
By Carlos Raphael
In the article Specification Pattern, for the sake of sanity, I didn’t mention about an underlying component to nicely make that thing happen. Now, I’ll elaborate a little bit more around the JavaBeanUtil class, that I put in place to read the value for a given fieldName from a particular javaBeanObject, which in that occasion turned out to be FxTransaction.
You can easily argue I could’ve basically used Apache Commons BeanUtils or one of its alternatives to achieve the same result. But I was interested in getting my own hands dirty with something different that I knew would be way faster than any library built on top of the widely known Java Reflection.
The enabler of the technique used to avoid the very slow reflection is the invokedynamic bytecode instruction. Briefly, invokedynamic (or “indy”) was the greatest thing introduced in Java 7 in order to pave the way for implementing dynamic languages on top of the JVM through dynamic method invocation. It also later allowed lambda expression and method reference in Java 8 as well as string concatenation in Java 9 to benefit from it.
In a nutshell, the technique I’m about to better describe below leverages LambdaMetafactory and MethodHandle in order to dynamically create an implementation of Function. Its single method delegates a call to the actual target method with a code defined inside of lambda body.
The target method in question here is the actual getter method that has direct access to the field we want to read. Also, I should say if you are quite familiar with the nice things that came up within Java 8, you will find the below code snippets fairly easy to understand. Otherwise, it may be tricky at a glance.
A peek at the homemade JavaBeanUtil
The following method is the utility used to read a value from a JavaBean field. It takes the JavaBean object and a single fieldA or even nested field separated by periods, for example, nestedJavaBean.nestedJavaBean.fieldA
For optimal performance, I’m caching the dynamically created function that is the actual way of reading the content of a given fieldName. So inside the getCachedFunction method, as you can see above, there’s a fast path leveraging the ClassValue for caching and there’s the slow createAndCacheFunction path executed only if nothing has been cached so far.
The slow path will basically delegate to the createFunctions method that is returning a list of functions to be reduced by chaining them using Function::andThen. When functions are chained, you can imagine some sort of nested calls like getNestedJavaBean().getNestedJavaBean().getFieldA(). Finally, after chaining we simply put the reduced function in the cache calling cacheAndGetFunction method.
Drilling a bit more into the slow path of function creation, we need to individually navigate through the field path variable by splitting it as per below:
The above createFunctions method delegates the individual fieldName and its class holder type to createFunction method, which will locate the needed getter based upon javaBeanClass.getDeclaredMethods(). Once it’s located, it maps to a Tuple object (facility from Vavr library), that contains the return type of the getter method and the dynamically created function in which will act as if it was the actual getter method itself.
This tuple mapping is done by createTupleWithReturnTypeAndGetter in conjunction with createCallSite method as follows:
In the above two methods, I make use of a constant called LOOKUP, which is simply a reference to MethodHandles.Lookup. With that, I can create a direct method handle based on the previously located getter method. And finally, the created MethodHandle is passed to createCallSite method whereby the lambda body for the function is produced using the LambdaMetafactory. From there, ultimately, we can obtain the CallSite instance, which is the function holder.
Note that if I wanted to deal with setters I could use a similar approach by leveraging BiFunction instead of Function.
Benchmark
In order to measure the gains of performance, I used the ever-awesome JMH (Java Microbenchmark Harness), which will likely be part of the JDK 12. As you may know, results are bound to the platform, so for reference I’ll be utilizing a single 1x6 i5-8600K 3.6GHz and Linux x86_64 as well as Oracle JDK 8u191 and GraalVM EE 1.0.0-rc9.
For comparison, I used Apache Commons BeanUtils, a well-known library for most Java developers, and one of its alternatives called Jodd BeanUtil which claims to be almost 20% faster.
Benchmark scenario is set as follows:
The benchmark is driven by how deep we are going to retrieve some value as per the four different levels specified above. For each fieldName, JMH will perform 5 iterations of 3 seconds each to warm things up and then 5 iterations of 1 second each to actually measure. Each scenario will then repeat 3 times to reasonably gather the metrics.
Results
Let’s start with the results gathered from the JDK 8u191 run:
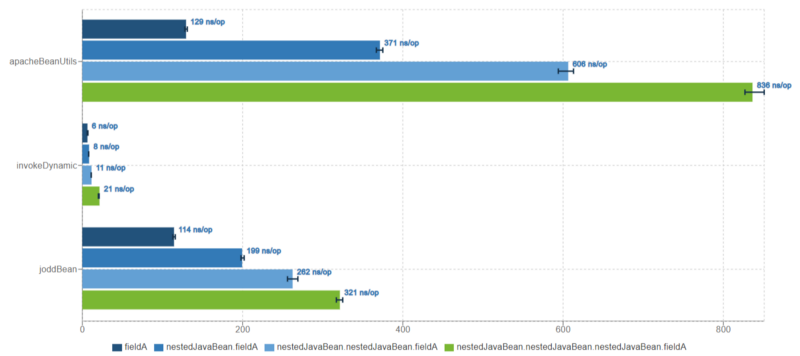 Oracle JDK 8u191
Oracle JDK 8u191
The worst scenario using invokedynamic approach is much faster than the fastest scenario from the other two libraries. That’s a huge difference, and if you’re doubting the results, you can always download the source code and play around as you like.
Now, let’s see how the same benchmark performs with GraalVM EE 1.0.0-rc9
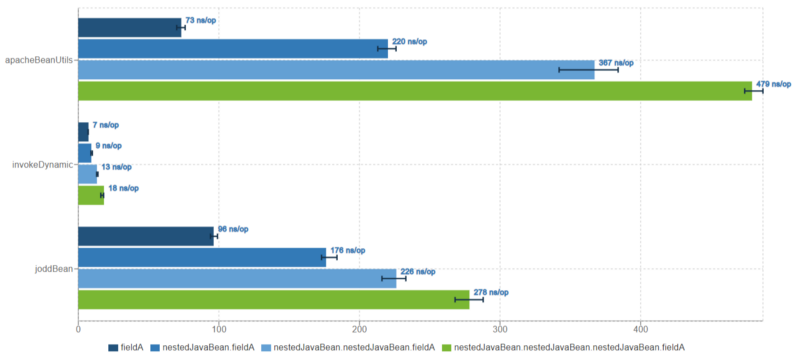 GraalVM EE 1.0.0-rc9
GraalVM EE 1.0.0-rc9
Full results can be viewed here with the nice JMH Visualizer.
Observations
The huge difference is because JIT-compiler knows CallSite and MethodHandle very well and knows how to inline them quite well as opposed to the reflection approach. Also, you can see how promising GraalVM is. Its compiler does a truly awesome job being capable of a great performance enhancement for the reflection approach.
If you’re curious and want to play further, I encourage you to pull the source code from my Github. Bear in mind I’m not encouraging you to do your own homemade JavaBeanUtil and use in production. Rather my aim here is to simply showcase my experiment and the possibilities we can get from invokedynamic.