

API stands for Application Programming Interface. The “I” in API is the key part that explains its purpose.
The interface is what the software presents to other humans or programs, allowing them to interact with it.
A good analogy for an interface is a remote control. Imagine you have a universal remote that can control your TV, lights, and fan.
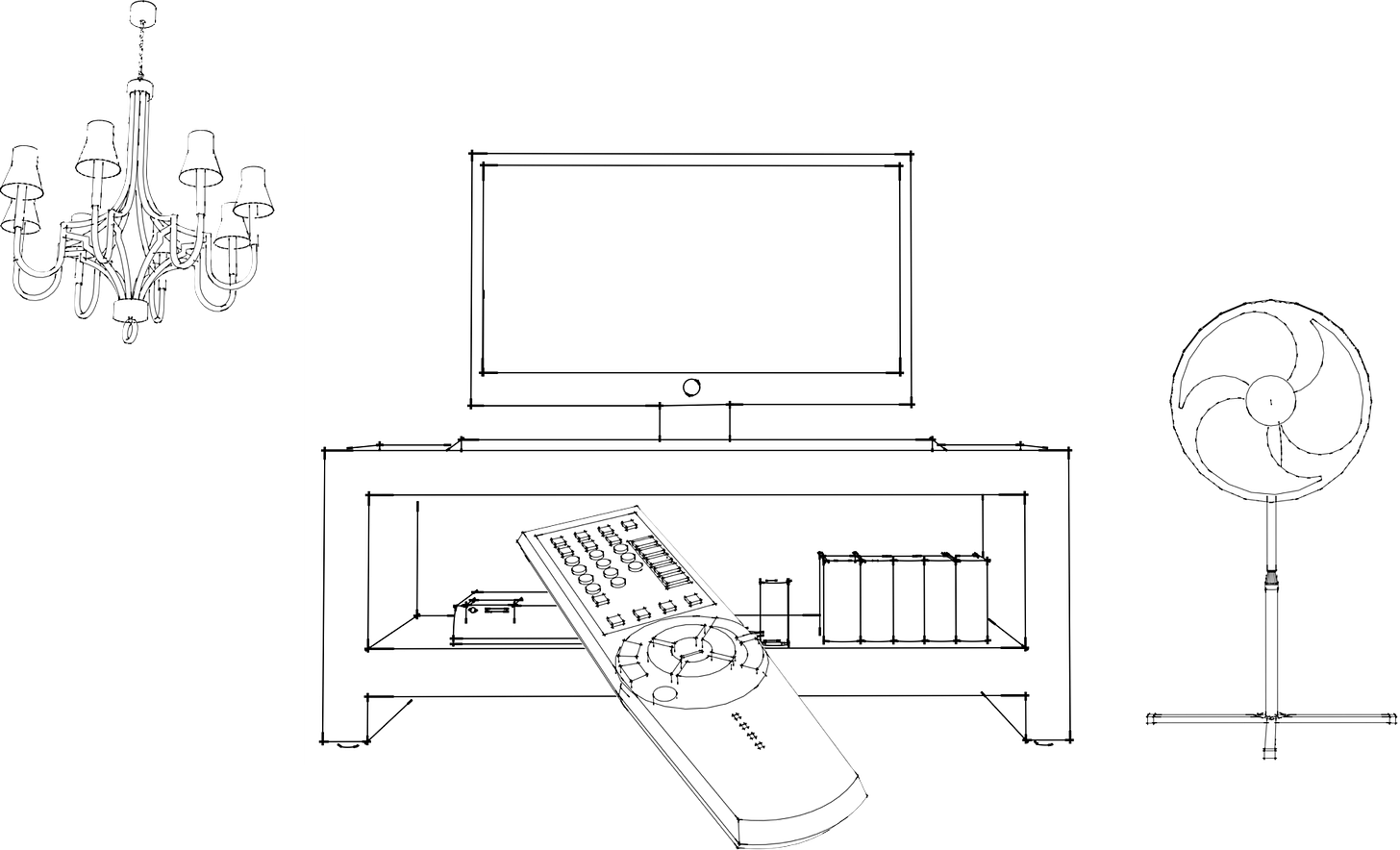
Image showing a remote control and a TV, light fixture, and fan.
Let’s break down what a universal remote control can do:
The remote control has various buttons, each serving a different purpose. One button might change the channel, while another can dim the lights of the chandelier, and another can turn on the fan.
When you press a button, it sends a specific signal via infrared, bluetooth, or wifi to the object you are controlling, instructing it to perform a particular action.
The key thing about the remote is that it allows you to interact with the TV, chandelier, and the fan without understanding the internal workings of these objects. All that complexity is abstracted away from you. You simply press a button, and you get a response that you can observe straight away.
APIs work in a similar way.
APIs can have various endpoints, each designed to perform a specific action. One endpoint might retrieve data, while another updates or deletes it.
When you send a request to an endpoint, it communicates with the server using HTTP methods – GET, POST, PUT, DELETE to instruct it to perform a particular action (like retrieving, sending, updating, or deleting data).
The key thing about APIs, as with remote controls, is that APIs abstract away the inner workings of the server and the database behind the API. The API allows users, developers and applications to interact with a software application or platform without needing to understand its internal code or database structure. You simply send a request, the server processes it and provides a response.
This analogy only holds true for so long, as APIs are more complex than a remote control. But the basic principles of operation between an API and a universal remote are quite similar.
This article will explain API integration patterns, which can be split into two broad groups: Request-response (REST, RPC & GraphQL) and event driven APIs (Polling, WebSockets & WebHooks).
Request-Response Integration
In a request-response integration, the client initiates the action by sending a request to the server and then waits for a response.
Different patterns of the request-response integration exist, but at a high level, they all conform to the same rule of the client initiating a request and waiting for a response from the server.
1. REST
Rest stands for Representational State Transfer – the acronym is a combination of the first one or two letters from these three words. This is the simplest and most popular form of a request-response integration.
REST APIs use a stateless, client-server communication model, wherein each message contains all the information necessary to understand and process the message.
REST is all about resources. Resources are entities that the API exposes, which can be accessed and manipulated using URL paths.
To understand REST APIs, consider the following analogy. Imagine you go into a restaurant to order some food. The menu is extensive and items are categorically organised. Each item on the menu can be equated to a resource.
First, you call the waiter to get their attention, then you place an order. Each request receives a response, before you proceed with another request, like ordering a dish.
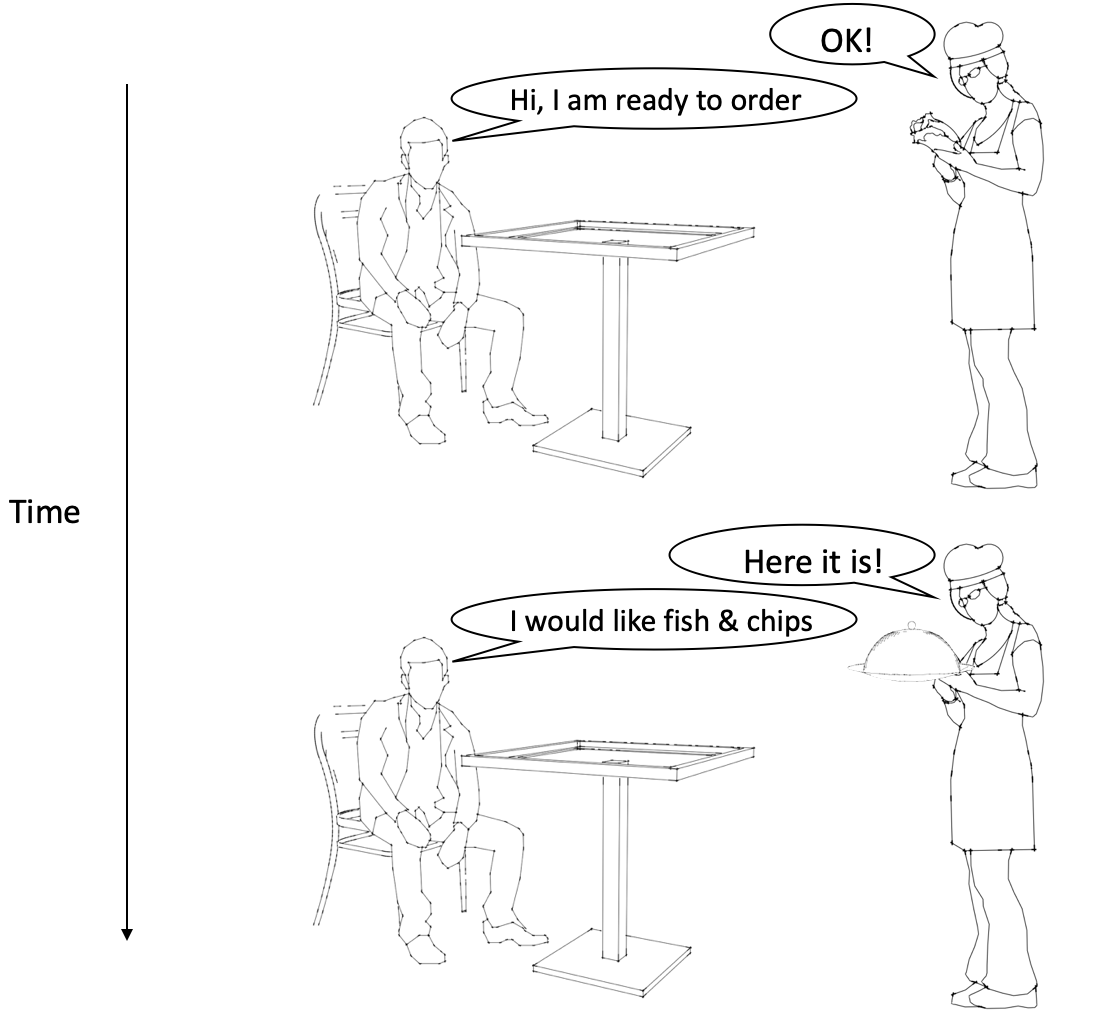
Restaurant analogy for REST API
In REST API terms, the client initiates requests to the server by specifying exactly what it wants using HTTP methods (such as GET, POST, PUT, DELETE) on specific URLs (the menu items). Each interaction is stateless, meaning that each request from the client to the server must contain all the information needed to understand and process the request.
The server then processes the request and returns the appropriate response – in our analogy, bringing the ordered item to the table.
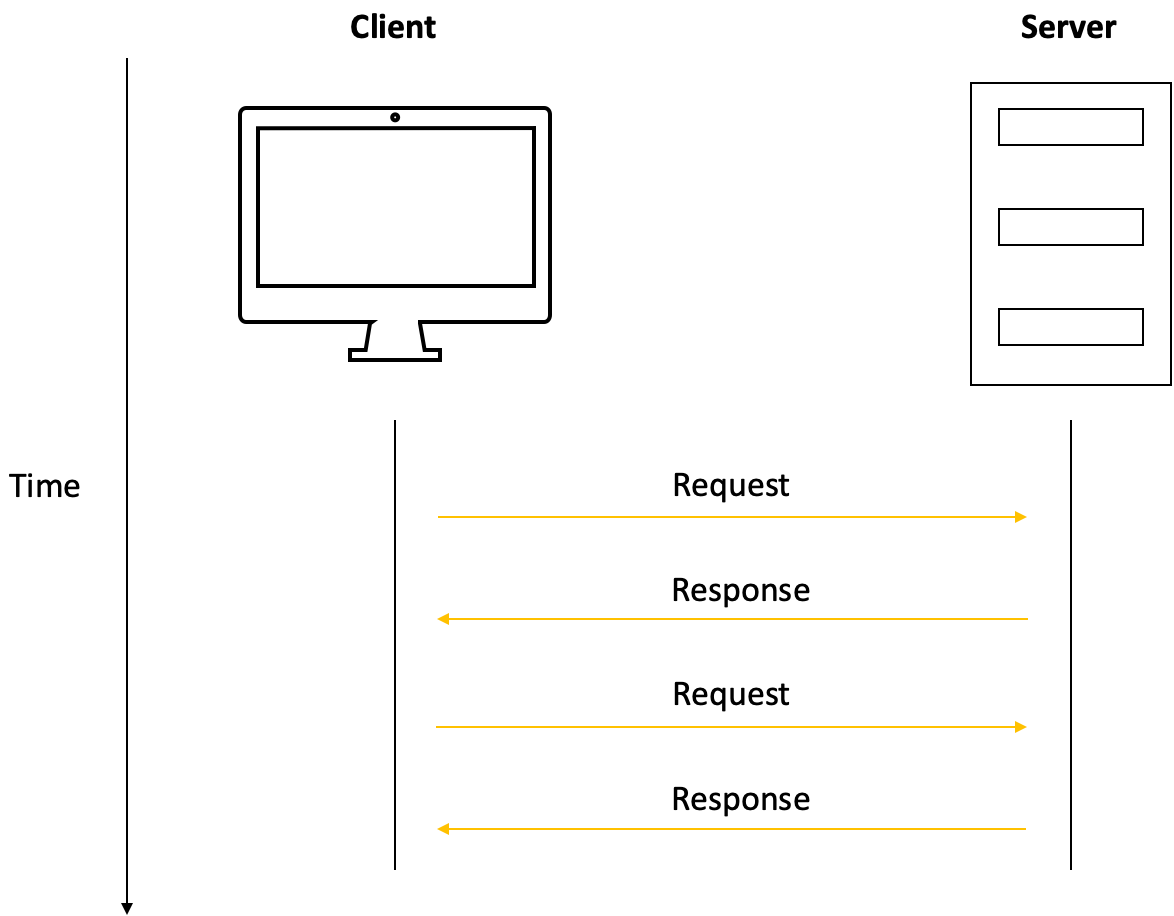
Simple sequence diagram for REST API
2. RPC
RPC stands for Remote Procedure Call. Unlike REST APIs which are all about resources, RPC is all about actions. With RPC, the client executes a block of code on the server
Think of a restaurant without a menu. There is no dish you can request in this restaurant. Instead, you request a specific action to be performed by the restaurant.
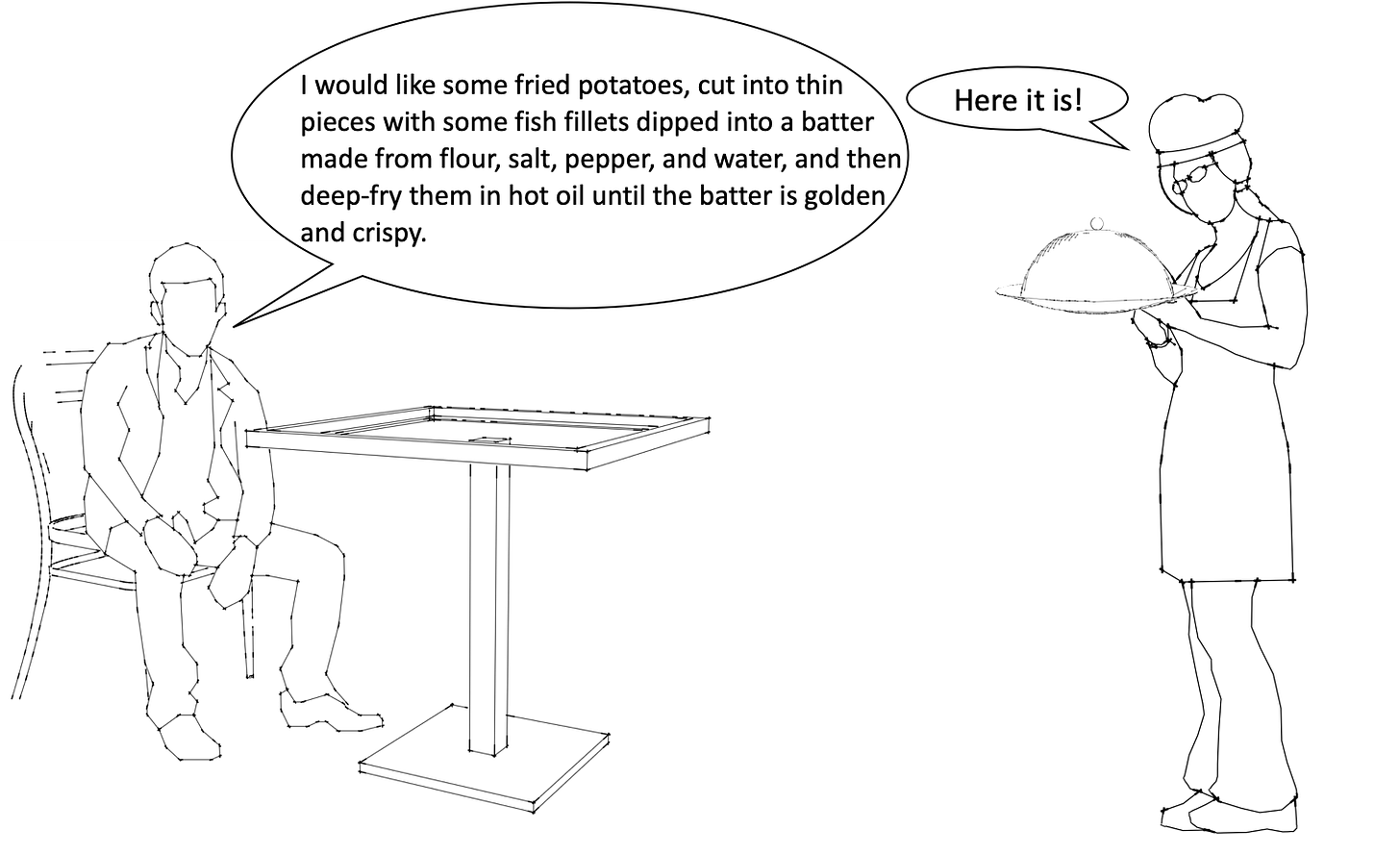
Restaurant analogy for RPC
With a REST API, the guest would have simply asked for some fish and chips. With RPC, they have to give instructions on what they want the kitchen to prepare.
In the RPC pattern, the client calls a specific procedure on the server and waits for the result. The procedure to prepare and what gets prepared are tightly bound together. This might give the client very specific and tailored results, but lacks the flexibility and ease of use of REST.
There is a reason most restaurants use menus, instead of following the custom requests of their customers. This partly explains why RPC is a less popular integration pattern compared to REST.
3. GraphQL
With GraphQL, the client specifies exactly what data it needs, which can include specific fields from various resources. The server processes this query, retrieves the exact data, and returns it to the client.
This enables the client to have a high degree of flexibility and only retrieve exactly the data it needs. It also requires the server to be capable of handling more complex and unique queries.
In this way, GraphQL is a more customisable form of REST. You still deal with resources (unlike actions in RPC) but you can customise how you want the resource returned to you.
Think of a restaurant that allows you to customise your own dish by specifying exact quantities or ingredients you want.

Restaurant analogy for GraphQL
This may look similar to the RPC pattern, but notice that the customer is not saying how the food should be made, they're just customising their order by removing some ingredients (no salt) and reducing the number of some items (two pieces of fish instead of four).
One of the drawbacks of GraphQL is that it adds complexity to the API since the server needs to do additional processing to parse complex queries. This additional complexity would also apply to the restaurant analogy, since each order would need to be customised to the guest.
GraphQL has one clear benefit over REST and RPC. Since clients can specify exactly what they need, the response payload sizes are typically smaller, which means faster response times.
Event Driven Integration
This integration pattern is ideal for services with fast changing data.
Some of these integration patterns are also asynchronous and initiated by the server, unlike the request-response patterns which are synchronous and initiated by the client.
1. Polling
Let’s bring back the restaurant analogy. When you order food, it will take some time for it to be prepared.
You can get updates on your order by asking the waiter if it is ready yet. The more frequently you ask, the closer you will be to having real-time information about your order.
This, however, puts unnecessary strain on the waiter since they have to constantly check the status of your order and have them update you whenever you ask.
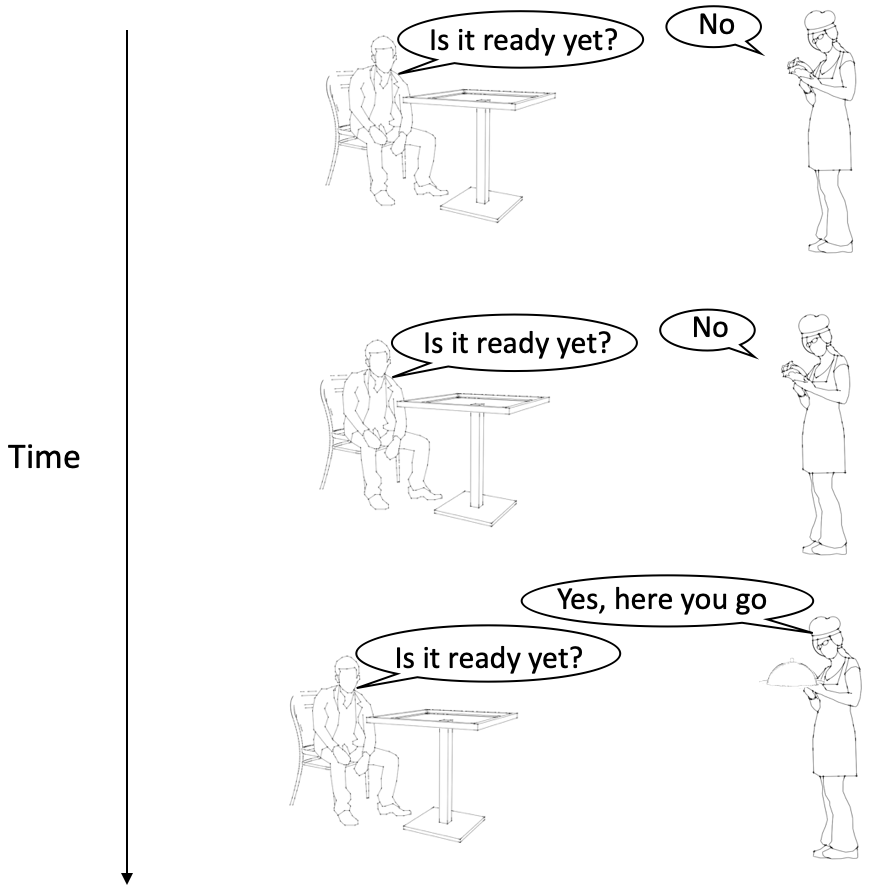
Restaurant analogy for polling
Polling is when the client continuously asks the server if there is new data available, with a set frequency. It's not efficient because many requests may return no new data, thus unnecessarily consuming resources.
The more frequently you poll (make requests) the closer the client gets to real-time communication with the server.
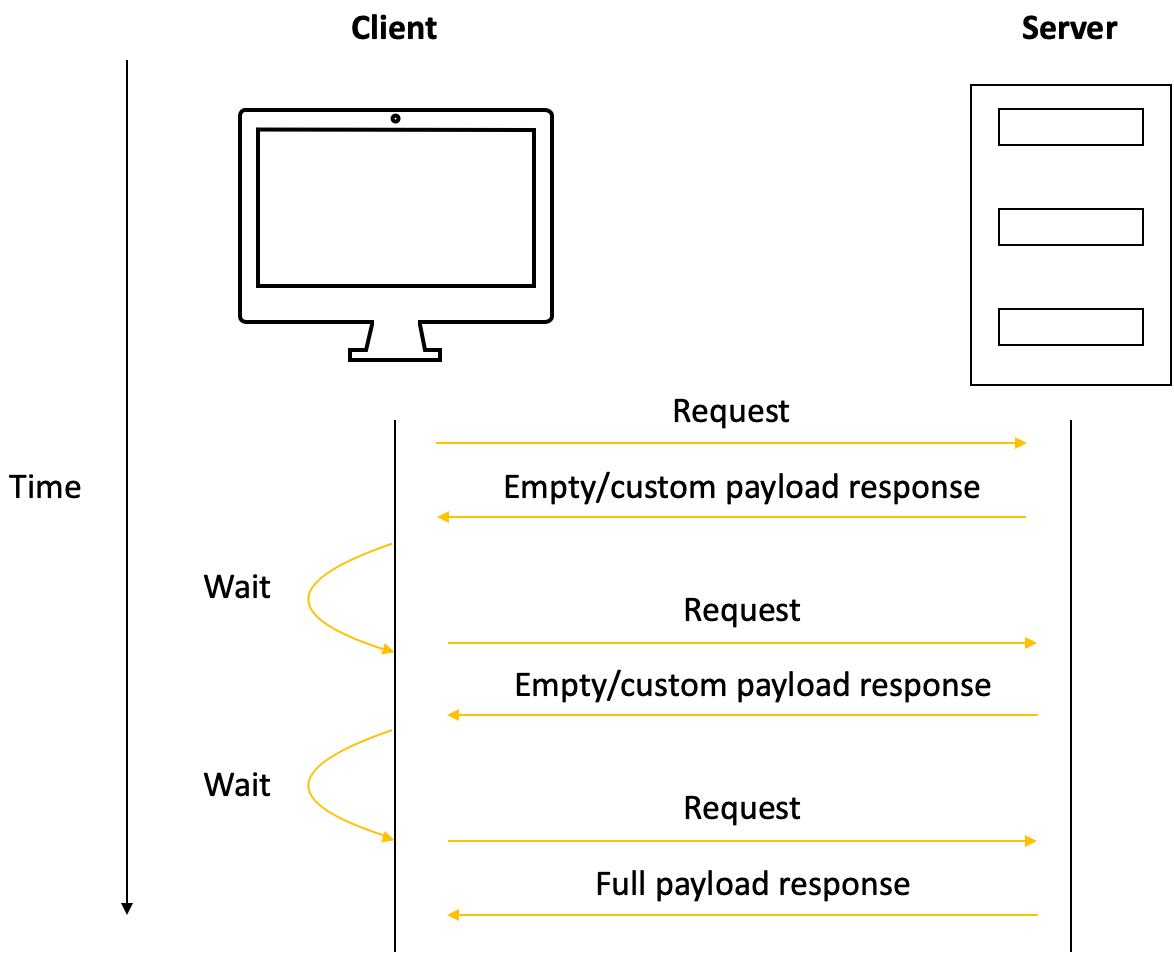
Simple sequence diagram showing polling in action
Most of the requests during polling are wasted, since they only return something useful to the client once there is a change on the server.
There is, however, another version of polling called long polling. With long polling, the waiter does not respond to the guest straightaway about the status of the order. Instead, the waiter only responds if there is an update.
Naturally, this only works if the guest and the waiter agree beforehand that a slow response from the waiter does not mean that the waiter is being rude and the guest is being ignored.
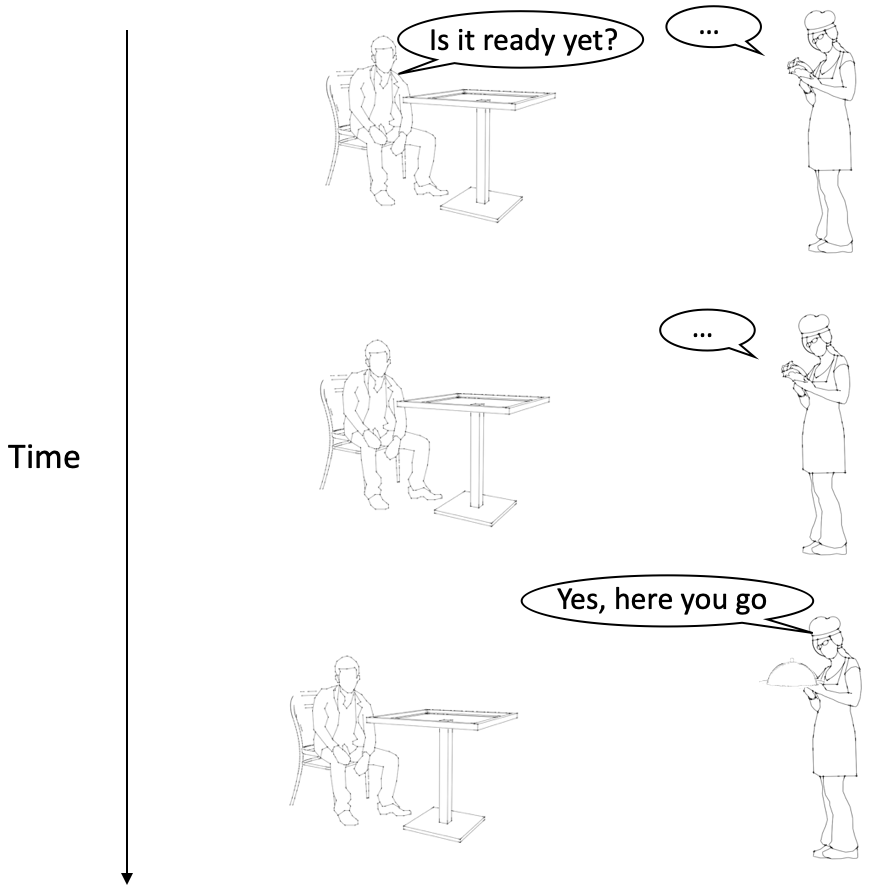
Restaurant analogy for long polling
With long polling, the server does not respond to the client immediately. It waits until something has changed before responding.
As long as the client and server agree that the server will hold on to the client’s request, and the connection between the client and server remains open, this pattern works and can be more efficient than simply polling.
These two assumptions for long polling may be unrealistic, though – the server can lose the client's request and/or the connection can be broken.
To address these limitations, long polling adds extra complexity to the process by requiring a directory of which server contains the connection to the client, which is used to send data to the client whenever the server is ready.
Standard polling on the other hand can remain stateless, making it more fault tolerant and scalable.
2. WebSockets
WebSockets provide a persistent, two-way communication channel between the client and server. Once a WebSocket connection is established, both parties can communicate freely, which enables real-time data flows and is more resource-efficient than polling.
Using the restaurant analogy again, a guest orders a meal and then establishes a dedicated communication channel with the waiter so they can freely communicate back and forth about updates or changes to the order until the meal is ready. This means the waiter can also initiate the communication with the guest, which is not the case for the other integration patterns mentioned so far.
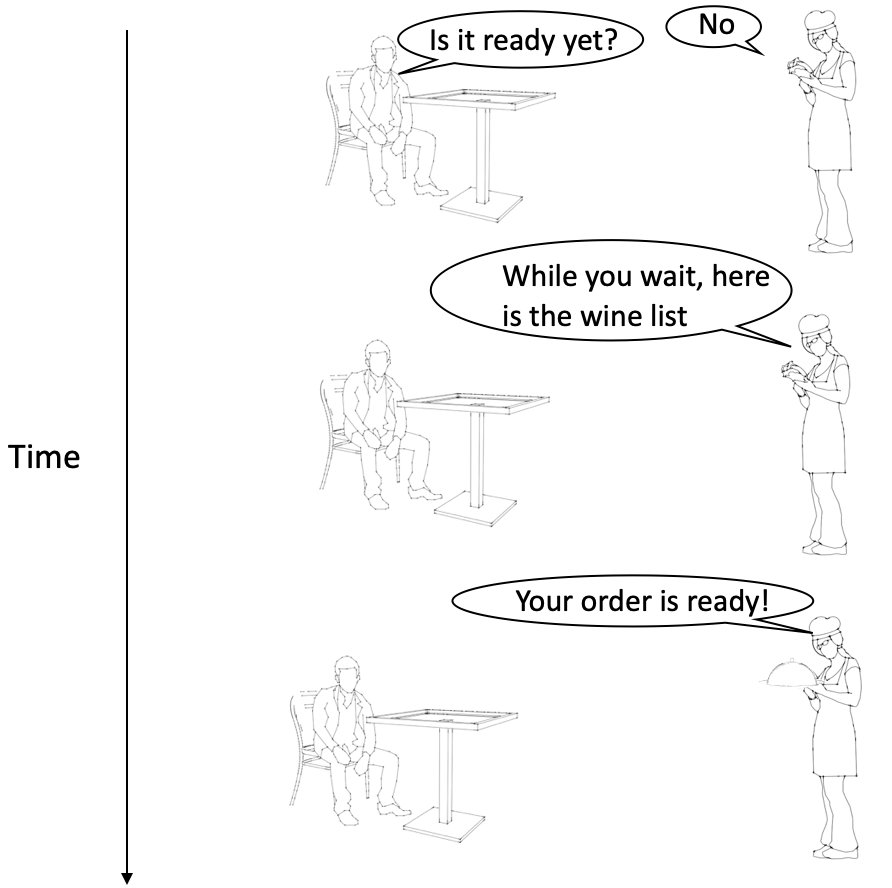
Restaurant analogy for WebSockets
WebSockets are similar to long polling. They both avoid the wasteful requests of polling, but WebSockets have the added benefit of having a persistent connection between the client and the server.
WebSockets are ideal for fast, live streaming data, like real-time chat applications. The downside of WebSockets is that the persistent connection consumes bandwidth, so may not be ideal for mobile applications or in areas with poor connectivity
3. WebHooks
WebHooks allow the server to notify the client when there's new data available. The client registers a callback URL with the server and the server sends a message to that URL when there is data to send.
With WebHooks, the client sends requests as usual, but can also listen for and receive requests like a server.
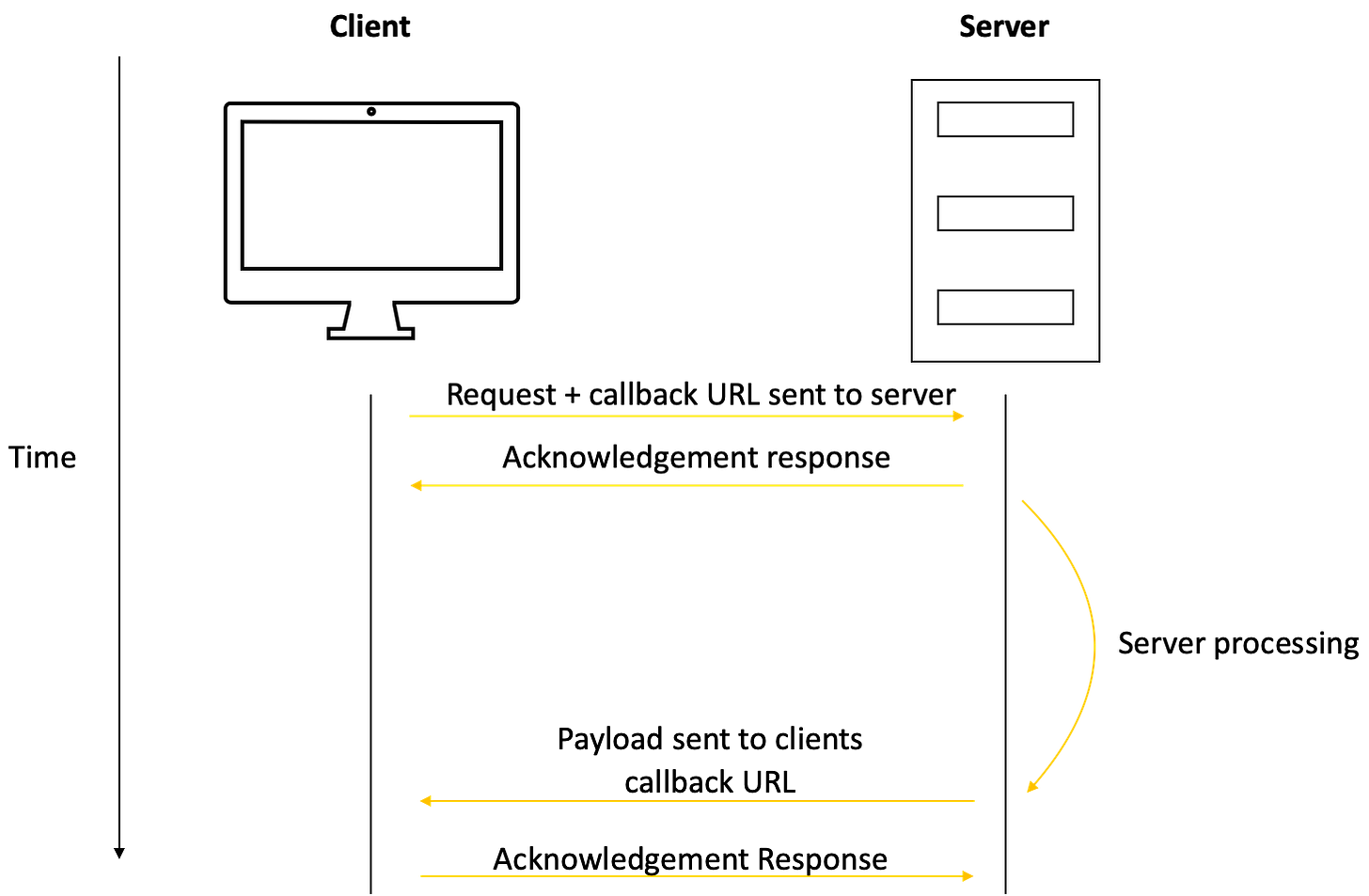
Simple sequence diagram showing WebHooks in action
Using the restaurant analogy, when the guest orders a meal, they give the waiter a bell (analogous to the callback URL). The waiter goes to the kitchen and rings the bell as soon as the meal is ready. This allows the client to know, in real-time, about the progress of his order.
WebHooks are superior to polling because you get real-time updates from the server once something changes, without having to make frequent, wasteful requests to the server about that change.
They're also superior to long polling because long polling can consume more client and server resources as it involves keeping connections open, potentially resulting in many open connections.
Bringing it Together
In conclusion, APIs are crucial tools in software development, allowing users and applications to interact with software without understanding its inner workings.
They come in different integration patterns, such as REST, RPC, GraphQL, Polling, WebSockets, and WebHooks.
If you need a simple request-response integration, then REST, RPC or GraphQL could be ideal. For real-time or near-real-time applications, polling, WebScokets, or WebHooks are ideal.
As with any design problem, the right choice depends on the business case and what tradeoffs you are willing to tolerate.