
By Davis David
Africa has over 2000 languages, but these languages are not well-represented in the existing Natural Language Processing ecosystem.
One challenge is the lack of useful African language datasets that we can use to solve different social and economic problems.
In this article, I have compiled a list of African language datasets from across the web. You can use these datasets in various NLP tasks such as text classification, named entity recognition, machine translation, sentiment analysis, speech recognition, and topic modeling.
I've made this collection of datasets public to give you an opportunity to use your skills and help solve different challenges.
Text Classification Datasets
Text classification datasets are categorized or organized into different groups based on their contents.
Below is the list of African language datasets for Text classification.
Swahili News Dataset
The Swahili news dataset contains more than 31,000 news articles from different news categories such as local, international, business or financial, health, sports, and entertainment. The Swahili language is one of the most spoken languages in Africa, with around 100–150 million speakers across East Africa.
I collected the data from different news publication platforms inside and outside of Tanzania. You can use this dataset to develop a multi-class classification model to classify news content according to specific categories.
Swahili online news platforms can use the model to automatically group news according to their categories and help readers find the specific news they want to read.
You can also download this dataset from the datasets python library:
from datasets import load_dataset
dataset = load_dataset("swahili_news")
Note: The Swahili news dataset has an imbalance of category distribution. It contains few news articles in the following categories:
- International News ( 6.2%)
- Health News (4.9%)
- Business News (4.3%)
Chichewa News Dataset
This dataset consists of news articles in Chichewa. Chichewa is a Bantu language spoken in much of Southern, Southeast, and East Africa, namely in Malawi and Zambia, where it is an official language.
The dataset contains a collection of 3,482 articles, containing over 930,000 words, and over 48,000 sentences. The Chichewa news articles have been categorized into 19 categories such as education, law/order, politics, culture, arts and crafts, farming, economy, and wildlife.
You can also download this dataset here: AI4D Malawi News Classification Zindi Challenge.
Named-entity Recognition Datasets
You use named-entity recognition datasets to extract information by locating and classifying named entities mentioned in unstructured text. Examples of entities are person names, organizations, locations, times, and dates.
NER is an essential component of numerous applications including spellcheckers, conversational agents, and localization of voice and dialogue systems.
Here is the list of African language datasets for Named-entity Recognition.
Masakhane-ner Datasets
Masakhane is a grassroots NLP community for Africa, by Africans with a mission to strengthen and spur NLP research in African languages. The community created the first large publicly available high-quality dataset for named entity recognition (NER) in ten African languages.
- Amharic
- Hausa
- Igbo
- Kinyarwanda
- Luganda
- Luo
- Naija Pidgin
- Swahili
- Wolof
- Yorùbá
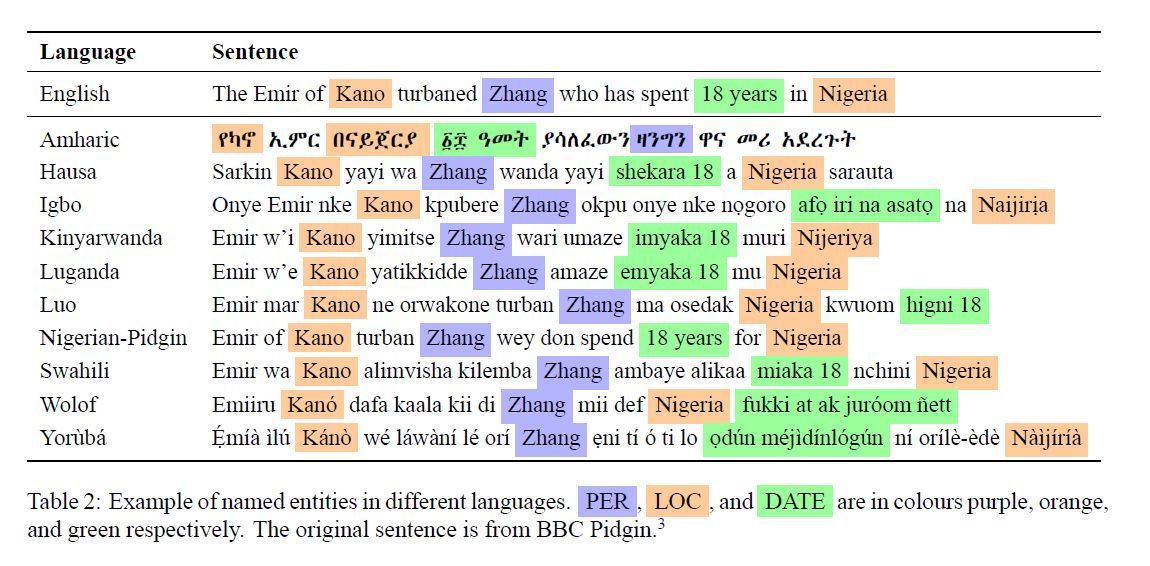
You can read the research paper here: MasakhaNER: Named Entity Recognition for African Languages, and you can download the ten NER datasets here.
Machine Translation Datasets
Machine translation (MT) is the task of translating a text or speech in a source language to a different target language. You can use machine translation to translate large volumes of text quickly without any human input.
You ca use machine translation datasets to create MT models for different purposes such as:
- Internal emails and other written or oral communication.
- Documentation and instructions for products or services.
Below is the list of African language datasets for Machine translation.
French to Ewe and French to Fongbe Machine Translation Dataset
This is a parallel corpus dataset for machine translation from French to Ewe and French to Fongbe.
Fonbge and Ewe are Niger-Congo languages. Fongbe is spoken in Benin with approximately 4.1 million speakers while Ewe is spoken in Togo and southeastern Ghana with approximately 4.5 million speakers.
This dataset contains roughly 23,000 French to Ewe and 53,000 French to Fongbe parallel sentences, collected from blogs, tales, newspapers, daily conversations, and webpages, and it's been annotated for neural machine translation.
Yorùbá to English Machine Translation Dataset
This is a parallel sentence corpus dataset for machine translation from the Yorùbá language to the English language.
Yorùbá is the Niger-Congo language and it is spoken in West Africa (southwestern Nigeria). The number of Yorùbá speakers is estimated at between 45 to 55 million.
The dataset consists of 10,054 parallel Yorùbá-English sentences from different areas like news, Yorùbá proverbs, movie transcripts, localization translations, and books.
English to Luganda Machine Translation Dataset
This is a parallel sentence corpus dataset for machine translation from the English language to the Luganda language.
Luganda is a Bantu language and it is one of the major languages in Uganda. More than 8.5 million Baganda speak it along with many other people in Kampala (the capital city of Uganda).
The dataset consists of 15,022 parallel English-Luganda sentences. A team of researchers from the AI and Data Science research Lab at Makerere University created it along with a team of Luganda teachers, students, and freelancers.
Sentiment Analysis Datasets
Sentiment Analysis Datasets are used for the interpretation and classification of emotions (positive, negative, and neutral) within text data using different text analysis methods.
Sentiment analysis has applications in various fields such as social media monitoring, brand monitoring, customer service, and market research.
Below is the list of African language datasets for Sentiment Analysis.
Tunizi Dataset
Tunizi is the first Tunisian Arabizi sentiment analysis dataset. Tunisian Arabizi represents the Tunisian dialect that is written in Latin characters and numbers rather than Arabic letters.
iCompass gathered comments from social media platforms that express sentiment about popular topics. They extracted 100k comments using public streaming APIs.
The collected comments were manually annotated using an overall polarity:
- Positive (1)
- Negative (-1)
- Neutral (0)
The annotators were diverse in gender, age, and social background.
You can also download this dataset from the datasets python library:
from datasets import load_dataset
dataset = load_dataset("tunizi")
Speech Recognition Datasets
Speech recognition, also known as Automatic Speech Recognition (ASR), is a technology that analyzes human speech and formulates an output, often a written transcription, in real-time. This is sometimes referred to as “speech to text.”
Don’t confuse this with voice recognition, as voice recognition just seeks to identify an individual user’s voice.
Below is the list of African language datasets for Speech Recognition.
Speech Recognition dataset in Wolof
Wolof is the language of Senegal, the Gambia, and Mauritania. It is spoken by more than 10 million people and about 40 percent (approximately 5 million people) of Senegal’s population speak Wolof as their native language.
The ASR dataset has a total of 6,683 audio files and transcriptions and it was created by a team of researchers from the Baamtu Datamation company in Senegal.
Speech Recognition dataset in Kinyarwanda
Kinyarwanda is the Bantu language and an official language of Rwanda. At least 12 million people speak it in Rwanda, the Eastern Democratic Republic of the Congo, and southern Uganda.
The dataset was created by 895 speakers from different genders and ages in a common voice platform. The dataset has a total of 1,183 hours of validated speech. The current dataset is 40GB.
Topic Modeling Datasets
Topic modeling uses unsupervised learning techniques to extract the main topic or set of topics that occur in a collection of text documents.
Here's an African language dataset for Topic Modeling.
South African News Dataset
This is the news dataset from South Africa. The news data were collected from SABC4 Facebook pages. The SABC is the public broadcaster in South Africa.
The dataset contains news headlines (that is, short text) from the Setswana and Sepedi languages. Setswana is a Bantu language spoken in Southern Africa by about 8.2 million people while Sepedi is mainly spoken in the northern parts of South Africa by 4.7 million people.
Since the dataset is not annotated, you can use it to create a topic model to cluster news data into different news topics such as sports, politics, culture, and entertainment.
Final Thoughts on African Language Datasets
I hope you found this list of different African language datasets useful and you can use them in your next data science projects. I'm exited to see what applications/solutions you create from these datasets.
If you didn't find the dataset you need, please check out the following links:
Congratulations 👏👏, you have made it to the end of this article! I hope you have learned something new that will help you in your next data science project.
If you learned something new or enjoyed reading this article, please share it so that others can see it. Until then, see you in the next post!
You can also find me on Twitter @Davis_McDavid.
You can read other articles here.