
![Gitting Things Done – Una guía visual y práctica para Git [Libro completo]](https://www.freecodecamp.org/espanol/news/content/images/size/w2000/2024/01/Gitting-Things-Done-Cover-with-Photo.png)
Artículo original: Gitting Things Done – A Visual and Practical Guide to Git [Full Book]
Introducción
Git es increíble.
La mayoría de los desarrolladores de software usan Git en el día a día. Pero, ¿cuántos realmente entienden Git? ¿Sientes que sabes lo que está pasando por detrás a medida que usas Git para ejecutar varias tareas?
Por ejemplo, ¿qué sucede cuando usas git commit? ¿Qué se almacena entre las confirmaciones? ¿Es sólo un diff entre la confirmación actual y el anterior? Si es así, ¿cómo se codifica el diff? O, ¿es una copia instantánea entero cada vez que el repositorio se almacena?
La mayoría de las personas que usan Git no saben las respuestas a estas preguntas de arriba. Pero, ¿esto importa realmente? ¿Realmente tienes que saber todas esas cosas?
Yo argumentaría que sí importa. Como profesionales, deberíamos esforzarnos en entender las herramientas que usamos, especialmente si los usamos todo el tiempo, como Git.
Aún más preciso. He encontrado que entender realmente cómo funciona Git es beneficioso en muchos escenarios – si estás resolviendo conflictos de fusión, viendo cómo conducir un rebase interesante, o inclusive cuando algo va mal ligeramente.
Muchísimas veces he recibido preguntas sobre Git de gente con experiencia, ingenieros de software altamente talentosos. He visto desarrolladores maravillosos reaccionar con miedo cuando algo sucede en su historial de confirmaciones, y simplemente no saben qué hacer. Esto no tiene que ser así.
Al leer este libro, obtendrás una nueva perspectiva de Git. Te sentirás con confianza cuando trabajes con Git, y entenderás los mecanismos subyacentes de Git, al menos aquellos que son beneficiosos de entender. Le vas a captar.
Tabla de Contenidos
- Introducción
- Parte 1 - Objetos principales e Introduciendo cambios
- Capítulo 1 - Objetos de Git
- Capítulo 2 - Ramas en Git
- Capítulo 3 - Cómo registrar cambios en Git
- Capítulo 4 - ¿Cómo crear un repo desde cero?
- Capítulo 5 - Cómo trabajar con las ramas en Git – Por debajo
- Parte 2 - Ramificando e Integrando Cambios
- Capítulo 6 - Diffs y Parches
- Capítulo 7 - Entendiendo la Fusión de Git
- Capítulo 8 - Entendiendo Git Rebase
- Parte 3 - Deshacer cambios
- Capítulo 9 - Git Reset
- Capítulo 10 - Herramientas adicionales para deshacer cambios
- Capítulo 11 - Ejercicios
- Parte 4 - Herramientas de Git Fantásticas y Útiles
- Capítulo 12 - Git Log
- Capítulo 13 - Git Bisect
- Capítulo 14 - Otros comandos útiles
- Resumen
- Apéndices
¿Para quién es este Libro?
Para cualquier desarrollador de software que quiera profundizar su conocimiento sobre Git.
Si ya tienes experiencia con Git – Estoy seguro que serás capaz de profundizar tus conocimientos. Inclusive si eres nuevo en Git - empezaré con una vista general del mecanismo de Git, y los términos usados a lo largo de este libro.
Este libro es para ti. Lo escribí así para que puedas aprender más sobre Git, y también llegues a apreciar, o inclusive amar a Git.
También notarás que uso un estilo casual en todo el libro. Creo que aprender Git debe de ser intuitivo y divertido. Aprender cosas nuevas siempre es difícil, y pensé que escribir en un estilo menos casual realmente no haría un buen servicio. Y como ya mencioné - Este libro es para ti.
¿Quién soy yo?
Este libro es sobre ti, y tu jornada con Git. Pero me gustaría decirte un poco sobre por qué pienso que puedo contribuir a tu jornada.
Soy el CTO y uno de los co-fundadores de Swimm.io, una herramienta de gestión de conocimiento para código. Parte de lo que hacemos es enlazar partes del código en repositorios de Git a partes de la documentación, y luego rastrear cambios en el repositorio para actualizar la documentación si es necesario.
En Swimm, tengo que diseccionar partes de Git, entender sus mecanismos subyacentes y también ganar intuición sobre por qué se implementa Git de la manera que se hace.
Antes de fundar Swimm practiqué enseñando en muchos entornos diferentes - entre ellos, gestionar el cyber track del Desafío Tech de Israel, fundar la Academia de Seguridad de Punto de Verificación (en inglés Check Point Security Academy), y escribir un libro completo de texto.
Este libro es mi intento de aprovechar lo máximo de ambos mundos - mi experiencia de enseñanza así como mi experiencia práctica profunda con Git, y darte la mejor experiencia de aprendizaje que puedo.
El enfoque de este libro
Este no es definitivamente el primer libro sobre Git. Cuando me senté a escribirlo, tuve tres principios en mente.
- Práctico - en este libro, aprenderás cómo lograr las cosas en Git. Cómo introducir cambios, cómo deshacerlos, y cómo arreglar las cosas cuando salen mal. Entenderás cómo funciona Git no sólo por el hecho de entender, sino con una mentalidad práctica. A veces me refiero a esto como el "principio práctico" - el cual me guía en decidir si incluyo ciertos tópicos, y en qué medida.
- A profundidad - te sumergirás en la forma de operar de Git, entender sus mecanismos. Construirás tu entendimiento gradualmente, y siempre enlazarás tus conocimientos a escenarios reales que podrías encontrar en tu trabajo. Para alcanzar un entendimiento a profundidad, casi siempre prefiero la línea de comandos en vez de interfaces gráficas, así realmente puedes ver qué comandos estoy ejecutando.
- Visual - a medida que me esfuerzo en proveerte con intuición, los capítulos estarán acompañados de ayudas visuales.
¿Por qué este libro está disponible públicamente?
Pienso que todos deberían tener acceso a contenido de alta calidad sobre Git, y me gustaría que este libro llegue a tantas personas como sea posible.
Si te gustaría apoyar este libro, eres bienvenido en comprar la versión física, un libro electrónico, o comprarme un café. ¡Gracias!
Videos Acompañantes
He cubierto muchos tópicos de este libro en mi canal de Youtube - @BriefVid. Eres bienvenido en verificarlos también.
A trabajar
A lo largo de este libro, mayormente usaré el singular en segunda persona - y directamente te escribiré a ti. También te pediré que trabajes, que ejecutes los comandos tú mismo, así llegas a sentir lo que es usar las cosas con Git, no sólo leerlo.
Los sentimientos de Git
A lo largo de este libro, a veces me refiero a Git con palabras tales como "cree", "piensa", o "quiere". Como puedes argumentar, Git no es humano, y no tiene sentimientos o creencias. Bueno, eso es verdad, pero para que nosotros disfrutemos al jugar con Git, y ayudarte en que disfrutes leer (y yo escribiendo), siento que referirme a Git más que sólo código lo hace muchos más divertido.
Mi configuración
Incluiré capturas de pantalla. No hay necesidad de que configures para coincidir con lo mío, pero si sientes curiosidad sobre mi configuración, entonces:
- Estoy usando Ubuntu 20.04 (WSL).
- Para mi terminal, use Oh My Zsh
- También uso plugins para Oh My Zsh, puedes seguir este tutorial en freeCodeCamp
- El alias
git lol - git-graph (mi alias es
gg)
Los comentarios son bienvenidos
Este libro ha sido creado para ayudarte y las personas como tú aprendan, entiendan Git, y apliquen ese conocimiento en la vida real.
Desde el principio, pedí comentarios y fui afortunado en recibirlo de grandes personas (ve reconocimientos) para asegurarte que el libro alcanza estos objetivos. Si te gustó algo sobre este libro, sentiste que algo le faltó, o que algo necesita mejorar - Me encantaría escucharlo de ti. Por favor encuéntrame en: gitting.things@gmail.com.
Nota
Este libro es provisto gratuitamente en freeCodeCamp como se describe arriba y de acuerdo a la licencia Creative Commons Attribution-NonCommercial-ShareAlike 4.0 International.
Si te gustaría apoyar este libro, eres bienvenido en comprar la versión física, una versión electrónica, o comprarme un café. ¡Gracias!
Parte 1 - Objetos Principales e Introduciendo cambios
Capítulo 1 - Objetos de Git
Es tiempo de empezar tu jornada en las profundidades de Git. En este capítulo - empezamos con lo básico - aprenderás sobre los objetos de Git más importantes, y adoptar una forma de pensar sobre Git. ¡Vamos a ello!
Git como un Sistema para mantener un Sistema de archivos
Siendo que hay diferentes formas de usar Git, adoptaré aquí una forma que he aprendido que es la más clara y útil: viendo a Git como un sistema que mantiene un sistema de archivos, y específicamente - copias instantáneas de ese sistema de archivos con el tiempo.
Un sistema de archivos con un directorio raíz (en sistemas basados en UNIX, /), el cual usualmente contiene otros directorios (por ejemplo, /usr o /bin). Estos directorios contienen otros directorios, y/o archivos (por ejemplo, /usr/1.txt). En una máquina Windows, un directorio raíz de un disco sería C:\, y un sub-directorio podría ser C:\users. Adoptaré la convención de los sistemas basados en UNIX a lo largo de este libro.
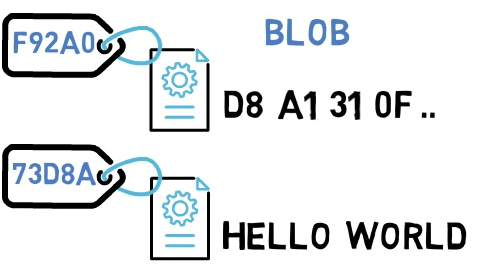
Blobs
En Git, los contenidos de los archivos son almacenados en objetos llamados blobs, abreviado para binary large objects (objetos grandes de binario).
La diferencia entre blobs y archivos es que los archivos también contienen meta-datos. Por ejemplo, un archivo "recuerda" cuando fue creado, de esa forma si tu mueves ese archivo de un directorio a otro, su tiempo de creación permanece el mismo.
Los blobs, en contraste, son sólo corrientes de binario de datos, como el contenido de un archivo. Un blob no registra su fecha de creación, su nombre, o cualquier otra cosa más que su contenido.
Cada blob en Git es identificado por su hash SHA-1. Los hashes SHA-1 consisten de 20 bytes, usualmente representados por 40 caracteres en forma hexadecimal. A lo largo de este libro a veces mostraré sólo los primeros caracteres de ese hash. Como los hashes, y específicamente los hashes SHA-1 son ubicuos en Git, es importante que entiendas las características básicas de los hashes.
Hashes
Un hash es una función determinista y matemática unidireccional.
Determinista significa que la misma entrada proveerá la misma salida. Eso es - tomas una corriente de datos, ejecutas una función hash en esa corriente, y obtienes un resultado.
Por ejemplo, si provees la función hash SHA-1 con la corriente hello, obtendrás 0xaaf4c61ddcc5e8a2dabede0f3b482cd9aea9434d. Si ejecutas la función hash SHA-1 nuevamente, desde una máquina diferente, y le provees los mismos datos (hello), obtendrás el mismo valor.
Git usa SHA-1 como su función hash para identificar objetos. Se basa en ella siendo determinista, y de esa forma un objeto siempre tendrá el mismo identificador.
Una función unidireccional es una función que es difícil de invertir dado una entrada. Eso es, es imposible (o al menos, muy difícil) de determinar, dado el resultado de la función hash (por ejemplo 0xaaf4c61ddcc5e8a2dabede0f3b482cd9aea9434d), qué entrada produce ese resultado (en este ejemplo hello).
De vuelta a Git
De vuelta a Git - Blobs, como cualquier otro objeto de Git, tienen hashes SHA-1 asociados a ellos.
Como dije al principio, Git puede ser visto como un sistema para mantener un sistema de archivos. Sistemas de archivos consisten en archivos y directorios. Un blob es el objeto de Git representando los contenidos de un archivo.
Árboles
En Git, el equivalente de un directorio es un árbol. Un árbol es básicamente un listado de directorios, refiriéndose a blobs, así también como otros árboles.
Los árboles son identificados por sus hashes SHA-1 también. Referirse a estos objetos, sean blobs u otros árboles, sucede por medio del hash SHA-1 de los objetos.
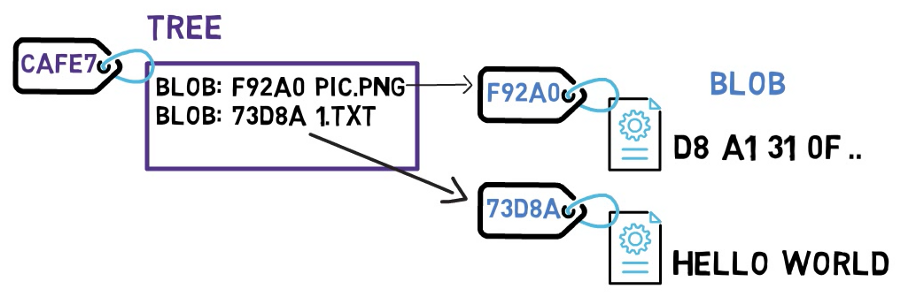
Considera el dibujo de arriba. Fíjate que el árbol CAFE7 se refiere al blob F92A0 como el archivo pic.png. En otro árbol, el mismo blob podría tener otro nombre - pero siempre y cuando los contenidos sean lo mismo, será el mismo objeto blob, y todavía tendrá el mismo valor SHA-1.
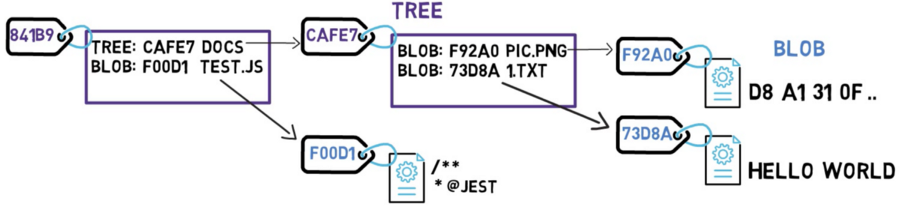
El diagrama de arriba es equivalente a un sistema de archivos con un directorio raíz que tiene un archivo en /test.js, y un directorio llamado /docs consistiendo de dos archivos: /docs/pic.png, y /docs/1.txt.
Confirmaciones
Ahora es tiempo de tomar una copia instantánea de ese sistema de archivos – y almacenar todos los archivos que existieron en ese tiempo, juntamente con sus contenidos.
En Git, una copia instantánea es una confirmación. Un objeto de confirmación incluye un puntero al árbol principal (el directorio raíz del sistema de archivos), así también como otros meta-datos tales como el confirmador (el usuario que autorizó la confirmación), un mensaje de la confirmación, y el tiempo de la confirmación.
En la mayoría de los casos, una confirmación también tiene uno o más confirmaciones padres – la copia instantánea anterior (o copias instantáneas). Por supuesto, los objetos de confirmación son también identificados por sus hashes SHA-1. Estos son los hashes que probablemente estás acostumbrado de ver cuando usas los comandos tales como git log.

Cada confirmación retiene la copia instantánea completa, no solo las diferencias entre sí mismo y su confirmación o confirmaciones padres.
¿Cómo puede funcionar eso? ¿No significa que Git tiene que almacenar un montón de datos para cada confirmación?
Examina lo que pasa si cambias los contenidos de un archivo. Digamos que editas el archivo 1.txt, y agregas un signo de exclamación – eso es, cambiaste el contenido de HELLO WORLD, a HELLO WORLD!.
Bueno, este cambio significa que Git crea un nuevo objeto blob, con un nuevo hash SHA-1. Esto tiene sentido, ya que sha1("HELLO WORLD") es diferente de sha1("HELLO WORLD!").
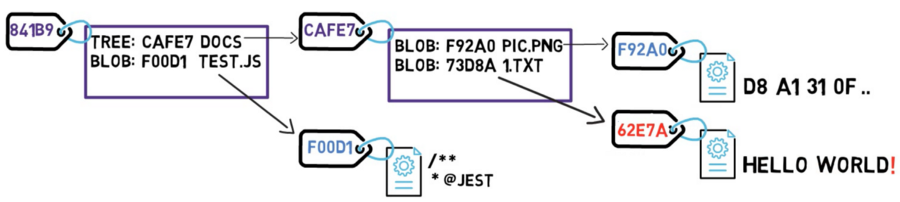
Ya que tienes un nuevo hash, entonces el listado del árbol debería también cambiar. Después de todo, tu árbol ya no apunta al blob 73D8A, sino al blob 62E7A. Desde el momento que cambies los contenidos del árbol, también cambias su hash.
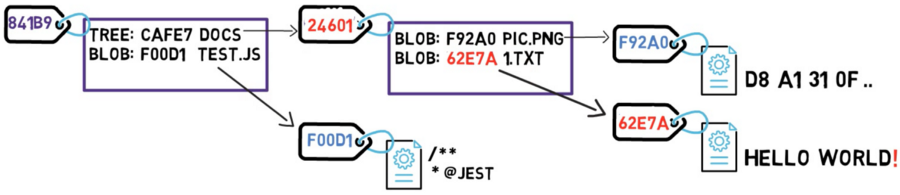
Y ahora, ya que el hash de ese árbol es diferente, también necesitas cambiar el árbol padre – ya que el último ya no apunta al árbol CAFE7, sino al árbol 24601. Consecuentemente, el árbol padre también tendrá un nuevo hash.
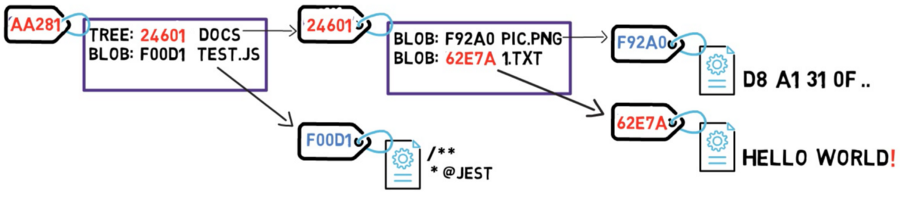
Casi listo para crear un nuevo objeto de confirmación, y parece que vas a almacenar un montón de datos – el sistema de archivos entero, ¡una vez más! ¿Pero es eso realmente necesario?
En realidad, algunos objetos, específicamente los objetos blob, no han cambiado ya que la confirmación anterior – el blob F92A0 permaneció intacto, y así también el blob F00D1.
Así que este es el truco – siempre y cuando un objeto no cambie, Git no lo almacena nuevamente. En este caso, Git no necesita almacenar el blob F92A0 o el blob F00D1 una vez más. Git se puede referir a ellos usando solamente sus valores hash. Entonces puedes crear tu objeto de confirmación.
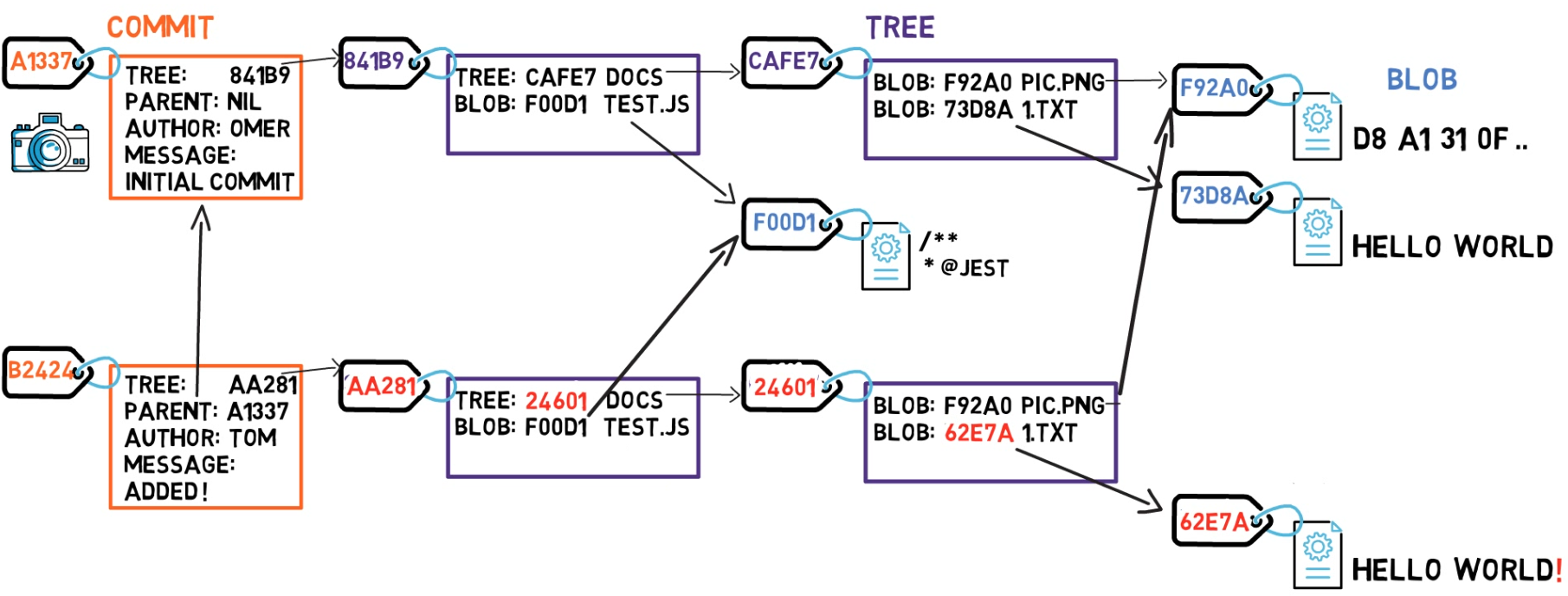
Ya que esta confirmación no es la primer confirmación, también tiene una confirmación padre – la confirmación A1337.
Considerando Hashes
Después de introducir blobs, árboles, y confirmaciones - considera los hashes de estos objetos. Digamos que escribí la cadena Git is awesome!, y de ahí creé un objeto blob. Tú hiciste lo mismo en tu sistema. ¿Tendríamos el mismo hash?
La respuesta es – Sí. Ya que los blobs consisten de los mismos datos, tendrán los mismos valores SHA-1.
¿Qué tal si hiciera un árbol que referencia al blob de Git is awesome!, y le diera un nombre específico y metadatos, y tú hicieras exactamente lo mismo en tu sistema? ¿Tendríamos el mismo hash?
De nuevo, sí. Ya que los objetos árboles son los mismos, tendrían el mismo hash.
¿Qué tal si creara una confirmación apuntando a ese árbol con el mensaje de confirmación Hello, y tú también hicieras lo mismo en tu sistema? ¿Tendrían el mismo hash?
En este caso, la respuesta es – No. Aunque nuestros objetos de confirmación se refieren al mismo árbol, tienen diferentes detalles de confirmación – tiempo, confirmador, y así sucesivamente.
¿Cómo son almacenados los Objetos?
Ahora entiendes el propósito de los blobs, los árboles y las confirmaciones. En los próximos capítulos, también crearás estos objetos tú mismo. A pesar de ser interesante, entender en realidad cómo estos objetos son codificados y almacenados no es vital para tu entendimiento.
Pequeña recapitulación - Objetos de Git
Para recapitular, en esta sección introdujimos tres objetos de Git:
- Blob – contenidos de un archivo.
- Árbol – un listado de directorios (de blobs y árboles).
- Confirmación – una copia instantánea del árbol de trabajo.
En el próximo capítulo, entenderemos sobre las ramas en Git.
Capítulo 2 - Las ramas en Git
En el capítulo anterior, sugerí que deberíamos ver a Git como un sistema para mantener un sistema de archivos.
Una de las maravillas de Git es que permite a múltiples personas trabajar en ese sistema de archivos, en paralelo, (mayormente) sin interferir en el trabajo de otros. La mayoría de las personas dirían que están "trabajando en la rama X." ¿Pero qué significa eso en realidad?
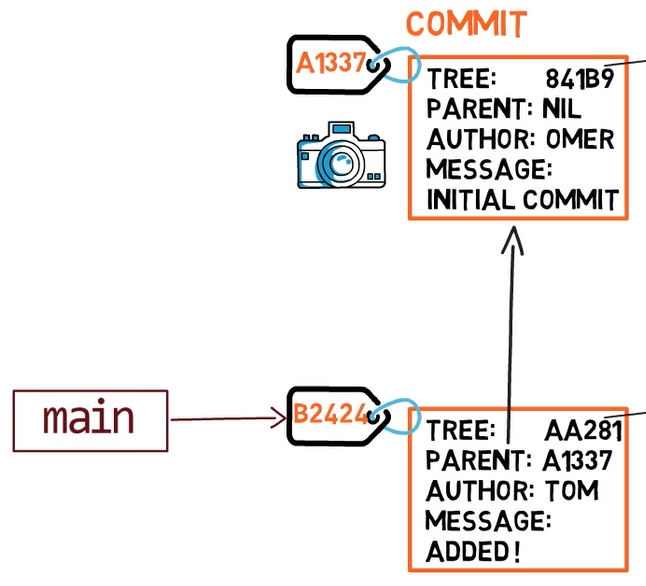
Una rama es sólo una referencia nombrada a una confirmación.
Siempre puedes referenciar a una confirmación por su hash SHA-1, pero los humanos usualmente prefieren otras formas de llamar a los objetos. Una rama es una forma de referenciar a una confirmación, pero realmente es eso nada más.
En la mayoría de los repositorios, la línea principal del desarrollo está hecho en una rama llamada main. Esto es sólo un nombre, y es creado cuando usas git init, haciéndolo que sea ampliamente usado. Sin embargo, podrías usar cualquier otro nombre que quisieres.
Típicamente, la rama apunta a la última confirmación en la línea de desarrollo en el que estás trabajando actualmente.
Para crear otra rama, puedes usar el comando git branch. Cuando haces eso, Git crea otro puntero. Si creaste una rama llamada test, usando git branch test, estarías creando otro puntero que apunta a la misma confirmación como la rama en la que se encuentra:
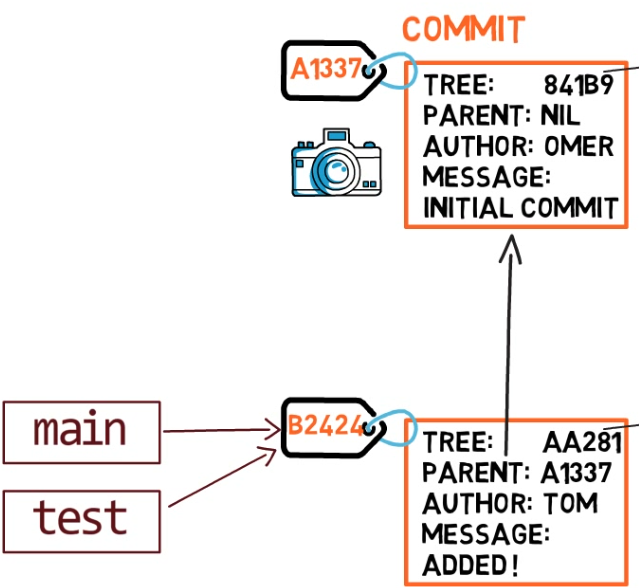
git branch creates another pointer¿Cómo sabe Git la rama en que te encuentras actualmente? Mantiene otro puntero designado, llamado HEAD. Usualmente, HEAD apunta a una rama, que a su vez apunta a una confirmación. En el caso descrito, HEAD podría apuntar a main, que a su vez apunta a la confirmación B2424. En algunos casos, HEAD también puede apuntar a una confirmación directamente.
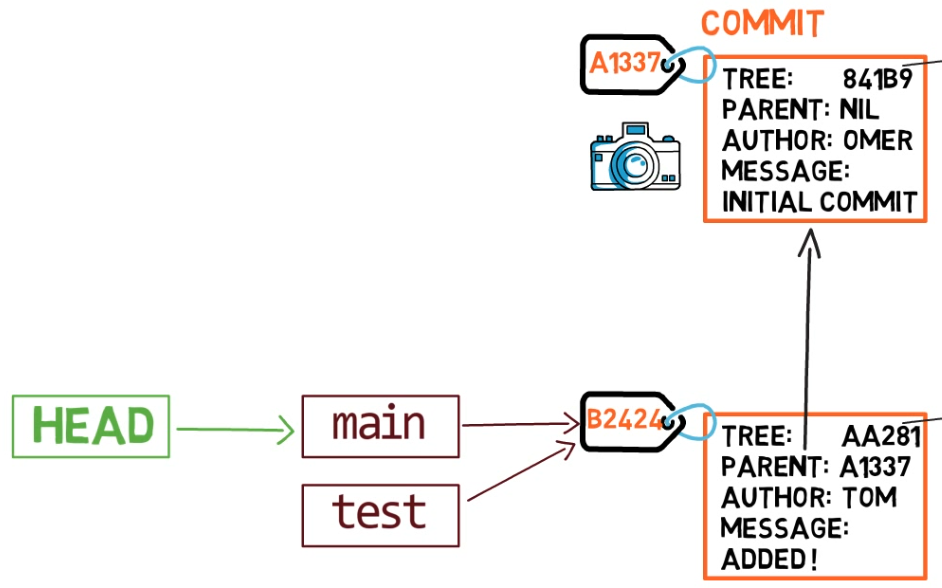
HEAD points to the branch you are currently onPara cambiar la rama activa a ser test, puedes usar el comando git checkout test, o git switch test. Ahora ya puedes adivinar lo que hace este comando en realidad – solo cambia a HEAD a que apunte a test.
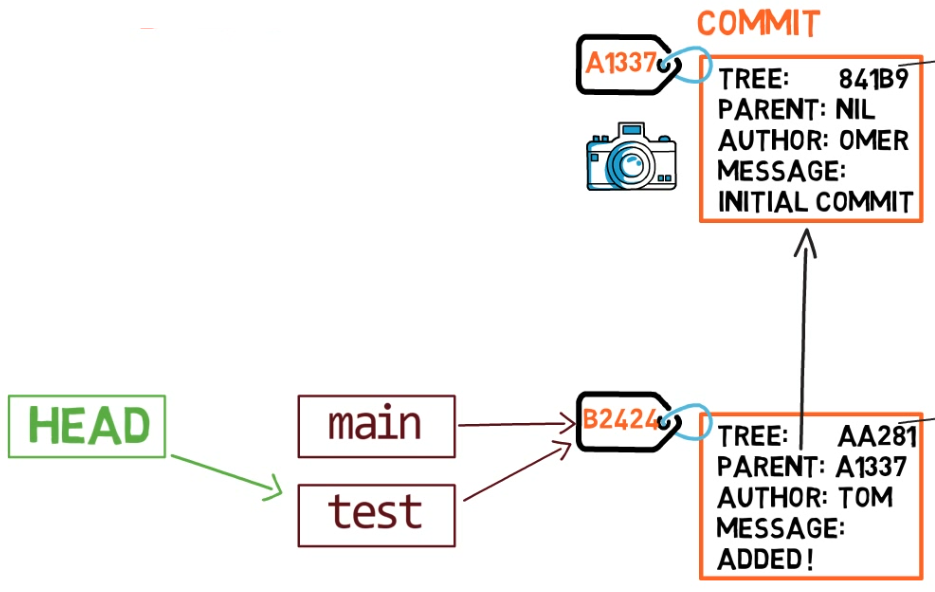
git checkout test changes where HEAD pointsTambién podrías usar git checkout -b test antes de crear la rama test, el cual es el equivalente de ejecutar git branch test para crear la rama, y luego git checkout test para mover el HEAD a que apunte a la nueva rama.
Al punto representado en el dibujo de arriba, ¿qué sucedería si hicieras algunos cambios y crearas una nueva confirmación usando git commit? ¿A qué rama será agregada la nueva confirmación?
La respuesta es la rama test, ya que éste es la rama activa (ya que HEAD apunta a éste). Después, el puntero test se moverá a la nueva confirmación agregada recientemente. Fíjate que HEAD todavía apunta a test.
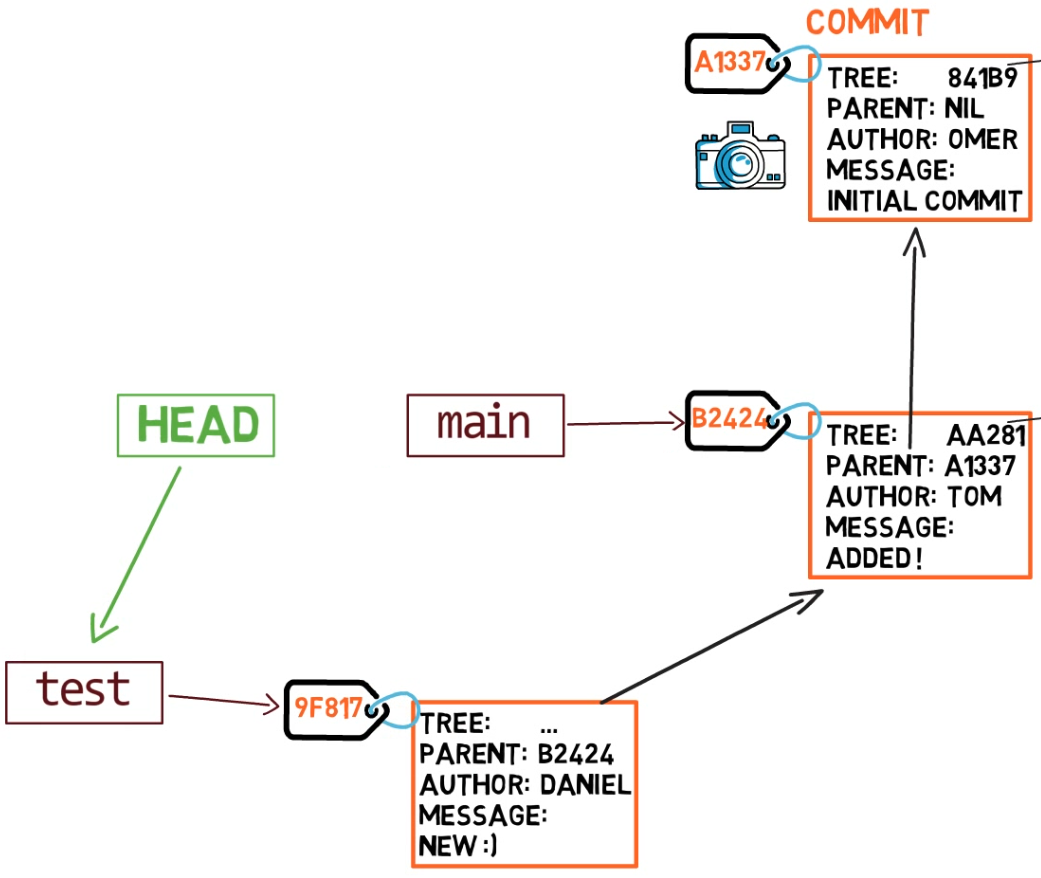
git commit, the branch pointer moves to the newly created commitSi vuelves atrás a main usando git checkout main, Git moverá el HEAD a que apunta a main nuevamente.
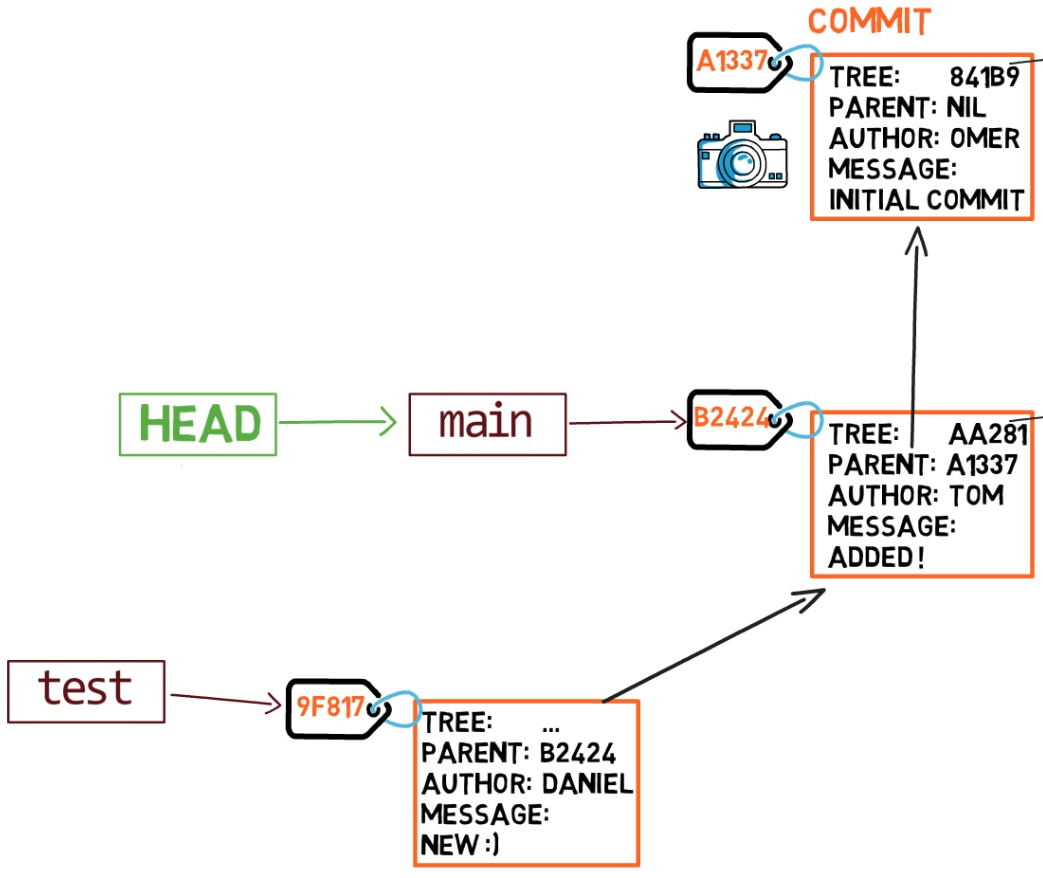
git checkout mainAhora, si creas otra confirmación, ¿a qué rama será agregado?
Así es, será agregado a la rama main (y su padre sería la confirmación B2424).
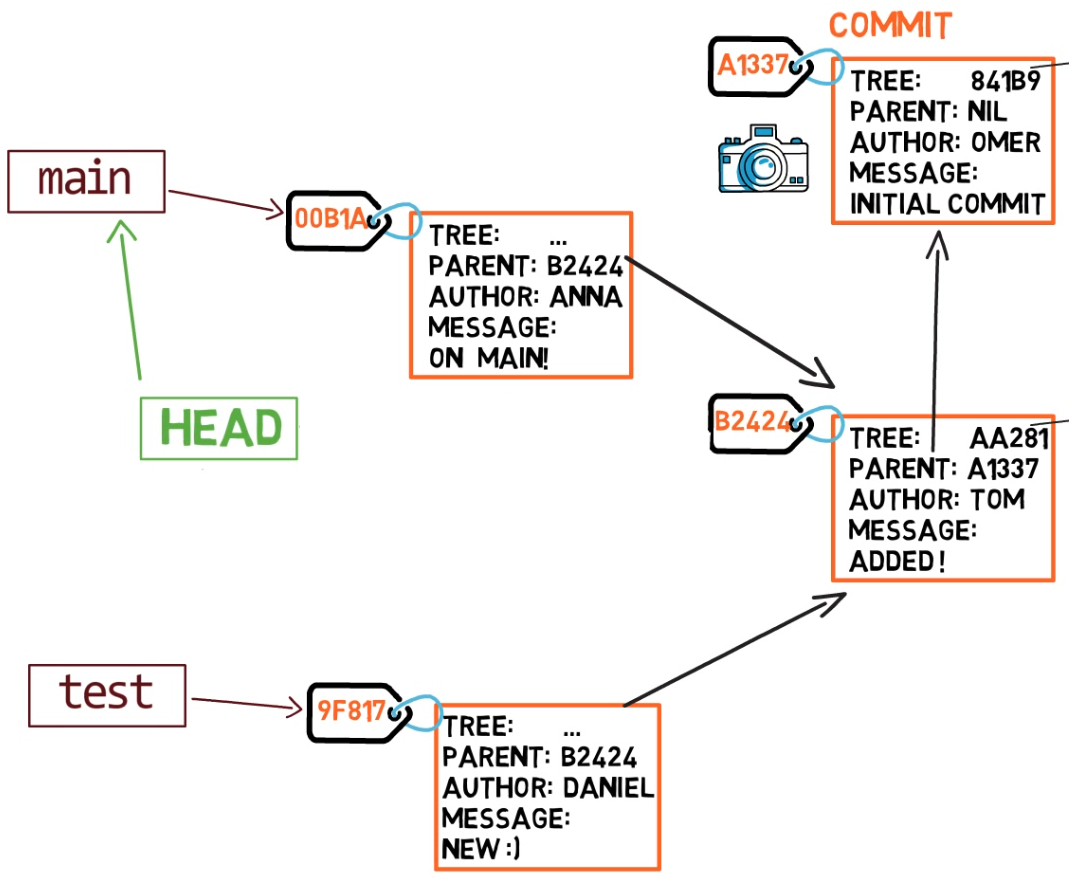
main branchPequeña recapitulación - Las ramas
- Una rama es una referencia nombrada a una confirmación.
- Cuando uses
git commit, Git crea un objeto de confirmación, y mueve la rama a que apunte a la confirmación creada recientemente. HEADes un puntero especial que le dice a Git qué rama es la rama activa (en casos excepcionales, puede apuntar directamente a una confirmación).
En los próximos capítulos, aprenderás cómo introducir cambios a Git. Crearás un repositorio desde cero – sin usar git init, git add, o git commit. Esto te permitirá profundizar tu entendimiento de lo que está pasando por debajo cuando trabajes con Git. También crearás nuevas ramas, cambiarás ramas, y crearás confirmaciones adicionales – todo sin usar git branch o git checkout. No lo sé tú, pero yo ¡ya estoy entusiasmado!
Capítulo 3 - Cómo registrar cambios en Git
Hasta ahora, hemos aprendido sobre cuatros entidades distintas en Git:
- Blob – contenidos de un archivo.
- Árbol – un lista de directorios (de blobs y árboles).
- Confirmación – una copia instantánea del árbol de trabajo, con algunos metadatos tales como el tiempo o el mensaje de confirmación.
- Rama – una referencia nombrada a una confirmación.
Los primeros tres son objetos, donde el cuarto es una forma de referirse a objetos (específicamente, confirmaciones).
Ahora, es tiempo de entender cómo introducir cambios en Git.
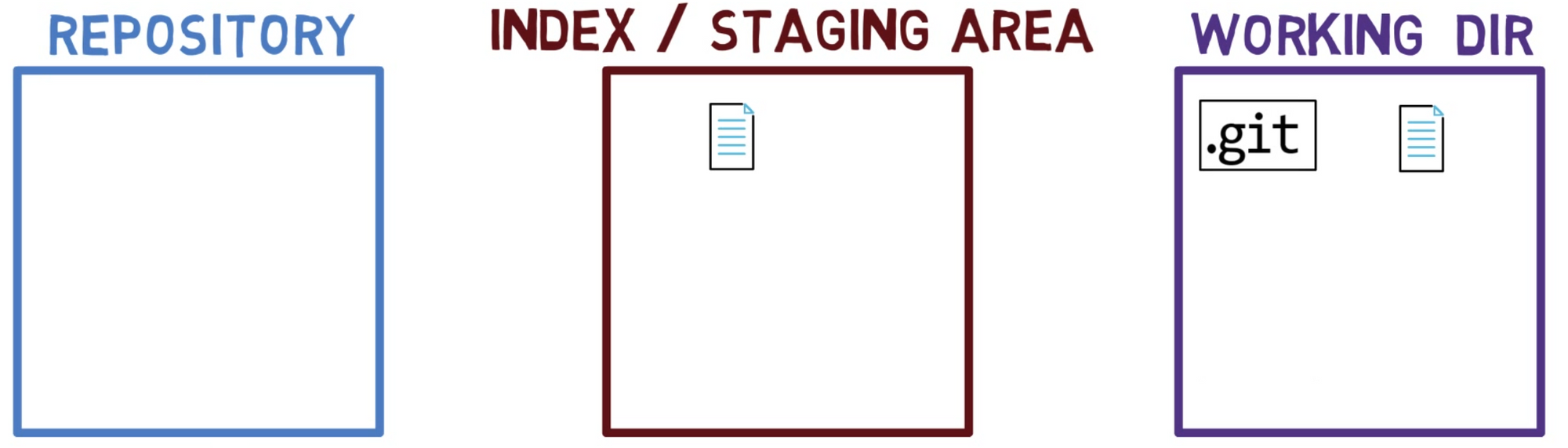
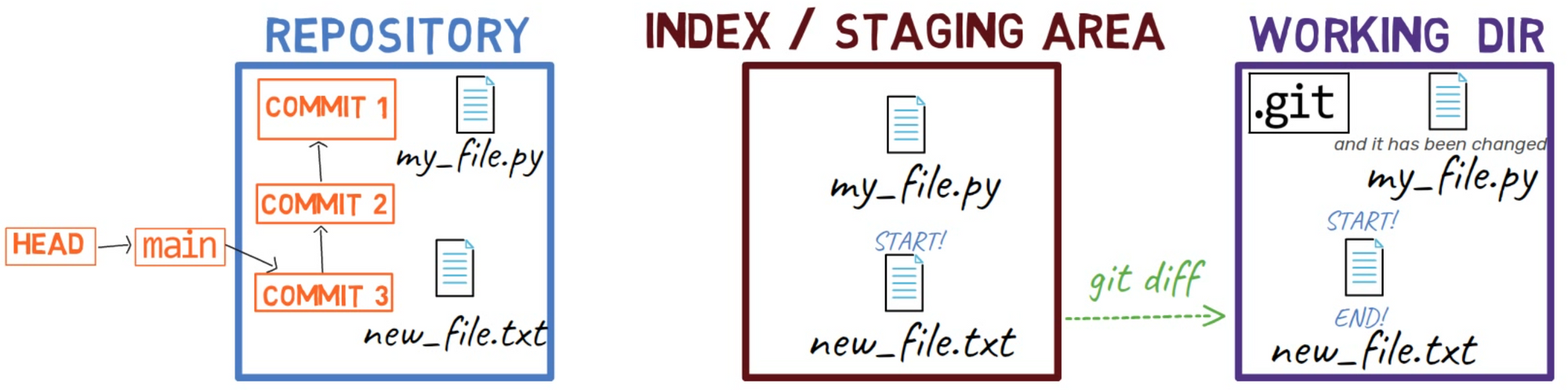
Cuando trabajas en tu código fuente, trabajas desde un directorio de trabajo. Un dir(ectorio) de trabajo (también llamado "árbol de trabajo") es cualquier directorio en tu sistema de archivos el cual tiene un repositorio asociado. Contiene las carpetas y los archivos de tu proyecto, y también un directorio llamado .git del cual hablaremos más adelante. Recuerda que dijimos que Git es un sistema para mantener un sistema de archivos. El directorio de trabajo es la raíz del sistema de archivos para Git.
Después de que haces algunos cambios, podrías querer registrarlos en tu repositorio. Un repositorio (en corto: "repo") es una colección de confirmaciones, cada uno de los cuales es un archivo de lo que el árbol de trabajo del proyecto parecía en una fecha anterior, sea en tu máquina o la de alguien más. Eso es, como dije antes, una confirmación es una copia instantánea del árbol de trabajo.
Un repositorio también incluye otras cosas además de tus archivos de código, tales como HEAD y ramas.
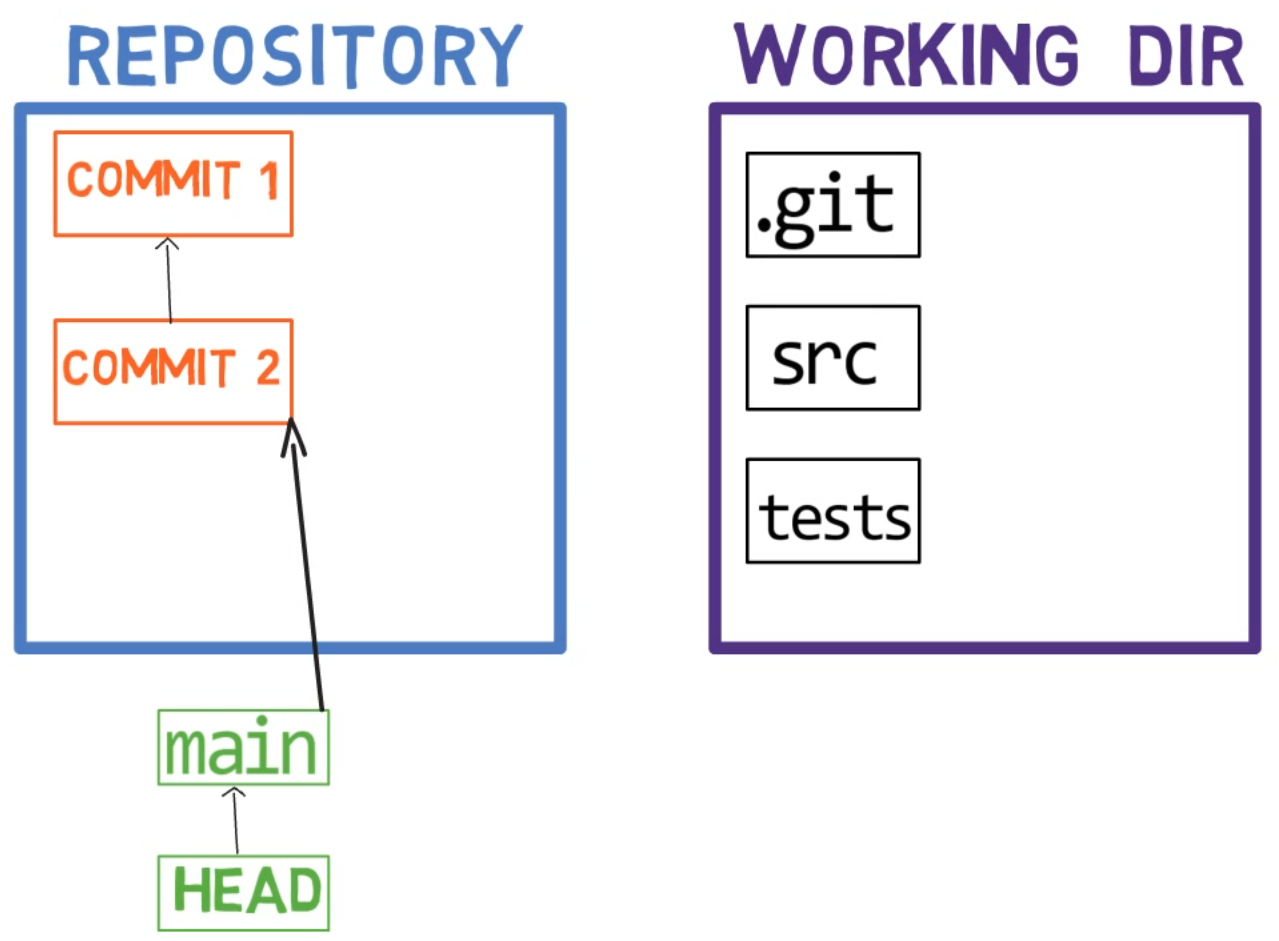
Fíjate las convenciones del dibujo que uso: incluyo .git dentro del directorio de trabajo, para recordarte que es una carpeta dentro de la carpeta del proyecto en el sistema de archivos. La carpeta .git en realidad contiene los objetos del repositorio, como veremos en el capítulo 4.
Hay otros sistemas de control de versión donde los cambios son confirmados directamente desde el directorio de trabajo al repositorio. En Git, este no es el caso. En sí, los cambios son primero registrados en algo llamado el índice, o el área de staging.
Ambos términos se refieren a la misma cosa, son usados frecuentemente en la documentación de Git. Usaré estos términos indistintamente a lo largo de este libro, ya que te sentirás mas cómodo con ambos.
Puedes imaginarte el agregar cambios al índice como una forma de "confirmando" tus cambios, uno por uno, antes de crear una confirmación (el cual registra todos los cambios aprobados de una sola vez).
Cuando haces checkout a una rama, Git popula el índice y el directorio de trabajo con los contenidos de los archivos ya que existen en la confirmación a la rama al cual está apuntando. Cuando usas git commit, Git crea un nuevo objeto de confirmación basado en el estado de ese índice.

Usando el índice te permite preparar cuidadosamente cada confirmación. Por ejemplo, podrías tener dos archivos con cambios en tu directorio de trabajo:

Por ejemplo, digamos que estos dos archivos son 1.txt y 2.txt. Es posible agregar solamente uno de ellos (por ejemplo, 1.txt) al índice, usando git add 1.txt:

1.txtComo resultado, el estado del índice coincide con el estado del HEAD (en este caso, "Commit 2"), con la excepción del archivo 1.txt, el cual coincide el estado de 1.txt en el directorio de trabajo. Ya que no pusiste en el área de preparación a 2.txt, el índice no incluye a la versión actualizada de 2.txt. Así que el estado de 2.txt en el índice coincide con el estado de 2.txt en el "Commit 2".
En detrás de escena - una vez que pones en el área de preparación una versión de un archivo, Git crea un objeto blob con los contenidos del archivo. Este objeto blob es agregado luego al índice. Siempre y cuando solamente modifiques el archivo en el directorio de trabajo, sin ponerlo en el área de preparación, los cambios que hagas no son registrados en los objetos blob.
Cuando consideramos la figura previa, fíjate que no dibujo la versión del área de preparación del archivo como parte del "repositorio", ya que esta representación, el "repositorio" se refiere a un árbol de confirmaciones y sus referencias, y este blob no ha sido parte de ninguna confirmación.
Ahora, puedes usar git commit para registrar el cambio a 1.txt solamente:

git commitUsando git commit ejecuta dos operaciones principales:
- Crea un nuevo objeto de confirmación. Este objeto de confirmación refleja el estado del índice cuando ejecutaste el comando
git commit. - Actualiza a la rama activa para que apunte a la confirmación creada recientemente. En este ejemplo, el
mainahora apunta al "Commit 3", el nuevo objeto de confirmación.
Cómo crear un repo – La Forma Convencional
Vamos a asegurarnos que entiendas cómo los términos que hemos introducidos se relacionan al proceso de crear un nuevo repositorio. Este es un vistazo rápido de alto nivel, antes de sumergirnos más profundamente en este proceso.
Inicializa un nuevo repositorio usando git init my_repo, y luego cambia tu directorio al repositorio usando cd my_repo:

git initUsando tree -f .git puedes ver que ejecutando git init my_repo resultó en unos pocos sub-directorios dentro de .git. (El argumento -f incluye archivos en la salida del árbol).
Nota: si estás usando Windows, ejecuta tree /f .git.
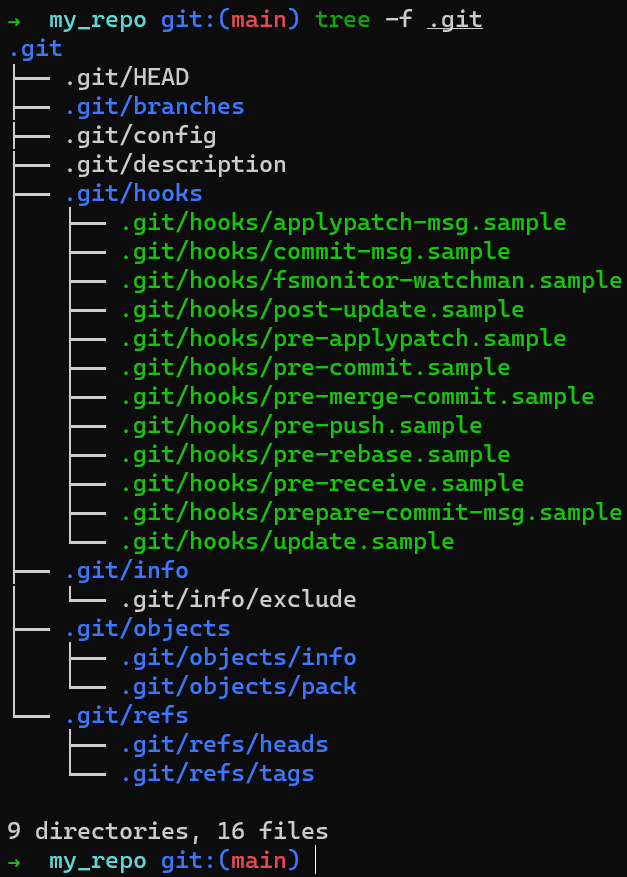
tree -f .git after using git initCrea un archivo dentro del directorio my_repo:
f.txtEste archivo está dentro de tu directorio de trabajo. Si ejecutas git status, verás este archivo no está rastreado:
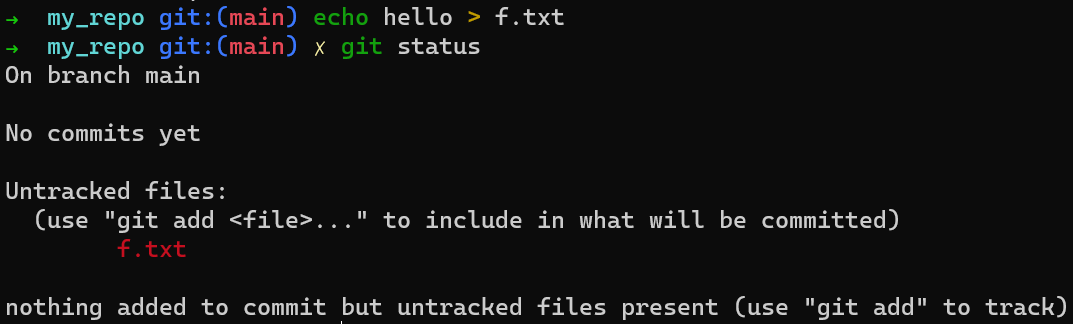
git statusLos archivos en tu directorio de trabajo puede ser uno de los dos estados: rastreados o no rastreados.
Los archivos rastreados son archivos que Git "conoce". Ellos estuvieron en la última confirmación, o están en el área de preparación ahora (eso es, están en el área staging).
Los archivos no rastreados son todos los demás – cualquier archivo en tu directorio de trabajo que no estuvieron en tu última confirmación, y que no están en tu área de preparación.
El nuevo archivo (f.txt) no está rastreado actualmente, ya que no lo has agregado al área de preparación, y no ha sido incluido en la confirmación anterior.

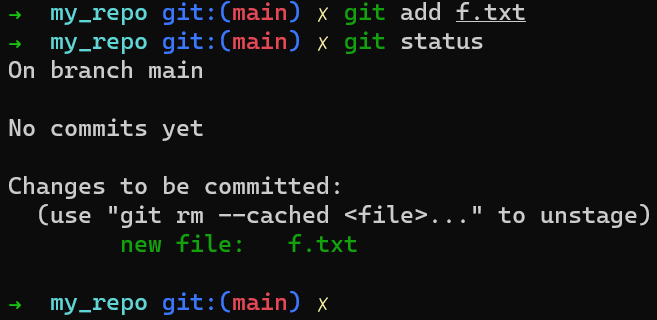
f.txt is in the working directory (and untracked)Ahora puedes agregar este archivo al área de preparación (también referido como poner en staging este archivo) usando git add f.txt. Puedes verificar que ha sido puesto en el área de preparación ejecutando git status:
Así que ahora el estado del índice coincide con el directorio de trabajo:
Ahora puedes crear una confirmación usando git commit:
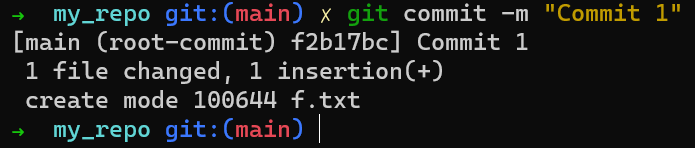
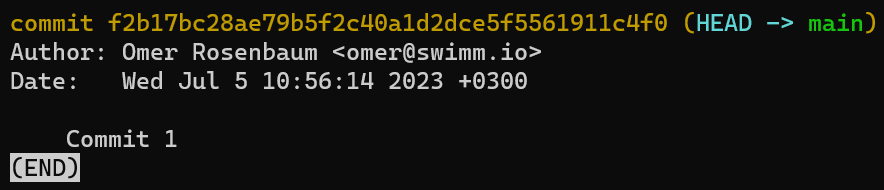
Si ejecutas git status nuevamente, verás que el estado está limpio - eso es, el estado de HEAD (el cal apunta a tu confirmación inicial) equivale al estado del índice, y también el estado del directorio de trabajo. Usando git log verás en realidad que HEAD apunta a main el cual a su vez apunta a la nueva confirmación:
¿Ha cambiado algo dentro del directorio .git? Ejecuta tree -f .git para verificar:
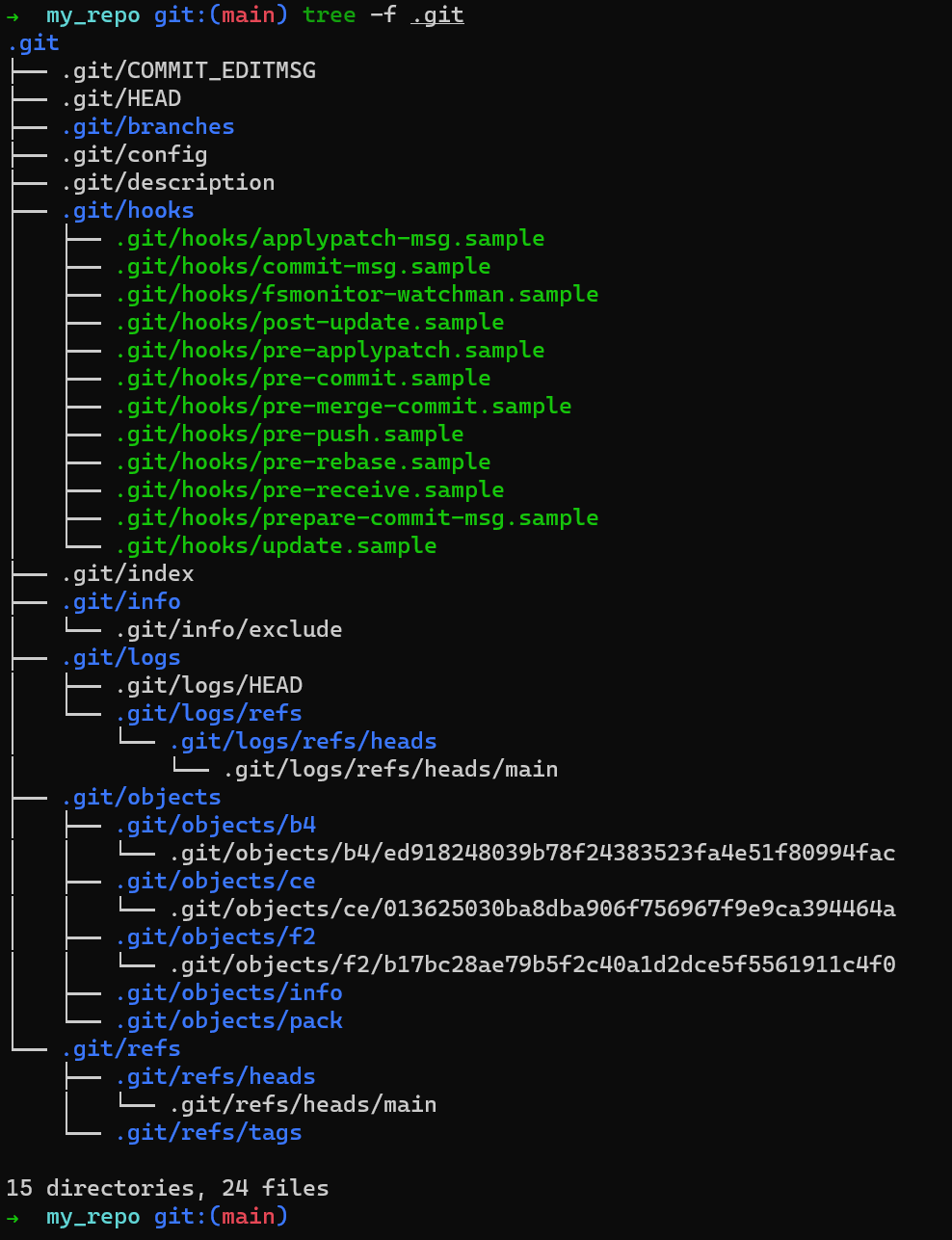
.gitAparentemente, un montón ha cambiado. Es tiempo de sumergirnos más profundo en la estructura de .git y entender qué está pasando por detrás cuando ejecutas git init, git add o git commit. Eso es exactamente lo que cubrirá el próximo capítulo.
Recapitulación - Cómo registrar cambios en Git
Aprendiste sobre los tres "estados" distintos del sistema de archivos que Git mantiene:
- Dir(ectorio) de trabajo (también llamado "árbol de trabajo") - cualquier directorio en tu sistema de archivos el cual tiene un repositorio asociado.
- Índice, o el Área de preparación - un espacio de interacción para la próxima confirmación.
- Repositorio (en corto: "repo") - una colección de confirmaciones, el cual cada una es una copia instantánea del árbol de trabajo.
Cuando introduces cambios en Git, casi siempre sigue este orden:
- Cambias el directorio de trabajo primero
- Luego pones estos cambios en el área de preparación (o algunos de ellos) al índice
- Y finalmente, confirmas estos cambios - de esta forma actualiza el repositorio con una nueva confirmación. El estado de esta nueva confirmación coincide con el estado del índice
¿Listo para sumergirte más profundo?
Capítulo 4 - ¿Cómo crear un repo desde cero?
Hasta ahora hemos cubiertos algunos fundamentos de Git, y ahora deberías estar listo para realmente continuar con Git.
Para entender profundamente cómo funciona Git, crearás un repositorio, pero esta vez – lo construirás desde cero. Como en otros capítulos, te animo a intentar los comandos a lo largo de este capítulo.
Cómo configurar .git
Crea un nuevo directorio, y ejecuta git status dentro:

git status in a new directoryMuy bien, parece que Git no está feliz ya que no tiene una carpeta .git todavía. Lo natural por hacer sería crear ese directorio e intentarlo otra vez:
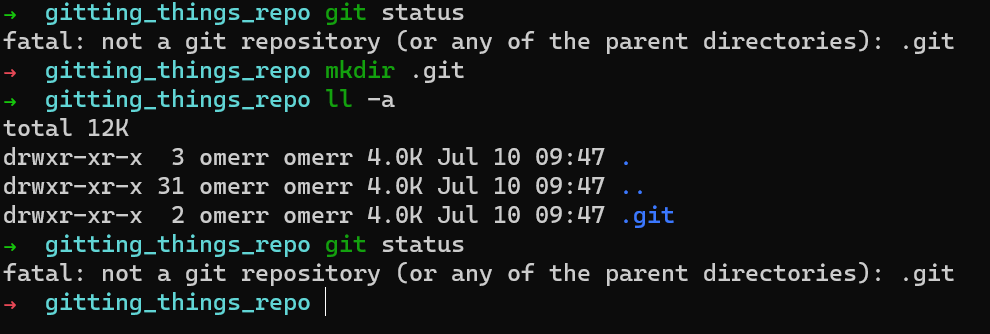
git status after creating .gitAparentemente, crear un directorio .git no es suficiente. Necesitas agregar algún contenido a ese directorio.
Un repositorio de Git tiene dos conceptos principales:
- Una colección de objetos – blobs, árboles, y confirmaciones.
- Un sistema de nombramiento de esos objetos – llamados referencias.
Un repositorio también podría contener otras cosas, tales como hooks, pero a lo menos – debe incluir objetos y referencias.
Crear un repositorio para los objetos en .git/objets, y un directorio para las referencias (en forma corta: "refs") en .git/refs (en sistemas Windows – .git\objects y .git\refs, respectivamente).
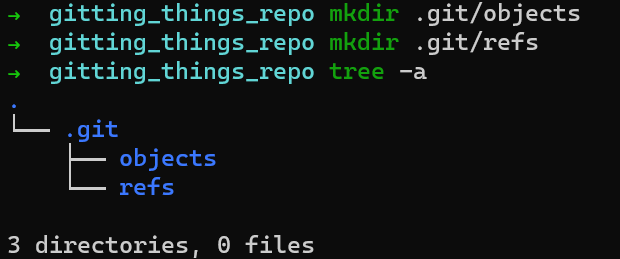
Un tipo de referencia son las ramas. Internamente, Git llama a las ramas por el nombre de heads. Crea un directorio para las ramas – .git/refs/heads.
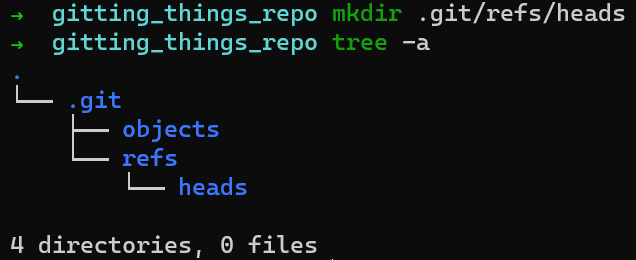
Esto todavía no cambia el resultado de git status:
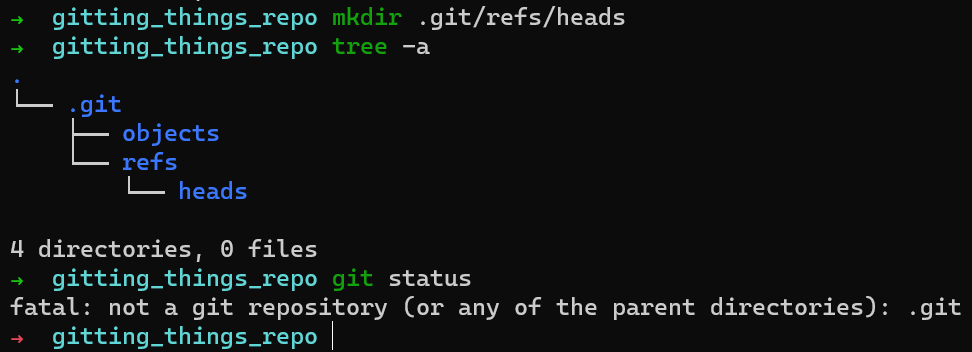
git status after creating .git/refs/heads¿Cómo sabe Git dónde comenzar cuando busca una confirmación en el repositorio? Como expliqué antes, busca el HEAD, el cual apunta a la rama actual activa (o la confirmación, en algunos casos).
Así que, necesitas crear el HEAD, el cual es sólo un archivo que reside en .git/HEAD. Puedes aplicar lo siguiente:
En UNIX:
echo "ref: refs/heads/main" > .git/HEAD
En Windows:
echo ref: refs/heads/main > .git\HEAD
Así que ahora sabes cómo se implementa HEAD – es simplemente un archivo, y su contenido describe a qué apunta.
Siguiendo el comando de arriba, git status parece cambiar su pensamiento:
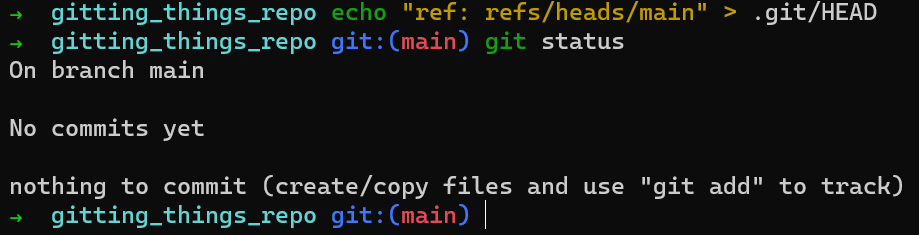
HEAD is just a fileFíjate que Git "cree" que estás en la rama llamada main, aunque no has creado esta rama. main es sólo un nombre. También puedes hacer creer a Git que estás en una rama llamada banana si quieres:
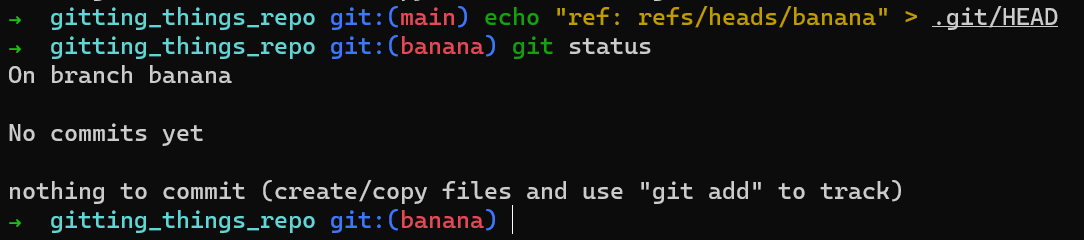
bananaVuelve al main, ya que continuarás trabajando (mayormente) allí a lo largo de este capítulo, sólo para aderirnos a la convención regular:
echo "ref: refs/heads/main" > .git/HEAD
Ahora que tienes tu directorio .git listo, puedes trabajar a tu manera para hacer una confirmación (de nuevo, sin usar git add o git commit).
Comandos de plomería vs comandos de porcelana en Git
A este punto, debería ser bueno hacer una distinción entre dos tipos de comandos de Git: de plomería y de porcelana. La aplicación de los términos extrañamente viene de los baños, tradicionalmente los hechos de porcelana, y la infraestructura de la plomería (las cañerías y los drenajes).
La capa de porcelana provee una interfaz amigable para el usuario en la plomería. La mayoría de la gente solamente manejan la porcelana. Aún así, cuando las cosas van (terriblemente) mal, y alguien quiere entender el por qué, tendrían que remangarse y tratar con la plomería.
Git usa esta terminología como una analogía para separar los comandos de bajo nivel que los usuarios usualmente no necesitan usar directamente (comandos "de plomería") de los comandos de alto nivel (comandos "de porcelana").
Hasta ahora, has lidiado con comandos de porcelana – git init, git add o git commit. Es tiempo de ir más profundo, y que te familiarices con algunos comandos de plomería.
Cómo crear objetos en Git
Empieza por crear un objeto y escríbelo dentro de la base de datos de los objetos de Git, que reside dentro de .git/objects. Para saber el valor del hash SHA-1 de un blob, puedes usar git hash-object. (Sí, un comando de plomería), de la siguiente forma:
En UNIX:
echo "Git is awesome" | git hash-object --stdin
En Windows:
> echo Git is awesome | git hash-object --stdin
Usando --stdin estás instruyendo a git hash-object que tome su entrada de la entrada estándar. Esto te proveerá con el valor del hash relevante:

En realidad para escribir ese blob dentro de la base de datos de objetos de Git, puedes agregar el conmutador -w por git hash-object. Después, verifica el contenido de la carpeta .git, y mira si han cambiado:
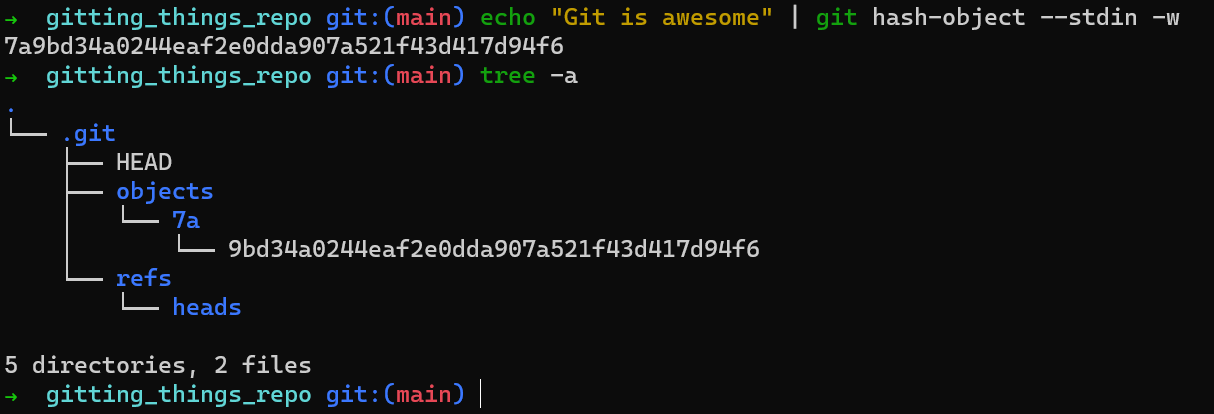
Puedes ver que el hash de tu blob es 7a9bd34a0244eaf2e0dda907a521f43d417d94f6. También puedes ver que un directorio ha sido creado como .git/objects, un directorio llamado 7a, y dentro, un archivo con el nombre de 7a9bd34a0244eaf2e0dda907a521f43d417d94f6.
Lo que Git hizo aquí es tomar los primeros dos caracteres del hash SHA-1, y usarlos como el nombre de un directorio. Los caracteres sobrantes son usados como el nombre de archivo para el archivo que en realidad contiene el blob.
¿Por qué eso es así? Considera un repositorio considerablemente grande, uno que tiene 400,000 objetos (blobs, árboles, y confirmaciones) en su base de datos. Buscar un hash dentro de esa lista de 400,000 hashes podría tomar un buen rato. Así, Git simplemente divide ese problema por 256.
Para buscar el hash de arriba, Git primero miraría el directorio llamado 7a dentro del directorio .git/objects, el cual tendría hasta 256 directorios (00 hasta FF). Luego, buscaría dentro de ese directorio, acortando la búsqueda a medida que continúa.
De vuelta al proceso de generar una confirmación. Has creado un objeto solamente. ¿Cuál es el tipo de ese objeto? Puedes usar otro comando de plomería, git cat-file -t (-t significa "type" - "tipo"), para verificar eso:

git cat-file -t <object_sha> reveals the type of the Git objectNo sorprendentemente, este objeto es un blob. También puedes usar git cat-file -p (-p significa "pretty-print" - "imprimir-bonito") para ver su contenido:

git cat-file -pEste proceso de crear un objeto blob como .git/objects usualmente sucede cuando agregas algo al área de preparación – eso es, cuando usas git add. Así que los blobs no son creados cada vez que guardes un archivo al sistema de archivos (el directorio de trabajo), sino solamente cuando lo pongas en el área de preparación.
Recuerda que Git crea un blob del archivo entero que se pone en el área de preparación. Inclusive si un solo caracter es modificado o agregado, el archivo tiene un nuevo blob con un nuevo hash (como en el ejemplo del capítulo 1 donde agregaste ! al final de la línea).
¿Habrá algún cambio a git status?
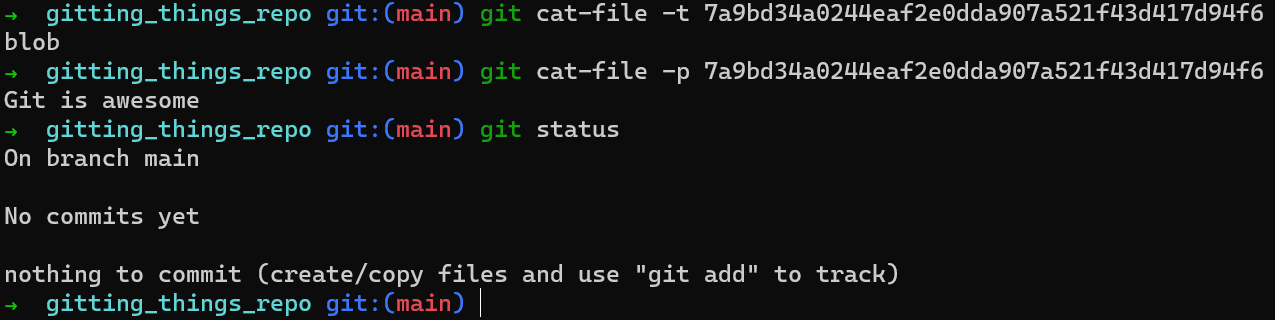
git status after creating a blob objectAparentemente, no. Agregar un objeto blob a la base de datos interno de Git no cambia el estado, ya que Git no sabe de ningún archivo con seguimiento (o sin seguimiento) en esta área de preparación.
Necesitas rastrear este archivo – agregarlo al área de preparación. Para hacer eso, puedes usar otro comando de plomería, git update-index, así:
git update-index --add --cacheinfo 100644 <blob-hash> <filename>
Nota: El cacheinfo es un modo de archivo de 16-bits almacenado por Git, siguiendo el diseño de los tipos y modos de POSIX. Esto no está dentro del enfoque de este libro, ya que no es realmente importante para que hagas las cosas.
Ejecutar el comando de arriba resultará en un cambio al contenido de .git:
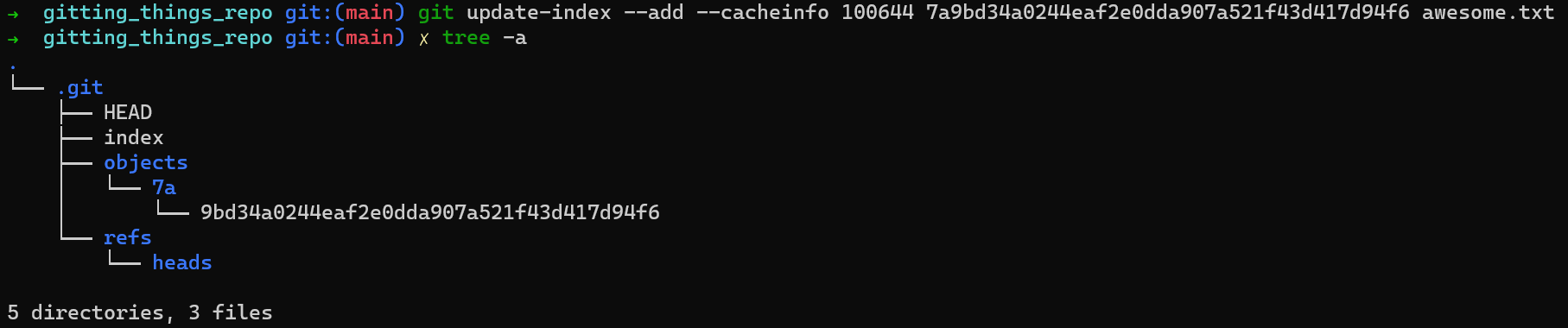
.git after updating the index¿Puedes encontrar el cambio? Un nuevo archivo con el nombre de index ha sido creado. Eso es todo – el famoso índice (o área de preparación), es básicamente un archivo que reside dentro de .git/index.
Así que ahora que tu blob ha sido agregado al índice, ¿esperas que git status luzca diferente?
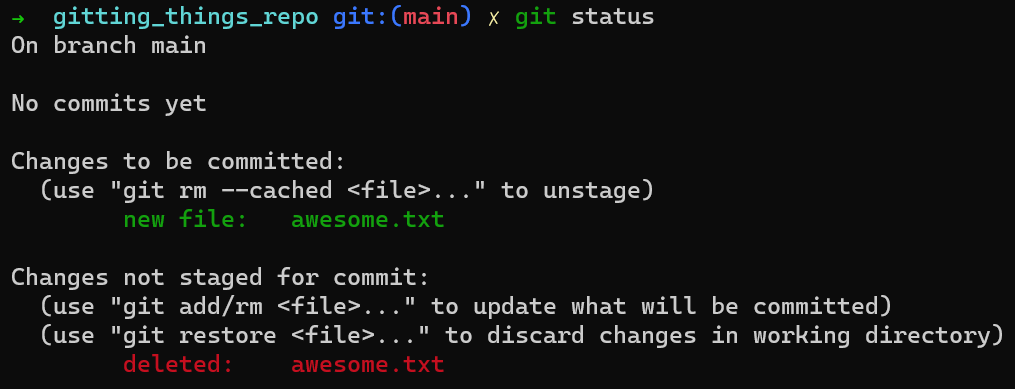
git update-index¡Eso es interesante! Dos cosas pasaron aquí.
Primero, puedes ver que awesome.txt aparece en verde, en el área "Changes to be committed" ("Cambios a ser confirmados"). Eso es así porque el índice ahora incluye a awesome.txt, esperando a ser confirmado.
Segundo, podemos ver que awesome.txt aparece en rojo – porque Git cree que el archivo awesome.txt ha sido eliminado, y el hecho que el archivo ha sido eliminado sino que no está en el área de preparación.
(Nota: te habrás dado cuenta que a veces me refiero a Git con palabras tales como "cree", "piensa", o "quiere". Como expliqué en la introducción de este libro - para que disfrutemos jugando con Git, y leer (y escribir) este libro, siento que referirse a Git más que sólo código lo hace mucho más divertido.)
Esto sucede ya que agregaste el blob con el contenido Git is awesome a la base de datos de los objetos, y actualizaste el índice que el archivo awesome.txt retiene el contenido de ese blob, pero en realidad nunca creaste ese archivo en el disco.
Fácilmente puedes resolver esto tomando el contenido de ese blob y escribirlo a nuestro sistema de archivos, a un archivo llamado awesome.txt:
echo "Git is awesome" > awesome.txt
Como resultado, ya no aparecerá en rojo por git status:
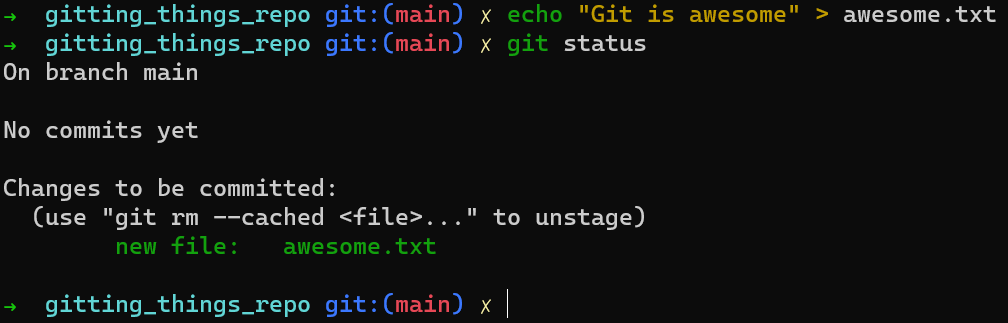
git status after creating awesome.txt on diskAsí que ahora es tiempo de crear un objeto de confirmación desde tu área de preparación. Como expliqué en el capítulo 1, un objeto de confirmación tiene una referencia a un árbol, así que necesitas crear un árbol.
Puedes lograr esto usando el comando git write-tree, el cual registra los contenidos del índice en un objeto árbol. Por supuesto, puedes usar git cat-file -t para ver que en sí es un árbol:

Y puedes usar git cat-file -p para ver su contenido:

git cat-file -p to see the tree's contentsGenial, así que creaste un árbol, y ahora necesitas crear un objeto de confirmación que referencia a este árbol. Para hacer eso, puedes usar el comando:
git commit-tree <tree-hash> -m <commit message>

Ahora deberías sentirte cómodo con los comandos usados para verificar el tipo de objeto creado, e imprimir su contenido:
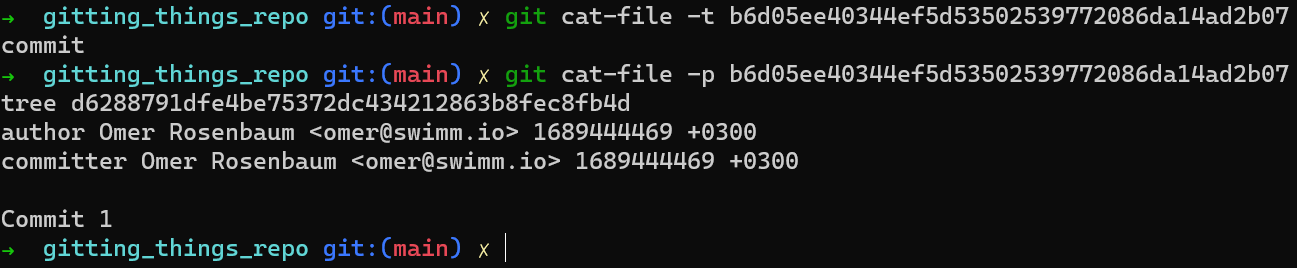
Fíjate que este objeto de confirmación no tiene un padre, porque no es la primer confirmación. Cuando agregas otra confirmación probablemente querrás declarar su padre – no te preocupes, lo harás así más tarde.
El último hash que tuvimos – b6d05ee40344ef5d53502539772086da14ad2b07 – es un hash de la confirmación. En realidad deberías estar acostumbrado en usar estos hashes – probablemente los ves todo el tiempo (cuando usas git log, por ejemplo). Fíjate que el objeto de confirmación apunta a un objeto de árbol, con su propio hash, el cual raramente especificas explícitamente.
¿Cambiará algo en git status?
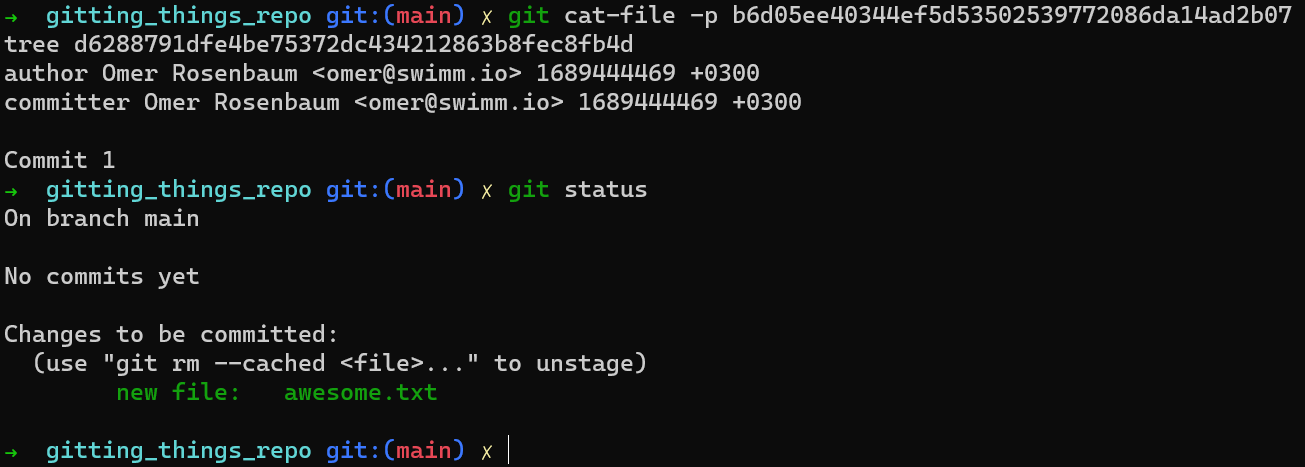
git status after creating a commit objectNo, nada ha cambiado. ¿Por qué es eso?
Bueno, para saber que tu archivo ha sido confirmado, Git necesita saber sobre la última confirmación. ¿Cómo sabe Git eso? Va al HEAD:

HEADHEAD apunta a main, pero, ¿qué es main? Aún no lo has creado.
Como explicamos en el capítulo 2, una rama es simplemente una referencia nombrada a una confirmación. Y en este caso, nos gustaría que main se refiriera al objeto de confirmación con el hash b6d05ee40344ef5d53502539772086da14ad2b07.
Puedes lograr esto creando un archivo en .git/refs/heads/main, con el contenido de este hash, así:
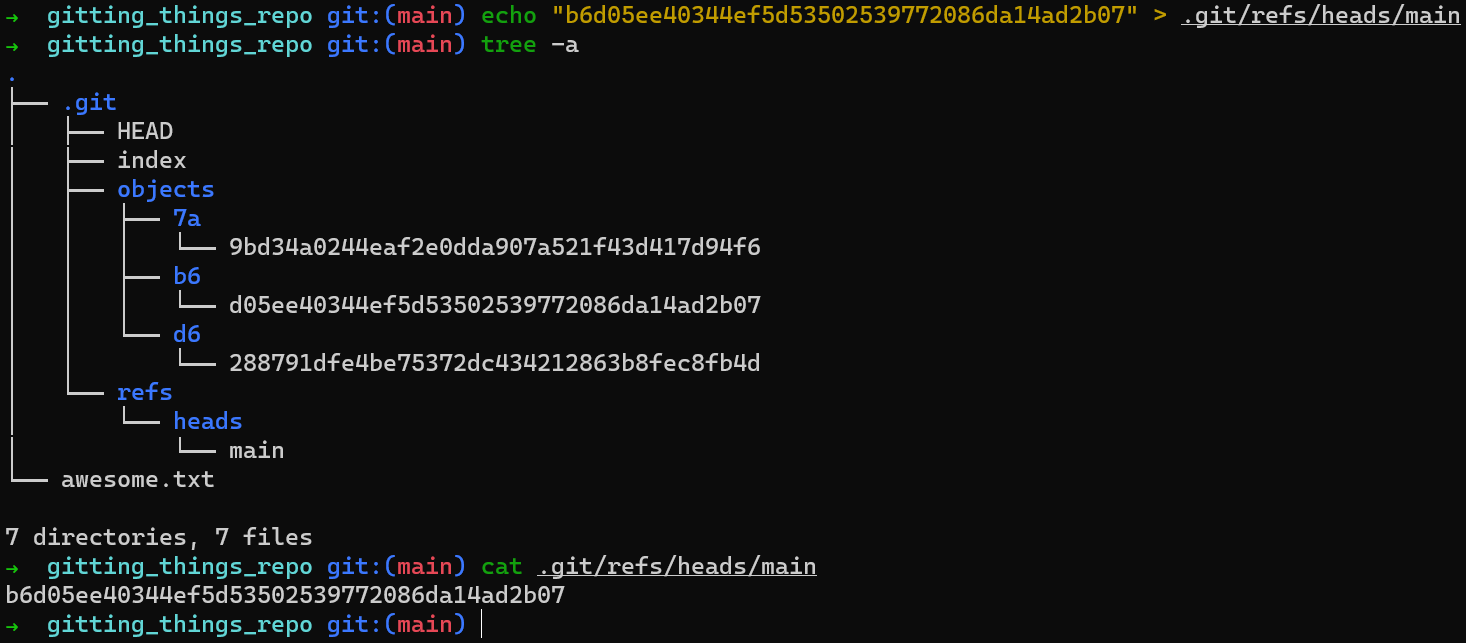
mainEn resumen, una rama es sólo un archivo dentro de .git/refs/heads, que contiene un hash de la confirmación a la que se refiere.
Ahora, finalmente, git status y git log parecen apreciar nuestros esfuerzos:

git status
git log¡Has creado con éxito una confirmación sin usar comandos de porcelana! ¿No es genial eso?
Recapitulación - Cómo crear un repo desde cero
En este capítulo, sin miedo te sumergiste en profundidad en Git. Paraste de usar comandos de porcelana y te cambiaste a los comandos de plomería.
Al usar echo y comandos de nivel bajo tales como git hash-object, fuiste capaz de crear un blob, agregarlo al índice, crear un árbol del índice, y crear un objeto de confirmación apuntando a ese árbol.
También aprendiste que HEAD es un archivo, localizado en .git/HEAD. Las ramas son archivos también, localizados en .git/refs/heads. Cuando entiendes cómo opera Git, esas nociones abstractas de HEAD o "ramas" se vuelven muy tangibles.
En el próximo capítulo profundizarás tu entendimiento de cómo trabajan las ramas por detrás.
Capítulo 5 - Cómo trabajar con las ramas en Git – Por debajo
En el capítulo anterior creaste un repositorio y una confirmación sin usar git init, git add o git commit. En este capítulo, crearemos y cambiaremos entre ramas sin usar comandos de porcelana (git branch, git switch, o git checkout).
Es perfectamente entendible si estás emocionado, ¡yo también lo estoy!
Continuando con lo del capítulo anterior - solamente tienes una rama, llamada main. Para crear otra con el nombre de test (como el equivalente de git branch test), necesitarías crear un archivo llamado test dentro de .git/refs/heads, y el contenido de ese archivo sería el mismo hash de la confirmación al que apunta la rama main.

test branchSi usas git log, puedes ver que esto en sí es el caso – ambos main y test apuntan a esta confirmación:

git log after creating test branch(Nota: si ejecutas este comando y no ves una salida válida, podrías haber escrito algo más que el hash de la confirmación en .git/refs/heads/test.)
Siguiente, cambiar a nuestra rama creada recientemente (el equivalente de git checkout test). ¿Cómo harías eso? Intenta responderte a ti mismo antes de que nos movamos al siguiente párrafo.
Para cambiar la rama activa, debería cambiar el HEAD a que apunte a tu nueva rama:

test by changing HEADComo puedes ver, git status confirma que HEAD ahora apunta a test, el cual es, por lo tanto, la rama activa.
Ahora puedes usar los comandos que ya has usado en el capítulo anterior para crear otro archivo y agregarlo al índice:

Siguiendo los comandos de arriba, tu:
- Creas un blob con el contenido de
Another file(usandogit hash-object). - Agregas al índice con el nombre de
another_file.txt(usandogit update-index). - Creas un archivo correspondiente en el disco con el contenido del blob (usando
git cat-file -p). - Creas un objeto árbol representando al índice (usando
git write-tree).
Ahora es tiempo de crear una confirmación que referencie a este árbol. Esta vez, también deberías especificar el padre de esta confirmación – el cual debería ser la confirmación anterior. Especificas el padre usando el argumento -p de git commit-tree:

Hemos creado una confirmación, con un árbol así también como un padre, como puedes ver:

¿git log nos mostrará la nueva confirmación?

git log after creating "Commit 2"Como puedes ver, git log no nos muestra nada nuevo. ¿Por qué es eso?
Recuerda que git log rastrea las ramas para encontrar confirmaciones relevantes para mostrar. Nos muestra ahora test y la confirmación a la que apunta, y también nos muestra a main el cual apunta a la misma confirmación.
Así es – necesitas hacer que test apunte al nuevo objeto de confirmación. Puedes hacer eso cambiando el contenido de .git/refs/heads/test:
echo 22267a945af8fde78b62ee7f705bbecfdd276b3d > .git/refs/heads/test
Y ahora si ejecutas git log:
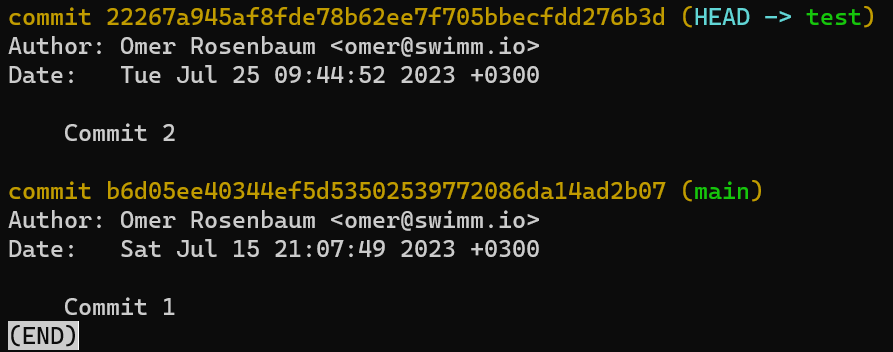
git log after updating test branch¡Funcionó!
git log va al HEAD, el cual le dice a Git que vaya a la rama test, el cual apunta a la confirmación 222..3d, el cual se enlaza a su confirmación padre b6d..07.
Admira la belleza de Git 😊
Al inspeccionar la carpeta de tu repositorio, puedes ver que tienes seis objetos distintos en la carpeta .git/objects - estos son los dos blobs que creaste (uno para awesome.txt y uno para file.txt), dos objetos de confirmación ("Commit 1" y "Commit 2"), y los tres objetos - cada uno apuntado por uno de los objetos de confirmación.
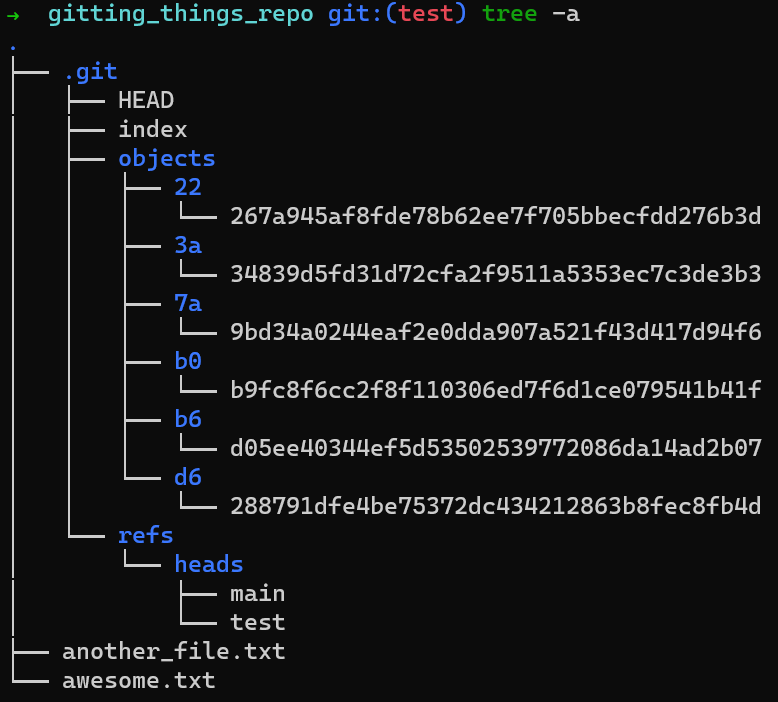
También tienes a .git/HEAD que apunta a la rama o confirmación activa, y dos ramas - dentro de .git/refs/heads.
Recapitulación - Cómo trabajar con las ramas en Git – Por debajo
En este capítulo entendiste cómo trabajan realmente las ramas en Git.
Las cosas principales que cubrimos:
- Una rama es un archivo en la carpeta
.git/refs/heads, donde el contenido del archivo es una valor SHA-1 de una confirmación. - Para crear una nueva rama, Git simplemente crea un nuevo archivo en la carpeta
.git/refs/headscon el nombre de la rama - por ejemplo,.git/refs/heads/my_branchpara la ramamy_branch. - Para cambiar la rama activa, Git modifica el contenido de
.git/HEADpara referirse a la nueva rama activa..git/HEADtambién podría apunta a un objeto de confirmación directamente. - Cuando se confirma usando
git commit, Git crea un objeto de confirmación, y también mueve la rama actual (eso es, el contenido del archivo en.git/refs/heads) a que apunte al objeto de confirmación recientemente creado.
Parte 1 - Resumen
Esta parte te introdujo lo interno de Git. Empezamos cubriendo los objetos básicos – blobs, árboles, y confirmaciones.
Aprendiste que un blob contiene el contenido de un archivo. Un árbol es un listado de directorios, conteniendo blobs y/o sub árboles. Una confirmación es una copia instantánea de nuestro directorio de trabajo, con algunos meta datos tales como el tiempo o el mensaje de confirmación.
Aprendiste sobre las ramas, viendo que no son más que una referencia nombrada a una confirmación.
Aprendiste el proceso de registrar cambios en Git, y que involucra el directorio de trabajo, un directorio que tiene un repositorio al que se asocia, el área de preparación (índice) el cual contiene el árbol para la próxima confirmación, y el repositorio, el cual es una colección de confirmaciones y referencias.
Clarificamos cómo estos términos se relacionan a los comandos de Git que conocemos al crear un nuevo repositorio y confirmando un archivo usando los comandos bien conocidos git init, git add y git commit.
Luego creaste un nuevo repositorio desde cero, usando echo y comandos de bajo nivel tales como git hash-object. Creaste un blob, le agregaste al índice, creaste un objeto de árbol representando al índice, e inclusive creaste un objeto de confirmación apuntando a ese árbol.
También fuiste capaz de crear y cambiar entre ramas modificando los archivos directamente. ¡Felicitaciones para aquellos que lo intentaron por sí mismos!
Todo junto ya, después de seguirme en esta parte, deberías sentir que has profundizado tu entendimiento de lo que está pasando por debajo cuando trabajas con Git.
La próxima parte explorarás diferentes estrategias para integrar cambios cuando se trabaja en diferentes ramas en Git - específicamente, merge y rebase.
Parte 2 - Ramificando e Integrando Cambios
Capítulo 6 - Diffs y Parches
En la parte 1 aprendiste cómo funciona Git por detrás, los diferentes objetos de Git, y cómo crear un repo desde cero.
Cuando los equipos trabajan con Git, introducen secuencias de cambios, usualmente en ramas, y luego necesitan combinar diferente historiales de cambios juntos. Para realmente entender cómo se logra esto, deberías aprender cómo trata Git a los diffs y a los parches. Luego aplicarás tus conocimientos para entender el proceso de merge y rebase.
Muchos de los procesos interesantes de Git como fusión, rebasing, o inclusive confirmar están basados en los diffs y parches. Los desarrolladores trabajan con diffs todo el tiempo, estés usando Git directamente o basándote en la vista diff del IDE. En este capítulo, aprenderás cómo son los diffs y parches, su esctructura, y cómo aplicar parches.
Como recordatorio del capítulo de Objetos de Git, una confirmación es una copia instantánea del árbol de trabajo en un cierto punto en el tiempo, además de algunos metadatos.
Aún así, es realmente difícil entender las confirmaciones individuales al mirar el árbol entero de trabajo. En sí, es más útil mirar cuán diferente es una confirmación de su confirmación padre, eso es, la diff entre estas confirmaciones.
Así que, ¿a qué me refiero cuando digo "diff"? Empecemos con algo de historia.
La historia de diff de Git
El diff de Git está basado en la utilidad diff de sistemas UNIX. diff fue desarrollado a principios de los '70 en el sistema operativo Unix. La primer versión lanzada se envió con la Quinta Edición de Unix en 1974.
git diff es un comando que toma dos entradas, y calcula la diferencia entre ellos. Las entradas pueden ser confirmaciones, pero también archivos, e inclusive archivos que nunca han sido introducidos al repositorio.

Esto es importante - git diff calcula la diferencia entre dos cadenas, el cual la mayor de las veces llega a consistir en código, pero no necesariamente.
Tiempo de manos a la obra
Como siempre, se te anima a que ejecutes los comandos tu mismo al leer este capítulo. A menos que se diga otra cosa, usaré el siguiente repositorio:
https://github.com/Omerr/gitting_things_repo.git
Lo puedes clonar localmente y tener el mismo punto de comienzo que estoy usando para este capítulo.
Considera este archivo de texto corto en mi máquina, llamado file.txt, el cual consiste de 6 líneas:
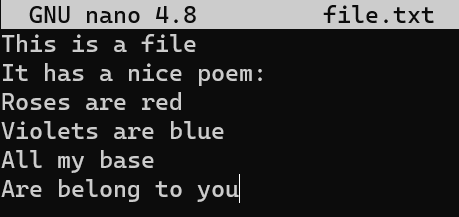
file.txt consists of six linesAhora, modifica este archivo un poco. Quita la segunda línea, e inserta una nueva línea como la línea cuatro. Agrega un signo de admiración (!) al final de la última línea, así obtienes este resultado:
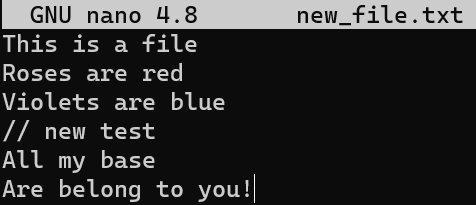
file.txt, we get different six linesGuarda este archivo con un nuevo nombre, new_line.txt.
Ahora puedes ejecutar git diff para calcular la diferencia entre los archivos así:
git diff --no-index file.txt new_file.txt
(Explicaré el argumento --no-index de este comando más tarde. Por ahora es suficiente saberlo para que nos permita comparar dos archivos que no son partes de un repositorio de Git.)
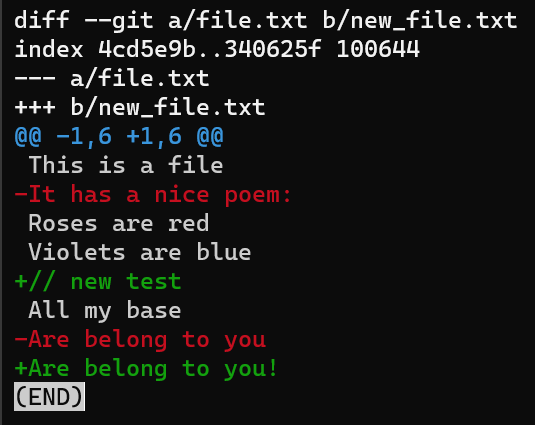
git diff --no-index file.txt new_file.txtLa salida de git diff muestra bastante cosas.
Enfócate en la parte empezando con This is a file. Puedes ver que la línea agregada (// new test) es precedida por un signo +. La línea eliminada es precedida por un símbolo -.
Curiosamente, fíjate que Git ve a la línea modificada como una secuencia de dos cambios - borrar una línea y agregar una nueva. Así que el parche incluye eliminar la última línea, y agregar una nueva línea que es igual a esa línea, con la suma de un !.

+, deletion lines by -, and modification lines are sequences of deletions and additionsAhora sería bueno discutir los términos "patch" y "diff". Estos dos son usados con frecuencia indistintamente, aunque hay una distinción, al menos históricamente.
Un diff muestra las diferencias entre dos archivos, o copias instantáneas, y puede ser bastante mínimo en hacerlo así. Un patch (parche) es una extensión de un diff, aumentado con más información tales como líneas de contexto y nombre de archivos, el cual le permite ser aplicado más ampliamente. Es un documento de texto que describe cómo alterar un archivo existente o base de código.
En estos días, el programa diff de Unix, y git diff, pueden producir parches de varios tipos.
Un parche es una representación compacta de las diferencias entre dos archivos. Describe cómo convertir un archivo en otro.
En otras palabras, si aplicas las "instrucciones" producidas por git diff en file.txt - eso es, quitar la segunda línea, insertar // new test como la cuarta línea, quitar la última línea, y agregar una línea con el mismo contenido y ! - tendrás el contenido de new_file.txt.
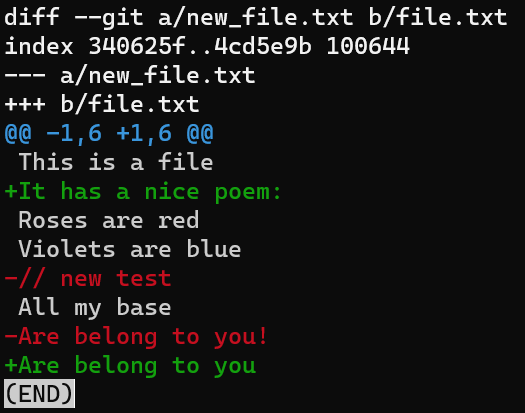
Otra cosa importante a notar es que un parche es asimétrico: el parche de file.txt a new_file.txt no es el mismo que el parche para la otra dirección. Generar un parche entre new_file.txt y file.txt, en este orden, significaría exactamente las instrucciones opuestas que antes - agregar la segunda línea en vez de quitarla, y así sucesivamente.

Inténtalo:
git diff --no-index new_file.txt file.txt
El formato del parche usa contexto, así también como números de líneas, para localizar diferentes regiones de archivos. Esto permite a un parche ser aplicado a alguna versión más antigua o más reciente de la primera línea a aquel del que se derivó, siempre y cuando el programa que se aplica aún pueda localizar el contexto del cambio. Veremos cómo son usados exactamente.
La Estructura de un Diff
Es tiempo de indagar más profundamente.
Genera un diff de file.txt a new_file.txt nuevamente, y considera la salida más cuidadosamente:
git diff --no-index file.txt new_file.txt
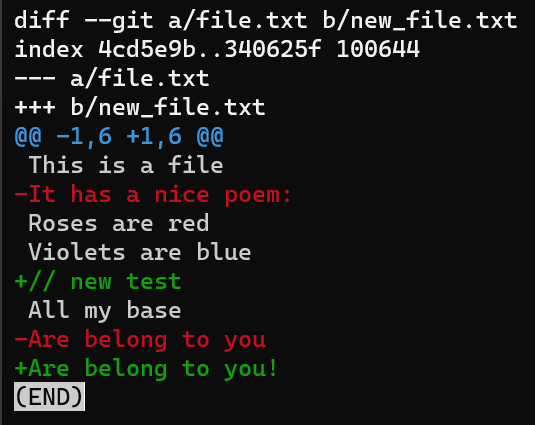
git diff --no-index file.txt new_file.txtLa primer línea introduce los archivos comparados. Git siempre le da a un archivo el nombre de a, y al otro el nombre de b. Así que en este caso file.txt se llama a, donde new_file.txt se llama b.
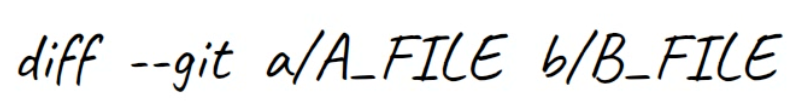
diff's output introduces the files being comparedLuego la segunda línea, comenzando con index, incluye los SHAs del blob de estos archivos. Así que aunque en nuestro caso inclusive no se guardan dentro de un repo de Git, Git muestra sus valores SHA-1 correspondientes.
El tercer valor en esta línea, 100644, es el "modo bits", indicando que esto es un archivo "regular": no ejecutable y no es un enlace simbólico.
El uso de dos puntos (..) aquí entre los SHAs del blob es sólo como un separador (a diferencia de otros casos donde se usa dentro de Git).
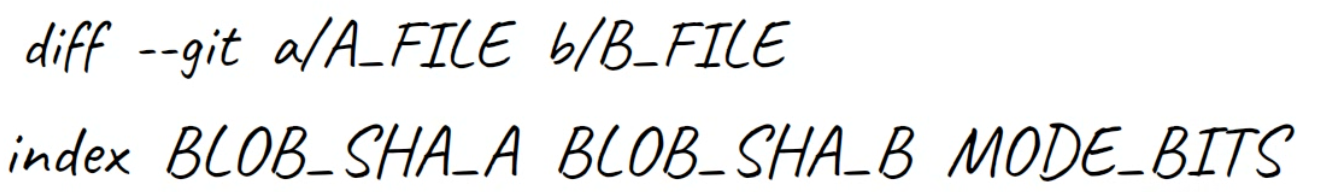
diff's output includes the blob SHAs of the compared files, as well as the mode bitsOtras líneas de encabezado pueden indicar el modo bits antiguo y nuevo si han cambiado, nombres de archivos antiguos y nuevos si los archivos fueron renombrados, y así sucesivamente.
Los SHAs del blob (también llamados "blob IDs") son útiles si este parche luego se aplica por Git al mismo proyecto y hay conflictos al aplicarse. Entenderás mejor qué significa esto cuando aprendas sobre las fusiones en el próximo capítulo.
Luego de los IDs del blob, tenemos dos líneas: una comenzando con signos -, y los otros comenzando con signos +. Este es el encabezado "diff unificado" tradicional, de nuevo mostrando los archivos siendo comparados y la dirección de los cambios: signos - muestra líneas en la versión A que faltan de la versión B, y signos - muestra líneas que faltan en la versión A pero que están presentes en el B.
Si el parche de este archivo estuviera siendo agregado o eliminado en su totalidad, entonces uno de estos serían /dev/null para señalar eso.
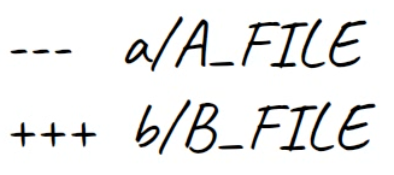
- signs show lines in the A version but missing from the B version, and + signs, lines missing in A version but present in BConsidera el caso donde eliminas un archivo:
rm awesome.txt
Y luego usa git diff:
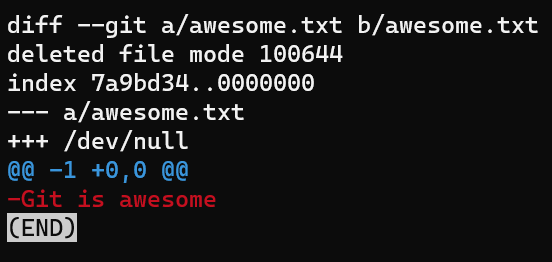
git diff's output for a deleted fileLa versión A, representando el estado del índice, es actualmente awesome.txt, comparado al directorio de trabajo donde este archivo no existe, así que es /dev/null. Todas las líneas son precedidas por signos - ya que existen solamente en la versión A.
Por ahora, deshace la eliminación (más sobre deshaciendo cambios en la Parte 3):
git restore awesome.txt
Volviendo al diff con el que comenzamos:
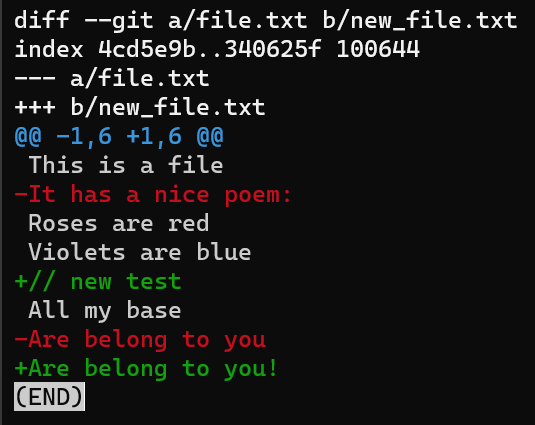
git diff --no-index file.txt new_file.txtDespués de este encabezado diff unificado, llegamos a la parte principal del diff, consistiendo de "secciones de diferencia", también llamados "hunks" o "chunks" en Git. Fíjate que estos términos son usados indistintamente, y podrías encontrarte con uno de ellos en la documentación y tutoriales de Git, así también como código fuente de Git.
Cada hunk comienza con una sola línea, comenzando con dos signos @. Estos signos son seguidos en la mayoría de veces por cuatro números, y luego un encabezado para el chunk - el cual es una suposición educada por Git. Usualmente, incluirá el comienzo de una función o una clase, cuando fuese posible.
En este ejemplo no incluye nada ya que este es un archivo de texto, así que considera otro ejemplo por un momento:
git diff --no-index example.py example_changed.py
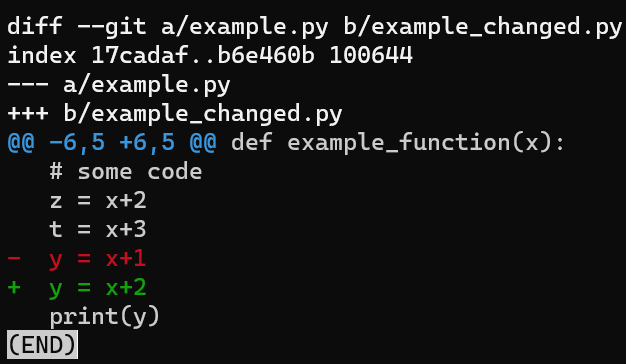
En la imagen de arriba, el encabezado del hunk incluye el comienzo de la función que incluye las líneas cambiados - def example_function(x).
De vuelta a nuestro ejemplo previo:
Después de dos signos @, encontrarás cuatro números:
Los primeros números son precedidos por un signo - ya que se refieren a file A. El primer número representa el número de línea correspondiente a la primer línea en file A a la que este hunk se refiere. En el ejemplo de arriba, es 1, lo que significa que la línea This is a file corresponde al número de línea 1 en la versión de file A.
Este número es seguido por una coma (,), y luego el número de líneas del que este chunk consiste en el file A. Este número incluye todas las líneas de contexto (las líneas precedidas con un espacio en el diff), o líneas marcadas con un signo -, ya que son parte de file A, pero no las líneas marcadas con un signo +, ya que no existen en file A.
En nuestro ejemplo, este número es 6, contando la línea de contexto This is a file, la línea - es It has a nice poem:, luego las tres líneas de contexto, y por último Are belong to you.
Como puedes ver, las líneas que comienzan con un caracter de espacio son líneas de contexto, lo que significa que aparecen como se muestran en ambos file A y file B.
Luego, tenemos un signo + para marcar a los dos números que se refieren a file B. Primero, está el número de línea correspondiente a la primer línea en file B, seguido del número de líneas del que este chunk consiste en file B.
Este número incluye todas las líneas de contexto, así también como las líneas marcadas con el signo +, ya que son parte de file B, pero no las líneas marcadas con un signo -.
Estos cuatros números son seguidos por dos signos @ adicionales.
Después del encabezado del chunk, obtenemos las líneas actuales - sean las líneas de contexto, - o +.
Típicamente y por defecto, un hunk comienza y termina con tres líneas de contexto. Por ejemplo, si modificas las líneas 4-5 en un archivo con diez líneas:
- Línea 1 - línea de contexto (antes de las líneas cambiadas)
- Línea 2 - línea de contexto (antes de las líneas cambiadas)
- Línea 3 - línea de contexto (antes de las líneas cambiadas)
- Línea 4 - línea cambiada (antes de las líneas cambiadas)
- Línea 5 - otra línea cambiada
- Línea 6 - línea de contexto (después de las líneas cambiadas)
- Línea 7 - línea de contexto (después de las líneas cambiadas)
- Línea 8 - línea de contexto (después de las líneas cambiadas)
- Línea 9 - esta línea no será parte del hunk
Así que por defecto, cambiar las líneas 4-5 resulta en un hunk consistiendo de las líneas 1-8, eso es, tres líneas antes y tres líneas después de las líneas modificadas.
Si ese archivo no tiene nueve líneas, sino seis líneas - entonces el hunk contendrá solamente una línea de contexto después de las líneas cambiadas, y no tres. De forma similar, si cambias la segunda línea de un archivo, entonces habría solamente una línea de contexto antes de las líneas cambiadas.

git diffCómo producir diffs
El último ejemplo que consideramos muestra un diff entre dos archivos. Un solo archivo parche puede contener las diferencias para cualquier número de archivos, y git diff produce diffs para todos los archivos alterados en el repositorio en un solo parche.
Frecuentemente, verás la salida de git diff mostrando dos versiones del mismo archivo y la diferencia entre ellos.
Para demostrar, considera el estado en otra rama llamada diffs:
git checkout diffs
De nuevo, te animo a ejecutar los comandos conmigo - asegúrate de clonar el repositorio de
https://github.com/Omerr/gitting_things_repo.git
En el estado actual, el directorio activo es un repositorio de Git, con una estado limpio:

git statusToma un archivo existente, my_file.py:
my_file.pyY cambia la segunda línea de print('An example function!') a print('An example function! And it has been changed!'):
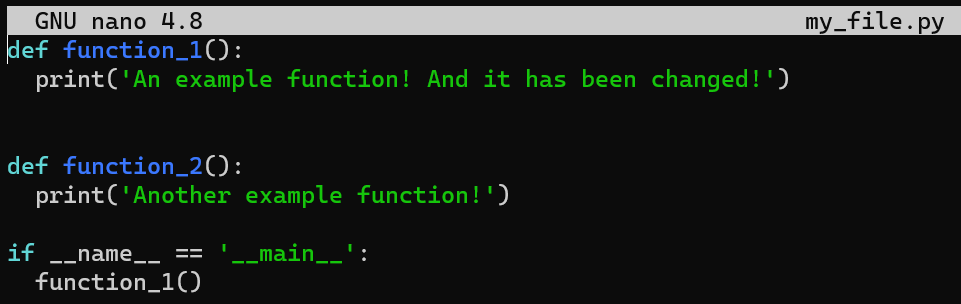
my_file.py after modifying the second lineGuarda tus cambios, pero no lo pongas en el área de preparación o no lo confirmes. Luego, ejecuta git diff:
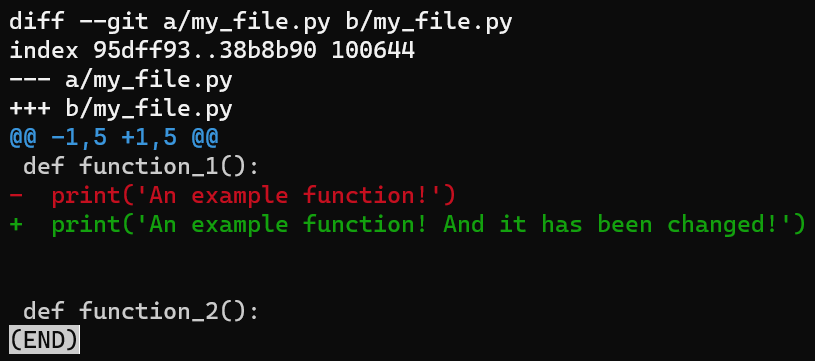
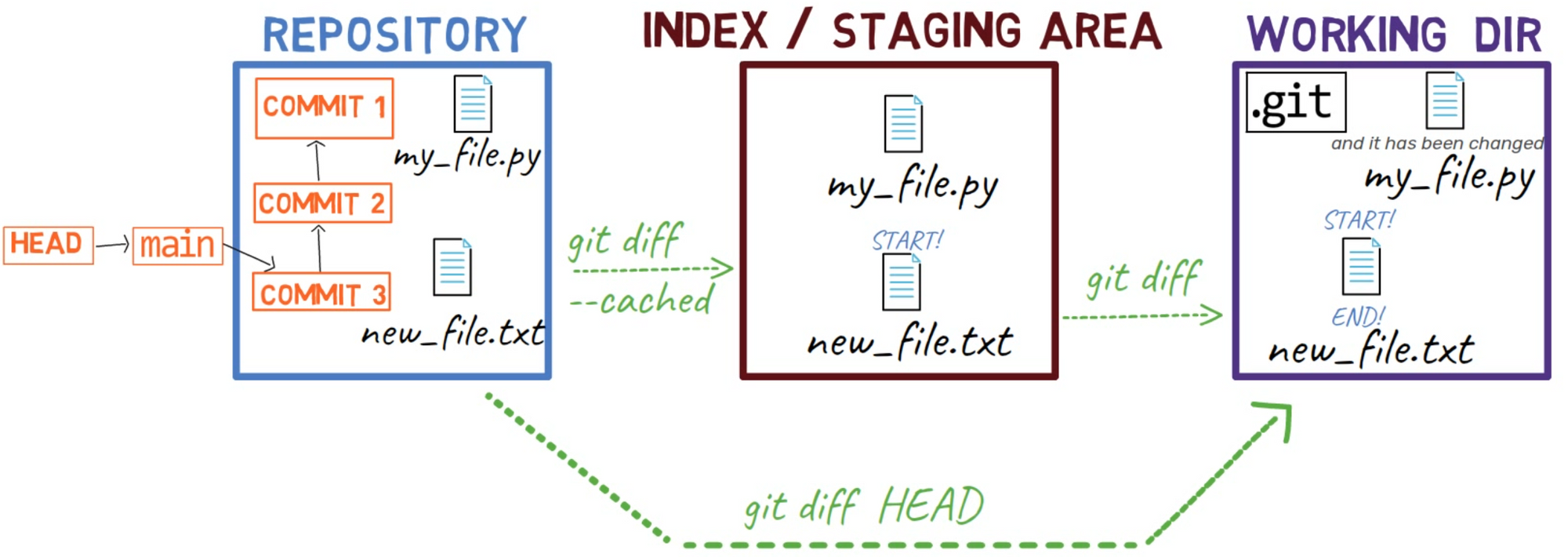
git diff for my_file.py after changing itLa salida de git diff muestra la diferencia entre las versiones de my_file.py en el área de preparación, el cual en este caso es el mismo que la última confirmación (HEAD), y la versión en el directorio de trabajo.
Cubrí los términos "directorio de trabajo", "área de preparación", y "confirmación" en el capítulo de objetos de Git, así que échale un vistazo en caso que te gustaría refrescar tu memoria. Como un recordatorio, los términos "área de preparación" e "índice" son intercambiables, y ambos son ampliamente usados.

HEADPara ver la diferencia entre el directorio de trabajo y el área de preparación, usa git diff, sin ningún argumento adicional.

git diff shows the difference between the staging area and the working directoryComo puedes ver, git diff aquí lista file A y file B apuntando a my_file.py. file A aquí se refiere a la versión de my_file.py en el área de preparación, donde file B se refiere a su versión en el directorio de trabajo.
Fíjate que si modificas my_file.py en un editor de texto, y no guardas el archivo, entonces git diff no estará al tanto de los cambios que has hecho. Esto se debe a que no han sido guardados en el directorio de trabajo.
Podemos proveer unos pocos cambios a git diff para obtener el diff entre el directorio de trabajo y una confirmación específica, o entre el área de preparación y la última confirmación, o entre dos confirmaciones, y así sucesivamente.
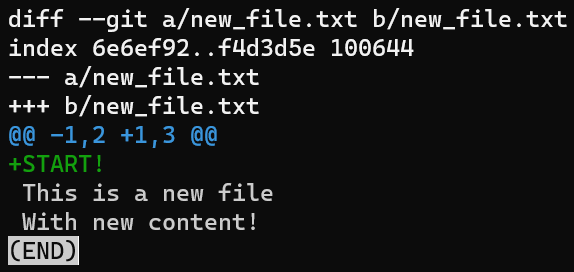
Primero crea un nuevo archivo, new_file.txt, y guárdalo:

new_file.txtActualmente el archivo está en el directorio de trabajo, y actualmente está sin seguimiento en Git.

Ahora pónlo en el área de preparación y confirma este archivo:
git add new_file.txt
git commit -m "Commit 3"
Ahora, el estado de HEAD es el mismo que el estado del área de preparación, así también como el árbol de trabajo:
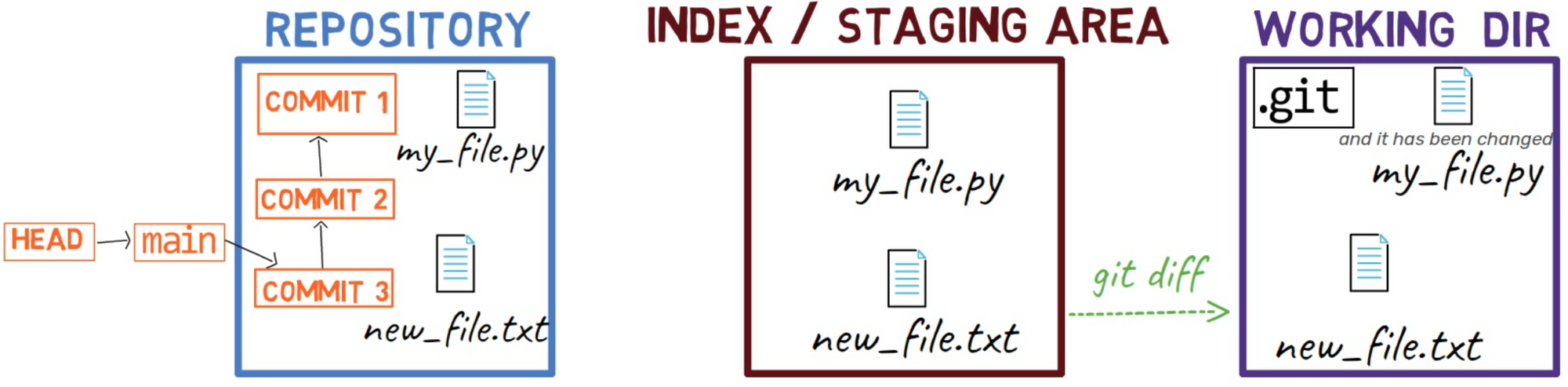
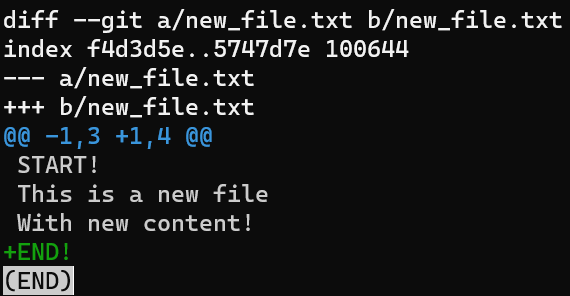
HEAD is the same as the index and the working dirLuego, edita new_file.txt agregando una nueva línea al principio y otra nueva línea al final:

new_file.txt by adding a line in the beginning and another in the endComo resultado, el estado es como sigue:
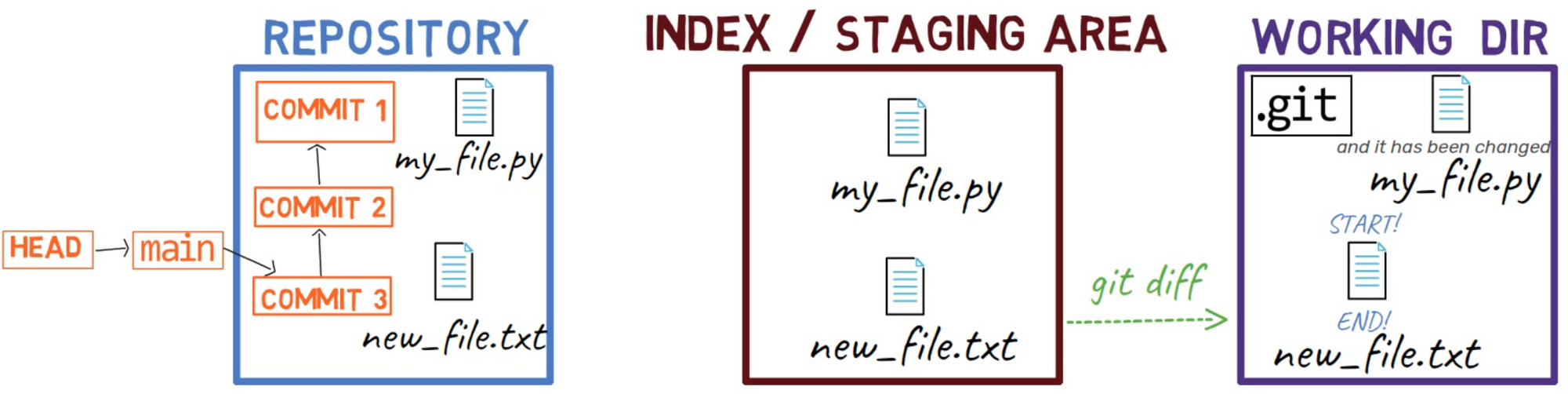
HEADUn lindo truco sería usar git add -p, el cual te permite dividir los cambios inclusive dentro de un archivo, y considerar cuáles te gustaría ponerlos en el área de preparación.
En este caso, agrega la primera línea al índice, pero no la última línea. Para hacer eso, puedes dividir el hunk usando s, luego acepta el primer hunk al área de preparación (usando y), y no la segunda parte (usando n).
Si no estás seguro qué significa cada letra, siempre puedes usar un ? y Git te dirá.
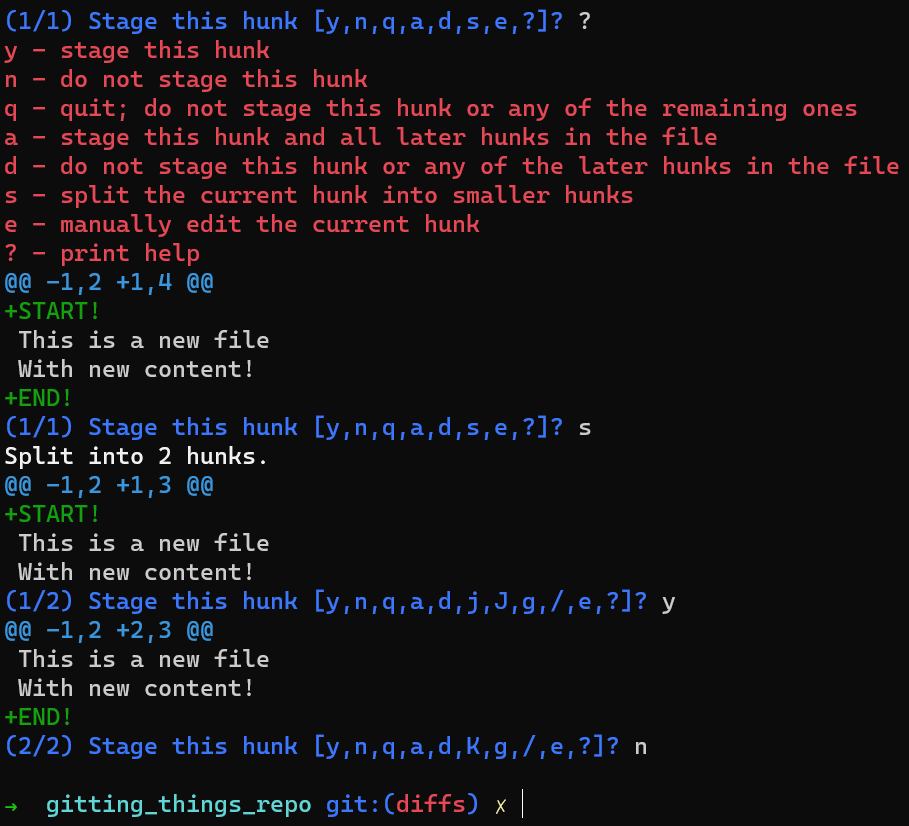
git add -p, you can stage only the first changeAsí que ahora el estado en HEAD están sin ninguna de esas nuevas líneas. En el área de preparación tienes la primer línea pero no la última línea, y en el directorio de trabajo tienes las dos nuevas líneas.
Si usas git diff, ¿qué sucederá?
git diff shows the difference between the index and the working dirBueno, como se dijo antes, obtienes el diff entre el área de preparación y el árbol de trabajo.
¿Qué sucede si quiere obtener el diff entre el HEAD y el área de preparación? Para eso, puedes usar git diff --cached:
git diff --cached shows the difference between HEAD and the index¿Y qué pasa si quieres la diferencia entre el HEAD y el árbol de trabajo? Para eso puedes ejecutar git diff HEAD:
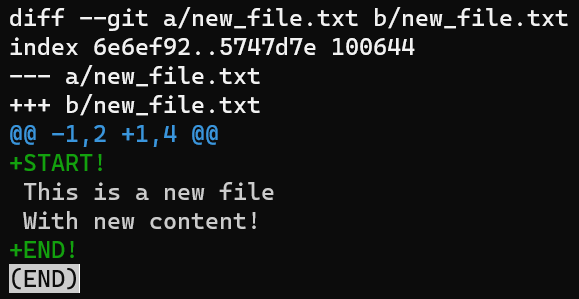
git diff HEAD shows the difference between HEAD and the working dirPara resumir los diferentes cambios para git diff que hemos visto hasta ahora, aquí hay un diagrama:
git diffComo un recordatorio, al principio de este capítulo usaste git diff --no-index. Con el conmutador --no-index, puedes comparar dos archivos que no son parte del repositorio - o de cualquier área de preparación.
Ahora, confirma los cambios que tienes en el área de preparación:
git commit -m "Commit 4"
Para observar el diff entre esta confirmación y su confirmación padre, puedes ejecutar el siguiente comando:
git diff HEAD~1 HEAD
git diff HEAD~1 HEADPor cierto, puedes omitir el 1 de arriba y escribir HEAD~, y obtener el mismo resultado. Usando 1 es la forma explícita para expresar que te refieres al primer padre de la confirmación.
Fíjate que escribir la confirmación padre aquí, HEAD~1, primero resulta en un diff mostrando cómo obtener de la confirmación padre a la confirmación actual. Por supuesto, podría también generar el diff en reversa al escribir:
git diff HEAD HEAD~1
git diff HEAD HEAD~1 generates the reverse patchPara resumir todos los diferentes cambios para git diff que cubrimos en esta sección, mira este diagrama:
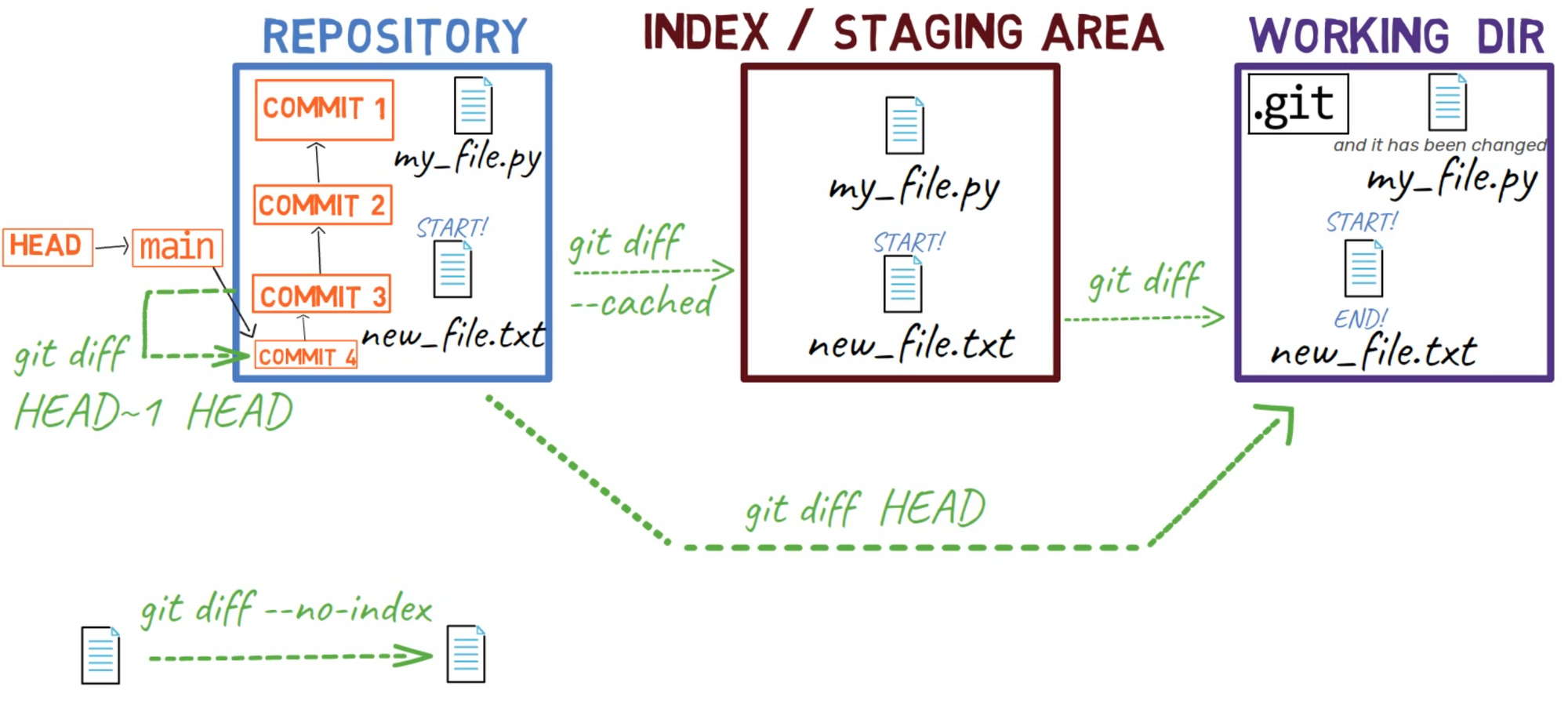
git diffUna forma corta de ver el diff entre una confirmación y su padre es usando git show, por ejemplo:
git show HEAD
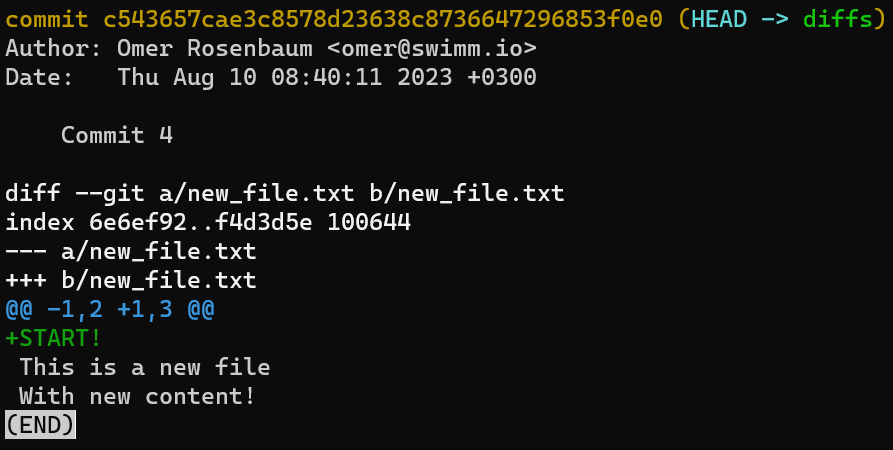
git show HEADEsto es lo mismo que escribir:
git diff HEAD~ HEAD
Ahora podemos actualizar nuestro diagrama:
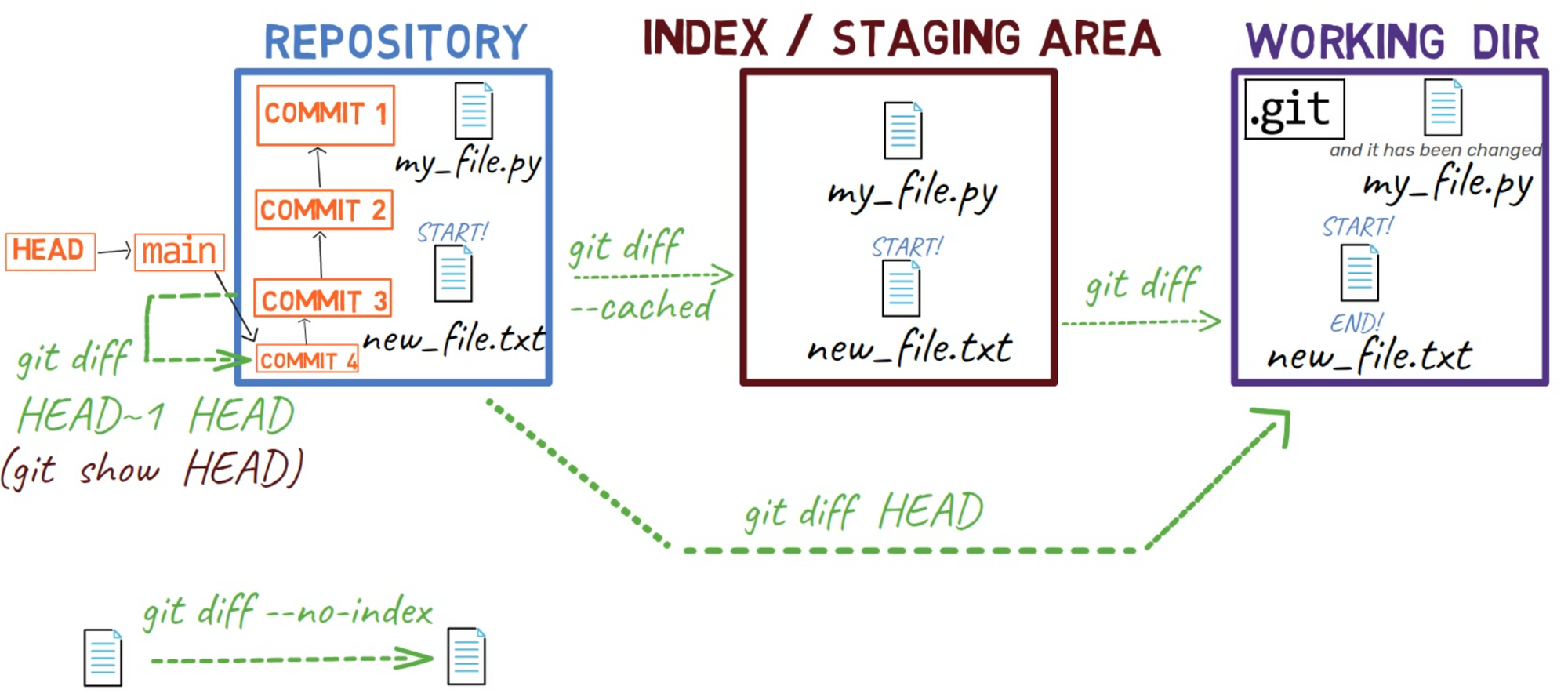
git diff HEAD~ HEAD is used to show the difference between commitsPuedes volver a este diagrama como una referencia cuando sea necesario.
Como un recordatorio, las confirmaciones de Git son copias instantáneas - del directorio de trabajo completo del repositorio, en un cierto punto en el tiempo. A pesar de todo, a veces no es útil considerar a una confirmación como una copia instantánea completa, sino más bien por los cambios que esta confirmación específica introdujo. En otras palabras, por el diff entre una confirmación padre a la confirmación siguiente.
Como aprendiste en el capítulo de Objetos de Git, Git almacena las copias instantáneas enteros. El diff es generado dinámicamente de los datos de la copia instantánea - al comparar los árboles principales de la confirmación y su padre.
Por supuesto, Git puede comparar cualquiera de las dos copias instantáneas en el tiempo, no sólo confirmaciones adyacentes, y también generar un diff de archivos que no son incluidos en un repositorio.
Cómo aplicar Parches
Al usar git diff puedes ver un parche que Git genera, y luego puedes aplicar este patch usando git apply.
Nota Histórica
En realidad, compartir parches solía ser la principal forma de compartir código al comienzo del código abierto. Pero ahora - virtualmente todos los proyectos se han movido a compartir confirmaciones de Git directamente a través de pull requests (llamados "merge requests - peticiones de fusión" en algunas plataformas).
El mayor problema con usar parches es que es difícil de aplicar un parche cuando tu directorio de trabajo no coincide con la confirmación previa del emisor. Perder el historial de la confirmación lo vuelve difícil para resolver conflictos. Entenderás mejor esto a medida que indagues más profundamente en el proceso de git apply, especialmente en el próximo capítulo donde cubrimos las fusiones.
Un Simple Parche
¿Qué significa aplicar un parche? ¡Es tiempo de intentarlo!
Toma la salida de git diff:
git diff HEAD~1 HEAD
Y almacénalo en un archivo:
git diff HEAD~1 HEAD > my_patch.patch
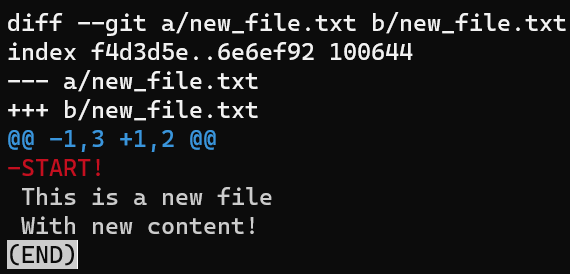
Usa reset para deshacer la última confirmación:
git reset --hard HEAD~1
No te preocupes del último comando - te lo explicaré en detalle en la Parte 3, donde discutimos deshacer cambios. En breve, nos permite "resetear" el estado a donde HEAD está apuntando, así también como el estado del índice y del directorio de trabajo. En el ejemplo de arriba, todos están puestos al estado de HEAD~1, o "Confirmación 3" en el diagrama.
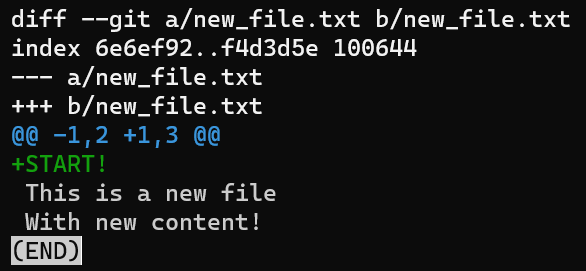
Así que después de ejecutar el comando reset, los contenidos del archivo son como sigue (el estado de "Confirmación 3"):
nano new_file.txt

new_file.txtY aplicarás este parche que recién has guardado:
nano my_patch.patch
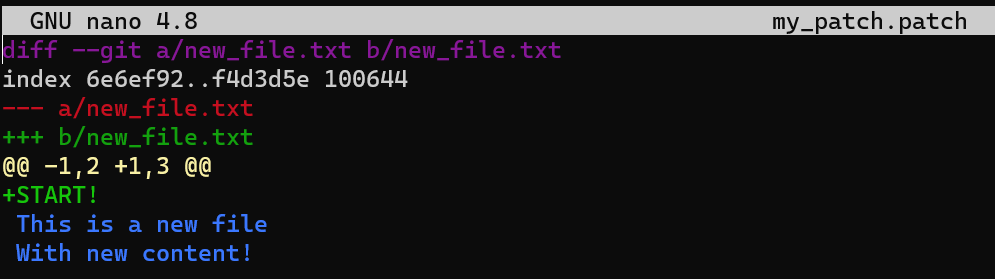
Este parche le dice a Git que encuentre las líneas:
This is a new file
With new content!
Esas líneas solían ser el número de línea 1 y número de línea 2 en new_file.txt, y agrega una línea con el contenido START! justo arriba de ellos.
Ejecuta este comando para aplicar el parche:
git apply my_patch.patch
Y como resultado, obtienes esta versión de tu archivo, justo como la confirmación que has creado antes:
nano new_file.txt

new_file.txt after applying the patchEntendiendo la Líneas de Contexto
Para entender la importancia de las líneas de contexto, considera un escenario más avanzado. ¿Qué sucede si los números de líneas han cambiado desde que creaste el archivo parche?
Para probar, comienza por crear otro archivo:
nano test.text
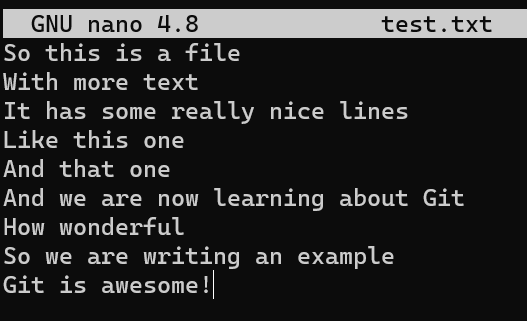
test.txtPónlo en el área de preparación y confirma este archivo:
git add test.txt
git commit -m "Test file"
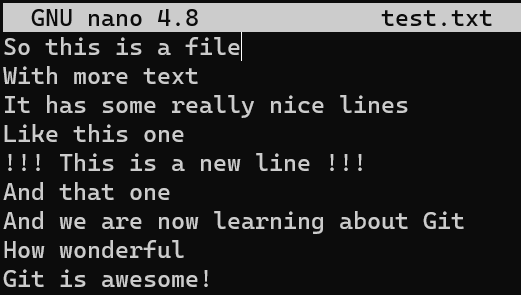
Ahora, cambia este archivo al agregar una nueva línea, y también eliminando la línea antes de la última:
test.txtObserva la diferencia entre la versión original del archivo y la versión incluyendo tus cambios:
git diff -- test.txt
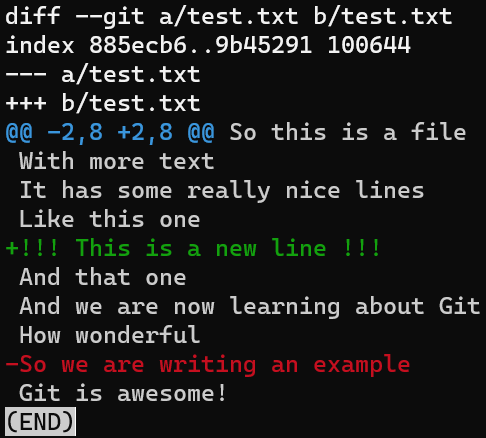
git diff -- test.txt(Usando --test.txt le dice a Git que ejecute el comando diff, tomando en consideración solamente a test.txt, así no obtienes el diff para otros archivos.)
Almacena este diff en un archivo parche:
git diff -- test.txt > new_patch.patch
Ahora, resetea tu estado a ese antes de introducir los cambios:
git reset --hard
Si llegaras a aplicar new_patch.patch ahora, simplemente funciona.
Ahora consideremos un caso más interesante. Modifica a test.txt nuevamente al agregar una nueva línea al principio:
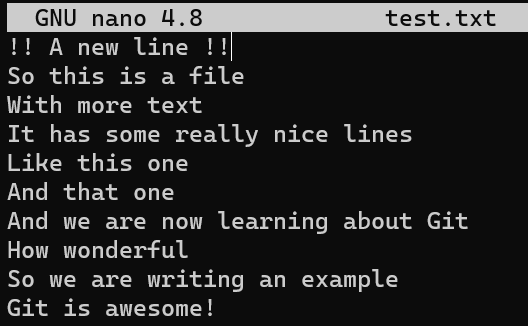
test.txtComo resultado, los números de líneas son diferentes de la versión original donde el parche ha sido creado. Considera el parche que creaste antes:
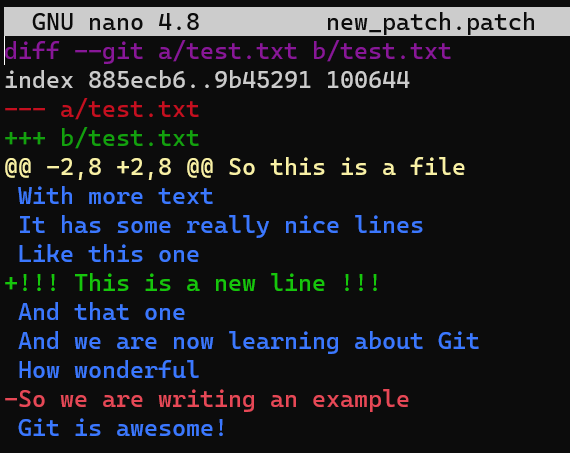
new_patch.patchAsume que la línea With more text es la segunda línea en test.txt, el cual no es más el caso. Así que... ¿funcionará git apply?
git apply new_patch.patch
¡Funcionó!
Por defecto, Git busca las 3 líneas de contexto antes y después de cada cambio introducido en el parche - como puedes ver, son incluidos en el archivo parche. Si tomas tres líneas antes y después de la línea agregada, y tres líneas antes y después de la línea eliminada (en realidad solamente una línea después, ya que no existen otras líneas) - llegas al archivo parche. Si todas estas líneas existen - entonces aplicar el parche funciona, inclusive si los números de línea cambiaron.
Resetea el estado de nuevo:
git reset --hard
¿Qué sucede si cambias una de las líneas de contexto? Intenta cambiando la línea With more text a With more text!:
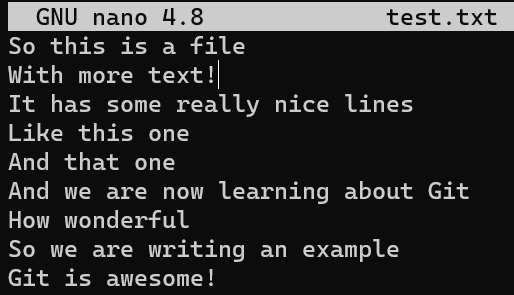
With more text!Y ahora:
git apply new_patch.patch

git apply doesn't apply the patchBueno, no. El parche no se aplica. Si no estás seguro por qué, o solo quieres entender mejor el proceso que Git está realizando, puedes agregar el argumento --verbose a git apply, así:
git apply --verbose new_patch.patch
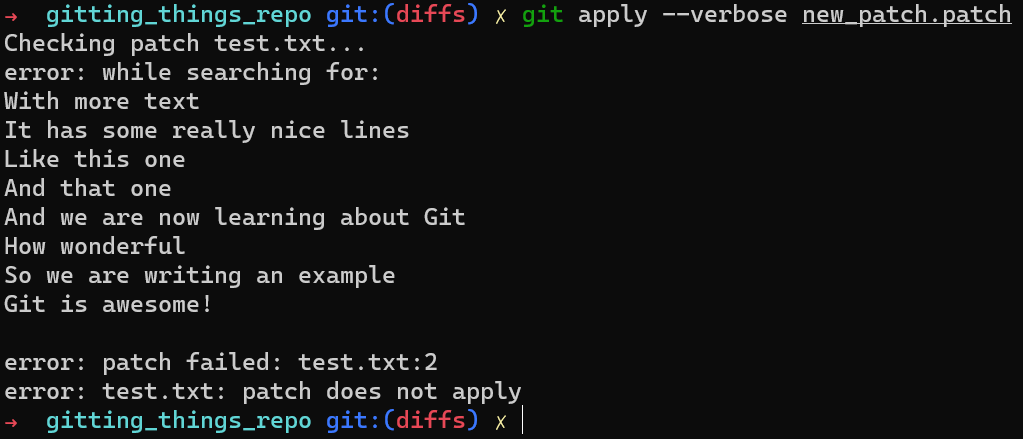
git apply --verbose shows the process Git is taking to apply the patchParece que Git buscó líneas del archivo, incluyendo la línea "With more text", justo antes de la línea "It has some really nice lines". Esta secuencia de líneas ya no existen en el archivo. Ya que Git no puede encontrar esta secuencia, no puede aplicar el parche.
Como se mencionó antes, por defecto, Git busca 3 líneas de contexto antes y después de cada cambio introducido en el parche. Si las tres líneas circundantes no existen, Git no puede aplicar el parche.
Le puedes pedir a Git que se base en menos líneas de contexto, usando el argumento -C. Por ejemplo, para pedir a Git que busque 1 línea de contexto circundante, ejecuta el siguiente comando:
git apply -C1 new_patch.patch
¡El parche se aplica!

git apply -C1 new_patch.patch¿Por qué es eso? Considera el parche nuevamente:
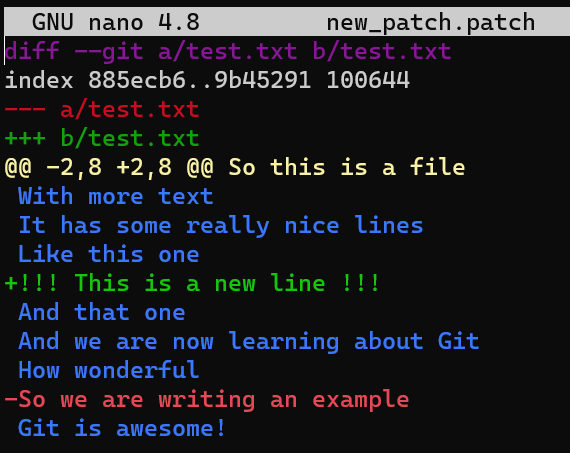
new_patch.patchCuando se aplica el parche con la opción -C1, Git está buscando las líneas:
Like this one
And that one
para agregar la línea !!!This is the new line!!! entre estas dos líneas. Estas líneas existen (e, importantemente, aparecen justo después de la otra). Como resultado, Git puede agregar la línea entre ellos con éxito, aunque los números de línea cambiaron.
De manera similar, Git buscaría las líneas:
How wonderful
So we are writing an example
Git is awesoome!
Ya que Git puede encontrar estas líneas, Git puede eliminar el del medio.
Si cambiamos una de estas líneas, digamos, cambiamos "How wonderful" a "How very wondeful", entonces Git no sería capaz de encontrar la cadena de arriba, y así el parche no se aplicaría.
Recapitulando - Git Diff y Patch
En este capítulo, aprendiste qué es un diff, y la diferencia entre un diff y un parche. Aprendiste cómo generar varios parches usando diferentes conmutadores para git diff. También aprendiste cómo luce la salida de git diff, y cómo se construye. Por último, aprendiste cómo se aplican los patches, y específicamente la importancia del contexto.
Entender los diff es un hito importante para entender muchos otros procesos dentro de Git - por ejemplo, fusionando o rebasing, los cuales exploraremos en los próximos capítulos.
Capítulo 7 - Entendiendo la Fusión de Git
Al leer este capítulo, vas a entender realmente git merge, una de las operaciones más comunes que ejecutarás en tus repositorios de Git.
¿Qué es un Merge (Fusión) en Git?
Fusionar es el proceso de combinar los cambios recientes de varias ramas en una sola nueva confirmación. Esta confirmación apunta a estas ramas.
De una forma, fusionar es el complemento de ramificación en control de versiones: una rama te permite trabajar de manera simultánea con otros en un conjunto particular de archivos, donde una fusión te permite luego combinar trabajos separados en ramas que difieren de una confirmación padre en común.
Muy bien, vamos poco a poco.
Recuerda que en Git, una rama es sólo un nombre que apunta a una confirmación única. Cuando pensamos sobre las confirmaciones como si estuvieran sólo "en" una rama específica, en realidad son accesibles a través de la cadena principal desde la confirmación a la que la rama está apuntando.
Eso es, si consideras este gráfico de confirmación:
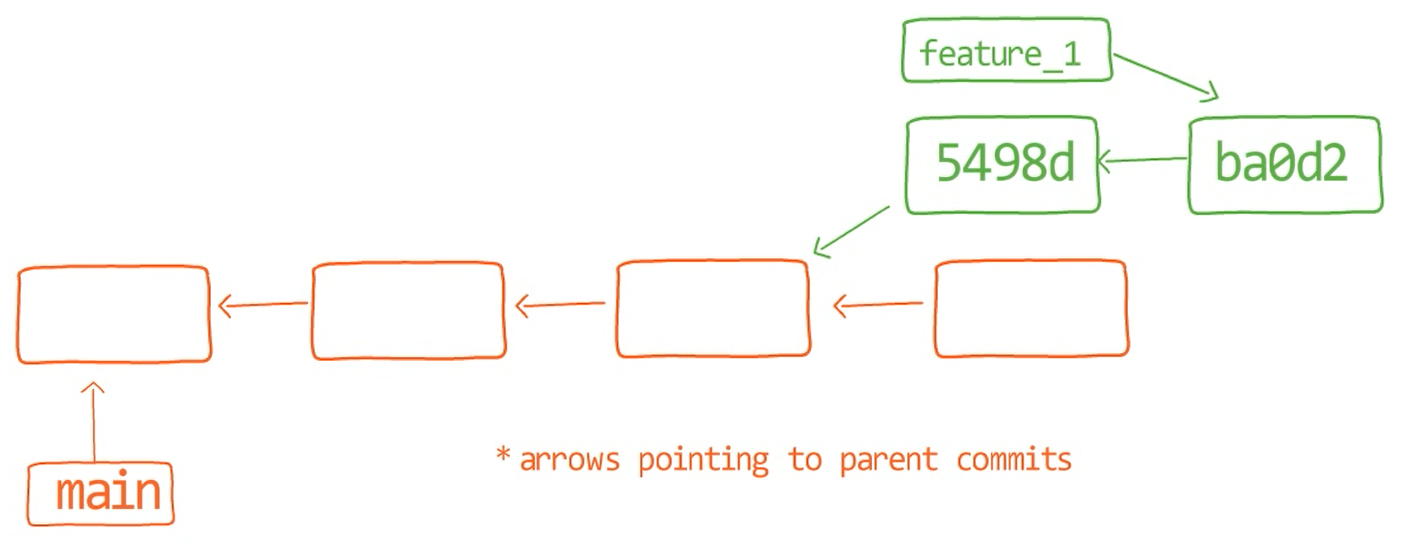
feature_1Ves la rama feature_1, el cual apunta a una confirmación con el valor de SHA-1 de ba0d2. Como en los capítulos previos, solamente escribo los primeros 5 dígitos del valor de SHA-1 para brevedad.
Fíjate que la confirmación 54a9d está también "en" esta rama, ya que es la confirmación antecesora de bad0d2. Si comienzas desde el puntero de feature_1, llegas a ba0d2, el cual luego apunta a 54a9d. Puedes continuar en la cadena de padres, y todas estas confirmaciones accesibles son considerados estar "en" el feature_1.
Cuando fusionas con Git, fusionas confirmaciones. Casi siempre, fusionamos dos confirmaciones al referirnos a ellos con los nombres de rama a los que apuntan. De esa forma decimos que "fusionamos ramas" - aunque por debajo, en realidad fusionamos confirmaciones.
Tiempo de manos a la obra
Para este capítulo, usaré el siguiente repositorio:
https://github.com/Omerr/gitting_things_merge.git
Como en capítulos previos, te animo a clonarlo localmente y tener el mismo punto de comienzo que estoy usando para este capítulo.
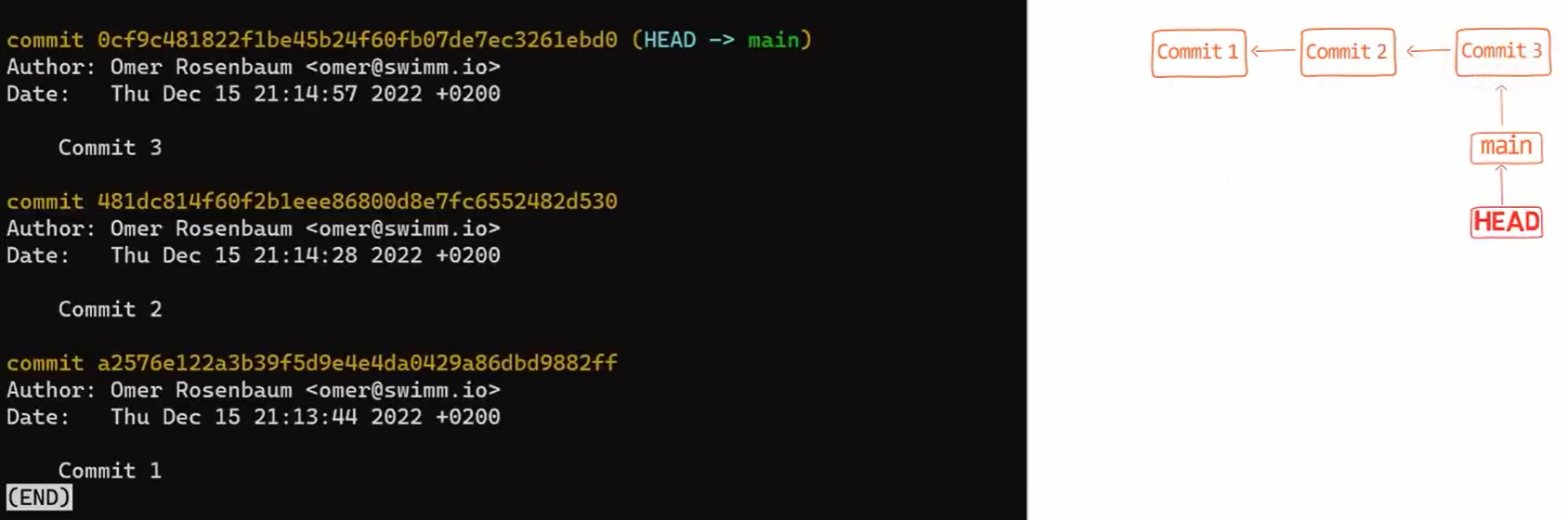
Muy bien, digamos que tenemos este simple repositorio aquí, con una rama llamada main, y unas pocas confirmaciones con los mensajes de confirmación de "Commit 1", "Commit 2", y "Commit 3":
Luego, crea una rama feature al escribir git branch new_feature:

git branchY cambia a HEAD para que apunte a esta nueva rama, usando git checkout new_feature (o git switch new_feature). Puedes ver la salida usando git log:
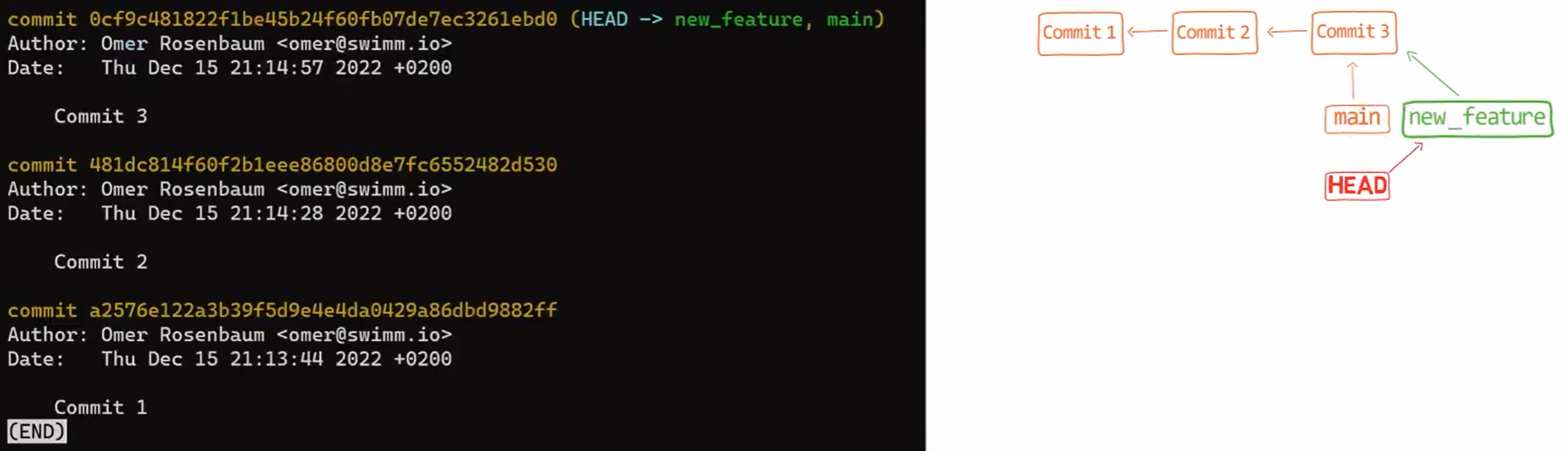
git log after using git checkout new_featureComo recordatorio, podrías también escribir git checkout -b new_feature, el cual crearía una nueva rama y cambiar el HEAD a que apunte a esta nueva rama.
Si necesitas un recordatorio sobre las ramas y cómo son implementados por debajo, por favor mira el capítulo 2. Sí, míralo. 😇
Ahora, en la rama new_feature, implementa una nueva característica. En este ejemplo, editaré un archivo que ya existe que luce así antes de editarlo:
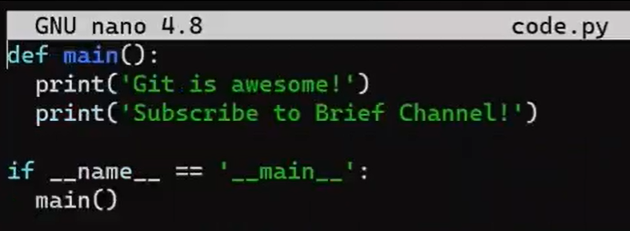
code.py before editing itY ahora lo editaré para que incluya una nueva función:
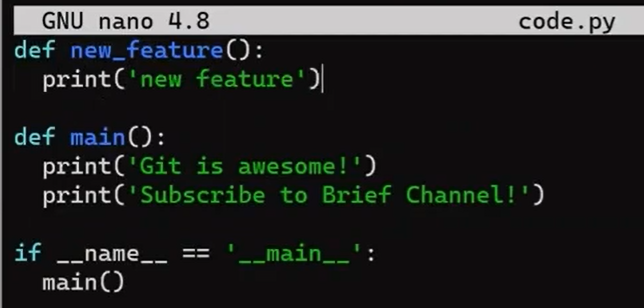
new_featureY afortunadamente, este no es un libro de programación, así que esta función es correcta 😇
Luego, colócalo en el área de preparación y confirma esta confirmación:
git add code.py
git commit -m "Commit 4"
Viendo al historial, tienes el branch new_feature, ahora apuntando a "Commit 4", el cual apunta a su antecesor, "Commit 3". La rama principal también está apuntando a "Commit 3".

¡Es tiempo de fusionar la nueva característica! Eso es, fusionar estas dos ramas, main y new_feature. O, en la jerga de Git, fusionar new_feature dentro de main. Esto significa fusionar "Commit 4" y "Commit 3". Esto es muy trivial, ya que después de todo, "Commit 3" es un ancestro de "Commit 4".
Verifica la rama principal (con git checkout main), y ejecuta la fusión usando git merge new_feature:
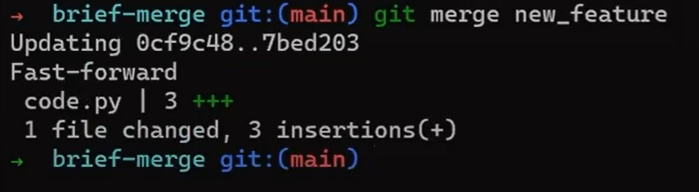
new_feature into mainYa que new_feature en realidad nunca difirió de main, Git podría realizar una fusión directa. Así que, ¿qué pasó aquí? Considera el historial:

Aunque usaste git merge, no hubo una fusión en sí aquí. En realidad, Git hizo algo muy sencillo - resetea la rama principal para que apunte a la misma confirmación como la rama new_feature.
En caso que no quieres que eso suceda, sino que quieres que Git realmente realice una fusión, podrías cambiar la configuración de Git, o ejecutar el comando de fusión con el argumento --no-ff.
Primero, deshace la última confirmación:
git reset --hard HEAD~1
Recordatorio: si esta forma de usar reset no te queda claro, no te preocupes - los cubriremos en detalle en la Parte 3. No es crucial para esta introducción de merge. Por ahora, es importante entender que básicamente deshace la operación de fusión.
Sólo para clarificar, ahora si verificas a new_feature nuevamente:
git checkout new_feature
El historial luciría igual como antes de la fusión:
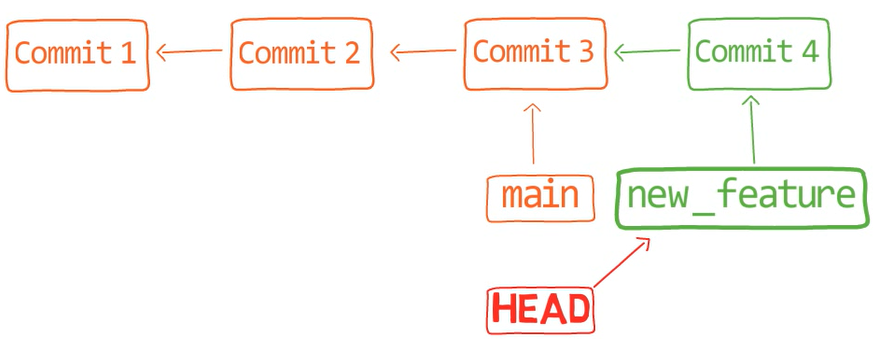
git reset --hard HEAD~1Luego, realiza la fusión con el argumento --no-fast-forward (en corto --no-ff):
git checkout main
git merge new_feature --no-ff
Ahora, si miramos el historial usando git lol:
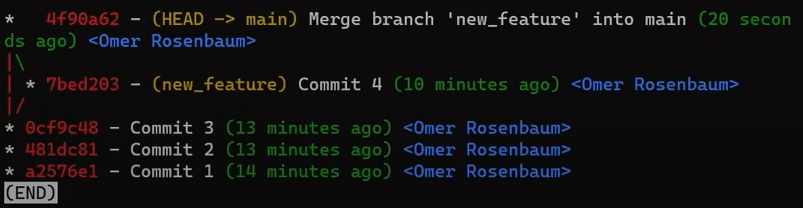
--no-ff flag(Recordatorio: git lol es un alias que agregué a Git para ver visiblemente el historial de una manera gráfica. Lo puedes encontrar, junto con los otros componentes de mi configuración, en la parte de Mi Configuración del capítulo de Introducción.)
Considera este historial, puedes ver que Git creó una nueva confirmación, una confirmación de fusión.
Si consideras esta confirmación un poco más de cerca:
git log -n1
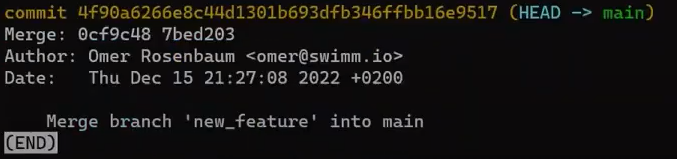
Verás que esta confirmación en realidad tiene dos padres - "Commit 4", el cual fue la confirmación a la que new_feature apuntó cuando ejecutaste git merge, y "Commit 3", el cual fue la confirmación a la que main apuntó.
Una confirmación de fusión tiene dos padres: las dos confirmaciones que fusionó.
La confirmación de fusión nos muestra el concepto de fusión bastante bien. Git toma dos confirmaciones, usualmente referenciados por dos ramas diferentes, y los fusiona juntos.
Después de la fusión, comenzaste el proceso desde main, estás todavía en main, y el historial de new_feature ha sido fusionado dentro de esta rama. Ya que comenzaste con main, luego "Commit 3", a la que apuntó main, es el primer antecesor de la confirmación de fusión, mientras que "Commit 4", la cual la fusionaste dentro de main, es el segundo antecesor de la confirmación de fusión.
Fíjate que empezaste en main cuando éste apuntaba a "Commit 3", y Git te ayudó bastante. Cambió el árbol de trabajo, el índice, y también el HEAD y creó un nuevo objeto de confirmación. Al menos cuando usas git merge sin el argumento --no-commit y cuando no es una fusión directa, Git hace todo eso.
Esto fue un caso super sencillo, donde las ramas que fusionaste no difirieron para nada. Pronto consideraremos casos más interesantes.
A propósito, puedes usar git merge para fusionar más de dos confirmaciones - en realidad, cualquier número de confirmaciones. Esto se hace raras veces, y para adherirnos al principio de practicidad de este libro, no lo profundizaremos.
Otra forma de ver a git merge es uniendo dos o más historiales de desarrollo juntos. Eso es, cuando fusionas, incorporas cambios desde las confirmaciones nombradas, desde el momento en que sus historiales difirieron de la rama actual, en la rama actual. Usé el término "rama" aquí, pero estoy enfatizando esto nuevamente - en realidad estamos fusionando confirmaciones.
Es tiempo de un Caso más Avanzado
Es tiempo de considerar un caso más avanzado, lo cual es probablemente el caso más común donde usamos git merge explícitamente - donde necesitas fusionar ramas que sí difieren uno del otro.
Supón que tenemos dos personas trabajando en este repo ahora, John y Paul.
John creó una rama:
git checkout -b john_branch
john_branchY John ha escrito una nueva canción en un nuevo archivo, lucy_in_the_sky_with_diamonds.md. Bueno, creo que John Lennon realmente no escribió en formato Markdown, o no usó Git para ese asunto, pero pretendamos que lo hizo para esta explicación.
git add lucy_in_the_sky_with_diamonds.md
git commit -m "Commit 5"
Mientras John estaba trabajando en esta canción, Paul también estaba escribiendo, en otra rama. Paul había comenzado desde main:
git checkout main
Y creó su propia rama:
git checkout -b paul_branch
Y Paul escribió su canción en un archivo llamado penny_lane.md. Paul puso en el área de preparación y confirmó este archivo:
git add penny_lane.md
git commit -m "Commit 6"
Así que ahora nuestro historial luce así - donde tenemos dos ramas distintas, que se ramifican desde main, con historiales distintos:
John está feliz con su rama (eso es, su canción), así que él decide fusionarlo en la rama main:
git checkout main
git merge john_branch
En realidad, este es una fusión directa, como hemos aprendido antes. Puedes validar eso al ver el historial (usando git lol, por ejemplo):
john_branch into main results in a fast-forward mergeA este punto, Paul también quiere fusionar su rama dentro de main, pero ahora una fusión directa ya no es relevante - hay dos diferentes historiales aquí: el historial de main y el de paul_branch. No es que paul_branch solamente agrega confirmaciones encima de la rama main o vice versa.
Ahora las cosas se ponen interesante. 😎😎
Primero, dejemos a Git que haga el trabajo duro por ti. Después de eso, entenderemos lo que en realidad está sucediendo por debajo.
git merge paul_branch
Considera este historial ahora:
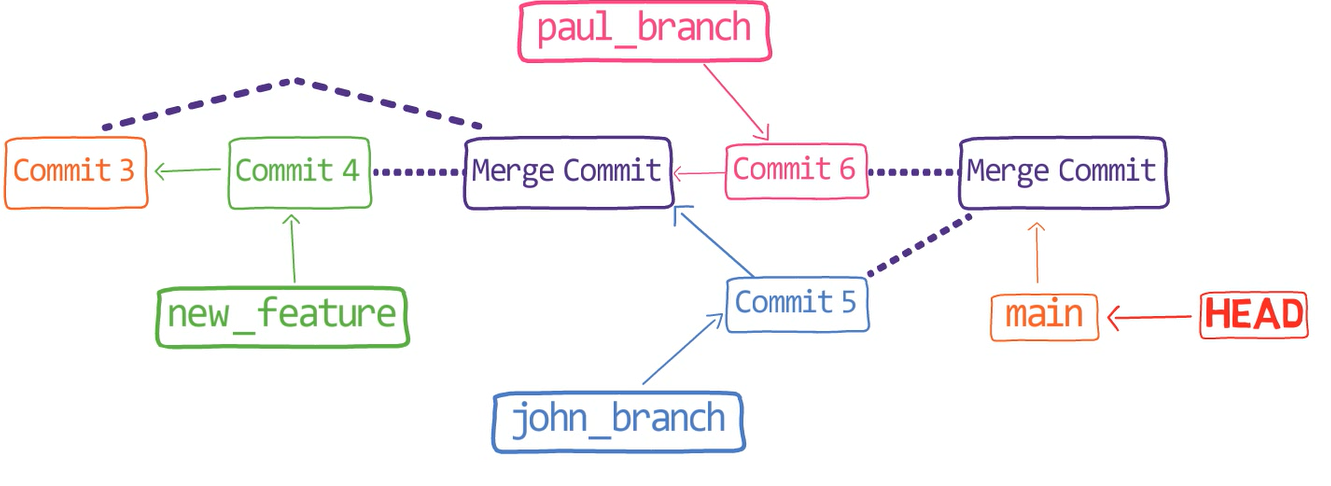
paul_branch, you get a new merge commitLo que tienes es una nueva confirmación, con dos antecesores - "Commit 5" y "Commit 6".
En el directorio de trabajo, puedes ver que la canción de John así también como la canción de Paul están ahí (si usas ls, verás ambos archivos en el directorio de trabajo).
Bien, Git realmente fusionó los cambios por ti. ¿Pero cómo hace que eso suceda?
Deshace la última confirmación:
git reset --hard HEAD~
Cómo realizar una Fusión de Tres Vías en Git
Es tiempo de entender lo que realmente está pasando por debajo. 😎
Lo que Git ha hecho aquí se le llama una fusión de 3 vías. Al delinear el proceso de una fusión de 3 vías, usaré el término "rama" para simplicidad, pero deberías recordar que podrías también fusionar dos (o más) confirmaciones que no son referenciados por una rama.
El proceso de fusión de 3 vías incluye estas etapas:
Primero, Git localiza el ancestro común de las dos ramas. Eso es, la confirmación común desde el cual las ramas de fusión difirieron más recientemente. Técnicamente, esto en realidad es la primer confirmación que es accesible desde ambas ramas. A esta confirmación entonces se le llama la base de fusión.
Segundo, Git calcula dos diffs - un diff de la base de fusión a la primer rama, y otro diff desde la base de fusión a la segunda rama. Git genera parches basados en esos diffs.
Tercero, Git aplica ambos parches a la base de fusión usando un algoritmo de fusión de 3 vías. El resultado es el estado de la nueva confirmación de fusión.

Así que, devuelta a nuestro ejemplo.
En el primer paso, Git mira desde ambas ramas - main y paul_branch - y atraviesa el historial para encontrar la primera confirmación que es accesible desde ambos. En este caso, este sería.. ¿cuál confirmación?
Correcto, la confirmación de fusión (el que tiene a "Commit 3" y "Commit 4" como sus predecesores).
Si no estás seguro, siempre puedes preguntarle a Git directamente:
git merge-base main paul_branch
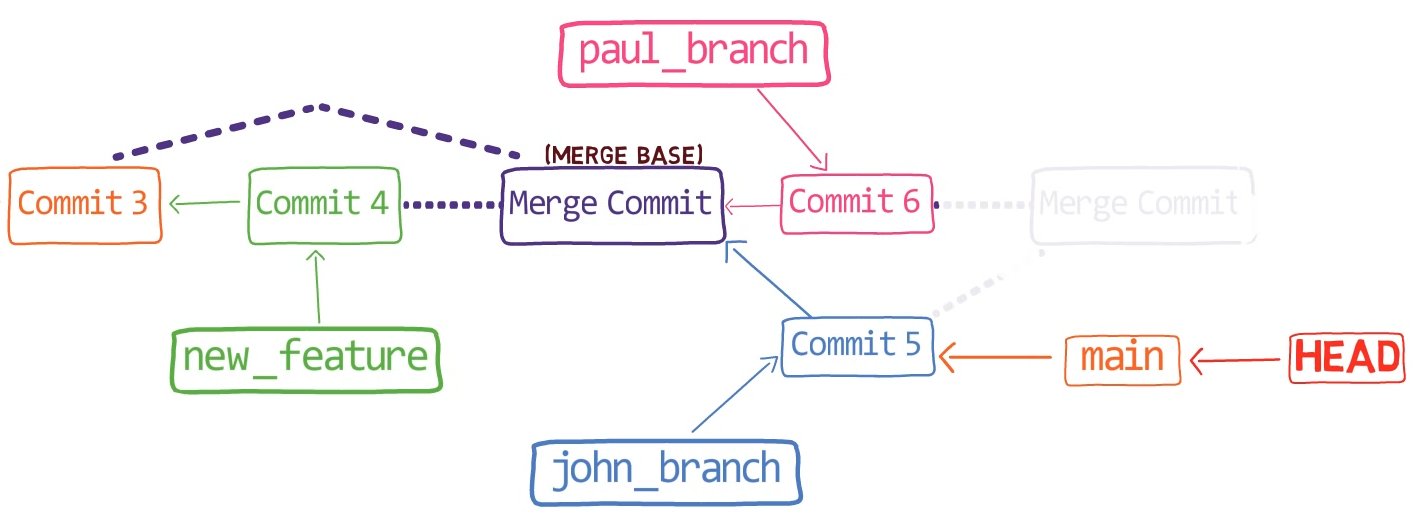
reset commandA propósito, este es el caso más común y sencillo, donde tenemos una única elección obvia para la base de fusión. En casos más complicados, podría haber múltiples posibilidades para una base de fusión, pero esto no está dentro de nuestro enfoque.
En el segundo paso, Git calcula las diferencias. Así que primero calcula la diferencia entre la confirmación de fusión y "Commit 5":
git diff 4f90a62 4683aef
(Los valores de SHA-1 serán distintas en tu máquina.)
Si no te sientes cómodo con la salida de git diff, puedes leer el capítulo anterior donde lo describí en detalle.
Puedes almacenar esa diferencia en un archivo:
git diff 4f90a62 4683aef > john_branch_diff.patch
Luego, Git calcula la diferencia entre la confirmación de fusión y "Commit 6":
git diff 4f90a62 c5e4951
Escribe esto en un archivo también:
git diff 4f90a62 c5e4951 > paul_branch_diff.patch
Ahora Git aplica esos parches en la base de fusión.
Primero, intenta eso directamente - aplica los parches (te lo explicaré en un momento). Esto no es lo que realmente hace Git por defecto, pero te ayudará a ganar un mejor entendimiento de por qué Git necesita hacer algo distinto.
Verifica la base de fusión primero, eso es, la confirmación de fusión:
git checkout 4f90a62
Y aplica el parche de John primero (como recordatorio, este es el parche que se muestra en la imagen con el subtítulo "The diff between the merge commit and "Commit 5""):
git apply --index john_branch_diff.patch
Fíjate que por ahora no hay una confirmación de fusión. git apply actualiza el directorio de trabajo así también como el índice, ya que usamos el conmutador --index.
Puedes observar el estado usando git status:
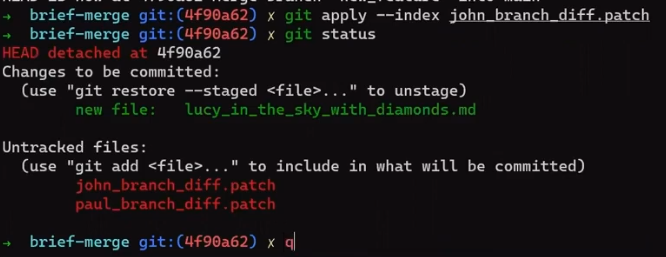
Así que ahora la nueva canción de John se incorpora en el índice. Aplica el otro parche:
git apply --index paul_branch_diff.patch
Como resultado, el índice contiene los cambios desde ambas ramas.
Ahora es tiempo de confirmar tu fusión. Ya que el comando de porcelana git commit siempre genera una confirmación con un solo predecesor, necesitarías el comando de plomería subyacente - git commit-tree.
Si necesitas un recordatorio sobre los comandos de porcelana vs de plomería, mira el capítulo 4 donde expliqué estos términos, y creé un repo entero desde cero.
Recuerda que cada objeto de confirmación de Git apunta a un sólo árbol. Así que necesitas registrar los contenidos del índice en un árbol:
git write-tree
Ahora obtienes el valor de SHA-1 del árbol creado, y puedes crear un objeto de confirmación usando git commit-tree:
git commit-tree <TREE_SHA> -p <COMMIT_5> -p <COMMIT_6> -m "Merge commit!"

Genial, ¡así que has creado un objeto de confirmación!
Recuerda que git merge también cambia el HEAD para que apunte al nuevo objeto de confirmación de fusión. Así que puedes simplemente hacer lo mismo:
git reset --hard db315a
Si miras al historial ahora:
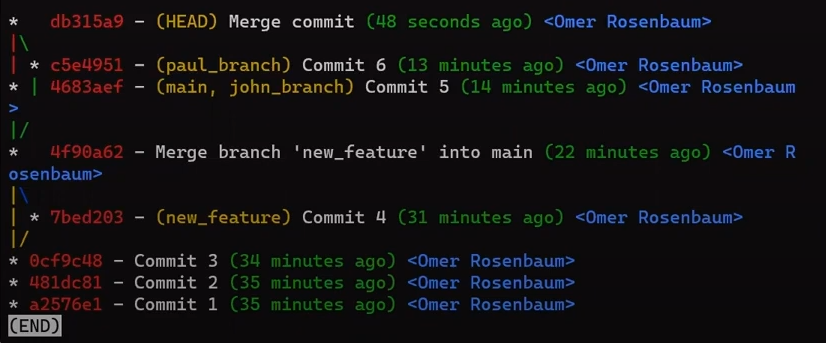
HEAD(Nota: en este estado, HEAD está "separado" - eso es, directamente apunta a un objeto de confirmación en vez de una referencia nombrada. gg no muestra el HEAD cuando está "separado", así que no te confundas si no puedes ver el HEAD en la salida de gg.)
Esto es casi lo que queríamos. Recuerda que cuando ejecutaste git merge, el resultado fue HEAD apuntando a main el cual apuntó a la nueva confirmación creada (como se muestra en la imagen con el subtítulo "When you merge paul_branch), obtienes una nueva confirmación de fusión". ¿Qué deberías hacer entonces?
Bueno, lo que quieres es modificar a main, así que lo puedes apuntar a la nueva confirmación:
git checkout main
git reset --hard db315a
Y ahora tienes el mismo resultado cuando ejecutaste git merge: main apunta a la nueva confirmación, el cual tiene "Commit 5" y Commit 6" como sus predecesores. Puedes usar git lol para verificar eso.
Así que esto es exactamente el mismo resultado como la fusión hecha por Git, con la excepción de la marca de tiempo y así el valor de SHA-1, por supuesto.
Sobretodo, tienes que fusionar los contenidos de las dos confirmaciones - eso es, el estado de los archivos, y también el historial de esas confirmaciones - creando una confirmación de fusión que apunta a ambos historiales.
En este caso sencillo, podrías en realidad aplicar los parches usando git apply y todo funciona bastante bien.
Rápida recapitulación de una Fusión de tres vías
Así que para recapitular rápidamente, en una fusión de tres vías, Git:
- Primero, localiza la base de fusión - el ancestro común de las dos ramas. Eso es, la primer confirmación que es accesible de ambas ramas.
- Segundo, Git calcula los dos diffs - un diff de la base de fusión a la primera rama, y otro diff de la base de fusión a la segunda rama.
- Tercero, Git aplica ambos parches a la base de fusión, usando un algoritmo de fusión de tres vías. No he explicado la fusión de tres vías todavía, pero lo explicaré más tarde. El resultado es el estado de la nueva confirmación de fusión.
También puedes entender por qué se llama una "fusión de 3 vías": Git fusiona, tres estados diferentes - el de la primera rama, el de la segunda rama, y su ancestro en común. En nuestro ejemplo anterior, main, paul_branch, y la confirmación de fusión (con "Commit 3" y "Commit 4" como predecesores), respectivamente.
Esto es improbable, digamos, los ejemplos directos que vimos antes. Los ejemplos directos son en realidad un caso de una fusión de dos vías, ya que Git solamente compara dos estados - por ejemplo, a donde main apuntó, y a donde john_branch apuntó.
Continuando
Todavía, esto fue un sencillo caso de una fusión de 3 vías. John y Paul crearon canciones distintos, así que cada uno de ellos tocaron un archivo distinto. Fue bastante directo para ejecutar la fusión.
¿Qué hay sobre casos más interesantes?
Digamos que ahora John y Paul son co-autores de una nueva canción.
Así que, John verificó la rama main y comenzó a escribir la canción:
git checkout main
Él lo puso en el área de preparación y lo confirmó ("Commit 7"):
git add a_day_in_the_life.md
git commit -m "Commit 7"
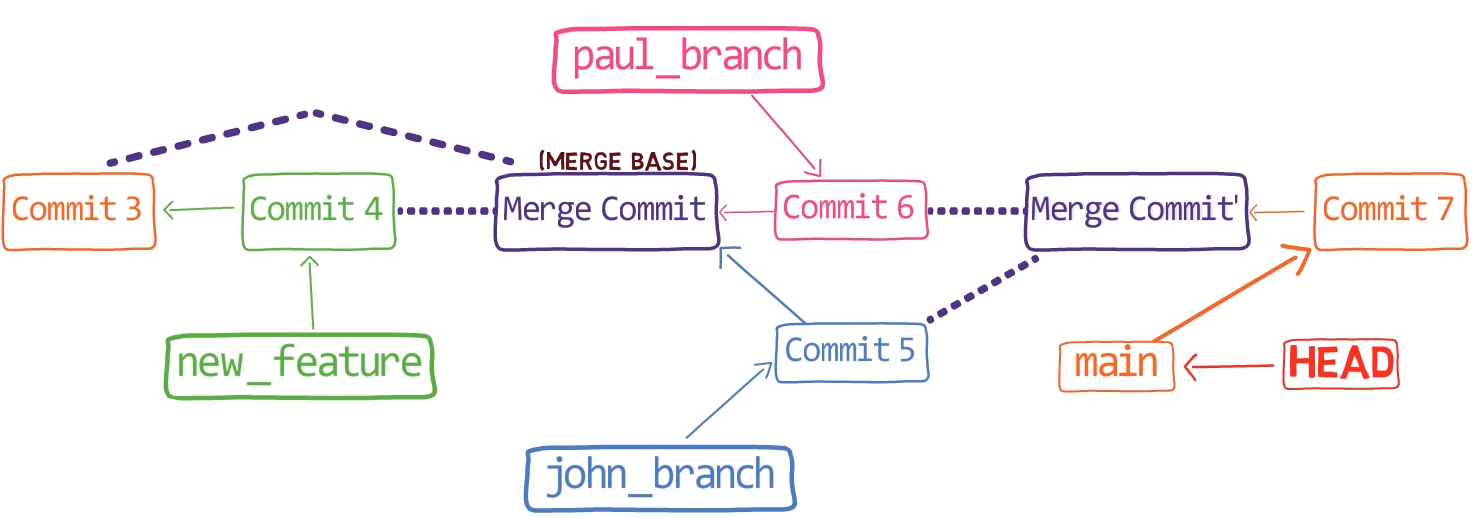
Ahora, Paul hace una rama:
git checkout -b paul_branch_2
Y edita la canción, agregando otro verso:
Por supuesto, la canción original no incluye el título "Paul's Verse", pero lo agregué para claridad.
Paul pone en el área de preparación y confirma los cambios:
git add a_day_in_the_life.md
git commit -m "Commit 8"
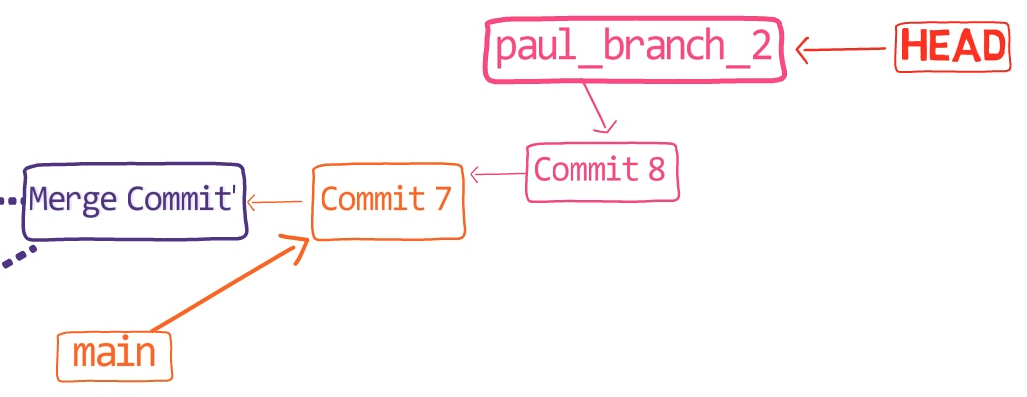
John también hace una rama tomando de main y agrega unas dos líneas adicionales al final:
git checkout main
git checkout -b john_branch_2
John pone en el área de preparación y confirma sus cambios también ("Commit 9"):
git add a_day_in_the_life.md
git commit -m "Commit 9"
Este es el historial resultante:
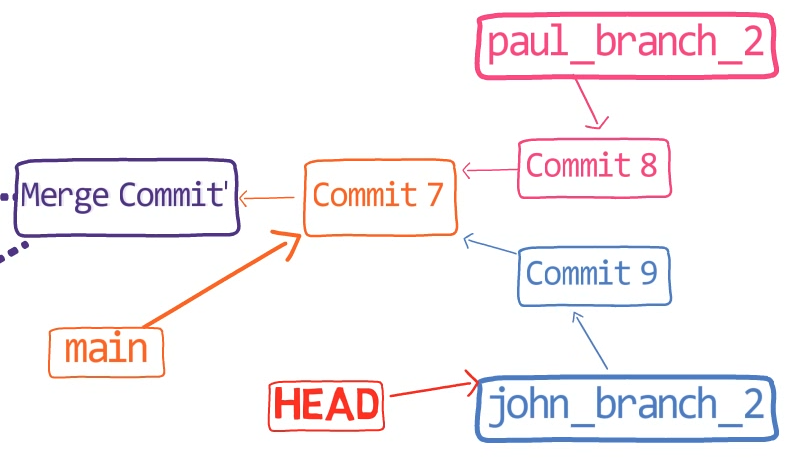
Así que, Paul y John modificó el mismo archivo en diferentes ramas. ¿Tendrá éxito Git al fusionarlos?
Digamos que ahora no vamos por main, sino que John intentará fusionar la nueva rama de Paul en su rama:
git merge paul_branch_2
¡Espera! ¡No ejecutes este comando! ¿Por qué le dejarías a Git hacer todo el trabajo duro? Estás intentando de entender el proceso aquí.
Así que, primero, Git necesita encontrar la base de fusión. ¿Puedes ver cual confirmación sería?
Correcto, sería la última confirmación en la rama main, donde los dos difieren - eso es, "Commit 7".
Puedes verificar eso usando:
git merge-base john_branch_2 paul_branch_2
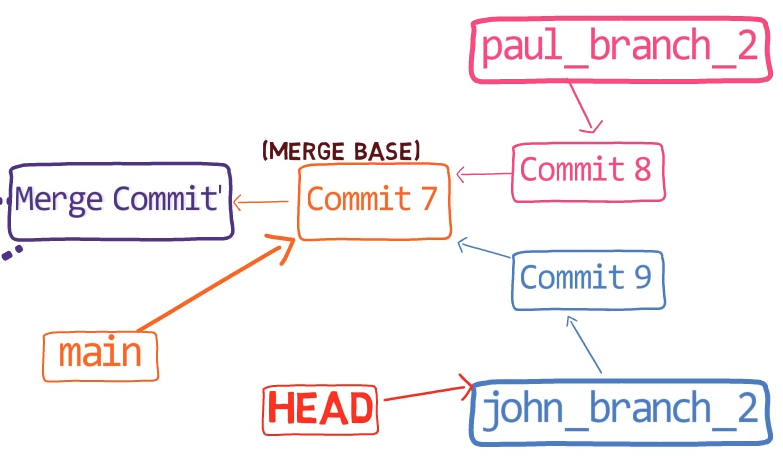
Cambia a la base de fusión así más tarde puedes aplicar los parches que crearás:
git checkout main
Genial, ahora Git debería calcular los diffs y generar los parches. Puedes observar los diffs directamente:
git diff main paul_branch_2
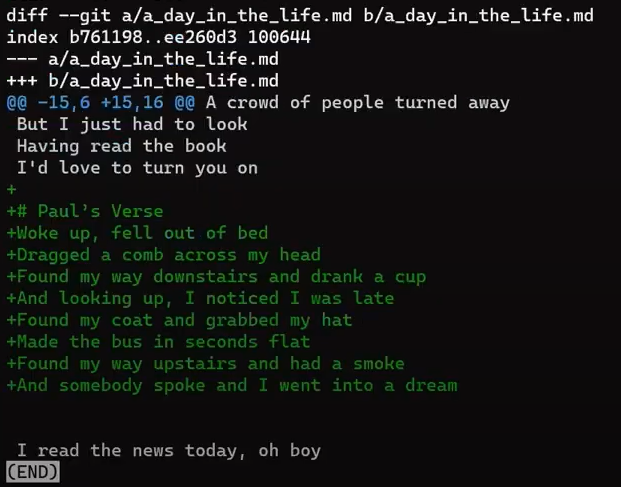
git diff main paul_branch_2¿Tendrá éxito en aplicar este parche? Bueno, sin problema, Git tiene todas las líneas de contexto en lugar.
Cambia a la base de fusión (el cual es "Commit 7", también referenciado por main), y pide a Git que aplique este parche:
git checkout main
git diff main paul_branch_2 > paul_branch_2.patch
git apply --index paul_branch_2.patch
Y esto funcionó, sin problemas para nada.
Ahora, calcula la diff entre la nueva rama de John y la base de fusión. Fíjate que no has confirmado los cambios aplicados, así que john_branch_2 todavía apunta a la misma confirmación como antes, "Commit 9":
git diff main john_branch_2
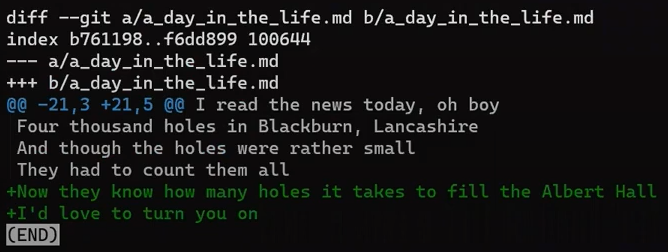
git diff main john_branch_2¿Funcionará si se aplica este diff?
Bueno, de hecho, sí. Fíjate que aunque los números de líneas han cambiado en la versión actual del archivo, gracias a las líneas de contexto que Git es capaz de localizar donde necesita agregar estas líneas...
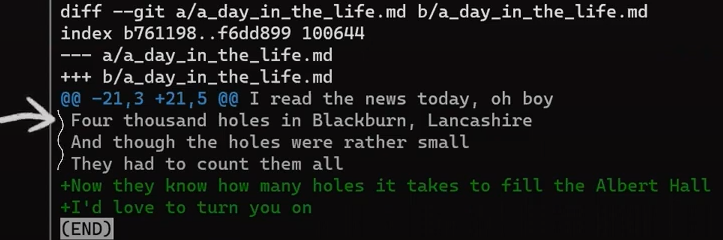
Guarda este parche y luego aplícalo:
git diff main john_branch_2 > john_branch_2.patch
git apply --index john_branch_2.patch
Observa el archivo resultante:
Genial, exactamente lo que queríamos.
Ahora puedes crear el árbol y la confirmación relevante:
git write-tree
No te olvides de especificar ambos predesores:
git commit-tree <TREE-ID> -p paul_branch_2 -p john_branch_2 -m "Merging new changes"
¿Viste cómo usé los nombres de rama aquí? Después de todo, sólo son punteros a las confirmaciones que queremos.
Genial, mira el log de la nueva confirmación:
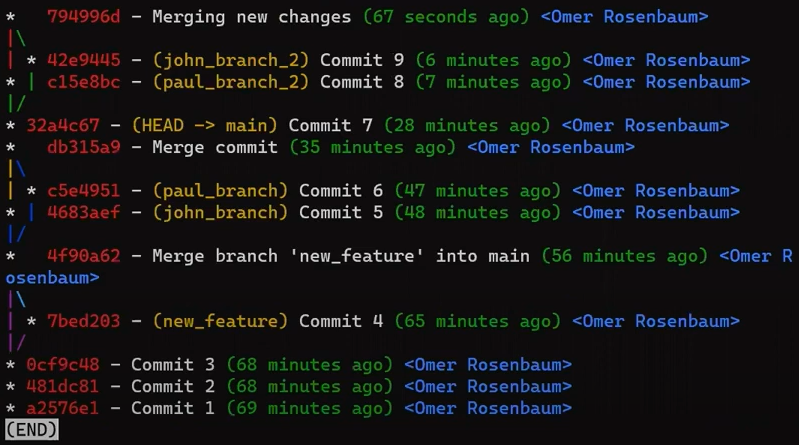
git lol <SHA_OF_THE_MERGE_COMMIT> after creating the merge commit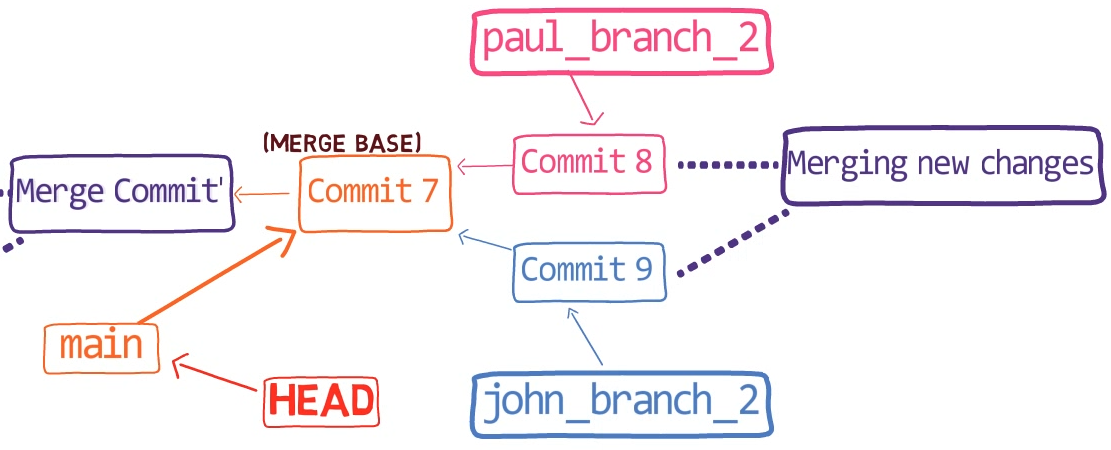
Exactamente lo que queríamos.
También puedes dejar a Git que haga el trabajo para ti. Puedes cambiar a john_branch_2, el cual no has movido - así que todavía apunta a la misma confirmación como lo hizo antes de la fusión. Así que todo lo que necesitas es ejecutar:
git checkout john_branch_2
git merge paul_branch_2
Observa el historial resultante:
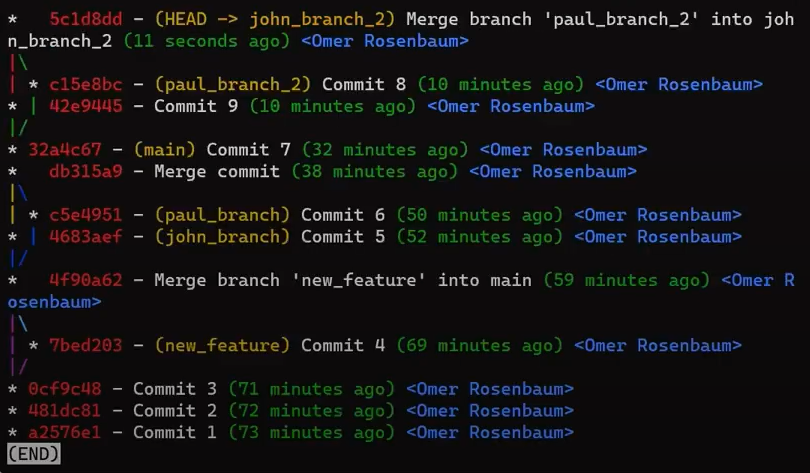
git lol after letting Git perform the merge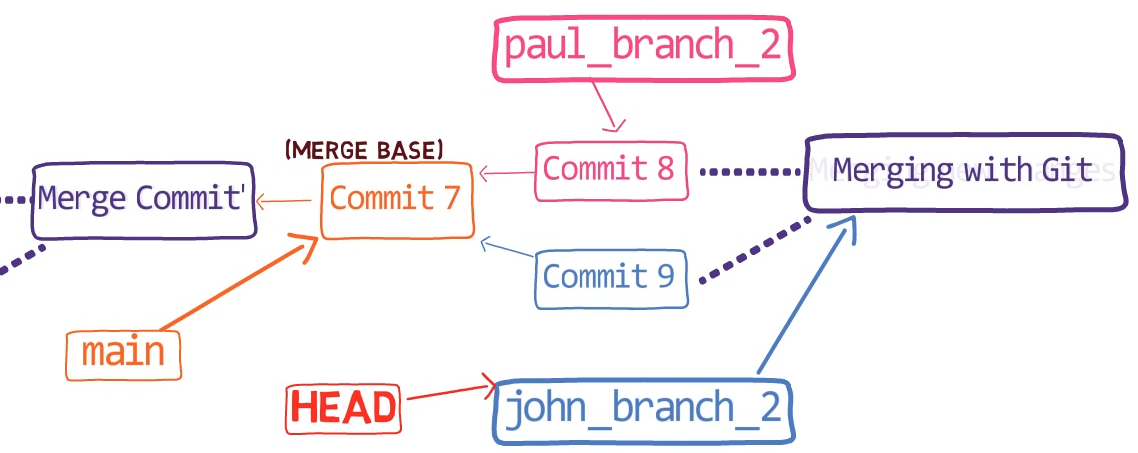
Como antes, tienes una confirmación de fusión apuntando a "Commit 8" y "Commit 9" como sus predecesores. "Commit 9" es el primer predecesor ya que lo fusionaste.
Pero esto fue bastante sencillo... John y Paul trabajaron en el mismo archivo, pero en partes muy distintas. También podrías directamente aplicar los cambios de Paul a la rama de John. Si vuelves a la rama de John antes de la fusión:
git reset --hard HEAD~
Y ahora aplica los cambios de Paul:
git apply --index paul_branch_2.patch
Obtendrías el mismo resultado.
Pero, ¿qué sucede cuando las dos ramas incluyen cambios en los mismos archivos, en las mismas ubicaciones?
Casos de Fusión de Git más avanzados
¿Qué sucedería si John y Paul fueran a coordinar una nueva canción, y lo realizan juntos?
En este caso, John crea la primer versión de esta canción en la rama main:
git checkout main
nano everyone.md

everyone.md prior to the first commitA propósito, este texto es de hecho tomado de la versión que John Lennon grabó para una demo en 1968. Pero esto no es un libro sobre los Beatles. Si estás interesado sobre el proceso por el que los Beatles atravesaron mientras escribían esta canción, puedes seguir los enlaces al final de este capítulo.
git add everyone.md
git commit -m "Commit 10"
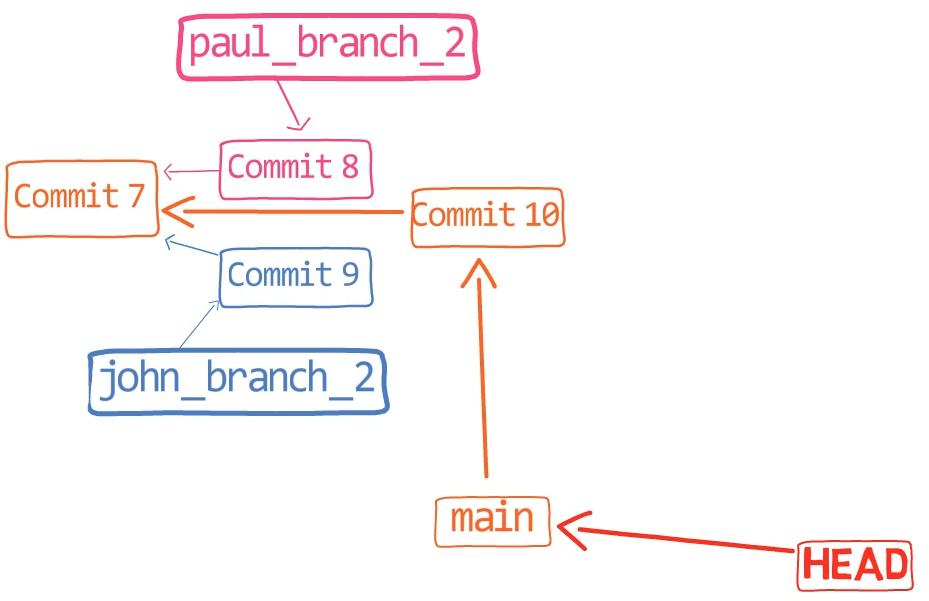
Ahora John y Paul se separon. Paul crea un nuevo verso al principio:
git checkout -b paul_branch_3
nano everyone.md
También, mientras hablando con John, decidieron cambiar la palabra "feet" a "foot", así que Paul agrega este cambio también.
Y Paul agrega y confirma sus cambios al repo:
git add everyone.md
git commit -m "Commit 11"
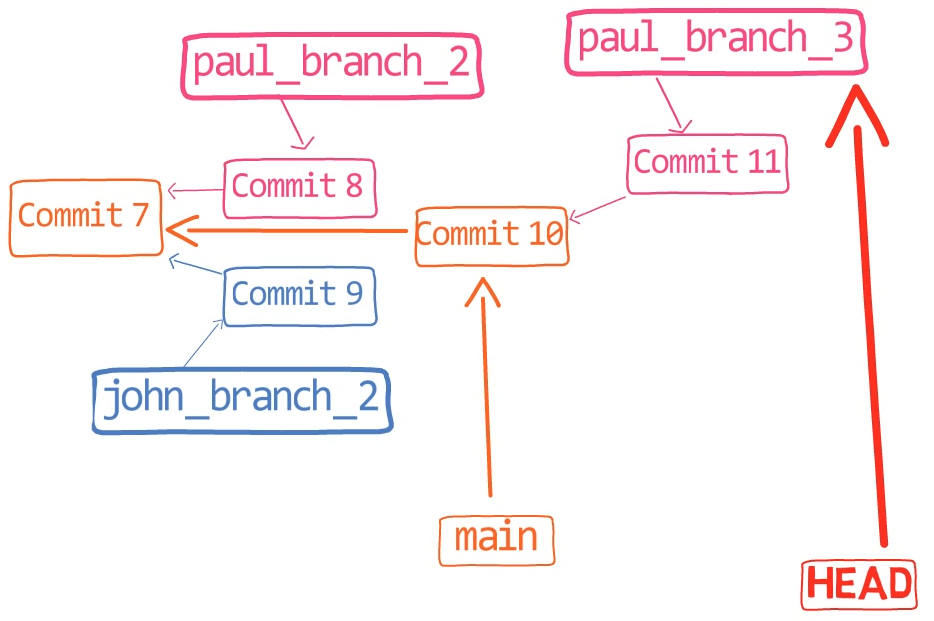
Puedes observar los cambios de Paul, comparando este estado de la rama al estado de la rama main:
git diff main
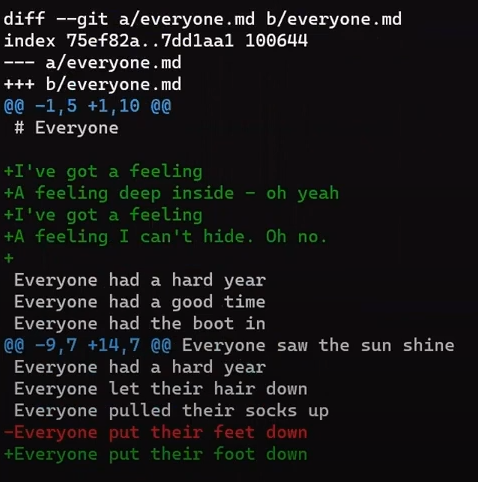
git diff main from Paul's branchAlmacena este diff en un archivo parche:
git diff main > paul_3.patch
Ahora devuelta a main...
git checkout main
John decide hacer otro cambio, en su propia nueva rama:
git checkout -b john_branch_3
Y reemplaza la línea "Everyone had the boot in" con la línea "Everyone had a wet dream". Además, John cambió la plabra "feet" a "foot", siguiendo su charla con Paul.
Observa el diff:
git diff main
git diff main from John's branchAlmacena esta salida también:
git diff main > john_3.patch
Ahora, pónlo en el área de preparación y confirma:
git add everyone.md
git commit -m "Commit 12"
Este debería ser tu historial actual:
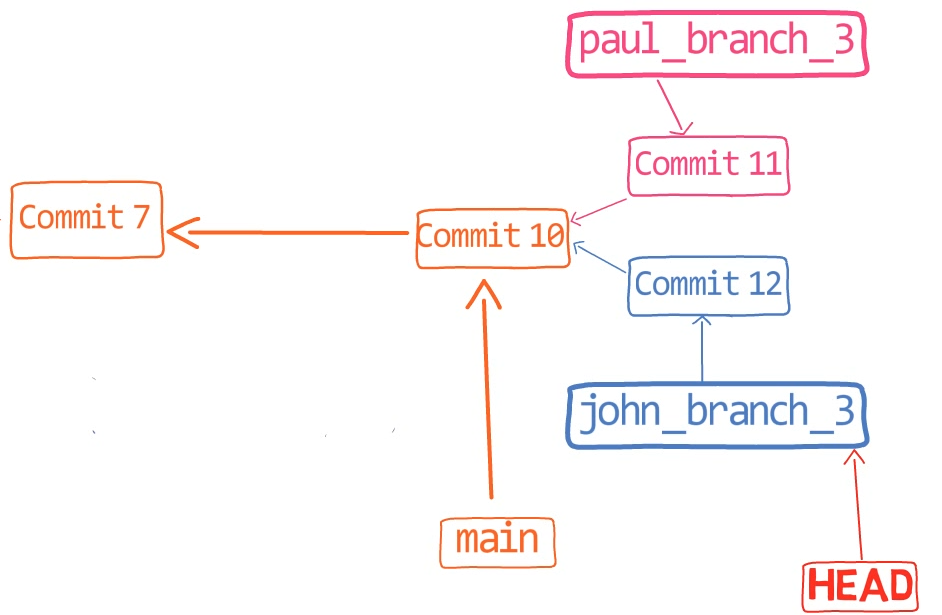
Fíjate que eliminé john_branch_2 y paul_branch_2 para simplicidad. Por supuesto, puedes eliminarlos de Git usando git branch -D <branch_name>. Como resultado, estos nombres de ramas no aparecerán en la salida de git log u otros comandos similares.
Esto también se aplica a las confirmaciones que ya no son accesibles desde ninguna referencia nombrada, tales como "Commit 8" o "Commit 9". Ya que ya no son accesibles desde ninguna referencia nombrada por medio de la cadena de los antecesores, no serán incluidos en la salida de comandos tales como git log.
Devuelta a nuestra historia - Paul y John han agregado un nuevo verso, así que a John le gustaría fusionar los cambios de Paul.
¿Puede John simplemente aplicar el parche de Paul?
Considera el parche de nuevo:
git diff main paul_branch_3
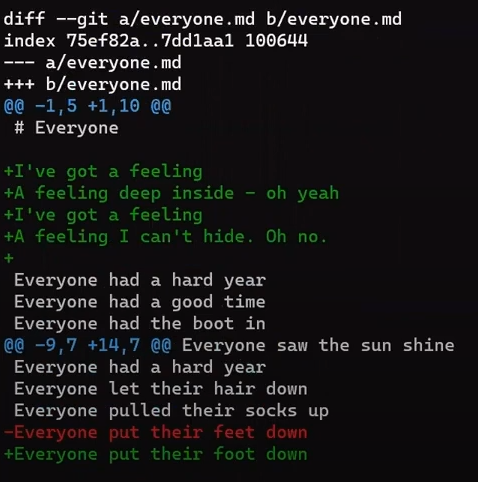
git diff main paul_branch_3Como puedes ver, este diff se basa en la línea "Everyone had the boot in", pero esta línea ya no existe en la rama de John. Como resultado, podrías esperar que aplicar el parche falle. Continúa, inténtalo:
git apply paul_3.patch

De hecho, puedes ver que falló.
¿Pero debería fallar realmente?
Como expliqué anteriormente, git merge usa un algoritmo de 3 vías, y esto puede ser útil aquí. ¿Cuál sería el primer paso de este algoritmo?
Bueno, primero, Git encontraría la base de fusión - eso es, el ancestro común de la rama de Paul y de la rama de John. Considera el historial:
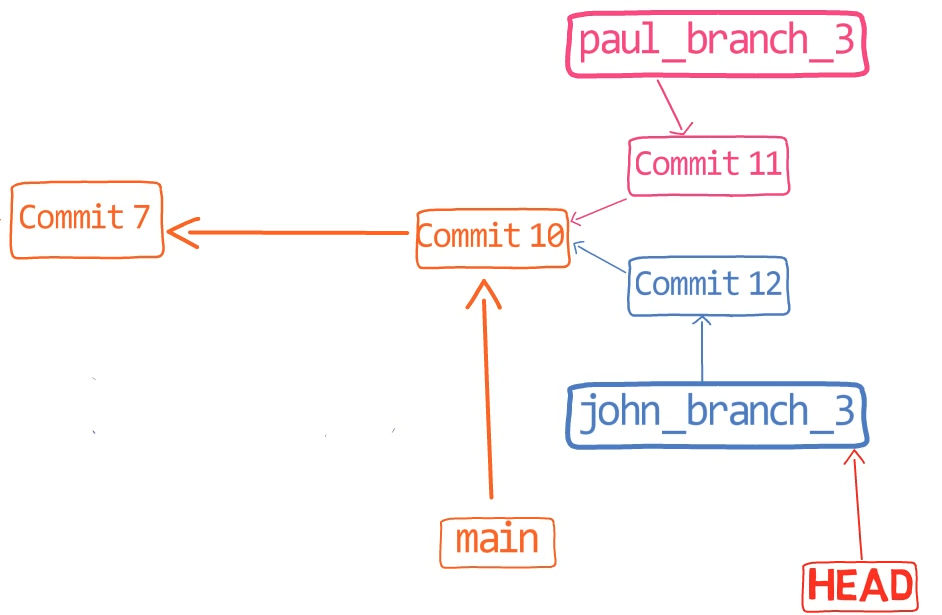
Así que el ancestro común de "Commit 11" y Commit 12" es "Commit 10". Puedes verificarlo ejecutando el comando:
git merge-base john_branch_3 paul_branch_3
Ahora podemos tomar los parches que generamos desde los diffs en ambas ramas, y aplicarlos al main. ¿Funcionaría?
Primero, intenta aplicar el parche de John, y luego el parche de Paul.
Considera el diff:
git diff main john_branch_3
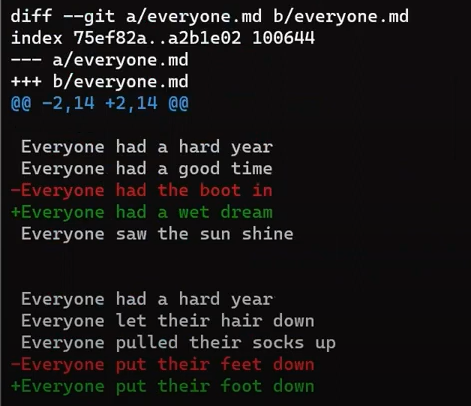
git diff main john_branch_3Podemos almacenarlo en un archivo:
git diff main john_branch_3 > john_3.patch
Y aplicar este parche en el main:
git checkout main
git apply john_3.patch
Consideremos el resultado:
nano everyone.md

everyone.md after applying John's patchLa línea cambió como se esperaba. Bien 😎
Ahora, ¿puede Git aplicar el parche de Paul? Para recordarte, este es el parche. Bueno, Git no puede aplicar este parche, porque este parche asume que la línea "Everyone had the boot in" existe. Tratar de aplicarlo es probable que falle:
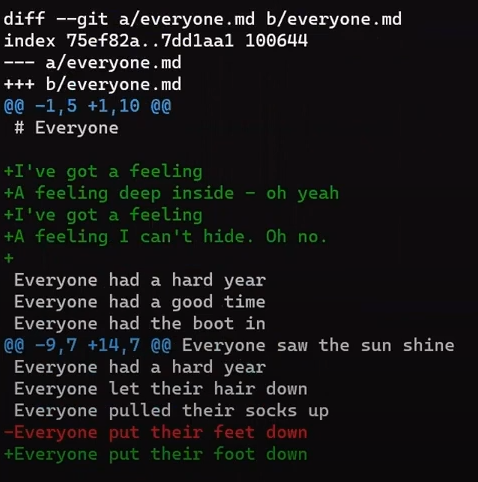
Bueno, Git no puede aplicar este parche, porque este parche asume que la línea "Everyone had the boot in" existe. Tratar de aplicarlo es probable que falle:
git apply -v paul_3.branch
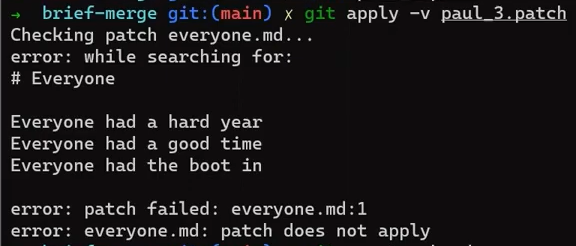
Lo que intentaste de hacer ahora, aplicar el parche de Paul en la rama main después de aplicar el parche de John, es lo mismo que estar en john_branch_3, e intentar de aplicar el parche. Eso es, ejecutando:
git apply paul_3.patch
¿Qué sucedería si intentaramos al revés?
Primero, limpia el estado:
git reset --hard
Y comienza desde la rama de Paul:
git checkout paul_branch_3
¿Podemos aplicar el parche de Paul? Como recordatorio, este es el estado de everyone.md en esta rama:
everyone.md on paul_branch_3Y este es el parche de John:
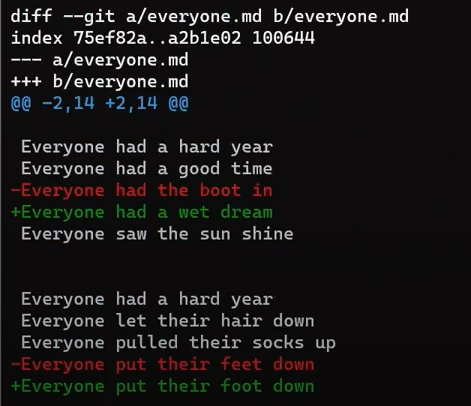
¿Funcionaría aplicar el parche de John?
Intenta contestarte a tí mismo antes de continuar leyendo.
Puedes intentar:
git apply john_3.patch

Bueno, ¡no! De nuevo, si estás seguro de lo que pasó, siempre puedes pedir con git apply para que sea un poco más verboso:
git apply -v john_3.patch
-v flagGit está buscando "Everyone put the feet down", pero Paul ya ha cambiado esta línea así que ahora consiste de la palabra "foot" en vez de "feet". Como resultado, aplicar este parche falla.
Fíjate que cambiar el número de las líneas de contexto aquí (eso es, usando git apply con el argumento -C, como se discutió en el capítulo anterior) es irrelevante - Git es incapaz de localizar la línea actual que el parche está intentando de eliminar.
Pero en realidad, Git puede hacer que esto funcione, si sólo agregas un argumento para aplicar, diciéndole que haga una fusión de tres vías por debajo:
git apply -3 john_3.patch

-3 flag succeedsY considera el resultado:
everyone.md after the merge¡Exactamente lo que queríamos! ¡Tienes el verso de Paul, y los de John!
Así que, ¿cómo Git fue capaz de lograr eso?
Bueno, como mencioné, Git realmente hizo una fusión de 3 vías, y con este ejemplo, será un buen momento para indagar lo que esto realmente significa.
Cómo funciona el Algoritmo de Fusión de 3 vías de Git
Vuelve al estado antes de aplicar este parche:
git reset --hard
Ahora tienes tres versiones: la base de fusión, el cual es "Commit 10", la rama de Paul, y la rama de John. En términos generales, podemos decir que estos son el merge base, commit A y commit B. Fíjate que el merge base es por definición un ancestro de ambos commit A y commit B.
Para realizar una fusión, Git mira al diff entre las tres diferentes versiones del archivo en cuestión de estas tres revisiones. En tu caso, es el archivo everyone.md, y las revisiones son "Commit 10", la rama de Paul - eso es, "Commit 11", y la rama de John, eso es, "Commit 12".
Git hace la decisión de fusión basado en el estado de cada línea en cada una de estas versiones.
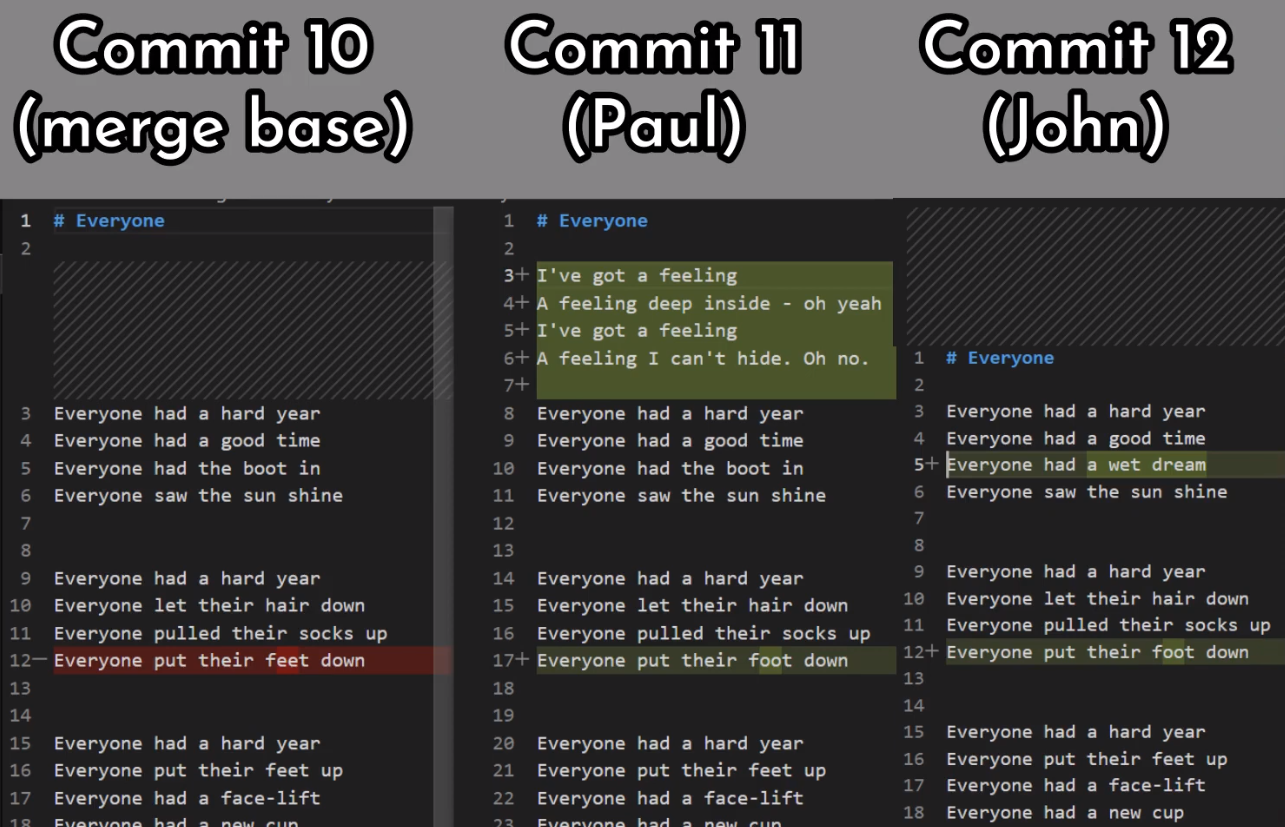
En caso que no todas las tres versiones coincidan, eso es un conflicto. Git puede resolver muchos de estos conflictos automáticamente, como veremos ahora.
Consideremos líneas específicas.
Las primeras líneas aquí existen solamente en la rama de Paul:
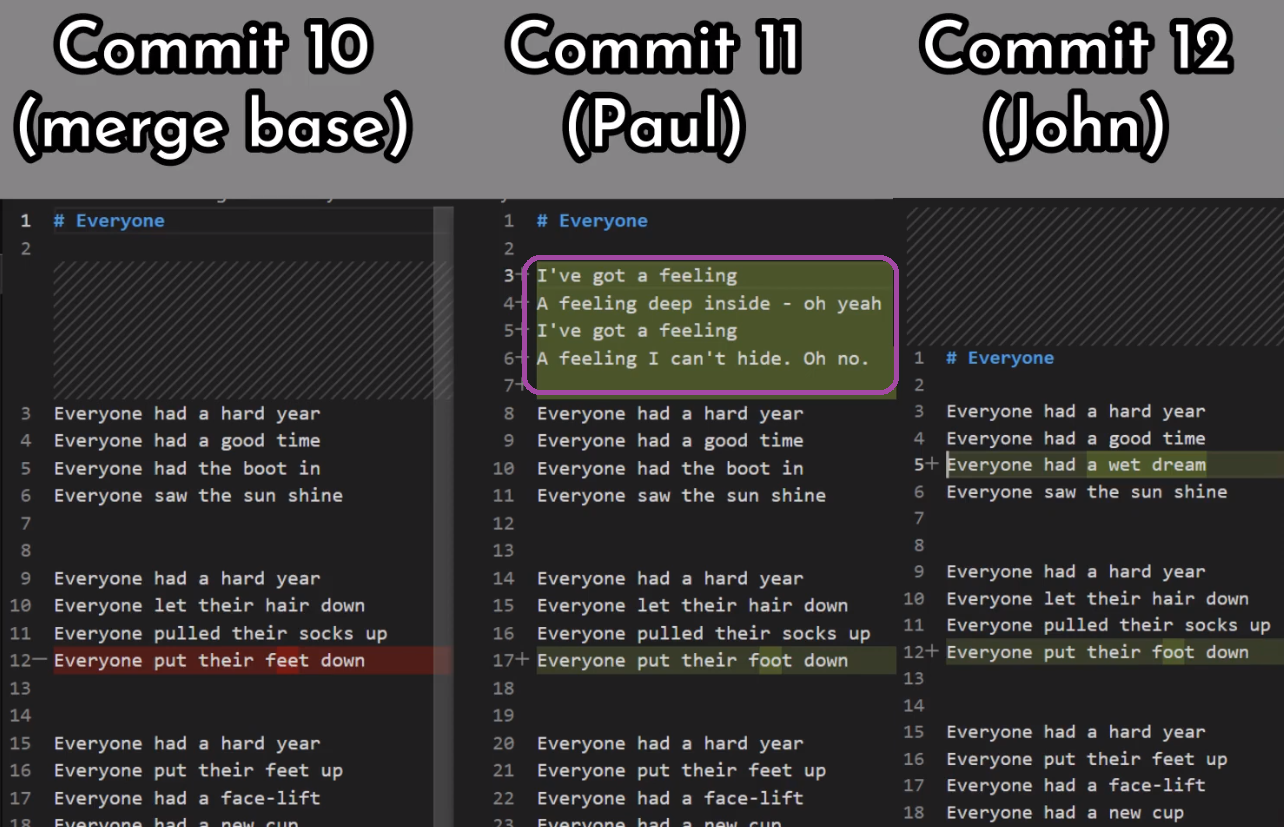
Esto significa que el estado de la rama de John es igual al estado de la base de fusión. Así que la fusión de 3 vías va a la par con la versión de Paul.
En general, si el estado de la base de fusión es el mismo que el A, el algoritmo va la par con B. La razón se debe a que la base de fusión es el ancestro de A y de B, Git asume que esta línea no ha cambiado en A, y ha cambiado en B, el cual es la versión más reciente para esa línea, y por lo tanto debería ser tomado en cuenta.
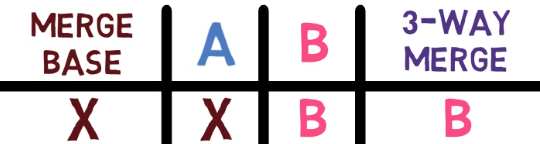
A, and this state is different from B, the algorithm goes with BLuego, puedes ver líneas donde toda las tres versiones están de acuerdo - están en la base de fusión, A y B, con datos iguales.
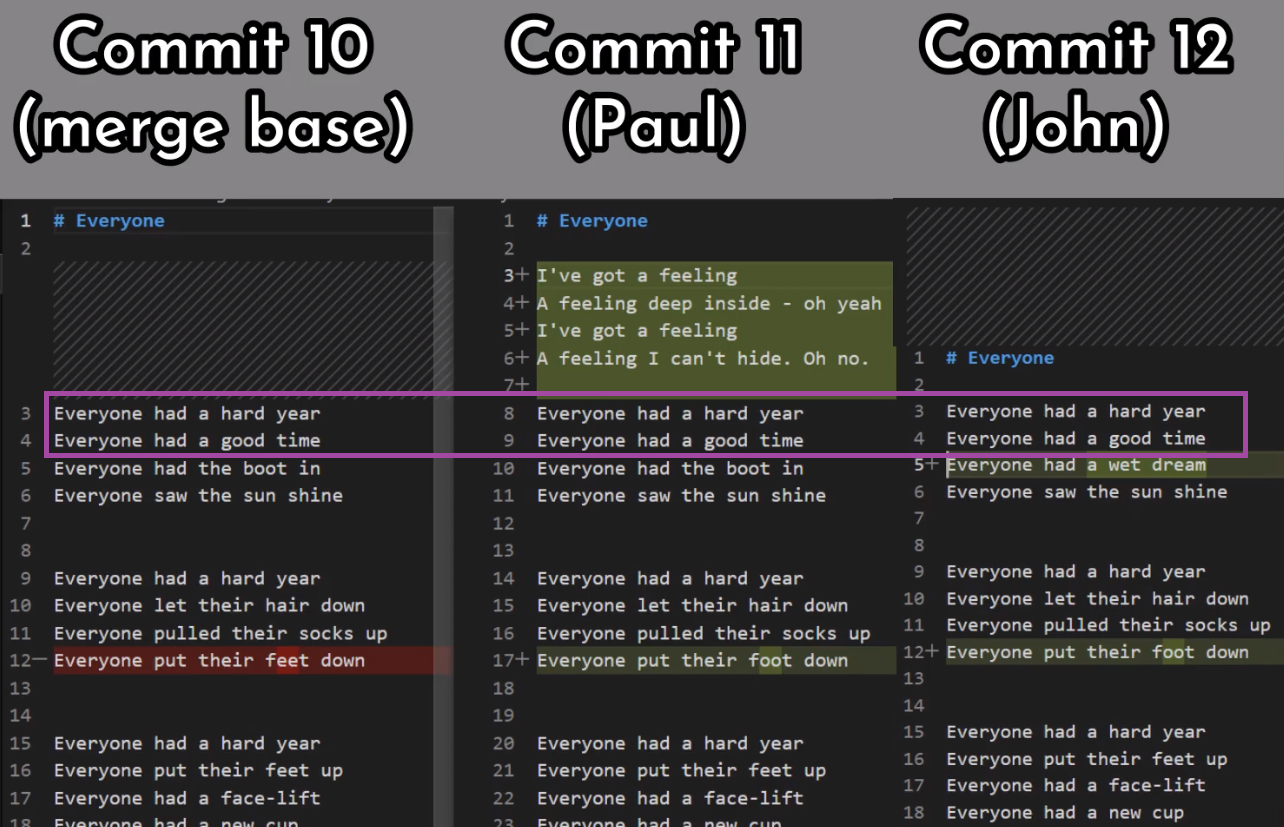
En este caso el algoritmo tiene una opción trivial - sólo toma esa versión.
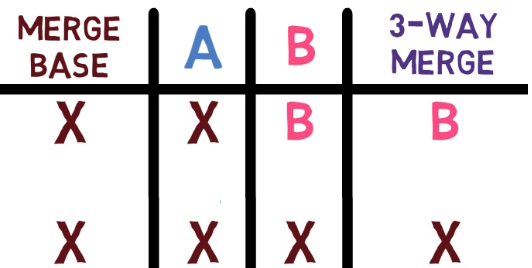
En un ejemplo previo, vimos que si la base de fusión y A están de acuerdo, y la versión de B es diferente, el agoritmo toma B. Esto funciona en la otra dirección también - por ejemplo, aquí tienes una línea que existe en la rama de John, distinto al de la base de fusión y al de la rama de Paul.
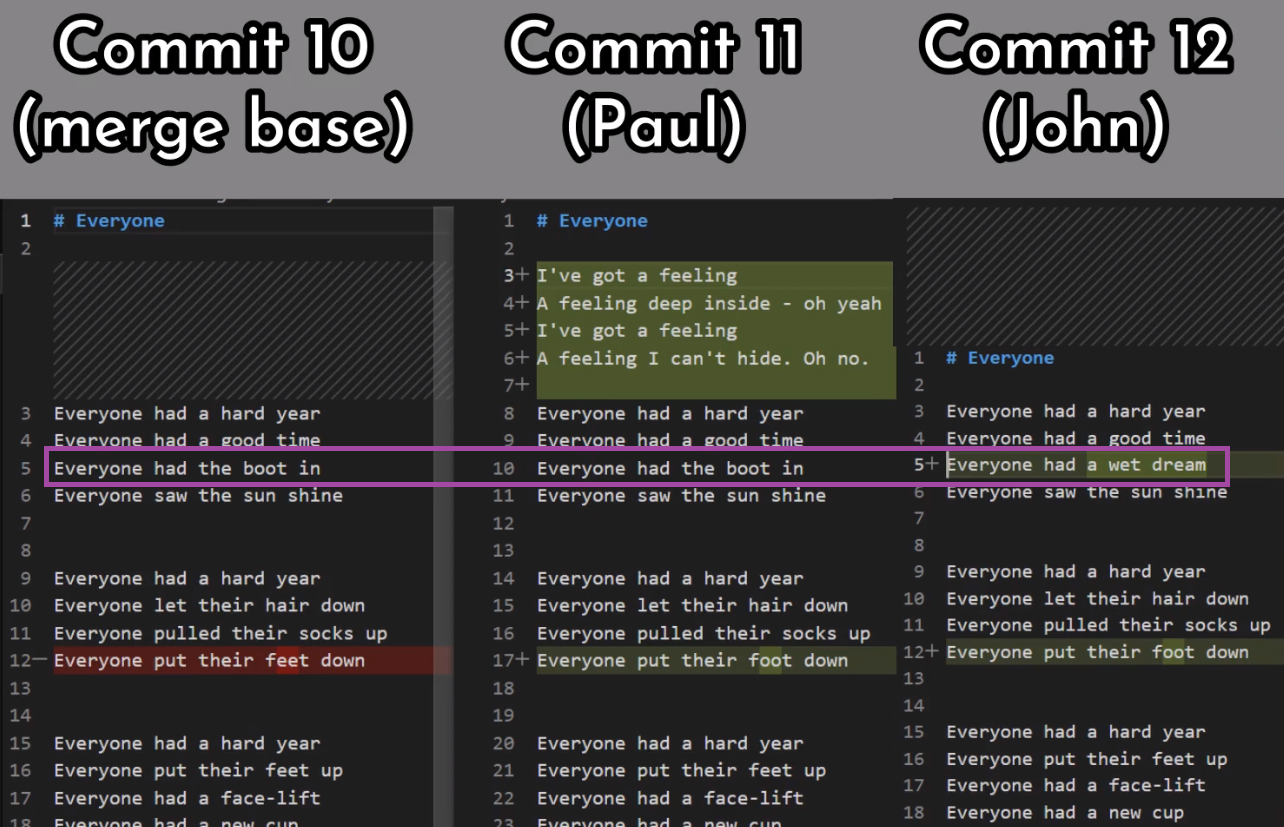
Por lo tanto, la versión de John es elegida:
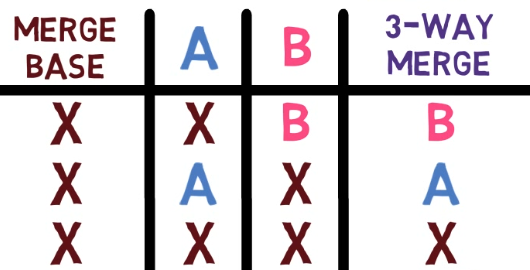
B, and this state is different from A, the algorithm goes with AAhora considera otro caso, donde A y B están de acuerdo en una línea, pero el valor en el que están de acuerdo es distinta del de la base de fusión: ambos John y Paul acordaron en cambiar la línea "Everyone put their feet down" a "Everyone put their foot down":
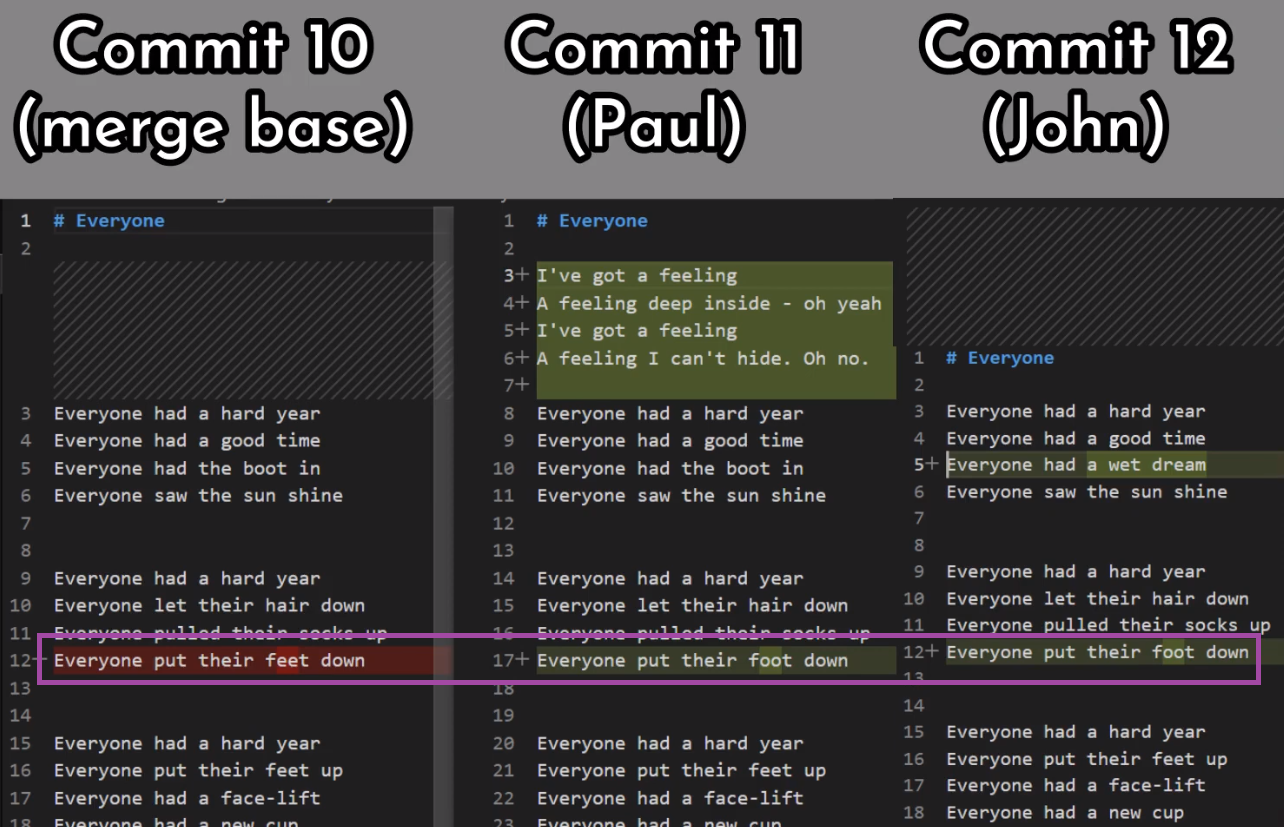
En este caso, el algoritmo toma la versión de A y de B.
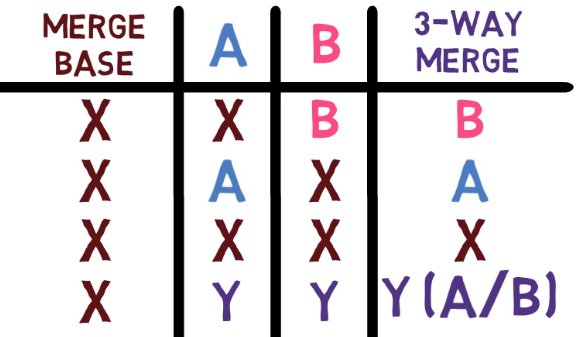
A and B agree on a version which is different from the merge base's version, the algorithm picks the version on both A and BFíjate que esto no es un voto democrático. En el caso previo, el algoritmo tomó la versión minoritaria, ya que se parecía a la versión más reciente de esta línea. En este caso, llega a tomar la mayoría - pero solamente porque A y B son las revisiones que acordan en la nueva versión.
Lo mismo sucedería si usaramos git merge:
git merge john_branch_3
Sin especificar ningún argumento, git merge por defecto usará una fusión de 3 vías.

git merge uses a 3-way merge algorithmEl estado de everyone.md después de ejecutar git merge john_branch sería el mismo que el resultado que alcanzaste al aplicar los parches con git apply -3.
Si consideras el historial:
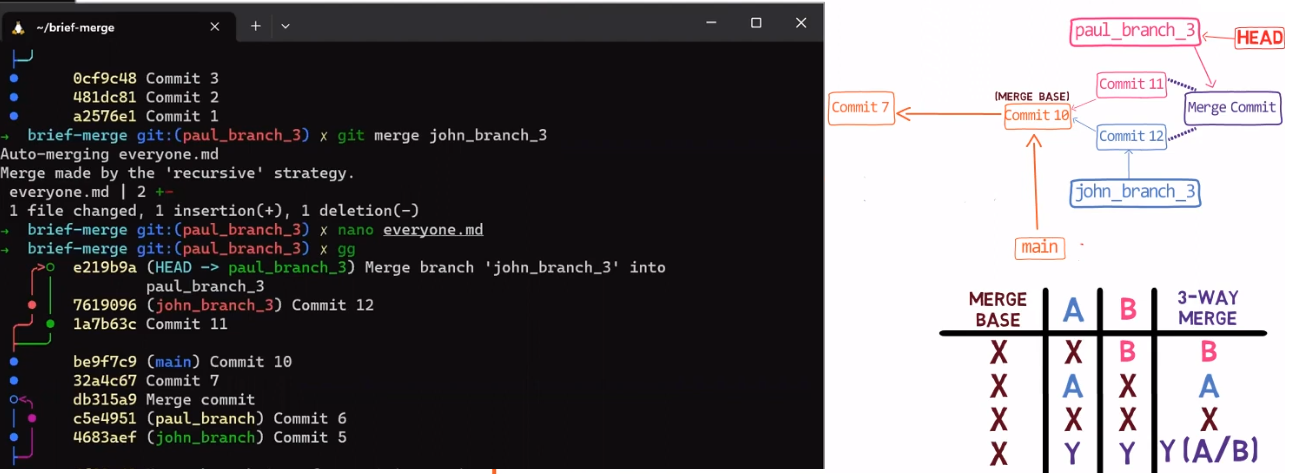
Verás que la confirmación de fusión tiene dos antecesores: el primero es el "Commit 11", eso es, a donde apuntó paul_branch_3 antes de la fusión. El segundo es "Commit 12", a donde john_branch_3 apuntó, y a donde todavía apunta ahora.
¿Qué sucederá si ahora fusionas desde main? Eso es, cambiar a la rama main, el cual apunta al "Commit 10":
git checkout main
¿Y luego fusionar la rama de Paul?
git merge paul_branch_3
De hecho, obtenemos una fusión directa - como antes de ejecutar este comando, main era un ancestro de paul_branch_3.
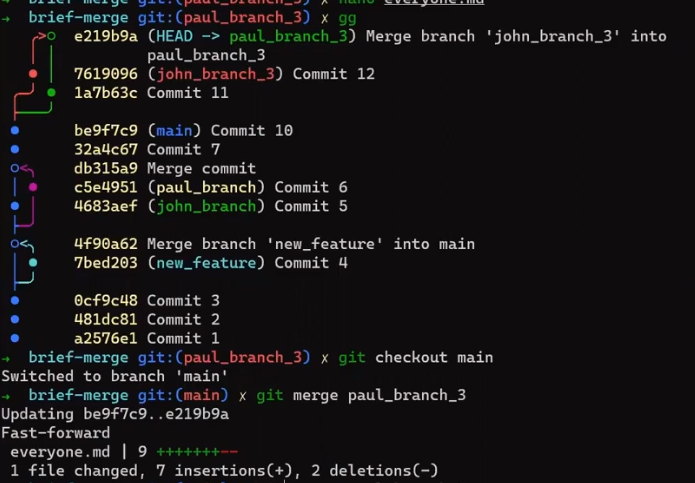
Así que, esto es una fusión de 3 vías. En general, si todas las versiones acuerdan en una línea, luego esta línea es usada. Si A y la base de fusión coinciden, y B tiene otra versión, B es tomado. En el caso opuesto, donde la base de fusión y B coinciden, la versión A es seleccionado. Si A y B coinciden, esta versión es tomada, sea que la base de fusión esté de acuerdo o no.
Esta descripción deja una pregunta abierta: ¿qué sucede en casos donde todas las tres versiones están en desacuerdo?
Bueno, eso es un conflicto que Git no lo resuelve automáticamente. En estos casos, Git pide ayuda de un humano.
Cómo resolver conflictos de fusión
Siguiendo hasta ahora, deberías entender las bases del comando git merge, y cómo Git puede resolver automáticamente algunos conflictos. También entiendes qué casos son resueltos automáticamente.
Ahora, consideremos un caso más avanzado.
Digamos que Paul y John continúan trabajando en esta canción.
Paul crea una nueva rama:
git checkout -b paul_branch_4
Y él decide agregar algunos "Yeah" a la canción, así que él cambia este verso como sigue:

Así que Paul pone en el área de preparación y confirma estos cambios:
git add everyone.md
git commit -m "Commit 13"
Paul también crea otra canción, let_it_be.md y lo agrega al repo:
git add let_it_be.md
git commit -m "Commit 14"
Este es el historial:
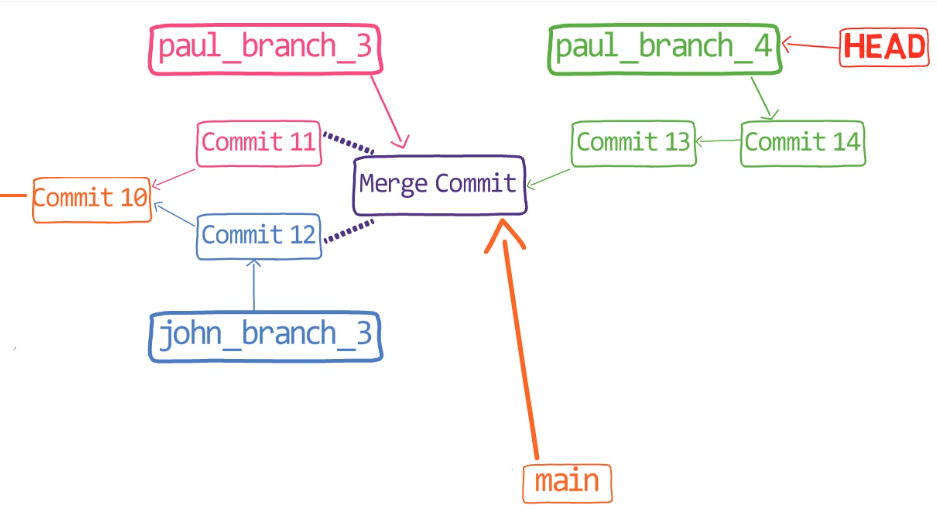
Volviendo a main:
git checkout main
John también crea una rama:
git checkout -b john_branch_4
Y John también trabaja en la canción "Everyone had a hard year", luego para ser llamado "I've got a feeling" (de nuevo, esto no es un libro sobre los Beatles, así que no daré mas detalles aquí. Mira los enlaces adicionales si tienes curiosidad).
John decide cambiar todas las ocurrencias de "Everyone" to "Everybody":
Él pone en el área de preparación y confirma esta canción al repo:
git add everyone.md
git commit -m "Commit 15"
Bien. Ahora John también crea otra canción, across_the_universe.md. Él lo agrega al repo también:
git add across_the_universe.md
git commit -m "Commit 16"
Observa el historial nuevamente:
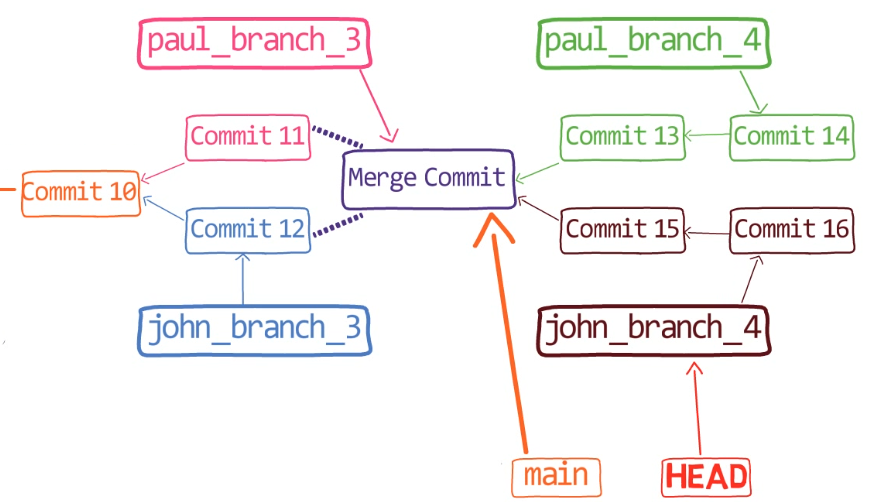
Puedes ver que el historial difiere de main, a dos ramas distintas - paul_branch_4, y john_branch_4.
A este punto, a John le gustaría fusionar los cambios introducidos por Paul.
¿Qué va a pasar aquí?
Recuerda los cambios introducidos por Paul:
git diff main paul_branch_4
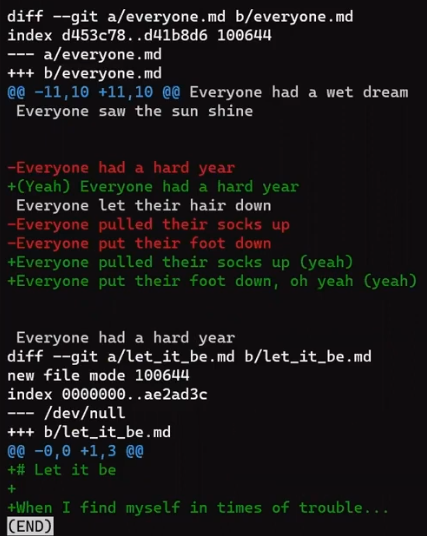
git diff main paul_branch_4¿Qué piensas? ¿La fusión funcionará?
Inténtalo:
git merge paul_branch_4

¡Tenemos un conflicto!
Git no puede fusionar estas ramas por sí mismo. Puedes obtener una vista general del estado de fusión, usando git status:
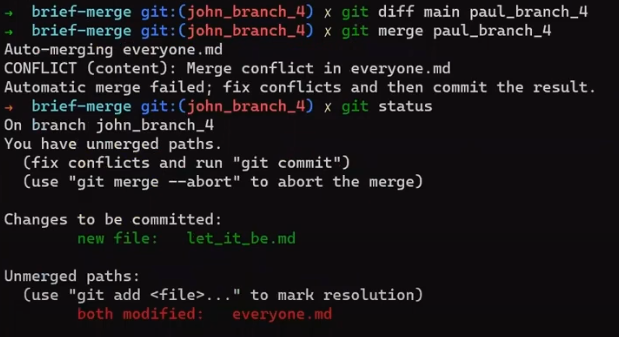
git status right after the merge operationLos cambios que Git no tuvo problema resolviendo están en el área de preparación para confimar. Y hay una sección separada para "rutas no fusionadas" - estos son archivos con conflictos que Git no podría resolver por sí mismo.
Es tiempo de entender por qué y cuando estos conflictos suceden, cómo resolverlos, y también cómo Git los maneja por debajo.
¡Muy bien entonces! Espero que al menos estés emocionado como yo. 😇
Recordemos lo que sabemos sobre fusiones de 3 vías:
Primero, Git buscará la base de fusión - el ancestro común de john_branch_4 y paul_branch_4. ¿Cuál confirmación sería ese?
Sería la punta de la rama main, la confirmación en el cual fusionamos john_branch_3 en paul_branch_3.
De vuelta, si no estás seguro, puedes verificar eso ejecutando:
git merge-base john_branch_4 paul_branch_4
Y en el estado actual, git status sabe qué archivos están en el área de preparación y cuáles no.
Considera el proceso para cada archivo, el cual es el mismo que el algoritmo de fusión de 3 vías que consideramos por línea, pero a nivel de archivo:
across_the_universe.md existe en la rama de John, pero no existe en la base de fusión o en la rama de Paul. Así que Git elige incluir este archivo. Ya que ya estás en la rama de John y este archivo es incluido en la punta de esta rama, no es mencionado por git status.
let_it_be.md existe en la rama de Paul, pero no existe en la base de fusión o en la rama de John. Así que git merge "elige" incluirlo.
¿Qué hay sobre everyone.md? Bueno, aquí tenemos tres estados distintos de este archivo: su estado en la base de fusión, su estado en la rama de John, y su estado en la rama de Paul. Mientras se realiza una fusión, Git almacena todas estas versiones en el índice.
Observemos eso mirando directamente al índice con el comando git ls-files:
git ls-files -s --abbrev
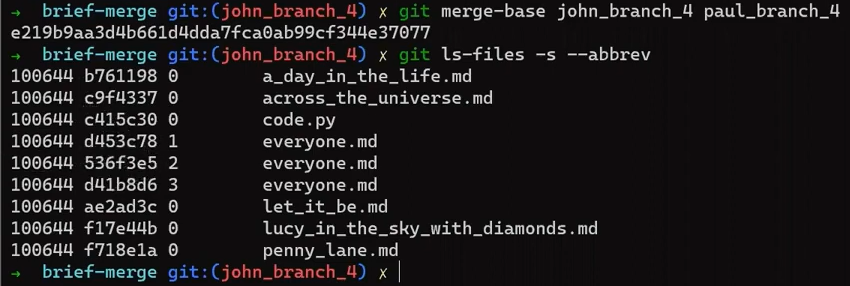
git ls-files -s --abbrev after the merge operationPuedes ver que everyone.md tiene tres entradas diferentes. Git le asigna a cada versión un número que representa la "fusión" del archivo, y esta es una propiedad distinta de una entrada de índice, junto con el nombre del archivo y el modo bits.
Cuando no hay conflicto de fusión en cuanto a un archivo, su "área de preparación" es 0. Esto es de hecho el estado para across_the_universe.md, y para let_it_be.md.
En un estado de conflicto, tenemos:
- Estado
1- el cual es la base de fusión. - Estado
2- el cual es "tu" versión. Eso es, la versión del archivo en la rama en la que estás fusionando. En nuestro ejemplo, este seríajohn_branch_4. - Estado
3- el cual es "su" versión, también llamado elMERGE_HEAD. Eso es, la versión en la rama que estás fusionando (en la rama actual). En nuestro ejemplo, ese espaul_branch_4.
Para observar los contenidos del archivo en un estado específico, puedes usar un comando que introduje en un post previo, git cat-file, y proveer el SHA del blob:
git cat-file -p <BLOB_SHA_FOR_STAGE_2>
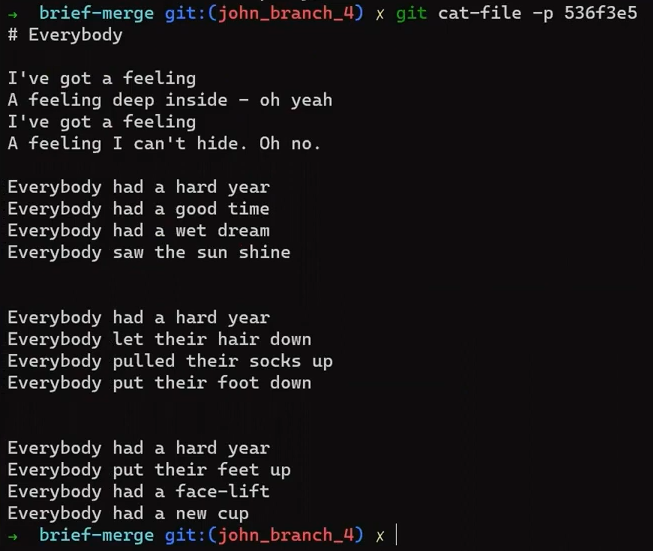
git cat-file to present the content of the file on John's branch, right from its state in the indexY justamente, este es el contenido que esperábamos - de la rama de John, donde las líneas comienzan con "Everybody" en vez de "Everyone".
Un lindo truco que te permite ver el contenido rápidamente sin proveer el valor SHA-1 del blob, es usando git show, así:
git show :<STAGE>:everyone.md
Por ejemplo, para obtener el contenido de la misma versión como con git cat-file -p <BLOB_SHA_FOR_STAGE_2>, puedes escribir git show :2:everyone.md.
Git registra los tres estados de los tres confirmaciones en el índice de esta forma al comienzo de la fusión. Luego continúa con el algoritmo de fusión de tres vías para resolver rápidamente los casos sencillos.
En el caso que todas las tres áreas de preparación coincidan, entonces la selección es trivial.
Si un lado hiciera un cambio mientras los otros no lo hicieron - eso es, área de preparación 1 coincide con el área de preparación 2 - entonces elegimos el área de preparación 3, o vice versa. Eso es exactamente lo que sucedió con let_it_be.md y across_the_universe.md.
En caso de una supresión en la rama entrante, por ejemplo, y dado que no hubieron cambios en la rama actual, entonces veríamos que el stage 1 coincide con el stage 2, pero no hay stage 3. En este caso, git merge quita el archivo para la versión fusionada.
Lo que es realmente interesante aquí es para coincidir, Git no necesita los archivos actuales. Más bien, se puede basar en los valores SHA-1 de los blobs correspondientes. De esta forma, Git puede detectar fácilmente el estado en el que se encuentra un archivo.
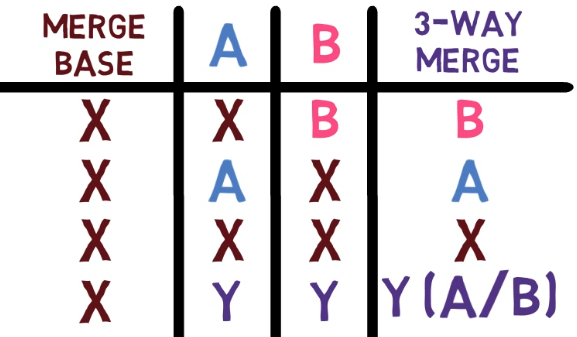
Para everyone.md tiene este caso especial - donde el área de preparación 1, el área de preparación 2 y el área de preparación 3 son todos distintos uno del otro. Eso es, tienen SHAs de blob distintos. Es momento de ir más profundo y entender el conflicto de fusión. 😊
Una forma de hacer eso sería simplemente usar git diff. En un capítulo anterior, examinamos git diff en detalle, y vimos que muestra las diferencias entre varias combinaciones del árbol de trabajo, del índice o de las confirmaciones.
Pero git diff también tiene un modo especial para ayudar con los conflictos de fusión:
git diff
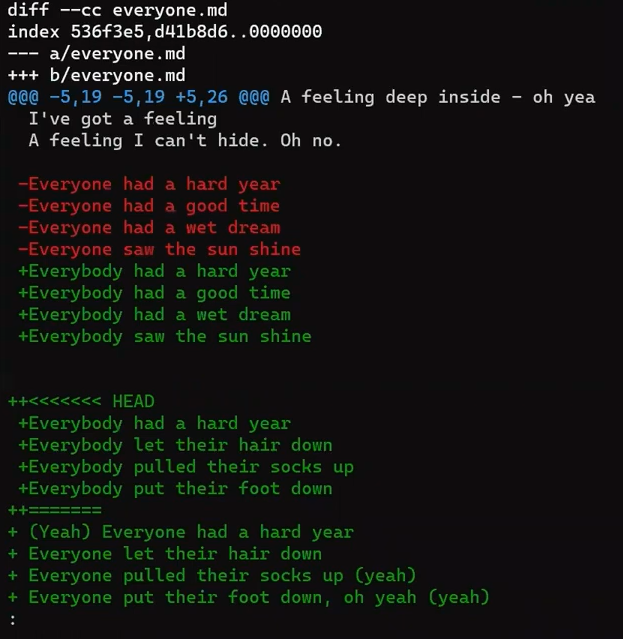
git diff during a merge conflictEsta salida podría ser confuso al principio, pero una vez que te acostumbras, es bastante claro. Empecemos por entenderlo, y luego veamos cómo puede resolver los conflictos con otras herramientas mas visuales.
La sección en conflictos está separado por los signos "iguales" (===), y marcado con las ramas correspondientes. En este contexto, "el nuestro" es la rama actual. En este ejemplo, sería john_branch_4, la rama a la que HEAD estaba apuntando cuando iniciamos el comando git merge. "El suyo" es el MERGE_HEAD, la rama que estamos fusionando - en este caso, paul_branch_4.
Así que git diff sin ningun argumento especial muestra los cambios entre el árbol de trabajo y el índice - el cual en este caso son los conflictos aún por resolver. La salida no incluye cambios en el área de preparación, lo cual es conveniente para resolver el conflicto.
Es tiempo de resolver esto manualmente. ¡Qué divertido!
Así, ¿por qué esto es un conflicto?
Para Git, Paul y John hicieron distintos cambios a la misma línea, por unas pocas líneas. John lo cambió a una cosa, y Paul lo cambió a otra cosa. Git no puede decidir cuál es el correcto.
Este es no es el caso para las últimas líneas, como la línea solía ser "Everyone had a hard year" en la base de fusión. Paul no ha cambiado esta línea, o las líneas que le rodean, así su versión en paul_branch_4 o "el suyo" en nuestro caso, se pone de acuerdo con el merge_base. Aunque la versión de John, "el nuestro", es distinto. Así git merge puede decidir fácilmente que tome esta versión.
Pero, ¿qué hay sobre las líneas en conflicto?
En este caso, sé lo que quiero, y eso es en realidad una combinación de estas líneas. Quiero que las líneas comiencen con "Everybody", siguiendo el cambio de John, pero también que incluya los "yeah" de Paul. Así que ve y crea la versión deseada editando a everyone.md:
nano everyone.md
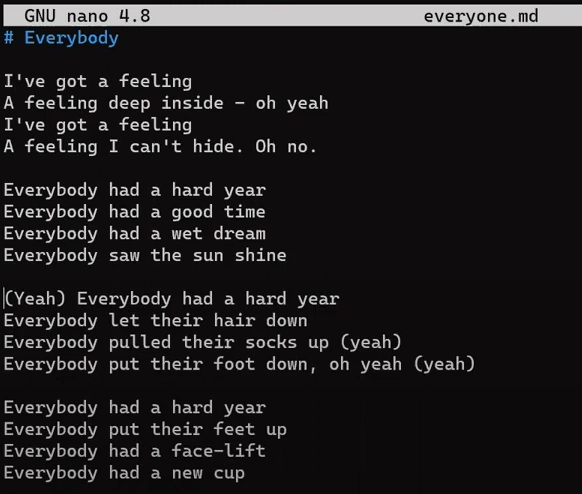
Para comparar el archivo resultante con lo que tenías en la rama previa a la fusión, puedes ejecutar:
git diff --ours
De manera similar, si deseas ver cuánto difiere el resultado de la fusión de la rama que fusionaste en nuestra rama, puedes ejecutar:
git diff --theirs
Inclusive puedes ver cuán distinto es el resultado de ambos lados usando:
git diff --base
Ahora puedes poner en el área de preparación la versión arreglada:
git add everyone.md
Después de poner en el área de preparación, si miras en git status, no verás conflictos:
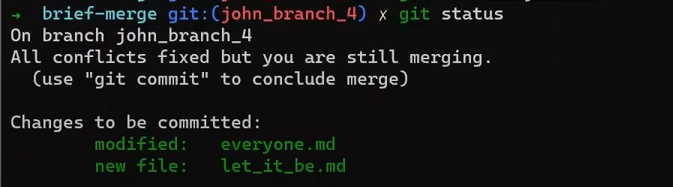
everyone.md, there are no conflictsAhora puedes simplemente usar git commit, y Git te presentará con un mensaje de confirmación conteniendo los detalles sobre la fusión. Puedes modificarlo si quisieras, o dejarlo como está. Sin importar del mensaje de confirmación, Git creará un "mensaje de fusión" - eso es, una confirmación con más de un precesor.
Para validar eso, considera el historial:
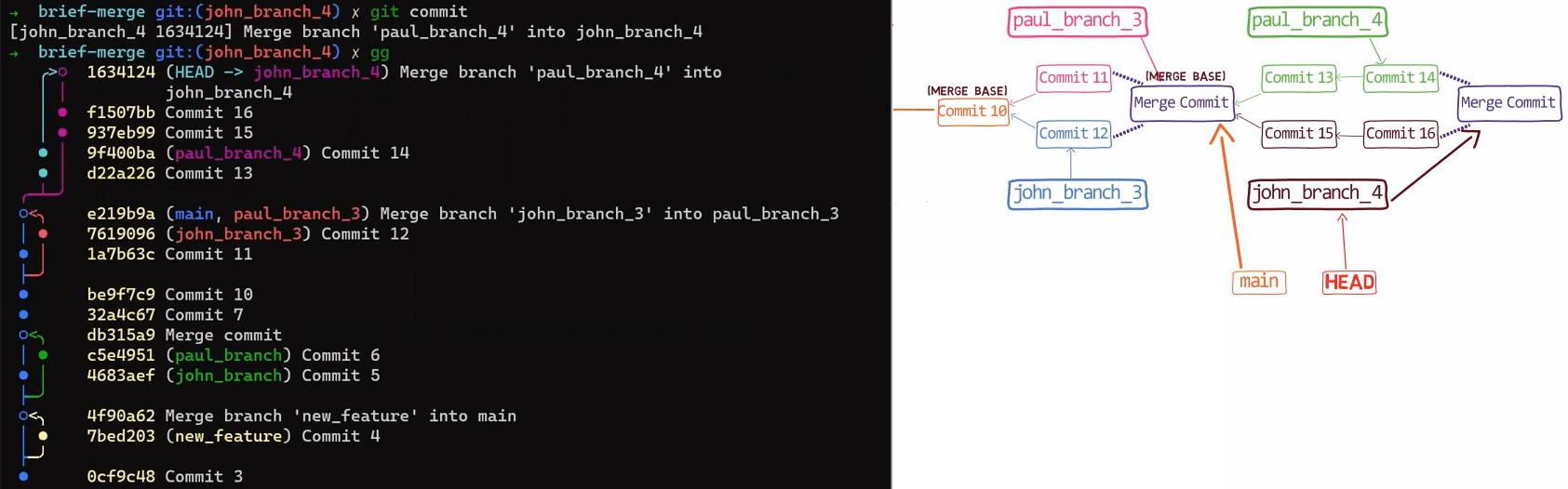
john_branch_4 ahora apunta a la nueva confirmación de fusión. La rama entrante, "el suyo", en este caso, paul_branch_4, se mantiene donde estaba.
Cómo usar VS Code para resolver los conflictos
Ahora verás cómo resolver el mismo conflicto usando una herramienta gráfica. Para este ejemplo, use VS Code, el cual es un editor de código popular y gratis. Hay muchas otras herramientas, pero el proceso es similar, así que solo mostraré VS Code como un ejemplo.
Primero, volvamos al estado antes de la fusión:
git reset --hard HEAD~
E intentemos fusionar otra vez:
git merge paul_branch_4
Deberías estar nuevamente al mismo estado:
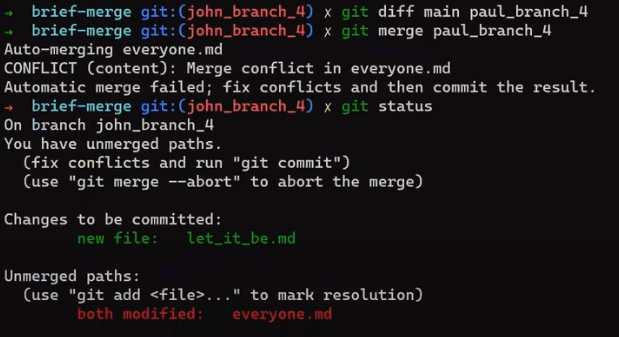
Veamos cómo aparece esto en VS Code:
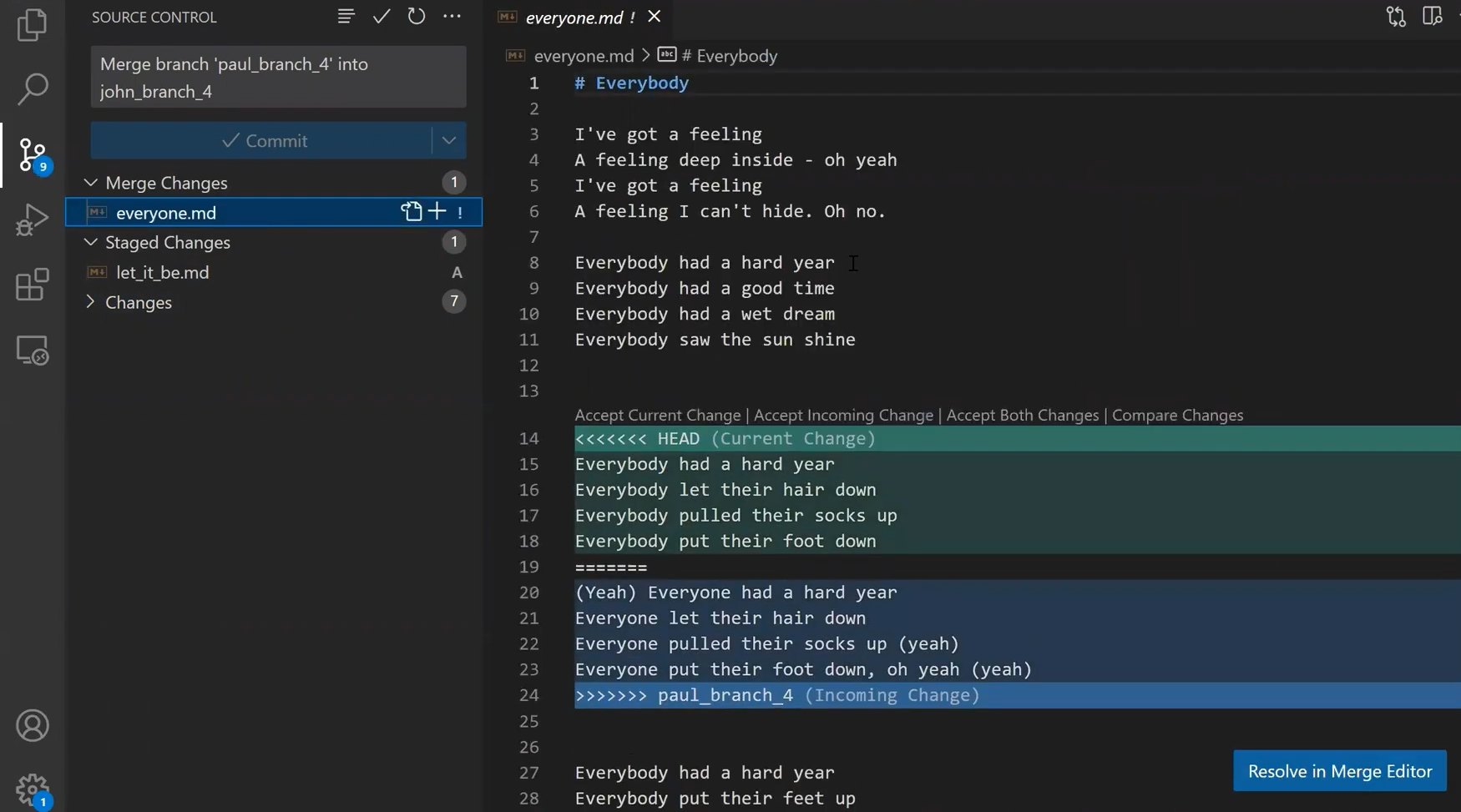
VS Code marca las distintas versiones con "Current Change" - el cual es la versión de la "nuestra", el actual HEAD, y "Cambio Entrante" para la rama que estamos fusionando en la rama activa. Puedes aceptar uno de los cambios (o ambos) haciendo clic en una de las opciones.
Si hiciste clic en Resolver en Editor de Fusión, obtendrás una vista mas visual del estado. VS Code muestra el estado de cada línea:
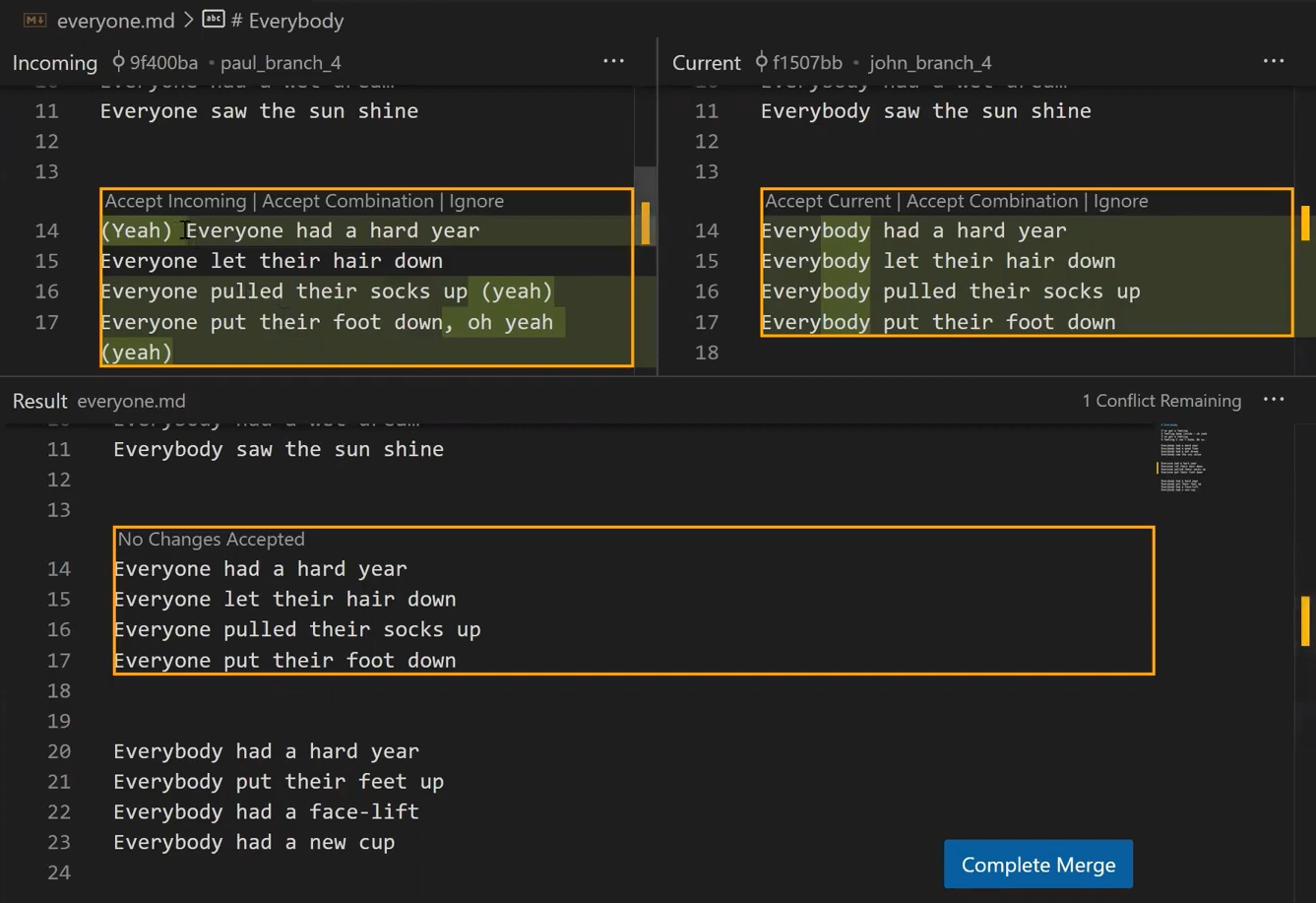
Si miras con atención, verás que VS Code muestra cambios dentro de las palabras - por ejemplo, muestra que "Everyone" fue cambiado a "Everybody", marcando las partes cambiadas.
Puedes aceptar cualquier versión, o puedes aceptar una combinación. En este caso, si haces clic en "Aceptar Combinación", obtienes este resultado:
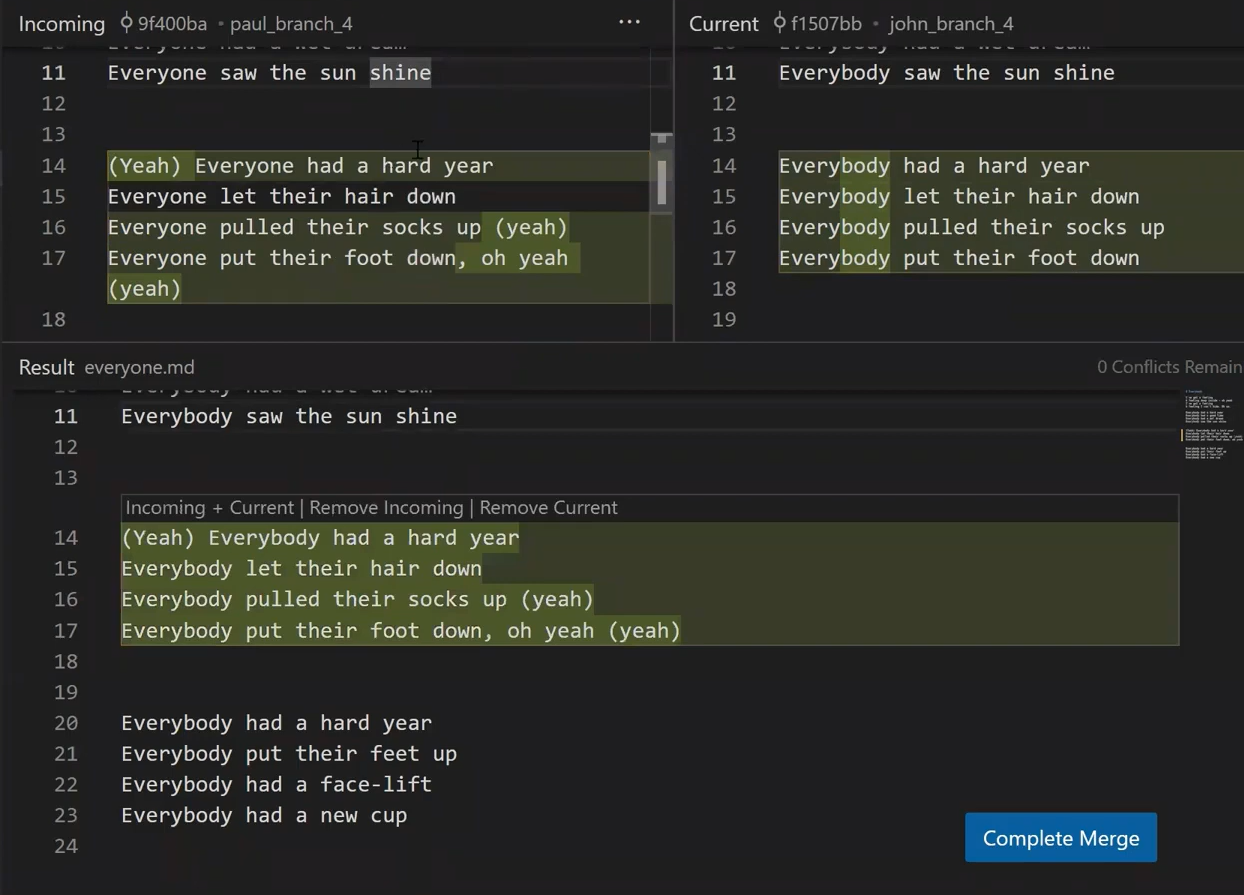
¡VS Code hizo un excelente trabajo! El mismo algoritmo de fusión de tres vías fue implementado aquí y usado a el nivel de palabra en vez a nivel de línea. Así que VS Code fue capaz en realidad de resolver este conflicto de una forma impresionante. Por supuesto, puedes modificar la sugerencia de VS Code, pero proveyó un comienzo muy bueno.
Una Herramienta Poderosa adicional
Bueno, este fue la primera vez en este libro que he usado una herramienta con una interfaz de usuario gráfica. De hecho, las interfaces gráficas pueden ser convenientes para entender lo que está sucediendo cuando estás resolviendo conflictos de fusión.
Sin embargo, como en muchos otros casos, cuando necesitamos realmente entender lo que está sucediendo, la línea de comando se vuelve práctico. Así que, volvamos a la línea de comandos y aprendamos una herramienta que nos puede venir bien en casos mas complicados.
De nuevo, vuelve al estado antes de la fusión:
git reset --hard HEAD~
Y fusiona:
git merge paul_branch_4
Y digamos, no estás seguro exactamente de lo que pasó. ¿Por qué hay un conflicto? Un comando muy útil sería:
git log -p --merge
Como recordatorio, git log muestra el historial de confirmaciones que son alcanzables desde HEAD. Agregando -p le dice a git log que muestre las confirmaciones juntamente con los diffs que introdujeron. El argumento --merge hace que el comando muestre todas las confirmaciones que contienen cambios relevantes a cualquier archivo que no están en el área de preparación, en cualquier rama, junto con sus diffs.
Esto te puede ayudar en identificar los cambios en el historial que llevaron a los conflictos. Así que en este ejemplo, verías:
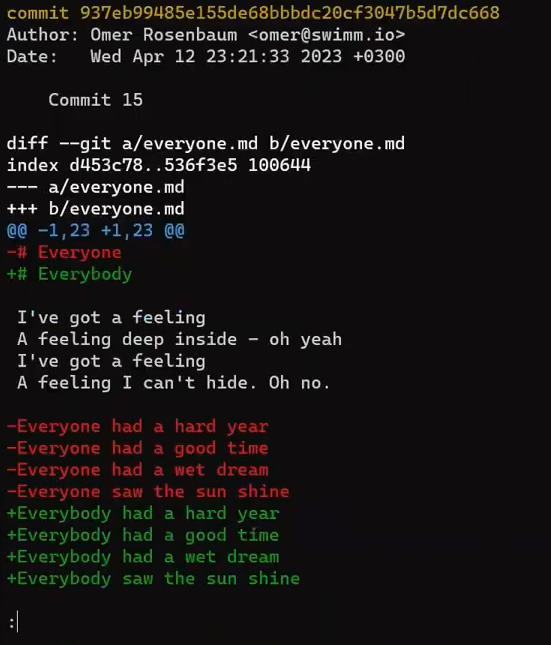
git log -p --mergeLa primer confirmación que vemos es "Commit 15", ya que en ésta confirmación John modificó everyone.md, un archivo que todavía tiene conflictos. Luego, Git muestra "Commit 13", donde Paul cambió everyone.md:
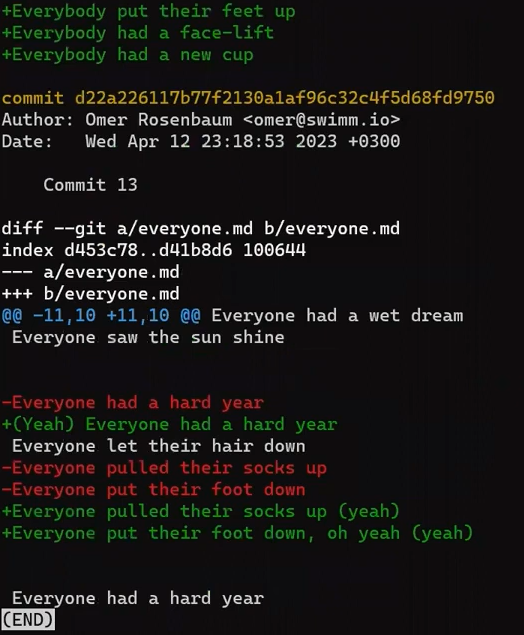
git log -p --merge - continuedFíjate que git log --merge no mencionó confirmaciones previas que cambiaron a everyone.md antes de "Commit 13", ya que no afectaron el conflicto actual.
De esta forma, git log te dice que todo lo que necesitas saber para entender el proceso que te llevó al estado de conflicto actual. ¡Genial! 😎
Usando la línea de comandos, también puedes preguntarle a Git que tome solamente un lado de los cambios - sea "el nuestro" o "el suyo", inclusive para un archivo específico.
También puedes instruir a Git que tome algunas partes de los diffs de un archivo y otro de otro archivo. Proveeré enlances que describen cómo hacer eso en los recursos adicionales de este capítulo en el apéndice.
Para la mayor parte, puedes lograr eso bastante fácil, sea manualmente o desde la UI de tu IDE favorito.
Por ahora, es tiempo de recapitular.
Recapitulando - Entendiendo Git Merge
En este capítulo, tuviste una vista general extensiva de fusión con Git. Aprendiste que fusionar es el proceso de combinar los cambios recientes desde varias ramas en una sola confirmación. La nueva confirmación tiene dos predecesores - esas confirmaciones los cuales han sido las puntas de las ramas que fueron fusionados.
Consideramos una fusión directa sencilla, lo cual es posible cuando una rama difiere de la rama base, y luego agregamos confirmaciones por encima de la rama base.
Luego consideramos fusiones de tres vías, y explicamos el proceso de tres estados:
- Primero, Git localiza la base de fusión. Como recordatorio, este es la primer confirmación que es alcanzable desde ambas ramas.
- Segudno, Git calcula los dos diffs - un diff desde la base de fusión a la primer rama, y otro diff desde la base de fusión a la segunda rama. Git genera parches basados en esos diffs.
- Tercero y último, Git aplica ambos parches a la base de fusión usando un algoritmo de fusión de 3 vías. El resultado es el estado de la nueva confirmación de fusión.
Indagamos profundamente en el proceso de fusión de 3 vías, sea a nivel de archivo o a nivel de hunk. Consideramos cuando Git es capaz de basarse en una fusión de 3 vías para resolver automáticamente los conflictos, y cuando no puede.
Viste la salida de git diff cuando estamos en un estado de conflicto, y cómo resolver los conficltos manualmente o con VS Code.
Hay mucho más que decir sobre las fusiones - diferentes estrategias de fusión, fusiones recursivas, y así sucesivamente. Con todo, creo que este capítulo cubrió todo lo necesario de esa forma tienes un entendimiento robusto de lo que es una fusión, y qué sucede por debajo en la vasta mayoría de casos.
Recursos relacionados a los Beatles
- https://www.the-paulmccartney-project.com/song/ive-got-a-feeling/
- https://www.cheatsheet.com/entertainment/did-john-lennon-or-paul-mccartney-write-the-classic-a-day-in-the-life.html/
- http://lifeofthebeatles.blogspot.com/2009/06/ive-got-feeling-lyrics.html
Capítulo 8 - Entendiendo Git Rebase
Una de las herramientas más poderosas que tiene un desarrollador en su caja de herramientas es git rebase. Aunque es notorio por ser complejo e incomprendido.
La verdad es, si entiendes lo que hace en realidad, git rebase es una herramienta muy elegante, y directa para alcanzar muchísimas cosas diferentes en Git.
En los capítulos previos en esta parte, aprendiste qué son los diffs de Git, lo que es una fusión, y cómo Git resuelve los conflictos de fusión. En este capítulo, entenderás lo que es rebase de Git, por qué es diferente de merge, y cómo hacer rebase (sobrescribir la base) con confianza.
Recapitulación Corta - ¿Qué es Git Merge?
Por debajo, git rebase y git merge son cosas muy muy distintas. Entonces, ¿por qué la gente los compara todo el tiempo?
La razón es su uso. Cuando se trabaja con Git, usualmente trabajamos en distintas ramas e introducimos cambios a esas ramas.
En el capítulo previo, consideramos el ejemplo donde John y Paul (de los Beatles) eran co-autores de nueva canción. Comenzaron desde la rama main, y luego cada uno difirió, modificaron la letra, y confirmaron sus cambios.
Luego, los dos querían integrar sus cambios, lo cual es algo que sucede muy frecuente cuando se trabaja con Git.
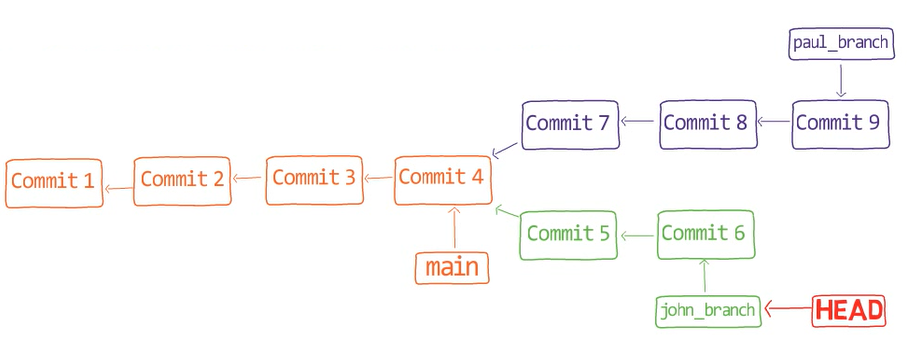
paul_branch and john_branch diverged from mainHay dos formas principales para integrar cambios introducidos en diferentes ramas en Git, o en otras palabras, en diferentes confirmaciones e historiales de confirmación. Estos son merge y rebase.
En el capítulo anterior, llegamos a saber git merge bastante bien. Vimos que cuando realizamos una fusión, creamos una confirmación de fusión - donde los contenidos de esta confirmación son una combinación de las dos ramas, y también tiene dos predecesores, una en cada rama.
Así que, digamos que estás en la rama john_branch (asumiendo el historial representado en el dibujo de arriba), y ejecutas git merge paul_branch. Llegarás a este estado - donde en john_branch, hay una nueva confirmación con dos predecesores. El primero será la confirmación en la rama john_branch donde el HEAD estaba apuntando a un estado antes de realizar la fusión - en este caso, "Commit 6". El segundo será la confirmación a la que apunta paul_branch, "Commit 9".
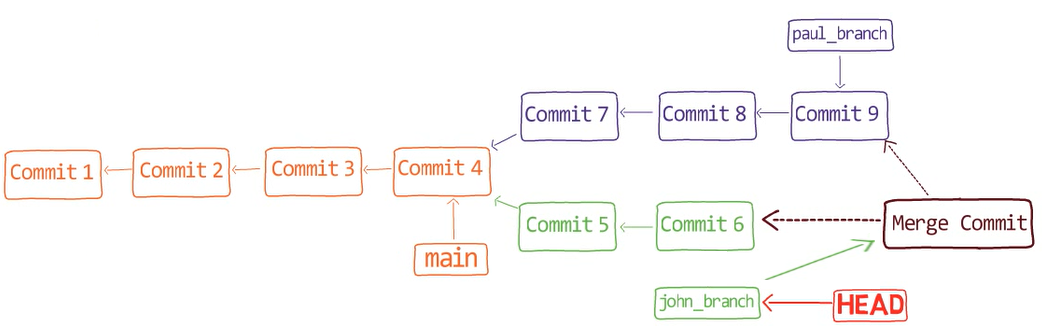
git merge paul_branch: a new Merge Commit with two parentsMira otra vez al gráfico del historial: creaste un historial divergente. Puedes ver dónde se ramificó y dónde se fusionó nuevamente.
Así que cuando usas git merge, no puedes reescribir el historial - sino, que agregas una confirmación al historial existente. Y específicamente, una confirmación que crea un historial divergente.
¿Cómo se diferencia git rebase de git merge?
Cuando se usa git rebase, algo distinto ocurre.
Comencemos con el panorama general: si estás en paul_branch, y usas git rebase john_branch, Git va al ancestro común de la rama de John y de Paul. Luego tomas los parches introducidos en las confirmaciones de la rama de Paul, y aplicar esos cambios a la rama de John.
Así que aquí, usas rebase para tomar los cambios que fueron confirmados en una rama - la rama de Paul - y reproducirlos en una rama distinta, john_branch.
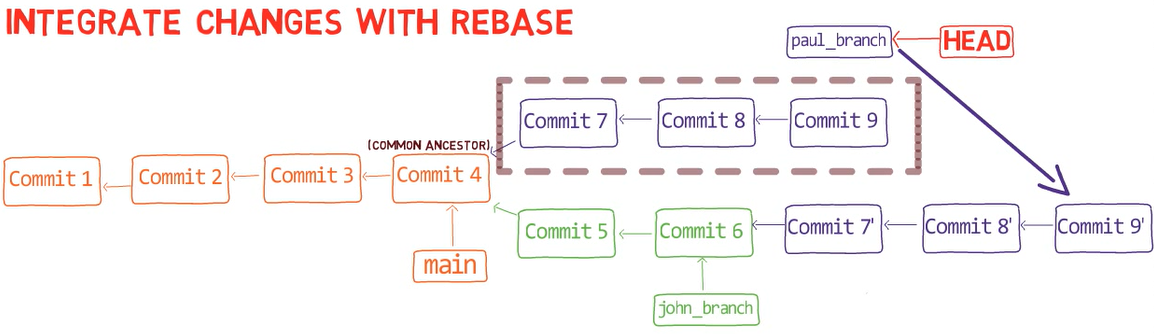
john_branchEspera, ¿qué significa eso?
Ahora tomaremos esto poco a poco para asegurarnos que entiendes completamente lo que estás sucediendo por debajo 😎.
cherry-pick como una base para Rebase
Es útil pensar de rebase como realizar git cherry-pick - un comando que toma una confirmación, calcula el parche que ésta confirmación introduce al calcular la diferencia entre la confirmación del predecesor y la confirmación misma, y luego cherry-pick "repite" esta diferencia.
Hagamos esto manualmente.
Si miramos la diferencia introducido por "Commit 5" al hacer git diff main <SHA_OF_COMMIT-5>:
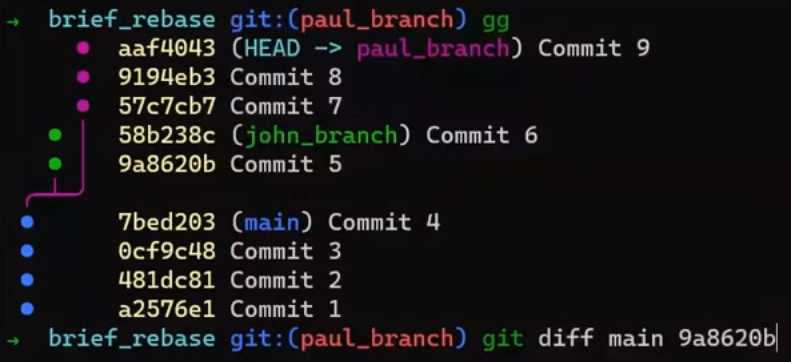
git diff to observe the patch introduced by "Commit 5"Como siempre, se te anima en ejecutar los comandos tú mismo mientras lees este capítulo. A menos que se diga otra cosa, usaré el siguiente repositorio:
https://github.com/Omerr/rebase_playground.git
Te recomiendo que lo clones de forma local y tener el mismo punto de inicio que estoy usando para este capítulo.
Puedes ver eso en esta confirmación, John comenzó trabajando en una canción llamada "Lucy in the Sky with Diamonds":
git diff - the patch introduced by "Commit 5"Como recordatorio, también puedes usar el comando git show para obtener la misma salida:
git show <SHA_OF_COMMIT_5>
Ahora, si haces cherry-pick a esta confirmación, introducirás este cambio específicamente, en la rama activa. Cambia a main primero:
git checkout main (or git switch main)
Y crea otra rama:
git checkout -b my_branch (or git switch -c my_branch)
my_branch that branches from mainLuego, haz cherry-pick a "Commit 5":
git cherry-pick <SHA_OF_COMMIT_5>
cherry-pick to apply the changes introduced in "Commit 5" onto mainConsidera el log (salida de git lol):

git lolParece que copiaste-pegaste el "Commit 5". Recuerda que inclusive tiene el mismo mensaje de confirmación, e introduce los mismos cambios, e inclusive apunta al mismo objeto de árbol como el "Commit 5" original en este caso - todavía es un objeto de confirmación distinto, como si fuese creado con una marca de tiempo distinto.
Mirando a los cambios, usando git show HEAD
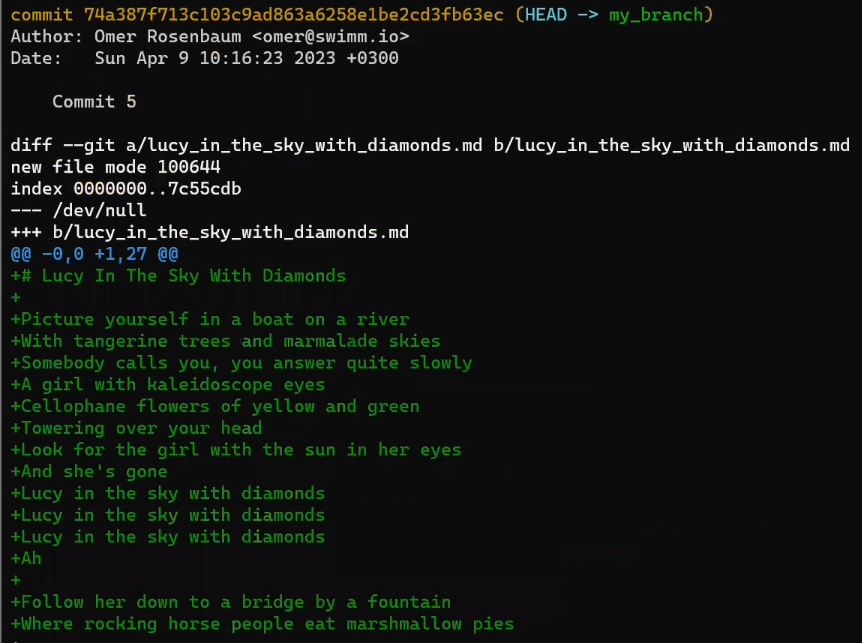
git show HEADSon lo mismo como los "Commit 5".
Y por supuesto, si miras al archivo (digamos, usando nano lucy_in_the_sky_with_diamonds.md), estará en el mismo estado que estaba después del "Commit 5" original.
¡Genial! 😎
Ahora puedes quitar la nueva rama así no aparece en tu historial cada vez:
git checkout main
git branch -D my_branch
Más allá de cherry-pick - Cómo usar git rebase
Puedes ver a git rebase como una forma de realizar múltiples cherry-pick uno después del otro - eso es, "repetir" múltiples confirmaciones. Esto no es lo único que puedes hacer con rebase, pero es un buen punto de comienzo para nuestra explicación.
¡Es tiempo de jugar con git rebase!
Antes, hiciste fusión de paul_branch en john_branch. ¿Qué debería de pasar si hicieras rebase de paul_branch por encima de john_branch? Obtendrías un historial muy distinto.
En esencia, parecería como si tomáramos los cambios introducidos en las confirmaciones de paul_branch, y repitiéramos en john_branch. El resultado sería un historial linear.
Para entender el proceso, te proveeré la vista de alto nivel, y luego indagaré más profundo en cada paso. El proceso de hacer rebase en una rama por encima de otra rama es como lo siguiente:
- Encuentra el ancestro común.
- Identifica las confirmaciones a ser "repetidos".
- Para cada confirmación
X, calculadiff(parent(X), X), y lo almacena como unpatch(X). - Mueve a
HEADa la nueva base. - Aplica los parches generados en orden en la rama de destino. Cada vez, crea un nuevo objeto de confirmación con el nuevo estado.
El proceso de hacer nuevas confirmaciones con el mismo conjunto de cambios que los existentes también se le llama "repetir" esas confirmaciones, un término que ya hemos usado.
Tiempo de practicar con Rebase
Antes de ejecutar el siguiente comando, asegúrate de tener a john_branch localmente, así que ejecuta:
git checkout john_branch
Comienza desde la rama de Paul:
git checkout paul_branch
Este es el historial:
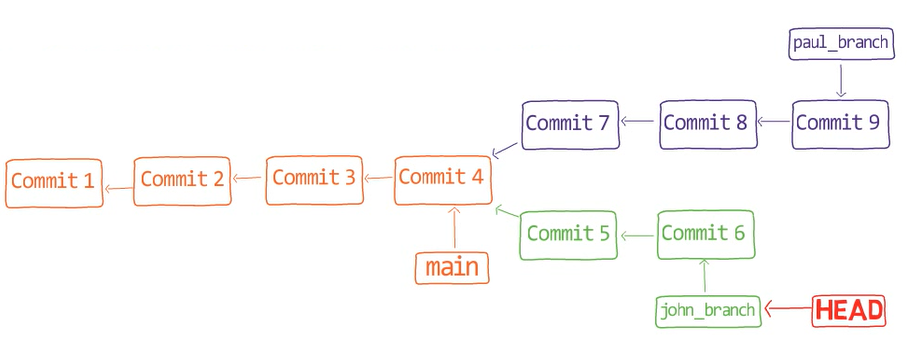
git rebaseY ahora, la parte emocionante:
git rebase john_branch
Y observa el historial:
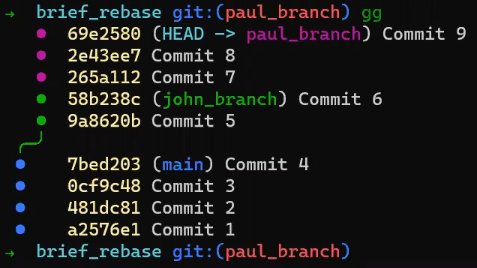
Con git merge agregaste al historial, mientras que con git rebase reescribes el historial. Creas nuevos objetos de confirmación. Además, el resultado es un gráfico de historial linear - en vez de un gráfico divergente.
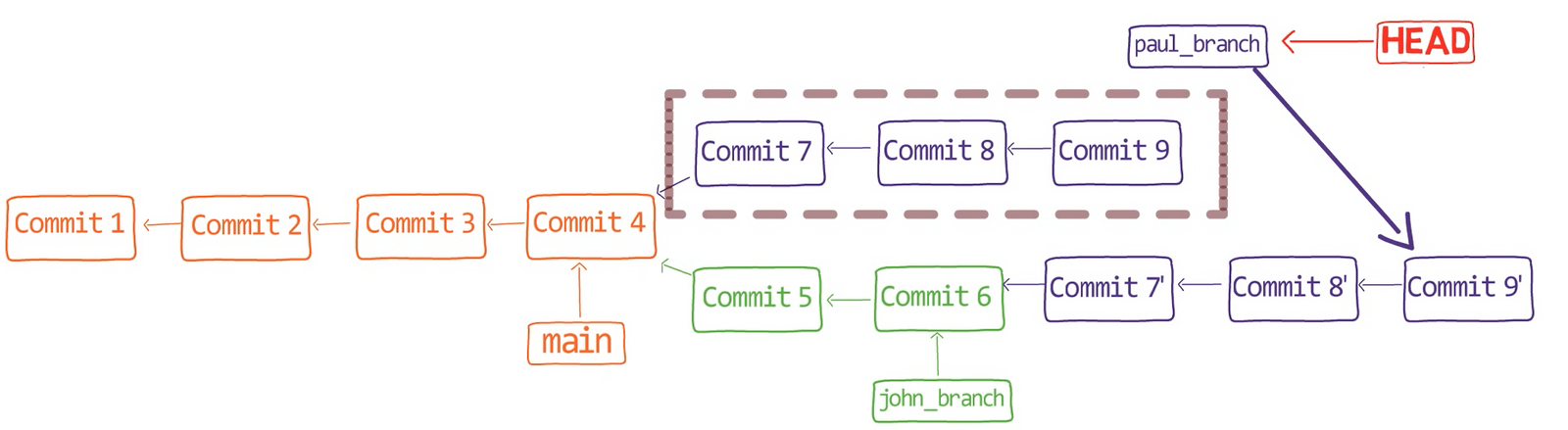
En esencia, "copiaste" las confirmaciones que estaban en paul_branch y que fueron introducidos después de "Commit 4", y los "pegaste" por encima de john_branch.
El comando se llama "rebase", porque cambia la confirmación base de la rama de donde se ejecuta. Eso es, en tu caso, antes de ejecutar git rebase, la base de paul_branch era "Commit 4" - ya que aquí es donde la rama "nació" (desde main). Con rebase, le pediste a Git que le diera otra base - eso es, pretender que haya nacido desde "Commit 6".
Para hacer eso, Git tomó lo que solía ser "Commit 7", y "repitió" los cambios introducidos en esta confirmación en "Commit 6". Luego creó un nuevo objeto de confirmación. Este objeto difiere del "Commit 7" original en tres aspectos:
- Tiene una marca de tiempo distinto.
- Tiene una confirmación antecesora distinta - "Commit 6", en vez de "Commit 4".
- El objeto árbol al que está apuntado es distinto - como si los cambios fueran introducidos en el árbol apuntado por "Commit 6", y no el árbol apuntado por "Commit 4".
Fíjate la última confirmación aquí, "Commit 9". La copia instantánea que representa (eso es, el árbol al que apunta) es exactamente el mismo árbol que obtendrías al hacer fusión de las dos ramas. El estado de los archivos en tu repositorio Git sería el mismo como si usaras git merge. Es solamente el historial que es diferente, y los objetos de confirmación por supuesto.
Ahora, puedes usar simplemente:
git checkout main
git merge paul_branch
Hm..... ¿qué sucedería si ejecutas este último comando? Considera el historial de confirmación de nuevo, después de verificar a main:
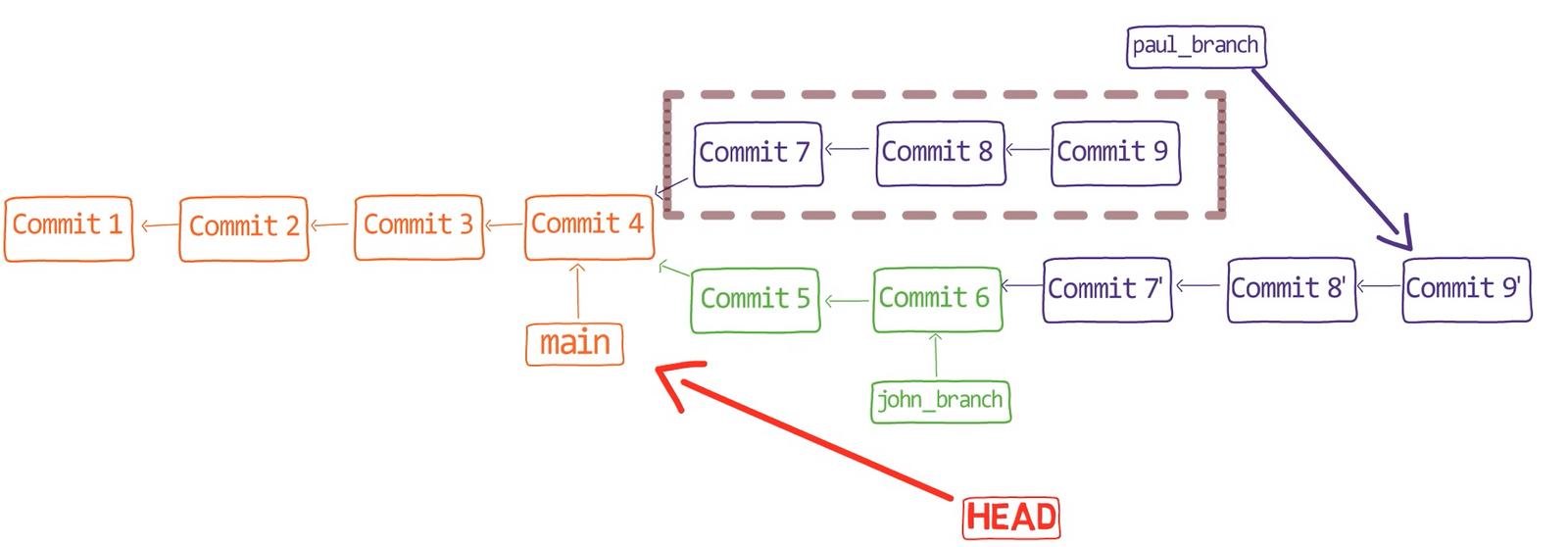
main¿Qué significaría el hacer fusión de main y paul_branch?
En efecto, Git puede simplemente hacer una fusión directa, ya que el historial es completamente linear (si necesitas un recordatorio sobre fusiones directos, mira el capítulo previo). Como resultado, main y paul_branch ahora apunta a la misma confirmación:
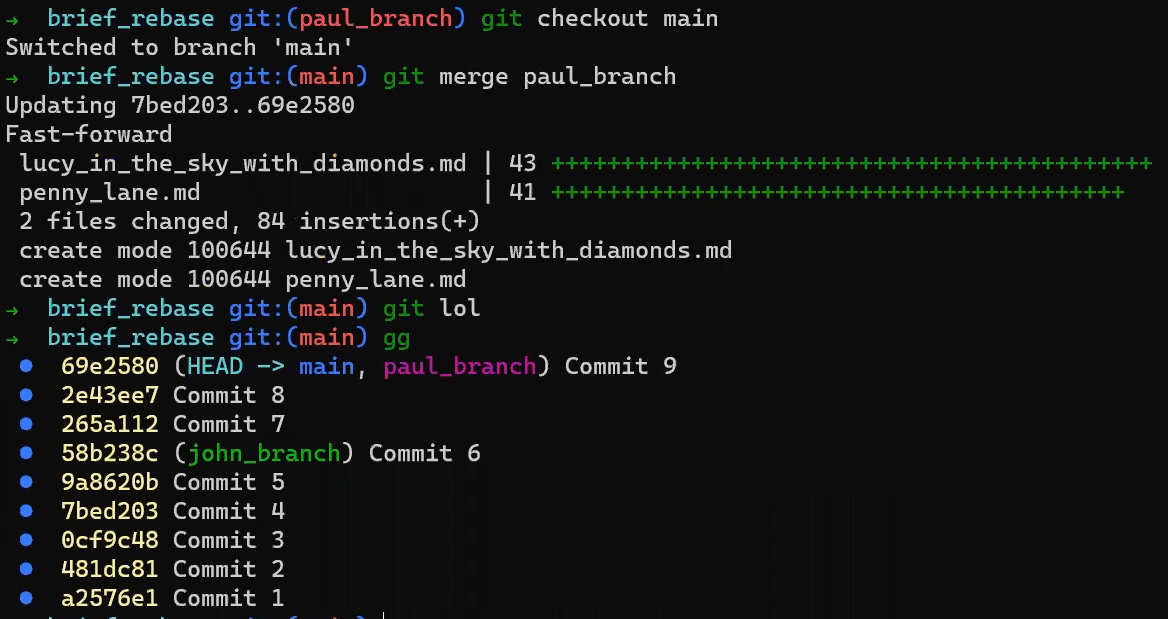
Rebase avanzado en Git
Ahora que entiendes lo básico de rebase, es tiempo de considerar casos más avanzados, donde conmutadores y argumentos adicionales al comando rebase serán útiles.
En el ejemplo previo, cuando solamente usaste rebase (sin conmutadores adicionales), Git repitió todas las confirmaciones desde el ancestro común a la punta de la rama actual.
Pero rebase es un super poder. Es un comando todopoderoso capaz de.. bueno, reescribir el historial. Y puede ser útil si quieres modificar el historial para hacer el tuyo propio.
Deshaz la última fusión haciendo que main apunte a "Commit 4" nuevamente:
git reset --hard <ORIGINAL_COMMIT 4>
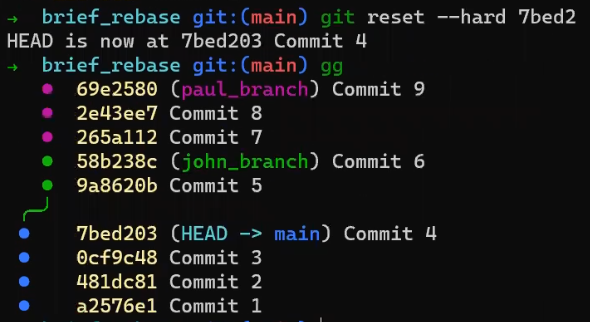
Y deshaz el rebasing usando:
git checkout paul_branch
git reset --hard <ORIGINAL_COMMIT 9>
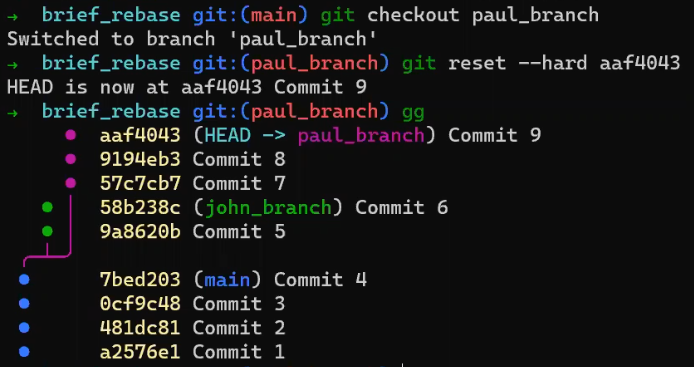
Fíjate que obtuviste exactamente el mismo historial que solías tener:
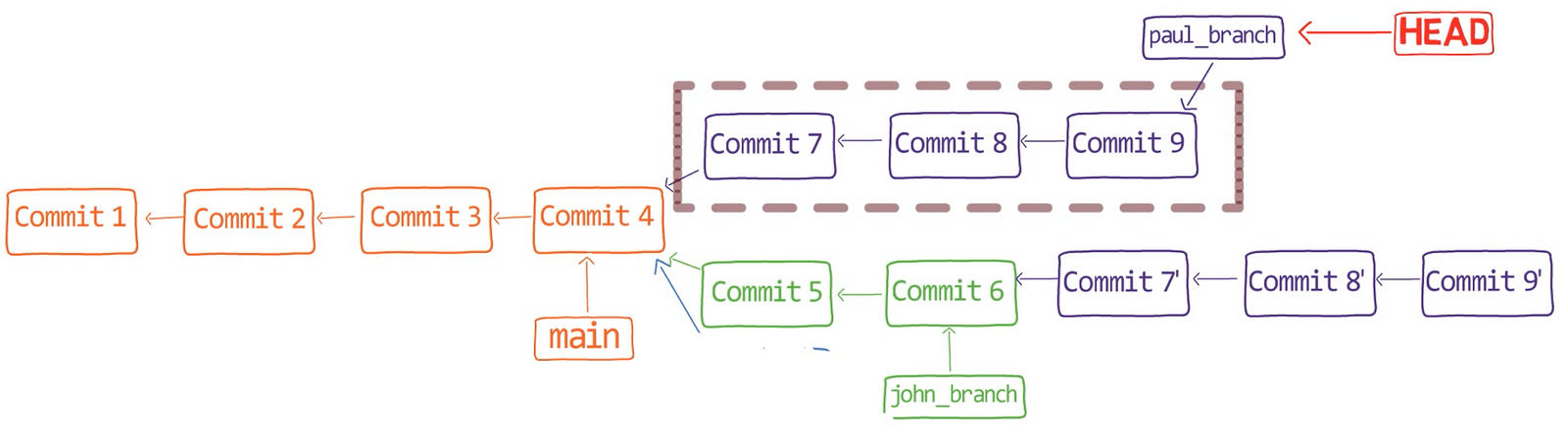
Para ser claro, "Commit 9" no sólo desaparece cuando no es alcanzable desde el HEAD actual. Al contrario, todavía es almacenado en la base de datos de objetos. Y como usaste git reset ahora para hacer que HEAD apunte a esta confirmación, fuiste capaz de recuperarlo, y también sus confirmaciones antecesoras ya que también están almacenados en la base de datos. Bastante genial, ¿hah? 😎
Aprenderás más sobre git reset en la próxima parte, donde discutimos sobre deshacer cambios en Git.
Mira los cambios que Paul introdujo:
git show HEAD
git show HEAD shows the patch introduced by "Commit 9"Sigue yendo hacia atrás en el gráfico de confirmación:
git show HEAD~
git show HEAD~ (same as git show HEAD~1) shows the patch introduced by "Commit 8"Y una confirmación más allá:
git show HEAD~2
git show HEAD~2 shows the patch introduced by "Commit 7"Tal vez Paul no quiere este tipo de historial. Más bien, quiere que parezca como si se introdujera los cambios en "Commit 7" y "Commit 8" como una sola confirmación.
Para eso, puedes usar un rebase interactivo. Para hacer eso, agregamos el conmutador -i (o --interactive) al comando rebase:
git rebase -i <SHA_OF_COMMIT_4>
O, ya que main está apuntando a "Commit 4" , podemos ejecutar:
git rebase -i main
Ejecutando este comando, le dices a Git que use una nueva base, "Commit 4". Así que le pides a Git que vuelva atrás a todas las confirmaciones que fueron introducidos después de "Commit 4" y que son alcanzables desde el HEAD actual, y repita esas confirmaciones.
Para cada confirmación que es repetido, Git nos pregunta que nos gustaría hacer con él:
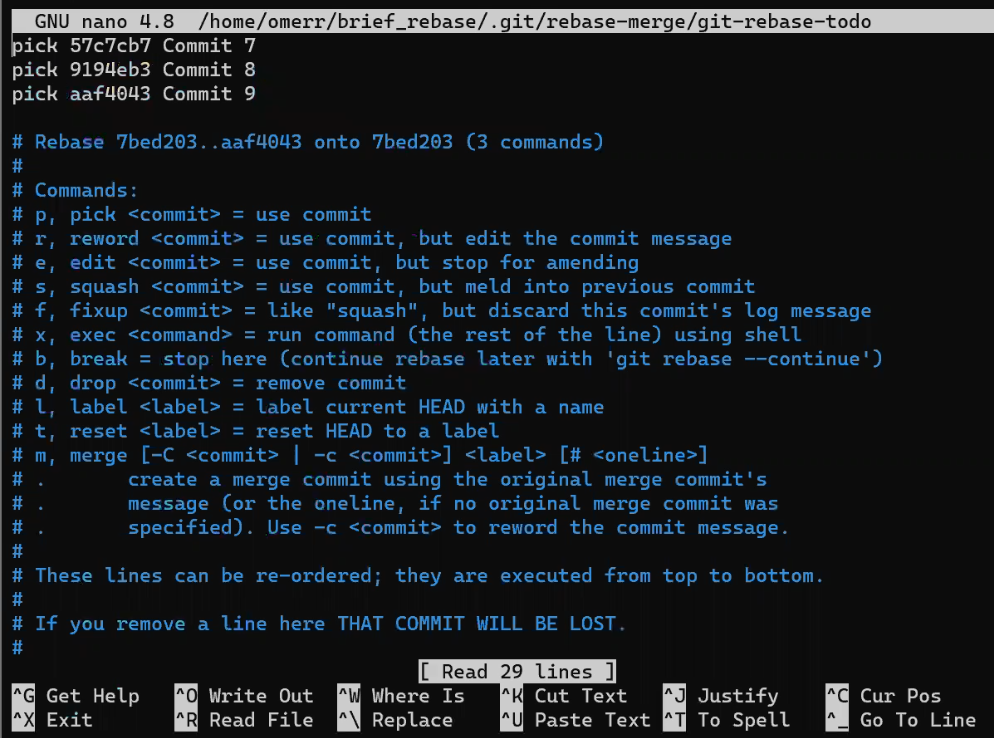
git rebase -i main prompts you to select what to do with each commitEn este contexto es útil imaginarse de una confirmación como un parche. Eso es, "Commit 7", como "el parche que "Commit 7" introdujo por encima de su antecesor".
Una opción es usar pick. Este es el comportamiento predeterminado, el cual le dice a Git que repita los cambios introducidos en esta confirmación. En este caso, si sólo lo dejas como está - y haces pick de todas las confirmaciones - obtendrás el mismo historial, y Git no creará nuevos objetos de confirmación.
Otra opción es squash. Una confirmación aplastada (del inglés "squashed") tendrá su contenido "doblado" (del inglés "folded") en los contenidos de la confirmación que le precede. Así que en nuestro caso, a Paul le gustaría aplastar "Commit 8" en "Commit 7":
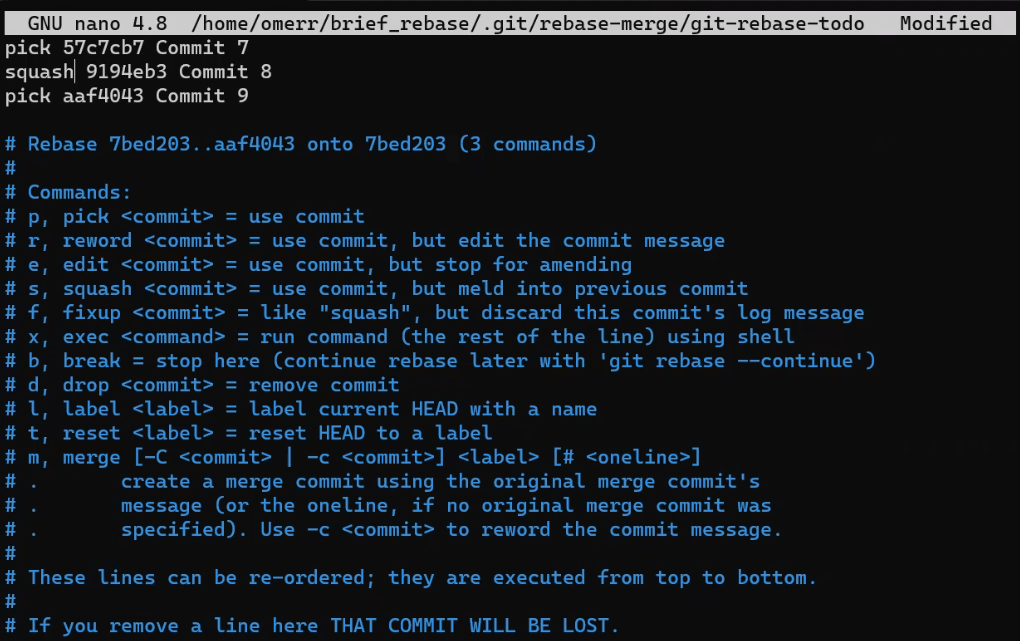
Como puedes ver, git rebase -i provee opciones adicionales, pero no lo veremos en este capítulo. Si permites a rebase que se ejecute, se te mostrará una ventana para seleccionar un mensaje de confirmación para la nueva confirmación creada (eso es, el que introdujo los cambios de "Commit 7" y "Commit 8"):
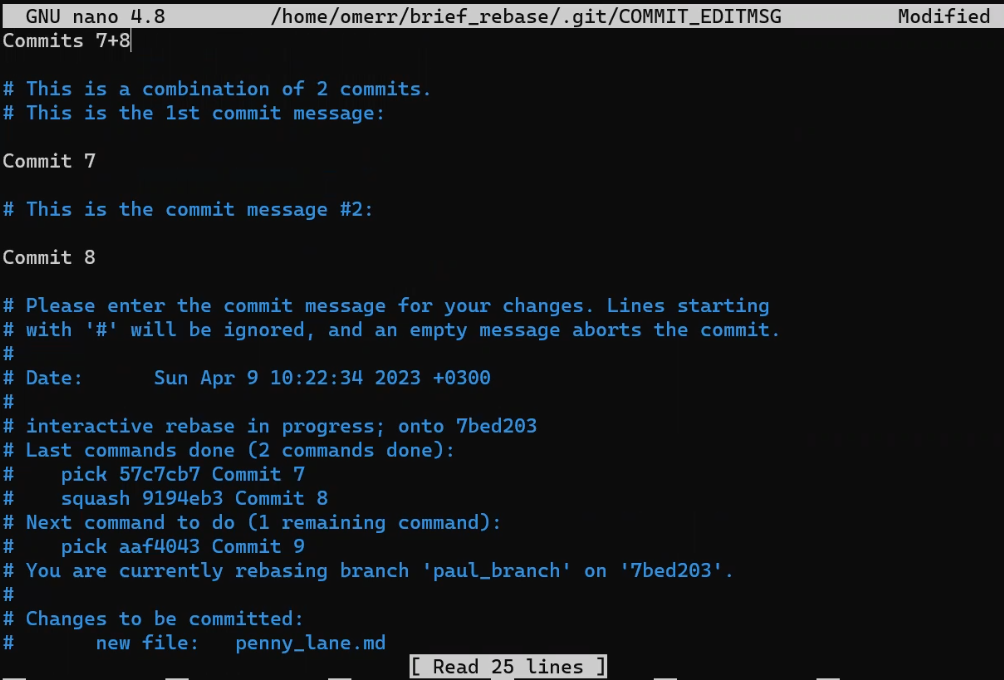
Y mira el historial:
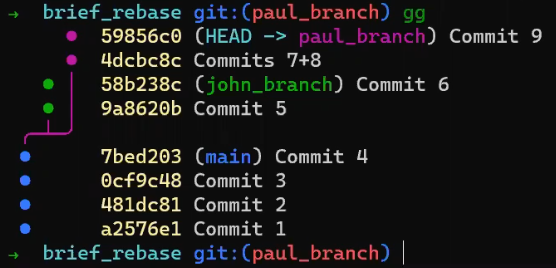
¡Exactamente lo que queríamos! En paul_branch, tenemos "Commit 9" (por supuesto, es un objeto distinto que el "Commit 9" original). Este objeto apunta a "Commit 7+8", el cual es una confirmación única que introduce los cambios del "Commit 7" original y el "Commit 8" original. El antecesor de la confirmación es "Commit 4", a donde main está apuntando.
Oh wow, ¿no es genial? 😎
git rebase te concede control sin límites sobre la figura de cualquier rama. Puedes usarlo para re-ordenar confirmaciones, o para quitar cambios incorrectos, o modificar un cambio en retrospectiva. Alternativamente, tal vez podrías mover la base de tu rama en otra confirmación, cualquier confirmación que desees.
Cómo usar el conmutador --onto de git rebase
Consideremos un ejemplo más. Vuelve a main nuevamente:
git checkout main
Y elimina los punteros de paul_branch y john_branch así ya no los ves en el gráfico de la confirmación:
git branch -D paul_branch
git branch -D john_branch
Luego, haz una nueva rama desde main:
git checkout -b new_branch
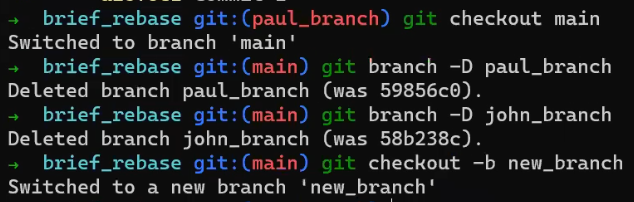
new_branch that diverges from mainEste es el historial limpio que deberías tener:
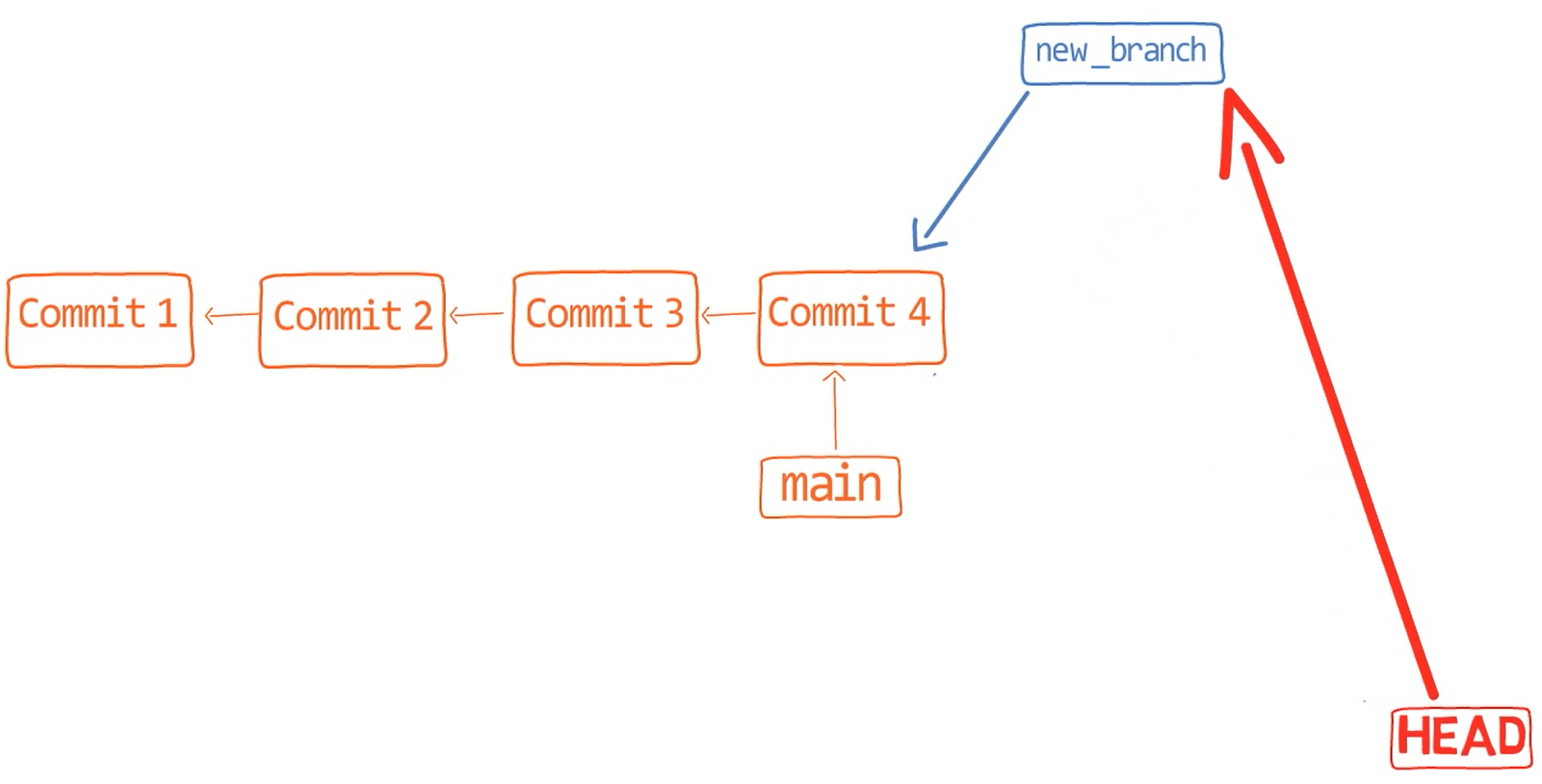
new_branch that diverges from mainAhora, cambia el archivo code.py (por ejemplo, agrega una nueva función) y confirma tus cambios:
nano code.py
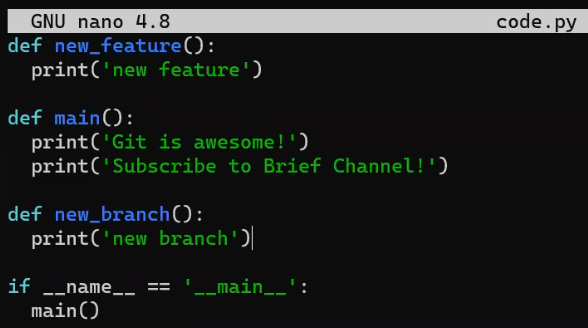
new_branch to code.pygit add code.py
git commit -m "Commit 10"
Vuelve a main:
git checkout main
E introduce otro cambio - agregando una cadena de documentos al principio del archivo:
Es tiempo de poner en el área de preparación y confirmar estos cambios:
git add code.py
git commit -m "Commit 11"
Y aún otro cambio, tal vez agrega @Author a la cadena de documentos:
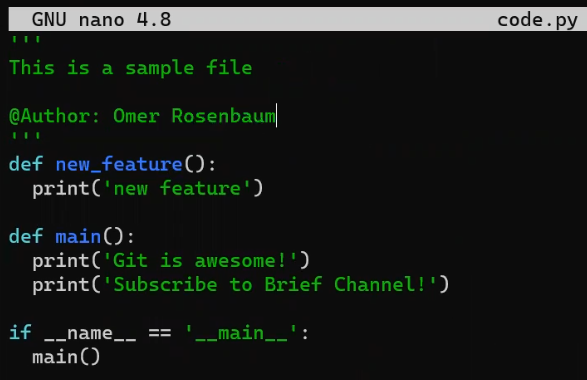
@Author to the docstringConfirma este cambio también:
git add code.py
git commit -m "Commit 12"
Oh espera, ahora me doy cuenta que quería que tú hicieras los cambios introducidos en "Commit 11" como parte de new_branch. Ugh. ¿Qué puedes hacer?
Considera el historial:
En vez de tener que "Commit 11" resida solamente en la rama main, quiero que esté en ambas ramas main y new_branch. Visualmente, quisiera moverlo hacia abajo en el gráfico aquí:
¿Puedes ver a dónde estoy yendo? 😇
Bueno, rebase te permite básicamente repetir los cambios introducidos en new_branch, aquellos introducidos en "Commit 10", como si hayan sido originalmente realizados sobre "Commit 11", en vez de "Commit 4".
Para hacer eso, puedes usar otros argumentos de git rebase. Específicamente, puedes usar git rebase --onto, el cual opcionalmente toma tres parámetros:
git rebase --onto <new_parent> <old_parent> <until>
Eso es, tomas todas las confirmaciones entre old_parent y until, y los "cortas" y "pegas" en new_parent.
En este caso, le dirías a Git que quieres tomar todo el historial introducidos entre el ancestro común de main y new_branch, el cual es "Commit 4", y que sea la nueva base para ese historial "Commit 11". Para hacer eso, usa:
git rebase --onto <SHA_OF_COMMIT_11> main new_branch
¡Y mira nuestro hermoso historial! 😍
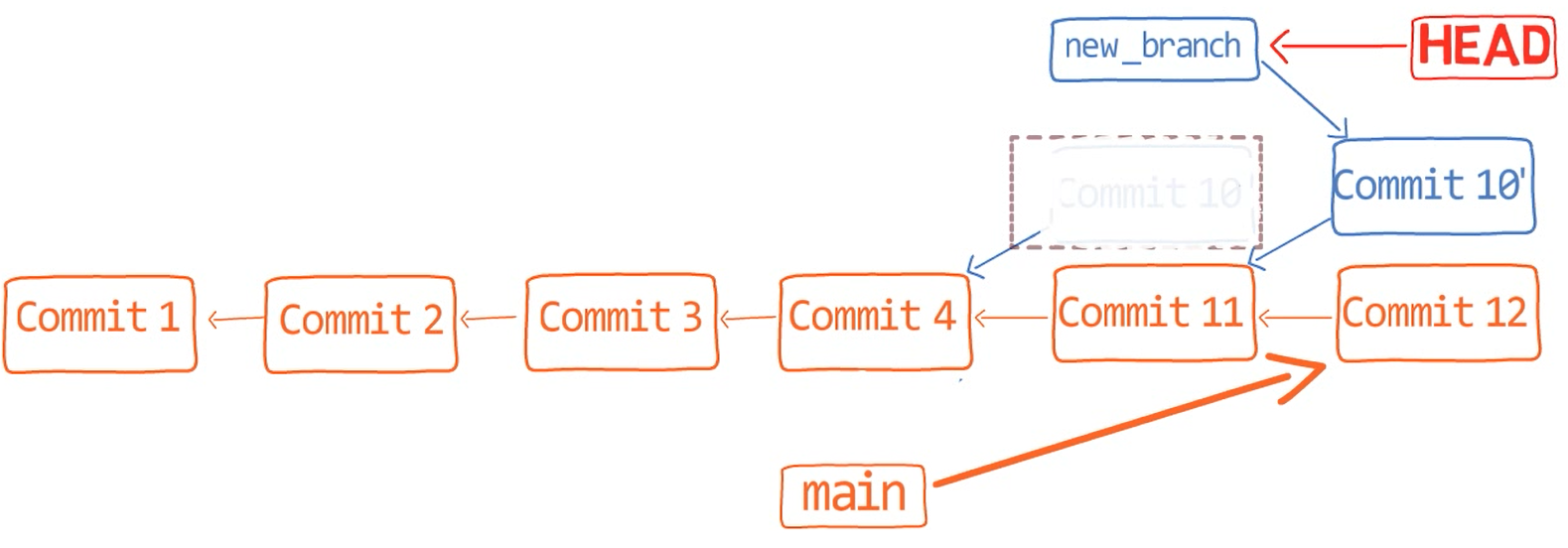
Consideremos otro caso.
Digamos que empecé a trabajar en una nueva característica, y por error comencé a trabajar desde feature_branch_1, en lugar de main.
Así que para emular esto, crea feature_branch_1:
git checkout main
git checkout -b feature_branch_1
Y elimina new_branch así ya no lo ves en el gráfico:
git branch -D new_branch
Crea un archivo Python sencillo llamado 1.py:

1.py, with print('Hello world!')Pónlo en el área de preparación y confirma este archivo:
git add 1.py
git commit -m "Commit 13"
Ahora haz una nueva rama desde feature_branch_1 (este es el error arreglará luego):
git checkout -b feature_branch_2
Y crea otro archivo, 2.py:

2.pyPónlo en el área de preparación y confirma este archivo también:
git add 2.py
git commit -m "Commit 14"
E introduce algo de código a 2.py:

2.pyPónlo en el área de preparación y confirma estos cambios también:
git add 2.py
git commit -m "Commit 15"
Hasta ahora tendrías este historial:
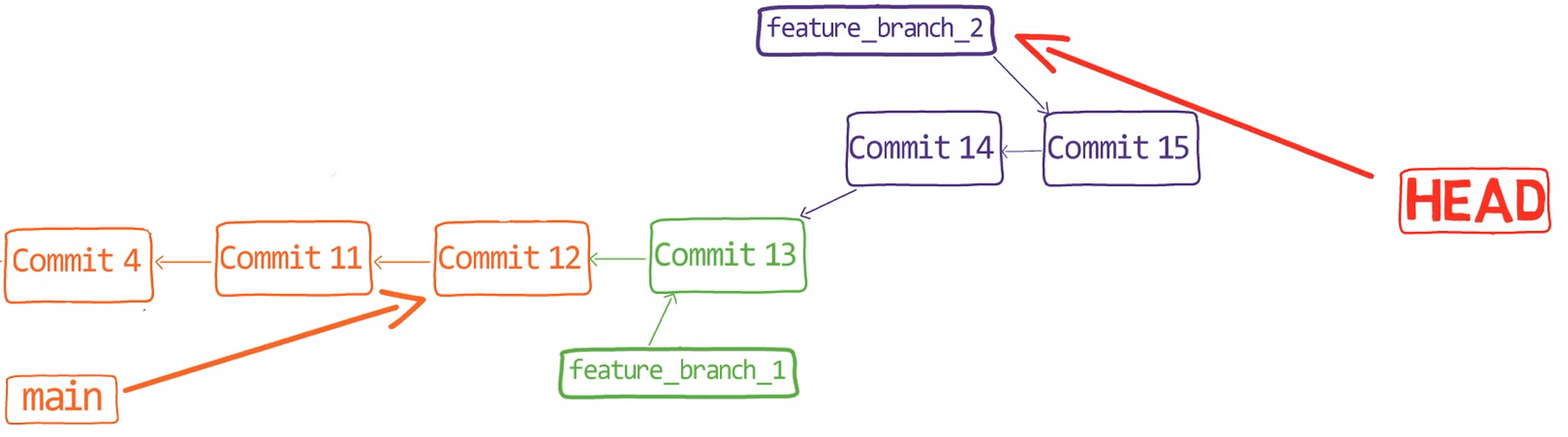
Vuelve a feature_branch_1 y edita 1.py:
git checkout feature_branch_1

1.pyAhora pónlo en el área de preparación y confirma:
git add 1.py
git commit -m "Commit 16"
Tu historial debería lucir así:
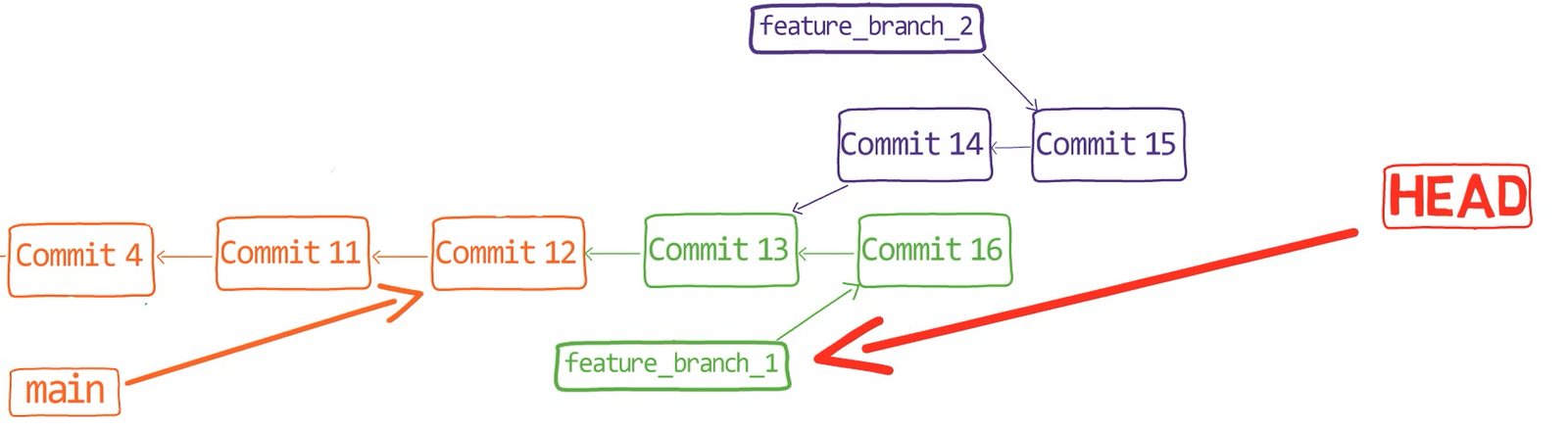
Digamos que ahora te das cuenta que cometiste un error. En realidad querías que feature_branch_2 naciera de la rama main, en vez de feature_branch_1.
¿Cómo puedes lograr eso?
Trata de imaginarlo dado el gráfico del historial y lo que has aprendido sobre el argumento --onto para el comando rebase.
Bueno, quieres "reemplazar" el antecesor de tu primera confirmación en feature_branch_2, el cual es "Commit 14", que está por encima de la rama main - en este caso, "Commit 12" - en vez del comienzo de feature_branch_1 - en este caso, "Commit 13". Así que devuelta, estarás creando una nueva base, esta vez para la primera confirmación en feature_branch_2.
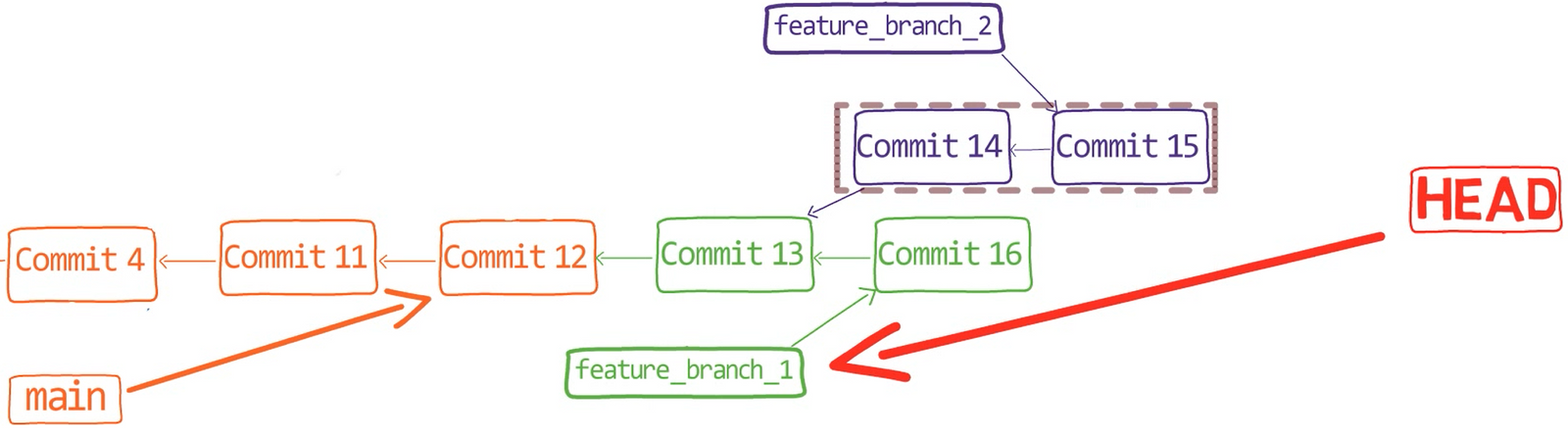
¿Cómo harías eso?
Primero, cambia a feature_branch_2:
git checkout feature_branch_2
Y ahora puedes usar:
git rebase --onto main <SHA_OF_COMMIT_13>
Esto le dice a Git que tome el historial con "Commit 13" como una base, y cambia esa base para que sea "Commit 12" (apuntado por main).
Como resultado, tienes a feature_branch_2 que tiene su base en main en vez de feature_branch_1:
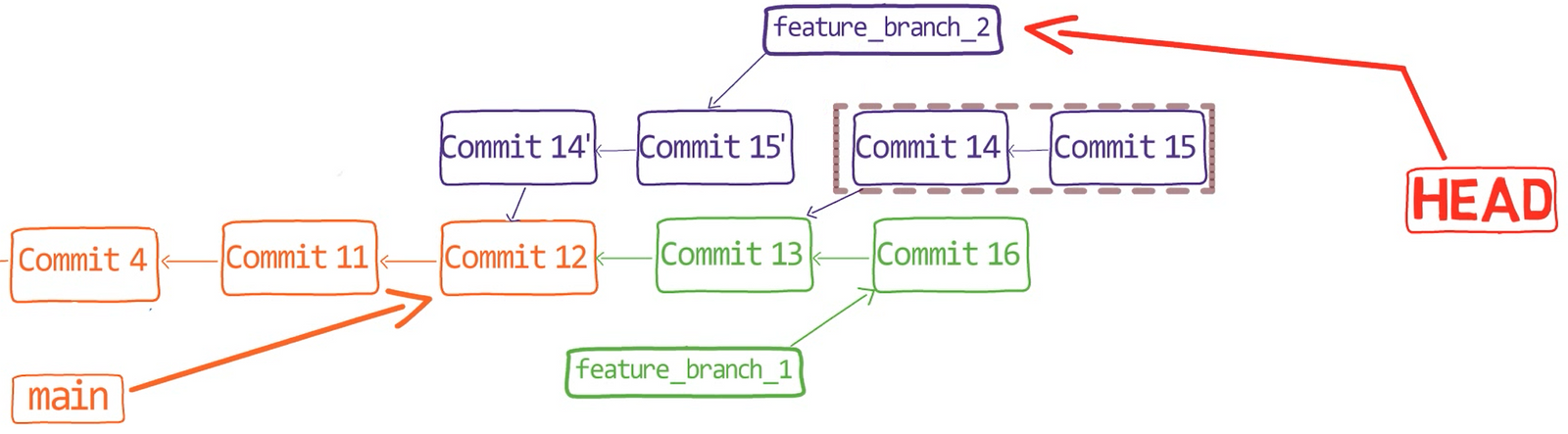
La sintaxis del comando es:
git rebase --onto <new_parent> <old_parent>
Cómo hacer rebase en una sola rama
También puedes usar git rebase mientras miras el historial de una sola rama.
Veamos si puedes ayudarme aquí.
Digamos que trabajé en feature_branch_2, específicamente edité el archivo code.py. Comencé cambiando todas las cadenas para que sean envueltos por doble comillas en vez de comillas simples.
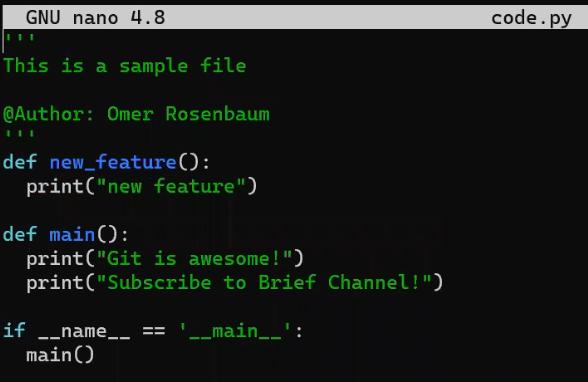
' into " in code.pyLuego, los puse en el área de preparación y los confirmé:
git add code.py
git commit -m "Commit 17"
Luego decidí agregar una nueva función al principio del archivo:
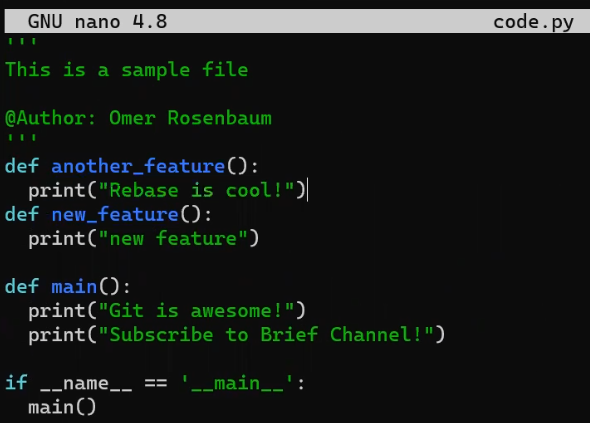
another_featureNuevamente, los puse en el área de preparación y confirmé:
git add code.py
git commit -m "Commit 18"
Y ahora me doy cuenta que en realidad me olvidé de cambiar las comillas simples a comillas dobles envolviendo a __main__ (como has notado), así que hice eso también:
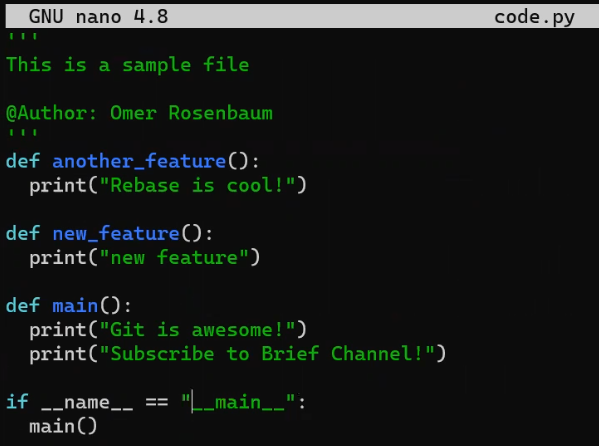
'__main__' into "__main__"Por supuesto. puse este cambio en el área de preparación y confirmé:
git add code.py
git commit -m "Commit 19"
Ahora, considera el historial:
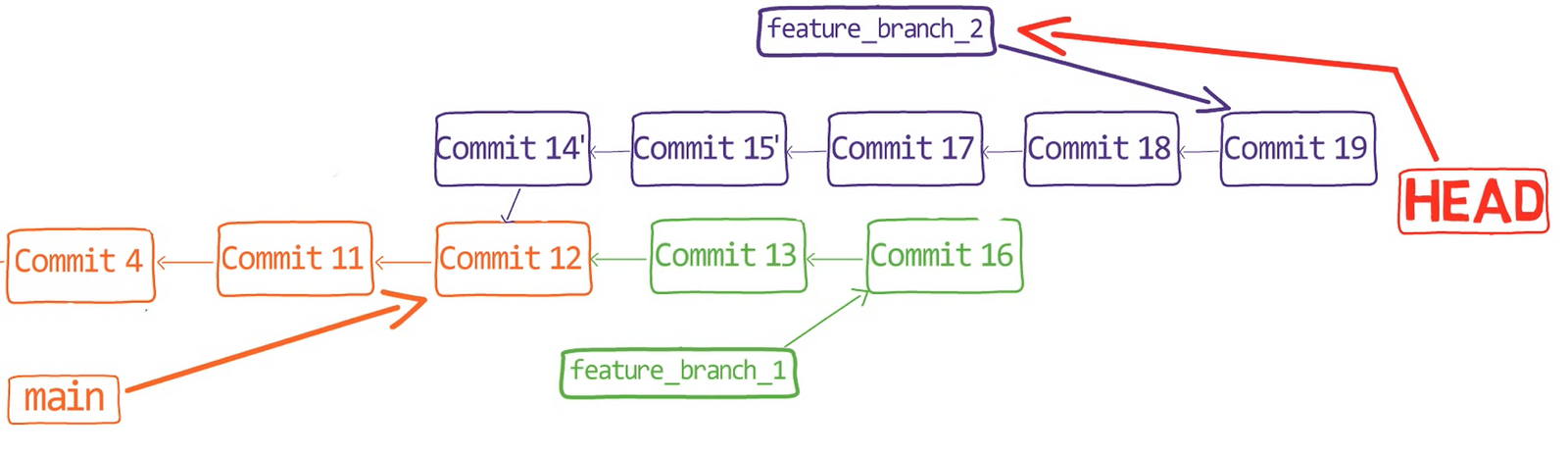
¿No es genial, no? O sea, tengo dos confirmaciones que están relacionados el uno al otro, "Commit 17" y "Commit 19" (cambiando los ' a "), pero están separados por "Commit 18" que no está relacionado (donde agregué una nueva función). ¿Qué podemos hacer? ¿Puedes ayudarme?
Intuitivamente, quiero editar el historial aquí:
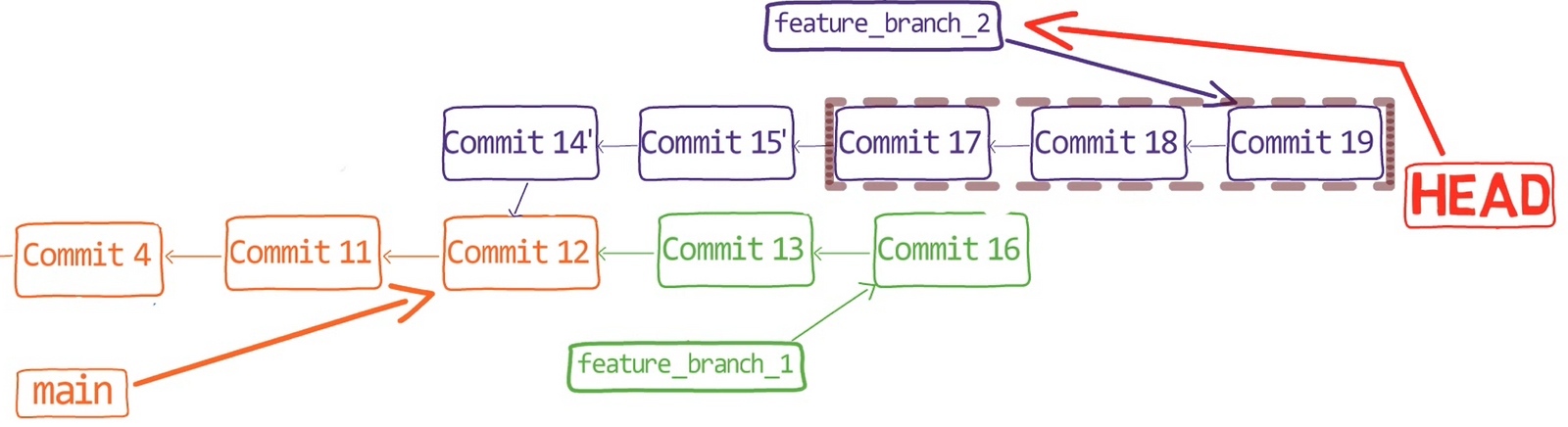
Así que, ¿qué harías?
¡Exacto!
Puedo hacer rebase del historial de "Commit 17" a "Commit 19", por encima de "Commit 15". Para hacer eso:
git rebase --interactive --onto <SHA_OF_COMMIT_15> <SHA_OF_COMMIT_15>
Fíjate que especifiqué "Commit 15" como el comienzo del rango de confirmaciones, excluyendo esta confirmación. Y no necesité especificar explícitamente a HEAD como el último parámetro.
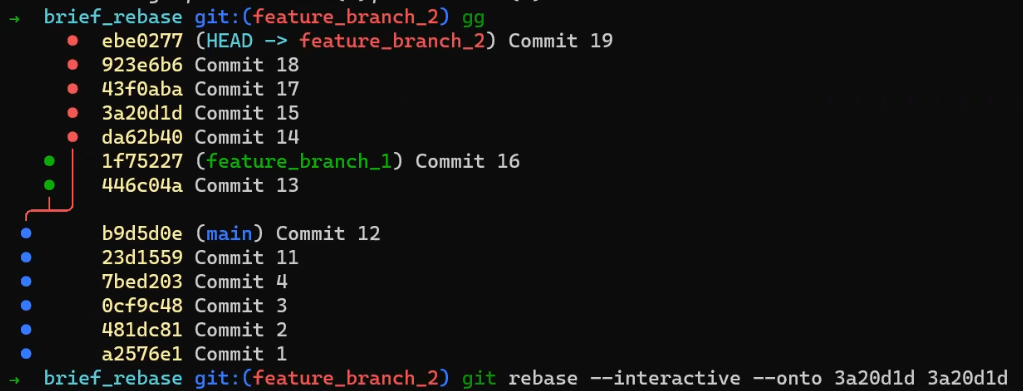
rebase --onto on a single branch(Nota: si sigues los pasos de arriba con mi repositorio y obtienes un conflicto de fusión, podrías tener una configuración distinta al de mi máquina debido a los caracteres de espacio en blanco en las líneas finales. En ese caso, puedes agregar el argumento --ignore-whitespace) al comando rebase, resultando en el siguiente comando: git rebase --ignore-whitspace --interactive --onto <SHA_OF_COMMIT_15> <SHA_OF_COMMIT_15>. Si quisieras saber más sobre este problema, busca autocrlf.)
Después de seguir tu consejo y ejecutar el comando rebase (¡gracias! 😇) obtengo la siguiente pantalla:
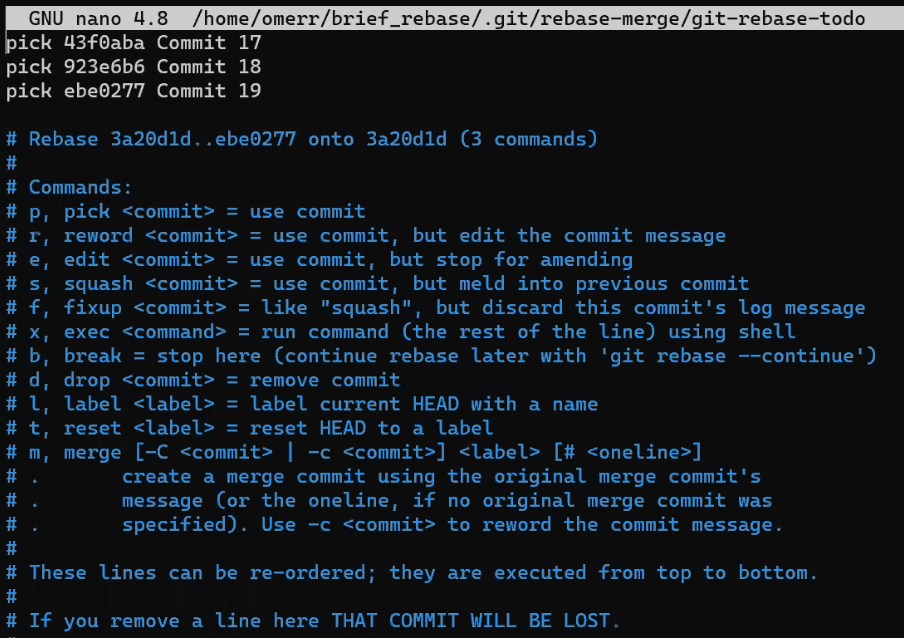
Así que, ¿qué haría? Quiero poner a "Commit 19" antes de "Commit 18", de esa forma viene después de "Commit 17". Puedo ir más lejos y hacer squash (aplastarlos juntos), así:
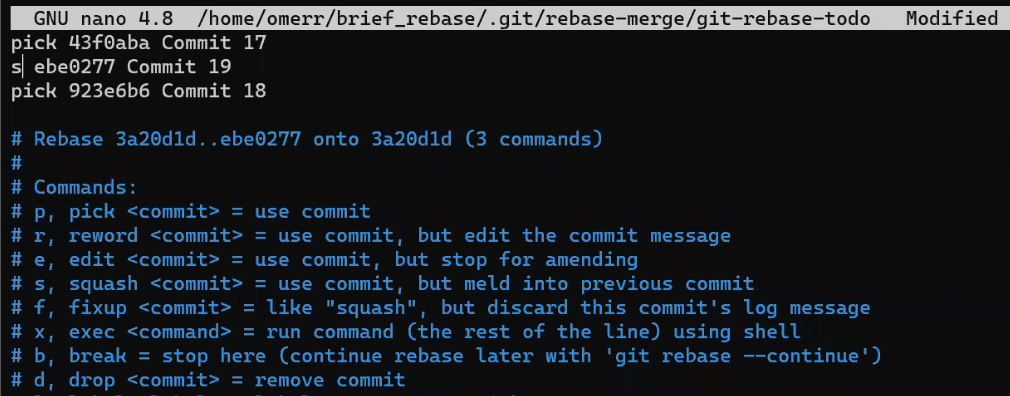
Ahora cuando se me aparece una ventana para un mensaje de confirmación, puedo proveer el mensaje "Commit 17+19":
Y ahora, mira nuestro hermoso historial:
¡Gracias nuevamente!
Más casos de uso de Rebase + Más práctica
Por ahora espero que te sientas cómodo con la sintaxis de rebase. La mejora forma de entenderlo en sí es considerar varios casos y averiguar cómo resolverlos tú mismo.
Con los casos que vienen, te recomiendo enérgicamente que dejes de leer después de lo que introduje en cada caso de uso, y luego intentes resolverlo por ti mismo.
Cómo excluir confirmaciones
Digamos que tienes este historial en otro repo:
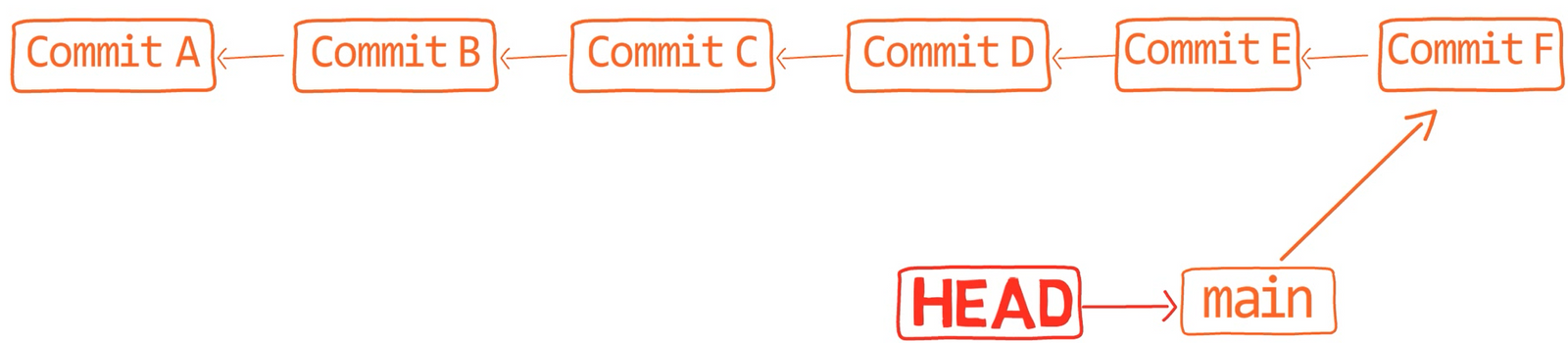
Antes de jugar con él, almacena una etiqueta a "Commit F" así puedes recuperarlo más tarde:
git tag original_commit_f
(Una etiqueta es una referencia nombrada a una confirmación, como una rama - pero no cambia cuando agregas confirmaciones adicionales. Es como una referencia nombrada constante.)
Ahora, en realidad no quieres los cambios en "Commit C" y "Commit D" que sean incluidos. Podrías usar un rebase interactivo como antes y quitar sus cambios. O, podrías usar git rebase --onto de nuevo. ¿Cómo usarías --onto para "quitar" estas dos confirmaciones?
Puedes hacer rebase de HEAD por encima de "Commit B", donde el antecesor viejo era en realidad "Commit D", y ahora debería ser "Commit B". Considera el historial nuevamente:
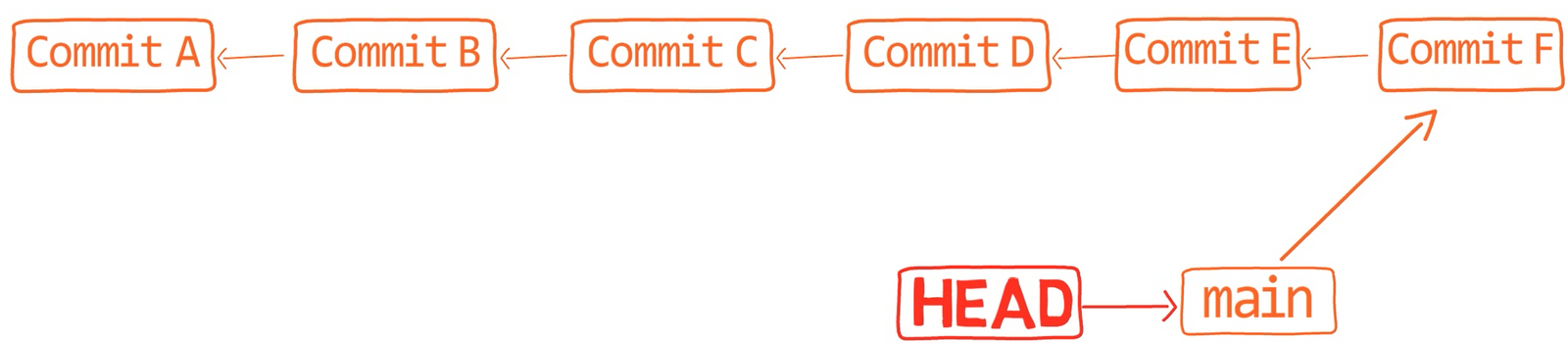
Hacer rebase para que "Commit B" sea la base de "Commit E" significa "mover" ambos "Commit E" y "Commit F", y darles otra base - "Commit B". ¿Puedes idearte el comando tú mismo?
git rebase --onto <SHA_OF_COMMIT_B> <SHA_OF_COMMIT_D> HEAD
Fíjate que usar la sintaxis de arriba (exactamente como se proveyó) no haría que main apunte a la nueva confirmación, para que el resultado sea un HEAD "separado". Si usas gg u otra herramienta que muestra el historial alcanzable desde las ramas, te podría confundir:
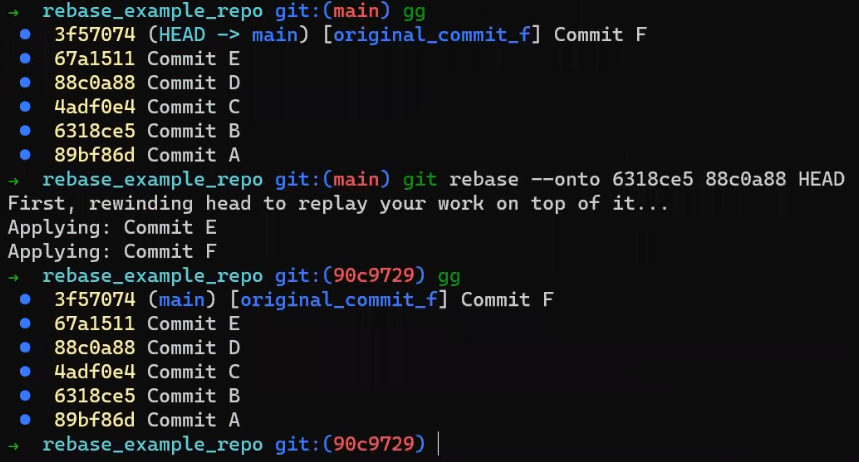
--onto results in a detached HEADPero si simplemente usas git log (o mi alias git lol), verás el historial deseado:

No sé tú, pero este tipo de cosas me hacen realmente feliz. 😊😇
Por cierto, podría omitir el HEAD del comando previo como si este fuera el valor predeterminado para el tercer parámetro. Así que usar:
git rebase --onto <SHA_OF_COMMIT_B> <SHA_OF_COMMIT_D>
Tendría el mismo efecto. El último parámetro en realidad le dice a Git donde está el final de la secuencia actual de las confirmaciones para hacerles rebase. Así que la sintaxis de git rebase --onto con los tres argumentos es:
git rebase --onto <new_parent> <old_parent> <until>
Cómo mover confirmaciones a través de las ramas
Así que digamos que obtenemos el mismo historial que antes:
git checkout original_commit_f
Y ahora quiero solamente que "Commit E" esté en una rama que tenga su base en "Commit B". Eso es, quiero tener una nueva rama, que venga desde "Commit B", que tenga solamente a "Commit E".
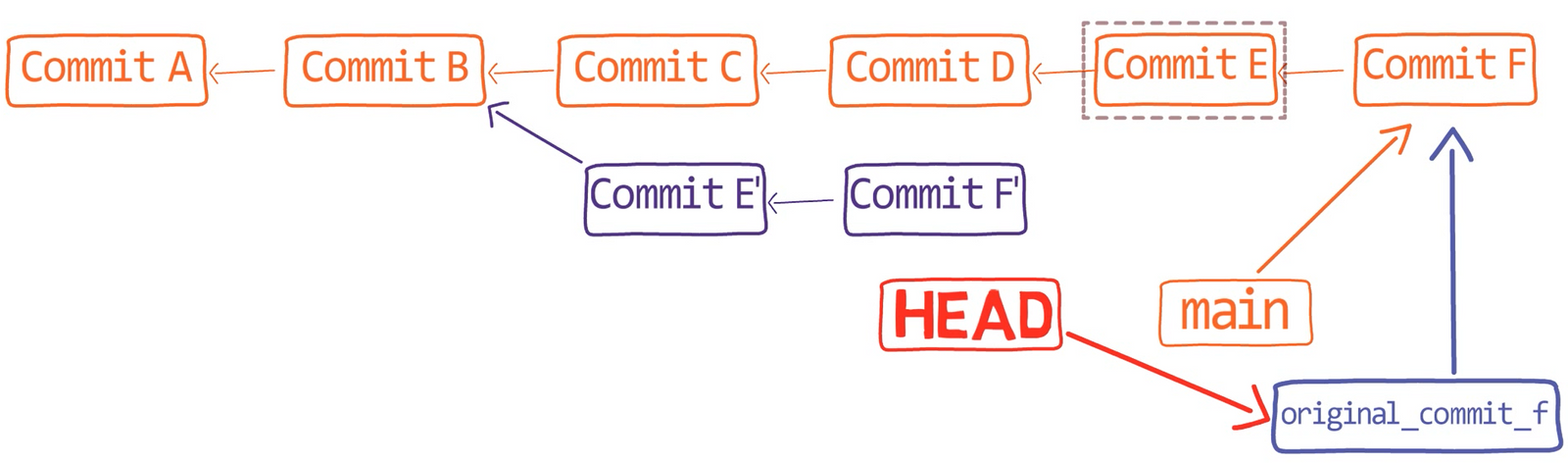
Así que, ¿qué significa esto en términos de rebase? Considera la imagen de arriba. ¿Qué confirmación (o confirmaciones) debería hacer rebase, y qué confirmación debería ser la nueva base?
Sé que puedo contar contigo aquí 😉
Lo que quiero es tomar el "Commit E", y solamente esta confirmación, y cambiar su base para que sea "Commit B". En otras palabras, repetir los cambios introducidos en "Commit E" en "Commit B".
¿Puedes aplicar esa lógica a la sintaxis de git rebase?
Aquí está (esta vez estoy escribiendo <COMMIT_X> en vez de <SHA_OF_COMMIT_X>, para brevedad):
git rebase --onto <COMMIT_B> <COMMIT_D> <COMMIT_E>
Ahora el historial luce así:
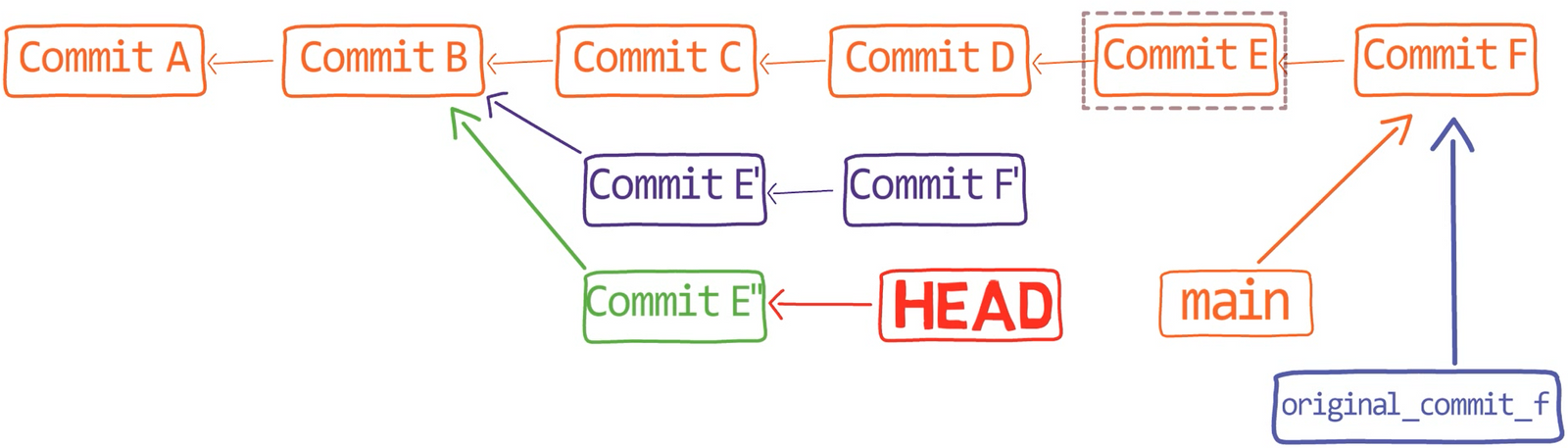
Fíjate que rebase movió a HEAD, pero ninguna otra referencia nombrada (tales como una rama o una etiqueta). En otras palabras, estás en un estado de HEAD separado. Así que aquí también, usando gg u otra herramienta que muestre el historial alcanzable desde las ramas y de las etiquetas te podría confundir. Puedes usar git log (o mi alias git lol) para mostrar el historial alcanzable desde HEAD.
¡Genial!
Una Nota sobre los Conflictos
Fíjate que cuando haces un rebase, podrías entrar en conflictos así como al fusionar. Podrías tener conflictos porque, cuando haces rebase, estás intentando aplicar parches en una base distinta, tal vez donde los parches no apliquen.
Por ejemplo, considera el repositorio nuevamente, y específicamente, considera el cambio introducido en "Commit 12", que es apuntado por main:
git show main
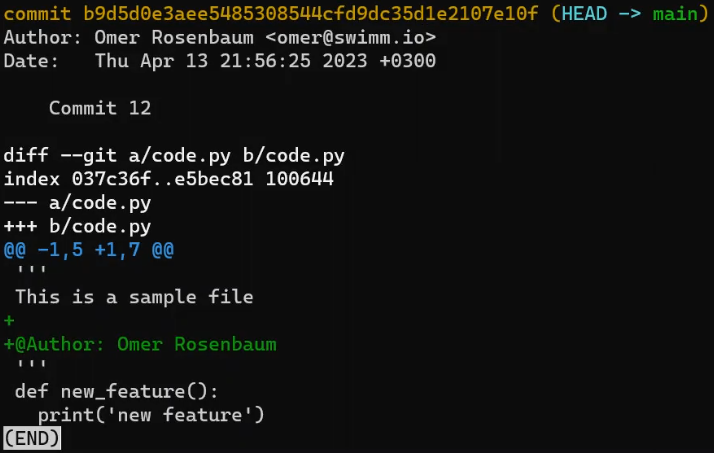
Ya cubrí el formato de git diff en detalle en el capítulo 6, pero como un recordatorio rápido, esta confirmación le instruye a Git que agregue una línea después de las dos líneas de contexto:
```
This is a sample file
Y antes de estas tres líneas de contexto:
```
def new_feature():
print('new feature')
Digamos que estás intentando hacer rebase de "Commit 12" en otra confirmación. Si, por alguna razón, estas líneas de contexto no existen como sí existen en el parche de la confirmación en la que estás haciendo rebase, entonces tendrías un conflicto.
Aléjandose para ver el panorama general
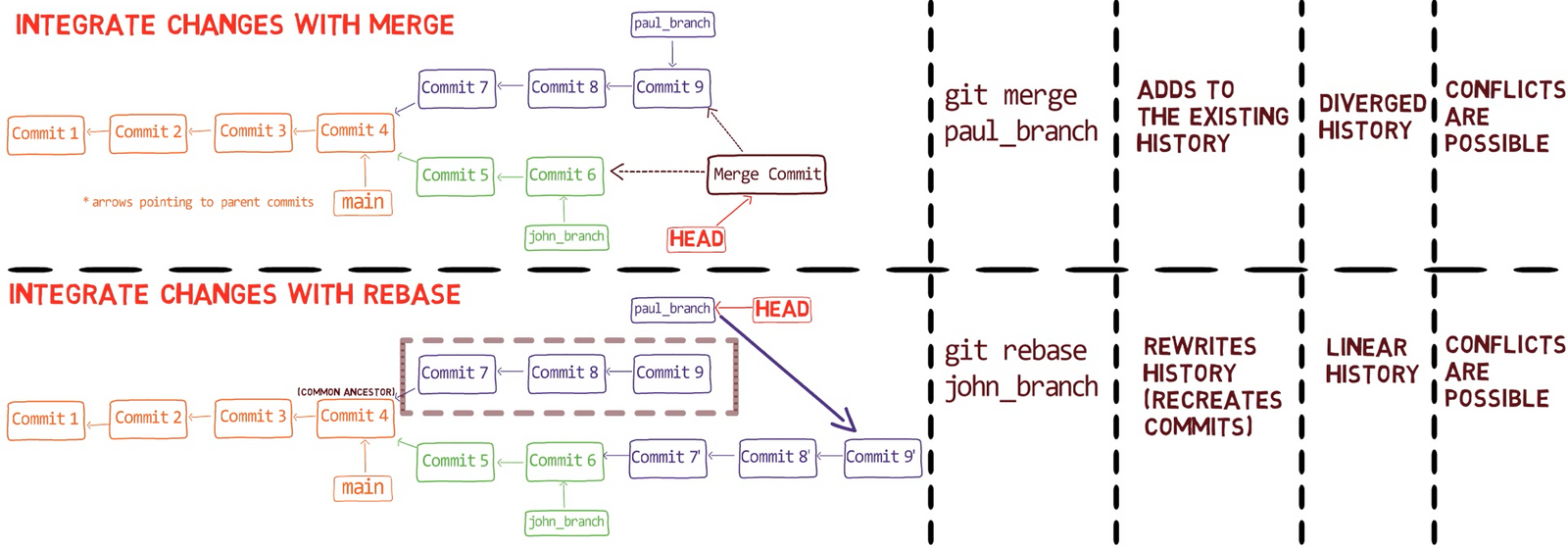
Al principio de este capítulo, comencé mencionando la similaridad entre git merge y git rebase: ambos son usados para integrar cambios introducidos en historiales distintos.
Pero, como ahora sabes, son muy distintos en cómo operan. Mientras se fusionan resultados en un historial divergente, hacer rebase resulta en un historial linear. Los conflictos son posibles en ambos casos. Y hay una columna más descrita en la tabla de arriba que requiere más atención.
Ahora que sabes qué es "Git rebase", y cómo usar el rebase interactivo o rebase --onto, como espero que estés de acuerdo, git rebase es una herramienta super poderosa. Aunque, tiene una desventaja grande cuando se compara con fusionar.
Git rebase cambia el historial.
Esto significa que no deberías hacer rebase de las confirmaciones que existen fuera de tu copia local del repositorio, y que otras personas podrían tener su base en sus confirmaciones.
En otras palabras, si sólo las confirmaciones en cuestión son aquellos que creaste de manera local - adelante, use rebase, enloquécete.
Pero si las confirmaciones han sido empujados (enviados), eso puede llevarte a un gran problema - ya que alguien más podría basarse en estas confirmaciones que tu luego sobreescribas, y después tú y ellos tendrás distintas versiones del repositorio.
Esto es distinto a merge el cual, como hemos visto, no modifica el historial.
Por ejemplo, considera el último caso donde cambiamos la base y resultó en este historial:
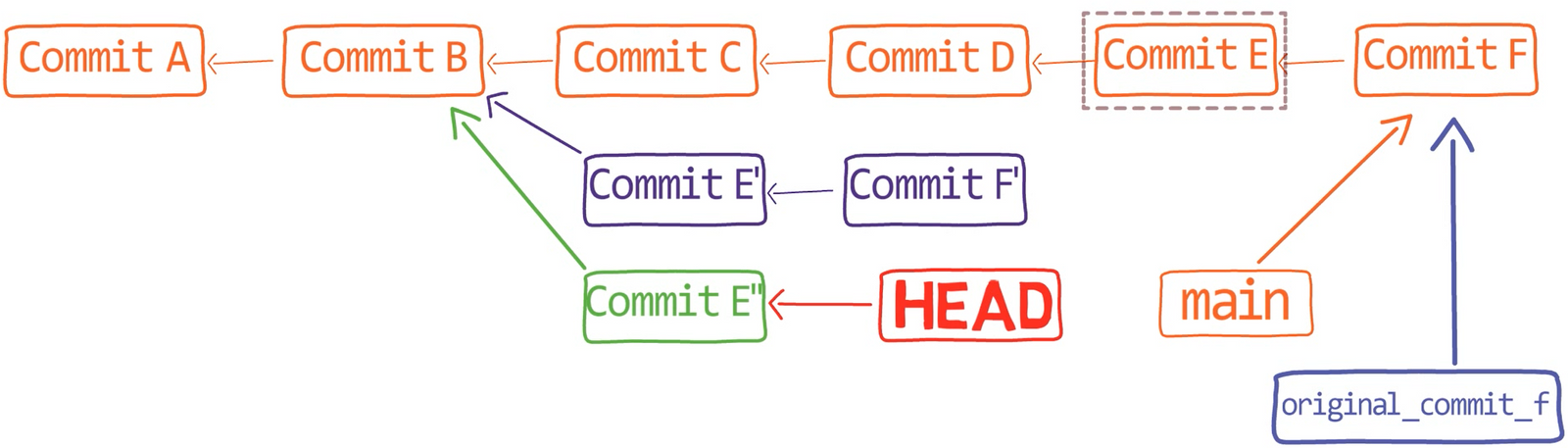
Ahora, digamos que ya empujé esta rama al remoto. Y después que he empujado la rama, otro desarrollador lo empujó e hizo una rama desde "Commit C". El otro desarrollador no sabía que mientras tanto, estuve haciendo rebase de mi rama de forma local, y luego lo subiría (empujaría) nuevamente.
Esto resulta en una inconsistencia: el otro desarrollador trabaja desde una confirmación que ya no está disponible en mi copia del repositorio.
No elaboraré exactamente lo que esto causa en este libro, ya que mi mensaje principal es que deberías evitar definitivamente tales casos. Si estás interesado en qué sucedería en sí, te dejaré un enlace a un recurso útil en las referencias adicionales. Por ahora, resumamos lo que hemos cubierto.
Recapitulación - Entendiendo Git rebase
En este capítulo, aprendiste sobre git rebase, una herramienta super poderosa para reescribir el histoiral en Git. Consideraste unos pocos casos donde git rebase puede ser útil, y cómo usarlo en uno, dos, o tres parámetros, con y sin el conmutador --onto.
Espero que haya sido capaz de convencerte que git rebase es poderoso - pero también que es bastante sencillo una vez que entiendes la esencia. Es una herramienta que puedes usar para "copiar-pegar" confirmaciones (o, más acertadamente, parches). Y es una herramienta útil para tener en tu cinto. En esencia, git rebase toma los parches introducidos por las confirmaciones, y repetirlos en un otra confirmación. Como se describió en este capítulo, esto es útil en muchos escenarios distintos.
Parte 2 - Resumen
En esta parte aprendiste a hacer ramas e integrar cambios en Git.
Aprendiste lo que es un diff, y la diferencia entre un diff y un parche. También aprendiste cómo se construye la salida de git diff.
Entender los diffs es un hito mayor para entender muchos otros procesos dentro de Git tales como fusionar o hacer rebase.
Después, tuviste una vista general extensiva sobre fusionar con Git. Aprendiste que la fusión es el proceso de combinar los cambios recientes de varias ramas en una sola nueva confirmación. La nueva confirmación tiene múltiples antecesores - esas confirmaciones han sido las puntas de las ramas que fueron fusionadas. En la mayoría de los casos, la fusión combina los cambios de dos ramas, y entonces la confirmación de fusión resultante tiene dos predecesores - uno de cada rama.
Consideramos una fusión sencilla y directa, la cual es posible cuando una rama difiere de la rama base, y luego agregamos confirmaciones por encima de la rama base.
Después consideramos fusiones de tres vías, y explicamos el proceso de tres etapas:
- Primero, Git localiza la base de fusión. Como recordatorio, este es la primera confirmación que es alcanzable desde ambas ramas.
- Segundo, Git calcula dos diffs - un diff desde la base de fusión a la primer rama, y otro diff desde la base de fusión a la segunda rama. Git genera parches basados en esos diffs.
- Tercero y último, Git aplica ambos parches a la base de fusión usando un algoritmo de fusión de 3 vías. El resultado es el estado de la nueva confirmación de fusión.
Viste la salida de git diff cuando estamos en un estado de conflicto, y cómo resolver conflictos sea de forma manual o con VS Code.
Por último, aprendiste Git rebase. Viste que git rebase es poderoso - pero también es bastante sencillo una vez que entiendes lo que hace. Es una herramienta para "copiar-pegar" confirmaciones (o, más específicamente, parches).
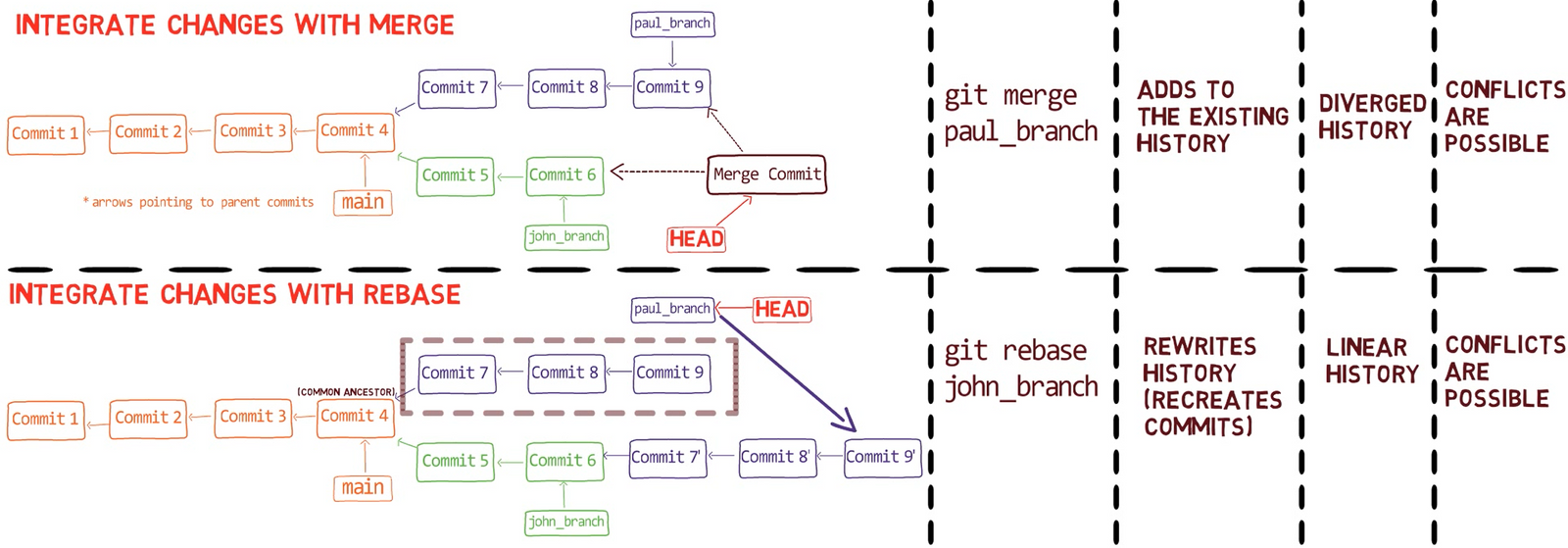
Ambos git merge y git rebase se usan para integrar cambios introducidos en diferentes historiales.
Aunque, difieren en cómo operan. Mientras que la fusión resulta en un historial divergente, los resultados de hacer rebase resulta en un historial linear. git rebase cambia el historial, mientras que git merge agrega al historial existente.
Con este entendimiento profundo de diffs, parches, fusión y rebase, deberías sentirte confiado al introducir cambios a un repositorio git.
La próxima parte se enfocará en lo que sucede cuando las cosas salen mal - cómo puedes cambiar el historial (con o sin git rebase), o encontrar confirmaciones "perdidas".
Parte 3 - Deshacer cambios
Alguna vez llegaste a un punto donde dijiste: "Oh-oh, ¿qué es lo que hice?" Supongo que lo hiciste, así como cualquiera que usa Git.
Tal vez confirmaste a la rama equivocada. Tal vez perdiste algo de código que has escrito. Tal vez confirmaste algo que no era tu intención de hacer.
Esta parte te dará las herramientas para reescribir el historial con confianza, de esa forma "deshacer" todo tipos de cambios en Git.
Así como las otras partes del libro, esta parte será practica aunque a profundidad - así que en vez de proveerte una lista de qué a hacer cuando las cosas salen mal, entenderemos los mecanismos subyacentes, así te sentirás confiable cuando sea que llegues al momento "oh-oh". En realidad, encontrarás estos momentos como oportunidades para un desafió interesante, en vez de un escenario espantoso.
Capítulo 9 - Git Reset
Nuestro trayecto comienza con un comando potente que puede ser usado para deshacer muchas diferentes acciones con Git - git reset.
Un pequeño recordatorio - Registrando cambios
En el capítulo 3, aprendiste cómo registrar cambios en Git. Si recuerdas todo de esta parte, puedes saltar la próxima sección.
Es útil imaginarse a Git como un sistema para registrar copias instantáneas de un sistema de archivos en el tiempo. Considerando un repositorio de Git, tiene tres "estados" o "árboles":
- El directorio de trabajo, un directorio que tiene un repositorio asociado.
- El área de preparación (índice) el cual tiene el árbol para la próxima confirmación.
- El repositorio, el cual es una colección de confirmaciones y referencias.

Fíjate que con respecto a las convenciones de dibujo que utilizo: incluyo .git dentro del directorio de trabajo, para recordarte es una carpeta dentro de la carpeta del proyecto en el sistema de archivos. La carpeta .git en realidad contiene los objetos y las referencias del repositorio, como se explicó en el capítulo 4.
Demostración práctica
Usa git init para inicializar un nuevo repositorio. Escribe algo de texto en un archivo llamado 1.txt:
mkdir my_repo
cd my_repo
git init
echo Hello world > 1.txt
De los tres estados descritos arriba, ¿dónde está 1.txt ahora?
En el árbol de trabajo, ya que todavía no ha sido introducido al índice.

1.txt is now a part of the working dir onlyPara ponerlo en área de preparación, para agregarlo al índice, usa:
git add 1.txt
git add stages the file so it is now in the index as wellFíjate que una vez que pones en el área de preparación 1.txt, Git crea un objeto blob con el contenido de este archivo, y lo agrega a la base de datos de objetos interno (dentro de la carpeta .git), como se cubrió en el capítulo 3 y capítulo 4. No lo dibujo como parte del "repositorio" ya que en esta representación, el "repositorio" se refiere a un árbol de confirmaciones y sus referencias, y este blob no ha sido parte de ninguna confirmación.
Ahora, usa git commit para confirmar tus cambios al repositorio:
git commit -m "Commit 1"

git commit creates a commit object in the repositoryCreaste un nuevo objeto de confirmación, el cual incluye un puntero a un árbol que describe todo el árbol de trabajo. En este caso, este árbol consiste solamente de 1.txt dentro de la carpeta raíz. Además de un puntero al árbol, el objeto de confirmación incluye metadatos, tales como marcas de tiempo e información del autor.
Cuando se considera los diagramas, fíjate que solamente tenemos una sola copia del archivo 1.txt en el disco, y un objeto blob correspondiente en la base de datos de objetos de Git. El árbol del "repositorio" ahora muestra este archivo ya que es parte de la confirmación activa - eso es, el objeto de confirmación "Commit 1" apunta a un árbol que apunta al blob con los contenidos de 1.txt, el mismo blob al que el índice está apuntando.
Para más información sobre los objetos en Git (tales como confirmaciones y árboles), ve al capítulo 1.
Luego, crea un nuevo archivo, y agrégalo al índice, como antes:
echo second file > 2.txt
git add 2.txt
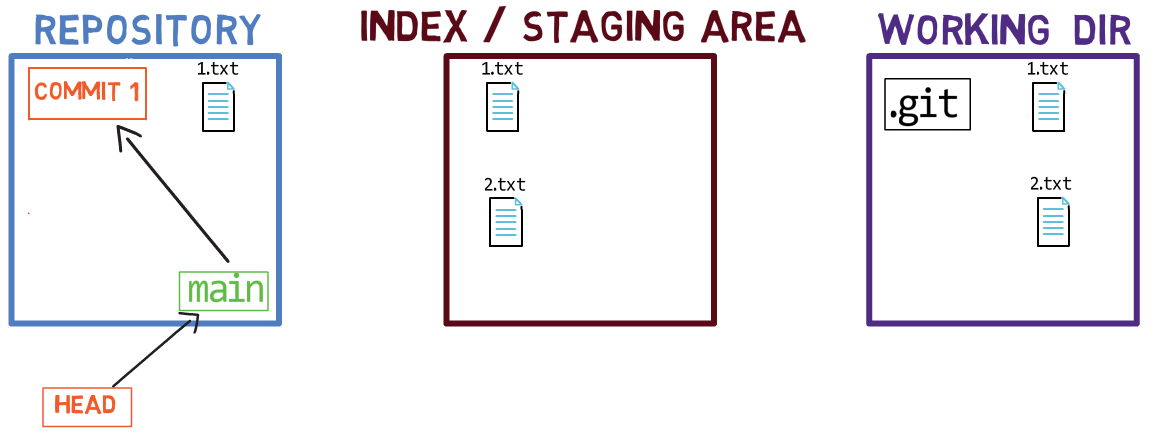
2.txt is in the working dir and the index after staging it with git addLuego, confirma:
git commit -m "Commit 2"
Muy importante, git commit hace dos cosas:
Primero, crea un objeto de confirmación, así que hay un objeto dentro de la base de datos de objetos interno de Git con un valor SHA-1 correspondiente. Este nuevo objeto de confirmación también apunta a la confirmación antecesor. Ese es la confirmación al que HEAD estaba apuntando cuando escribiste el comando git commit.
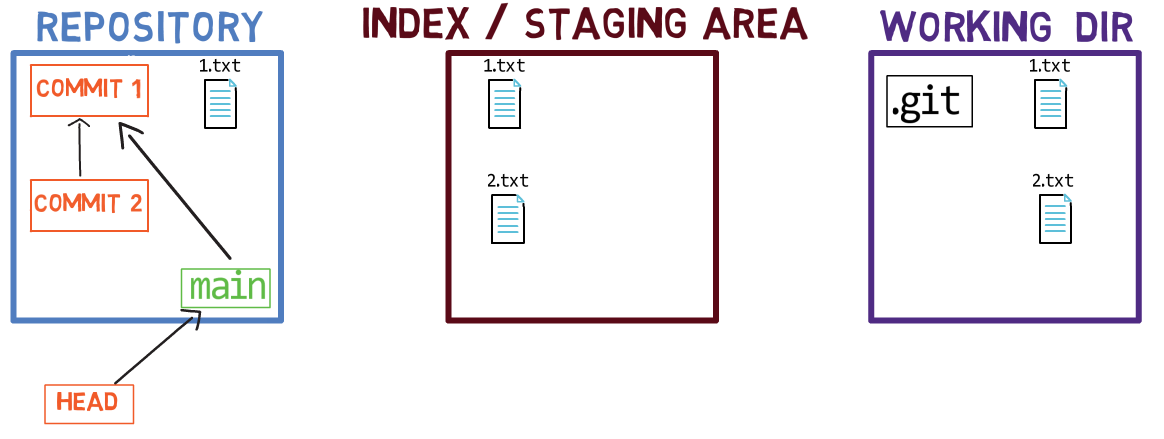
main still points to the previous commitSegundo, git commit mueve el puntero de la rama activa – en nuestro caso, eso sería main, a que apunte al objeto de confirmación creado recientemente.
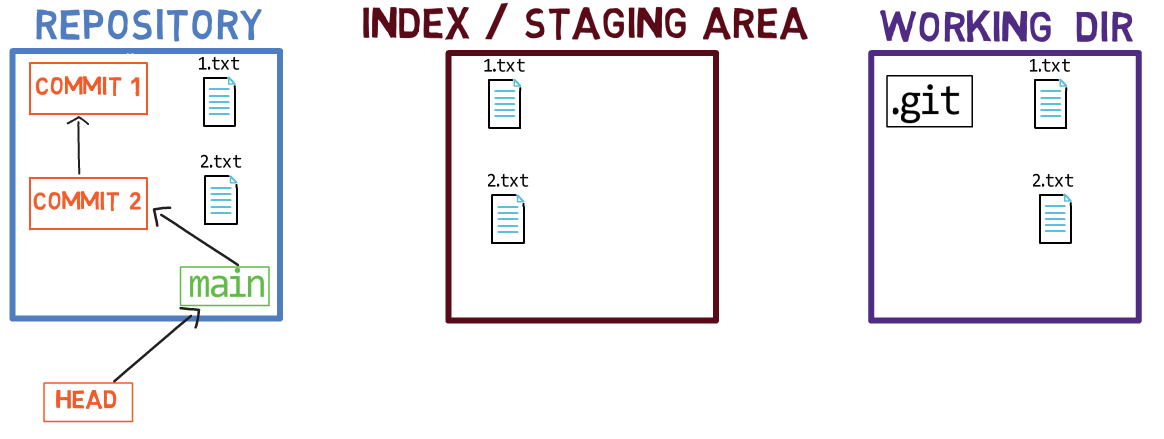
git commit also updates the active branch to point to the newly created commit objectIntroduciendo git reset
Ahora aprenderás cómo revertir el proceso de introducir una confirmación. Para eso, aprenderás el comando git reset.
git reset --soft
El último paso que hiciste antes fue git commit, el cual en realidad significa dos cosas – Git creó un objeto de confirmación y movió a main, la rama activa. Para deshacer este paso, usa el siguiente comando:
git reset --soft HEAD~1
La sintaxis HEAD~1 se refiere al primer antecesor de HEAD. Considera un caso donde tenía más de una confirmación en el gráfico de confirmaciones, digamos que "Commit 3" está apuntando a "Commit 2", el cual, en sí, está apuntando a "Commit 1". Y considera que HEAD estaba apuntando a "Commit 3". Podrías usar HEAD~1 para referirte a "Commit 2", y HEAD~2 se referiría a "Commit 1".
Así que, devuelta al comando: git reset --soft HEAD~1.
Este comando le pide a Git que cambie cualquier HEAD al que está apuntando. (Nota: En los diagramas de abajo, uso *HEAD para "cualquier HEAD al que está apuntando".) En nuestro ejemplo, el HEAD está apuntando a main. Así que Git solamente cambiará el puntero de main a que apunte a HEAD~1. Eso es, main apuntará al "Commit 1".
Sin embargo, este comando no afectará el estado del índice o el árbol de trabajo. Así que si usas git status verás que 2.txt está en el área de preparación, justo como antes que ejecutaste git commit:
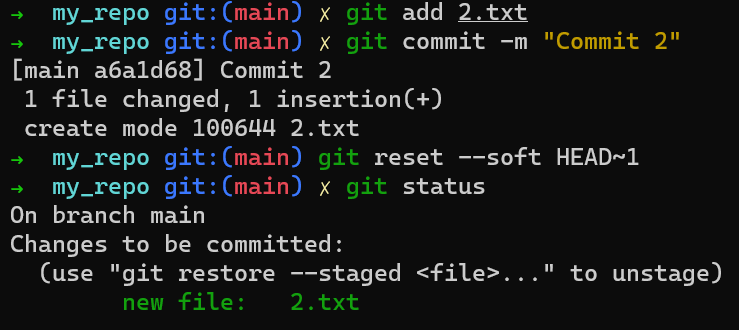
git status shows that 2.txt is in the index, but not in the active commitEl estado es ahora:
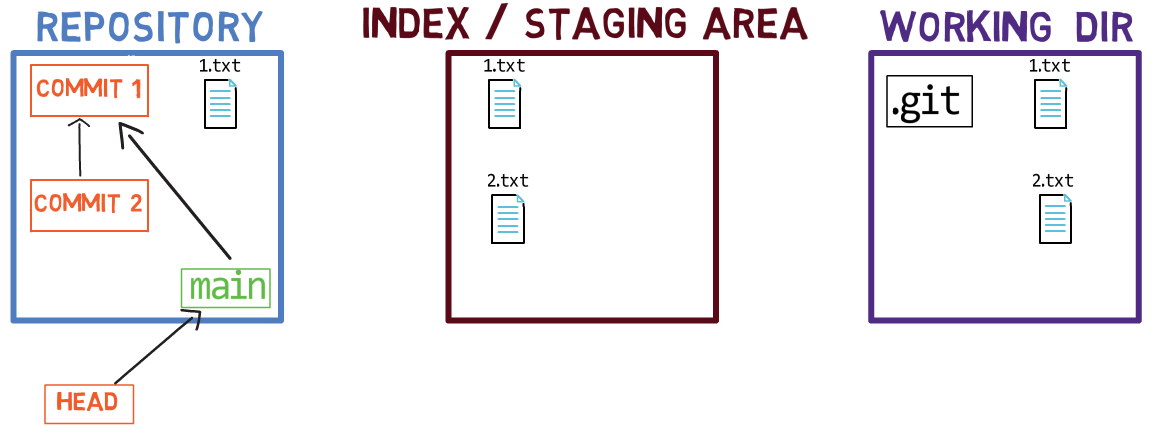
main to "Commit 1"(Nota: quité 2.txt del "repositorio" en el diagrama ya que no es parte de la confirmación activa - eso es, el árbol apuntado por el "Commit 1" no referencia a este archivo. Sin embargo, no ha sido quitado del sistema de archivos - ya que existe en el árbol de trabajo y el índice.)
¿Qué hay sobre git log? Comenzará desde el HEAD, va al main, y luego a "Commit 1":
git logFíjate que esto significa que "Commit 2" ya no es alcanzable desde nuestro historial.
¿Eso significa que el objeto de confirmación de "Commit 2" se elimina?
No, no se elimina. Todavía residen dentro de la base de datos de objetos interno de Git.
Si subes el historial actual ahora, usando git push, Git no empujará el "Commit 2" al servidor remoto (ya que no es alcanzable desde el HEAD actual), pero el objeto de confirmación todavía existe en tu copia local del repositorio.
Ahora, confirma nuevamente - y use el mensaje de confirmación de "Commit 2.1" para diferenciar este nuevo objeto desde el "Commit 2" original:
git commit -m "Commit 2.1"
Este el estado resultante:
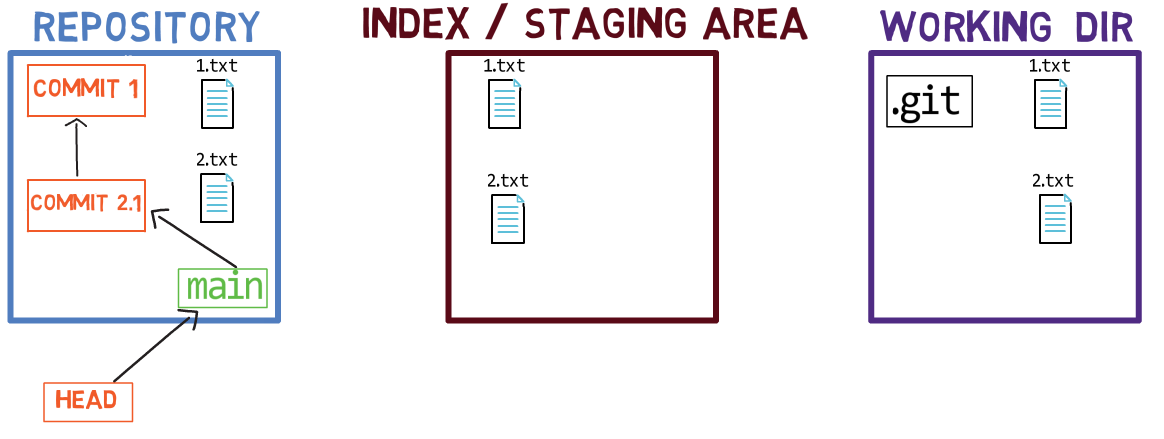
Omití el "Commit 2" ya que no es alcanzable desde el HEAD, aunque su objeto existe en la base de datos de objetos interno de Git.
¿Por qué "Commit 2" y "Commit 2.1" son distintos? Inclusive si usáramos el mismo mensaje de confirmación, y aunque apunten al mismo objeto de árbol (de la carpeta raíz consistiendo de 1.txt y 2.txt), todavía tienen distintas marcas de tiempo, ya que fueron creados en diferentes tiempos. Ambos "Commit 2" y "Commit 2.1" ahora apuntan a "Commit 1", sino que solamente "Commit 2.1" es alcanzable desde el HEAD.
git reset --mixed
Es tiempo de deshacer aún mas allá. Esta vez, usa:
git reset --mixed HEAD~1
(Nota: --mixed es el conmutador predeterminado para git reset.)
Este comando comienza de la misma forma que git reset --soft HEAD~1. Eso es, el comando toma el puntero de cualquier HEAD que está apuntando ahora, el cual es la rama main, y lo establece a HEAD~1, en nuestro ejemplo - "Commit 1".
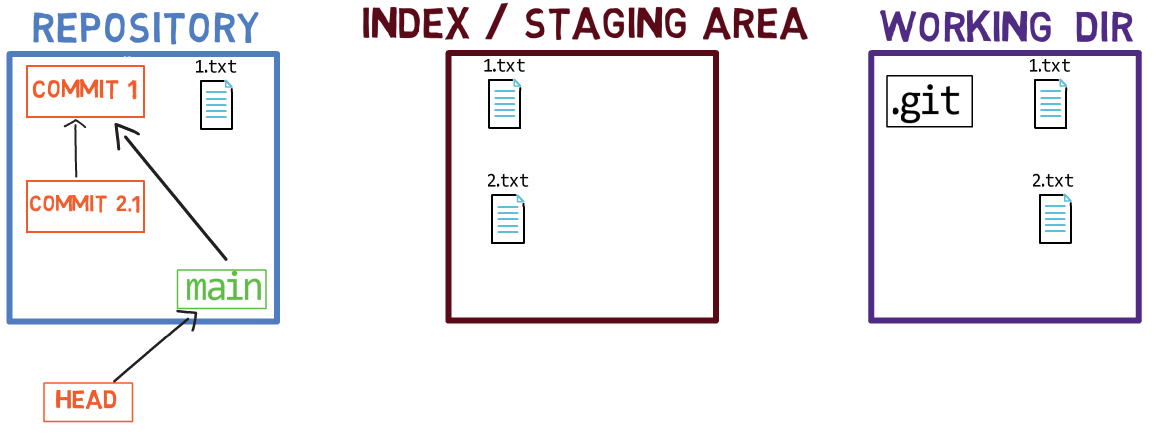
git reset --mixed is the same as git reset --softLuego, Git va más allá, efectivamente deshaciendo los cambios que hicimos al índice. Eso es, cambiar el índice para que coincida con el HEAD actual, el nuevo HEAD después de establecerlo en el primer paso.
Si ejecutáramos git reset --mixed HEAD~1, entonces el HEAD (main) sería puesto al HEAD~1 ("Commit 1"), y luego Git coincidiría el índice al estado de "Commit 1" - en este caso, significa que 2.txt ya no sería parte del índice.

git reset --mixed is to match the index with the new HEADEs tiempo de crear una nueva confirmación con el estado del "Commit 2" original. Esta vez necesita poner en el área de preparación a 2.txt nuevamente antes de crearlo:
git add 2.txt
git commit -m "Commit 2.2"
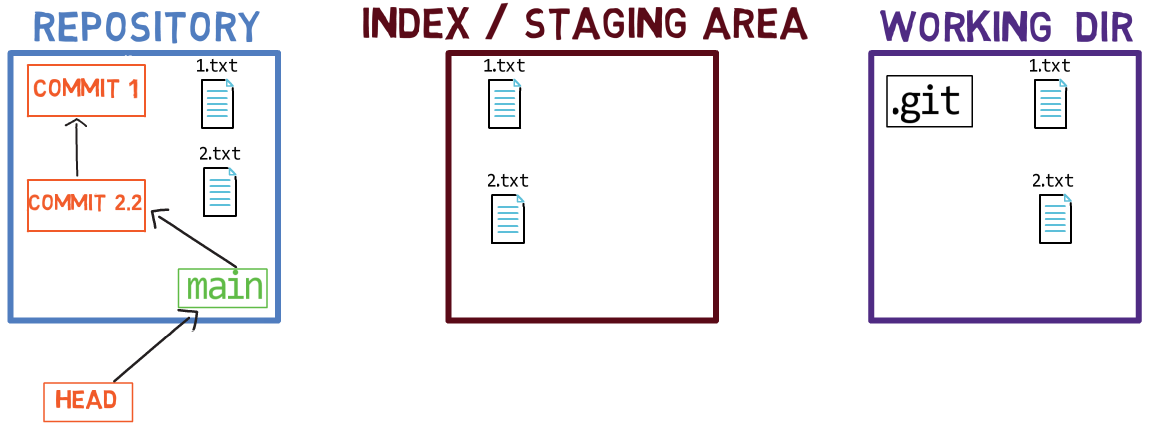
De forma similar a "Commit 2.1", "nombro" a esta confirmación "Commit 2.2" para diferenciarlo del del "Commit 2" original o "Commit 2.1" - estas confirmaciones resultan en el mismo estado que el "Commit 2" original, pero son distintos objetos de confirmación.
git reset --hard
Continúa, ¡deshaz aún más!
Esta vez, usa el conmutador --hard, y ejecuta:
git reset --hard HEAD~1
Una vez más, Git comienza con el paso --soft, estableciendo cualquier HEAD que esté apuntando a (main), a que apunte a HEAD~1 ("Commit 1").
git reset --hard is the same as git reset --softLuego, moviéndonos al siguiente paso --mixed, coincidiendo con el índice con HEAD. Eso es, Git deshace el paso de 2.txt.

git reset --hard is the same as git reset --mixedLuego viene el paso de --hard, donde Git va mas allá y coincide con el directorio de trabajo con la etapa del índice. En este caso, significa también quitar 2.txt del directorio de trabajo.

git reset --hard matches the state of the working dir with that of the index(Nota: en este caso específico, el archivo no está registrado, así que no será eliminado del sistema de archivos; no es realmente importante para entender git reset.)
Así que para introducir un cambio en Git, tienes tres pasos: cambias el directorio de trabajo, el índice, o el área de preparación, y luego confirmas una nueva copia instantánea con esos cambios. Para deshacer estos cambios:
- Si usamos
git reset --soft, deshacemos el último paso. - Si usamos
git reset --mixed, también deshacemos el paso del copia instantánea. - Si usamos
git reset --hard, deshacemos los cambios al directorio de trabajo.

git resetEscenarios de la vida real
Escenario #1
Así que en un escenario de la vida real, escribe "I love Git" en un archivo (love.txt), ya que todos amamos Git 😍. Adelante, pónlo en el área de preparación y confirmas esto también:
echo I love Git > love.txt
git add love.txt
git commit -m "Commit 2.3"
También, guarda una etiqueta así puedes volver a esta confirmación más tarde si es necesario:
git tag scenario-1
Oh, oops!
En realidad, no quería que lo confirmaras.
Lo que en realidad quería que hicieras era escribir algunas otras palabras lindas en este archivo antes de confirmarlo.
¿Qué puedes hacer?
Bueno, una forma de superar esto sería usar git reset --mixed HEAD~1, efectivamente deshaciendo tanto la confirmación y las acciones del área de preparación que tomaste:
git reset --mixed HEAD~1
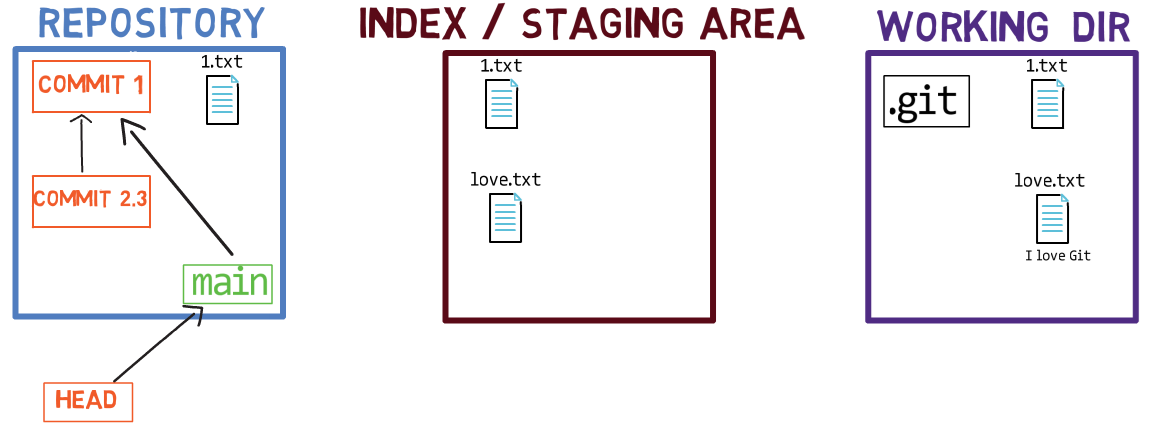
Así que main apunta a "Commit 1" nuevamente, y love.txt ya no es una parte del índice. Sin embargo, el archivo permanece en el directorio de trabajo. Ahora puedes agregarle mas contenido:
echo and Gitting Things Done >> love.txt
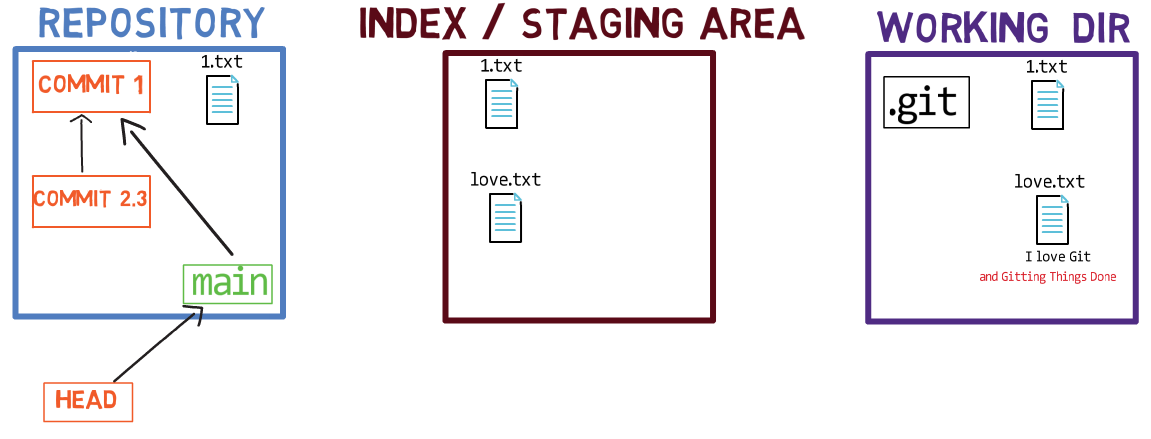
Pónlo en el área de preparación y confirma tu archivo:
git add love.txt
git commit -m "Commit 2.4"
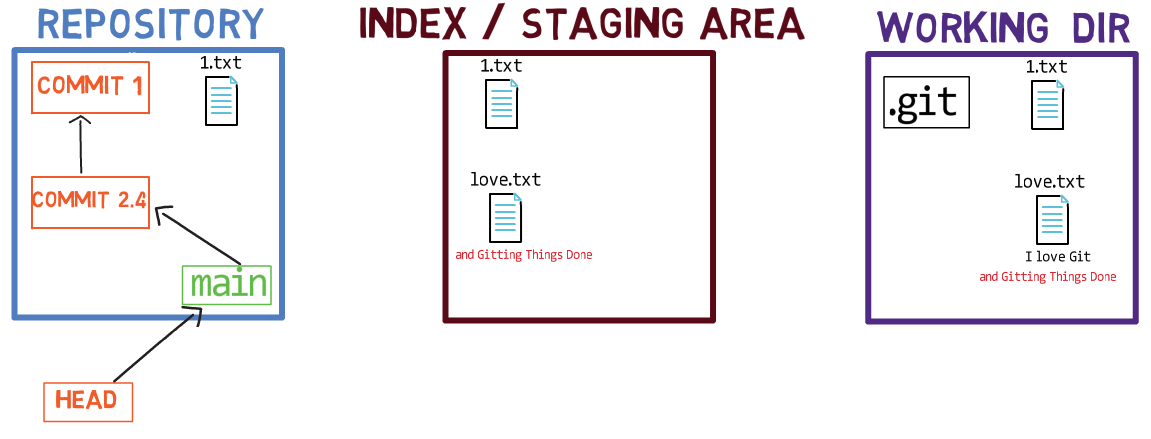
¡Bien hecho!
Lo tienes claro, lindo historial de "Commit 2.4" apuntando a "Commit 1".
Ahora tienes una nueva herramienta en tu caja de herramientas, git reset.
Esta herramienta es super, super útil, y puedes logar casi cualquier cosa con él. No es siempre la herramienta más conveniente, pero es capaz de resolver casi cualquier escenario de reescritura de historial si lo usas con cuidado.
Para principiantes, te recomiendo usar solamente git reset para casi cualquier vez que quieras deshacer en Git. Una vez que te sientas cómodo con él, continúa con otras herramientas.
Escenario #2
Consideremos otro caso.
Crea un nuevo archivo llamado new.txt; pónlo en el área de preparación y confirma:
echo this is a new file > new.txt
git add new.txt
git commit -m "Commit 3"
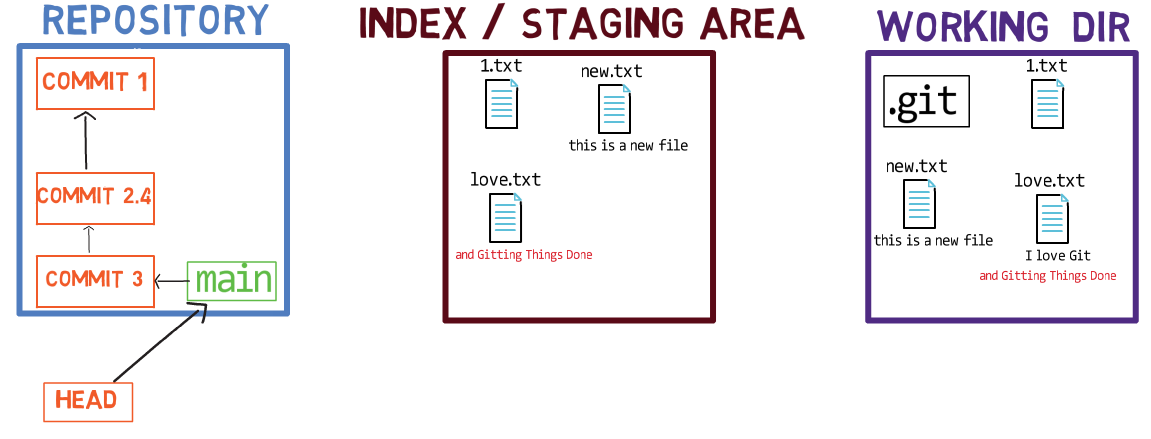
new.txt and "Commit 3"(Nota: En el dibujo omití los archivos del repositorio para evitar desorden. Commit 3 incluye 1.txt, love.txt y new.txt en esta etapa.)
Ups. En realidad, eso es un error. Estabas en main, y quería que crearas esta confirmación en una rama feature. Mi culpa 😇
Hay dos herramientas mas importantes que quiero que tomes de este capítulo. El segundo es git reset. El primero y el más importante es limpiar el estado actual versus el estado en el que quieres que esté.
Para este escenario, el estado actual y el estado deseado lucen así:
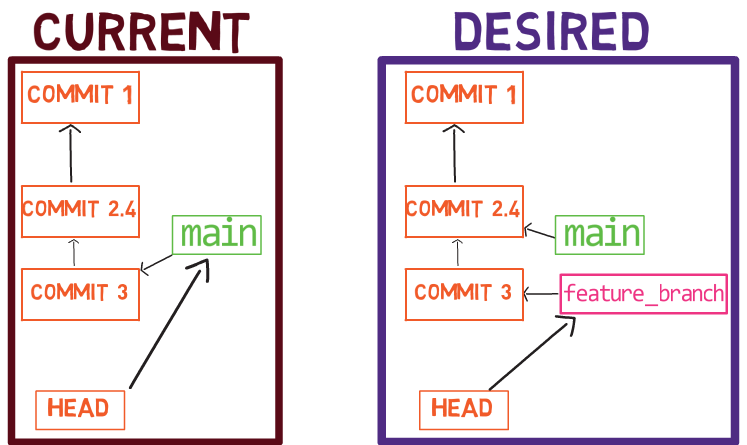
(Nota: En las diagramas siguientes, me referiré al estado actual como el estado "original" - antes de empezar el proceso de reescribir el historial.)
Notarás tres cambios:
mainapunta a "Commit 3" (el azul) en el estado actual, pero apunta a "Commit 2.4" en el estado deseado.feature_branchno existe en el estado actual, aunque existe y apunta al "Commit 3" en el estado deseado.HEADapunta amainen el estado actual, y apunta afeature_branchen el estado deseado.
Si lo puedes dibujar y sabes cómo usar git reset, puedes definitivamente salir de esta situación.
Así que nuevamente, lo más importante es tomar un respiro y dibujarlo.
Observando el dibujo de arriba, ¿cómo llegas al estado deseado del estado actual?
Hay unas pocas formas por supuesto, pero te presentaré una opción solamente para cada escenario. Siéntete libre de jugar con otras opciones también.
Puedes comenzar usando git reset --soft HEAD~1. Esto pondría a main a que apunte a la confirmación previa, "Commit 2.4":
git reset --soft HEAD~1
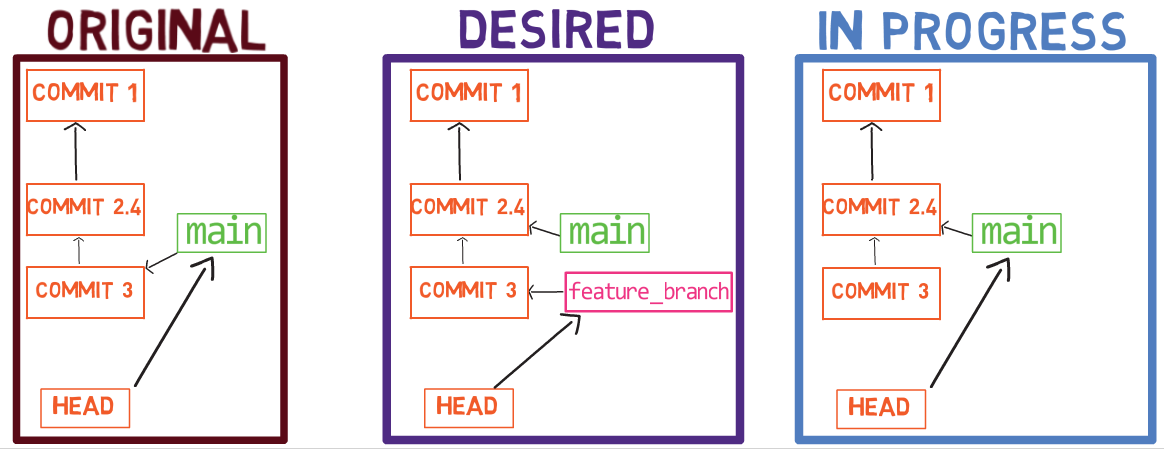
main: "Commit 3" is still there, just not reachable from HEADMirando el diagrama actual-vs-deseado (original-vs-desired) nuevamente, puedes ver que necesitas una nueva rama, ¿no? Puedes usar git switch -c feature_branch para eso, o git checkout -b feature_branch (el cual hace lo mismo):
git switch -c feature_branch
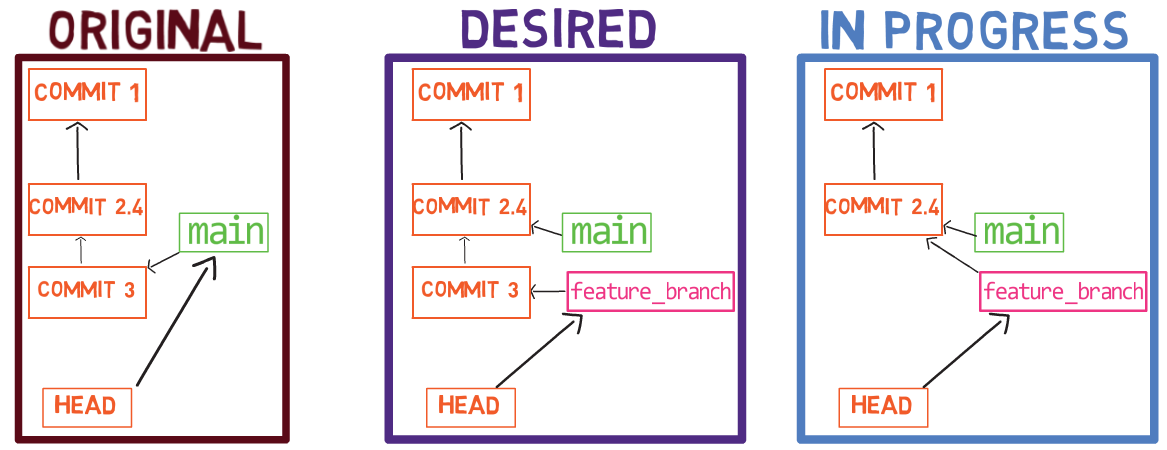
feature_branch branchEste comando también actualiza el HEAD a que apunte a la nueva rama.
Ya que usaste git reset --soft, no cambiaste el índice, así que actualmente tiene exactamente el estado que quieres confirmar - ¡qué conveniente! Puedes simplemente confirmar a feature_branch:
git commit -m "Commit 3.1"
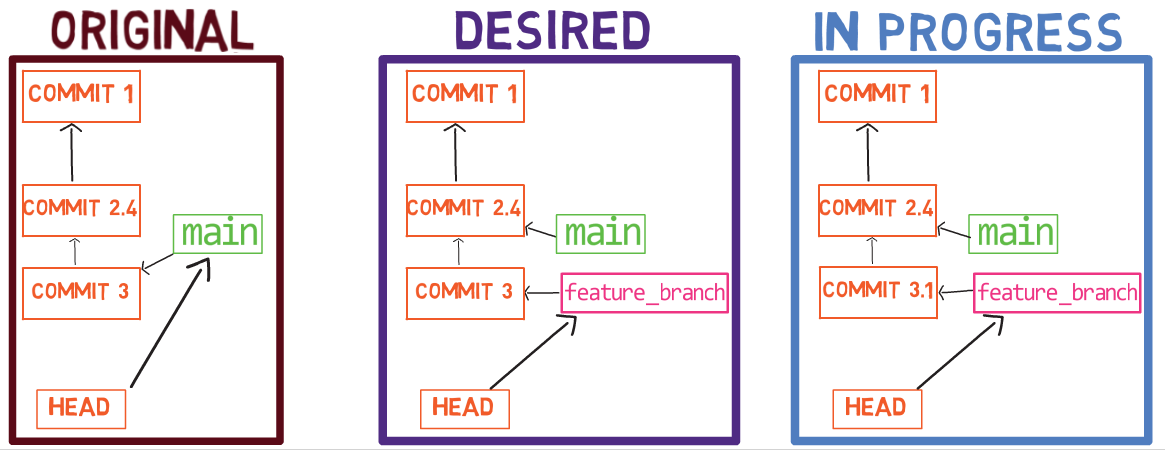
feature_branch branchY llegas al estado deseado.
Escenario #3
¿Listo para aplicar tus conocimientos para casos adicionales?
Todavía en feature_branch, agrega algunos cambios a love.txt, y crea un nuevo archivo llamado cool.txt. Pónlos en el área de preparación y confirma:
echo Some changes >> love.txt
echo Git is cool > cool.txt
git add love.txt
git add cool.txt
git commit -m "Commit 4"
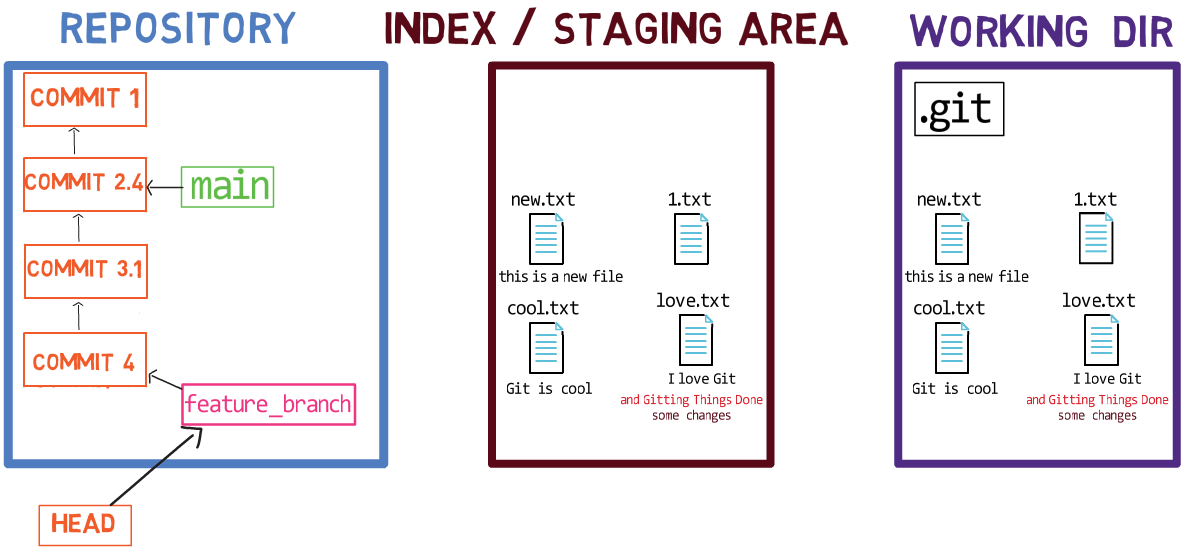
Oh, ups, en realidad quería que crearas dos confirmaciones separadas, una con cada cambio...
¿Quieres intentar este por ti mismo (antes de seguir leyendo)?
Puedes deshacer los pasos de confirmación y del área de preparación:
git reset --mixed HEAD~1
Siguiendo este comando, el índice ya no incluye esos dos cambios, pero todavía están en tu sistema de archivos:
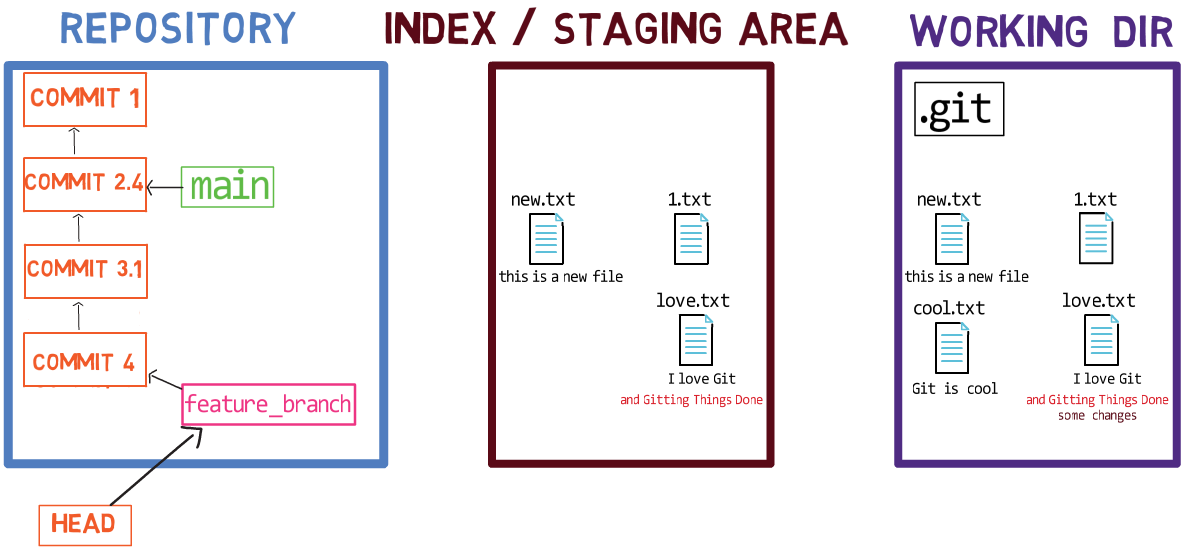
git reset --mixed HEAD~1Así que ahora, si solamente pones en el área de preparación a love.tx, puedes confirmarlo de forma separada:
git add love.txt
git commit -m "Love"
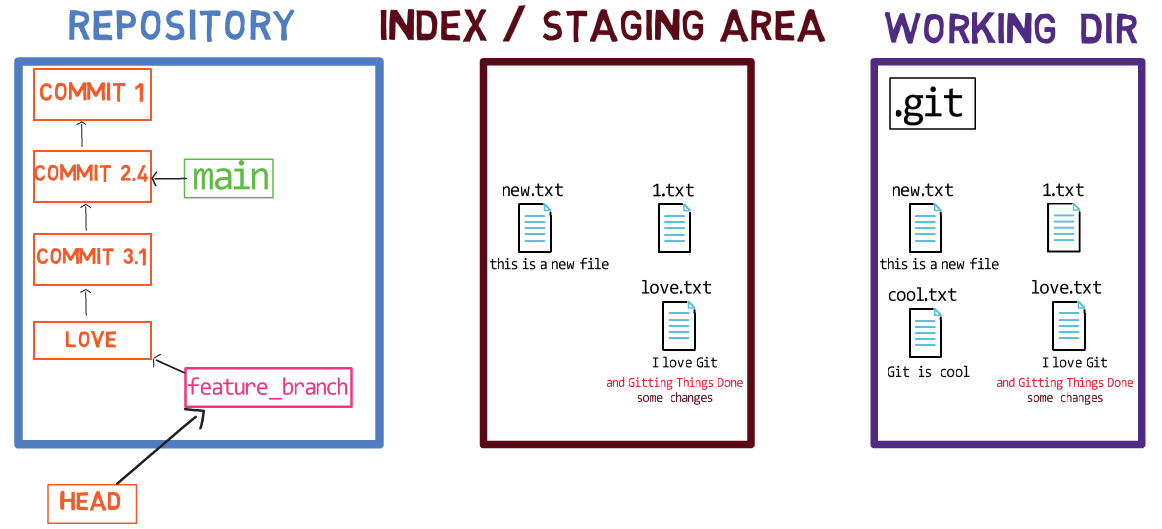
love.txtLuego, haz lo mismo para cool.txt:
git add cool.txt
git commit -m "Cool"
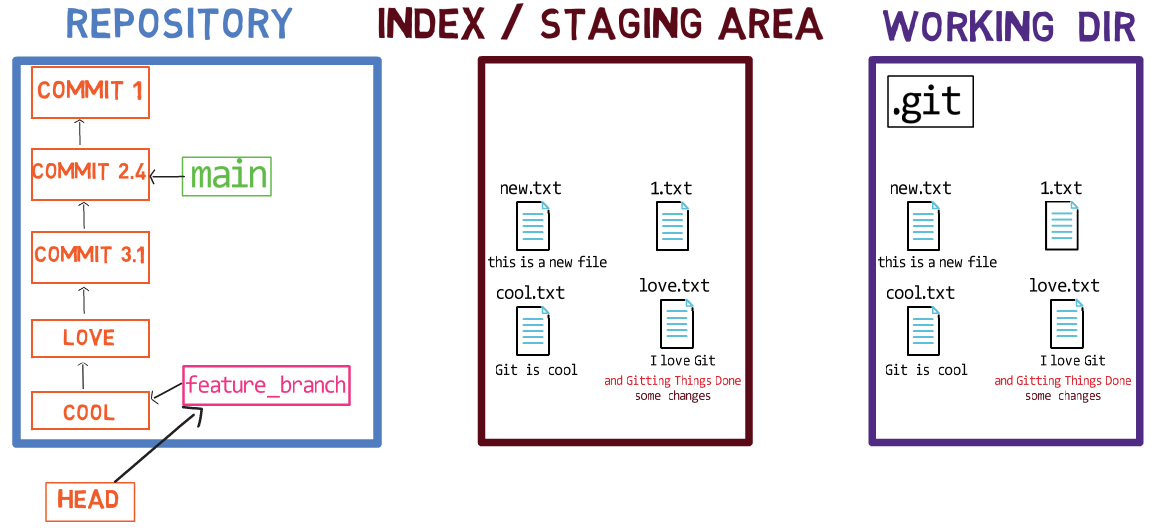
¡Genial!
Escenario #4
Para limpiar el estado, cambia a main y usa reset --hard para hacer que apunte a "Commit 3.1", mientras pones el índice y el directorio de trabajo al estado de "Commit 3.1":
git checkout main
git reset --hard <SHA_OF_COMMIT_3_1>
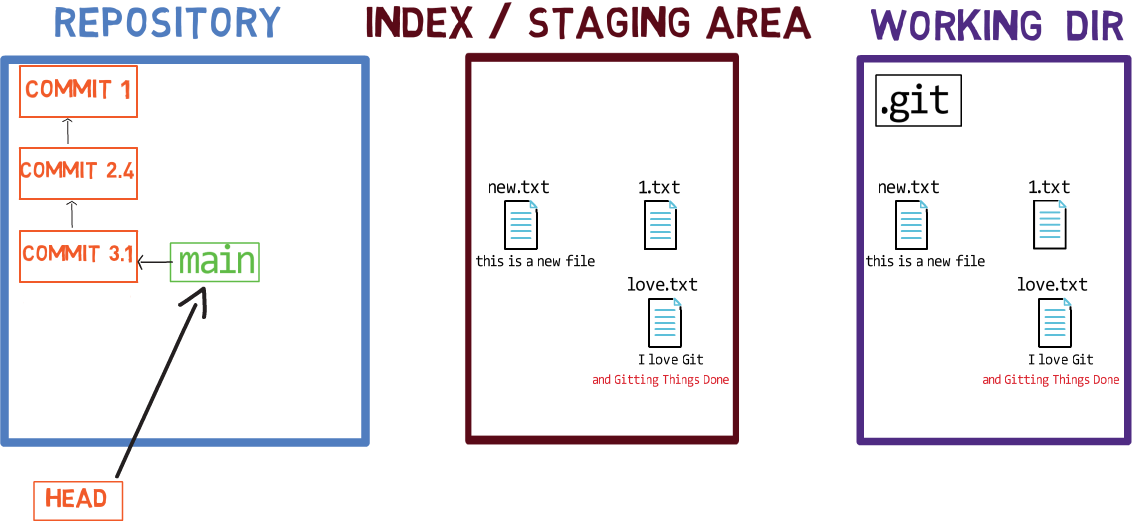
main to "Commit 3.1"Crea otro archivo (another.txt) con algo de texto, y agrega algo de texto a love.txt. Pónlos en el área de preparación ambos cambios, y confirmarlos:
echo Another file > another.txt
echo More love >> love.txt
git add another.txt
git add love.txt
git commit -m "Commit 4.1"
Este debería ser el resultado:
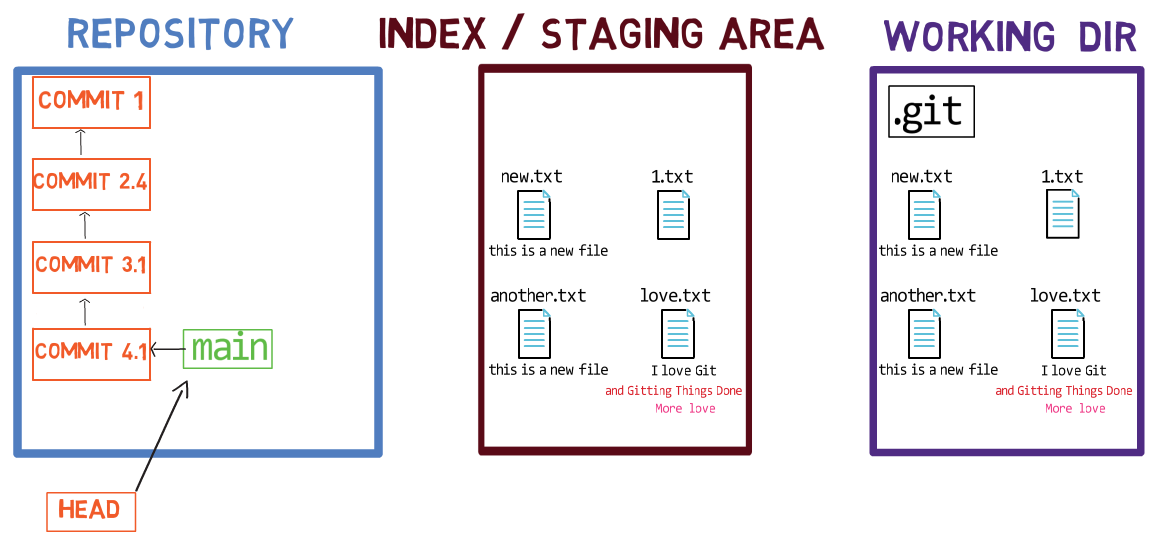
Ups...
Así que esta vez, quería que esté en otra rama, pero no una nueva rama, sino - una rama ya existente.
Así que, ¿qué puedes hacer?
Te daré una pista. La respuesta es realmente corta y fácil. ¿Qué hacemos primero?
No, no reset. Dibujemos. Esto es lo primero en hacer, ya que haría todo lo demás más fácil. Así que este es el estado actual:
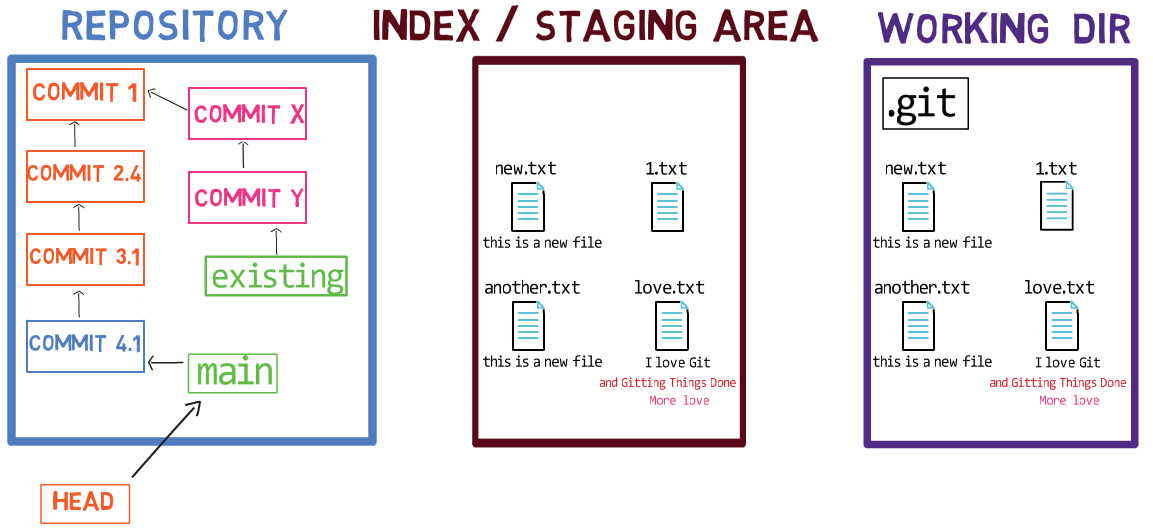
main appears blue¿Y el estado deseado?
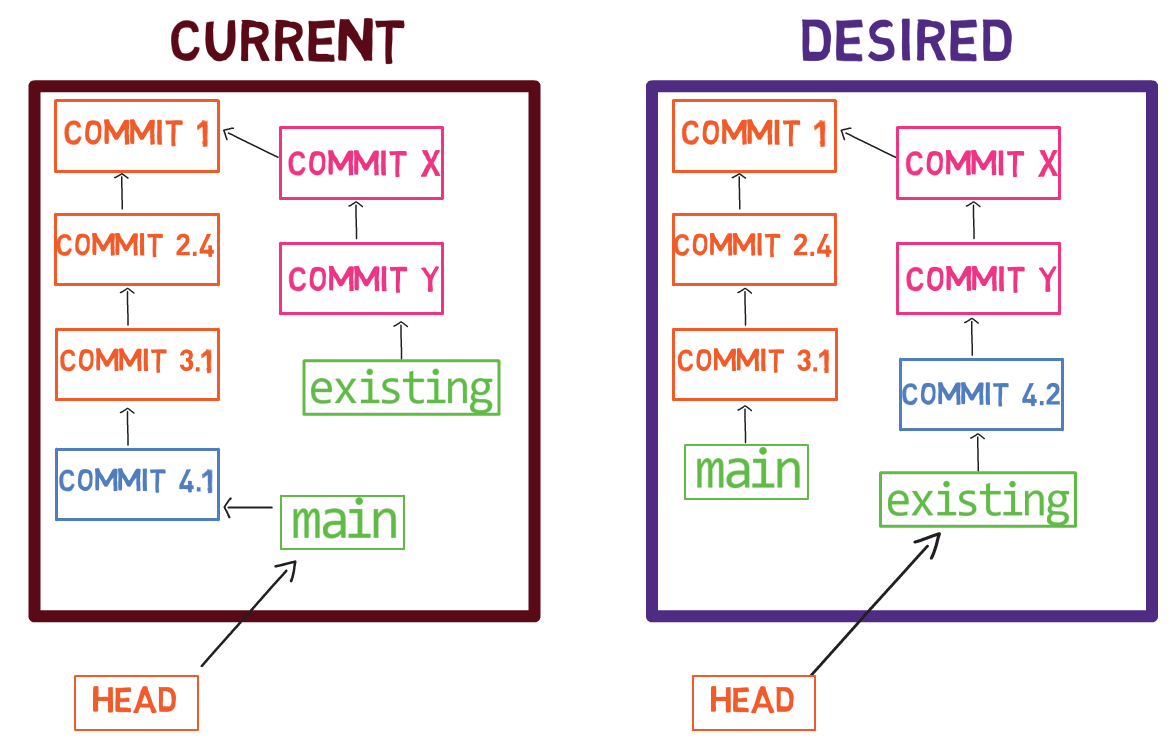
existing, branch¿Cómo obtienes el estado actual al estado deseado, qué sería más fácil?
Una forma sería usar git reset como hiciste antes, pero hay otra forma que me gustaría intentar.
Fíjate que los siguientes comandos en sí asumen que la rama existing existe en tu repositorio, aunque no lo has creado anteriormente. Para coincidir un estado donde esta rama existe, puedes usar los siguientes comandos:
git checkout <SHA_OF_COMMIT_1>
git checkout -b existing
echo "Hello" > x.txt
git add x.txt
git commit -m "Commit X"
git checkout <SHA_OF_COMMIT_3_1> -- love.txt
git commit -m "Commit Y"
git checkout main
(El comando git checkout <SHA_OF _COMMIT_3_1> -- love.txt copia los contenidos de love.txt desde "Commit 3.1" al índice y el directorio de trabajo, así puedes confirmarlo en la rama existing. Necesitamos el estado de love.txt en el "Commit Y" que sea lo mismo que "Commit 3.1" para evitar conflictos.)
Ahora tu historial debería coincidir con el que se muestra en la imagen con el subtítulo "Queremos que la confirmación "blue" esté en otra rama, existing".
Primero, haz que el HEAD apunte a la rama existente:
git switch existing
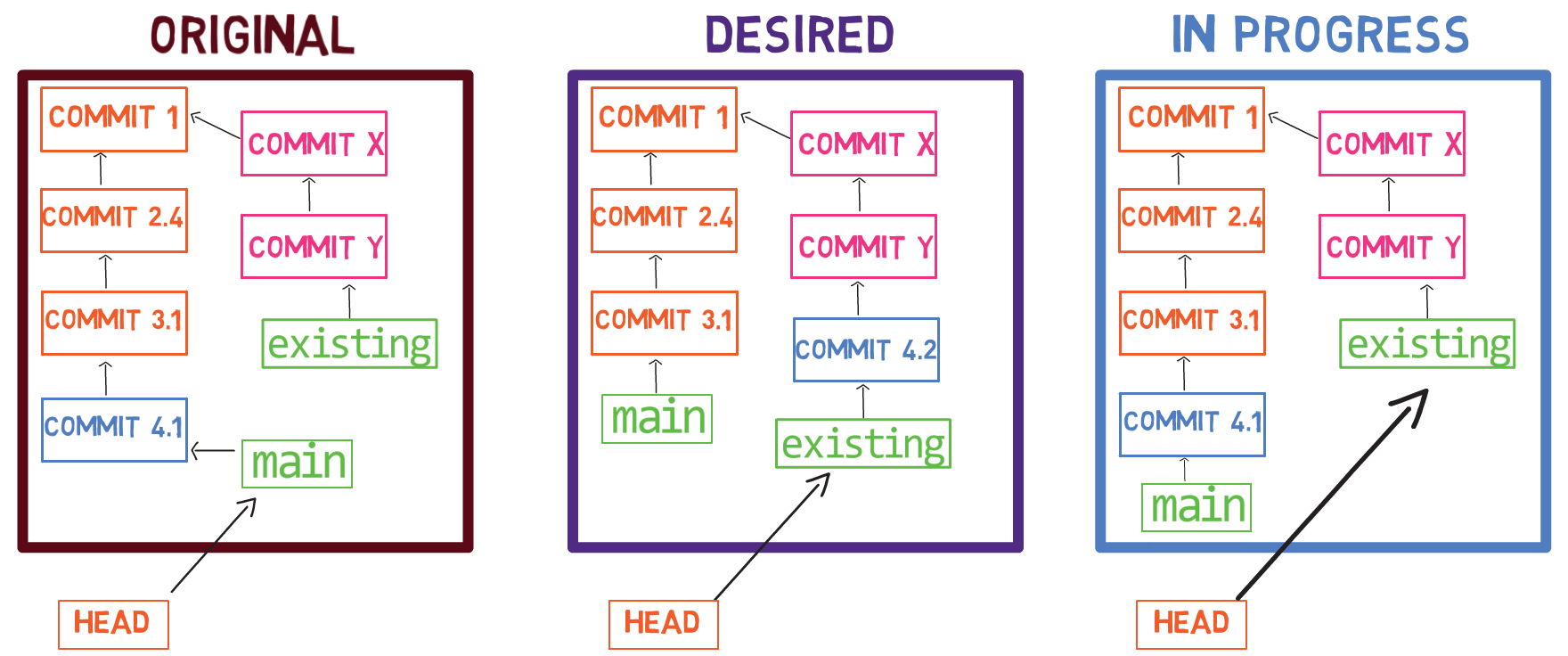
existing branchIntuitivamente, lo que quieres hacer es tomar los cambios introducidos en el "Commit 4.1", y aplicar estos cambios ("copiar-pegar") por encima de la rama exisitng. Y Git tiene una herramienta para eso.
Para pedirle a Git que tome los cambios introducidos entre una confirmación y su confirmación antecesor y sólo aplicar estos cambios en la rama activa, puedes usar git cherry-pick, un comando que introducimos en el capítulo 8. Este comando toma los cambios introducidos en la versión específicada y aplicarlos al estado de la confirmación activa. Ejecuta:
git cherry-pick <SHA_OF_COMMIT_4_1>
Puedes especificar el identificador SHA-1 de la confirmación deseada, pero también puedes usar git cherry-pick main, como la confirmación cuyos cambios estás aplicando es al que está apuntando main.
git cherry-pick también crea un nuevo objeto de confirmación, y actualiza la rama activa a que apunte a este nuevo objeto, así que el estado resultante sería:
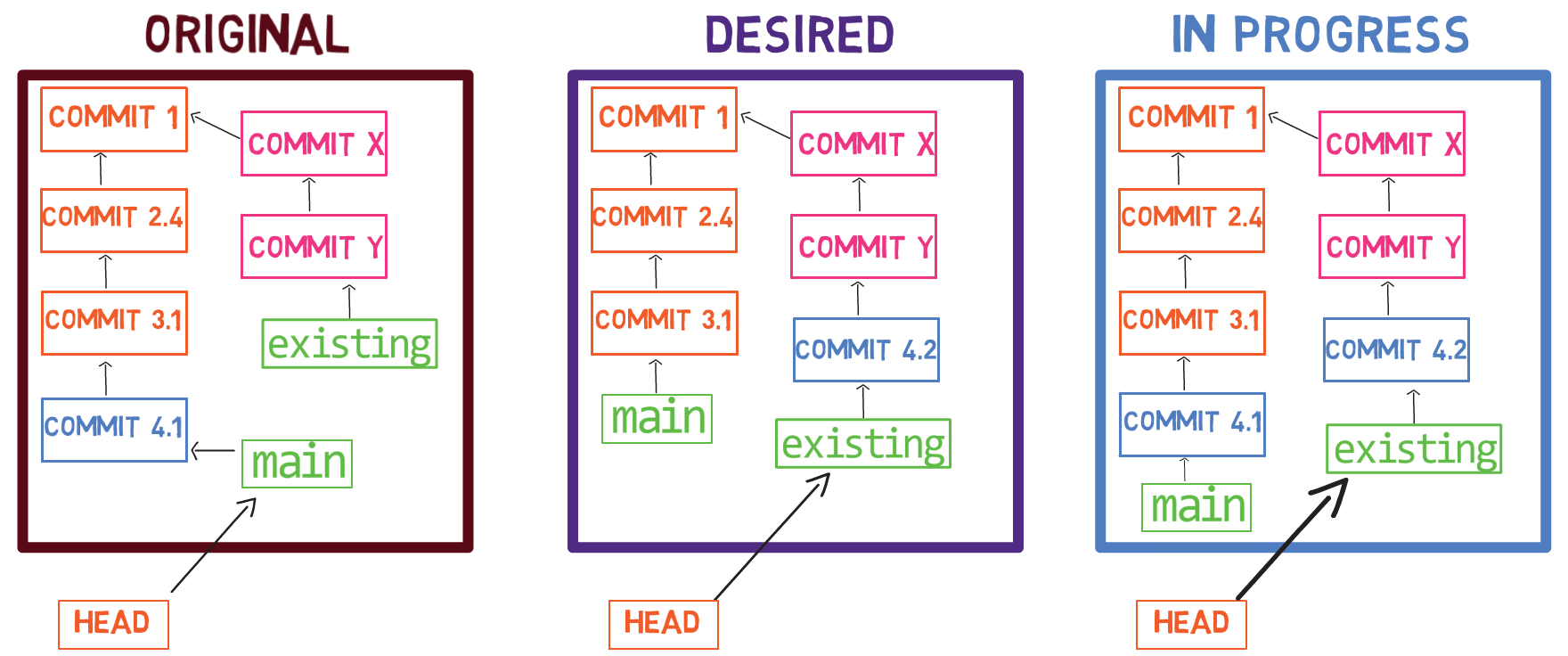
git cherry-pickMarco a la confirmación como "Commit 4.2" ya que tiene una marca de tiempo, un antecesor y un valor SHA-1 distinto de "Commit 4.1", aunque los cambios que introducen son los mismos.
Hiciste buen progreso - la confirmación deseada está ahora en la rama ¡existing! Pero no queremos que estos cambios existan el rama main. git cherry-pick solamente aplicó los cambios a la rama existente. ¿Cómo puedes quitarlos del main?
Una forma sería volver a main, y luego hacer reset:
git switch main
git reset --hard HEAD~1
Y el resultado:
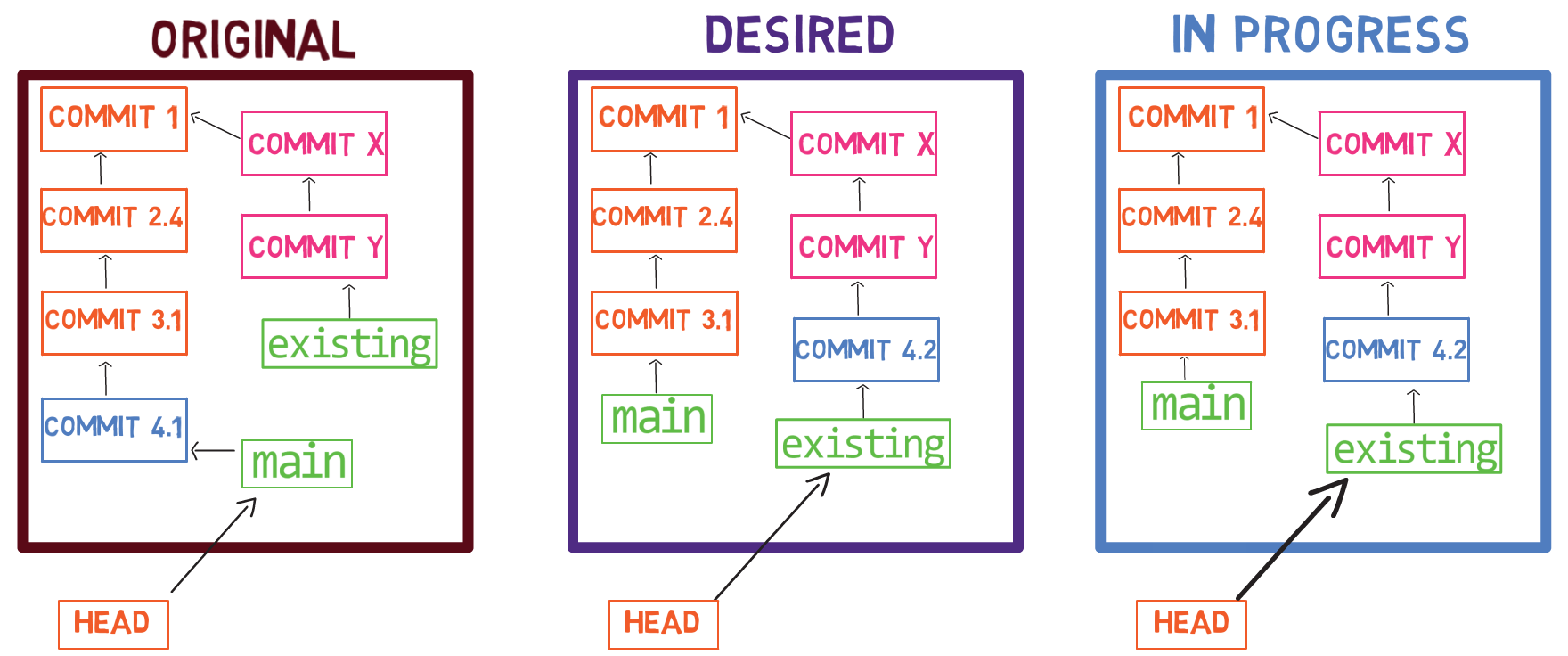
main¡Lo hiciste!
Fíjate que git cherry-pick en realidad calcula la diferencia entre la confirmación especificada y su antecesor, y luego aplica la diferencia a la confirmación activa. Esto significa que a veces, Git no será capaz de aplicar esos cambios debido a un conflicto.
También, fíjate que puedes pedirle a Git que haga cherry-pick de los cambios introducidos en cualquier confirmación, no solamente las confirmaciones referenciadas por una rama.
Recapitulación - Git Reset
En este capítulo, aprendimos cómo git reset opera, y clarificó sus tres modos principales de operación:
git reset --soft <commit>, el cual cambia cualquierHEADal que esté apuntando - a<commit>.git reset --mixed <commit>, el cual pasa por la etapa--soft, y también establece el estado del índice para que coincida con el deHEAD.git reset --hard <commit>, el cual pasa por las etapas--softy--mixed, y luego pone el estado del directorio de trabajo para que coincide con el del índice.
Luego aplica tus conocimientos sobre git reset para que resuelva algunos problemas de la vida real que surgen cuando se usa Git.
Al entender la forma en que Git opera, y al limpiar el estado actual versus el estado deseado, puedes abarcar con toda confianza todo tipo de escenarios.
En capítulos futuros, cubriremos comandos de Git adicionales y cómo nos pueden ayudar a resolver todo tipos de situaciones no deseadas.
Capítulo 10 - Herramientas adicionales para deshacer cambios
En el capítulo previo, conociste a git reset. De hecho, git reset es una herramienta super poderosa, y te recomiendo mucho usarlo hasta que te sientas completamente confiado con él.
Aunque, git reset no es la única herramienta a nuestra disposición. Algunas veces, no es la herramienta más conveniente para usar. En otras veces, no es suficiente. Este corto capítulo abordo algunas herramientas que son útiles para deshacer cambios en Git.
git commit --amend
Considera el Escenario #1 del capítulo anterior nuevamente. Como recordatorio, escribiste "I love Git" en un archivo (love.txt), lo pusiste en el área de preparación y confirmaste este archivo:
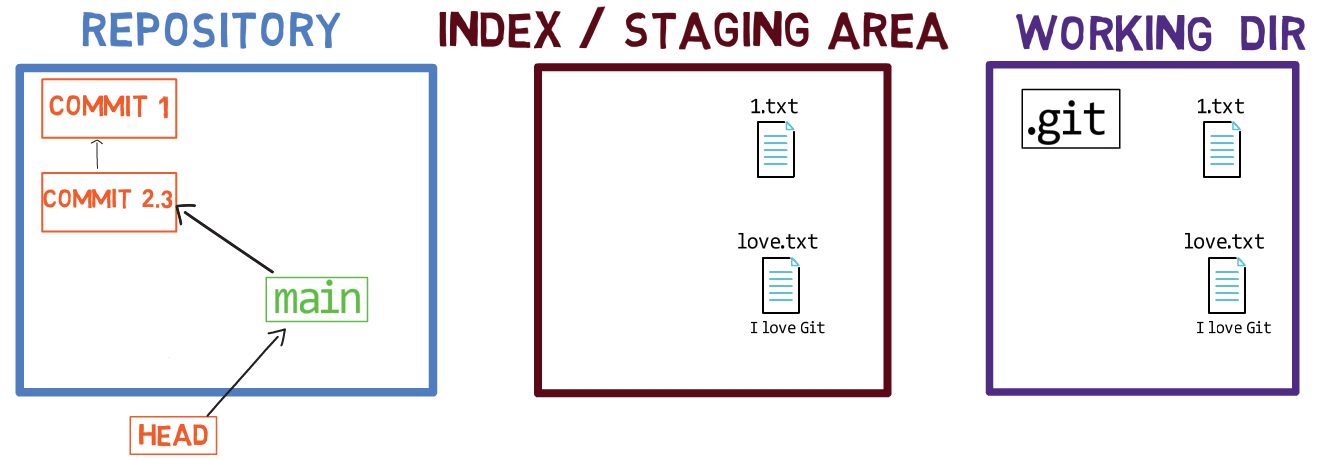
Y luego me di cuenta que no quería que lo confirmaras a ese estado, sino - que escribieras algunas palabras de amor en este archivo antes de confirmarlo.
Para coincidir con este estado, simplemente revisa la etiqueta que creaste, el cual apunta a "Commit 2.3":
git checkout scenario-1
En el capítulo previo, cuando introdujimos git reset, resolviste este error usando git reset --mixed HEAD~1, deshaciendo efectivamente las acciones de confirmación y las acciones puesto en el área de preparación que hiciste.
Ahora me gustaría considerar otro enfoque. Continúa trabajando en el estado de la última confirmación introducida ("Commit 2.3", referenciado por la etiqueta "scenario-1"), y haz los cambios que quieras:
echo And I love this book >> love.txt
Agrega este cambio al índice:
git add love.txt
Ahora, puedes usar git commit con el conmutador --ammend, el cual le dice que sobreescriba la confirmación al que HEAD está apuntando. En realidad, creará otra nueva confirmación, que apunta a HEAD~1 ("Commit 1" en nuestro ejemplo), y hará que HEAD apunte a esta nueva confirmación creada. Proveyendo el argumento -m puedes especificar un nuevo mensaje de confirmación también:
git commit --amend -m "Commit 2.4"
Después de ejecutar este comando, HEAD apunta a main, el cual apunta a "Commit 2.4", el cual en sí apunta a "Commit 1". El "Commit 2.3" previo ya no es alcanzable desde el historial.
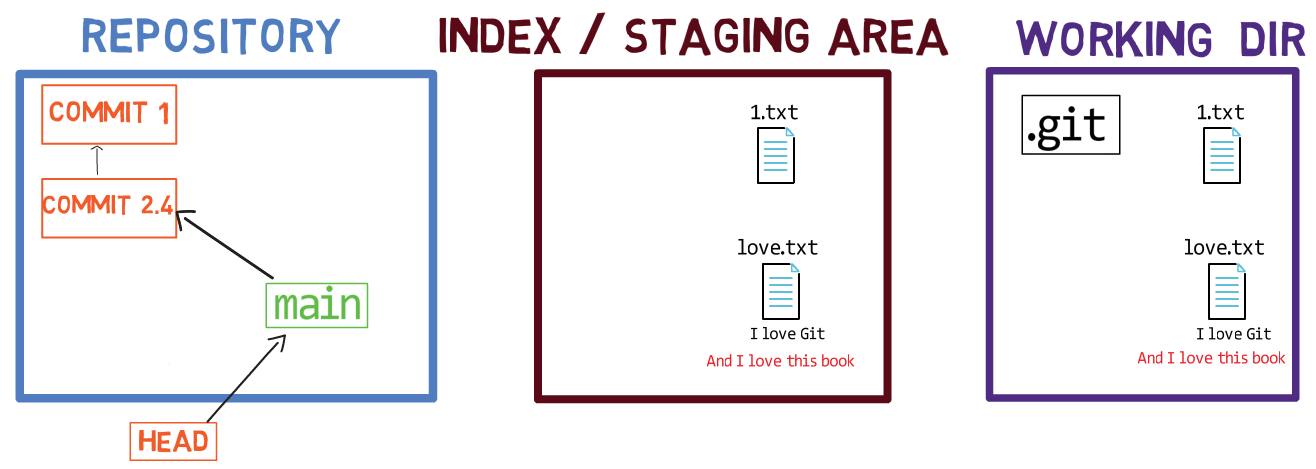
git commit --amend (Commit "2.3" is unreachable and thus not included in the drawing)Esta herramienta es útil cuando quieras sobrescribir rápidamente la última confirmación que creaste. De hecho, podrías usar git reset para lograr lo mismo, pero puedes ver git commit --ammend como un atajo más conveniente.
git revert
Muy bien, otro día, otro problema.
Agrega el siguiente texto a love.txt, pónlo en el área de preparación y confirma como sigue:
echo This is more tezt >> love.txt
git add love.txt
git commit -m "Commit 3"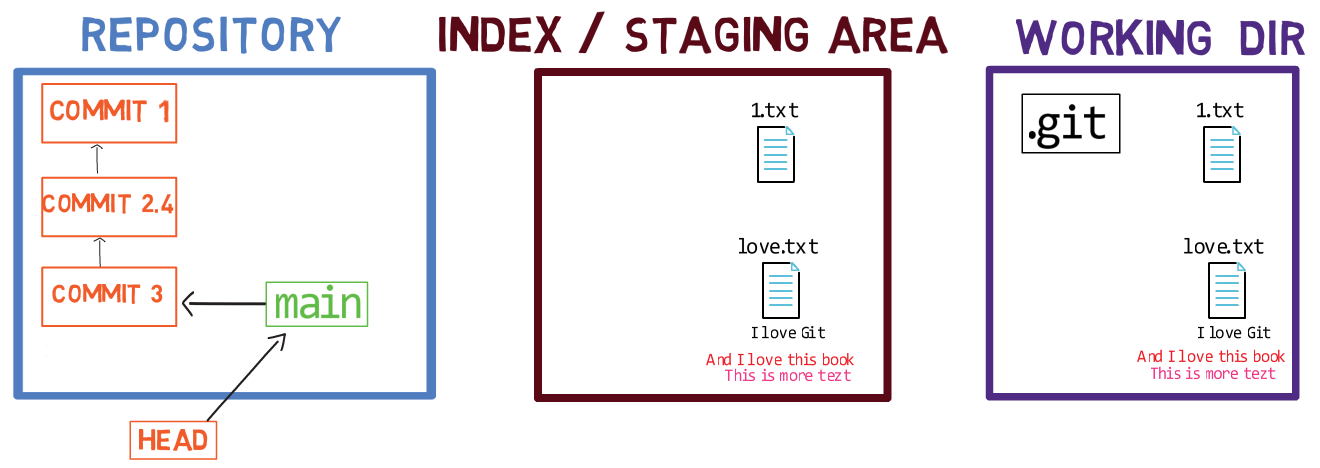
Y empújalo al servidor remoto:
git push origin HEAD
Am, ups 😓…
Noté algo. Tuve un error de tipado aquí. Escribí "This is more tezt" en vez de "This is more text". Woops. Así que, ¿cuál es el problema grande ahora? Hice push, lo que significa que alguien más ya podría haber hecho push de esos cambios.
Si sobrescribo esos cambios usando git reset, tendremos historiales distintos, y todo el infierno podría desatarse. Puedes sobrescribir tu propia copia del repo tanto como quieras hasta que hagas push.
Una vez que hagas push del cambio, necesitas estar seguro que nadie más ha solicitado esos cambios si vas a reescribir el historial.
De forma alternativa, puedes usar otra herramienta llamada git revert. Este comando toma la confirmación que le estás proveyendo y calcula el diff de su confirmación antecesor, así como git cherry-pick, pero esta vez, calcula los cambios inversos. Eso es, si en la confirmación especificada agregaste una línea, el servidor eliminaría la línea, y vice versa.
En nuestro caso estamos revirtiendo "Commit 3", así que la reversa sería eliminar la línea "This is more tezt" de love.txt. Ya que "Commit 3" está referenciado por main y HEAD, podemos usar cualquier de las referencias nombradas en este comando:
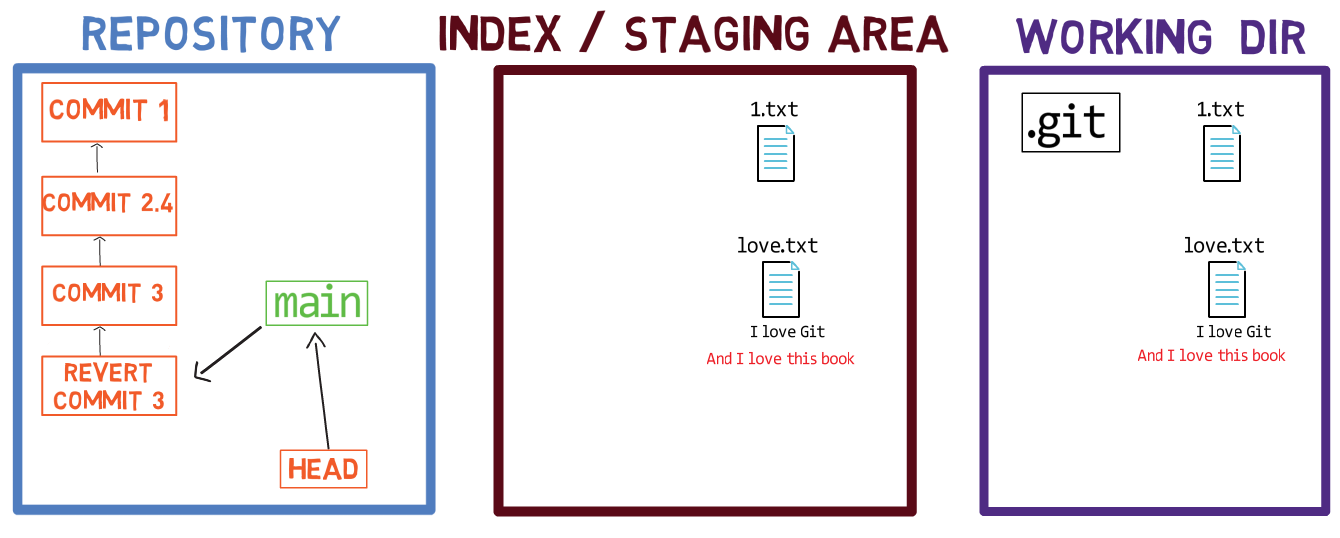
git revert to undo the changesgit revert creó un nuevo objeto de confirmación, lo cual significa que es una adición al historial. Al usar git revert, no reescribiste el historial. Admitiste tu error pasado, y esta confirmación es un reconocimiento que cometiste un error y ahora lo arreglaste.
Alguno diría esta es la forma más madura. Alguno diría que no es un historial tan limpio como lo obtendrías si usaras git reset para reescribir la confirmación previa. Pero este es una forma de evitar reescribir el historial.
Ahora puedes arreglar el error de tipado y confirmar nuevamente:
echo This is more text >> love.txt
git add love.txt
git commit -m "Commit 3.1"
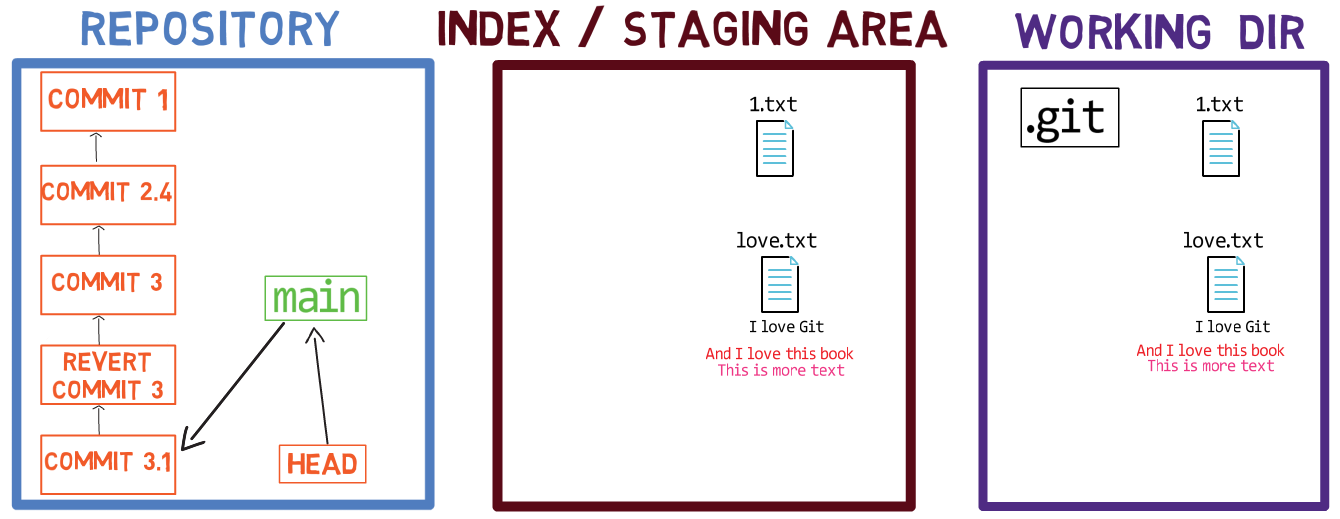
Puedes usar git revert para revertir una confirmación que no sea HEAD. Digamos que quieres revertir el antecesor de HEAD, puedes usar:
git revert HEAD~1
O podrías proveer el SHA-1 de la confirmación para revertir.
Fíjate ya que Git aplicará el parche de reversa del parche anterior - esta operación podría fallar, ya que el parche ya no se podría aplicar y tendrías un conflicto.
Git Rebase como una herramienta para deshacer cosas
En el capítulo 8, aprendiste sobre Git rebase. Lo consideramos principalmente como una herramienta para combinar cambios introducidos en diferentes ramas. Sin embargo, siempre y cuando no hayas hecho push de tus cambios, usando rebase en tu propia rama puede ser una forma muy conveniente para reordenar tu historial de confirmaciones.
Para ello, usualmente harías rebase en una sola rama, y usa el rebase interactivo. Considera nuevamente este ejemplo abarcado en el capítulo 8, donde trabajé desde feature_branch_2, y específicamente edité el archivo code.py. Comencé por cambiar todas las cadenas para que sean envueltas por comillas dobles en vez de comillas simples:
' into " in code.pyLuego, lo puse en el área de preparación y confirmé:
git add code.py
git commit -m "Commit 17"
Luego decidí agregar una nueva función al principio del archivo:
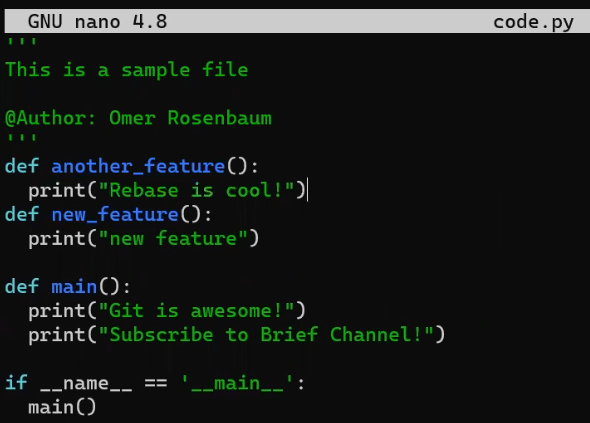
another_featureNuevamente, lo puse en el área de preparación y confirmé:
git add code.py
git commit -m "Commit 18"
Y ahora me di cuenta que en realidad me olvidé de cambiar las comillas simples a comillas dobles al envuelto de __main__ (como lo has visto), así que hice eso también:
'__main__' into "__main__"Por supuesto, lo puse en el área de preparación y confirmé este cambio:
git add code.py
git commit -m "Commit 19"
Ahora, considera el historial:
Como expliqué en el capítulo 8, obtuve un estado con dos confirmaciones que están relacionados uno con el otro, "Commit 17" y "Commit 19" (cambiando ' a "), pero están separados por el "Commit 18" que no está relacionado (donde agregué una nueva función).
Este es un caso básico donde git rebase sería práctico, para deshacer los cambios locales antes de hacer push de un historial limpio.
Intuitivamente, quiero editar el historial aquí:
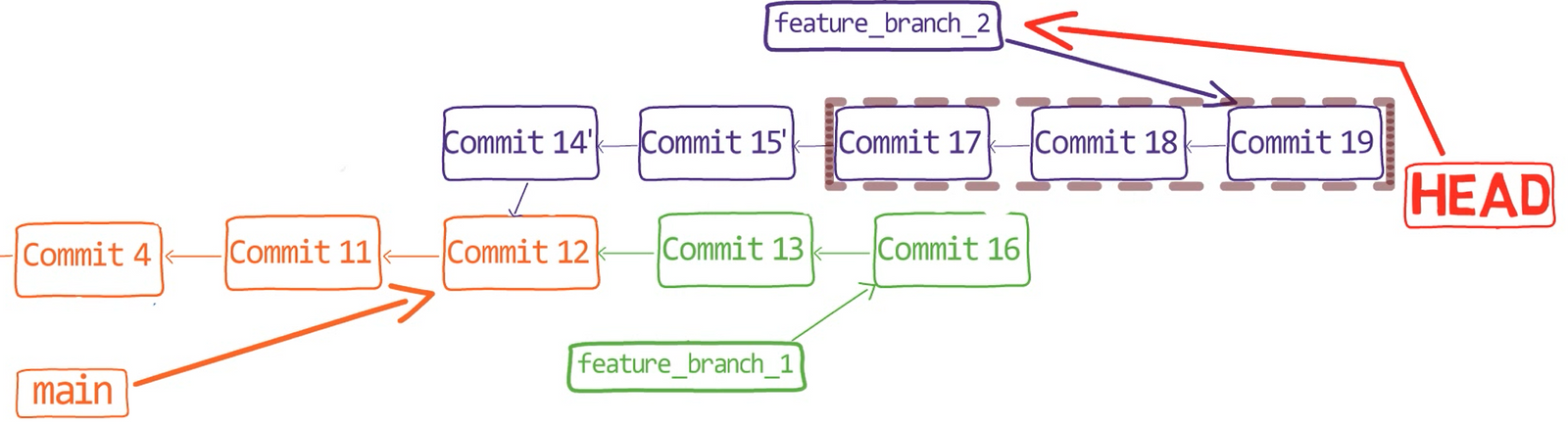
Puedo hacer rebase del historial desde "Commit 17" a "Commit 19", por encima de "Commit 15". Para hacer eso:
git rebase --interactive --onto <SHA_OF_COMMIT_15> <SHA_OF_COMMIT_15>
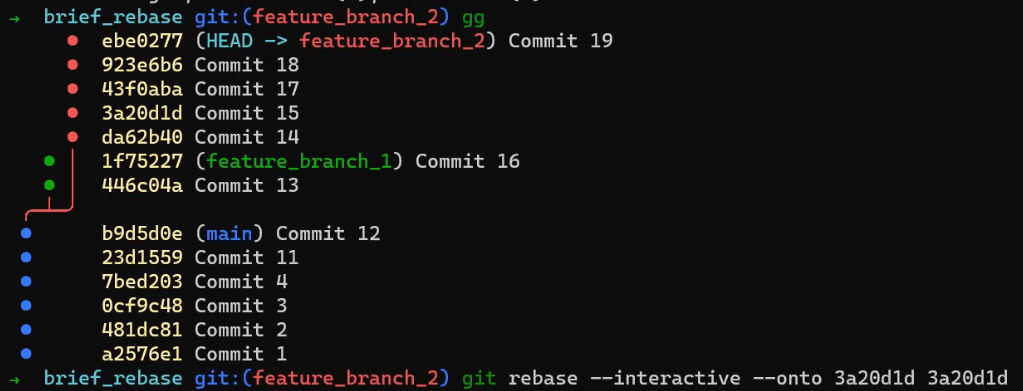
rebase --onto on a single branchEsto resulta en la siguiente pantalla:
Así que, ¿qué haría? Quiero poner a "Commit 19" antes de "Commit 18", así viene justo después de "Commit 17". Puedo ir más lejos y hacerles squash ("aplastarlos", de manera figurativa), así:
Ahora cuando recibo una pantalla para escribir un mensaje de confirmación, puedo proveer el mensaje "Commit 17+19":
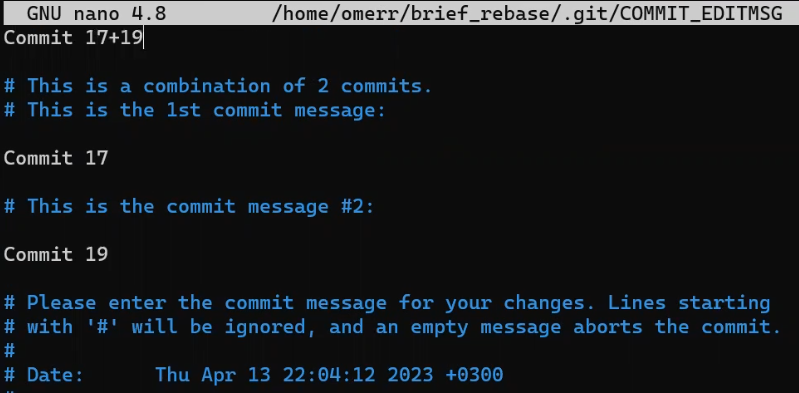
Y ahora, vemos nuestro precioso historial:
La sintaxis usada arriba, git rebase --interactive --onto <COMMIT X> <COMMIT X> sería la sintaxis más usada comúnmente por aquellos que usan rebase regularmente. La manera de pensar que estos desarrolladores usualmente tienen es crear confirmaciones atómicas mientras trabajan, todo el tiempo, sin asustarse de cambiarlos luego. Entonces, antes de hacer push de sus cambios, harían rebase a todo el conjunto de cambios desde el último push, y re-arreglarlo así el historial se vuelve coherente.
git reflog
Es tiempo de considerar un caso más alarmante.
Vuelve al "Commit 2.4":
git reset --hard <SHA_OF_COMMIT_2_4>
Haz algo, escribe algo de código, y agrégalo a love.txt. Pónlo en el área de preparación a este cambio, y confírmalo:
echo lots of work >> love.txt
git add love.txt
git commit -m "Commit 3.2"
(Estoy usando "Commit 3.2" para indicar que este no es la misma confirmación que "Commit 3" que usamos cuando explicamos sobre git revert.)
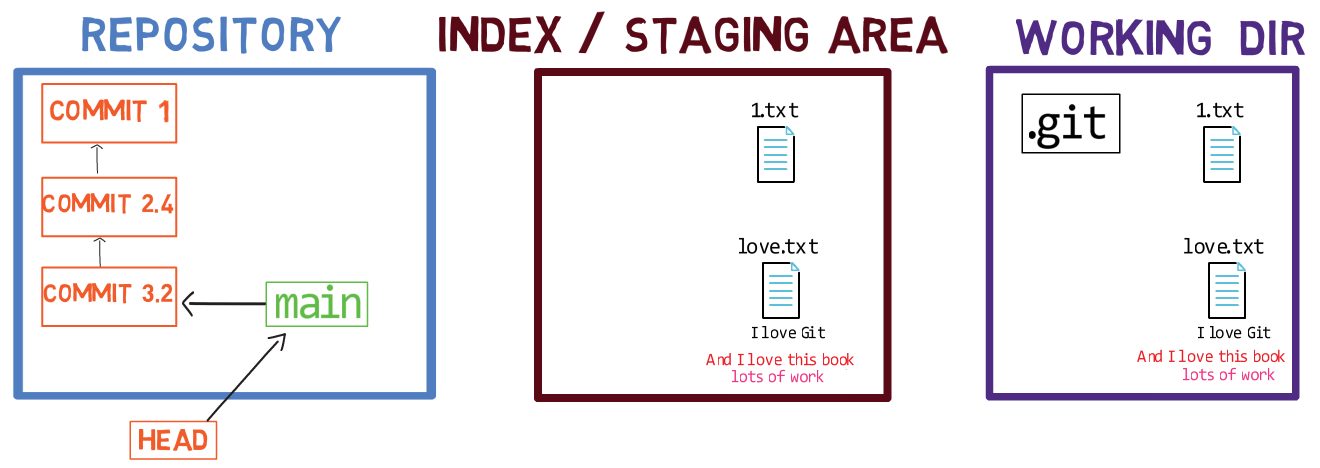
Hice lo mismo en mi máquina, y usé la tecla flecha arriba Up en mi teclado para volver a los comandos anteriores, y luego presioné Enter, y... Wow.
Whoops.

git reset -- hard?¿Acaso usé git reset --hard? 😨
¿Pero qué pasó en realidad? Como aprendiste en el capítulo previo, Git movió el puntero a HEAD~1, de esa forma la última confirmación, con todo mi trabajo precioso, no es alcanzable desde el historial actual. Git también quitó todos los cambios desde el área de preparación, y luego hice coincidir el directorio de trabajo con el del estado del área de preparación.
Eso es, todo coincide con este estado donde mi trabajo... se ha ido.
Momento de terror. Me voy asustando.
Pero, realmente, ¿hay una razón para asustarse? No realmente... Somos personas relajadas. ¿Qué hacemos? Bueno, intuitivamente, ¿realmente, realmente se ha ido la última confirmación?
No. ¿Y por qué no? Todavía existe dentro de la base de datos interno de Git.
Si tan solo supiera dónde está, sabría el valor SHA-1 que identifica a esta confirmación, y podríamos restaurarlo. Inclusive podría deshacer lo deshecho, y hacer reset y volver a esta confirmación.
En realidad, lo único que realmente necesito aquí es el SHA-1 de la confirmación "eliminada".
Ahora la pregunta es, ¿cómo lo encuentro? ¿git log sería útil?
Bueno, no realmente. git log iría al HEAD, el cual apunta a main, el cual apunta a la confirmación antecesora de la confirmación que estamos buscando. Luego, git log recorrería a través de la cadena de antecesores, el cual no incluye la confirmación con mi trabajo precioso.
git log doesn't help in this caseAfortunadamente, los genios que crearon Git también crearon un plan de recuperación para nosotros, y se llama el reflog.
Mientras trabajas con Git, cuando sea que cambies el HEAD, lo cual lo puedes hacer usando git reset, pero también con otros comandos como git switch o git checkout, Git agrega una entrada al reflog.

git reflog shows us where HEAD was¡Encontramos nuestra confirmación! Es el que comienza con 0fb929e.
También podemos relacionarlo por su "nickname" - HEAD@{1}. De forma similar Git usa al HEAD~1 para obtener el primer antecesor de HEAD, y HEAD~2 para que se refiera al segundo antecesor de HEAD, y así sucesivamente, Git usa HEAD@{1} para referirse al primer reflog antecesor de HEAD, eso es, a donde apuntaba HEAD en el paso anterior.
También podemos pedirle a git rev-parse que nos muestre su valor:
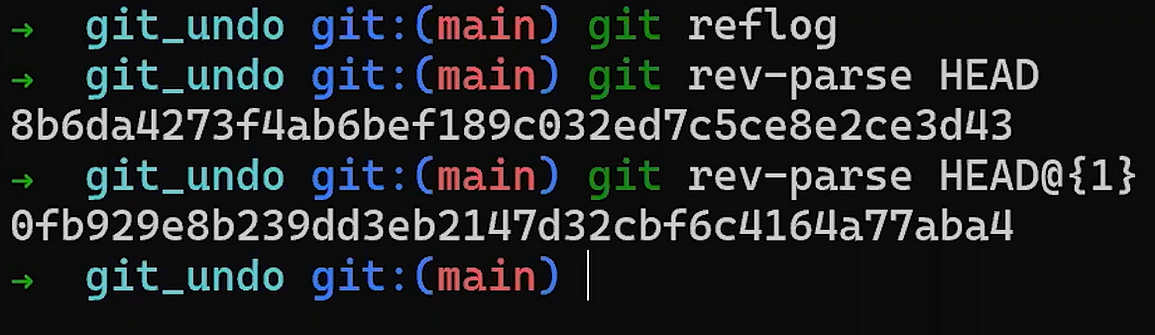
git rev-parse HEAD@{1}Nota: En caso que estés usando Windows, podrías necesitar envolverlo con comillas - así:
git rev-parse "HEAD@{1}"
Otra forma de ver el reflog es usando git log -g, el cual le pide a git log que considere el reflog:
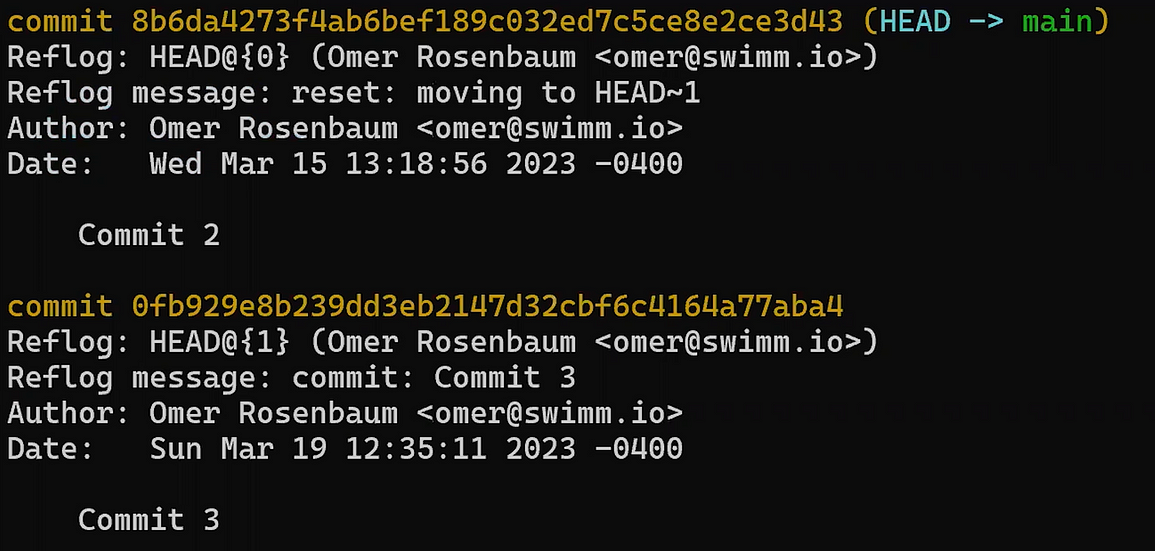
git log -gPuedes ver en la salida de git log -g que la entrada de reflogHEAD@{0}, justo como el HEAD, apunta a main, el cual apunta a "Commit 2". Pero el antecesor de esa entrada en el reflog apunta a "Commit 3".
Así que para volver a "Commit 3", puedes usar git reset --hard HEAD@{1} (o el valor SHA-1 de "Commit 3"):
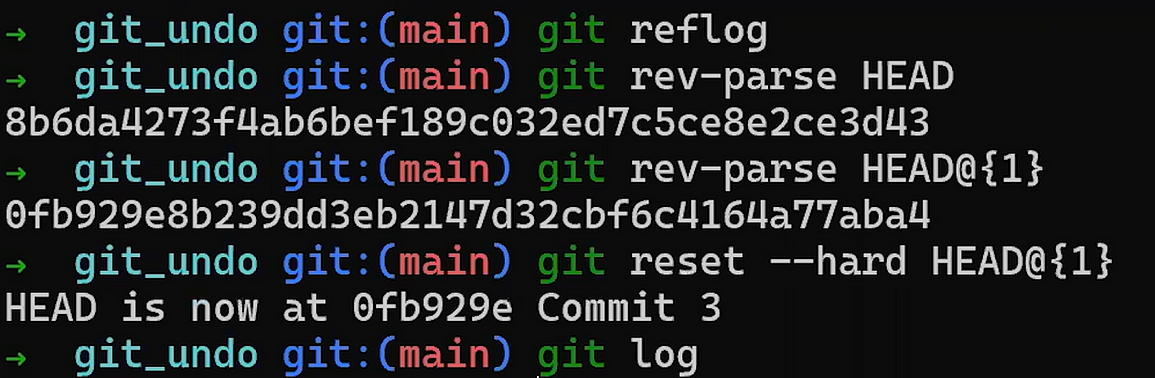
git reset --hard HEAD@{1}Y ahora, si haces git log:
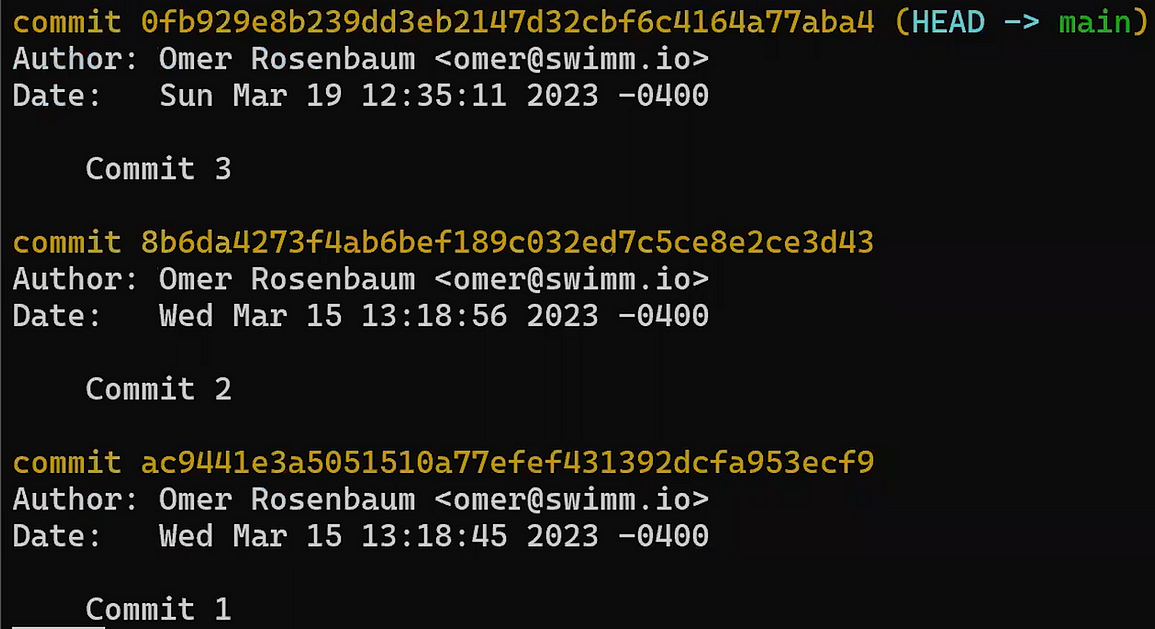
¡Nos salvamos!
¿Qué sucedería si usara este comando nuevamente? ¿Y ejecutara git reset --hard HEAD@{1}?
Git pondría al HEAD a dónde HEAD estaba apuntando antes del último reset, lo que significa a "Commit 2". Podemos continuar todo el día:
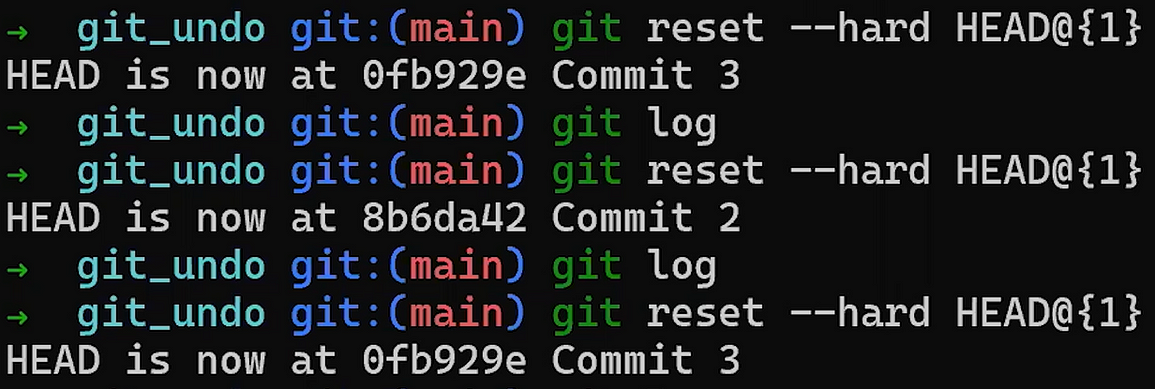
git reset --hard againRecapitulación - Herramientas adicionales para Deshacer Cambios
En el capítulo anterior, aprendiste cómo usar git reset para deshacer cambios.
En este capítulo, agrandaste tu caja de herramientas para deshacer cambios en Git con algunos comandos nuevos:
git commit --ammend- el cual "sobreescribe" la última confirmación con el área de preparación del índice. Mayoritariamente útil cuando confirmaste algo y quieres modificar la última confirmación.git revert- el cual crea una nueva confirmación, que revierte una confirmación anterior agregando una nueva confirmación al historial con los cambios revertidos. Especialmente útil cuando la confirmación "defectuosa" ya ha sido subida al remoto.git rebase- el cual ya los conocías desde el capítulo 8, y es útil para reescribir el historial de confirmaciones múltiples, especialmente antes de empujarlos.git reflog(ygit log -g) - el cual rastrea todos los cambios hasta elHEAD, así puedes encontrar el valor SHA-1 de una confirmación al que necesitas volver.
La herramienta más importante, inclusive más importante que las herramientas que listé, es limpiar la situación actual vs el desado. Créeme en esta, hará que cada situación parezca menos intimidante y la solución más clara.
Hay herramientas adicionales que te permiten revertir cambios en Git (proveeré enlaces en el apéndice), pero la colección de herramientas que cubrí aquí debería prepararte para abarcar cualquier desafío con confianza.
Capítulo 11 - Ejercicios
Este capítulo incluye algunos ejercicios para profundizar tus conocimientos de las herramientas que aprendiste en la Parte 3. La versión completa de este libro también incluye soluciones detalladas de cada una.
Los ejercicios se encuentran en este repositorio:
https://github.com/Omerr/undo-exercises.git
Cada ejercicio está en una rama con el nombre exercise_XX, así que el Ejercicio 1 se encuentra en la rama exercise_01, el Ejercicio 2 se encuentra en la rama exercise_02 y así sucesivamente.
Nota: como se explicó en los capítulos previos, si trabajas con confirmaciones que pueden ser encontradas en un servidor remoto (los cuales son en la que estás en este caso, ya que estás usando mi repositorio "undo-exercises"), deberías probablemente usar git revert en vez de git reset. De la misma forma con git rebase, el comando git reset también reescribe el historial - y así te refrenas de usarlo en las confirmaciones en las que otros podían basarse.
Para los propósitos de estos ejercicios, puedes asumir que nadie ha clonado o haya descargado (pull) el código del repositorio remoto. Sólo recuerda - en la vida real, probablemente deberías usar git revert en vez de comandos que reescriben el historial en tales casos.
Ejercicio 1
En la rama execise_01, considera el archivo hello.txt:

hello.txtEste archivo incluye un error de tipado (en el último caracter). Encuentra la confirmación que introdujo este error de tipado.
Ejercicio (1a)
Quita esta confirmación del historial alcanzable usando git reset (con los argumentos correctos), arregla el error de tipado, y confirma nuevamente. Considera tu historial.
Revierte al estado previo.
Ejercicio (1b)
Quita la confirmación defectuosa usando git commit --ammend, y vuelve al mismo estado del historial como al final del ejercicio (1a).
Revierte al estado previo.
Ejercicio (1c)
Haz revert de la confirmación defectuosa usando git revert y arregla el error de tipado. Considera tu historial.
Revierte al estado previo.
Ejercicio (1d)
Usando git rebase, vuelve al misma estado como al final del ejercicio (1a).
Ejercicio 2
Cambia a la rama exercise_02, y considera los contenidos de exercise_02.txt:
exercise_02.txtUn archivo sencillo, con un caracter en cada línea.
Considera el historial (usando git lol):
git lolOh mi. Cada caracter fue introducido en una confirmación separada. ¡Eso no tiene sentido!
Usa las herramientas que has adquirido para crear un historial donde la creación de exercise_02.txt está hecho en una sola confirmación.
Ejercicio 3
Considera el historial en la rama exercise_03:
exercise_03Esto parece un desastre. Notarás que:
- El orden está sesgado. Necesitamos que "Commit 1" sea la primera confirmación en esta rama, y tenga a "Initial Commit" como su antecesor, seguido de "Commit 2" y así sucesivamente.
- No deberíamos tener "Commit 2a" y "Commit 2b", o "Commit 4a" y "Commit 4b" - estos dos pares necesitan ser combinados en una sola confirmación cada uno - "Commit 2" y "Commit 4".
- Hay un error de tipado en el mensaje de confirmación de "Commit 1", no debería tener 3
m.
Arregla estos errores, pero básate en los cambios de cada confirmación original. El historial resultante debería lucir así:
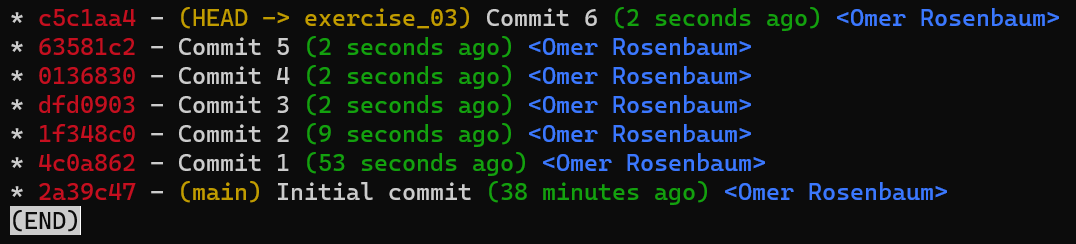
Ejercicio 4
Este ejercicio en realidad consiste de tres ramas: exercise_04, exercise_04_a, y exercise_04_b.
Para ver el historial de estas ramas sin las otras, usa la siguiente sintaxis:
git lol --branches="exercise_04*"
El resultado es:
git lol --branches="exercise_04*"Tu objetivo es hacer que exercise_04_b sea independiente de exercise_04_a. Eso es, obtener este historial:
¡Buena suerte!
Parte 4 - Herramientas de Git Fantásticas y Útiles
Git tiene un montón de comandos, y estos comandos tienen muchísimas opciones y argumentos. Podría intentar cubrirlos todos (aunque cambian con el tiempo), pero no veo el punto en ello. Probablemente deberías conocer un sub-conjunto de estos comandos realmente bien, aquellos que usas regularmente. Luego, siempre puedes buscar por un comando específico para realizar una tarea a mano.
Esta parte se basa en las bases que adquiriste en las partes previas, y cubre comandos específicos y opciones que podrías encontrar útiles. Dado tu entendimiento de cómo funciona Git, tener estas pequeñas herramientas puede hacerte un verdadero pro para llevar a Git a cabo.
Capítulo 12 - Git Log
Usaste git log muchas veces a lo largo de los distintos capítulos, y probablemente lo has usado muchas veces antes de leer este libro.
La mayoría de los desarrolladores usan git log, pocos lo usan de forma efectiva. En este capítulo aprenderás ajustes útiles para sacar el mayor provecho a git log. Una vez que te sientas cómodo con los diferentes conmutadores de este comando, será un verdadero cambio en tu día a día trabajando con Git.
Pensando en ello, git log abarca la esencia de cada versión del sistema de control - es decir, para registrar cambios en las versiones. Registras versiones de esa forma puedes considerar el historial de tu proyecto - tal vez revertir o aplicar cambios específicos, preferir cambiar a un punto distinto en el tiempo y probar las cosas allí. Tal vez te gustaría saber quién contribuyó una cierta pieza de código o cuando lo hicieron.
Mientras que git sí preserva esta información usando objetos de confirmación, eso también apunta a sus confirmaciones antecesoras, y referencias a objetos de confirmación (tales como ramas o HEAD), este almacenamiento de versiones no es suficiente. Sin ser capaz de encontrar la confirmación relevante que te gustaría considerar, o reunir información relevante sobre ello, tener estos datos almacenados es bastante inútil.
Puedes imaginarte a tus objetos de confirmación como distintos libros que se apilan en un pila gigante, o en una biblioteca, llenando largos estantes. La información que podrías necesitar está en estos libros, pero si no tienes un índice - una forma para saber en qué libro yace la información que buscas, o dónde este libro se localiza dentro de la biblioteca - no serías capaz de hacer uso de él. git log es esta indexación de tu biblioteca - es una forma de encontrar las confirmaciones relevantes y la información sobre ellos.
Los argumentos útiles para git log que aprenderás en este capítulo dan formato en cómo se muestran las confirmaciones en el log, o filtran confirmaciones específicas.
git lol, un alias que he usado a lo largo de este libro, usa algunos de estos conmutadores, como lo demostraré. Siéntete libre de ajustar este alias (o crea otro desde cero) después de leer este capítulo.
Como en otros capítulos, el objetivo no es proveer una referencia completa, por lo tanto no proveeré todos los diferentes conmutadores de git lol. Me enfocaré en los conmutadores que creo que los encontrarás útiles.
Filtrando comandos
Considera la salida predeterminada de git log:
git log without additional switchesEl log comienza desde el HEAD, y sigue la cadena de antecesores.
Las Confirmaciones (no) alcanzables desde...
Cuando escribes git log <revision>, git log incluirá todas las entradas accesibles desde <revision>. Con "accesible", me refiero accesible al seguir la cadena de antecesores. Así que ejecutando git log sin argumentos es lo mismo que ejecutar git log HEAD.
Puedes especificar múltiples revisiones para git log- si escribes git log branch_1 branch_2, le pides a git log que incluya cada confirmación que es alcanzable desde branch_1 o branch_2 (o ambos).
git log excluirá cualquier confirmación que sea alcanzable desde las revisiones precedidos por un ^.
Por ejemplo, el siguiente comando:
git log branch_1 ^branch_2
le pide a git log que incluya cada confirmación que es accesible desde branch_1, pero no aquellos que son accesibles desde branch_2.
Considera el historial cuando uso git log feature_branch_2 en este repo:
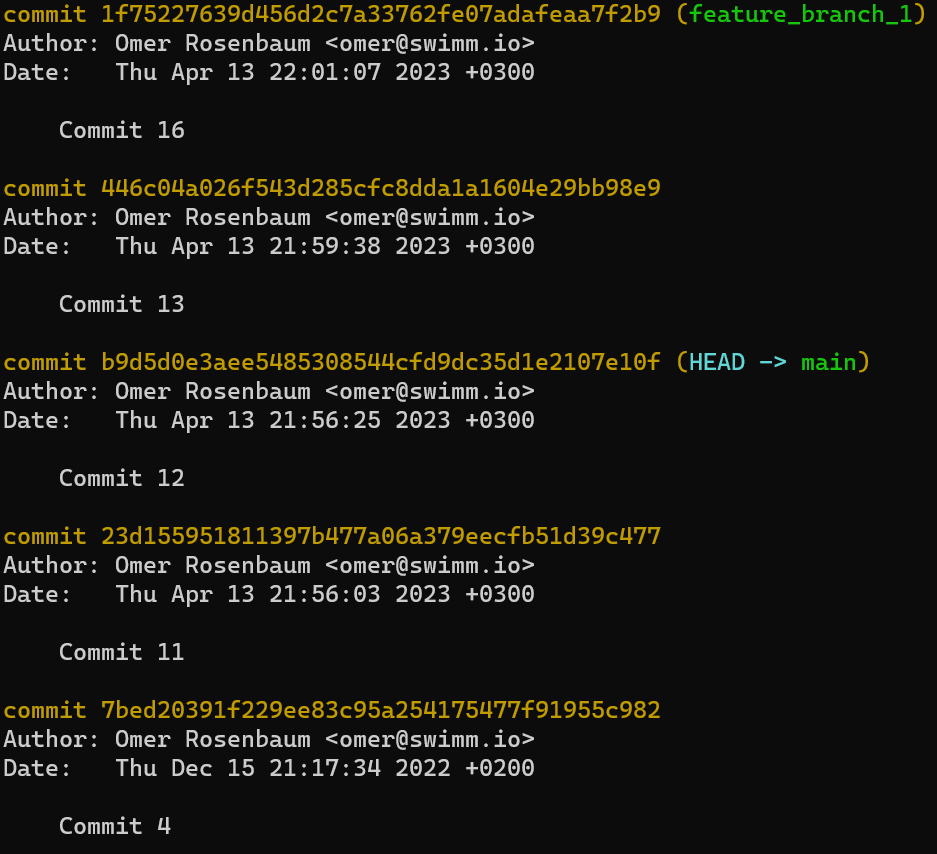
git log feature_branch_1El historial incluye todas las confirmaciones accesibles por feature_branch_1. Ya que esta rama "se creó" desde main (eso es, "Commit 12", al que apunta main, es accesible desde la cadena de antecesores) - el log también incluye todas las confirmaciones accesibles desde main.
¿Qué sucedería si ejecutara este comando?
git log feature_branch_1 ^main
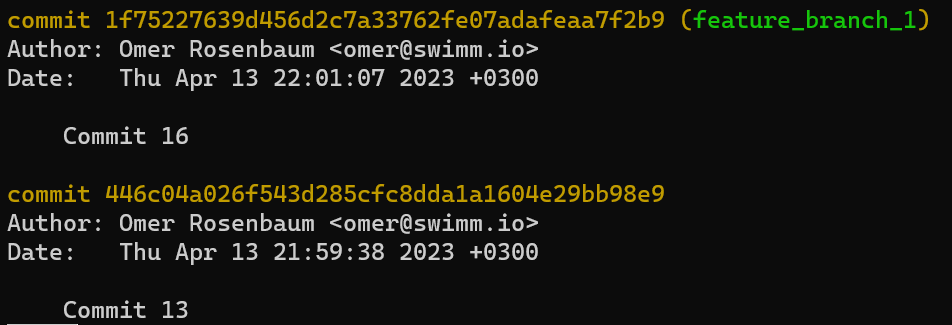
git log feature_branch_1 ^mainEn efecto, git log muestra sólo "Commit 13" y "Commit 16", los cuales son accesibles desde feature_branch_1 pero no desde main.
git log --all
Para seguir las confirmaciones que son accesibles desde cualquier referencia nombrada o (cualquier ref en refs/) o desde el HEAD.
Por Autor
Si sabes que estás buscando una confirmación que tiene una persona específica como autor, puedes filtrar estas confirmaciones usando el nombre del usuario o su email, así:
git log --author="Name"
Puedes usar expresiones regulares para buscar los nombres de los autores que coinciden con un patrón específico, por ejemplo:
git log --author="John\|Jane"
filtrará las confirmaciones cuyo autor es John o Jane.
Por Fecha
Cuando sabes que el cambio que estás buscando ha sido confirmado dentro de una fracción de tiempo específico, puedes usar --before o --after para filtrar las confirmaciones desde esa fracción de tiempo.
Por ejemplo, para obtener todas las confirmaciones introducidos después del 12 de Abril de 2023 (inclusivo), usa:
git log --after="2023-04-12"
Por Rutas
Puedes pedir a git log que sólo muestre las confirmaciones donde los cambios han sido introducidos en rutas específicas. Fíjate que no significa que cualquier confirmación que apunte a un árbol que incluya los archivos en cuestión, sino más bien que si calculamos la diferencia entre la confirmación en cuestión y sus antecesores, veríamos que al menos uno de las rutas ha sido modificado.
Por ejemplo, puedes usar:
git log --all -- 1.py
para encontrar todas las confirmaciones que son accesibles desde cualquier puntero nombrado, o HEAD, e introducir un cambio a 1.py. Puedes especificar múltiples rutas:
git log --all -- 1.py 2.py
El comando previo hará que git log incluya confirmaciones accesibles que introdujeron un cambio a 1.py o 2.py (o ambos).
También puedes usar un patrón glob, por ejemplo:
git log -- *.py
incluirá las confirmaciones que son accesibles desde el HEAD que incluye un cambio a cualquier archivo en el directorio raíz cuyo nombre termina con un .py. Para buscar un archivo que termine con .py, puedes usar:
git log -- **/*.py
Por Mensaje de Confirmación
Si conoces el mensaje de confirmación (o partes de él) de la confirmación que estás buscando, puedes usar el conmutador --grep para "git log", por ejemplo:
git log --grep="Commit 12"
devuelve la confirmación con el mensaje "Commit 12".
Por Contenido de Diff
Este es super útil, y me ha salvado incontables veces. Al usar git log -S, puedes buscar confirmaciones que introducen o quitan una línea en particular del código fuente.
Esto es práctico, por ejemplo, cuando sabes que has creado algo en el repo, pero no sabes dónde está ahora. No puedes encontrarlo en ningún lugar de tu sistema de archivos (no está en el HEAD), y sabes que debe estar ahí - acechando en algún lugar en esta librería (montón de confirmaciones) que tienes.
Digamos que recuerdo dónde escribí una línea con el texto Git is awesome, pero no puedo encontrarlo ahora. Podría ejecutar:
git log --all -S"Git is awesome"
Fíjate que usé --all para evitar limitarme a confirmaciones alcanzables desde el HEAD.
También puedes buscar una expresión regular, usando -G:
git log --all -G"Git .* awesome"
Formateando el Log
Considera la salida predeterminada de git log nuevamente:
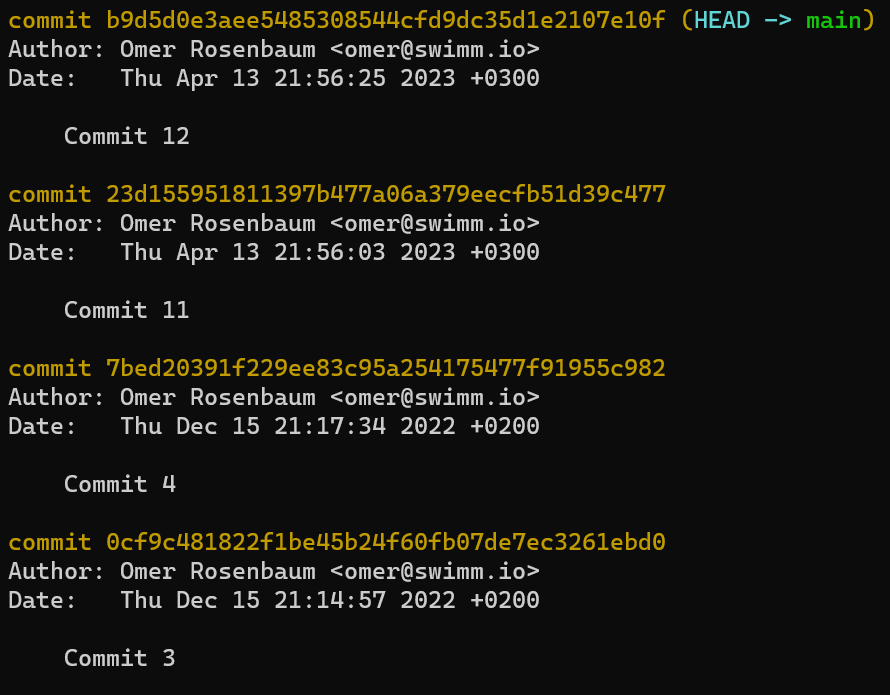
git log without additional switchesEl log comienza desde el HEAD, y sigue la cadena de antecesores.
Cada entrada del log comienza con una línea con commit y luego el SHA-1 de la confirmación, tal vez seguida de punteros adicionales que apuntan a esta confirmación.
Luego es seguido por el autor, fecha, y mensaje de confirmación.
--oneline
La principal dificultad con la salida predeterminada de git log es que es difícil de entender un historial con más de unas pocas confirmaciones, ya que simplemente no los ves a todos.
En la salida de git log que se muestra abajo, solamente cuatro objetos de confirmación aparecieron en mi pantalla. Usando git log --oneline provee una vista más concisa, mostrando el SHA-1 de la confirmación, al lado de su mensaje, y referencia nombradas si son relevantes:
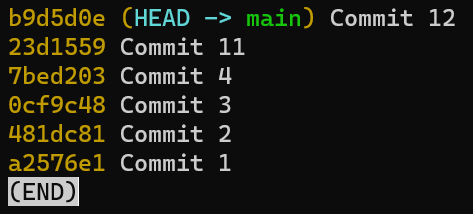
git log --onelineSi deseas omitir las referencias nombradas, puedes agregar el conmutador --no-decorate:
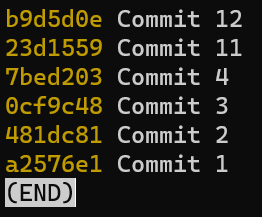
git log --oneline --no-decoratePara pedirle a git log explícitamente que muestre decoraciones, puedes usar git log --decorate.
--graph
git log --oneline muestra una representación compacta. Eso es genial cuando tenemos un historial linear, tal vez en una sola rama. Pero, ¿qué sucede cuando tenemos múltiples ramas, que podría diferir uno del otro?
Considera la salida del siguiente comando en mi repositorio:
git log --oneline feature_branch_1 feature_branch_2
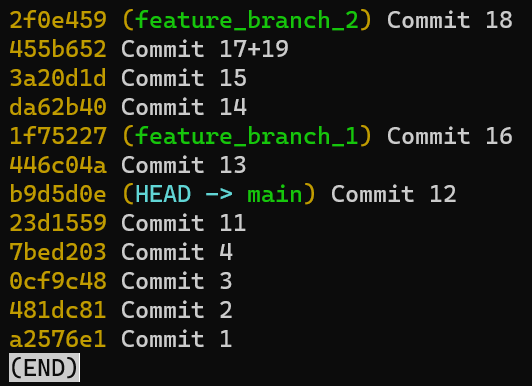
git log --oneline feature_branch_1 feature_branch_2git log muestra cualquier confirmación accesible por feature_branch_1, feature_branch_2, o ambos. Pero, ¿cómo se ve el historial? ¿feature_branch_2 difirió de feature_branch_1? ¿O difirió de main? Es imposible distinguirlo desde esta vista.
Aquí es donde --graph viene a mano, dibujando un gráfico ASCII representando la estructura de la rama del historial de confirmaciones. Si agregamos esta opción al comando previo:
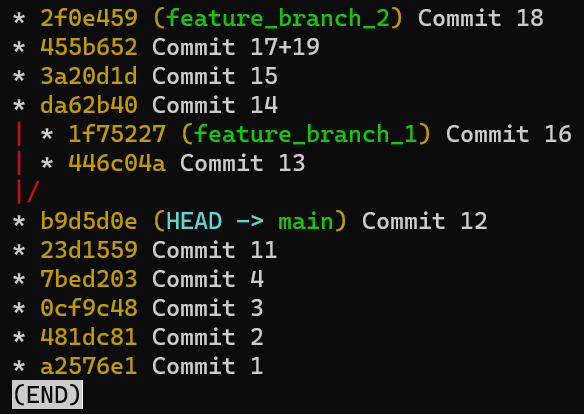
git log --oneline --graph feature_branch_1 feature_branch_2En realidad puedes ver que feature_branch_1 se creó desde main (ya que "Commit 12", main, es el antecesor de "Commit 13"), y también que feature_branch_2 se creó desde main (ya que el antecesor de "Commit 14" también es "Commit 12").
El símbolo * nos dice "en" qué rama está una cierta confirmación, así sabes con certeza que "Commit 13" está en feature_branch_1, y no en feature_branch_2.
--pretty=format
El resultado de arriba, ¡ya es muy útil! Aunque, le falta un par de cosas. No sabemos el autor o el tiempo de la confirmación. Estos dos detalles fueron incluidos en la salida predeterminada de git log el cual fue muy largo. Tal vez, ¿los podemos agregar de una forma más compacta?
Al usar --pretty=format:, puedes mostrar la información de cada confirmación en varias formas usando marcadores de posición al estilo de printf.
En el siguiente comando, los marcadores de posición %s, %an y %cd son reemplazados por el sujeto de la confirmación (mensaje), nombre de autor, y la fecha de la confirmación, respectivamente.
git log --oneline --graph feature_branch_1 feature_branch_2 --pretty=format:"%s (%an) [%cd]"
La salida luce así:
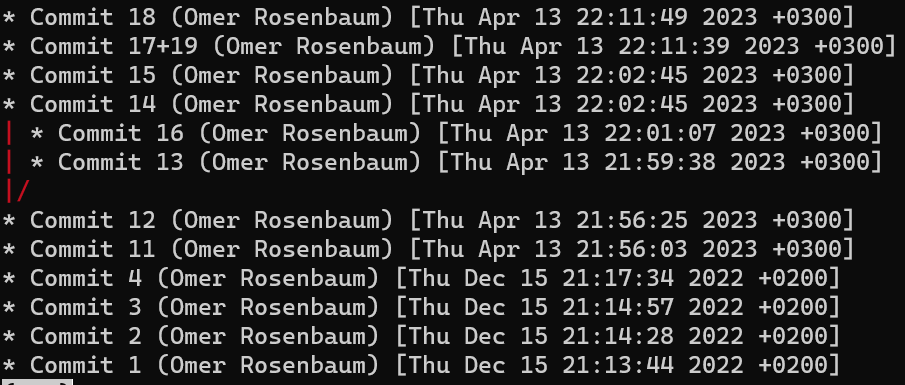
git log --oneline --graph feature_branch_1 feature_branch_2 --pretty=format:"%s (%an) [%cd]Eso es útil, pero no bueno al mirarlo. Entonces podemos usar otros trucos de formateo, específicamente %C(color) que cambiará el color a color, hasta que alcance un %Creset que resetea el color. Para hacer que el nombre del autor sea amarillo, puedes usar:
git log --oneline --graph feature_branch_1 feature_branch_2 --pretty=format:"%s %C(yellow)(%an)%Creset [%cd]"
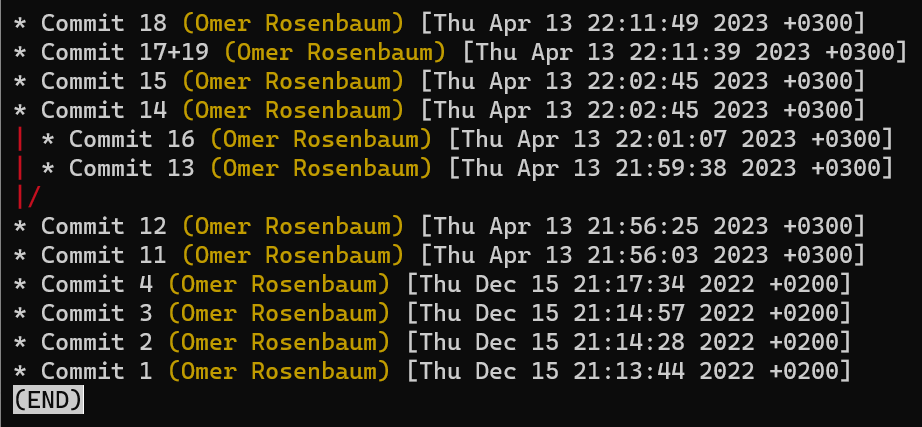
git log --oneline --graph feature_branch_1 feature_branch_2 --pretty=format:"%s %C(yellow)(%an)%Creset [%cd]"Para algunos colores, como rojo o verde, es innecesario incluir el paréntesis, así que rojo es suficiente.
¿Cómo se estructura git lol?
Cuando ejecuto git lol, en realidad ejecuta lo siguiente:
git log --graph --pretty=format:'%Cred%h%Creset -%C(yellow)%d%Creset %s %Cgreen(%cr) %C(bold blue)<%an>%Creset' --abbrev-commit
¿Puedes tomar esto poco a poco?
Ya conoces --graph, el cual hace que la salida incluya un gráfico ASCII.
--abbrev-commit usa un prefijo corto del SHA-1 completo de la confirmación (en mi configuración, los siete primero caracteres).
El resto es sólo el coloreamiento de varios detalles sobre la confirmación:
git lol --all
git lol --allMe gusta esta salida porque lo encuentro claro. Me da la información que necesito, con colores suficientes así cada detalles se destaca sin lastimar mis ojos. Pero si prefieres otra información, otros colores, un diferente orden, o cualquier cosa - adelante y ajústalo a tu gusto.
Definiendo un alias
Como sabes, defino a git lol como un alias - eso es, cuando ejecuto git lol, ejecuta el comando largo que proveí anteriormente.
¿Cómo puedes crear un alias en Git?
La forma mas fácil es usar git alias, así:
git config --global alias.co checkout
Este comando pone co para que sea un alias para el comando checkout, así puedes usar git co main en vez de git checkout main.
Para definir git lol como un alias, puedes usar:
git config --global alias.lol 'log --graph --pretty=format:'%Cred%h%Creset -%C(yellow)%d%Creset %s %Cgreen(%cr) %C(bold blue)<%an>%Creset' --abbrev-commit'
Capítulo 13 - Git Bisect
Ups.
Tengo un error.
Sí, sucede a veces, a todos nosotros. Algo en mi sistema está roto, y no puedo distinguir por qué. He estado depurando por un rato, pero la solución no está clara.
Puedo decir que dos semanas atrás, esto no sucedió. Afortunadamente para mí, he estado usando Git (obviamente lo sé...), así que puedo volver en el tiempo y probar una versión anterior de mi código. En efecto, en esta versión - todo funcionó bien.
Pero... he hecho muchos cambios en estas dos semanas. Ay, no solo yo - mi equipo completo ha contribuido con confirmaciones que agregan, eliminan, o modifican partes del código base. ¿Por dónde comienzo? ¿Debería ir por cada cambio introducido en esas dos semanas?
Ingresa - git bisect.
El objetivo de git bisect es ayudarte a encontrar la confirmación donde un error fue introducido, de una manera efectiva.
¿Cómo funciona git bisect?
git bisect primero te pide que marques una confirmación como "mala" (donde el error ocurre), y otra confirmación como "buena" (una sin el error). Luego, verifica una confirmación a medio camino entre estas dos confirmaciones, y luego te pide que identifiques la confirmación como "buena" o "mala". Este proceso se repite hasta que encuentres la primer confirmación "mala".
La clave aquí es usar la búsqueda binaria - mirando al punto a medio camino y decidir si es la nueva punta o el piso de la lista de confirmaciones, puedes encontrar la confirmación correcta de forma eficiente. Inclusive si tienes 10,000 confirmaciones que cazar, solamente toma un máximo de 13 pasos para encontrar la primer confirmación que introdujo el error.
Ejemplo de git bisect
Para este ejemplo, usaré el repositorio en https://github.com/Omerr/bisect-exercise.git. Para crearlo, adaptaré el repositorio de código abierto https://github.com/bast/git-bisect-exercise (acorde a su licencia).
En este repositorio, tenemos un archivo python sencillo que se usa para calcular el valor de pi (el cual es aproximadamente 3.14). Si ejecutas python3 get_pi.py en el main, sin embargo, obtendrás un resultado erróneo:

Esta rama consiste de más de 500 confirmaciones.
Encuentra la primer confirmación en esta rama usando:
git log --oneline | tail -n 1

git log --oneline | tail -n 1Si ejecutas checkout para esta confirmación y ejecutas python3 get_pi.py nuevamente, el resultado es correcto:
Así que en algún lugar entre el HEAD y la confirmación f0ea950, un cambio fue introducido que resultó en esta salida errónea.
Para encontrarlo usando git bisect, comienza el proceso de bisect, y marca esta confirmación como "buena":
git bisect start
git bisect good
Por defecto, git bisect good tomaría el HEAD como la confirmación "buena". Para marcar a main como "mala", puedes usar git bisect bad main:

git bisect bad maingit bisect comprobó el número de confirmación 251, el "punto medio" de la rama main. ¿El estado de esta confirmación produce la saluda correcta o errónea?

Todavía obtenemos la salida errónea, lo cual significa que podemos descartar las confirmaciones 252 hasta el 500 (y confirmaciones adicionales después de ese), y acortar nuestra búsqueda desde la confirmación 2 hasta el 251. Marca a éste como "mala":

badgit bisect comprobó la confirmación "media" (número 126), y ejecutando el código nuevamente resulta en la respuesta, ¡correcta! Esto significa que esta confirmación es "buena", y que la primer confirmación "mala" está en algún lugar entre 127 y 251. Márcalo como "buena".

goodGenial, git bisect nos toma a la confirmación 188, ya que esta es la confirmación "media" entre 127 y 251. Al ejecutar el código nuevamente, puedes ver que el resultado es incorrecto, así que este es en realidad una confirmación "mala", lo que significa que la primer confirmación defectuosa se encuentre en algún lugar entre 127 y 188. Como puedes ver, git bisect achica el espacio de búsqueda a la mitad en cada iteración.
Vamos, ahora es tu turno - ¡continúa desde aquí! Prueba el resultado de python3 get_pi.py y usa git bisect good o git bisect bad para marcar la confirmación según sea el caso. ¿Cuál es la confirmación defectuosa?
Cuando estés listo, usa git bisect reset para detener el proceso bisect.
git bisect automático
En el ejemplo previo, podrías simplemente ejecutar pytho3 get_pi.py y verificar el resultado. En otras veces, el proceso de validar si una cierta confirmación es "buena" o "mala" puede ser tramposo, propenso a errores, o solo lleva mucho tiempo.
Es posible automatizar el proceso de git bisect al crear código que debería ser ejecutado en cada iteración, devolviendo 0 cuando la confirmación actual es "buena", y un valor entre 1-127 (inclusivo), excepto 125, si debería ser considerada "mala".
La sintaxis es:
git bisect run my_script arguments
Ya que este libro no trata sobre programación y no se asume que conoces un lenguaje de programación específico, no mostraré un ejemplo de la implementación my_script. El archivo README.md en el repositorio usado en este capítulo (https://github.com/Omerr/bisect-exercise.git) incluye un ejemplo para un script que puedes ejecutar con git bisect run para encontrar automáticamente la confirmación defectuosa para el ejemplo previo.
Capítulo 14 - Otros comandos útiles
Este capítulo resalta algunos comandos que ya han sido mencionados en los capítulos anteriores. Los estoy poniendo aquí juntos así puedes revisarlos como una referencia cuando sea necesario.
git cherry-pick
Introducido en el capítulo 8, este comando toma una confirmación dada, calcula el parche que esta confirmación introduce al calcular la diferencia entre la confirmación del antecesor y la confirmación misma, y luego git bisect "repite" esta diferencia. Es como "copiar-pegar" una confirmación, es decir, el diff de esta confirmación introducida.
En el capítulo 8 consideramos la diferencia introducida por el "Commit 5" (usando git diff main <SHA_OF_COMMIT_5>):
git diff to observe the patch introduced by "Commit 5"Puedes ver que en esta confirmación, John comenzó a trabajar en una canción llamada "Lucy in the Sky with Diamonds":
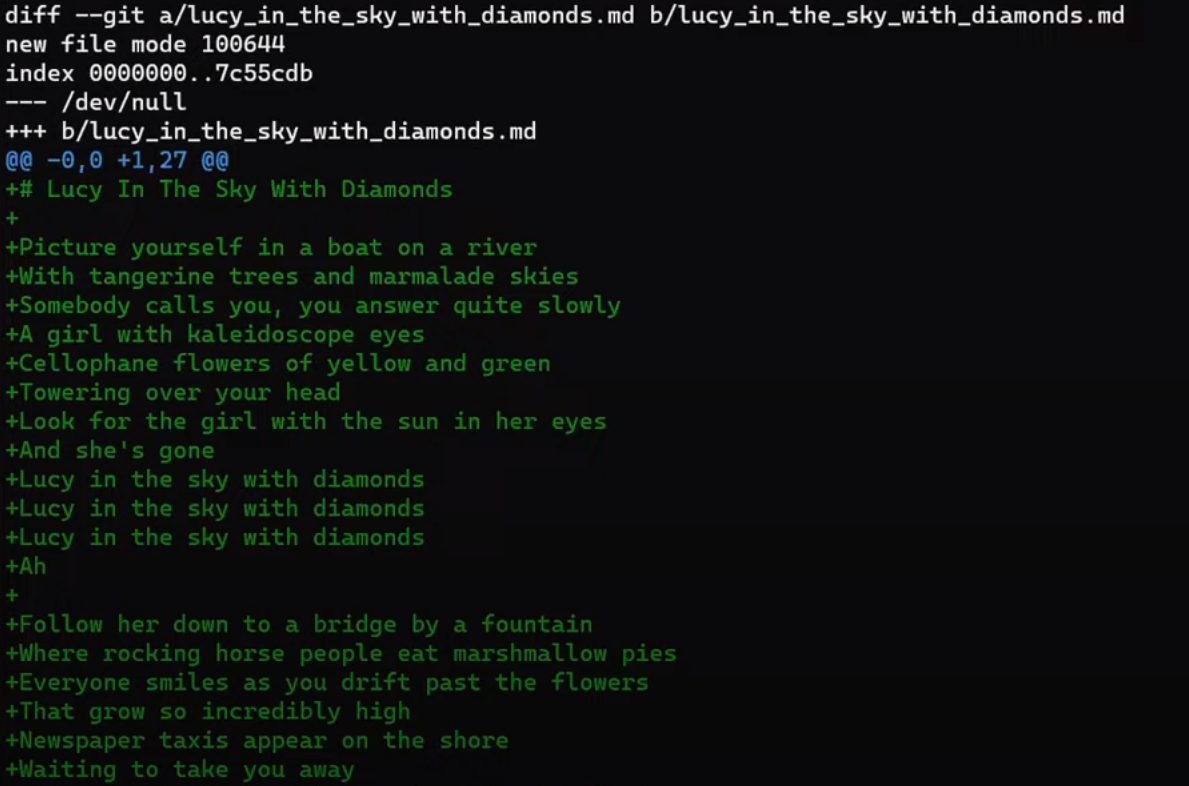
git diff - the patch introduced by "Commit 5"Como recordatorio, también puedes usar el comando git show para obtener la misma salida:
git show <SHA_OF_COMMIT_5>
Ahora, si haces cherry-pick a esta confirmación, introducirás este cambio específicamente, en la rama activa. Puedes cambiar a la rama main:
git checkout main (or git switch main)
Y crear otra rama:
git checkout -b my_branch (or git switch -c my_branch)
my_branch that branches from mainLuego, haz cherry-pick al "Commit 5":
git cherry-pick <SHA_OF_COMMIT_5>
cherry-pick to apply the changes introduced in "Commit 5" onto mainConsidera el log (salida de git lol):

git lolParece que copiaste-pegaste a "Commit 5". Recuerda que inclusive tiene el mismo mensaje de confirmación, e introduce los mismos cambios, e inclusive apunta al mismo objeto árbol como el "Commit 5" original en este caso - todavía es un objeto de confirmación distinto, ya que fue creado con una marca de tiempo distinto.
Mirando a los cambios, usando git show HEAD:
git show HEADSon los mismos como los de "Commit 5".
git revert
git revert es esencialmente la reversa de git cherry-pick, introducido en el capítulo 10. Este comando toma la confirmación con el que le estás proveyendo y calcula el diff desde su confirmación antecesora, así como git cherry-pick, pero esta vez, calcula los cambios de reversa. Eso es, si en la confirmación especificada agregaste una línea, la reversa eliminaría la línea, y vice versa.
git add -p
Poniendo en el área de preparación los cambios es una parte integral de introducir cambios a Git. A veces, deseas poner en el área de preparación todos los cambios juntos (con git add .), o tal vez poner en stage todos los cambios de un archivo específico (usando git add <file_path>). Aunque hay veces donde sería conveniente poner en stage solamente ciertas partes de los archivos modificados.
En el capítulo 6, introdujimos git add -p. Este comando te permite poner en stage ciertas partes de los archivos, al separarlos en pequeños trozos (p significa parche). Por ejemplo, digamos que tienes este archivo, my_file.py:
my_file.pyLuego modificas este archivo - al cambiar el texto dentro de function_1, y también agregando una nueva función, function_5:

my_file.py after the changesSi usaste git add my_file.py a este punto, pondrías en el área de preparación ambos de estos cambios juntos. En caso de que quieras separarlos en confirmaciones distintas, podrías usar git add -p, el cual separa estos dos cambios y te pregunta sobre cada uno como un pedazo independiente:
git add -pAl tipear ?, puedes ver qué significan cada opción distinta:
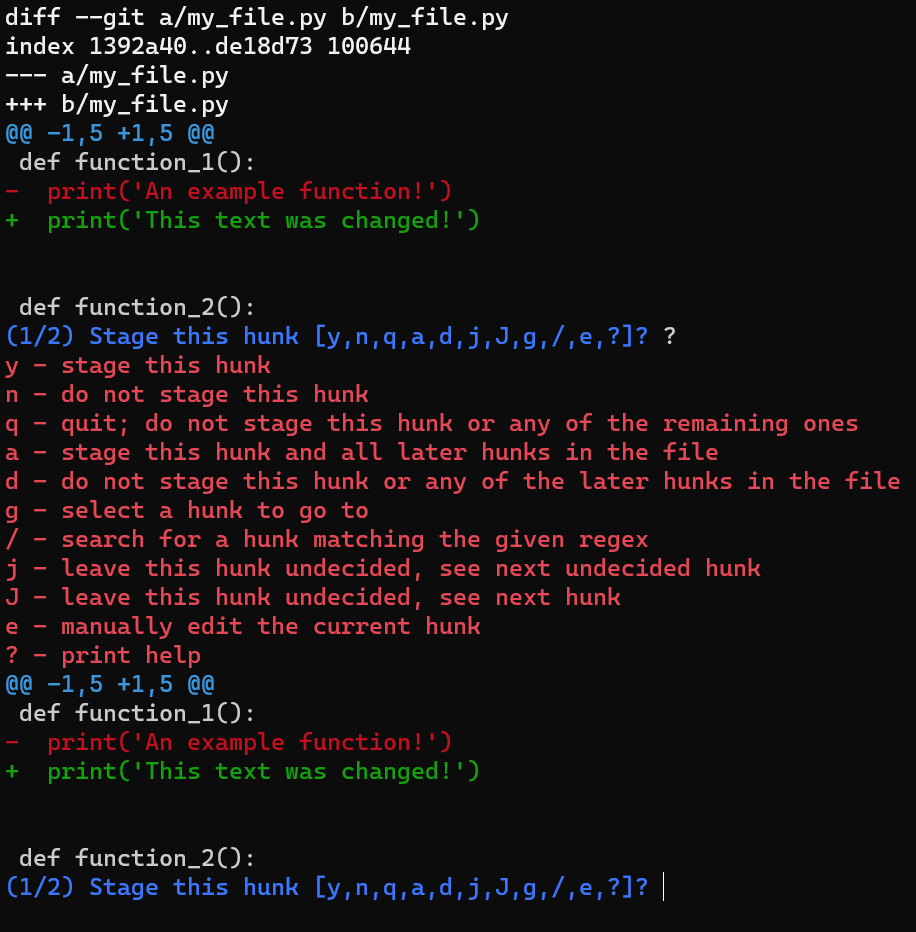
? to get a description of the different optionsEn este caso, digamos que solamente queremos poner en el área de preparación el cambio introduciendo function_5. No queremos poner en el área de preparación el cambio de function_1, así que seleccionamos n:

function_1Luego, nos aparece una ventana para el segundo cambio - el que introduce function_5. Queremos poner en el área de preparación este pedazo, así podemos tipear y.
Resumen
Bueno, ¡esto fue divertido!
¿Puedes creer cuánto has aprendido?
En la Parte 1 aprendiste sobre blobs, árboles y confirmaciones.
Luego aprendiste sobre las ramas, viendo que no son mas que una referencia nombrada a una confirmación.
Aprendiste el proceso de registrar cambios en Git, y que involucra el directorio de trabajo, el área de preparación (índice), y el repositorio.
Luego - creaste un nuevo repositorio desde cero, al usar echo y comandos de bajo nivel tales como git hash-object. Creaste un blob, un árbol, y un objeto de confirmación apuntando a ese árbol.
En la Parte 2 aprendiste sobre hacer ramas e integrar cambios en Git.
Aprendiste lo que es un diff, y la diferencia entre un diff y un parche. También aprendiste cómo se construye la salida de git diff.
Luego, tuviste un vistazo extensivo sobre fusionar con Git, específicamente entendiendo el algoritmo de fusión de tres vías. Entendiste cuándo los conflictos de fusión ocurren, cuándo Git los puede resolver automáticamente, y cómo los resuelve de forma manual cuando sea necesario.
Viste que git rebase es poderoso - pero también es bastante sencillo una vez que entiendes lo que hace. Entendiste las diferencias entre fusionar y hacer rebase, y cuando deberías usar cada uno.
En la Parte 3 aprendiste cómo deshacer cambios en Git - especialmente cuando las cosas van mal. Aprendiste cómo usar un par de herramientas, como git reset, git commit --ammend, git revert, git reflog (y git log -g).
La herramienta más importante, aún más importante que las herramientas que listé, es limpiar la situación actual vs el que se desea. Créeme en esta, hará que cada situación parezca menos intimidante y la solución más claro.
En la Parte 4 adquiriste herramientas poderosas adicionales, como diferentes conmutadores de git log, git bisect, git cherry-pick, git revert y git add -p.
Wow, ¡deberías sentirte orgulloso!
Un mensaje de mí para tí
En efecto, eso fue divertido, pero todas las cosas deben pasar. Terminaste de leer este libro, pero no significa que tu jornada de aprendizaje termina aquí.
Lo que has adquirido, más que cualquier herramienta específica, es intuición y entendimiento de cómo opera Git, y cómo pensar sobre varias operaciones en Git. Sigue investigando, leyendo, y usando Git. Estoy seguro que serás capaz de enseñarme algo nuevo, y por todos los medios - hazlo por favor.
Si te gustó este libro, por favor compártelo con más personas.
Si quieres leer más de mis artículos de Git y manuales, aquí están:
- The Git Rebase Handbook
- The Git Merge Handbook
- The Git Diff and Patch Handbook
- Git Internals - Objects, Branches, and How to Create a Repo
- Git Reset Command Explained
Reconocimientos
Mucha gente ayudó en hacer este libro lo mejor que se podía. Entre ellos, fui afortunado de tener muchos lectores beta que me dieron comentarios así podía mejorar el libro. Específicamente, me gustaría agradecer a Jason S. Shapiro, Anna Łapińska, C. Bruce Hilbert, y Jonathon McKitrick por sus revisiones exhaustivas.
Abbey Rennemeyer ha sido una editor maravillosa. Después que ha revisado mis publicaciones para freeCodeCamp por tres años, fue claro que le pidiera que fuera el editor de este libro también. Ella me ayudó en mejorar el libro de muchas formas, y estoy agradecido por su ayuda.
Quincy Larson fundó la maravillosa comunidad en freeCodeCamp, me motivó por medio de emails y discusiones de cara a cara. Le agradezco por generar esta increíble comunidad, y por su amistad.
Estefania Cassingena Navone diseñó la portada de este libro. Estoy agradecido por su trabajo profesional y su paciencia con mis pedidos y perfeccionismo.
El sitio web de Daphne Gray-Grant, "Publication Coach", me dio inspiración así también como consejos técnicos que me ayudó mucho con mi proceso de escritura.
Si deseas apoyar este libro
Si te gustaría apoyar este libro, puedes comprar la versión en papel, un versión E-Book (libro electrónico), o comprarme un café. ¡Gracias!
Contáctame
Este libro ha sido creado para ayudarte y gente como tú aprenda, entienda Git, y aplique sus conocimientos en la vida real.
Bien al principio, pedí comentarios y fui afortunado de recibirlo de gente estupenda (mencionado en los Reconocimientos) para asegurar que el libro alcanzara estos objetivos. Si te gustó algo de este libro, sentiste que algo estaba faltando o necesitaba mejorar - me encantaría que me lo dijeras. Por favor háblame en: gitting.things@gmail.com.
Gracias por aprender y permitirme ser parte de tu jornada.
- Omer Rosenbaum
Apéndices
Referencias Adicionales - Por Parte
(Nota - esta es una lista corta. Puedes encontrar una lista más larga de referencias en la versión E-Book o la impresa.)
Parte 1
- Lista de reproducción de Youtube sobre los Componentes Internos de Git - por Brief:
https://www.youtube.com/playlist?list=PL9lx0DXCC4BNUby5H58y6s2TQVLadV8v7 - Conferencia de Tim Berglund - "Git From the Bits Up":
https://www.youtube.com/watch?v=MYP56QJpDr4 - como prometí, la documentación: Git for the confused:
https://www.gelato.unsw.edu.au/archives/git/0512/13748.html
Parte 2
Diffs y Parches
Algoritmos de Diffs de Git:
El algoritmo de diff más predeterminado en Git es Myers:
- https://www.nathaniel.ai/myers-diff/
- https://blog.jcoglan.com/2017/02/12/the-myers-diff-algorithm-part-1/
- https://blog.robertelder.org/diff-algorithm/
Git Merge
- https://git-scm.com/book/es/v2/Herramientas-de-Git-Fusión-Avanzada
- https://blog.plasticscm.com/2010/11/live-to-merge-merge-to-live.html
Git Rebase
- https://jwiegley.github.io/git-from-the-bottom-up/1-Repository/7-branching-and-the-power-of-rebase.html
- https://git-scm.com/book/es/v2/Ramificaciones-en-Git-Reorganizar-el-Trabajo-Realizado
Recursos relacionados a los Beatles
- https://www.the-paulmccartney-project.com/song/ive-got-a-feeling/
- https://www.cheatsheet.com/entertainment/did-john-lennon-or-paul-mccartney-write-the-classic-a-day-in-the-life.html/
- http://lifeofthebeatles.blogspot.com/2009/06/ive-got-feeling-lyrics.html