0][0].transcript;
paragraph.textContent = speechToText;
if (event.results[0].isFinal) {
if (speechToText.includes('what is the time')) {
speak(getTime);
};
if (speechToText.includes('what is today\'s date')) {
speak(getDate);
};
if (speechToText.includes('what is the weather in')) {
getTheWeather(speechToText);
};
}
}
}
const speak = (action) => {
utterThis = new SpeechSynthesisUtterance(action());
synth.speak(utterThis);
};
const getTime = () => {
const time = new Date(Date.now());
return `the time is ${time.toLocaleString('en-US', { hour: 'numeric', minute: 'numeric', hour12: true })}`
};
const getDate = () => {
const time = new Date(Date.now())
return `today is ${time.toLocaleDateString()}`;
};
const getTheWeather = (speech) => {
fetch(`http://api.openweathermap.org/data/2.5/weather?q=${speech.split(' ')[5]}&appid=58b6f7c78582bffab3936dac99c31b25&units=metric`)
.then(function(response){
return response.json();
})
.then(function(weather){
if (weather.cod === '404') {
utterThis = new SpeechSynthesisUtterance(`I cannot find the weather for ${speech.split(' ')[5]}`);
synth.speak(utterThis);
return;
}
utterThis = new SpeechSynthesisUtterance(`the weather condition in ${weather.name} is mostly full of ${weather.weather[0].description} at a temperature of ${weather.main.temp} degrees Celcius`);
synth.speak(utterThis);
});
};
Let’s click the icon and try one of the following phrases:
- What is the time?
- What is today’s date?
- What is the weather in Lagos?
We should get a reply from the app.
Conclusion
In this article, we’ve been able to build a simple speech recognition app. There are a few more cool things we could do, like select a different voice to read to the users, but I’ll leave that for you to do.
If you have questions or feedback, please leave them as a comment below. I can’t wait to see what you build with this. You can hit me up on Twitter @developia_.