By Dalya Gartzman
Have you ever wondered what are all these neural networks that everyone is talking about, and were too afraid to ask? Well, fear no more! By the end of this post you’ll be able to walk into any conference and dazzle the lunch table with your newly acquired buzzwords!
If you’ve opened your browser in the last couple of years, you must have seen the expression “Neural Networks” a couple ( hundred) times.
In this short read, I will give you some context on the domain and on the thing itself. You won’t become the world’s expert in the field in the next 5 minutes, but you will get through the non-trivial onboarding stage. You will also learn some buzzwords to impress the family at the dinner table, especially if you follow the reading list at the end.
What is Machine Learning?
To understand Neural Networks, we first need to understand Machine Learning. And to understand Machine Learning, let’s talk about Human Learning first, or “classical programming”.
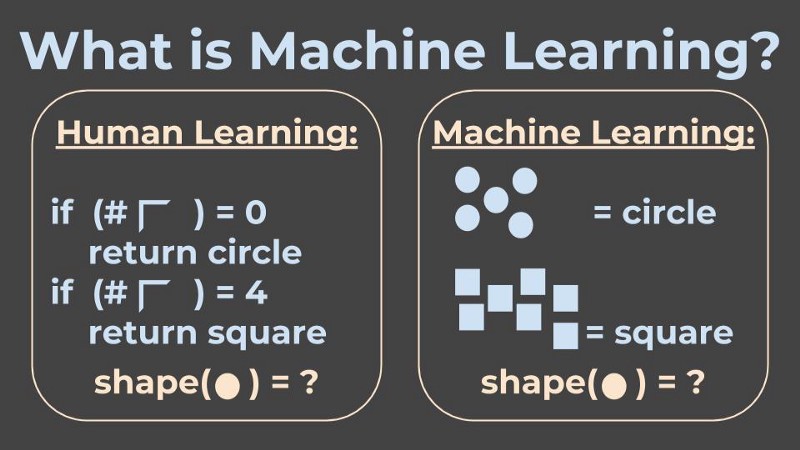
In classical programming, I, the developer, need to understand the aspects of the problem I am trying to solve, and to know exactly what all the rules are to make it to the solution.
For example, let’s say I want my program to know the difference between a square and a circle. Then one way to handle it is to write a program that can detect corners, and then apply it to count the corners. If my program sees 4 corners, then this shape is a square, and if it sees no corners, then this shape is a circle.
And Machine Learning? Very generally speaking, Machine Learning = learning from examples.
In Machine Learning, when facing the exact same problem of telling apart circles and squares, we would design a learning system that would take as input many examples of shapes and their class (square or circle). We would hope that the machine would learn by itself the properties that tell them apart.
And then, my friends, once the machine has learned all these properties, I can give it a new image of a circle or a square, one it hasn’t seen before, and it will hopefully classify it correctly.
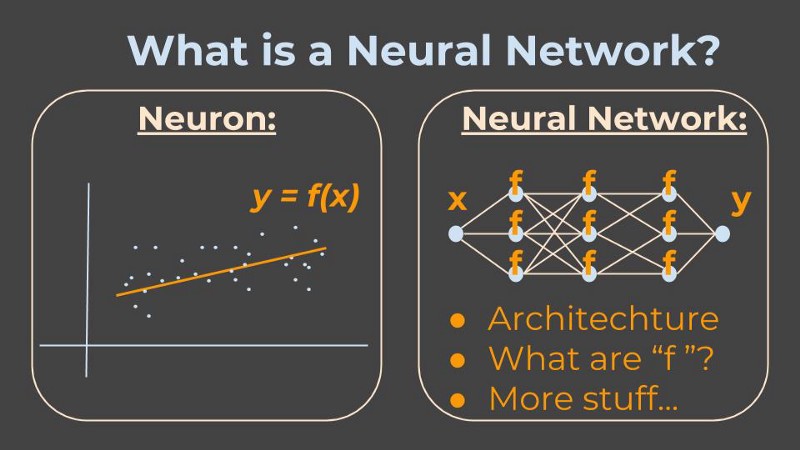
What is a Neuron?
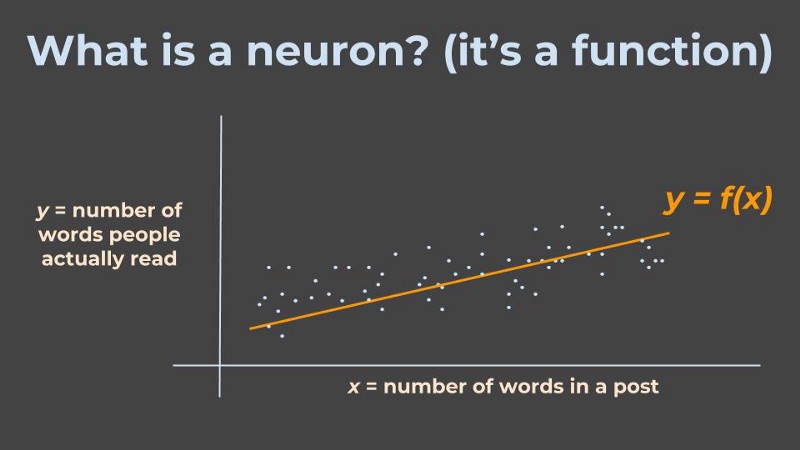
A neuron, in the context of Neural Networks, is a fancy name that smart-alecky people use when they are too fancy to say function. A function, in the context of mathematics and computer science, is a fancy name for something that takes some input, applies some logic, and outputs the result.
More to the point, a neuron can be thought of as one learning unit.
Therefore, we need to understand what is a learning unit, in the context of Machine Learning. Then we will also understand the most basic building block of a Neural Network, which is the neuron.
To illustrate, let’s say I am trying to understand the relationship between the number of words in a blog post, and the number of words people actually read from that blog post. Remember - we are in the Machine Learning domain, where we learn from examples.
So I collect many examples of word count in blog posts, denoted by x, and how many words people actually read in those posts, y, and I imagine there is some relationship between them, denoted by f.
However, the trick is, that I just need to tell the machine (the program) sort of what is the relationship I expect to see (for example a straight line), and the machine will understand the actual line it needs to draw.
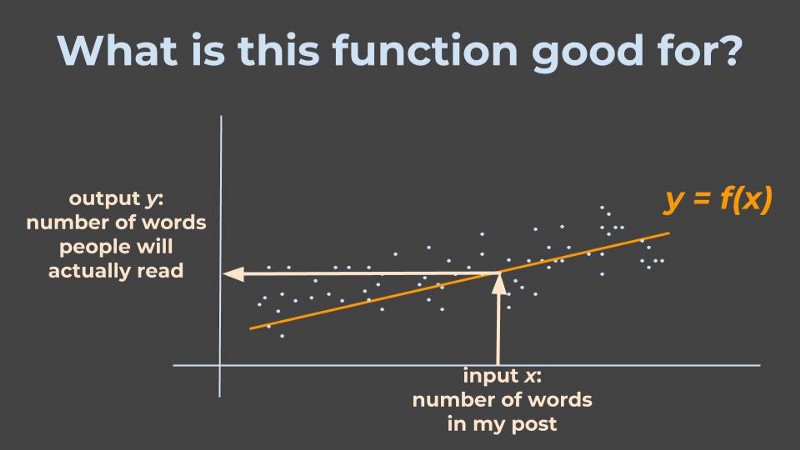
What did I gain here?
Next time I want to write a blog post that has x words in it, the machine can apply the relationship f it found, and tell me how many words I can expect people to actually read, y.
So, a Neural Network is…
Well, if a neuron is a function, then a Neural Network is a network of functions! Meaning we have many (many many) such functions, such learning units, and all their inputs and outputs are intertwined and they feed each other.
As the designer of this network, it is my job to answer some questions:
- How do I model the inputs and outputs? (for example, if the input is some text, can I model it in letters? numbers? vectors?….)
- What are the functions in each neuron? (are they linear? exponential?…)
- What is the architecture of the network? (that is, which function’s output is which function’s input?)
- What are the buzzwords I can use to describe my network?
Once I’ve answered these questions, I can “show” the network many (many many) examples of correct inputs and outputs, in the hope that when I “show” it a new example input it has never seen before, it will know to give the correct output.
How this learning process works is beyond the scope of this post, but to learn more you can watch this. You can also go to this insanely cool Neural Network Playground to get a better sense of what this means.
Neural Networks - The Never-ending Story
As this field is literally exploding, the amount of new (and high quality!) content coming out every minute is impossible for any human to follow. (OMG do you think there will come a time when humans can build an AI that will be able to keep track of human advancements in the AI domain??)
Coming into this field, the first thing to know is that NOBODY knows everything. So feel comfortable where you are, and just keep being curious :)
Therefore, I want my last words in this post to be a reference to some of my personal favourite resources to learn from:
- Gal Yona - one of my favourite bloggers in the field. Her posts range from hard-core technical explanations to semi-philosophical reviews.
- Siraj Raval - a youtuber with a huge collection of videos, ranging from theoretical explanations to hand-on tutorials, all super fun as well!
- Christopher Olah - a passionate and insightful researcher, maintains a visually inviting blog, with posts from basic concepts to deep-dives.
- Towards Data Science is the largest Medium publication specific to the field, and what I love about it is that the editors are excellent curators. Whenever you have a few minutes/hours to spare, just go to their homepage and start exploring everything, from practical tools to deep algorithmic content.