

One of the most powerful tools a developer can have in their toolbox is git rebase. Yet it is notorious for being complex and misunderstood.
The truth is, if you understand what it actually does, git rebase is a very elegant, and straightforward tool to achieve so many different things in Git.
In previous posts, you understood what Git diffs are, what a merge is, and how Git resolves merge conflicts. In this post, you will understand what Git rebase is, why it's different from merge, and how to rebase with confidence 💪🏻
Notes before we start
- I also created a video covering the contents of this post. If you wish to watch alongside reading, you can find it here.
- If you want to play around with the repository I used and try out the commands for yourself, you can get the repo here.
- I am working on a book about Git! Are you interested in reading the initial versions and providing feedback? Send me an email: gitting.things@gmail.com
OK, are you ready?
Short Recap - What is Git Merge? 🤔
Under the hood, git rebase and git merge are very, very different things. Then why do people compare them all the time?
The reason is their usage. When working with Git, we usually work in different branches and introduce changes to those branches.
In a previous tutorial, I gave an example where John and Paul (of the Beatles) were co-authoring a new song. They started from the main branch, and then each diverged, modified the lyrics and committed their changes.
Then, the two wanted to integrate their changes, which is something that happens very frequently when working with Git.
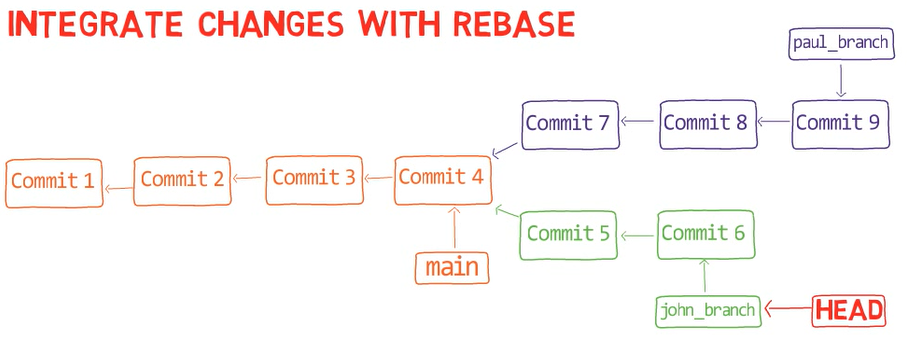 _A diverging history -
_A diverging history - paul_branch and john_branch diverged from main (Source: Brief)_
There are two main ways to integrate changes introduced in different branches in Git, or in other words, different commits and commit histories. These are merge and rebase.
In a previous tutorial, we got to know git merge pretty well. We saw that when performing a merge, we create a merge commit – where the contents of this commit are a combination of the two branches, and it also has two parents, one in each branch.
So, say you are on the branch john_branch (assuming the history depicted in the drawing above), and you run git merge paul_branch. You will get to this state – where on john_branch, there is a new commit with two parents. The first one will be the commit on john_branch branch where HEAD was pointing to before performing the merge, in this case - "Commit 6". The second will be the commit pointed to by paul_branch, "Commit 9".
 _The result of running
_The result of running git merge paul_branch: a new Merge Commit with two parents (Source: Brief)_
Look again at the history graph: you created a diverged history. You can actually see where it branched and where it merged again.
So when using git merge, you do not rewrite history – but rather, you add a commit to the existing history. And specifically, a commit that creates a diverged history.
How is git rebase Different than git merge? 🤔
When using git rebase, something different happens. 🥁
Let's start with the big picture: if you are on paul_branch, and use git rebase john_branch, Git goes to the common ancestor of John's branch and Paul's branch. Then it takes the patches introduced in the commits on Paul's branch, and applies those changes to John's branch.
So here, you use rebase to take the changes that were committed on one branch – Paul's branch – and replay them on a different branch, john_branch.
 _The result of running
_The result of running git rebase john_branch: the commits on paul_branch were "replayed" on top of john_branch (Source: Brief)_
Wait, what does that mean? 🤔
We will now take this bit by bit to make sure you fully understand what's happening under the hood 😎
cherry-pick as a Basis for Rebase
It is useful to think of rebase as performing git cherry-pick – a command takes a commit, computes the patch this commit introduces by computing the difference between the parent's commit and the commit itself, and then cherry-pick "replays" this difference.
Let's do this manually.
If we look at the difference introduced by "Commit 5" by performing git diff main <SHA_OF_COMMIT_5>:
 Running
Running git diff to observe the patch introduced by "Commit 5" (Source: Brief)
(If you want to play around with the repository I used and try out the commands for yourself, you can get the repo here).
You can see that in this commit, John started working on a song called "Lucy in the Sky with Diamonds":
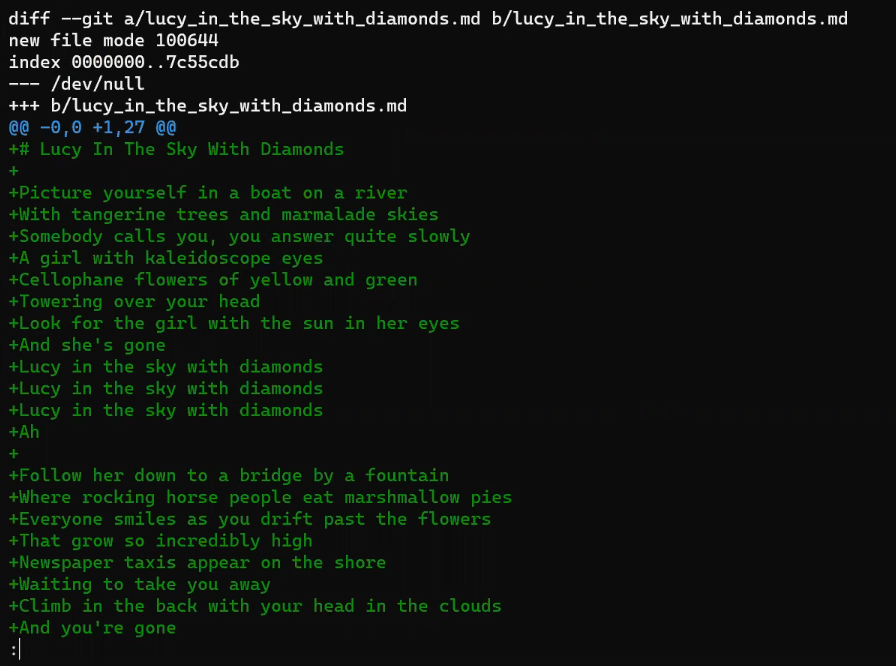 The output of
The output of git diff - the patch introduced by "Commit 5" (Source: Brief)
As a reminder, you can also use the command git show to get the same output:
git show <SHA_OF_COMMIT_5>
Now, if you cherry-pick this commit, you will introduce this change specifically, on the active branch. Switch to main first:
git checkout main (or git switch main)
And create another branch, just to be clear:
git checkout -b my_branch (or git switch -c my_branch)
 _Creating
_Creating my_branch that branches from main (Source: Brief)_
And cherry-pick this commit:
git cherry-pick <SHA_OF_COMMIT_5>
 Using
Using cherry-pick to apply the changes introduced in "Commit 5" onto main (Source: Brief)
Consider the log (output of git lol):
 The output of
The output of git lol (Source: Brief)
(git lol is an alias I added to Git to visibly see the history in a graphical manner. You can find it here).
It seems like you copy-pasted "Commit 5". Remember that even though it has the same commit message, and introduces the same changes, and even points to the same tree object as the original "Commit 5" in this case – it is still a different commit object, as it was created with a different timestamp.
Looking at the changes, using git show HEAD:
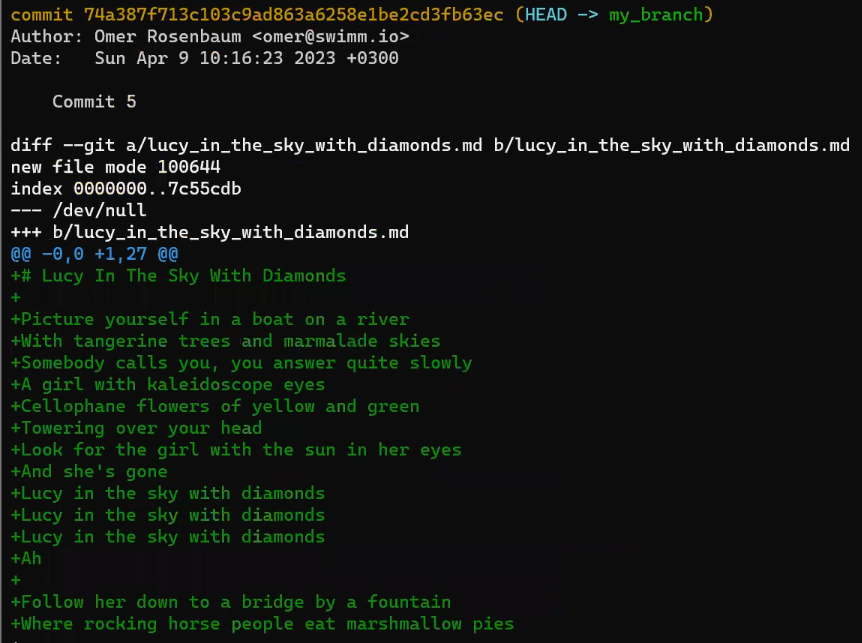 The output of
The output of git show HEAD (Source: Brief)
They are the same as "Commit 5"'s.
And of course, if you look at the file (say, by using nano lucy_in_the_sky_with_diamonds.md), it will be in the same state as it has been after the original "Commit 5".
Cool! 😎
OK, you can now remove the new branch so it doesn't appear on your history every time:
git checkout main
git branch -D my_branch
Beyond cherry-pick – How to Use git rebase
You can look at git rebase as a way to perform multiple cherry-picks one after the other – that is, to "replay" multiple commits. This is not the only thing you can do with rebase, but it's a good starting point for our explanation.
It's time to play with git rebase! 👏🏻👏🏻
Before, you merged paul_branch into john_branch. What would happen if you rebased paul_branch on top of john_branch? You would get a very different history.
In essence, it would seem as if we took the changes introduced in the commits on paul_branch, and replayed them on john_branch. The result would be a linear history.
To understand the process, I will provide the high level view, and then dive deeper into each step. The process of rebasing one branch on top of another branch is as follows:
- Find the common ancestor.
- Identify the commits to be "replayed".
- For every commit
X, computediff(parent(X), X), and store it as apatch(X). - Move
HEADto the new base. - Apply the generated patches in order on the target branch. Each time, create a new commit object with the new state.
The process of making new commits with the same changesets as existing ones is also called "replaying" those commits, a term we have already used.
Time to Get Hands-On with Rebase🙌🏻
Start from Paul's branch:
git checkout paul_branch
This is the history:
 Commit history before performing
Commit history before performing git rebase (Source: Brief)
And now, to the exciting part:
git rebase john_branch
And observe the history:
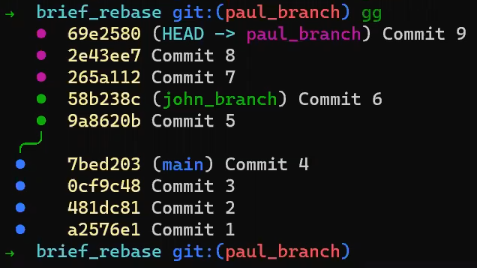 The history after rebasing (Source: Brief)
The history after rebasing (Source: Brief)
( gg is an alias for an external tool I introduced in the video).
So whereas with git merge you added to the history, with git rebase you rewrite history. You create new commit objects. In addition, the result is a linear history graph – rather than a diverging graph.
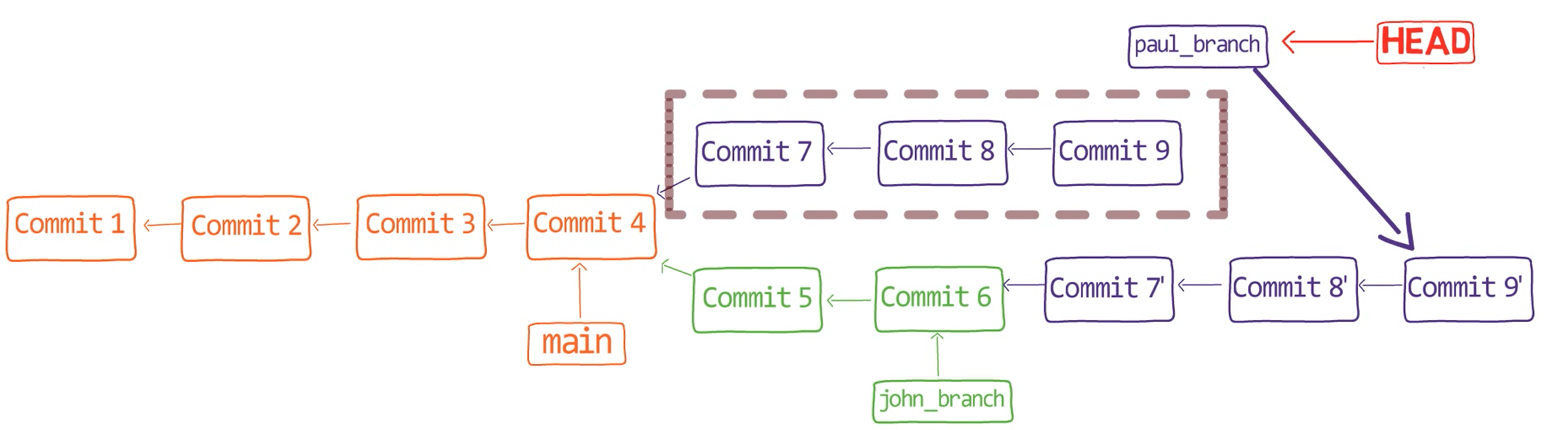 The history after rebasing (Source: Brief)
The history after rebasing (Source: Brief)
In essence, we "copied" the commits that were on paul_branch and introduced after "Commit 4", and "pasted" them on top of john_branch.
The command is called "rebase", because it changes the base commit of the branch it's run from. That is, in your case, before running git rebase, the base of paul_branch was "Commit 4" – as this is where the branch was "born" (from main). With rebase, you asked Git to give it another base – that is, pretend as if it had been born from "Commit 6".
To do that, Git took what used to be "Commit 7", and "replayed" the changes introduced in this commit onto "Commit 6", and then created a new commit object. This object differs from the original "Commit 7" in three aspects:
- It has a different timestamp.
- It has a different parent commit – "Commit 6" rather than "Commit 4".
- The tree object it is pointing to is different - as the changes were introduced to the tree pointed to by "Commit 6", and not the tree pointed to by "Commit 4".
Notice the last commit here, "Commit 9'". The snapshot it represents (that is, the tree that it points to) is exactly the same tree you would get by merging the two branches. The state of the files in your Git repository would be the same as if you used git merge. It's only the history that is different, and the commit objects of course.
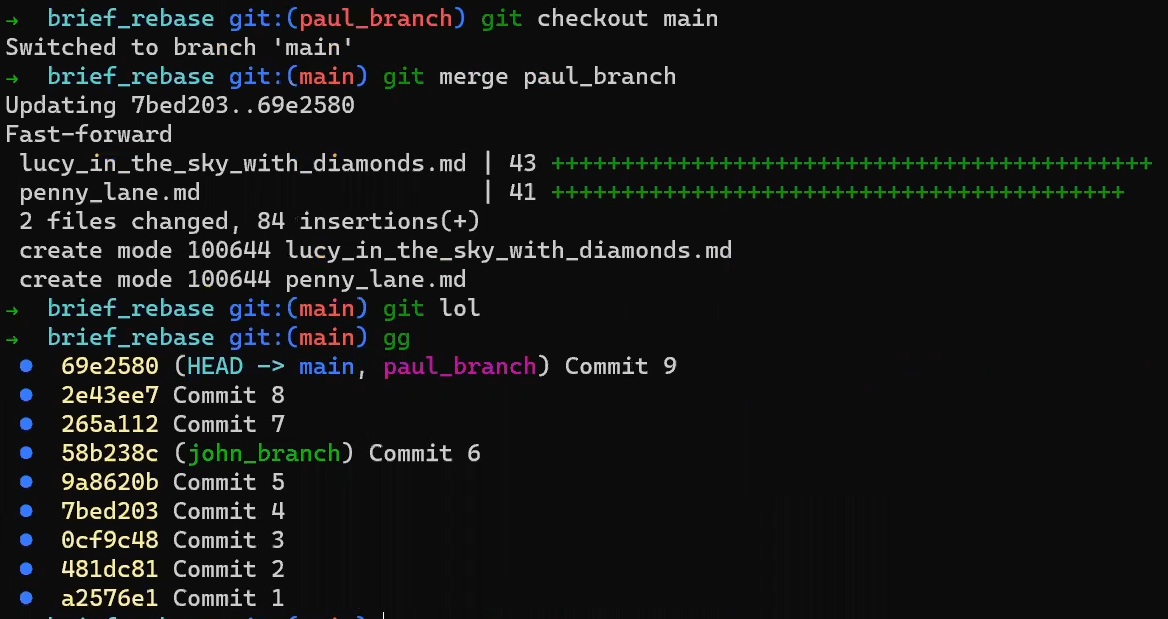
Now, you can simply use:
git checkout main
git merge paul_branch
Hm.... What would happen if you ran this last command? 🤔 Consider the commit history again, after checking out main:
 The history after rebasing and checking out
The history after rebasing and checking out main (Source: Brief)
What would it mean to merge main and paul_branch?
Indeed, Git can simply perform a fast-forward merge, as the history is completely linear (if you need a reminder about fast forward merges, check out this post). As a result, main and paul_branch now point to the same commit:
 The result of a fast-forward merge (Source: Brief)
The result of a fast-forward merge (Source: Brief)
Advanced Rebasing in Git💪🏻
Now that you understand the basics of rebase, it is time to consider more advanced cases, where additional switches and arguments to the rebase command will come in handy.
In the previous example, when you only said rebase (without additional switches), Git replayed all the commits from the common ancestor to the tip of the current branch.
But rebase is a super-power, it's an almighty command capable of…well, rewriting history. And it can come in handy if you want to modify history to make it your own.
Undo the last merge by making main point to "Commit 4" again:
git reset -–hard <ORIGINAL_COMMIT 4>
 "Undoing" the last merge operation (Source: Brief)
"Undoing" the last merge operation (Source: Brief)
And undo the rebasing by using:
git checkout paul_branch
git reset -–hard <ORIGINAL_COMMIT 9>
 "Undoing" the rebase operation (Source: Brief)
"Undoing" the rebase operation (Source: Brief)
Notice that you got to exactly the same history you used to have:
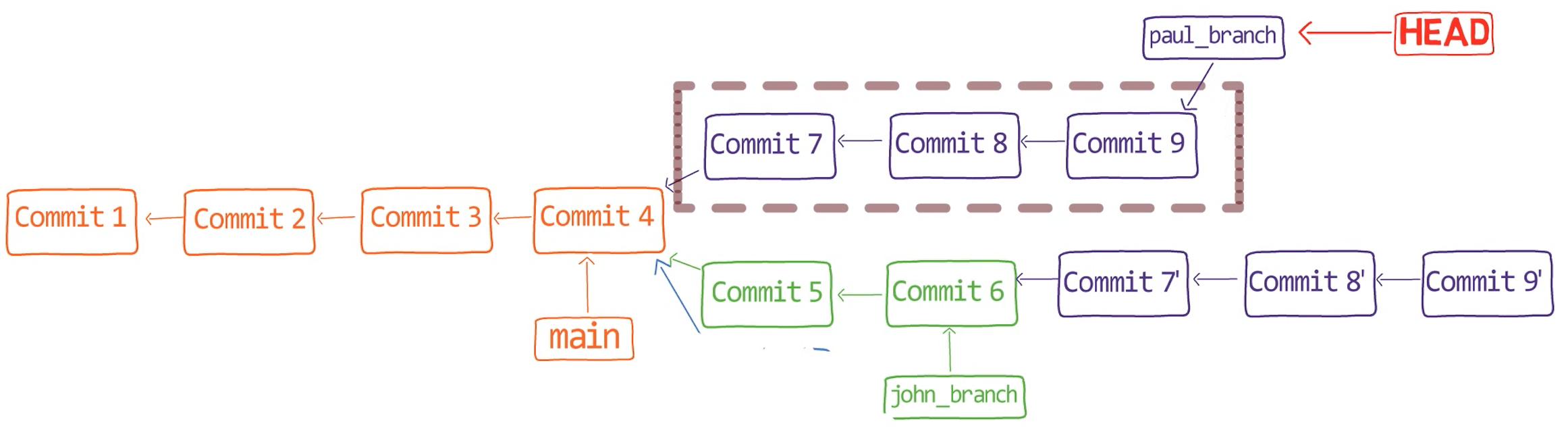 Visualizing the history after "undoing" the rebase operation (Source: Brief)
Visualizing the history after "undoing" the rebase operation (Source: Brief)
Again, to be clear, "Commit 9" doesn't just disappear when it's not reachable from the current HEAD. Rather, it's still stored in the object database. And as you used git reset now to change HEAD to point to this commit, you were able to retrieve it, and also its parent commits since they are also stored in the database. Pretty cool, huh? 😎
OK, quickly view the changes that Paul introduced:
git show HEAD
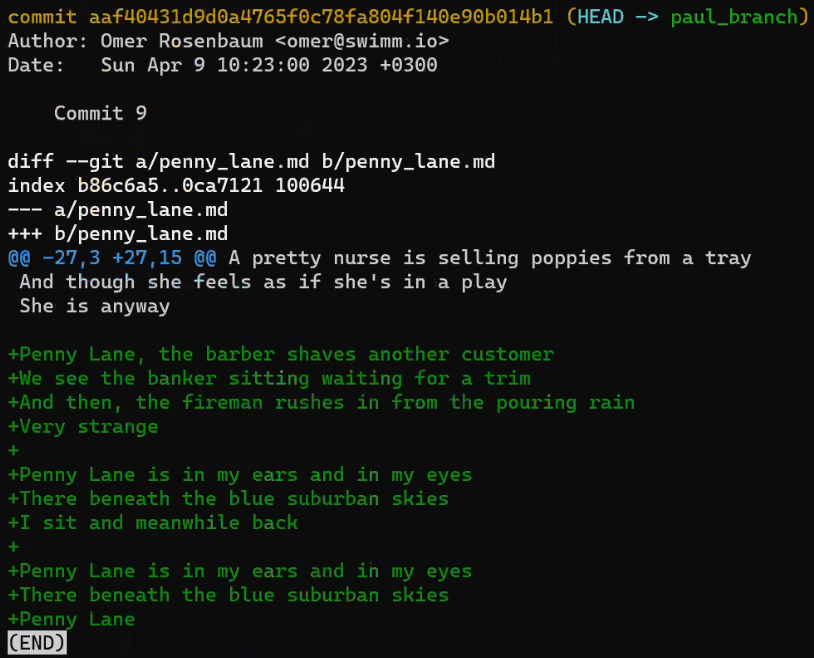
git show HEAD shows the patch introduced by "Commit 9" (Source: Brief)
Keep going backwards in the commit graph:
git show HEAD~

git show HEAD~ (same as git show HEAD~1) shows the patch introduced by "Commit 8" (Source: Brief)
And one commit further:
git show HEAD~2

git show HEAD~2 shows the patch introduced by "Commit 7" (Source: Brief)
So, these changes are nice, but perhaps Paul doesn't want this kind of history. Rather, he wants it to seem as if he introduced the changes in "Commit 7" and "Commit 8" as a single commit.
For that, you can use an interactive rebase. To do that, we add the -i (or --interactive) switch to the rebase command:
git rebase -i <SHA_OF_COMMIT_4>
Or, since main is pointing to "Commit 4", we can simply run:
git rebase -i main
By running this command, you tell Git to use a new base, "Commit 4". So you are asking Git to go back to all commits that were introduced after "Commit 4" and that are reachable from the current HEAD, and replay those commits.
For every commit that is replayed, Git asks us what we'd like to do with it:

git rebase -i main prompts you to select what to do with each commit (Source: Brief)
In this context it's useful to think of a commit as a patch. That is, "Commit 7" as in "the patch that "Commit 7" introduced on top of its parent".
One option is to use pick. This is the default behavior, which tells Git to replay the changes introduced in this commit. In this case, if you just leave it as is – and pick all commits – you will get the same history, and Git won't even create new commit objects.
Another option is squash. A squashed commit will have its contents "folded" into the contents of the commit preceding it. So in our case, Paul would like to squash "Commit 8" into "Commit 7":
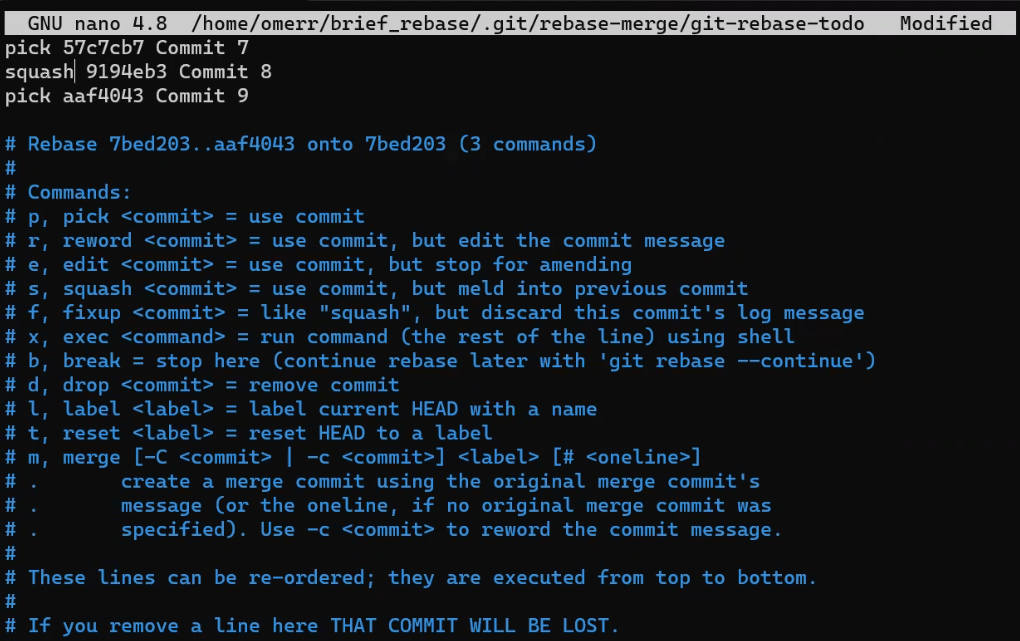 Squashing "Commit 8" into "Commit 7" (Source: Brief)
Squashing "Commit 8" into "Commit 7" (Source: Brief)
As you can see, git rebase -i provides additional options, but we won't go into all of them in this post. If you allow the rebase to run, you will get prompted to select a commit message for the newly created commit (that is, the one that introduced the changes of both "Commit 7" and "Commit 8"):
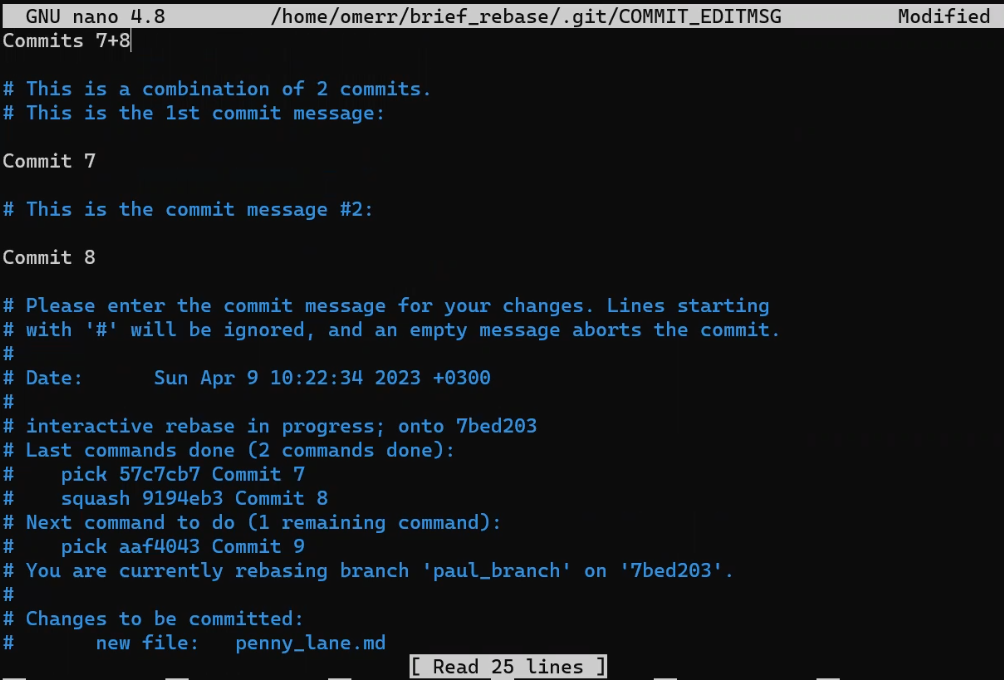 Providing the commit message:
Providing the commit message: Commits 7+8 (Source: Brief)
And look at the history:
 The history after the interactive rebase (Source: Brief)
The history after the interactive rebase (Source: Brief)
Exactly as we wanted! We have on paul_branch "Commit 9" (of course, it's a different object than the original "Commit 9"). This points to "Commits 7+8", which is a single commit introducing the changes of both the original "Commit 7" and the original "Commit 8". This commit's parent is "Commit 4", where main is pointing to. You have john_branch.
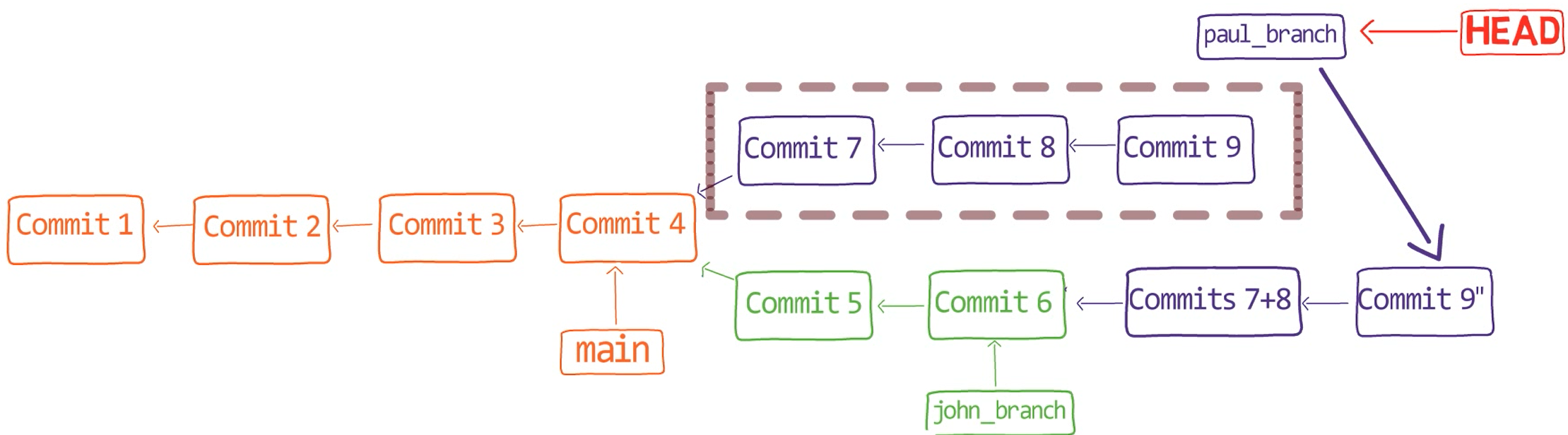 The history after the interactive rebase - visualized (Source: Brief)
The history after the interactive rebase - visualized (Source: Brief)
Oh wow, isn't that cool? 😎
git rebase grants you unlimited control over the shape of any branch. You can use it to reorder commits, or to remove incorrect changes, or modify a change in retrospect. Alternatively, you could perhaps move the base of your branch onto another commit, any commit that you wish.
How to Use the --onto Switch of git rebase
Let's consider one more example. Get to main again:
git checkout main
And delete the pointers to paul_branch and john_branch so you don't see them in the commit graph anymore:
git branch -D paul_branch
git branch -D john_branch
And now branch from main to a new branch:
git checkout -b new_branch
 _Creating
_Creating new_branch that diverges from main (Source: Brief)_
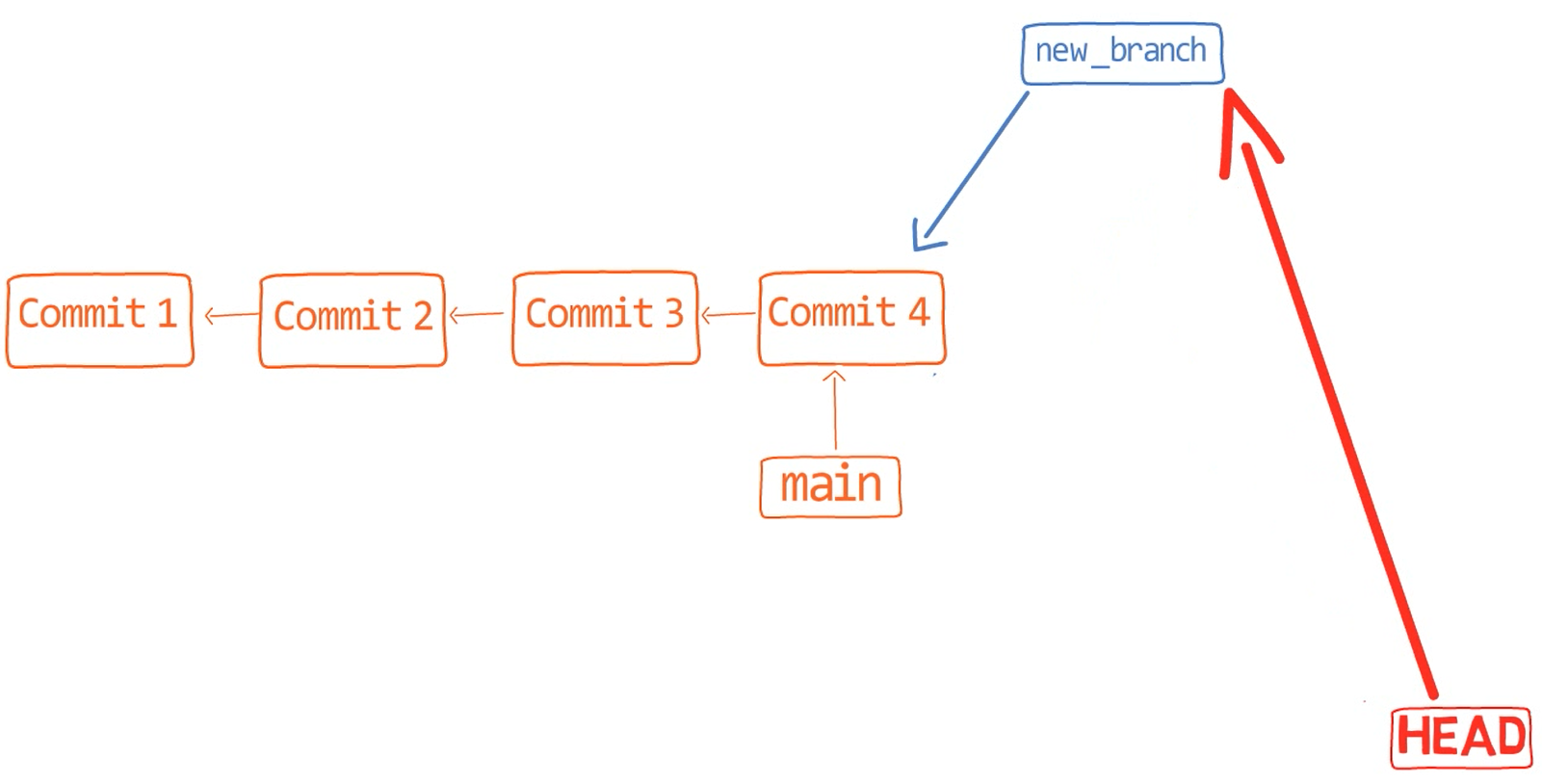 _A clean history with
_A clean history with new_branch that diverges from main (Source: Brief)_
Now, add a few changes here and commit them:
nano code.py
 _Adding the function
_Adding the function new_branch to code.py (Source: Brief)_
git add code.py
git commit -m "Commit 10"
Get back to main:
git checkout main
And introduce another change:
 Added a docstring at the beginning of the file (Source: Brief)
Added a docstring at the beginning of the file (Source: Brief)
Time to stage and commit these changes:
git add code.py
git commit -m "Commit 11"
And yet another change:
 Added
Added @Author to the docstring (Source: Brief)
Commit this change as well:
git add code.py
git commit -m "Commit 12"
Oh wait, now I realize that I wanted you to make the changes introduced in "Commit 11" as a part of the new_branch. Ugh. What can you do? 🤔
Consider the history:
 The history after introducing "Commit 12" (Source: Brief)
The history after introducing "Commit 12" (Source: Brief)
What I want is, instead of having "Commit 10" reside only on the main branch, I want it to be on both the main branch as well as the new_branch. Visually, I would want to move it down the graph here:
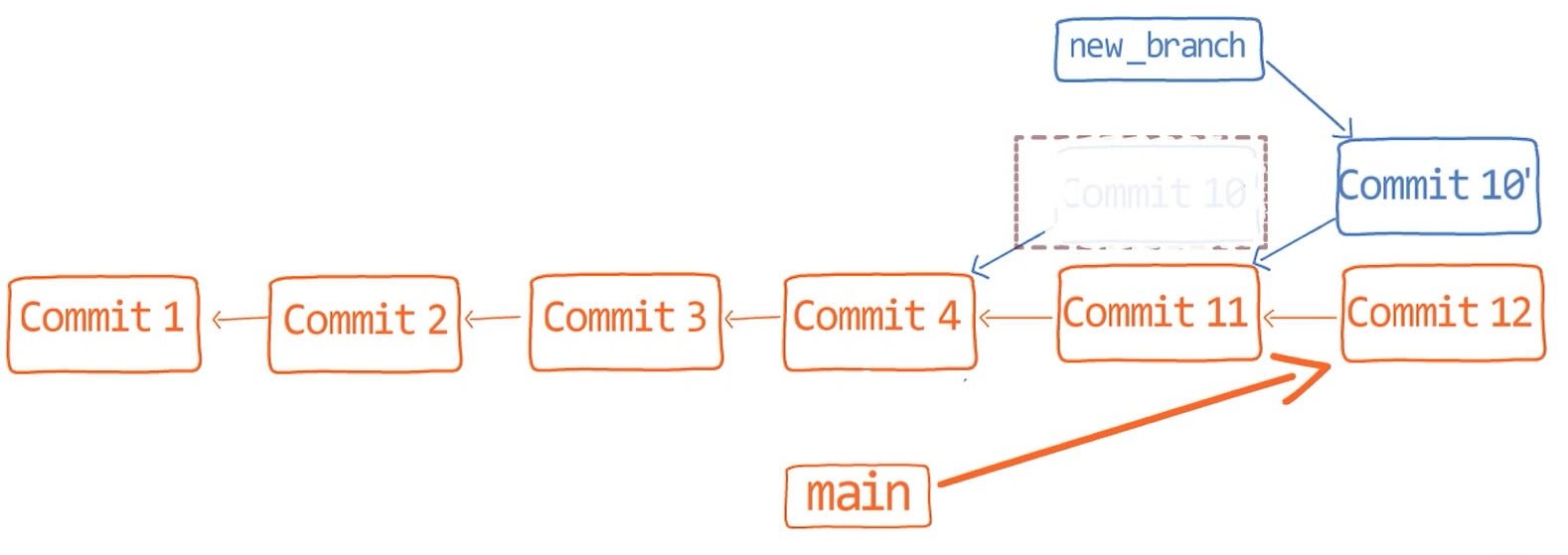 Visually, I want you to "push" "Commit 10" (Source: Brief)
Visually, I want you to "push" "Commit 10" (Source: Brief)
Can you see where I am going? 😇
Well, as we understand, rebase allows us to basically replay the changes introduced in new_branch, those introduced in "Commit 10", as if they had been originally conducted on "Commit 11", rather than "Commit 4".
To do that, you can use other arguments of git rebase. You'd tell Git that you want to take all the history introduced between the common ancestor of main and new_branch, which is "Commit 4", and have the new base for that history be "Commit 11". To do that, use:
git rebase -–onto <SHA_OF_COMMIT_11> main new_branch
 The history before and after the rebase, "Commit 10" has been "pushed" (Source: Brief)
The history before and after the rebase, "Commit 10" has been "pushed" (Source: Brief)
And look at our beautiful history! 😍
 The history before and after the rebase, "Commit 10" has been "pushed" (Source: Brief)
The history before and after the rebase, "Commit 10" has been "pushed" (Source: Brief)
Let's consider another case.
Say I started working on a branch, and by mistake I started working from feature_branch_1, rather than from main.
So to emulate this, create feature_branch_1:
git checkout main
git checkout -b feature_branch_1
And erase new_branch so you don't see it in the graph anymore:
git branch -D new_branch
Create a simple Python file called 1.py:
 A new file,
A new file, 1.py, with print('Hello world!') (Source: Brief)
Stage and commit this file:
git add 1.py
git commit -m "Commit 13"
Now branched out (by mistake) from feature_branch_1:
git checkout -b feature_branch_2
And create another file, 2.py:
 Creating
Creating 2.py (Source: Brief)
Stage and commit this file as well:
git add 2.py
git commit -m "Commit 14"
And introduce some more code to 2.py:
 Modifying
Modifying 2.py (Source: Brief)
Stage and commit these changes too:
git add 2.py
git commit -m "Commit 15"
So far you should have this history:
 The history after introducing "Commit 15" (Source: Brief)
The history after introducing "Commit 15" (Source: Brief)
Get back to feature_branch_1 and edit 1.py:
git checkout feature_branch_1
 Modifying
Modifying 1.py (Source: Brief)
Now stage and commit:
git add 1.py
git commit -m "Commit 16"
Your history should look like this:
 The history after introducing "Commit 16" (Source: Brief)
The history after introducing "Commit 16" (Source: Brief)
Say now you realize, you've made a mistake. You actually wanted feature_branch_2 to be born from the main branch, rather than from feature_branch_1.
How can you achieve that? 🤔
Try to think about it given the history graph and what you've learned about the --onto flag for the rebase command.
Well, you want to "replace" the parent of your first commit on feature_branch_2, which is "Commit 14", to be on top of main branch, in this case, "Commit 12", rather than the beginning of feature_branch_1, in this case, "Commit 13". So again, you will be creating a new base, this time for the first commit on feature_branch_2.
 You want to move around "Commit 14" and "Commit 15" (Source: Brief)
You want to move around "Commit 14" and "Commit 15" (Source: Brief)
How would you do that?
First, switch to feature_branch_2:
git checkout feature_branch_2
And now you can use:
git rebase -–onto main <SHA_OF_COMMIT_13>
As a result, you have feature_branch_2 based on main rather than feature_branch_1:
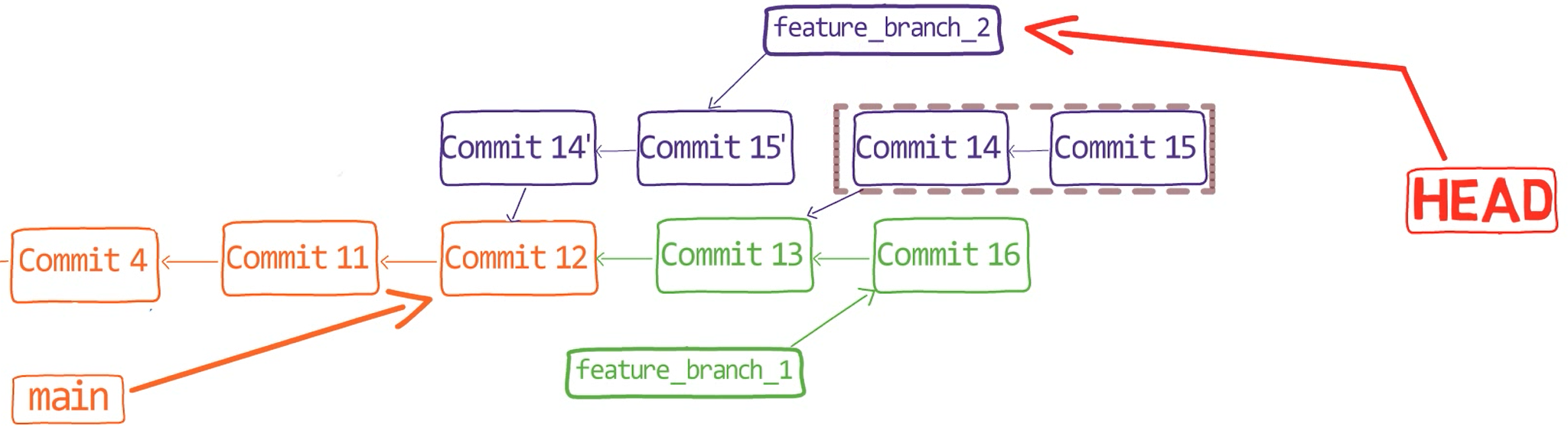 The commit history after performing rebase (Source: Brief)
The commit history after performing rebase (Source: Brief)
The syntax is of the command is:
git rebase --onto <new_parent> <old_parent>
How to rebase on a single branch
You can also use git rebase while looking at a history of a single branch.
Let's see if you can help me here.
Say I worked from feature_branch_2, and specifically edited the file code.py. I started by changing all strings to be wrapped by double quotes rather than single quotes:
 Changing
Changing ' into " in code.py (Source: Brief)
Then, I staged and committed:
git add code.py
git commit -m "Commit 17"
I then decided to add a new function at the beginning of the file:
 _Adding the function
_Adding the function another_feature (Source: Brief)_
Again, I staged and committed:
git add code.py
git commit -m "Commit 18"
And now I realized I actually forgot to change the single quotes to double quotes wrapping the __main__ (as you might have noticed), so I did that too:
 Changing
Changing '__main__' into "__main__" (Source: Brief)
Of course, I staged and committed this change:
git add code.py
git commit -m "Commit 19"
Now, consider the history:
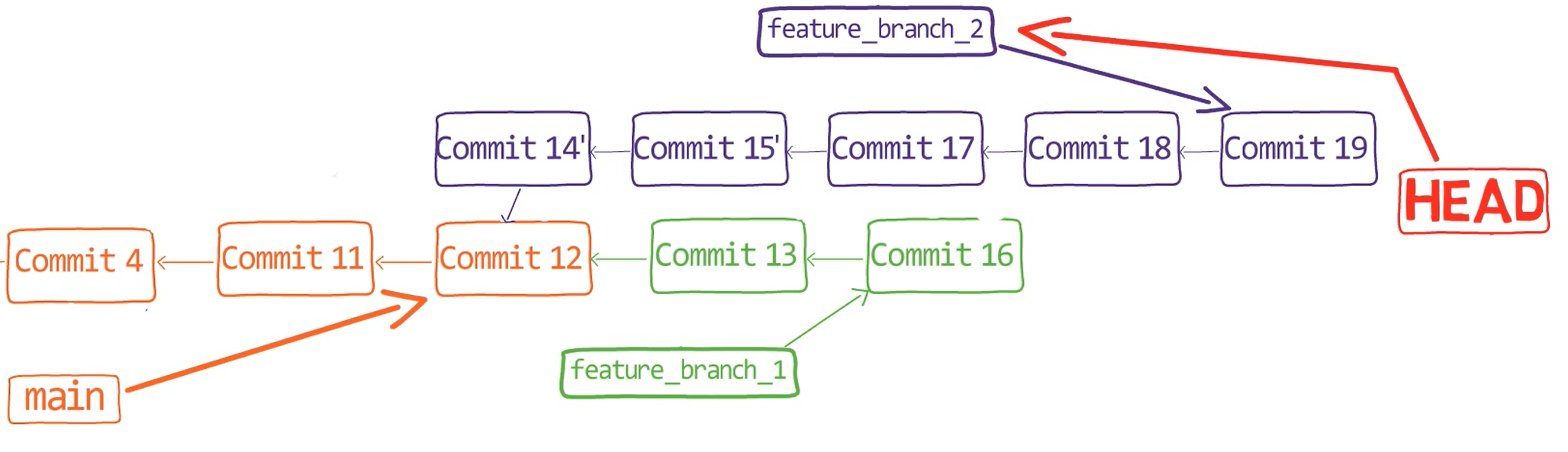 The commit history after introducing "Commit 19" (Source: Brief)
The commit history after introducing "Commit 19" (Source: Brief)
It isn't really nice, is it? I mean, I have two commits that are related to one another, "Commit 17" and "Commit 19" (turning 's into "s), but they are split by the unrelated "Commit 18" (where I added a new function). What can we do? 🤔 Can you help me?
Intuitively, I want to edit the history here:
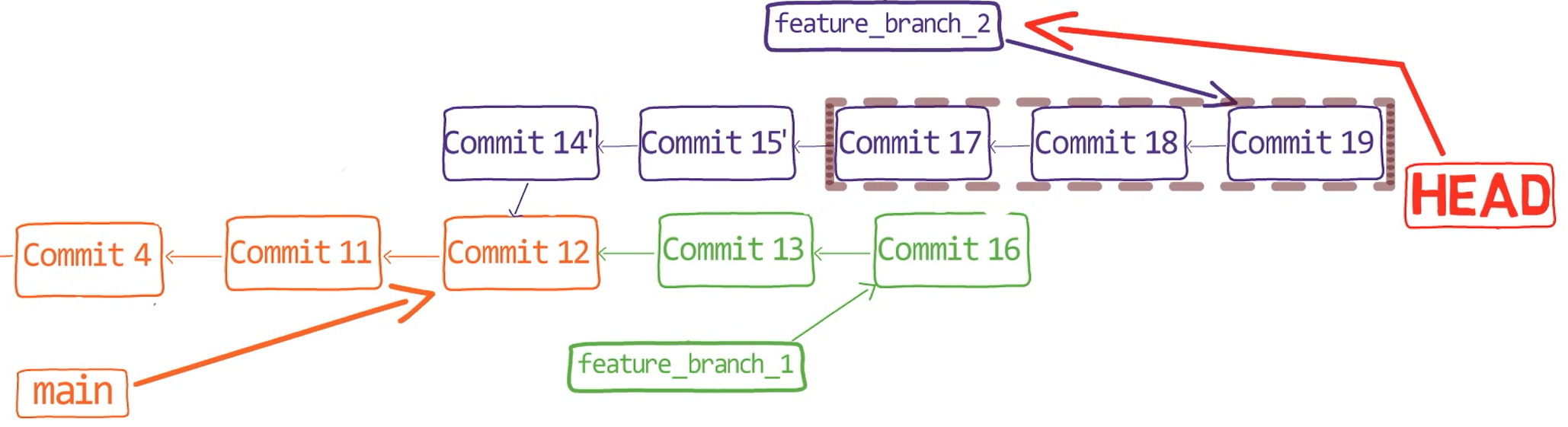 These are the commits I want to edit (Source: Brief)
These are the commits I want to edit (Source: Brief)
So, what would you do?
You are right! 👏🏻
I can rebase the history from "Commit 17" to "Commit 19", on top of "Commit 15". To do that:
git rebase --interactive --onto <SHA_OF_COMMIT_15> <SHA_OF_COMMIT_15>
Notice I specified "Commit 15" as the beginning of the range of commits, excluding this commit. And I didn't need to explicitly specify HEAD as the last parameter.
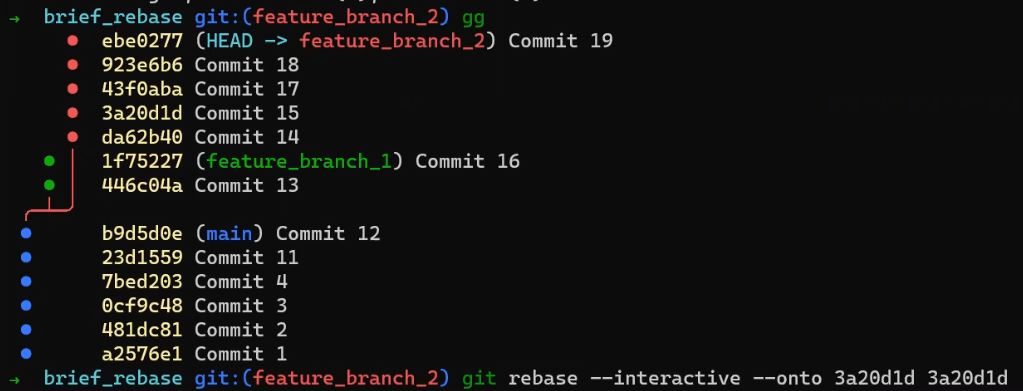 Using
Using rebase --onto on a single branch (Source: Brief)
After following your advice and running the rebase command (thanks! 😇) I get the following screen:
 Interactive rebase (Source: Brief)
Interactive rebase (Source: Brief)
So what would I do? I want to put "Commit 19" before "Commit 18", so it comes right after "Commit 17". I can go further and squash them together, like so:
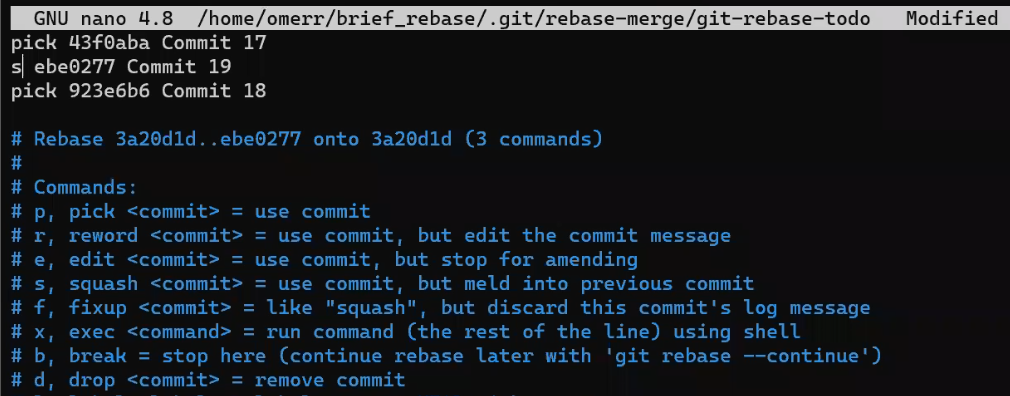 Interactive rebase - changing the order of commit and squashing (Source: Brief)
Interactive rebase - changing the order of commit and squashing (Source: Brief)
Now when I get prompted for a commit message, I can provide the message "Commit 17+19":
 Providing a commit message (Source: Brief)
Providing a commit message (Source: Brief)
And now, see our beautiful history:
 The resulting history (Source: Brief)
The resulting history (Source: Brief)
Thanks again! 🙌🏻
More Rebase Use Cases + More Practice
By now I hope you feel comfortable with the syntax of rebase. The best way to actually understand it is to consider various cases and figure out how to solve them yourself.
With the upcoming use cases, I strongly suggest you stop reading after I've introduced each use case, and then try to solve it on your own.
How to Exclude Commits
Say you have this history on another repo:
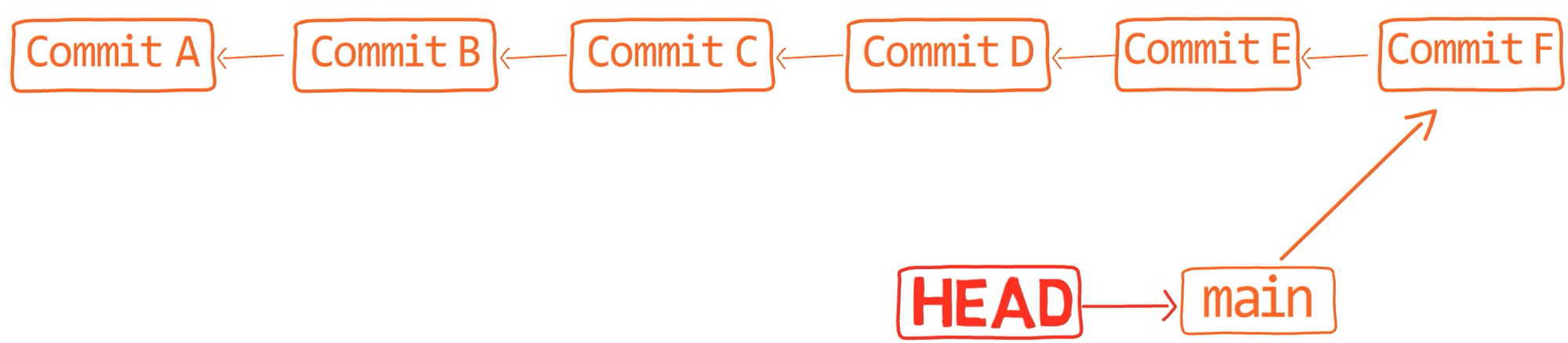 Another commit history (Source: Brief)
Another commit history (Source: Brief)
Before playing around with it, store a tag to "Commit F" so you can get back to it later:
git tag original_commit_f
Now, you actually don't want the changes in "Commit C" and "Commit D" to be included. You could use an interactive rebase like before and remove their changes. Or, could can use again git rebase -–onto. How would you use --onto in order to "remove" these two commits?
You can rebase HEAD on top of "Commit B", where the old parent was actually "Commit D", and now it should be "Commit B". Consider the history again:
The history again (Source: Brief)
Rebasing so that "Commit B" is the base of "Commit E", means "moving" both "Commit E" and "Commit F", and giving them another base – "Commit B". Can you come up with the command yourself?
git rebase --onto <SHA_OF_COMMIT_B> <SHA_OF_COMMIT_D> HEAD
Notice that using the syntax above would not move main to point to the new commit, so the result is a "detached" HEAD. If you use gg or another tool that displays the history reachable from branches it might confuse you:
 Rebasing with
Rebasing with --onto results in a detached HEAD (Source: Brief)
But if you simply use git log (or my alias git lol), you will see the desired history:
 The resulting history (Source: Brief)
The resulting history (Source: Brief)
I don't know about you, but these kinds of things make me really happy. 😊😇
By the way, you could omit HEAD from the previous command as this is the default value for the third parameter. So just using:
git rebase --onto <SHA_OF_COMMIT_B> <SHA_OF_COMMIT_D>
Would have the same effect. The last parameter actually tells Git where the end of the current sequence of commits to rebase is. So the syntax of git rebase --onto with three arguments is:
git rebase --onto <new_parent> <old_parent> <until>
How to move commits across branches
So let's say we get to the same history as before:
git checkout original_commit_f
And now I want only "Commit E", to be on a branch based on "Commit B". That is, I want to have a new branch, branching from "Commit B", with only "Commit E".
 The current history, considering "Commit E" (Source: Brief)
The current history, considering "Commit E" (Source: Brief)
So, what does this mean in terms of rebase? Consider the image above. What commit (or commits) should I rebase, and which commit would be the new base?
I know I can count on you here 😉
What I want is to take "Commit E", and this commit only, and change its base to be "Commit B". In other words, to replay the changes introduced in "Commit E" onto "Commit B".
Can you apply that logic to the syntax of git rebase?
Here it is (this time I'm writing <COMMIT_B> instead of <SHA_OF_COMMIT_B>, for brevity):
git rebase –-onto <COMMIT_B> <COMMIT_D> <COMMIT_E>
Now the history looks like so:
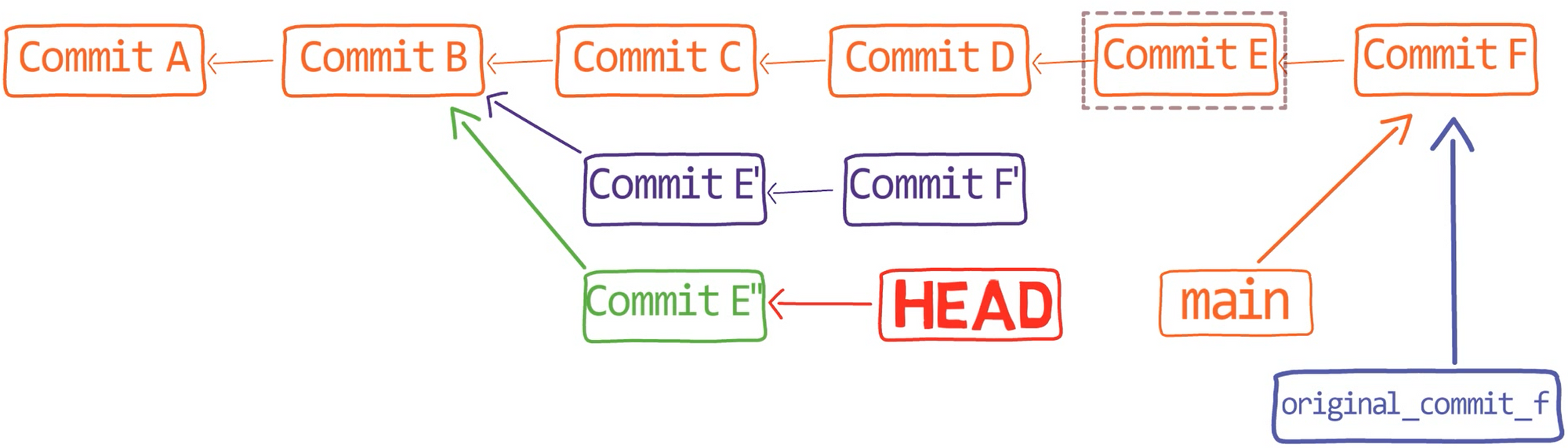 The history after rebase (Source: Brief)
The history after rebase (Source: Brief)
Awesome!
A Note About Conflicts
Note that when performing a rebase, you may run into conflicts just as when merging. You may have conflicts because when rebasing, you are trying to apply patches on a different base, perhaps where the patches do not apply.
For example, consider the previous repository again, and specifically, consider the change introduced in "Commit 12", pointed to by main:
git show main
 The patch introduced in "Commit 12" (Source: Brief)
The patch introduced in "Commit 12" (Source: Brief)
I already covered the format of git diff in detail in a previous post, but as a quick reminder, this commit instructs Git to add a line after the two lines of context:
This is a sample file
And before these three lines of context:
def new_feature():
print('new feature')
Say you are trying to rebase "Commit 12" onto another commit. If, for some reason, these context lines don't exist as they do in the patch on the commit you are rebasing onto, then you will have a conflict. To learn more about conflicts and how to resolve them, see this guide.
Zooming Out for the Big Picture
 Comparing rebase and merge (Source: Brief)
Comparing rebase and merge (Source: Brief)
In the beginning of this guide, I started by mentioning the similarity between git merge and git rebase: both are used to integrate changes introduced in different histories.
But, as you now know, they are very different in how they operate. While merging results in a diverged history, rebasing results in a linear history. Conflicts are possible in both cases. And there is one more column described in the table above that requires some close attention.
Now that you know what "Git rebase" is, and how to use interactive rebase or rebase --onto, as I hope you agree, git rebase is a super powerful tool. Yet, it has one huge drawback when compared with merging.
Git rebase changes the history.
This means that you should not rebase commits that exist outside your local copy of the repository, and that other people may have based their commits on.
In other words, if the only commits in question are those you created locally – go ahead, use rebase, go wild.
But if the commits have been pushed, this can lead to a huge problem – as someone else may rely on these commits, that you later overwrite, and then you and they will have different versions of the repository.
This is unlike merge which, as we have seen, does not modify history.
For example, consider the last case where we rebased and resulted in this history:
The history after rebase (Source: Brief)
Now, assume that I have already pushed this branch to the remote. And after I had pushed the branch, another developer pulled it and branched out from "Commit C". The other developer didn't know that meanwhile, I was locally rebasing my branch, and would later push it again.
This results in an inconsistency: the other developer works from a commit that is no longer available on my copy of the repository.
I will not elaborate on what exactly this causes in this guide, as my main message is that you should definitely avoid such cases. If you're interested in what would actually happen, I'll leave a link to a useful resource below. For now, let's summarize what we have covered.
Recap
In this tutorial, you learned about git rebase, a super-powerful tool to rewrite history in Git. You considered a few use cases where git rebase can be helpful, and how to use it with one, two, or three parameters, with and without the --onto switch.
I hope I was able to convince you that git rebase is powerful – but also that it is quite simple once you get the gist. It is a tool to "copy-paste" commits (or, more accurately, patches). And it's a useful tool to have under your belt.
Additional References
- Git Internals YouTube playlist — by Brief (my YouTube channel).
- Omer's previous post about Git internals.
- Omer's tutorial about Git UNDO - rewriting history with Git.
- Git docs on rebasing
- Branching and the power of rebase
- Interactive rebasing
- Git rebase --onto
About the Author
Omer Rosenbaum is Swimm’s Chief Technology Officer. He's the author of the Brief YouTube Channel. He's also a cyber training expert and founder of Checkpoint Security Academy. He's the author of Computer Networks (in Hebrew). You can find him on Twitter.