By Sanchit Gera
Network architectures based on the micro service pattern have gained quite some popularity in recent years. Micro services have emerged as a solution to large, unwieldy monolithic applications.
This design attempts to solve the problems that emerge when your codebase grows beyond a certain size, and it becomes increasingly difficult to maintain.
Small scale services were borne out of the necessity to scale rapidly while still keeping your code manageable. Netflix, Amazon, and Spotify are some of the larger and more interesting players moving towards this type of pattern. Let’s explore why.
What are microservices?
Defining microservices is tricky business. There is no set requirement or specification that your codebase should meet in order to be considered “micro.” Instead, developers and architects must adhere to a set of general ideas in order to come up with a system that works for them.
The microservice architectural style is an approach to developing a single application as a suite of small services, each running in its own process and communicating with lightweight mechanisms, often an HTTP resource API. Martin Fowler
In Building Microservices, Sam Newman lists two key ideas that must be kept in mind while designing these services: loose coupling and high cohesion. These admittedly sound like even more buzz words, but allow me to elaborate.
Loose Coupling
Ideally, you want the services to have little to no dependence amongst one another. Services should be changable and deployable independently, without requiring changes to other parts of the system.
Services must expose only the information that is absolutely necessary in order to prevent the apps that consume their data from binding too tightly to them. This makes it easier to roll out changes in the future.
High cohesion
High Cohesion can be thought of as a corollary to Loose Coupling. Cohesion refers to the idea that all the logic pertaining a particular entity in the system should be bundled together in a single place. This makes it easier to modify the behavior of a portion of the system, since it minimizes the number of places where code needs to be updated.
It’s important to bear in mind that there is nothing about a monolithic structure that would stop you from applying the same principles. Modularity is encouraged in any codebase. Large codebases have traditionally relied on the concepts of shared modules and libraries in order to enforce a similar degree of logical separation. Microservices go one step further, by making these boundaries more obvious and slightly harder to breach.
Inducing factors
In order to understand micro services, you should understand that there are some shortfalls in a traditional monolithic structure, which are the reasons that developers are shifting towards more loosely coupled services.
Technology Diversity
As your application grows in size, so do the number of features it implements and by extension, the number of technological requirements imposed on your system.
For example, some parts of your application may demand a specific library written in a specific language which just happens to be the right tool for it. Parts of your application may benefit from the statically typed, secure nature of Java. While other portions may be less demanding. Similarly, the optimal database may very well vary across the application.

This also provides a good opportunity to experiment with new languages and frameworks in a limited scope. Experimentation, in a way, becomes less risky since it is limited to only a handful of services which can be reverted back to their original states fairly quickly.
In general, in a monolithic application, the tools you choose typically end up being the “least common denominator,” rather than optimized for the task at hand.
There is, however, an downside to all of this. In practice, it is possible for the large number of frameworks and languages being employed by different services to itself turn into a mess. Moving developers between teams (typically one team per service) can be a nightmare if they aren’t familiar with the new stack.
Interestingly, Spotify — a major advocate of the microservice architecture pattern — have a zero tolerance policy when it comes to the variety of languages used on their production services. Essentially, every service being deployed to production must be written in Java and Java alone (thus invalidating this argument).
Nevertheless, technological diversity is a key advantage to a microservice based design, even if only used sparingly.
Fault Tolerance
The idea of fault tolerance is strongly related to the concept of loose coupling discussed previously. Teams should focus on making each service as independent as possible. This ensures that if one service goes down, it doesn’t affect the other services (except for the ones immediately depending on it).
As an end user, your experience may be degraded and limited, but the application should still remain functional. This is, in most cases, far better than crashing the entire application.
As an example, consider Amazon. Lets assume that Amazon is composed of a couple of different services, each handling a crucial part of the application.
- Inventory Service: Responsible for managing all the items that amazon sells, as well as their stock levels
- Order Service: Responsible for taking customer orders and dispatching the item
- Recommendation Service: Responsible for coming up with recommendations about products that a customer may be interested in
This is by no means a complete or accurate description of how Amazon is structured. But it works well for this example.
Consider the scenario where the recommendation service decides to fly off the handle and crash on us. Now, in a traditional monolithic application, this might lead to the shutdown of Amazon! Yikes!
In the present case, however, a user may be served up a page without any recommendations, while other parts of the application continue to function just as well. A sub-optimal experience, but still functional. Not bad!
Scalability
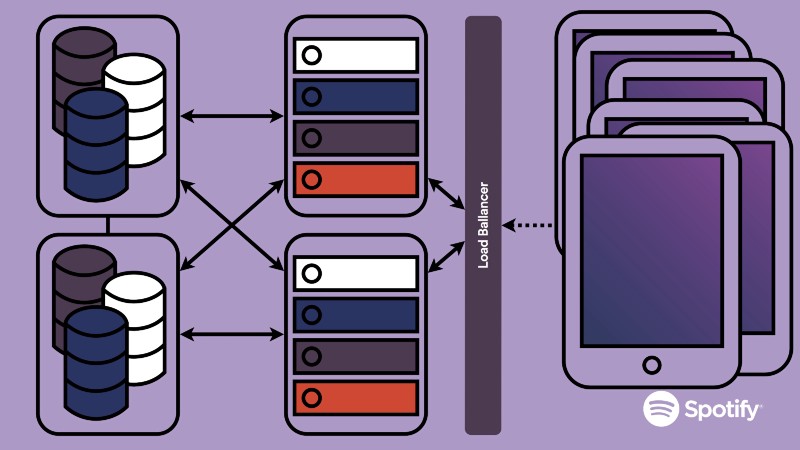
The issue of scalability is an immensely important one for a fast growing company. When you have a single gigantic application, not all parts of it are equally load intensive. Some may be responsible for more passive, mundane things such as serving static information, while others may be more intensive, requiring a lot of database interaction and/or computing power.
The problem with a monolithic codebase, then, is that regardless of the different types of operations it’s conducting, you need to scale the entire application up and down based on need. Since this isn’t an accurate representation of the actual demands on your system, it leads to huge amounts of wasted computing power and resources.
This is one of the issues microservices attempt to solve. Because functionality is separated into different “boxes”, each box can be scaled up or down independently, without affecting the rest of the system. And so you end up going from a system that looks like this:
to one that looks like this:
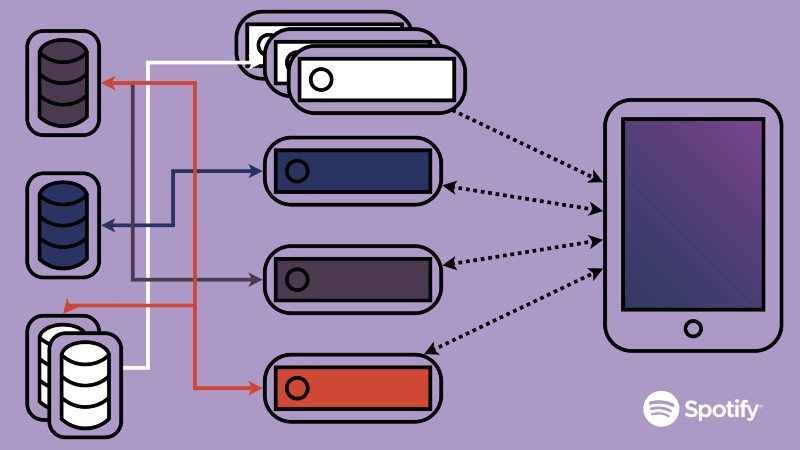
Voila!
Ease of deployment
Lastly, lets talk a little bit about how deploying these services would work. Given the sheer number of services being deployed, this may seem a bit like a counter argument at first. However, the key thing to remember is that any change in the behavior of a particular part of the application usually requires a change in one and preferably only one part of the application, isolated away into a microservice in this case.
When you have a small change, this difference boils down to redeploying a small service versus redeploying a million-line application. In practice, monolithic applications are seldom redeployed at that rate. As a result changes usually build up between releases, leading to bigger, more comprehensive releases. The sheer number of changes being deployed could itself be a potential risk.
But as always, there is a tradeoff involved here. Although microservices allow you to deploy changes rapidly, they necessitate all clients of your service to be in sync with your releases. This could be trivial if the number of services depending on your services is small, but in a larger organization this may not always be the case. A compromise may be reached, and you may very well end up supporting previous versions of your microservices for clients that depend on them, until they get around to upgrading!
In this post, I have only scratched the surface. There are several other ideas that you should consider before going down the microservice route. Concepts like data decentralization and service discovery are central to a robust architecture, and require more study. (Maybe a future post!)
I’m fairly new to this style of development myself. If there is something I’ve left out or misrepresented, please do let me know in the comments :)
If this is a topic you want to learn more about, here are some resources that I found useful while coming up with this post: