
By Kangze Huang
The Complete AWS Web Boilerplate — Tutorial 2

Table of Contents
Part 0: Introduction to the Complete AWS Web Boilerplate
Part 1: User Authentication with AWS Cognito (3 parts)
Part 2: Saving File Storage Costs with Amazon S3 (1 part)
Part 3: Sending Emails with Amazon SES (1 part)
Part 4: Manage Users and Permissions with AWS IAM [Coming Soon]
Part 5: Cloud Server Hosting with AWS EC2 and ELB[Coming Soon]
Part 6: The MongoDB Killer: AWS DynamoDB [Coming Soon]
Part 7: Painless SQL Scaling using AWS RDS [Coming Soon]
Part 8: Serverless Architecture with Amazon Lambda [Coming Soon]
Download the Github here.
Introduction
Traditionally, files served to an app would be saved to a server’s filesystem and the architecture designed by a developer. We can immediately see that this is costly in terms of labor and a business risk as we must rely on the expertise/design of a developer(s). This is also costly in terms of bandwidth, as every file must be transferred from the server to the client. If we keep the file system on the main server, it will slow down processing of all the core functionality. If we separate the file system into its own server, we must pay extra for the uptime this server runs on, as well as devise a way to access images reliably even when URLs change. And how about different file types? We need to write code to handle JPGs, MP4s, PDFs, ZIP files..etc. How about security and restricted access to only authorized users? Security is a monumental task in itself. Finally, if we want all this to scale we will have to pay out of the ass for it. What if there were a way to achieve all this production level functionality easily and cost effectively?
Introducing Amazon Simple Storage Service (S3) — A fully managed file storage system that you can reliably use at scale, and secure right out of the box. Your files are automatically stored in multiple physical locations for guaranteed availability, even if one storage center fails. Everything is handled for you so that all you need to do to access your content is provide the URL (and be an authorized user if applicable). S3 is a bargin because S3 bandwidth/storage is a lot cheaper than EC2 bandwidth/storage: to store 10GB of images with 30GB data transfer-out and 1 million GET requests comes out to a monthly total of… $1.89 USD. Wow. Let’s get started.
Initial Setup
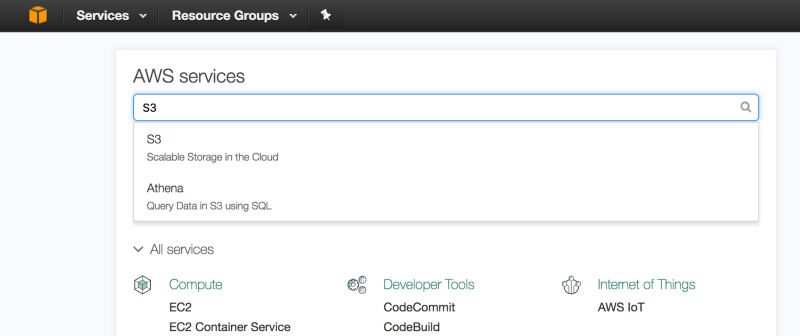
Click the AWS Console icon (the cube) at the top left hand corner and search for S3.
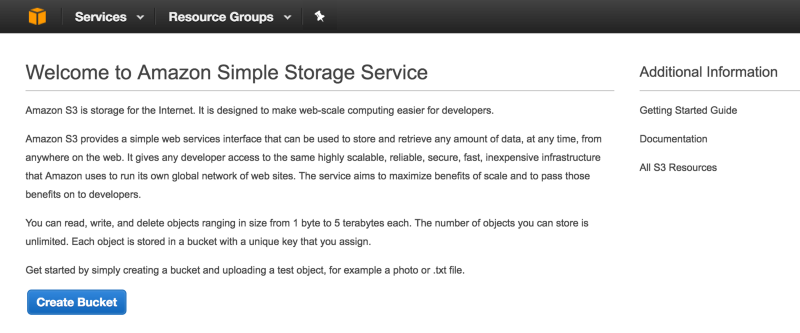
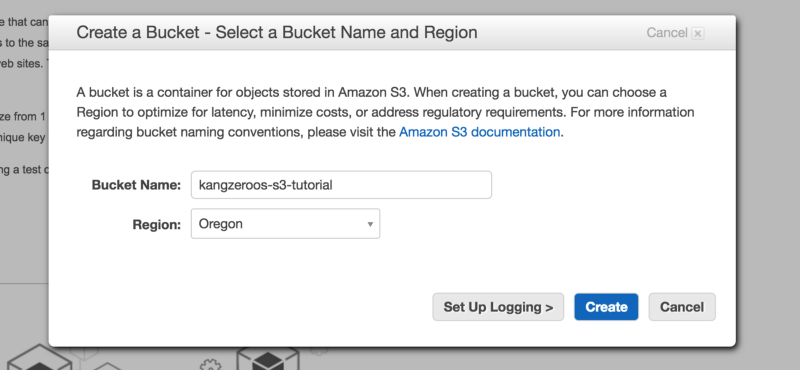
At the S3 page, click the “Create Bucket” button. Name your S3 bucket something unique, as you cannot have the same bucket name as any other S3 bucket on the internet. Also choose a region closest to where your users will reside so that connection speeds are fastest.
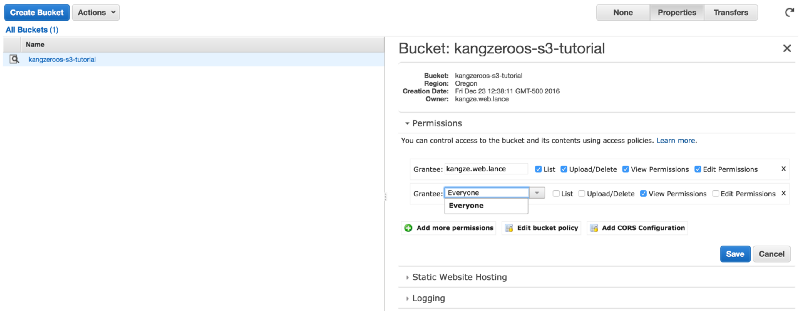
On the next S3 management screen, click Permissions and “Add more permissions”. In the dropdown menu, select “Everyone”. This will make your S3 bucket and all its contents publicly accessible.
If we want to more fine-tune who has access to our S3 bucket, we can create a bucket policy. Click the “Add bucket policy” button and then “AWS Policy Generator” in the bottom left hand corner. The policy text you see below is the output of the policy generator.
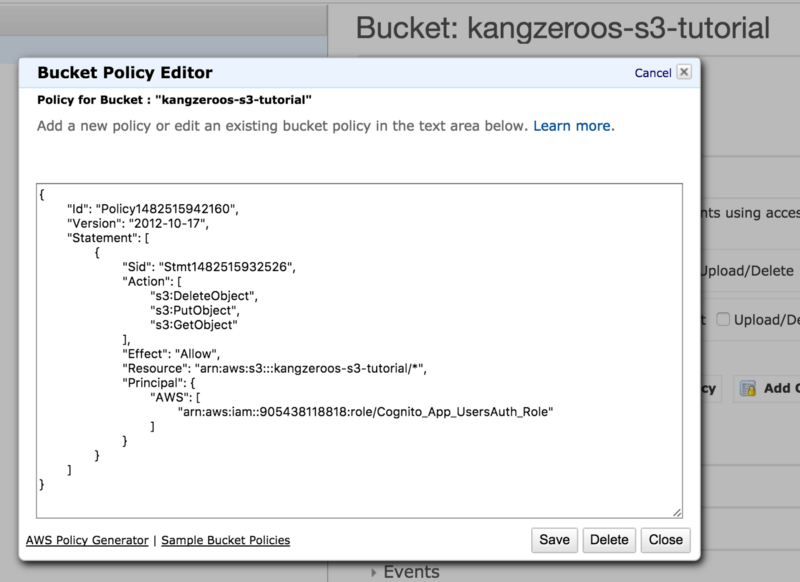
Two things to note when you are generating your policy. “Action” refers to a functionality that is allowed to be done on this S3 bucket, in this case deleting, creating and viewing objects. “Principal” refers to the entity allowed to do that action, such as a Cognito User’s IAM role (the example here uses the Cognito_App_UsersAuth_Role created in my AWS Cognito Tutorial). The “Principal” is referred to by its ARN identifier which you can find on the info page for that principal, and follows the format of arn:aws:<AWS_SERVICE>:::<UNIQUE_IDENTIFIER>. If you look at the ARN for the “Principal” or “Resource”, you will find a similar pattern. Finally, “Resource” refers to the S3 bucket object that this policy applies to, identified again by its ARN. In this case our “Resource” is our S3 bucket followed by /* to indicate all child objects of our S3 bucket. You can always add more policy rules by adding another statement object inside the Statement array.
One last thing we must set-up is the S3 bucket CORS configuration. If we want websites to be able to access our S3 bucket resources without security complaints, we must specify which http actions are allowed. If you don’t know what CORS is, read up on it here.
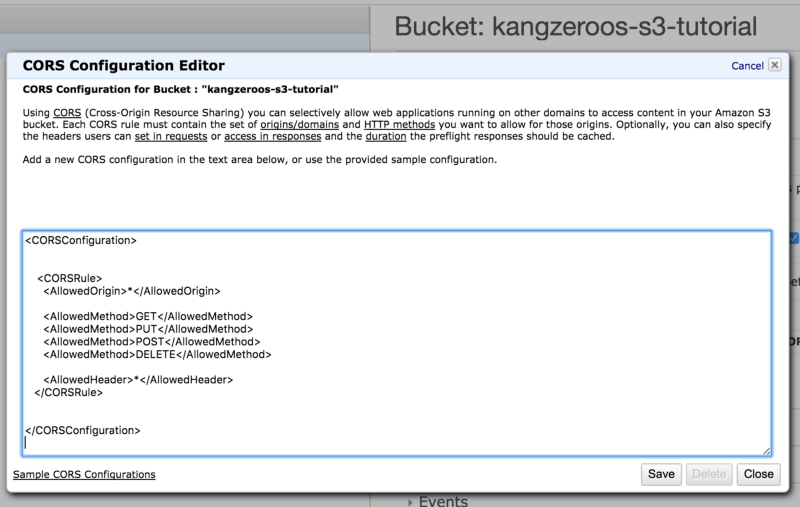
So this is pretty straightforward, the <AllowedOrigin>*</AllowedOrigin> means our http request can come from anywhere. If we wanted to only allow requests from a certain IP address (such would be the case in production), we would have <AllowedOrigin>10.67.53.55. Next, the GET specifies that GET requests are allowed. We can specify more allowed methods, or if we enjoy living dangerously, we can do allows any header, such as OPTION, to be authorized communication with this S3 bucket. If we want to add more rules, simply add another . Simple isn’t it? If you need more examples, click “Sample CORS Configurations” on the bottom left hand corner.
Ok, we’re almost ready to dive into the code!
A Quick S3 Briefing
Recall that only users authenticated through AWS Cognito are able to modify (upload or delete) files, whereas all users are able to view files. This boilerplate will start with the uploading of files, after an authenticated user is logged into our app via AWS Cognito. If you don’t know how to do this with AWS Cognito, check out the previous tutorials. If your use case allows all users to modify files, then just make sure your S3 permissions match that. The code is otherwise the same, so let’s get started!
Amazon S3 is a raw key-value store of files, which means each file has a name, and a raw data value for that name. Technically this means we can store any type of file on S3, but there are some limitations as defined in their Amazon Web Service Licensing Agreement that are mostly restrictions regarding malicious activity. The maximum size of an individual file on S3 is 5 terabytes, and the max size of a single PUT request is 5 gigabytes. Aside from this, what we can store on S3 is limitless. In S3, folders are also objects but with a null-like value, as their purpose is for organization. S3 folders cannot be re-named, and if changed from private to public cannot be changed back. Unlike a typical file system, S3 has a flat hierarchy which means a file that resides inside a folder is technically on the same level as the folder — everything is one level deep. S3 simply uses filename prefixes to distinguish folder hierarchy. For example, a file called “panda.jpg” inside the folder “ChinaTrip” will actually have a filename “ChinaTrip/panda.jpg” in S3. This is Amazon’s simple but effective solution to having folder hierarchies while keeping the benefits of a simple 1-layer deep key-value store. That’s all for the briefing, let’s get started on the code!
The Code
In the boilerplate front-end, go to App/src/api/aws/aws_s3.js. What we first notice is that we are importing an S3 bucket name from App/src/api/aws/aws_profile.js. Make sure in aws_profile.js you are exporting a bucket name like so:
export const BUCKET_NAME = 'kangzeroos-s3-tutorial'
And then import it in App/src/api/aws/aws_cognito.js like so:
import {BUCKET_NAME} from './aws_profile'
Now lets continue on aws_cognito.js and run through the first function we will be using.
Create A User Album
Imagine your users upload photos for whatever purpose. You would want to organize the images that your users upload in folders that represent each user. This is the purpose of createUserS3Album() which creates an S3 folder named from its only argument albumName — in the case of this boilerplate and its integration with AWS Cognito, the albumName will be the user’s email. Let’s walk through the function.
export function createUserS3Album(albumName){ const p = new Promise((res, rej)=>{ AWS.config.credentials.refresh(function(){ const S3 = new AWS.S3() if (!albumName) { const msg = 'Please provide a valid album name' rej(msg) return } albumName = albumName.trim(); if (albumName.indexOf('/') !== -1) { const msg = 'Album names cannot contain slashes.' rej(msg) return }
const albumKey = encodeURIComponent(albumName) + '/'; const params = { Bucket: BUCKET_NAME, Key: albumKey } S3.headObject(params, function(err, data) { if (!err) { const msg = 'Album already exists.' res() return } if (err.code !== 'NotFound') { const msg = 'There was an error creating your album: ' + err.message rej() return } if(err){ const albumParams = { ...params, ACL: "bucket-owner-full-control", StorageClass: "STANDARD" } S3.putObject(params, function(err, data) { if (err) { const msg = 'There was an error creating your album: ' + err.message rej(msg) return } res('Successfully created album.'); }); } }); }) }) return p}
At a high level, this is the process. We first refresh the Amazon credentials that AWS Cognito provided for us. This is only needed in the case that your S3 bucket security is set up so that only logged in AWS Cognito users can upload files. If your use case allows for anyone to post, then you won’t need to refresh the Amazon credentials. In the boilerplate, createUserS3Album() is called each time a user logs in.
Next we instantiate the S3 object and check for the existence of an albumName. We continue by URI-encoding the albumName into albumKey, which is needed if albumName comes from an email address, as S3 will not accept characters like / and @ in a filename.
Finally we can take albumKey and BUCKET_NAME to call S3.headObject(). Inside headObject() we check if the albumKey already exists or if we get an error code. If all is good, then we call S3.putObject() with the albumKey. Upon successful creation of albumKey, we can resolve the promise and complete the function.
Upload Files to S3
Now let’s cover how to upload actual files. In the boilerplate we use images, but the same concepts apply to any file. The function requires 2 arguments: the albumName (which in the boilerplate is a user’s email), and an array of the files to be uploaded. Let’s walk through the process.
export function uploadImageToS3(email, files){ const p = new Promise((res, rej)=>{ if (!files.length || files.length == 0) { const msg = 'Please choose a file to upload first.' rej(msg) } AWS.config.credentials.refresh(function(){ const S3 = new AWS.S3()
const S3ImageObjs = [] let uploadedCount = 0
for(let f = 0; f<files.length; f++){ const file = files[f]; const fileName = file.name; const albumPhotosKey = encodeURIComponent(email) + '/'; const timestamp = new Date().getTime()/1000
const photoKey = albumPhotosKey + "--" + timestamp + "--" + fileName; S3.upload({ Bucket: BUCKET_NAME, Key: photoKey, Body: file, ACL: 'public-read' }, function(err, data) { if (err) { const msg = 'There was an error uploading your photo: '+ err.message rej(msg) return } const msg = 'Successfully uploaded photo: ' + fileName
S3ImageObjs.push({ photoKey: photoKey, url: data.Location }) uploadedCount++ if(uploadedCount==files.length){ res(S3ImageObjs) } }) } }) }) return p}
First we check that files actually has an array of items inside it. Then we again refresh the AWS credentials and instantiate the S3 object. Now we use a for-loop to loop through all the files and one by one upload them to S3. At the last file we resolve the promise with an array of all the uploaded files S3ImageObjs. So what is the for-loop doing?
Each file is named with albumName (which in this case is an URI-encoded email) as a prefix, then timestamped, and then appended with the files’ original filename. The end name is the photoKey. Then we call S3.upload() with the correct params, and upon successful upload, we push the result into the S3ImageObjs array. A successful upload will return an object with a Location property that is a string url for accessing that file. If we visit the Location url, we will see our uploaded images. One last thing to note is the ACL property in S3.upload(). ACL is set to ‘public-read’ so that the file is publicly accessible by all.
The Rest of The Stuff
Great, so we have file reading and posting (GET & POST) completed for our boilerplate. What about updating and deleting? Well, updating is a matter of replacing a previous file and follows a similar POST process. Deleting is a simple matter of calling S3.deleteObject() with the photoKey and bucket name.
const params = { Bucket: 'STRING_VALUE', Key: 'STRING_VALUE' };
s3.deleteObject(params, function(err, data) { if (err) console.log(err, err.stack); // an error occurred else console.log(data); // successful response });
And that’s it! The basics of Amazon S3 with coverage on security and auth-integration. For the majority of your usage cases, this will be all you need. That was pretty straightforward, and wow do we get a lot of benefit using a raw file storage over traditional file-systems on our main server. I hope this article has convinced you of S3's benefits and how to implement it in your own app.
See you in the next article of this series!
These methods were partially used in the deployment of renthero.ca