By Jayvardhan Reddy
Apache Sqoop is a data ingestion tool designed for efficiently transferring bulk data between Apache Hadoop and structured data-stores such as relational databases, and vice-versa.
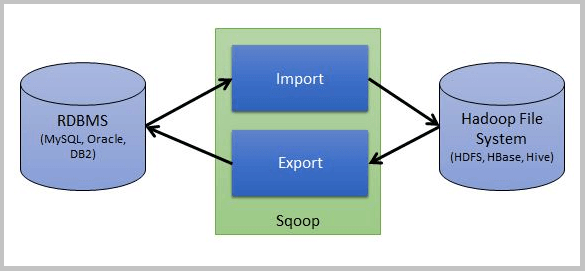
As part of this blog, I will be explaining how the architecture works on executing a Sqoop command. I’ll cover details such as the jar generation via Codegen, execution of MapReduce job, and the various stages involved in running a Sqoop import/export command.
Codegen
Understanding Codegen is essential, as internally this converts our Sqoop job into a jar which consists of several Java classes such as POJO, ORM, and a class that implements DBWritable, extending SqoopRecord to read and write the data from relational databases to Hadoop & vice-versa.
You can create a Codegen explicitly as shown below to check the classes present as part of the jar.
sqoop codegen \ -- connect jdbc:mysql://ms.jayReddy.com:3306/retail_db \ -- username retail_user \ -- password ******* \ -- table products
The output jar will be written in your local file system. You will get a Jar file, Java file and java files which are compiled into .class files:

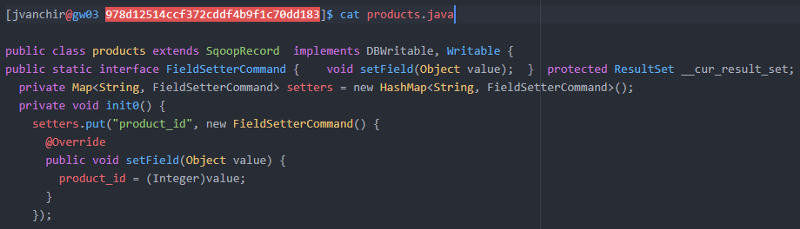
Let us see a snippet of the code that will be generated.
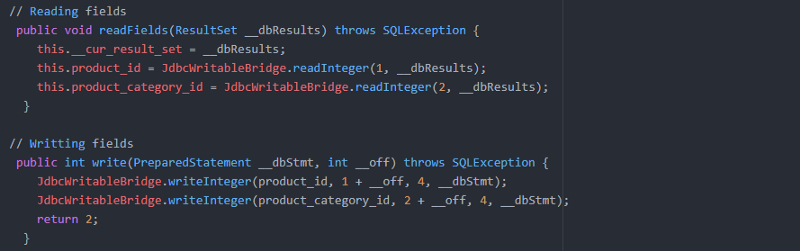
ORM class for table ‘products’ // Object-relational modal generated for mapping:
Setter & Getter methods to get values:
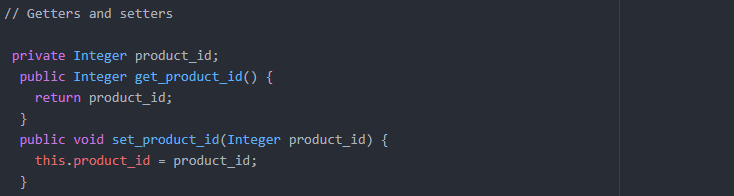
Internally it uses JDBC prepared statements to write to Hadoop and ResultSet to read data from Hadoop.
Sqoop Import
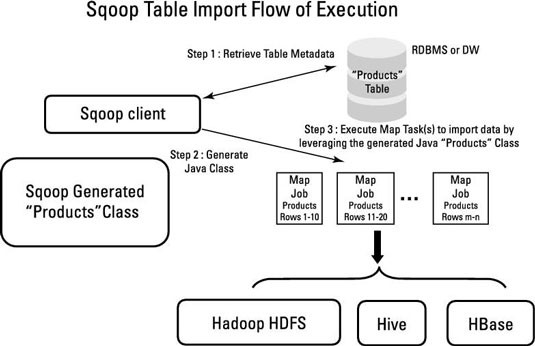
It is used to import data from traditional relational databases into Hadoop.
Let’s see a sample snippet for the same.
sqoop import \ -- connect jdbc:mysql://ms.jayReddy.com:3306/retail_db \ -- username retail_user \ -- password ******* \ -- table products \ -- warehouse-dir /user/jvanchir/sqoop_prac/import_table_dir \ -- delete-target-dir
The following steps take place internally during the execution of sqoop.
Step 1: Read data from MySQL in streaming fashion. It does various operations before writing the data into HDFS.
As part of this process, it will first generate code (typical Map reduce code) which is nothing but Java code. Using this Java code it will try to import.
- Generate the code. (Hadoop MR)
- Compile the code and generate the Jar file.
- Submit the Jar file and perform the import operations
During the import, it has to make certain decisions as to how to divide the data into multiple threads so that Sqoop import can be scaled.
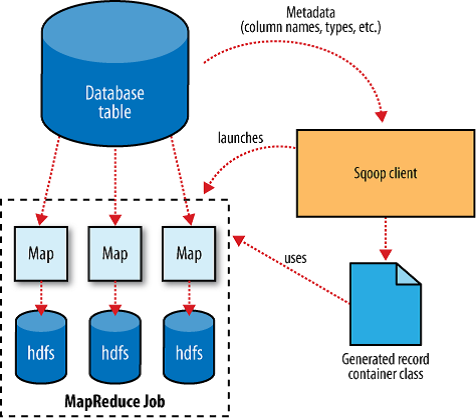
Step 2: Understand the structure of the data and perform CodeGen
Using the above SQL statement, it will fetch one record along with the column names. Using this information, it will extract the metadata information of the columns, datatype etc.
Step 3: Create the java file, compile it and generate a jar file
As part of code generation, it needs to understand the structure of the data and it has to apply that object on the incoming data internally to make sure the data is correctly copied onto the target database. Each unique table has one Java file talking about the structure of data.
This jar file will be injected into Sqoop binaries to apply the structure to incoming data.
Step 4: Delete the target directory if it already exists.
Step 5: Import the data

Here, it connects to a resource manager, gets the resource, and starts the application master.
To perform equal distribution of data among the map tasks, it internally executes a boundary query based on the primary key by default
to find the minimum and maximum count of records in the table.
Based on the max count, it will divide by the number of mappers and split it amongst each mapper.

It uses 4 mappers by default:
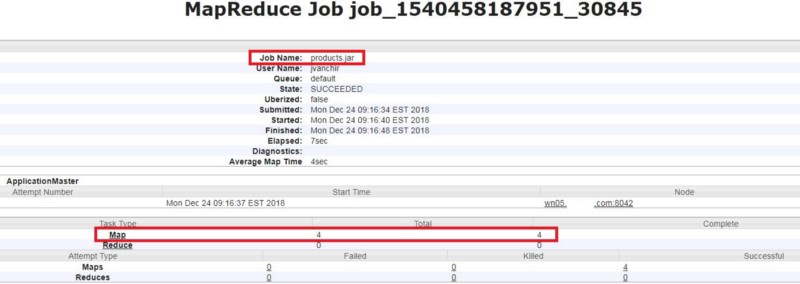
It executes these jobs on different executors as shown below:

The default number of mappers can be changed by setting the following parameter:
So in our case, it uses 4 threads. Each thread processes mutually exclusive subsets, that is each thread processes different data from the others.
To see the different values, check out the below:
Operations that are being performed under each executor nodes:

In case you perform a Sqooop hive import, one extra step as part of the execution takes place.
Step 6: Copy data to hive table

Sqoop Export
This is used to export data from Hadoop into traditional relational databases.
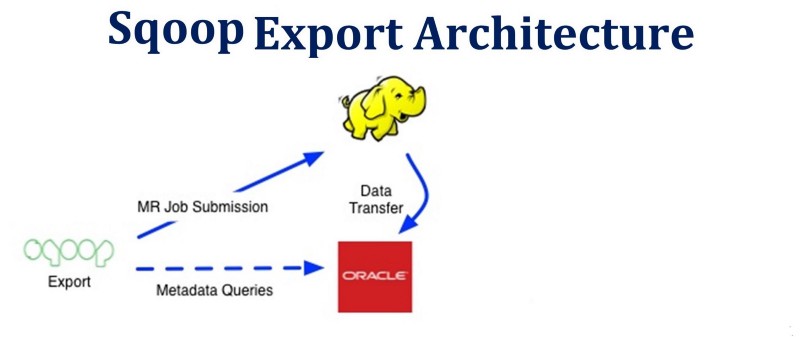
Let’s see a sample snippet for the same:
sqoop export \ -- connect jdbc:mysql://ms.jayReddy.com:3306/retail_export \ -- username retail_user \ -- password ******* \ -- table product_sqoop_exp \ -- export-dir /user/jvanchir/sqoop_prac/import_table_dir/products
On executing the above command, the execution steps (1–4) similar to Sqoop import take place, but the source data is read from the file system (which is nothing but HDFS). Here it will use boundaries upon block size to divide the data and it is internally taken care by Sqoop.
The processing splits are done as shown below:

After connecting to the respective database to which the records are to be exported, it will issue a JDBC insert command to read data from HDFS and store it into the database as shown below.
Now that we have seen how Sqoop works internally, you can determine the flow of execution from jar generation to execution of a MapReduce task on the submission of a Sqoop job.
Note: The commands that were executed related to this post are added as part of my GIT account.
Similarly, you can also read more here:
- Hive Architecture in Depth with code.
- HDFS Architecture in Depth with code.
If you would like too, you can connect with me on LinkedIn - Jayvardhan Reddy.
If you enjoyed reading this article, you can click the clap and let others know about it. If you would like me to add anything else, please feel free to leave a response ?