

“Bad programmers worry about the code. Good programmers worry about data structures and their relationships.” — Linus Torvalds, creator of Linux
Update _My video course about Algorithms is now live! Check out Algorithms in Motion from Manning Publications. Get 39% off my course by using code ‘39carnes’! Or you can get 50% off my Deep Learning in Motion course with code ‘vlcarnes2’._
Data structures are a critical part of software development, and one of the most common topics for developer job interview questions.
The good news is that they’re basically just specialized formats for organizing and storing data.
I’m going to teach you 10 of the most common data structures — right here in this short article.
I’ve embedded videos that I created for each of these data structures. I’ve also linked to code examples for each of them, which show how to implement these in JavaScript.
And to give you some practice, I’ve linked to challenges from the freeCodeCamp curriculum.
Note that some of these data structures include time complexity in Big O notation. This isn’t included for all of them since the time complexity is sometimes based on how it’s implemented. If you want to learn more about Big O Notation, check out my article about it or this video by Briana Marie.
Also note that even though I show how to implement these data structures in JavaScript, for most of them you would never need to implement them yourself, unless you were using a low-level language like C.
JavaScript (like most high-level languages) has built-in implementations of many of these data structures.
Still, knowing how to implement these data structures will give you a huge edge in your developer job search, and may come in handy when you’re trying to write high-performance code.
Linked Lists
A linked list is one of the most basic data structures. It is often compared to an array since many other data structures can be implemented with either an array or a linked list. They each have advantages and disadvantages.
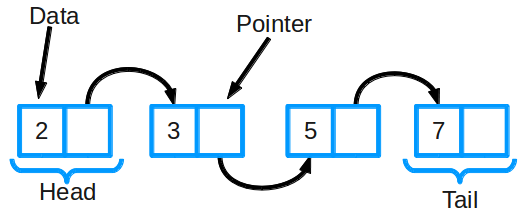 Linked list representation
Linked list representation
A linked list consists of a group of nodes which together represent a sequence. Each node contains two things: the actual data being stored (which can be basically any type of data) and a pointer (or link) to the next node in the sequence. There are also doubly linked lists where each node has a pointer to both the next item and the previous item in the list.
The most basic operations in a linked list are adding an item to the list, deleting an item from the list, and searching the list for an item.
See the code for a linked list in JavaScript here.
Linked list time complexity
| Algorithm | Average | Worst Case |
| Space | 0(n) | 0(n) |
| Search | 0(n) | 0(n) |
| Insert | 0(1) | 0(1) |
| Delete | 0(1) | 0(1) |
freeCodeCamp challenges
- Work with Nodes in a Linked List
- Create a Linked List Class
- Remove Elements from a Linked List
- Search within a Linked List
- Remove Elements from a Linked List by Index
- Add Elements at a Specific Index in a Linked List
- Create a Doubly Linked List
- Reverse a Doubly Linked List
Stacks
A stack is a basic data structure where you can only insert or delete items at the top of the stack. It is kind of similar to a stack of books. If you want to look at a book in the middle of the stack you must take all of the books above it off first.
The stack is considered LIFO (Last In First Out) — meaning the last item you put in the stack is the first item that comes out of the stack
 Stack representation
Stack representation
There are three main operations that can be performed on stacks: inserting an item into a stack (called ‘push’), deleting an item from the stack (called ‘pop’), and displaying the contents of the stack (sometimes called ‘pip’).
See the code for a stack in JavaScript here.
Stack time complexity
| Algorithm | Average | Worst Case |
| Space | 0(n) | 0(n) |
| Search | 0(n) | 0(n) |
| Insert | 0(1) | 0(1) |
| Delete | 0(1) | 0(1) |
freeCodeCamp challenges
Queues
You can think of a queue as a line of people at a grocery store. The first one in the line is the first one to be served. Just like a queue.
 Queue representation
Queue representation
A queue is considered FIFO (First In First Out) to demonstrate the way it accesses data. This means that once a new element is added, all elements that were added before have to be removed before the new element can be removed.
A queue has just two main operations: enqueue and dequeue. Enqueue means to insert an item into the back of the queue and dequeue means removing the front item.
See the code for a queue in JavaScript here.
Queue time complexity
| Algorithm | Average | Worst Case |
| Space | 0(n) | 0(n) |
| Search | 0(n) | 0(n) |
| Insert | 0(1) | 0(1) |
| Delete | 0(1) | 0(1) |
freeCodeCamp challenges
Sets
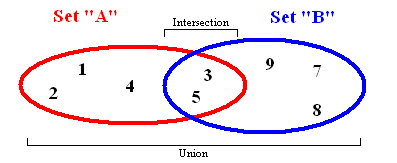 Set representation
Set representation
The set data structure stores values without any particular order and with no repeated values. Besides being able to add and remove elements to a set, there are a few other important set functions that work with two sets at once.
- Union — This combines all the items from two different sets and returns this as a new set (with no duplicates).
- Intersection — Given two sets, this function returns another set that has all items that are part of both sets.
- Difference — This returns a list of items that are in one set but NOT in a different set.
- Subset — This returns a boolean value that shows if all the elements in one set are included in a different set.
View the code to implement a set in JavaScript here.
freeCodeCamp challenges
- Create a Set Class
- Remove from a Set
- Size of the Set
- Perform a Union on Two Sets
- Perform an Intersection on Two Sets of Data
- Perform a Difference on Two Sets of Data
- Perform a Subset Check on Two Sets of Data
- Create and Add to Sets in ES6
- Remove items from a set in ES6
- Use .has and .size on an ES6 Set
- Use Spread and Notes for ES5 Set() Integration
Maps
A map is a data structure that stores data in key / value pairs where every key is unique. A map is sometimes called an associative array or dictionary. It is often used for fast look-ups of data. Maps allow the following things:
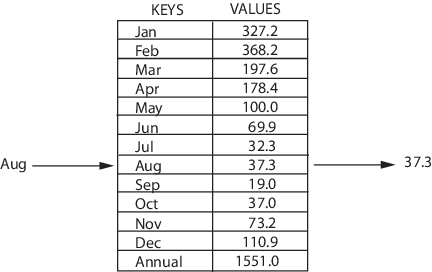 Map representation
Map representation
- the addition of a pair to the collection
- the removal of a pair from the collection
- the modification of an existing pair
- the lookup of a value associated with a particular key
View the code to implement a map in JavaScript here.
freeCodeCamp challenges
Hash Tables
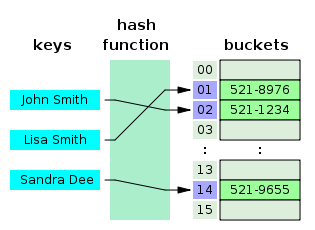 Hash table and hash function representation
Hash table and hash function representation
A hash table is a map data structure that contains key / value pairs. It uses a hash function to compute an index into an array of buckets or slots, from which the desired value can be found.
The hash function usually takes a string as input and it outputs an numerical value. The hash function should always give the same output number for the same input. When two inputs hash to the same numerical output, this is called a collision. The goal is to have few collisions.
So when you input a key / value pair into a hash table, the key is run through the hash function and turned into a number. This numerical value is then used as the actual key that the value is stored by. When you try to access the same key again, the hashing function will process the key and return the same numerical result. The number will then be used to look up the associated value. This provides very efficient O(1) lookup time on average.
View the code for a hash table here.
Hash table time complexity
| Algorithm | Average | Worst Case |
| Space | 0(n) | 0(n) |
| Search | 0(1) | 0(n) |
| Insert | 0(1) | 0(n) |
| Delete | 0(1) | 0(n) |
freeCodeCamp challenges
Binary Search Tree
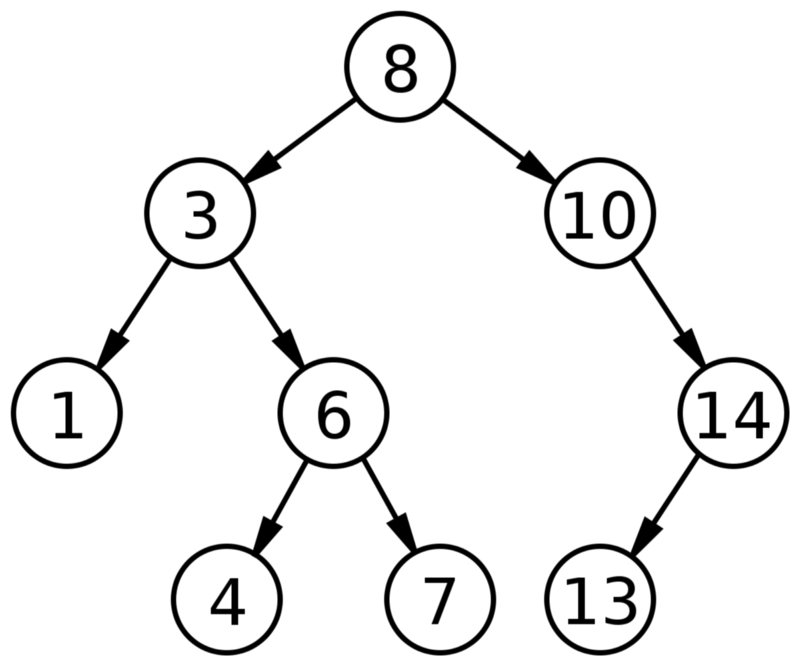 Binary search tree
Binary search tree
A tree is a data structure composed of nodes It has the following characteristics:
- Each tree has a root node (at the top).
- The root node has zero or more child nodes.
- Each child node has zero or more child nodes, and so on.
A binary search tree adds these two characteristics:
- Each node has up to two children.
- For each node, its left descendents are less than the current node, which is less than the right descendents.
Binary search trees allow fast lookup, addition and removal of items. The way that they are set up means that, on average, each comparison allows the operations to skip about half of the tree, so that each lookup, insertion or deletion takes time proportional to the logarithm of the number of items stored in the tree.
View the code for a binary search tree in JavaScript here.
Binary search time complexity
| Algorithm | Average | Worst Case |
| Space | 0(n) | 0(n) |
| Search | 0(log n) | 0(n) |
| Insert | 0(log n) | 0(n) |
| Delete | 0(log n) | 0(n) |
freeCodeCamp challenges
- Find the Minimum and Maximum Value in a Binary Search Tree
- Add a New Element to a Binary Search Tree
- Check if an Element is Present in a Binary Search Tree
- Find the Minimum and Maximum Height of a Binary Search Tree
- Use Depth First Search in a Binary Search Tree
- Use Breadth First Search in a Binary Search Tree
- Delete a Leaf Node in a Binary Search Tree
- Delete a Node with One Child in a Binary Search Tree
- Delete a Node with Two Children in a Binary Search Tree
- Invert a Binary Tree
Trie
The trie (pronounced ‘try’), or prefix tree, is a kind of search tree. A trie stores data in steps where each step is a node in the trie. Tries are often used to store words for quick lookup, such as a word auto-complete feature.
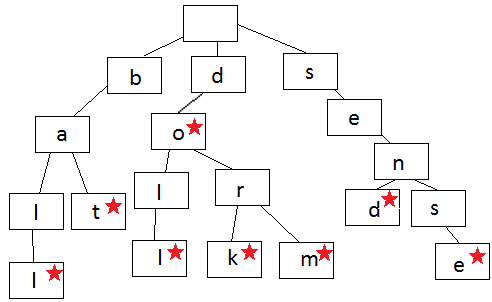 Trie representation
Trie representation
Each node in a language trie contains one letter of a word. You follow the branches of a trie to spell a word, one letter at a time. The steps begin to branch off when the order of the letters diverge from the other words in the trie, or when a word ends. Each node contains a letter (data) and a boolean that indicates whether the node is the last node in a word.
Look at the image and you can form words. Always start at the root node at the top and work down. The trie shown here contains the word ball, bat, doll, do, dork, dorm, send, sense.
View the code for a trie in JavaScript here.
freeCodeCamp challenges
Binary Heap
A binary heap is another type of tree data structure. Every node has at most two children. Also, it is a complete tree. This means that all levels are completely filled until the last level and the last level is filled from left to right.
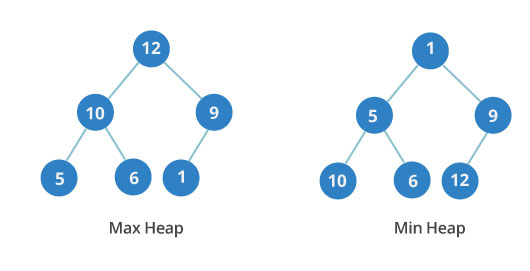 Min and max heap representations
Min and max heap representations
A binary heap can be either a min heap or a max heap. In a max heap, the keys of parent nodes are always greater than or equal to those of the children. In a min heap, the keys of parent nodes are less than or equal to those of the children.
The order between levels is important but the order of nodes on the same level is not important. In the image, you can see that the third level of the min heap has values 10, 6, and 12. Those numbers are not in order.
View the code for a heap in JavaScript here.
Binary heap time complexity
| Algorithm | Average | Worst Case |
| Space | 0(n) | 0(n) |
| Search | 0(1) | 0(log n) |
| Insert | 0(log n) | 0(log n) |
| Delete | 0(1) | 0(1) |
freeCodeCamp challenges
- Insert an Element into a Max Heap
- Remove an Element from a Max Heap
- Implement Heap Sort with a Min Heap
Graph
Graphs are collections of nodes (also called vertices) and the connections (called edges) between them. Graphs are also known as networks.
One example of graphs is a social network. The nodes are people and the edges are friendship.
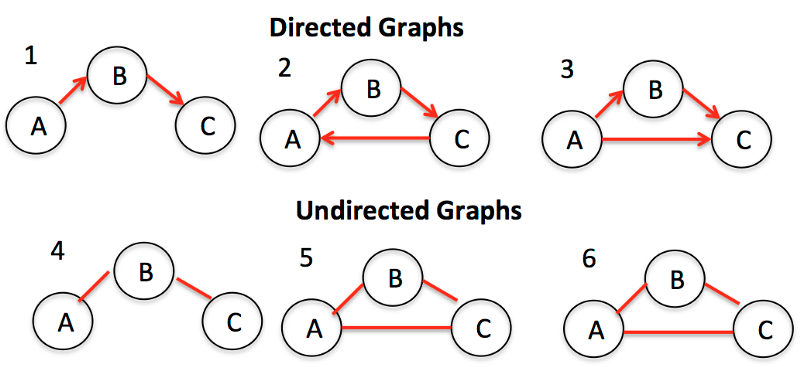
There are two major types of graphs: directed and undirected. Undirected graphs are graphs without any direction on the edges between nodes. Directed graphs, in contrast, are graphs with a direction in its edges.
Two common ways to represent a graph are an adjacency list and an adjacency matrix.
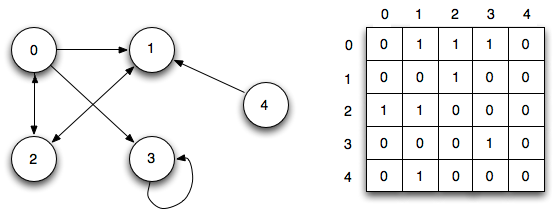 Adjacency matrix graph
Adjacency matrix graph
An adjacency list can be represented as a list where the left side is the node and the right side lists all the other nodes it’s connected to.
An adjacency matrix is a grid of numbers, where each row or column represents a different node in the graph. At the intersection of a row and a column is a number that indicates the relationship. Zeros mean there is no edge or relationship. Ones mean there is a relationship. Numbers higher than one can be used to show different weights.
Traversal algorithms are algorithms to traverse or visit nodes in a graph. The main types of traversal algorithms are breadth-first search and depth-first search. One of the uses is to determine how close nodes are to a root node. See how to implement breadth-first search in JavaScript in the video below.
See the code for breadth-first search on an adjacency matrix graph in JavaScript.
Binary search time complexity
| Algorithm | Time | ||||
| Storage | O(\ | V\ | +\ | E\ | ) |
| Add Vertex | O(1) | ||||
| Add Edge | O(1) | ||||
| Remove Vertex | O(\ | V\ | +\ | E\ | ) |
| Remove Edge | O(\ | E\ | ) | ||
| Query | O(\ | V\ | ) |
freeCodeCamp challenges
More
The book Grokking Algorithms is the best book on the topic if you are new to data structures/algorithms and don’t have a computer science background. It uses easy-to-understand explanations and fun, hand-drawn illustrations (by the author who is a lead developer at Etsy) to explain some of the data structures featured in this article.
Grokking Algorithms: An illustrated guide for programmers and other curious people
_Summary Grokking Algorithms is a fully illustrated, friendly guide that teaches you how to apply common algorithms to…_www.amazon.com
Or you can check out my video course based on that book: Algorithms in Motion from Manning Publications. Get 39% off my course by using code ‘39carnes’!
