
By Tim Nolet ???
Imagine the following:
- You have a Saas service that allows users to run server side Node.js code.
- The code is executed on your servers.
- The code can download anything from the internet.
- Any output generated by the code is made available to the user.
This is a performance and security nightmare. It is also the situation I found myself in when building a new tool for my new solo SaaS endeavour.
The use case
One of the key features of my new tool is to let anonymous users run Puppeteer scripts in a sandbox environment. Puppeteer is a project by the Google Chrome team (22k Github stars ✨ ) that allows users to run Chrome headless, as in without a screen, and automate interactions with a web page.
This is very useful for testing, web scraping, monitoring and a whole bunch of other use cases. The new tool’s purpose is that users can quickly try out these scripts without the hassle of installing and running Puppeteer on their own machines. Very similar to the JSFiddle, CodePen and other code playgrounds out there.
Key here is that the user has full access to JavaScript and Node.js , can download whatever they want from the internet and that I (well…my servers) will run that code for them! ? Yikes!
What could possibly go wrong?
Here are some of the ways people (my users) can screw things up with their bits of code:
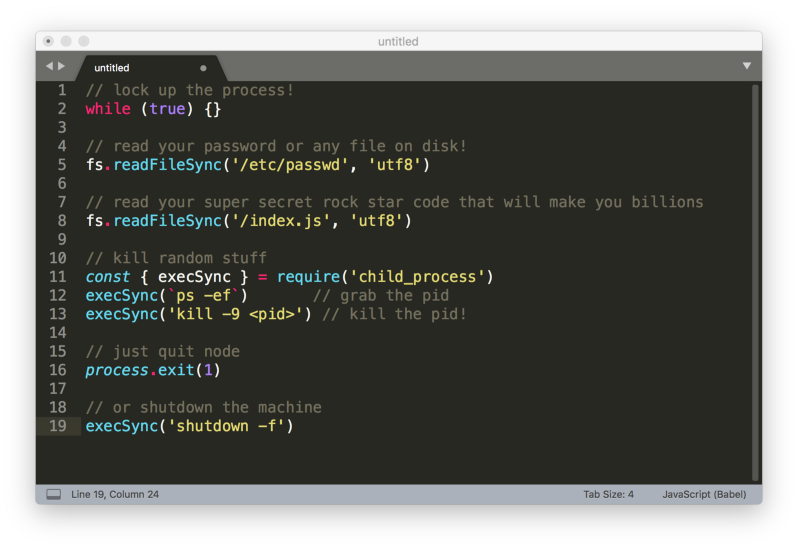
And, as we’re running a multi-tenant Saas, there are probably ways to hijack other sessions and peak into other peoples processes and code. Yes, it’s pretty nasty.
Whether this is due to malicious intent or just by writing buggy code doesn’t really matter. The end result is either slow/dead servers, your (and possibly other users) credentials on the street, and just a general bad time.
Layers, layers…layers!
The solution to this problem that I’ve come up with is as follows.
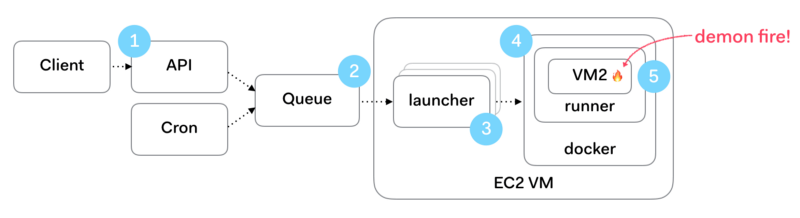
A request to run some untrusted code is first rate limited at (1), after which it is put into an AWS SQS message queue at (2). Messages are picked up by what I call a launcher process (3) which executes the work. This is a typical fan out / master-worker pattern. The launcher preps and launches a Docker container (4) which in turn executes the user’s code inside a Node.js VM2 “soft container” (5). Let’s look at each of these steps in detail.
1. Rate limiting
To avoid DDOS scenarios, where users pummel your API with HTTP requests, we need to first add rate limiting, also called request throttling. This is even more important in my specific scenario. Each lightweight HTTP request can potentially trigger a much heavier background job. (Puppeteer spins up a full Chrome browser.)
This means the API server could become unresponsive but also that the job servers could start being overwhelmed. As I’m planning to add autoscaling functionality to the job servers, more job requests equals more resource usage. This would result in ballooning servers cost. Not good for your poor solo-dev startup owner.
There are many rate limiting frameworks and plugins out there. As I’m using the Hapi.js framework, I opted for the hapi-rate-limit plugin. And there’s not much else to say about it. Install it, add it to the API routes you want protected et voilà, it just works. This plugins gives you some great options that cover a lot of rate limiting scenarios:
- IP and user white listing.
- Limiting per user, per path or both.
- X-Forward-For awareness, handy for running behind a load balancer.
Furthermore, the plugin adds a couple of HTTP response headers to each request, showing the status of the rate limiting algorithm.
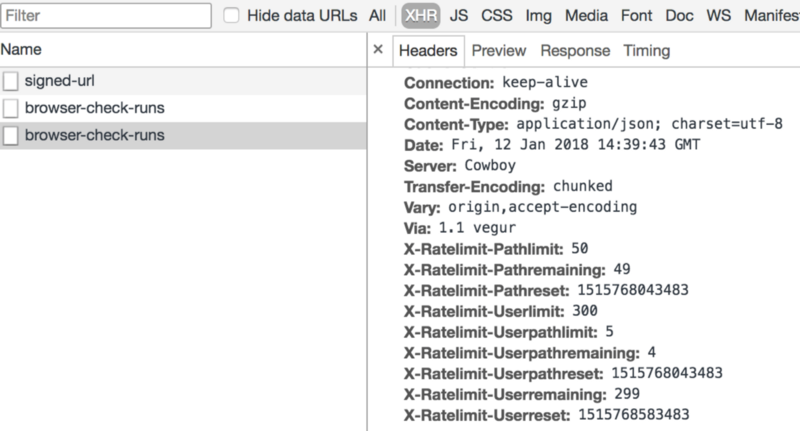
In the image above, you can see that I’ve made one request. This request is subtracted from the maximum amount of requests I can make per my UserPathLimit. This is defined as the number of total requests that can be made on a given path per user per period. This period resets after a while.
What happens if someone hits the rate limit? We put them in the naughty corner for a bit and serve them cheese. The motto being that the customer is always right but he/she should not be allowed to trash your system.
2. Async background jobs
Delegating the the actual running of the untrusted code into background jobs is a pretty common pattern. You don’t want to tie up your HTTP server’s request cycle with long running jobs. The added benefit here is that if anything bad happens while running the untrusted code, it will not take down or otherwise compromise your customer facing API server.
In my solution, the HTTP POST request that contains the code to run is unwrapped and dumped into an SQS message queue. The message sits there until a launcher node picks the message up and attempts to process it. This is where the role of the API server ends. The motto being to never bother your user facing API server with long running and potentially dangerous requests.
3. Process isolation: splitting launcher and runner
Late into building this architecture, I realised I needed to split the launcher and runner code AND stick the runner into a Docker container. The reason for this becomes evident when we look at what the launcher/runner combo needs to do.
These are the tasks assigned to the launcher process:
- Listen to SQS, unwrap the message and extract untrusted code from it.
- Write the code to a dedicated work directory.
- Launch a Docker container (the runner) mounted with the work directory using the excellent Dockerode.
- Read the output from the runner and relay message via AWS IOT to the waiting user.
- Monitor the state of the running container.
- Upload any screenshots to S3.
- Pass a final message after the run has finished to the database.
- Cleanup files, temporary work dir and other debris.
To perform all this work, the launcher has quite a lot of privileges and needs access to a lot of credentials like AWS services, database access, file system access. All of these are attack vectors that are easy to exploit by anyone doing a console.log(.../configuration/config.json) , console.log(process.env) or something similar.
Again…yikes! ?
This is why the untrusted code should never run in the same context as the launcher.
Stability is also increased by splitting launcher and runner. If the launcher would hang or die, the whole system effectively loses capacity. Something like the PM2 process monitor would of course restart the process, but there would certainly be noise and friction due to these crashes.
Ergo, in the current design the launcher is never directly exposed to any untrusted code. The motto being to always protect the server code, even at the expense of the user’s code.
The runner is a bit weird, let’s have a look.
4. OS Sandboxing with Docker
The runner part of this equation is started by the launcher kicking of a Docker container which holds the runner process. The runner then executes the users untrusted code. Using a Docker container brings a couple of benefits:
- The Node process has no access to the parent host. All environment variables, files etc. are not accessible so there is no snooping into sensitive files. Actually the reading of files is not possible but more on that later.
- Job isolation: jobs from multiple users run on one machine and we want to at all times avoid any possibility of “cross pollination”.
- Easy cleanup: every container is destroyed when it finishes running, together with all the horrible downloads, code and whatever malicious bits and bobs it dragged in.
Docker in general provides pretty in depth security tweaking by using the --cap-add flags described in the Runtime privilege and Linux capabilities docs. I was happy to not have to dive into the horrible mess that is selinux…
Outside of these security benefits, the Docker container also makes shipping and testing a bit easier. Getting Puppeteer to run inside a Docker environment was a bit of a challenge, requiring a lot of extra packages but there are some excellent guide lines that should help with most Debian / Ubuntu based distro’s.
5. Node Sandboxing with VM2
The runner-inside-Docker solution is effectively a jail. But we are still allowing the inmates to use all the tools the Node.js standard library gives them to poke around. Would it not be better to severely thin out the toolbox? Yes, it is, and the first stop is Node VM.
Node VM is part of the standard Node distribution and provides sandboxing capabilities within the V8 engine: it just has a very limited interpretation of the the term “sandbox”, as in you can break out of it very easily and you can add packages and do whatever damage you want. Admittedly, the Node guys put this in big fat letters in the docs:

Luckily, there is VM2 a semi offshoot that is built to clamp down on untrusted code and the things it can run. Its main party tricks are that you can white list what modules the code injected into the VM has access to.
For example, you could white list just fs.write() but not fs.read() . Or you can block the usage of process to avoid the dreaded process.exit() or process.env . This is pretty amazing and full credit goes to @patricksimek
External packages can also be whitelisted, giving you the option to allow the use of popular packages like lodash or other utility libraries without giving users access to npm install .
We are now finally at the point where the untrusted code is executed. Using VM2 this is as simple as invoking the run() method with a stringified version of the untrusted code.
vm.run(untrustedCode) .then(output => { console.log(output)})
We have however one problem left. How do we get output back to the user? We are not allowing the runner inside the VM2 process inside the Docker container to have any access to a message bus or anything else outside of its context. The process is also decoupled from the launcher process, so we cannot use a simple callback.
At this moment, I solved this problem by allowing the runner to only write logging to stdout and to write images to a shielded of temporary directory which gets erased after running.
This means the launcher reads the stdout of the runner, basically parsing a long string and chopping out useful data based on prepended and appended control codes. This way the data is sanitized and passed into the upstream channels. Image files are read from disk and directly pushed to S3, taking into account file size and possible file corruption.
Conclusion
Running untrusted code is a bit like building a medieval castle. It is not about one, unbreakable magic gate, one deep moat or one high tower that takes care of all your woes. It’s about layers of solutions that are annoying enough to scare of intruders and catch the mistakes of the layer above or below it.
P.S. If you liked this article, please show your appreciation by clapping ? below and follow me on Twitter! But wait, there’s more!
I’m building an active monitoring solution for developers and startups https://checklyhq.com

Cray cray! ?