
By Ivan Yung
When I was first introduced to machine learning, I had no idea what I was reading. All the articles I read consisted of weird jargon and crazy equations. How could I figure all this out?
I opened a new tab in Chrome and looked for easier solutions. I found APIs from Amazon, Microsoft, and Google that did all the machine learning for me. Each hackathon project I made would call their servers and WOW — it looked so smart! I was hooked.
But, after a year, I realized that I wasn’t learning anything. Everything I was doing was described by this Nedroid comic that I modified:
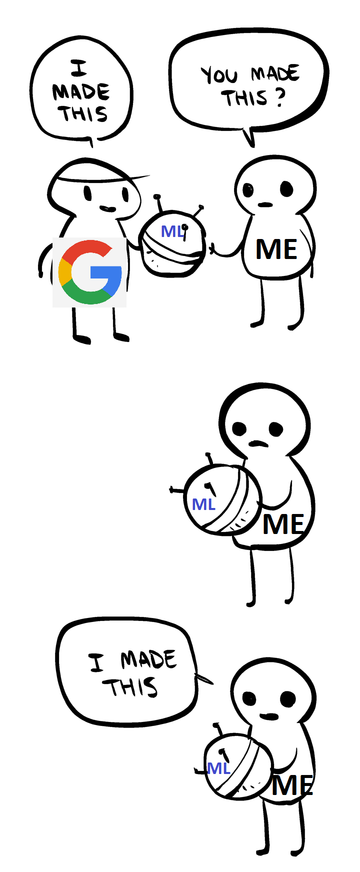 _[Original image source](https://nedroidcomics.tumblr.com/post/41879001445/the-internet" rel="noopener" target="blank" title=").
_[Original image source](https://nedroidcomics.tumblr.com/post/41879001445/the-internet" rel="noopener" target="blank" title=").
Eventually, I sat down and learned how to use machine learning without megacorporations. And turns out, anyone can do it. The current libraries we have in Python are amazing. In this article, I will explain how I use these libraries to create a proper machine learning back end.
Getting a dataset
Machine learning projects are reliant on finding good datasets. If the dataset is bad, or too small, we cannot make accurate predictions. You can find some good datasets at Kaggle or the UC Irvine Machine Learning Repository.
In this article, I am using a wine quality dataset with many features and one label. Features are independent variables which affect the dependent variable called the label. In this case, we have one label column — wine quality — that is affected by all the other columns (features like pH, density, acidity, and so on).
In the following Python code, I use a library called pandas to control my dataset. pandas provides datasets with many functions to select and manipulate data.
First, I load the dataset to a panda and split it into the label and its features. I then grab the label column by its name (quality) and then drop the column to get all the features.
 Scikits-learn, the library we will use for machine learning
Scikits-learn, the library we will use for machine learning
Training a model
Machine learning works by finding a relationship between a label and its features. We do this by showing an object (our model) a bunch of examples from our dataset. Each example helps define how each feature affects the label. We refer to this process as training our model.
I use the estimator object from the Scikit-learn library for simple machine learning. Estimators are empty models that create relationships through a predefined algorithm.
For this wine dataset, I create a model from a linear regression estimator. (Linear regression attempts to draw a straight line of best fit through our dataset.) The model is able to get the regression data through the fit function. I can use the model by passing in a fake set of features through the predict function. The example below shows the features for one fake wine. The model will output an answer based on its training.
The code for this model, and fake wine, is below:
Importing and exporting our Python model
The pickle library makes it easy to serialize the models into files that I create. I am also able to load the model back into my code. This allows me to keep my model training code separated from the code that deploys my model.
I can import or export my Python model for use in other Python scripts with the code below:
Creating a simple web server
 Flask, the framework we will use to create a web server.
Flask, the framework we will use to create a web server.
To deploy my model, I first have to create a server. Servers listen to web traffic, and run functions when they find a request addressed to them. The function that runs can depend on the request’s route and other data that it has. Afterwards, the server can send a message of confirmation back to the requester.
The Flask Python framework allows me to create web servers in record time.
In the code below, I use Flask to run a simple one-route web server. My one route listens to POST requests and sends a hello back. POST requests are a special type of request that carry data in a JSON object.
Adding the model to my server
With the pickle library, I am able to able to load our trained model into my web server.
Our server now loads the trained model during its initialization. I can access it by sending a post request to my “/echo” route. The route grabs an array of features from the request body and gives it to the model. The model’s prediction is then sent back to the requester.
Conclusion
After reading this article, you should be able to create your own machine learning back end. For more detail, you can find a full example that I made at this repository.
When you have time, I recommend taking a step back from coding and reading about machine learning. This article only teaches the bare necessities to create a model. There are topics like loss reduction and neural nets that you need to know.
Good luck and happy coding!