By Megan Risdal
Kaggle recently gave data scientists the ability to add a GPU to Kernels (Kaggle’s cloud-based hosted notebook platform). I knew this would be the perfect opportunity for me to learn how to build and train more computationally intensive models.
With Kaggle Learn, Keras documentation, and cool natural language data from freeCodeCamp I had everything I needed to advance from random forests to recurrent neural networks.
In this blog post, I’ll show you how I used text from freeCodeCamp’s Gitter chat logs dataset published on Kaggle Datasets to train an LSTM network which generates novel text output.
You can find all of my reproducible code in this Python notebook kernel.
Now that you can use GPUs in Kernels — Kaggle’s, cloud-based hosted notebook platform— with 6 hours of run time, you can train much more computationally intensive models than ever before on Kaggle.
I’ll use a GPU to train the model in this notebook. (You can request a GPU for your session by clicking on the “Settings” tab from a kernel editor.)
import tensorflow as tfprint(tf.test.gpu_device_name())# See https://www.tensorflow.org/tutorials/using_gpu#allowing_gpu_memory_growthconfig = tf.ConfigProto()config.gpu_options.allow_growth = True
I’ll use text from one of the channel’s most prolific user ids as the training data. There are two parts to this notebook:
- Reading in, exploring, and preparing the data
- Training the LSTM on a single user id’s chat logs and generating novel text as output
You can follow along by simply reading the notebook or you can fork it (click “Fork notebook”) and run the cells yourself to learn what each part is doing interactively. By the end, you’ll learn how to format text data as input to a character-level LSTM model implemented in Keras and in turn use the model’s character-level predictions to generate novel sequences of text.
Before I get into the code, what is an LSTM (“Long Short-Term Memory”) network anyway?
In this tutorial, we’ll take a hands-on approach to implementing this flavor of recurrent neural network especially equipped to handle longer distance dependencies (including ones you get with language) in Keras, a deep learning framework.
If you want to review more of the theoretical underpinnings, I recommend that you check out this excellent blog post, Understanding LSTM Networks by Christopher Olah.
Part one: Data Preparation
In part one, I’ll first read in the data and try to explore it enough to give you a sense of what we’re working with. One of my frustrations with following non-interactive tutorials (such as static code shared on GitHub) is that it’s often hard to know how the data you want to work with differs from the code sample. You have to download it and compare it locally which is a pain.
The two nice things about following this tutorial using Kernels is that a) I’ll try to give you glimpses into the data at every significant step; and 2) you can always fork this notebook and ?boom? you’ve got a copy of my environment, data, Docker image, and all with no downloads or installs necessary whatsoever. Especially if you have experience installing CUDA to use GPUs for deep learning, you’ll appreciate how wonderful it is to have an environment already setup for you.
Read in the data
import pandas as pdimport numpy as np# Read in only the two columns we need chat = pd.read_csv('../input/freecodecamp_casual_chatroom.csv', usecols = ['fromUser.id', 'text'])
# Removing user id for CamperBotchat = chat[chat['fromUser.id'] != '55b977f00fc9f982beab7883'] chat.head()

Looks good!
Explore the data
In my plot below, you can see the number of posts from the top ten most active chat participants by their user id in freeCodeCamp’s Gitter:
import matplotlib.pyplot as pltplt.style.use('fivethirtyeight')f, g = plt.subplots(figsize=(12, 9))chat['fromUser.id'].value_counts().head(10).plot.bar(color="green")g.set_xticklabels(g.get_xticklabels(), rotation=25)plt.title("Most active users in freeCodeCamp's Gitter channel")plt.show(g)
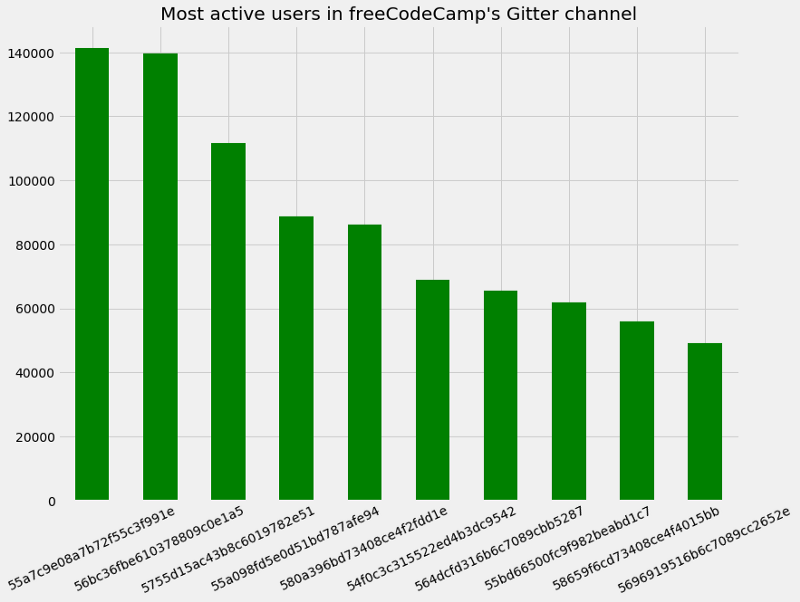
So, userid 55a7c9e08a7b72f55c3f991e is the most active user in the channel with over 140,000 messages. We'll use their messages to train the LSTM to generate novel 55a7c9e08a7b72f55c3f991e-like sentences. But first, let's take a look at the first few messages from 55a7c9e08a7b72f55c3f991e to get a sense for what they're chatting about:
chat[chat['fromUser.id'] == "55a7c9e08a7b72f55c3f991e"].text.head(20)
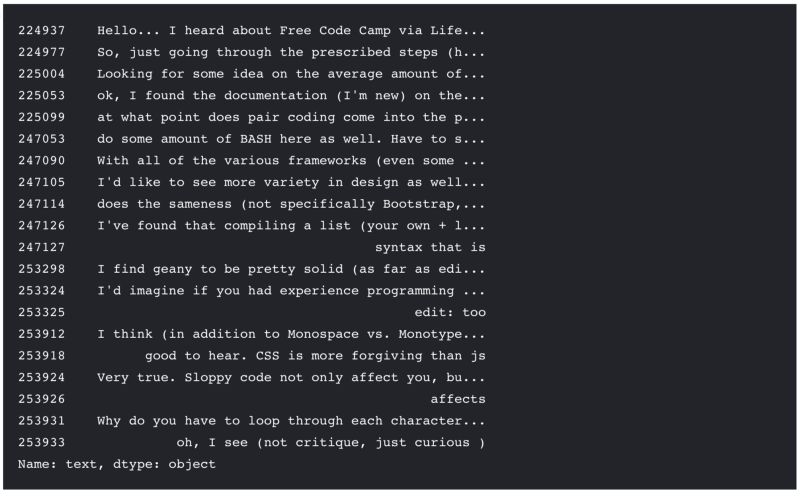
I see words and phrases like “documentation”, “pair coding”, “BASH”, “Bootstrap”, “CSS”, etc. And I can only assume the sentence starting “With all of the various frameworks…” is referring to JavaScript. Yep, sounds like they’re on-topic as far as freeCodeCamp goes. So we’ll expect our novel sentences to look roughly like this if we’re successful.
Prepare sequence data for input to LSTM
Right now we have a dataframe with columns corresponding to user ids and message text where each row corresponds to a single message sent. This is pretty far from the 3D shape the input layer of our LSTM network requires: model.add(LSTM(batch_size, input_shape=(time_steps, features))) where batch_size is the number of sequences in each sample (can be one or more), time_steps is the size of observations in each sample, and features is the number of possible observable features (i.e., characters in our case).
So how do we get from a dataframe to sequence data in the correct shape? I’ll break it into three steps:
- Subset the data to form a corpus
- Format the corpus from #1 into arrays of semi-overlapping sequences of uniform length and next characters
- Represent the sequence data from #2 as sparse boolean tensors
Subset the data to form a corpus
In the next two cells, we’ll grab only messages from 55a7c9e08a7b72f55c3f991e ('fromUser.id' == '55a7c9e08a7b72f55c3f991e') to subset the data and collapse the vector of strings into a single string. Since we don't care if our model generates text with correct capitalization, we use tolower(). This gives the model one less dimension to learn.
I’m also just going to use the first 20% of the data as a sample since we don’t need more than that to generate halfway decent text. You can try forking this kernel and experimenting with more (or less) data if you want.
user = chat[chat['fromUser.id'] == '55a7c9e08a7b72f55c3f991e'].textn_messages = len(user)n_chars = len(' '.join(map(str, user)))print("55a7c9e08a7b72f55c3f991e accounts for %d messages" % n_messages)print("Their messages add up to %d characters" % n_chars)

sample_size = int(len(user) * 0.2)user = user[:sample_size]user = ' '.join(map(str, user)).lower()user[:100] # Show first 100 characters

Format the corpus into arrays of semi-overlapping sequences of uniform length and next characters
The rest of the code used here is adapated from this example script, originally written by François Chollet (author of Keras and Kaggler), to prepare the data in the correct format for training an LSTM. Since we’re training a character-level model, we relate unique characters (such as “a”, “b”, “c”, …) to numeric indices in the cell below. If you rerun this code yourself by clicking “Fork Notebook” you can print out all of the characters used.
chars = sorted(list(set(user)))print('Count of unique characters (i.e., features):', len(chars))
char_indices = dict((c, i) for i, c in enumerate(chars))indices_char = dict((i, c) for i, c in enumerate(chars))

This next cell step gives us an array, sentences, made up of maxlen (40) character sequences chunked in steps of 3 characters from our corpus user, and next_chars, an array of single characters from user at i + maxlen for each i. I've printed out the first 10 strings in the array so you can see we're chunking the corpus into partially overlapping, equal length "sentences."
maxlen = 40step = 3sentences = []next_chars = []for i in range(0, len(user) - maxlen, step): sentences.append(user[i: i + maxlen]) next_chars.append(user[i + maxlen])print('Number of sequences:', len(sentences), "\n")print(sentences[:10], "\n")print(next_chars[:10])

You can see how the next character following the first sequence 'hi folks. just doing the new signee stuf' is the character f to finish the word "stuff". And the next character following the sequence 'folks. just doing the new signee stuff. ' is the character h to start the word "hello". In this way, it should be clear now how next_chars is the "data labels" or ground truth for our sequences in sentences and our model trained on this labeled data will be able to generate new next characters as predictions given sequence input.
Represent the sequence data as sparse boolean tensors
The next cell will take a few seconds to run if you’re following along interactively in the kernel. We’re creating a sparse boolean tensors x and y encoding character-level features from sentences and next_chars to use as inputs to the model we train. The shape we end up with will be: input_shape=(maxlen, len(chars)) where maxlen is 40 and len(chars) is the number of features (i.e., unique count of characters from our corpus).
x = np.zeros((len(sentences), maxlen, len(chars)), dtype=np.bool)y = np.zeros((len(sentences), len(chars)), dtype=np.bool)for i, sentence in enumerate(sentences): for t, char in enumerate(sentence): x[i, t, char_indices[char]] = 1 y[i, char_indices[next_chars[i]]] = 1
Part two: Modeling
In part two, we do the actual model training and text generation. We’ve explored the data and reshaped it correctly so we that we can use it as an input to our LSTM model. There are two sections to this part:
- Defining an LSTM network model
- Training the model and generating predictions
Defining an LSTM network model
Let’s start by reading in our libraries. I’m using Keras which is a popular and easy-to-use interface to a TensorFlow backend. Read more about why to use Keras as a deep learning framework here. Below you can see the models, layers, optimizers, and callbacks we’ll be using.
from keras.models import Sequentialfrom keras.layers import Dense, Activationfrom keras.layers import LSTMfrom keras.optimizers import RMSpropfrom keras.callbacks import LambdaCallback, ModelCheckpointimport randomimport sysimport io

In the cell below, we define the model. We start with a sequential model and add an LSTM as an input layer. The shape we define for our input is identical to our data by this point which is exactly what we need. I’ve selected a batch_size of 128 which is the number of samples, or sequences, our model looks at during training before updating. You can experiment with different numbers here if you want. I'm also adding a dense output layer. Finally, we'll use add an activation layer with softmax as our activation function as we're in essence doing multiclass classification to predict the next character in a sequence.
model = Sequential()model.add(LSTM(128, input_shape=(maxlen, len(chars))))model.add(Dense(len(chars)))model.add(Activation('softmax'))
Now we can compile our model. We’ll use RMSprop with a learning rate of 0.1 to optimize the weights in our model (you can experiment with different learning rates here) and categorical_crossentropy as our loss function. Cross entropy is the same as log loss commonly used as the evaluation metric in binary classification competitions on Kaggle (except in our case there are more than two possible outcomes).
optimizer = RMSprop(lr=0.01)model.compile(loss='categorical_crossentropy', optimizer=optimizer)
Now our model is ready. Before we feed it any data, the cell below defines a couple of helper functions with code modified from this script. The first one, sample(), samples an index from an array of probabilities with some temperature. Quick pause to ask, what is temperature exactly?
Temperature is a scaling factor applied to the outputs of our dense layer before applying the
softmaxactivation function. In a nutshell, it defines how conservative or "creative" the model's guesses are for the next character in a sequence. Lower values oftemperature(e.g.,0.2) will generate "safe" guesses whereas values oftemperatureabove1.0will start to generate "riskier" guesses. Think of it as the amount of surpise you'd have at seeing an English word start with "st" versus "sg". When temperature is low, we may get lots of "the"s and "and"s; when temperature is high, things get more unpredictable.
Anyway, so the second is defining a callback function to print out predicted text generated by our trained LSTM at the first and then every subsequent fifth epoch with five different settings of temperature each time (see the line for diversity in [0.2, 0.5, 1.0, 1.2]: for the values of temperature; feel free to tweak these, too!). This way we can fiddle with the temperature knob to see what gets us the best generated text ranging from conservative to creative. Note that we're using our model to predict based on a random sequence, or "seed", from our original subsetted data, user: start_index = random.randint(0, len(user) - maxlen - 1).
Finally, we name our callback function generate_text which we'll add to the list of callbacks when we fit our model in the cell after this one.
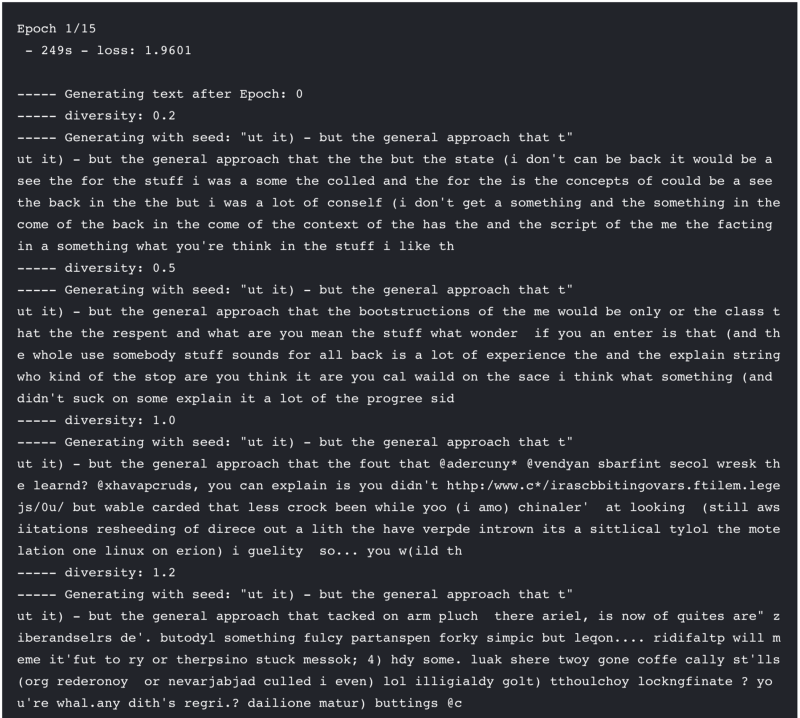
def sample(preds, temperature=1.0): # helper function to sample an index from a probability array preds = np.asarray(preds).astype('float64') preds = np.log(preds) / temperature exp_preds = np.exp(preds) preds = exp_preds / np.sum(exp_preds) probas = np.random.multinomial(1, preds, 1) return np.argmax(probas)def on_epoch_end(epoch, logs): # Function invoked for specified epochs. Prints generated text. # Using epoch+1 to be consistent with the training epochs printed by Keras if epoch+1 == 1 or epoch+1 == 15: print() print('----- Generating text after Epoch: %d' % epoch) start_index = random.randint(0, len(user) - maxlen - 1) for diversity in [0.2, 0.5, 1.0, 1.2]: print('----- diversity:', diversity) generated = '' sentence = user[start_index: start_index + maxlen] generated += sentence print('----- Generating with seed: "' + sentence + '"') sys.stdout.write(generated) for i in range(400): x_pred = np.zeros((1, maxlen, len(chars))) for t, char in enumerate(sentence): x_pred[0, t, char_indices[char]] = 1. preds = model.predict(x_pred, verbose=0)[0] next_index = sample(preds, diversity) next_char = indices_char[next_index] generated += next_char sentence = sentence[1:] + next_char sys.stdout.write(next_char) sys.stdout.flush() print() else: print() print('----- Not generating text after Epoch: %d' % epoch)generate_text = LambdaCallback(on_epoch_end=on_epoch_end)
Training the model and generating predictions
Finally we’ve made it! Our data is ready (x for sequences, y for next characters), we've chosen a batch_size of 128, and we've defined a callback function which will print generated text using model.predict() at the end of the first epoch followed by every fifth epoch with five different temperature setting each time. We have another callback, ModelCheckpoint, which will save the best model at each epoch if it's improved based on our loss value (find the saved weights file weights.hdf5 in the "Output" tab of the kernel).
Let’s fit our model with these specifications and epochs = 15 for the number of epochs to train. And of course, let's not forget to put our GPU to use! This will make training/prediction much faster than if we used a CPU. In any case, you will still want to grab some lunch or go for a walk while you wait for the model to train and generate predictions if you're running this code interactively.
P.S. If you’re running this interactively in your own notebook on Kaggle, you can click the blue square “Stop” button next to the console at the bottom of your screen to interrupt the model training.
# define the checkpointfilepath = "weights.hdf5"checkpoint = ModelCheckpoint(filepath, monitor='loss', verbose=1, save_best_only=True, mode='min')# fit model using our gpuwith tf.device('/gpu:0'): model.fit(x, y, batch_size=128, epochs=15, verbose=2, callbacks=[generate_text, checkpoint])
Conclusion
And there you have it! If you ran this notebook in Kaggle Kernels, you hopefully caught the model printing out generated text character-by-character to dramatic effect.
I hope you’ve enjoyed learning how to start from a dataframe containing rows of text to using an LSTM model implemented using Keras in Kernels to generate novel sentences thanks to the power of GPUs. You can see how our model improved from the first epoch to the last. The text generated by the model’s predictions in the first epoch didn’t really resemble English at all. And overall, lower levels of diversity generate text with a lot of repetitions, whereas higher levels of diversity correspond to more gobbledegook.
Can you tweak the model or its hyperparameters to generate even better text? Try it out for yourself by forking this notebook kernel (click “Fork Notebook” at the top).
Inspiration for next steps
Here are just a few ideas for how to take what you learned here and expand it:
- Experiment with different (hyper)-parameters like the amount of training data, number of epochs or batch sizes,
temperature, etc. - Try out the same code with different data; fork this notebook, go to the “Data” tab and remove the freeCodeCamp data source, then add a different dataset (good examples here).
- Try out more complicated network architectures like adding dropout layers.
- Learn more about deep learning on Kaggle Learn, a series of videos and hands-on notebook tutorials in Kernels.
- Use
weights.hdf5in the "Output" to predict based on different data in a new kernel what it would be like if the user in this tutorial completed someone else's sentences. - Compare the speed-up effect of using a CPU versus a GPU on a minimal example.