By Andrew Walsh
As a framework for developing desktop applications, Electron has a lot to offer. It grants full access to Node’s API and ecosphere. It deploys on all major operating systems (with a single codebase). And with its web-based architecture, you can use the latest features of CSS to create advanced UIs.
There are a lot of articles addressing getting up and running with Electron, but fewer dedicated to using SQLite or how to go about multithreading. We’ll look at how to use Electron to build applications that handle large amounts of data or run lots of tasks.
In particular, we’ll cover:
- How Electron works (in brief), and how its architecture affects what we can do
- Multithreading
- Using local databases such as SQLite, or writing to any file inside an Electron app
- Native modules
- A few gotchas to be aware of
- Packaging an application using native modules
How Electron works — abridged

It’s worth repeating the key principles behind Electron’s architecture. An Electron application consists of at least two processes. The main thread is the entryway to your application and does all the work necessary to show your renderer process (or processes) to your users. There can only ever be one instance of the main process.
Renderer processes use Chromium to render your app. Just as each tab runs in its own process, so too does each renderer. They are loaded using the BrowserWindow constructor’s loadURL method, which needs to point to a local or remote HTML file. That means that the only way to start up a renderer process is to use an HTML file as an entry.
Caveats of Electron’s architecture
The simplicity of Electron is one of its greatest assets. Your main process does any configuration necessary then passes a HTML file or URL to the renderer process. This file can do anything that a regular web application can — and you’re good to go from there.
But the fact that there can only be one main process makes it unclear on how to implement multithreading. Electron’s documentation implies that renderer processes are strictly designed for the task of rendering UIs (which as we’ll see, isn’t true).
It’s important to know that doing anything computationally intensive on the main process will slow down (or freeze) your renderer processes. It’s critical that any computationally intensive work is moved off the main thread. It’s best to leave it solely to the task of doing everything necessary to start your renderer processes. Since we can’t do intensive work on the same renderer process that’s rendering the application’s frontend (as this will also impact the UI), we need another approach.
Multithreading

There are three general approaches to multithreading in Electron:
- Use web workers
- Fork new processes to run tasks
- Run (hidden) renderer processes as workers
Web workers
Since Electron is built on top of Chromium, anything that can be done on a browser can be done in a renderer process. This means that you can use web workers to run intensive tasks in separate threads. The advantage of this approach is simplicity and retaining isomorphism with a web application.
However, there is one very large caveat — you cannot use native modules. Technically you can, but doing so will cause your application to crash. This is a significant problem, as any application that needs multithreading may also need to use native modules (such as node-sqlite3).
Forking new processes
Electron uses Node as a runtime, meaning that you have full access to built-in modules like cluster. New processes can be forked to run tasks, keeping intensive work off the main thread.
The main issue is that, unlike renderer processes, child processes can’t use methods from the Electron library. This forces you to maintain a channel of communication with the main process over IPC. Renderer processes can use the remote module to tell the main process to do main-only tasks without this extra step.
Another issue is that if you’re using ES modules or TC39 features of JavaScript, you’ll need to ensure that you run transpiled versions of your scripts. You will also need to include these in your packaged application. This issue affects any Node application that forks processes, but it does add another layer of complexity to your build process. It can also become tricky when balancing the demands of packaging your application with using development tools that utilise features such as live-reloading.
Using renderer processes as worker threads
Renderer processes are conventionally treated as being used to render your UI. However, they are not bound to this sole task. They can be hidden and run in the background by configuring the show flag passed to BrowserWindow.
Doing this has many advantages. Unlike web workers, you have the freedom to use native modules. And unlike forked processes you can still use the electron library to tell the main process to do things like open a dialog or create OS notifications.
One challenge when using Electron is IPC. While simple, it requires a hefty amount of boilerplate and imposes the difficulty of debugging large numbers of event listeners. It’s also another thing you have to unit test. By using a renderer process as a worker thread, you can circumvent this completely. Just as you would with a server, you can listen on a local port and receive requests, enabling you to use tools such as GraphQL + React Apollo. You can also use websockets for real-time communication. Another bonus is that you don’t need to use ipcRenderer, and can keep your Electron and web applications isomorphic (should you wish to use a shared codebase for a desktop and web application).
For advanced use cases, this approach can be combined with clustering to get the best of all worlds. The only drawback is that you’ll need to provide an HTML file as the entry for your worker renderer processes (which does feel like something of a hack).
How to use SQLite (or anything you need to write to)

There are several approaches to state management that don’t require native modules. For example, handling all of your state in the context of a renderer with Redux.
However if you need to handle large amounts of data, this won’t suffice. In particular, we’ll look at how to use SQLite in an Electron application.
To deploy your Electron application, you’ll first need to package it. There are a number of tools available for doing so — the most popular being Electron Builder. Electron uses the ASAR archive format for bundling your application into a single, uncompressed file. ASAR archives are read-only — meaning that you can’t write any data to them. This means that you cannot include your database in your ASAR archive along with the rest of your code (in electron builder, this would be under “files”).
Instead, include your database in the Resources directory of your electron package. The file structure of a packaged Electron application and where to place your database can be seen below:
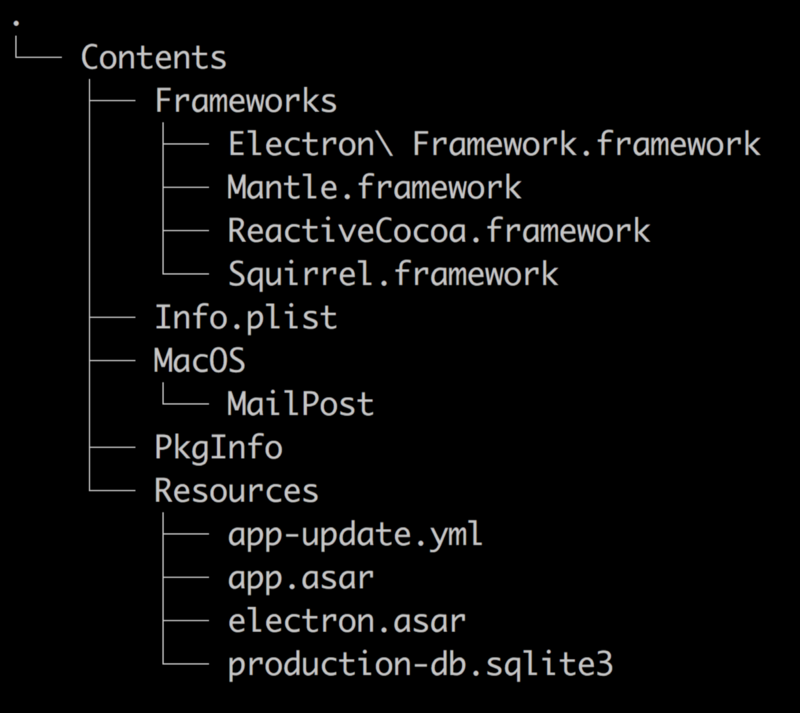
The packaged ASAR archive called app.asar exists in ./Contents/Resources. You can place your database, or any file you want to write to but include in your packaged application, in the same directory. This can be achieved with Electron Builder using the “extraResources” configuration.
Another approach is to create a database in another directory entirely. But you will need to account for deleting this file on all platforms if users decide to uninstall your application.
Packaging with native modules
The vast majority of Node modules are scripts written in JavaScript. Native modules are modules written in C++ that have bindings for use with Node. They act as an interface to other libraries written in C/C++, and are typically configured to compile after installation.
As low level modules, they need to be compiled for target architectures and operating systems. A native module compiled on a Windows machine will not work on a Linux machine — even though a regular module would. This is a problem for Electron, as we eventually need to package everything into a .dmg (OSX), .exe (Windows) or .deb (Linux) executable.
Electron applications using native modules need to be packaged on the system they are targeting. Since you’ll want to automate this process in a CI/CD pipeline, you will need to build your native dependencies before packaging. To accomplish this, you can use a tool developed by the Electron team called electron-rebuild.
If you’re developing a non-commercial open source project, you can use TravisCI (Linux, OSX) and Appveyor (Windows) to automatically build, test, and deploy your application for free.
The setup for this can be tricky if you have integration tests, as you’ll need to install certain dependencies for headless tests to work. An example config for OSX and Linux with TravisCI can be found here, and an example Appveyor config here (these examples are based on the configuration in the electron-react-boilerplate project, with the addition of OSX and deployment).
Gotchas
When your Electron application is packaged, some built-in properties of Node relating to paths may not behave as you’d expect and won’t behave as they do when you run the prebuilt binary to serve your application.
Variables such as dirname, filename and methods like process.cwd will not behave as expected in a packaged application (see issues here, here, and here). Use app.getAppPath instead.
A final note on packaging
While developing an Electron application, you may want to use both production (serving bundled code with the prebuilt binary) and development (using webpack-dev-server or webpack-serve to watch your files) modes.
To retain your sanity, build and serve your bundles from the same directory as your source code. This means that when you select these files for packaging, any file path assumptions remain consistent across these modes and your package.
At the very least, your main process will need to point to the filepath of your renderer processes’ HTML file. If you move this file into another directory as part of your build process, you will be forced to maintain file structure assumptions and this can quickly become another taxing layer of complication you need to maintain.
Debugging issues relating to incorrect filepaths in a packaged application is very much a case of trial and error.
Summary

There are several approaches to multithreading in Electron. Web workers are convenient, but lack the ability to use native modules. Forking new processes works as it would in Node, but the lack of ability to use the Electron library forces the use of IPC for common tasks and can quickly become complicated. Using render processes as workers grants the full power of all available Node server tools as a replacement for communication over IPC, while retaining access to native modules and methods from the Electron renderer library.
As Electron packages files in a read-only ASAR archive, any file we need to write to (such as an SQLite database) can’t be included. Instead, these can be placed in the Resources directory where they will remain in the packaged application.
Finally, be mindful of the fact that in a packaged application, some Node properties don’t behave as you’d expect. And for clarity of mind, match your packaged application’s file structure with your source code.