

By using big data, companies can learn a lot about how their businesses are performing. Analytics on sales, churn rates, and other basic metrics are available in almost real time as data comes in.
Then there are more complex analyses that you'll need to do. At times relationships between two seemingly unrelated data sets can provide surprising insights and unveil important opportunities for the organization.
Data scientists and engineers are continuing to improve how they break down and work on data. Experimentation entails discovering the right correlations among data points.
This means they also need to do some sort of parallelization of such data and resulting models. Parallelization simply means that the same data set is being operated upon in many different ways without damaging the integrity of the original data.
In this article we are going to talk about how you can make sure you're doing such experimentation and parallel processing efficiently and that it provides the maximum insights. We will be tackling different concepts related to data storage and data versioning.
Block Storage vs Object Storage
For the uninitiated, we first must understand the difference between block and object storage and why the latter is the better option when dealing with data experimentation.
 _
_What is Block Storage?
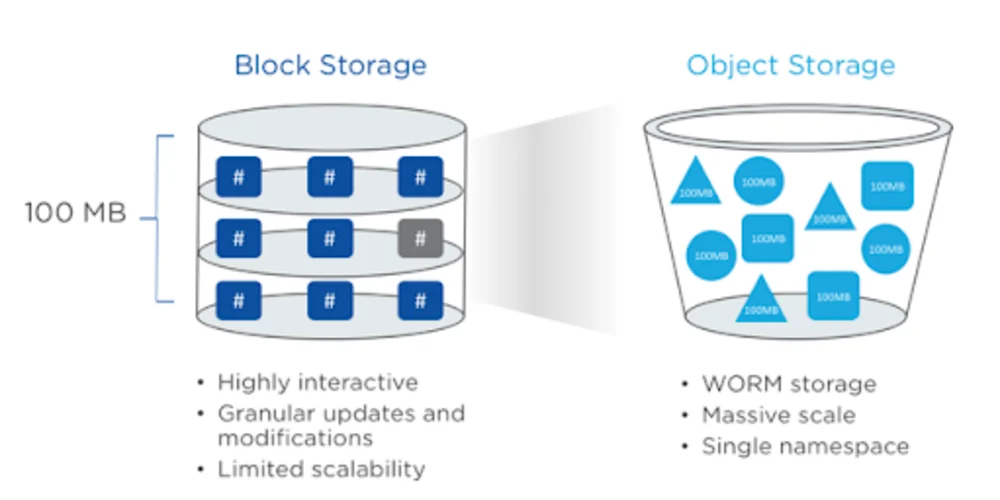
It is called “block storage” (also known as SAN) because each dataset (in the form of files) is grouped into blocks stored in disks.
A classic example of block storage is the file system on your personal computer. For enterprise-level use-cases, it is scaled through a network of hard drives connected through fiber optic cables.
There are a few disadvantages to using block storage. First, if a sector (or a block) becomes corrupted, it can damage the files. Another problem is the lack of scalability (expanding the network of fiber optic cables is costly).
What is Object Storage?
In object storage, data is stored as objects. Each object contains the actual data, called the blob, a unique identifier (UUID), and metadata, which contains information about the object (such as timestamp, version, and author).
Object storage makes it cost-effective to scale your data store—you don’t need complex hardware for this. It also makes data retrieval faster as each object can be retrieved through its UUID.
This is in contrast to block storage, where each data location needs to be identified before the actual information can be retrieved.
One disadvantage of using object storage is that data can only be written once and cannot be updated. But this isn’t really a disadvantage as we will see further on in this article.
What Problems Does Object Storage Solve?
As we have already seen, data retrieval can be incredibly fast with object storage (no matter the size of the data store). But when it comes to data experimentation and data parallelization, object storage shines the brightest.
As mentioned before, you can't overwrite any data already stored as an object. This ensures object storage is protected from unwanted (or unauthorized) data destruction or updating. That’s great to know if you do a lot of data processing where accidental corruption of information could happen.
One other problem that object storage can solve is that it doesn’t require data to be structured. As companies produce and consume tremendous amounts of information every moment, often non-structured data (such as PDFs, videos, images) are not so easily processed into useful forms (such as for analytics or dashboards).
With object storage, this is now possible. You can now use non-structured data to develop machine learning models.
With data storage, it’s possible to have different versions of the same blob (with different metadata). As there is Git for code version control, we can have similar ways of managing different versions of the same data.
This brings us to the concept of data lakes.
What are Data Lakes?
Data lakes are central repositories of data that don’t care which format such data is in.
Companies produce and consume tremendous amounts of data. Such data traditionally sits in silos because they belong to different departments or are in different forms (for example, videos aren’t stored in the same directory as the data in the MySQL database).
With data lakes, any department in the enterprise can store information without the need to pre-process it. Likewise, any data can be retrieved and analyzed by anybody from any department.
Data lakes are important because they make data analytics extremely fast and convenient.
How Data Experimentation and Parallelization Work with Object Storage
As with developing software, working with data requires us to utilize tools that can aid us in our workflow. A powerful open source tool for experimenting with data and performing parallelization (that is working on the same data to create different sets of machine learning models) is LakeFS.
LakeFS is an open source platform that provides Git-like capabilities when working with data. This means you can create branches (allowing you to experiment with data) and commit versions of data (and data models).
Why is this Git-like feature important?
First, you need to make sure that your data lake is ACID compliant. This means that your data changes can happen in isolation (in branches). Thus, the integrity of the data is maintained in the master branch (until such changes are ready to be merged).
Another important feature of LakeFS is continuous integration of data (again, much like in software development). Enterprises need to incorporate new data quickly and without being disrupted. Therefore, this ability to have a CI/CD workflow is invaluable.
So, let’s see how we can get started with using LakeFS with our object storage experimentation and parallelization.
How to Install LakeFS
Locally you can install LakeFS by running the following command in your terminal:*
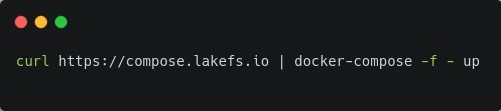
_*This is assuming you have Docker and Docker-Compose installed in your system. If you don’t have Docker and Docker-Compose, you may try other installation methods here._
Now visit http://127.0.0.1:8000/setup in your browser to verify you have installed it correctly.
How to Create a Repository in LakeFS
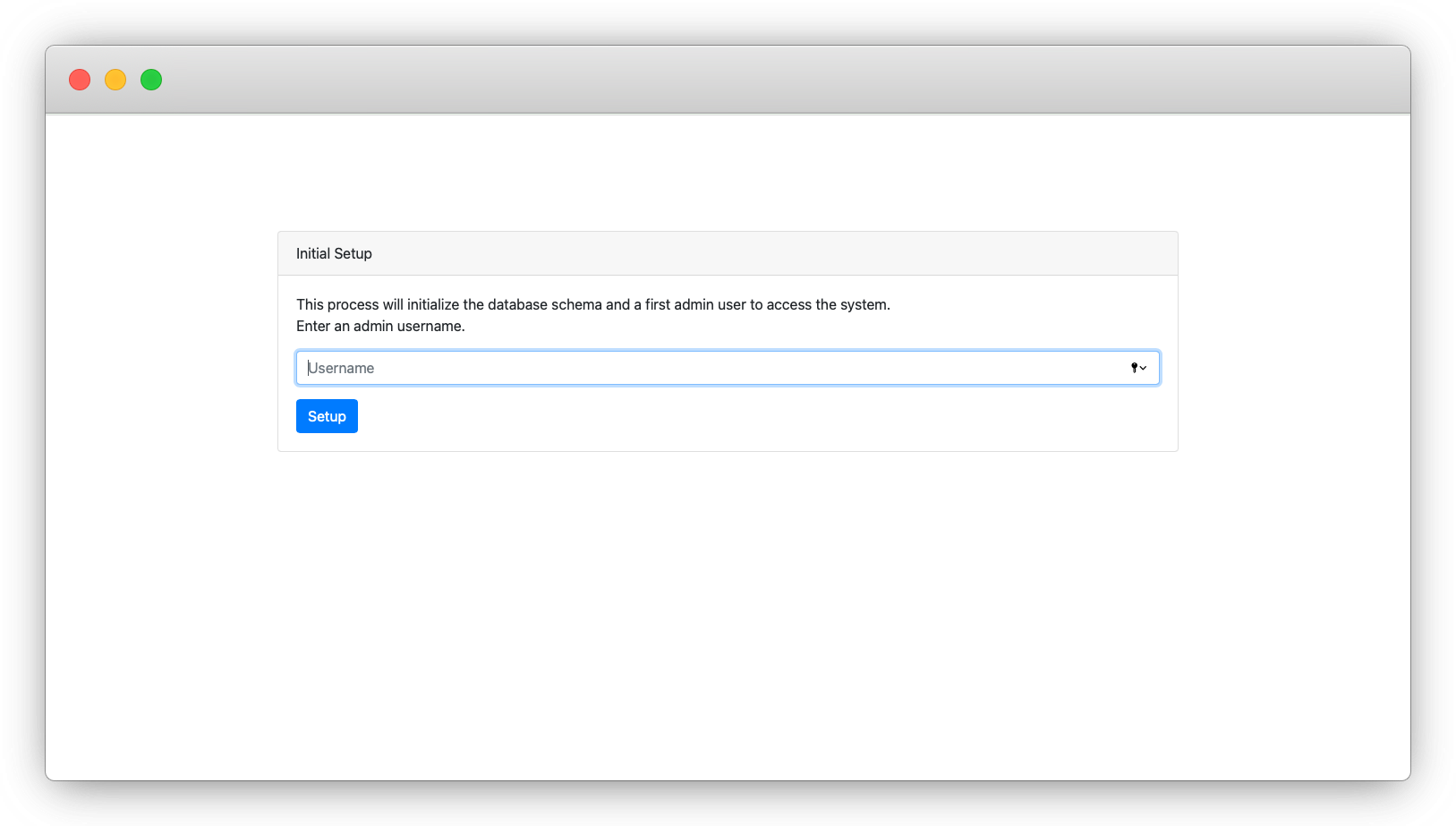
Once you’ve verified that LakeFS is installed correctly, go ahead and create an admin user.
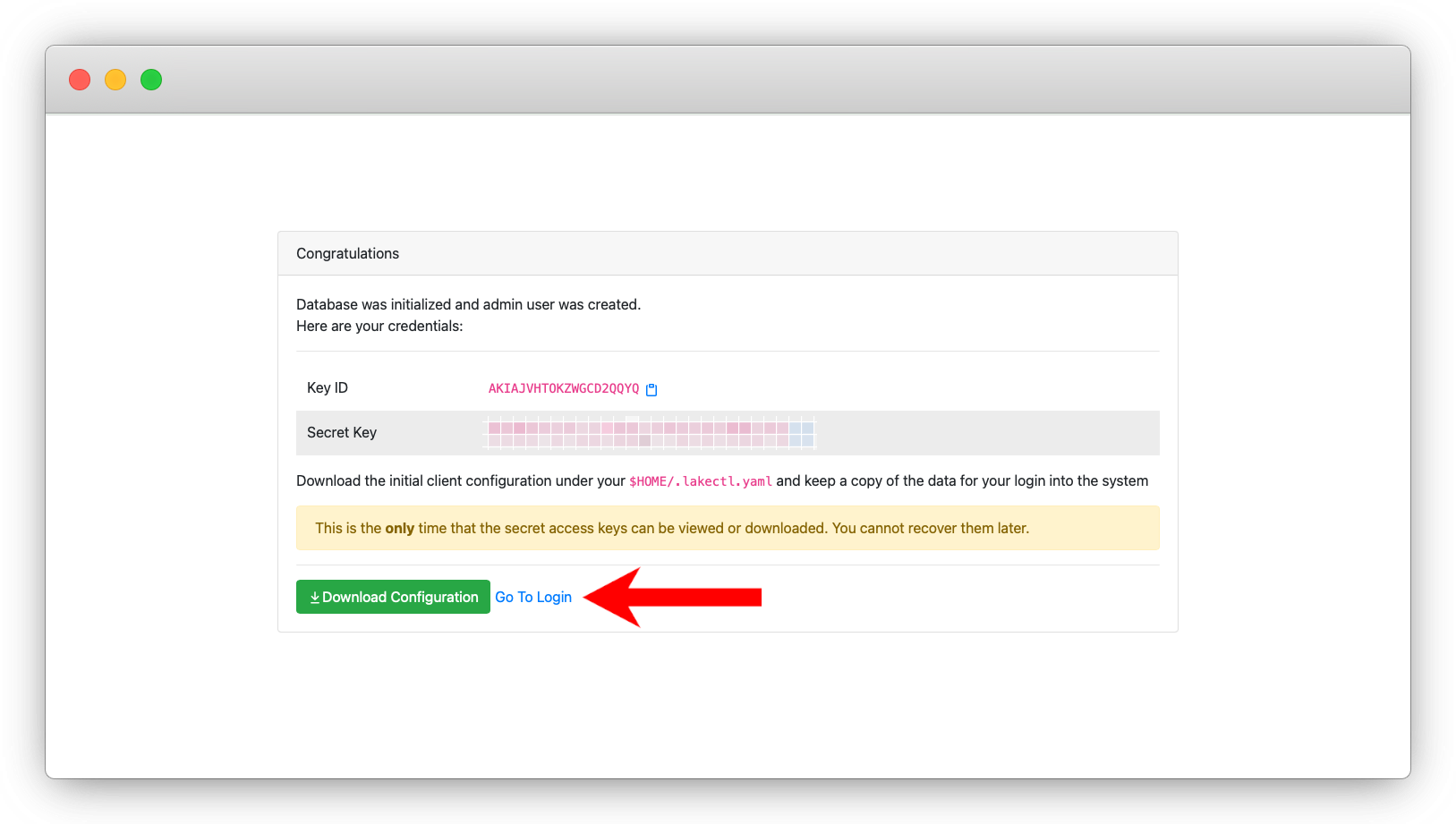 _
_Click on the login link and log in as an administrator.
On the page to which you get redirected, click on Create Repository. A popup will appear:
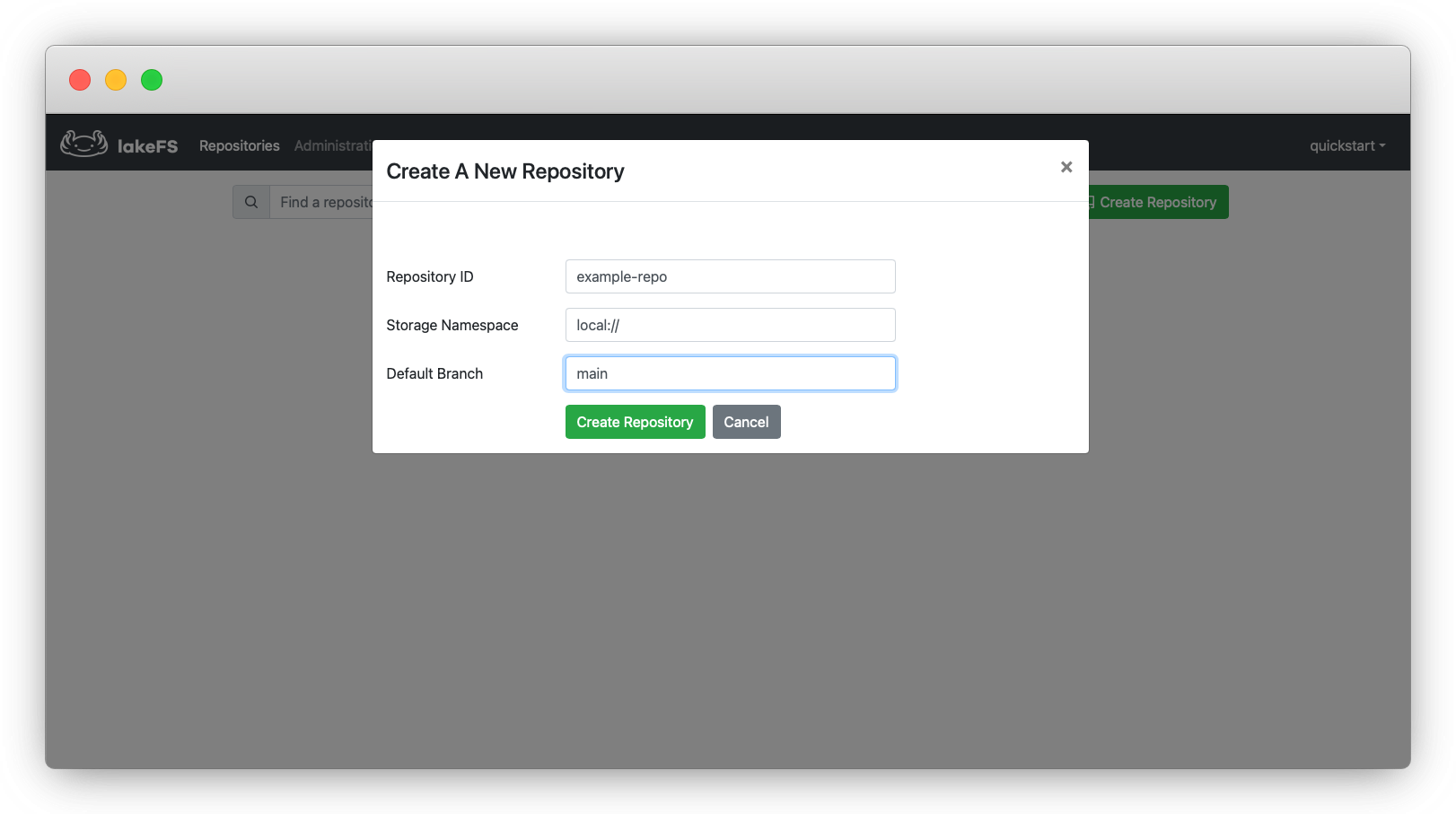 _
_Congratulations! You now have your first repository. This is the main “bucket” in which you are going to store your data.
Next, we’ll start adding some data.
How to Add Data to your LakeFS Repository
Visit here to install AWS CLI.
With the credentials created during the admin-user creation phase, configure a new connection profile:
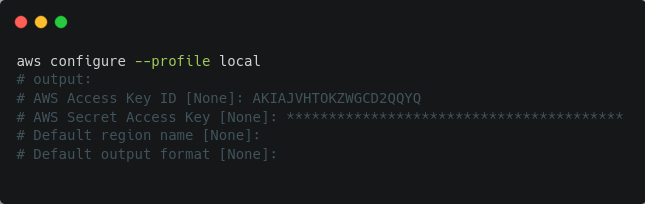
To test if the connection is working, run the following:
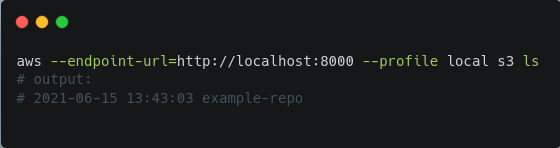
Now, to copy files into the main branch:

Just note that we need to prefix the path with the name of the branch we want to use.
Now, we will see the file we’ve added in the UI:
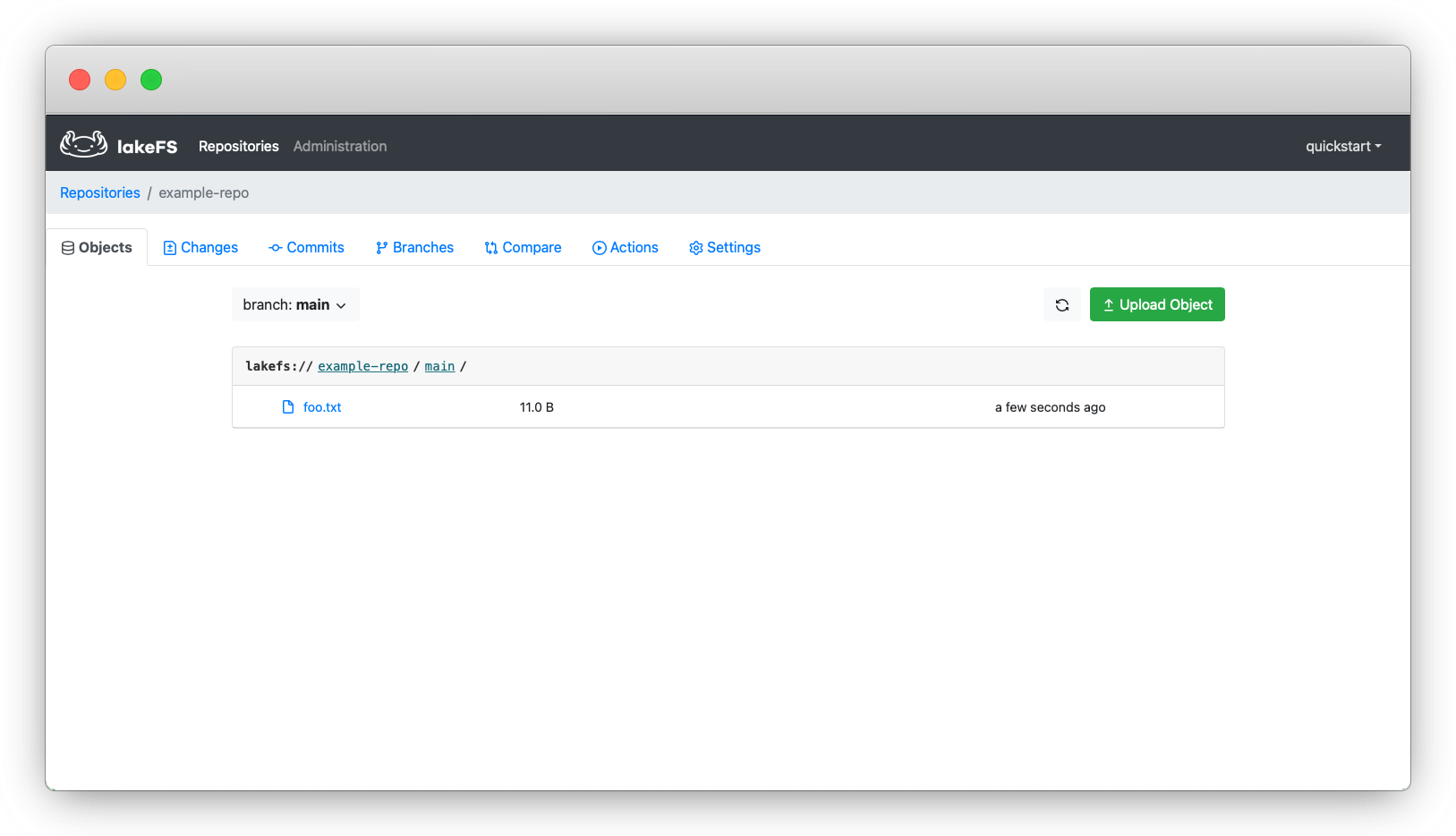 _
_Next, we will need to know how to commit and create branches. To do that, we will need to install the LakeFS CLI.
How to Install the LakeFS CLI
You need to first download the binary file here.
Again, we need to use the earlier created admin credentials:
Here are some of the commands we can run to try it out:

You can find all the other commands, such as branch creation, and so on, online.
There you have it! Now, you can work with your data any way you like. Experiment without guilt and create multiple versions of your data models.
In Closing
In this article, we covered a bit of ground. We learned the different kinds of data storage mechanisms and why object storage has a lot of edge when dealing with data experimentations and parallelism.
Next, we looked into data lakes and LakeFS, which is a powerful tool for working with data.
At first, it might seem a daunting task. But, as we’ve shown here, with the right set of tools and knowledge, there’s a lot you can accomplish.