


Artigo original: Introduction to Algorithms Handbook – with JavaScript Examples
Oi, pessoal! Neste artigo, vamos dar uma olhada em algoritmos, um tópico chave quando se trata de ciência da computação e desenvolvimento de software.
Algoritmo é uma palavra chique e às vezes intimidadora, mas frequentemente incompreendida. Parece algo muito difícil e complexo, mas, na verdade, nada mais é do que um conjunto de passos que devem ser dados para atingir um determinado objetivo.
Eu diria que o conhecimento básico sobre algoritmos consiste principalmente em duas coisas:
- Notação assintótica (que usamos para comparar o desempenho de um algoritmo com outro).
- Um conhecimento geral de algoritmos clássicos usados para tarefas muito frequentes, como pesquisar, classificar e percorrer.
É exatamente isso que vamos ver aqui.😉
Vamos lá!
Sumário
- O que é um algoritmo?
- Complexidade algorítmica
- Algoritmos de pesquisa
- Pesquisa linear
- Pesquisa binária
- Algoritmos de ordenação
- Ordenação por bolha
- Ordenação por seleção
- Ordenação por inserção
- Ordenação por mistura
- Ordenação rápida
- Ordenação Radix
- Algoritmos de travessia
- Pesquisa por largura (Breadth-first search, ou BFS)
- Pesquisa por profundidade (Depth-first search, ou DFS)
- Pré-ordem por DFS
- Pós-ordem por DFS
- Em ordem por DFS
- Conclusão
O que é um algoritmo?
Como mencionado anteriormente, um algoritmo é apenas um conjunto de etapas que precisam ser executadas em ordem para atingir um determinado objetivo.
Eu acho que quando as pessoas ouvem a palavra algoritmo pela primeira vez, elas imaginam algo assim...

Na verdade, porém, a imagem abaixo seria a mais correta...

Um algoritmo é como uma receita, no sentido de que indicará os passos necessários que precisam ser seguidos para atingir seu objetivo.
Uma receita para fazer pão pode ser:
1- Misture farinha, sal, água e fermento
2- Deixe a massa crescer
3- Leve ao forno por 30 minutos
4- Deixe esfriar e aproveiteComentário à parte: espero que você aprecie o fato de eu estar ensinando como codificar e cozinhar ao mesmo tempo, tudo de graça. Aproveite que não é sempre! 😜
Um algoritmo para identificar se uma palavra é um palíndromo ou não poderia ser:
function isPalindrome(word) {
// Passo 1- Colocar um ponteiro em cada extremo da palavra
// Passo 2 - Percorrer a string "internamente"
// Passo 3 - A cada iteração, verificar se os ponteiros representam valores iguais
// Se esta condição não for cumprida, a palavra não é um palíndromo
let left = 0
let right = word.length-1
while (left < right) {
if (word[left] !== word[right]) return false
left++
right--
}
return true
}
isPalindrome("neuquen") // true
isPalindrome("Buenos Aires") // falseAssim como em uma receita, nesse algoritmo temos etapas com uma determinada finalidade, que são executadas em uma determinada ordem para alcançar o resultado que desejamos.
Seguindo a Wikipédia:
Um algoritmo é uma sequência finita de instruções bem definidas, normalmente usadas para resolver uma classe de problemas específicos ou para realizar uma computação.
Complexidade algorítmica
Agora que sabemos o que é um algoritmo, vamos aprender a comparar diferentes algoritmos entre si.
Digamos que nos é apresentado este problema:
Escreva uma função que receba dois parâmetros: um array não vazio de inteiros distintos e um inteiro representando o resultado desejado. Se quaisquer dois números no array, somados, forem igual ao desejado, a função deve retorná-los em um array. Se não houver dois números que, somados, sejam iguais ao resultado desejado, a função deve retornar um array vazio.
Esta poderia ser uma solução válida para o problema:
function twoNumberSum(array, targetSum) {
let result = []
// Usamos um laço aninhado para testar todas as combinações possíveis de números dentro do array
for (let i = 0; i < array.length; i++) {
for (let j = i+1; j < array.length; j++) {
// Se encontrarmos a combinação certa, colocamos ambos os valores no array result e o retornamos
if (array[i] + array[j] === targetSum) {
result.push(array[i])
result.push(array[j])
return result
}
}
}
// Retorna o array result
return result
}
console.log(twoNumberSum([9,1,3,4,5], 6)) // [1,5]
console.log(twoNumberSum([1,2,3,4,5], 10)) // []Esta é outra solução válida:
function twoNumberSum(array, targetSum) {
// Ordenar o array e fazer a iteração por ele com um ponteiro em cada extremo
// A cada iteração, verificar se a soma dos dois ponteiros é maior ou menor que o alvo
// Se for maior, mover o ponteiro da direita para a esquerda
// Se for menor, mover o ponteiro da esquerda para a direita
let sortedArray = array.sort((a,b) => a-b)
let leftLimit = 0
let rightLimit = sortedArray.length-1
while (leftLimit < rightLimit) {
const currentSum = sortedArray[leftLimit] + sortedArray[rightLimit]
if (currentSum === targetSum) return [sortedArray[leftLimit], sortedArray[rightLimit]]
else currentSum < targetSum ? leftLimit++ : rightLimit--
}
return []
}
console.log(twoNumberSum([9,1,3,4,5], 6)) // [1,5]
console.log(twoNumberSum([1,2,3,4,5], 10)) // []E esta é uma terceira solução válida:
function twoNumberSum(array, targetSum) {
// Iterar sobre o array uma vez e a cada iteração
// Verificar se o número que você precisa para chegar ao destino existe no array
// Se existir, retornar seu índice e o índice de número atual
let result = []
for (let i = 0; i < array.length; i++) {
let desiredNumber = targetSum - array[i]
if (array.indexOf(desiredNumber) !== -1 && array.indexOf(desiredNumber) !== i) {
result.push(array[i])
result.push(array[array.indexOf(desiredNumber)])
break
}
}
return result
}
console.log(twoNumberSum([9,1,3,4,5], 6)) // [1,5]
console.log(twoNumberSum([1,2,3,4,5], 10)) // []Então, como podemos comparar qual solução é a melhor? Todas elas cumprem o objetivo, certo?
Mas além da eficácia (se o objetivo é alcançado ou não), devemos também avaliar os algoritmos em termos de eficiência , ou seja, o que resolve o problema usando a menor quantidade de recursos em termos de tempo (tempo de processamento) e espaço (uso de memória).
Um pensamento automático que surge quando se pensa nisso pela primeira vez é: "É só medir quanto tempo leva para o algoritmo ser executado". E isso é válido.
O problema é que o mesmo algoritmo pode demorar mais ou menos tempo em um computador diferente, devido ao seu hardware e configuração. E mesmo no mesmo computador, pode levar mais ou menos tempo para executar, por conta das tarefas em segundo plano que você está executando naquele determinado momento.
O que precisamos é de uma maneira objetiva e invariável de medir o desempenho de um algoritmo, e é justamente para isso que serve a notação assintótica.
A notação assintótica (também chamada de notação Big O) é um sistema que nos permite analisar e comparar o desempenho de um algoritmo à medida que sua entrada aumenta.
Big O é um método padronizado para analisar e comparar a complexidade (em termos de tempo de execução e espaço) de diferentes algoritmos. A complexidade Big O de um algoritmo será sempre a mesma, não importa em qual computador você a "calcule", porque a complexidade é calculada com base no fato de que o número de operações do algoritmo varia quando a entrada varia. Essa relação continua sempre igual, não importando o ambiente de execução.
Existem muitas complexidades possíveis que um algoritmo pode ter, mas as mais comuns são as seguintes:
- Constante — O(1): Quando o número de operações/espaço necessário permanece igual, independentemente da entrada. Tomemos, por exemplo, uma função que recebe um número como entrada e retorna esse número menos 10. Não importa se você inserir 100 ou 1000000 como entrada, essa função sempre executará uma única operação (a subtração de 10), então a complexidade é constante O(1).
- Logarítmica — O(log n): Quando o número de operações/espaço necessário cresce a uma taxa cada vez mais lenta em comparação ao crescimento da entrada. Esse tipo de complexidade é frequentemente encontrada em algoritmos que adotam uma abordagem de dividir e conquistar ou em algoritmos de busca. O exemplo clássico é a busca binária, em que, dado o conjunto de dados, você continuamente passa/corta pela metade até chegar ao resultado final.
- Linear — O(n): Quando o número de operações/espaço necessário cresce na mesma taxa que a entrada. Por exemplo, um laço que imprime todos os valores encontrados em um array. O número de operações crescerá junto com o comprimento do array, então a complexidade é linear O(n).
- Quadrática — O(n²): Quando o número de operações/espaço necessário cresce à potência de dois em relação à entrada. Laços aninhados são o exemplo clássico dessa complexidade. Imagine que temos um laço que itera através de um array de números, e dentro desse laço temos outro que itera todo o array novamente. Para cada valor no array estamos iterando sobre o array duas vezes, então a complexidade é quadrática O(n²).
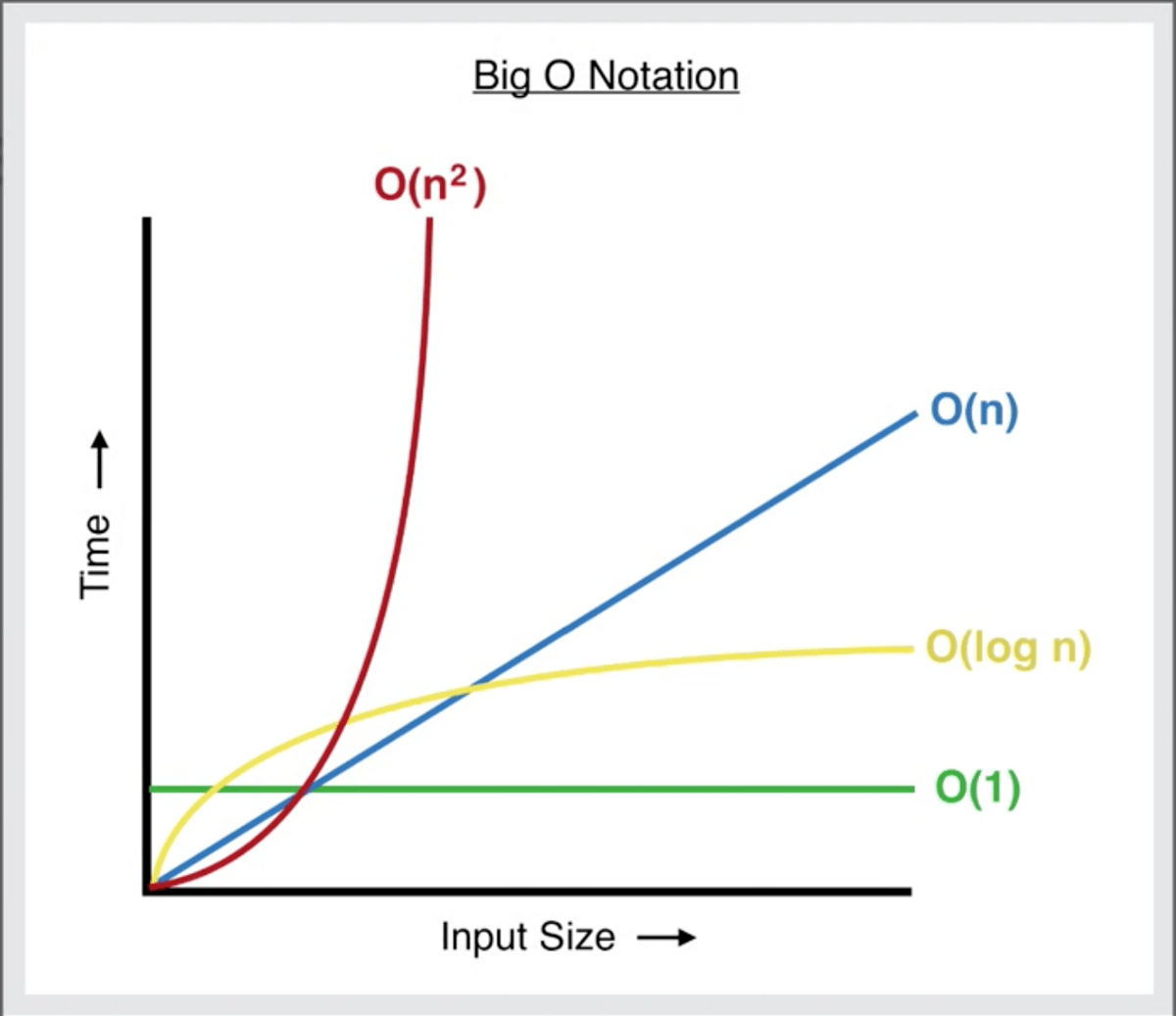
Observe que a mesma notação é usada quando falamos sobre ambas as complexidades, tempo e espaço. Digamos, por exemplo, que temos uma função que sempre cria um array com um único valor, não importando a entrada que ela receba, então a complexidade do espaço será constante O(1), e assim por diante com os outros tipos de complexidade.
Para entender melhor tudo isso, vamos voltar ao nosso problema e analisar as soluções.
Exemplo 1:
function twoNumberSum(array, targetSum) {
let result = []
for (let i = 0; i < array.length; i++) {
for (let j = i+1; j < array.length; j++) {
if (array[i] + array[j] === targetSum) {
result.push(array[i])
result.push(array[j])
return result
}
}
}
return result
}
console.log(twoNumberSum([9,1,3,4,5], 6)) // [1,5]
console.log(twoNumberSum([1,2,3,4,5], 10)) // []Neste exemplo, estamos iterando sobre o array de parâmetros e, para cada valor dentro do array, estamos iterando todo o array novamente procurando por um número que, somado, seja igual ao resultado desejado.
Então, cada iteração conta como uma tarefa.
- Se tivéssemos 3 números no array, iteraríamos 3 vezes para cada número e mais 9 vezes (3 vezes os três números do array). Total: 12 tarefas.
- Se tivéssemos 4 números no array, iteraríamos 4 vezes para cada número e mais 16 vezes (4 vezes os quatro números do array). Total: 20 tarefas.
- Se tivéssemos 5 números no array, iteraríamos 5 vezes para cada número e mais 25 vezes (5 vezes os cinco números do array). Total: 25 tarefas.
Você pode ver como o número de tarefas neste algoritmo cresce exponencialmente e desproporcional à entrada. A complexidade para este algoritmo é quadrática – O(n²).
Sempre que vemos laços aninhados, devemos pensar em complexidade quadrática => O QUE É RUIM => Provavelmente, há uma maneira melhor de resolver isso.
Exemplo 2:
function twoNumberSum(array, targetSum) {
let sortedArray = array.sort((a,b) => a-b)
let leftLimit = 0
let rightLimit = sortedArray.length-1
while (leftLimit < rightLimit) {
const currentSum = sortedArray[leftLimit] + sortedArray[rightLimit]
if (currentSum === targetSum) return [sortedArray[leftLimit], sortedArray[rightLimit]]
else currentSum < targetSum ? leftLimit++ : rightLimit--
}
return []
}
console.log(twoNumberSum([9,1,3,4,5], 6)) // [1,5]
console.log(twoNumberSum([1,2,3,4,5], 10)) // []Aqui, estamos classificando o algoritmo antes de iterarmos nele. E só depois, iteramos apenas uma vez, usando um ponteiro em cada extremo do array e iterando "internamente".
Essa solução é melhor do que a anterior, pois estamos iterando apenas uma vez. Ainda estamos, no entanto, classificando o array (que geralmente tem uma complexidade logarítmica) e depois iterando uma vez (que é a complexidade linear). A complexidade algorítmica desta solução é O(n log(n)).
Exemplo 3:
function twoNumberSum(array, targetSum) {
// Iterar sobre o array uma vez e, a cada iteração
// verificar se o número que você precisa obter para chegar ao resultado esperado existe no array
// Se existir, retornar o índice e o índice do número atual
let result = []
for (let i = 0; i < array.length; i++) {
let desiredNumber = targetSum - array[i]
if (array.indexOf(desiredNumber) !== -1 && array.indexOf(desiredNumber) !== i) {
result.push(array[i])
result.push(array[array.indexOf(desiredNumber)])
break
}
}
return result
}
console.log(twoNumberSum([9,1,3,4,5], 6)) // [1,5]
console.log(twoNumberSum([1,2,3,4,5], 10)) // []Neste último exemplo, estamos iterando o array apenas uma vez, sem fazer mais nada antes. Essa é a melhor solução, pois estamos realizando o menor número de operações. A complexidade neste caso é linear – O(n) .
Este é realmente o conceito mais importante por trás dos algoritmos. Ser capaz de comparar diferentes implementações e entender qual é mais eficiente e por que é realmente um conhecimento importante de se ter. Portanto, se o conceito ainda não estiver claro para você, eu sugiro ler os exemplos novamente, procurar outros recursos ou conferir esta aula incrível do freeCodeCamp (em inglês).
Algoritmos de pesquisa
Uma vez que você tenha um bom entendimento sobre a complexidade algorítmica, a próxima coisa a saber são os algoritmos populares usados para resolver tarefas de programação muito comuns. Então, vamos começar com as pesquisas.
Ao procurar um valor em uma estrutura de dados, existem diferentes abordagens que podemos adotar. Vamos dar uma olhada em duas das opções mais usadas e compará-las.
Pesquisa linear
A pesquisa linear consiste em iterar sobre a estrutura de dados, um valor por vez, e verificar se esse valor é o que estamos procurando. É, provavelmente, o melhor e mais intuitivo tipo de pesquisa que podemos fazer se a estrutura de dados que estamos usando não estiver ordenada.
Suponha que temos um array de números e que, para esse array, queremos escrever uma função que receba um número como entrada e retorne o índice desse número no array. Caso o número não exista no array, retornamos -1. Uma abordagem possível poderia ser a seguinte:
const arr = [1,2,3,4,5,6,7,8,9,10]
const search = num => {
for (let i = 0; i < arr.length; i++) {
if (num === arr[i]) return i
}
return -1
}
console.log(search(6)) // 5
console.log(search(11)) // -1Como o array não está ordenado, não temos como saber a posição aproximada de cada valor, então o melhor que podemos fazer é verificar um valor por vez. A complexidade desse algoritmo é linear - O(n) e, no pior cenário, teremos que iterar sobre todo o array uma vez para obter o resultado da nossa pesquisa.
A pesquisa linear é a abordagem usada por muitos métodos integrados do JavaScript, como indexOf, includes e findIndex.
Pesquisa binária
Quando temos uma estrutura de dados ordenada, há uma abordagem muito mais eficiente que podemos adotar: a pesquisa binária. O que fazemos na pesquisa (ou busca) binária é o seguinte:
- Selecionamos o valor médio da nossa estrutura de dados e "perguntamos": este é o valor que estamos procurando?
- Se não for, "perguntamos" se o valor que procuramos é maior ou menor que o valor médio
- Se for maior, "descartamos" todos os valores menores que o valor médio. Se for menor, "descartamos" todos os valores maiores que o valor médio.
- Por fim, repetimos a mesma operação até encontrarmos o valor pesquisado ou até não ser mais possível dividir o "pedaço" restante da estrutura de dados.
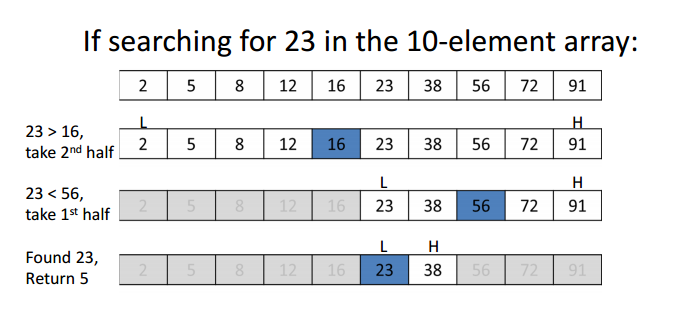
O que é mais legal na busca binária é que, em cada iteração, estamos descartando aproximadamente metade da estrutura de dados. Isso torna a pesquisa realmente rápida e eficiente. 👌
Suponha que temos o mesmo array (ordenado) e queremos escrever a mesma função de antes, que recebe um número como entrada e retorna o índice desse número no array. Caso ele não exista no array, retornamos -1. Podemos escrever essa pesquisa binária da seguinte forma:
const arr = [1,2,3,4,5,6,7,8,9,10]
const search = num => {
// Usaremos três ponteiros.
// Um no início do array, um no final e outro no meio.
let start = 0
let end = arr.length-1
let middle = Math.floor((start+end)/2)
// Enquanto não encontramos o número, e o ponteiro inicial for igual ou menor ao ponteiro final
while (arr[middle] !== num && start <= end) {
// Se o número desejado for menor que o meio, descartamos a metade maior do array
if (num < arr[middle]) end = middle - 1
// Se o número desejado for maior que o meio, descartamos a metade menor do array
else start = middle + 1
// Recalculamos o valor do meio
middle = Math.floor((start+end)/2)
}
// Se saírmos do laço, significa que encontramos o valor ou que o array não pode mais ser dividido
return arr[middle] === num ? middle : -1
}
console.log(search(6)) // 5
console.log(search(11)) // -1Essa abordagem pode parecer "mais código" no início, mas as iterações potenciais são, na verdade, muito menores do que na pesquisa linear. Isso ocorre porque, em cada iteração, estamos descartando aproximadamente metade da estrutura de dados. A complexidade deste algoritmo é logarítmica – O(log n).
Algoritmos de ordenação
Ao ordenar estruturas de dados, existem muitas abordagens que podemos adotar. Vamos olhar algumas das opções mais usadas e compará-las.
Ordenação por bolha
A ordenação por bolha (do inglês Bubble Sort) itera pela estrutura de dados e compara um par de valores por vez. Se a ordem desses valores estiver incorreta, ele troca suas posições para corrigi-la. A iteração é repetida até que os dados estejam ordenados. Esse algoritmo faz com que valores maiores "borbulhem" até o final do array.
Esse algoritmo tem uma complexidade quadrática – O(n²), pois vai comparar cada valor com o resto dos valores uma vez.
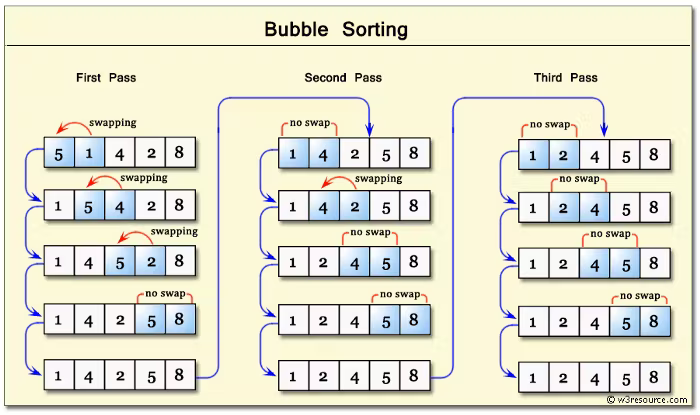
Uma forma de fazer isso é:
const arr = [3,2,1,4,6,5,7,9,8,10]
const bubbleSort = arr => {
// Definir uma variável como flag
let noSwaps
// Fazer um laço aninhado
// com um ponteiro iterando da direita para a esquerda
for (let i = arr.length; i > 0; i--) {
noSwaps = true
// e outro iterando da esquerda para a direita
for (let j = 0; j < i-1; j++) {
// Comparar os dois ponteiros
if (arr[j] > arr[j+1]) {
let temp = arr[j]
arr[j] = arr[j+1]
arr[j+1] = temp
noSwaps = false
}
}
if (noSwaps) break
}
}
bubbleSort(arr)
console.log(arr) // [1,2,3,4,5,6,7,8,9,10]Ordenação por seleção
A ordenação por seleção (do inglês Selection Sort) é semelhante à ordenação por bolha, mas, em vez de colocar os valores maiores no final da estrutura de dados, ela se concentra em colocar os valores menores no início. Os passos que executa são:
- Armazenar o primeiro item da estrutura de dados como o valor mínimo.
- Iterar através da estrutura de dados comparando cada valor com o valor mínimo.
- Se um valor menor for encontrado, identificar esse valor como o novo valor mínimo e troca as posições do novo valor mínimo com o antigo.
- Repetir essa iteração até que a estrutura de dados esteja ordenada.
Este algoritmo tem uma complexidade quadrática – O(n²).
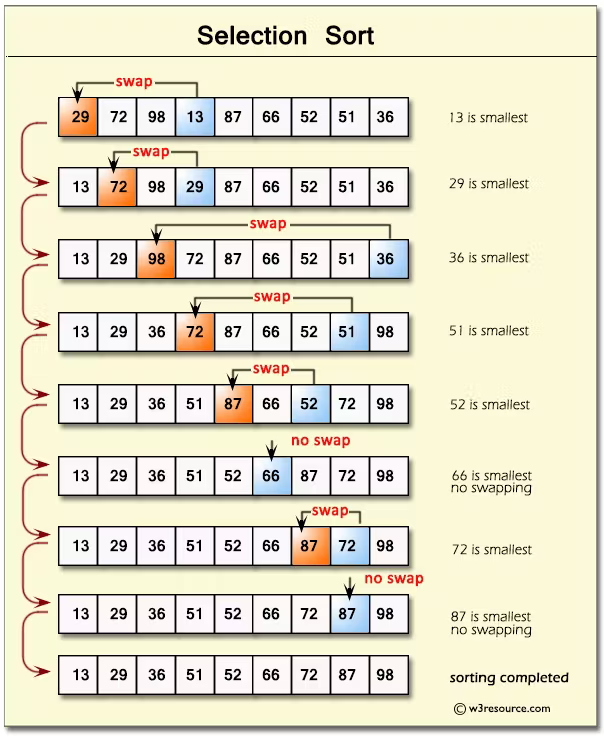
Uma forma de fazer isso é assim:
const arr = [3,2,1,4,6,5,7,9,8,10]
const selectionSort = arr => {
for (let i = 0; i < arr.length; i++) {
let lowest = i
for (let j = i+1; j < arr.length; j++) {
if (arr[j] < arr[lowest]) {
lowest = j
}
}
if (i !== lowest) {
let temp = arr[i]
arr[i] = arr[lowest]
arr[lowest] = temp
}
}
}
selectionSort(arr)
console.log(arr) // [1,2,3,4,5,6,7,8,9,10]Ordenação por inserção
A ordenação por inserção (do inglês Insertion Sort) ordena a estrutura de dados criando uma "metade ordenada", que é sempre ordenada corretamente e itera pela estrutura de dados selecionando cada valor e inserindo-o na metade ordenada, no local exato em que deveria estar.
As etapas que ela faz são:
- Começar escolhendo o segundo elemento na estrutura de dados.
- Comparar este elemento com o anterior e trocar suas posições, se necessário.
- Continuar com o próximo elemento e, se não estiver na posição correta, percorrer a "metade ordenada" para encontrar sua posição correta e inserir ali.
- Repetir o mesmo processo até que toda a estrutura de dados esteja ordenada.
A complexidade desse algoritmo é quadrática (O(n²)).
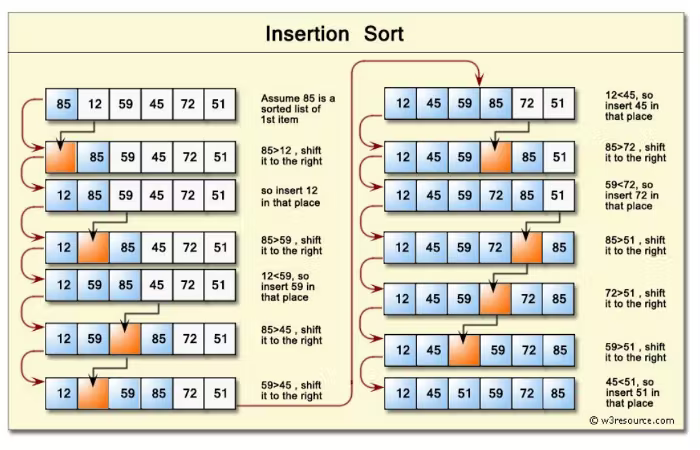
Uma possível aplicação dela é assim:
const arr = [3,2,1,4,6,5,7,9,8,10]
const insertionSort = arr => {
let currentVal
for (let i = 0; i < arr.length; i++) {
currentVal = arr[i]
for (var j = i-1; j >= 0 && arr[j] > currentVal; j--) {
arr[j+1] = arr[j]
}
arr[j+1] = currentVal
}
return arr
}
insertionSort(arr)
console.log(arr) // [1,2,3,4,5,6,7,8,9,10]O problema com as ordenações por bolha, seleção e inserção é que esses algoritmos não são bem dimensionados (todos de complexidade quadrática).
Há opções muito melhores que podemos escolher quando trabalhamos com grandes conjuntos de dados. Algumas delas são a ordenação por mistura, a rápida e a Radix. Então, vamos dar uma olhada nelas agora!
Ordenação por mistura
A ordenação por mistura (do inglês Merge Sort) é um algoritmo que decompõe recursivamente a estrutura de dados em valores individuais e depois a compõe novamente de forma ordenada.
As etapas dele são:
- Quebrar recursivamente a estrutura de dados em metades até que cada "peça" tenha apenas um valor.
- Em seguida, mesclar recursivamente as partes de forma ordenada até voltar ao tamanho da estrutura de dados original.
Este algoritmo tem complexidade O(n log n), uma vez que a decomposição tem uma complexidade de log n e a comparação tem uma complexidade de n.
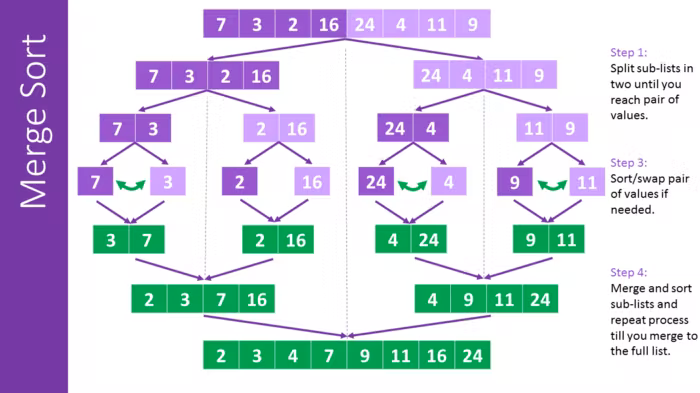
Podemos escrevê-lo deste modo:
const arr = [3,2,1,4,6,5,7,9,8,10]
// Função do merge (mistura)
const merge = (arr1, arr2) => {
const results = []
let i = 0
let j = 0
while (i < arr1.length && j < arr2.length) {
if (arr2[j] > arr1[i]) {
results.push(arr1[i])
i++
} else {
results.push(arr2[j])
j++
}
}
while (i < arr1.length) {
results.push(arr1[i])
i++
}
while (j < arr2.length) {
results.push(arr2[j])
j++
}
return results
}
const mergeSort = arr => {
if (arr.length <= 1) return arr
let mid = Math.floor(arr.length/2)
let left = mergeSort(arr.slice(0,mid))
let right = mergeSort(arr.slice(mid))
return merge(left, right)
}
console.log(mergeSort(arr)) // [1,2,3,4,5,6,7,8,9,10]Ordenação rápida
A ordenação rápida (do inglês Quick Sort) funciona selecionando um elemento de "pivô" (ou eixo) e encontrando o índice onde ele deve terminar no array classificado.
O tempo de execução dessa classificação depende em parte de como o pivô é selecionado. Idealmente, deve ser aproximadamente o valor mediano do conjunto de dados que está sendo classificado.
Os passos desse algoritmo são:
- Identificar o valor do pivô e colocá-lo no índice que deveria ser.
- Executar recursivamente o mesmo processo em cada “metade” da estrutura de dados.
Este algoritmo tem uma complexidade O(n log n).
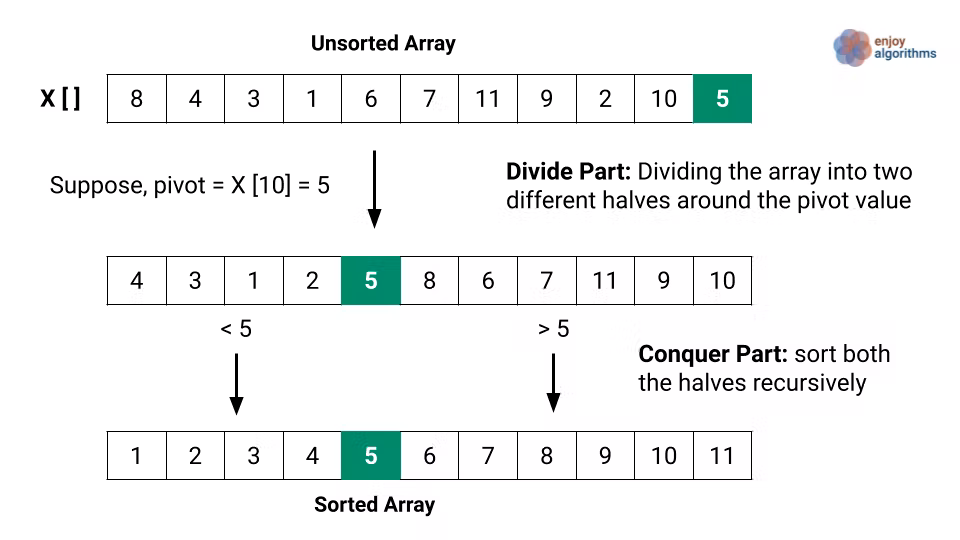
Uma forma de fazer isso é:
const arr = [3,2,1,4,6,5,7,9,8,10]
const pivot = (arr, start = 0, end = arr.length - 1) => {
const swap = (arr, idx1, idx2) => [arr[idx1], arr[idx2]] = [arr[idx2], arr[idx1]]
let pivot = arr[start]
let swapIdx = start
for (let i = start+1; i <= end; i++) {
if (pivot > arr[i]) {
swapIdx++
swap(arr, swapIdx, i)
}
}
swap(arr, start, swapIdx)
return swapIdx
}
const quickSort = (arr, left = 0, right = arr.length - 1) => {
if (left < right) {
let pivotIndex = pivot(arr, left, right)
quickSort(arr, left, pivotIndex-1)
quickSort(arr, pivotIndex+1, right)
}
return arr
}
console.log(quickSort(arr)) // [1,2,3,4,5,6,7,8,9,10]Ordenação Radix
Radix é um algoritmo que funciona de modo diferente dos vistos anteriormente, no sentido de não comparar valores. Ele é usado para ordenar listas de números e, para isso, explora o fato de que o tamanho de um número é definido pelo número de algarismos que ele possui (quanto mais algarismos, maior o número).
O que o Radix faz é ordenar os valores por seus algarismos, em ordem. Ele ordena todos os valores pelo primeiro algarismo, depois novamente pelo segundo, depois pelo terceiro… Este processo é repetido tantas vezes quanto o número de algarismos do maior número da lista. E ao final desse processo, o algoritmo retorna a lista totalmente ordenada.
Os passos que ele faz são:
- Calcular quantos algarismos o maior número tem.
- Percorrer a lista até o maior número de algarismos. Em cada iteração:
- Criar "buckets" para cada algarismo (de 0 a 9) e coloca cada valor em seu bucket correspondente de acordo com o algarismo que está sendo avaliado.
- Substituir a lista existente pelos valores classificados nos buckets, começando em 0 e indo até 9.
Este algoritmo tem uma complexidade O(n*k), sendo k o número de algarismos que o maior número possui. Dado que não compara valores entre si, esse algoritmo tem um tempo de execução melhor do que os vistos anteriormente, mas somente funcionará em listas numéricas.
Se quisermos um algoritmo de ordenação agnóstica de dados, provavelmente usaríamos qualquer um dos anteriores.
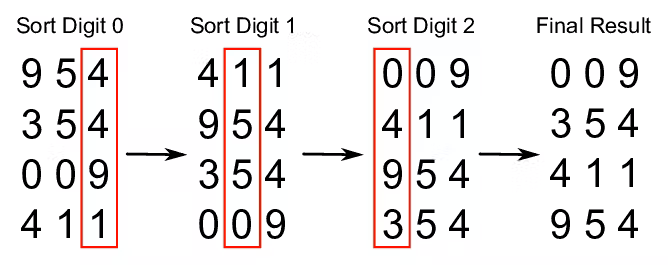
Uma possível implementação poderia ser a seguinte:
const arr = [3,2,1,4,6,5,7,9,8,10]
const getDigit = (num, i) => Math.floor(Math.abs(num) / Math.pow(10, i)) % 10
const digitCount = num => {
if (num === 0) return 1
return Math.floor(Math.log10(Math.abs(num))) + 1
}
const mostDigits = nums => {
let maxDigits = 0
for (let i = 0; i < nums.length; i++) maxDigits = Math.max(maxDigits, digitCount(nums[i]))
return maxDigits
}
const radixSort = nums => {
let maxDigitCount = mostDigits(nums)
for (let k = 0; k < maxDigitCount; k++) {
let digitBuckets = Array.from({ length: 10 }, () => [])
for (let i = 0; i < nums.length; i++) {
let digit = getDigit(nums[i], k)
digitBuckets[digit].push(nums[i])
}
nums = [].concat(...digitBuckets)
}
return nums
}
console.log(radixSort(arr)) // [1,2,3,4,5,6,7,8,9,10]Algoritmos de travessia
O último tipo de algoritmo que veremos são os algoritmos de travessia, usados para iterar através de estruturas de dados de formas diferentes (mas, principalmente, árvores e grafos).
Ao iterar uma estrutura de dados como a de árvore, podemos priorizar as iterações de duas formas: profundidade ou largura.
Se priorizarmos a profundidade, vamos "descer" por cada galho da árvore, indo do tronco até a folha de cada galho.
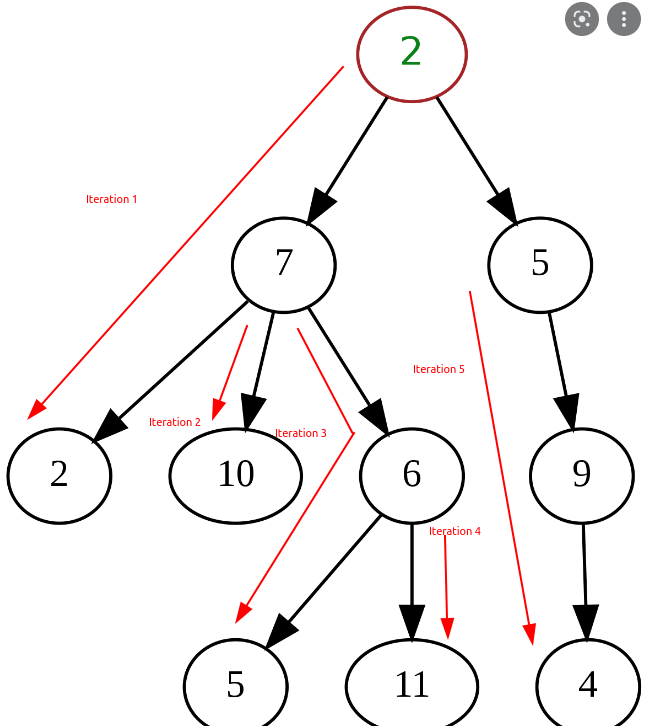
Se priorizarmos a largura, passaremos por cada "nível" da árvore horizontalmente, iterando por todos os nós que estão no mesmo nível antes de "descer" para o próximo nível.
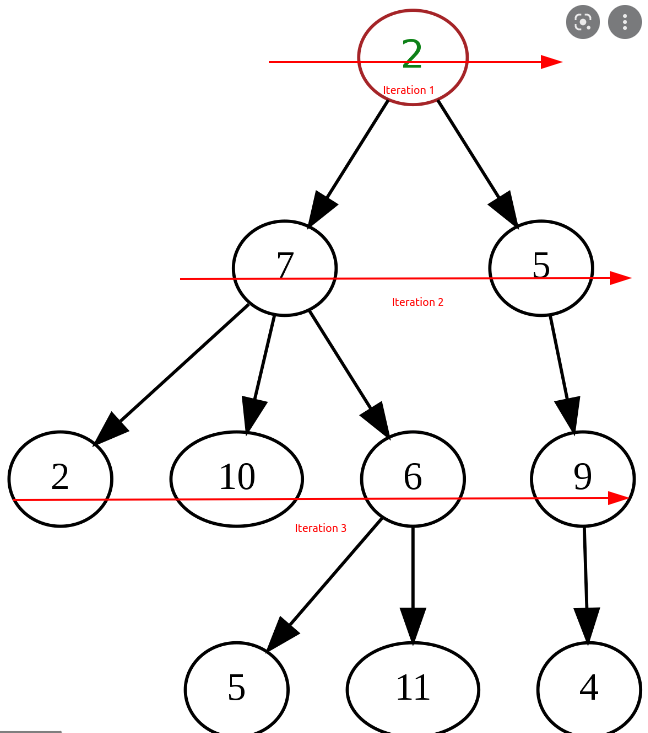
A decisão de qual algoritmo escolher dependerá em grande parte do valor que procuramos em nossa iteração e de como nossa estrutura de dados está construída.
Pesquisa por largura (BFS)
Vamos analisar a BFS primeiro. Como mencionei antes, esse tipo de travessia percorrerá nossa estrutura de dados de modo horizontal. Seguindo esta imagem de exemplo abaixo, os valores seriam percorridos na seguinte ordem: [10, 6, 15, 3, 8, 20].
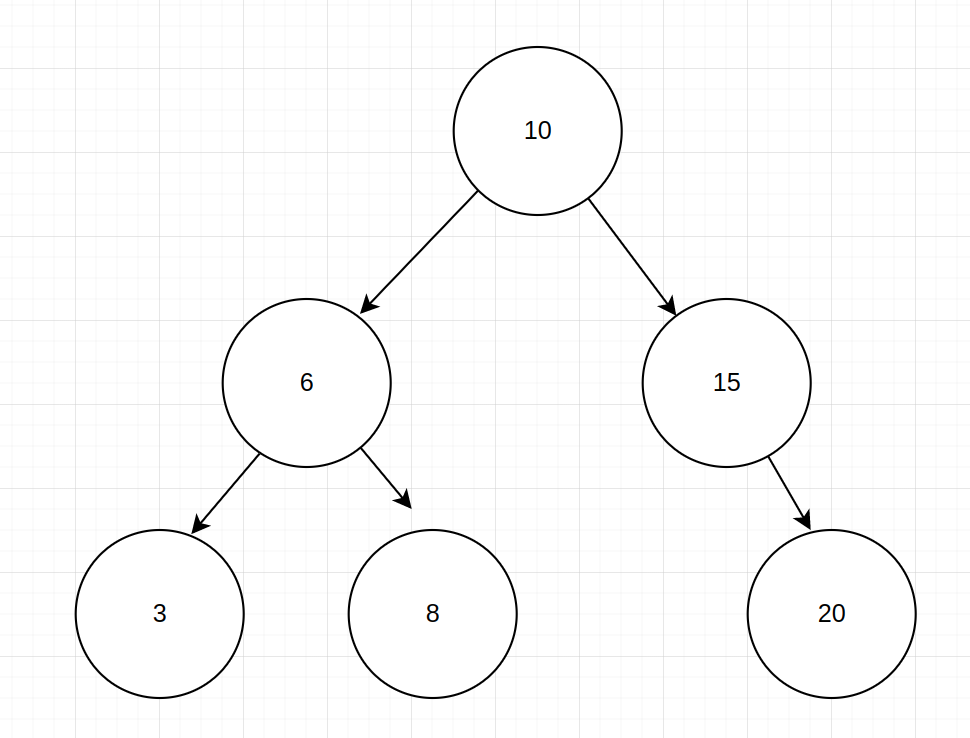
Normalmente, as etapas seguidas pelos algoritmos BFS são as seguintes:
- Criar uma fila e uma variável para armazenar os nós que foram "visitados"
- Colocar o nó principal dentro da fila
- Continuar fazendo o laço enquanto houver algo na fila
- Retirar um nó da fila e colocar o valor do nó na variável que armazena os nós visitados
- Se houver a propriedade left no nó que foi removido da fila, adicioná-la à fila
- Se houver uma propriedade right no nó que foi removido da fila, adicioná-la à fila
Uma forma de fazer isso é a seguinte:
class Node {
constructor(value) {
this.value = value
this.left = null
this.right = null
}
}
class BinarySearchTree {
constructor(){ this.root = null; }
insert(value){
let newNode = new Node(value);
if(this.root === null){
this.root = newNode;
return this;
}
let current = this.root;
while(true){
if(value === current.value) return undefined;
if(value < current.value){
if(current.left === null){
current.left = newNode;
return this;
}
current = current.left;
} else {
if(current.right === null){
current.right = newNode;
return this;
}
current = current.right;
}
}
}
BFS(){
let node = this.root,
data = [],
queue = [];
queue.push(node);
while(queue.length){
node = queue.shift();
data.push(node.value);
if(node.left) queue.push(node.left);
if(node.right) queue.push(node.right);
}
return data;
}
}
const tree = new BinarySearchTree()
tree.insert(10)
tree.insert(6)
tree.insert(15)
tree.insert(3)
tree.insert(8)
tree.insert(20)
console.log(tree.BFS()) // [ 10, 6, 15, 3, 8, 20 ]Pesquisa por profundidade (DFS)
A DFS por sua vez, fará a iteração através da nossa estrutura de dados de modo vertical. Seguindo o mesmo exemplo que usamos para a BFS, os valores seriam percorridos nessa ordem: [10, 6, 3, 8, 15, 20].
Essa maneira de fazer a DFS é chamada de "pré-ordem". Existem, na verdade, três maneiras principais pelas quais a DFS pode ser feita, a diferença entre elas é apenas a alteração da ordem em que os nós são visitados.
- Pré-ordem: visite o nó atual, depois o nó menor e depois o nó maior.
- Pós-ordem: explore todos os filhos menores e todos os filhos maiores antes de visitar o nó.
- Na ordem: Explore todos os filhos menores, visita o nó atual e explore todos os filhos maiores.
Se isso parece confuso, não se preocupe. Não é tão complexo e ficará mais claro depois com os exemplos.
Pré-ordem por DFS
No algoritmo de pré-ordem por profundidade, seguimos as etapas de:
- Criar uma variável para armazenar os valores dos nós visitados
- Armazenar a raiz da árvore em uma variável
- Escrever uma função auxiliar que aceite um nó como parâmetro
- Adicionar o valor do nó para a variável que armazena os valores
- Se o nó tiver uma propriedade left (que é um filho com valor menor que o atual), chamar a função auxiliar com o nó left como parâmetro
- Se o nó tiver uma propriedade right (que é um filho com valor maior que o atual), chamar a função auxiliar com o nó right como parâmetro
Uma maneira de fazer isso é:
class Node {
constructor(value){
this.value = value;
this.left = null;
this.right = null;
}
}
class BinarySearchTree {
constructor(){
this.root = null;
}
insert(value){
var newNode = new Node(value);
if(this.root === null){
this.root = newNode;
return this;
}
var current = this.root;
while(true){
if(value === current.value) return undefined;
if(value < current.value){
if(current.left === null){
current.left = newNode;
return this;
}
current = current.left;
} else {
if(current.right === null){
current.right = newNode;
return this;
}
current = current.right;
}
}
}
DFSPreOrder(){
var data = [];
function traverse(node){
data.push(node.value);
if(node.left) traverse(node.left);
if(node.right) traverse(node.right);
}
traverse(this.root);
return data;
}
}
var tree = new BinarySearchTree()
tree.insert(10)
tree.insert(6)
tree.insert(15)
tree.insert(3)
tree.insert(8)
tree.insert(20)
console.log(tree.DFSPreOrder()) // [ 10, 6, 3, 8, 15, 20 ]Pós-ordem por DFS
No algoritmo de pós-ordem por profundidade, fazemos o seguinte:
- Criar uma variável para armazenar os valores dos nós visitados
- Armazenar a raiz da árvore em uma variável
- Escrever uma função auxiliar que aceite um nó como parâmetro
- Se o nó tiver uma propriedade left, chamar a função auxiliar com o nó left como parâmetro
- Se o nó tiver uma propriedade right, chamar a função auxiliar com o nó right como parâmetro
- Adicionar o valor do nó para a variável que armazena os valores
- Chamar a função auxiliar com o nó atual como parâmetro
Uma forma possível de fazer isso é a seguinte:
class Node {
constructor(value){
this.value = value;
this.left = null;
this.right = null;
}
}
class BinarySearchTree {
constructor(){
this.root = null;
}
insert(value){
var newNode = new Node(value);
if(this.root === null){
this.root = newNode;
return this;
}
var current = this.root;
while(true){
if(value === current.value) return undefined;
if(value < current.value){
if(current.left === null){
current.left = newNode;
return this;
}
current = current.left;
} else {
if(current.right === null){
current.right = newNode;
return this;
}
current = current.right;
}
}
}
DFSPostOrder(){
var data = [];
function traverse(node){
if(node.left) traverse(node.left);
if(node.right) traverse(node.right);
data.push(node.value);
}
traverse(this.root);
return data;
}
}
var tree = new BinarySearchTree()
tree.insert(10)
tree.insert(6)
tree.insert(15)
tree.insert(3)
tree.insert(8)
tree.insert(20)
console.log(tree.DFSPostOrder()) // [ 3, 8, 6, 20, 15, 10 ]Em ordem por DFS
No algoritmo em ordem por profundidade, fazemos o seguinte:
- Criamos uma variável para armazenar os valores dos nós visitados
- Armazenamos a raiz da árvore em uma variável
- Escrevemos uma função auxiliar que aceite um nó como parâmetro
- Se o nó tiver uma propriedade left, chamamos a função auxiliar com o nó left como parâmetro
- Adicionar o valor do nó para a variável que armazena os valores
- Se o nó tiver uma propriedade right, chamamos a função auxiliar com o nó right como parâmetro
- Chamamos a função auxiliar com o nó atual como parâmetro
Uma forma possível de fazer isso é assim:
class Node {
constructor(value){
this.value = value;
this.left = null;
this.right = null;
}
}
class BinarySearchTree {
constructor(){
this.root = null;
}
insert(value){
var newNode = new Node(value);
if(this.root === null){
this.root = newNode;
return this;
}
var current = this.root;
while(true){
if(value === current.value) return undefined;
if(value < current.value){
if(current.left === null){
current.left = newNode;
return this;
}
current = current.left;
} else {
if(current.right === null){
current.right = newNode;
return this;
}
current = current.right;
}
}
}
DFSInOrder(){
var data = [];
function traverse(node){
if(node.left) traverse(node.left);
data.push(node.value);
if(node.right) traverse(node.right);
}
traverse(this.root);
return data;
}
}
var tree = new BinarySearchTree()
tree.insert(10)
tree.insert(6)
tree.insert(15)
tree.insert(3)
tree.insert(8)
tree.insert(20)
console.log(tree.DFSInOrder()) // [ 3, 6, 8, 10, 15, 20 ]Como você deve ter notado, as implementações de pré-ordem, pós-ordem e em ordem são quase iguais, pois o que é alterado é apenas a ordem de como os nós são visitados. Porém o resultado de travessia que chegamos em cada um são bem diferentes e, às vezes, uma forma pode ser até mais útil do que as outras.
Em relação a quando usar BFS ou DFS, como eu disse, depende de como nossa estrutura de dados está organizada.
De um modo geral, se tivermos uma árvore ou grafo muito amplo (o que significa que existem muitos nós irmãos no mesmo nível), devemos priorizar a DFS. Se, no entanto, estivermos lidando com uma árvore ou grafo muito grande com ramificações muito longas, devemos priorizar a BFS.
Na questão do tempo, a complexidade dos dois os algoritmos é a mesma, pois estamos sempre visitando cada nó apenas uma vez. A complexidade de espaço, por outro lado, pode ser muito diferente, dependendo de quantos nós precisam ser armazenados na memória para cada implementação. Portanto, quanto menos nós tivermos que acompanhar, melhor!😊
Conclusão
Como sempre, espero que você tenha gostado do artigo e que tenha aprendido algo novo. Se quiser, você também pode seguir o autor no LinkedIn ou no Twitter.
Até logo!
