By Vagdevi Kommineni
As a continuation of my previous post on ASL Recognition using AlexNet — training from scratch, let us now consider how to solve this problem using the transfer learning technique.

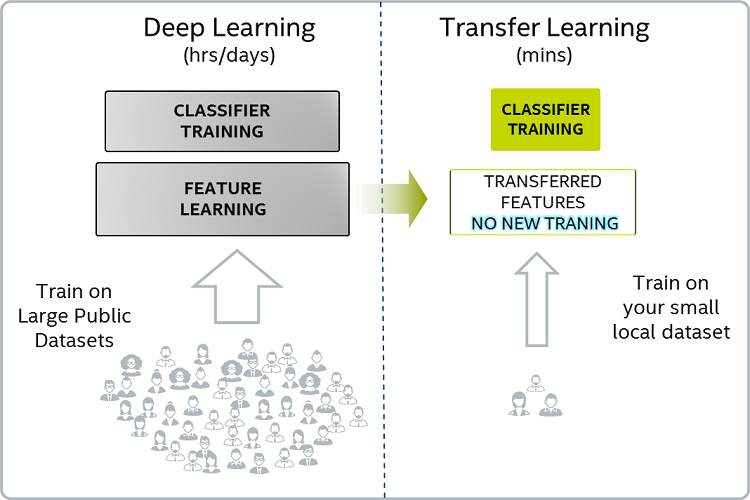
Transfer learning has become so handy for computer vision geeks.
It’s basically a mechanism where the knowledge acquired by training a model for achieving a task is efficiently modified or optimized in order to accomplish the second related task.
One of the powerful tasks of deep learning is that, sometimes we can take the knowlewdge the neural network has learnt from one task (task A) and apply that knowledge in another task (task B). This is called transfer learning.
— Andrew Ng

For example, a neural network trained on object recognition can be used to read x-ray scans. This is achieved by freezing the weights until the initial or mid-layers are learned on the data for task A, removing the last layer or a few of the last layers, and adding new layers and training those parameters using the data for task B.
Transfer learning makes sense when the data in training for task A is quite large and that of task B is relatively smaller. By getting trained on such vast amounts of data and showing excellent performance on its test data, this implies that the neural network has a good knowledge of extracting useful features from the input images. This is essential and powerful for achieving a task.
Now that we have such powerful features from these layers (whose weights from task A are frozen), we just need to make use of these extracted features to achieve task B. So, these features from frozen layers are fed to the new layers and the parameters for these layers are trained on the data of task B.
So basically, we store the knowledge from the previous task in the form of the weights of the frozen layers (called pre-training). Then we make the neural network task B-specific by training (called fine-tuning) the latter layers on the new data. For more information about transfer learning, please visit here.
This technique is really useful because:
- we can bring up a model which performs elegantly for task B, though we have less data available for task B,
- there are fewer parameters to be trained (only last layer/layers) and thus less training time,
- there is less demand for heavy computational resources like GPU, TPU (but still depends on the data available for task B).
Since this post is the continuation of the previous post about ASL Recognition using AlexNet — training from scratch, please refer to that post for preprocessing details and the code (preprocess.py).
The data used for both the posts is this Kaggle data for ASL. The dataset consists of images of hand gestures for each letter in the English alphabet. The images of a single class are of different variants, as in zoomed versions, dim and bright light conditions, etc. For each class, there are as many as 3000 images. Here are links for the full code of preprocessing & training and testing.
For transfer learning, I have used the VGG16 pre-trained model trained on the ImageNet Dataset. The weights are readily available in keras. We shall first import all the necessary modules as follows:
import kerasfrom keras.optimizers import SGD from keras.models import Sequential from keras.applications import VGG16 #VGG16 pretrained weights from keras.preprocessing import imagefrom keras.layers.normalization import BatchNormalizationfrom keras.layers import Dense, Activation, Dropout, Flatten,Conv2D, MaxPooling2D
print("Imported Network Essentials")
Let us now initiate the model to be a sequential one and first add the pre-trained VGG16 network to our model. Note that we need to remove the last layers (called top layers) and freeze the weights of all the previous layers. That’s done by include_top=False . weights='imagenet’ takes the weights of the VGG16 network trained on the ImageNet Dataset.
# to fix the input image sizeimage_size=224
# Load the VGG modelvgg_base = VGG16(weights='imagenet',include_top=False, input_shape=(image_size,image_size,3))
Now, the part of VGG16 we want is stored in vgg_base. We shall also add the other layers like dense layers and dropout layers on top of vgg_base. Thus the full architecture of the neural network we use shall be:
#initiate a modelmodel = Sequential() #Add the VGG base modelmodel.add(vgg_base) #Add new layersmodel.add(Flatten()) model.add(Dense(8192,activation='relu'))model.add(Dropout(0.8))model.add(Dense(4096,activation='relu'))model.add(Dropout(0.5))model.add(Dense(5, activation='softmax'))
We shall next define our optimizer as SGD and set the learning rate lr value. Since this is a categorical classification, we use categorical_crossentropy as the loss function in model.compile. Using checkpoints is the best way to store the weights we got until the point of interruption, so that we may use them later. The first parameter is to set the place to store: save it as weights.{epoch:02d}-{val_loss:.2f}.hdf5 in the Checkpoints folder. We then go for training by using model.fit.
# Compile sgd = SGD(lr=0.001)model.compile(loss='categorical_crossentropy', optimizer=sgd, metrics=['accuracy'])checkpoint = keras.callbacks.ModelCheckpoint("Weights/weights.{epoch:02d}-{val_loss:.2f}.hdf5", monitor='val_loss', verbose=0, save_best_only=False, save_weights_only=False, mode='auto', period=1)
# Trainmodel.fit(X_train/255.0, Y_train, batch_size=32, epochs=15, verbose=1,validation_data=(X_test/255.0,Y_test/255.0), shuffle=True,callbacks=[checkpoint])
We can save the model and weights as follows:
# serialize model to JSONmodel_json = model.to_json()with open("Model/model.json", "w") as json_file: json_file.write(model_json)
# serialize weights to HDF5model.save_weights("Model/model_weights.h5")print("Saved model to disk")
Let’s have a look at the whole code for training here:
# train.py
import kerasfrom keras.optimizers import SGD from keras.models import Sequential from keras.applications import VGG16 #VGG16 pretrained weights from keras.preprocessing import imagefrom keras.layers.normalization import BatchNormalizationfrom keras.layers import Dense, Activation, Dropout, Flatten,Conv2D, MaxPooling2Dprint("Imported Network Essentials")
# to fix the input image sizeimage_size=224
# Load the VGG modelvgg_base = VGG16(weights='imagenet',include_top=False, input_shape=(image_size,image_size,3))
#initiate a modelmodel = Sequential() #Add the VGG base modelmodel.add(vgg_base) #Add new layersmodel.add(Flatten()) model.add(Dense(8192,activation='relu'))model.add(Dropout(0.8))model.add(Dense(4096,activation='relu'))model.add(Dropout(0.5))model.add(Dense(5, activation='softmax'))
# Compile sgd = SGD(lr=0.001)model.compile(loss='categorical_crossentropy', optimizer=sgd, metrics=['accuracy'])checkpoint = keras.callbacks.ModelCheckpoint("Weights/weights.{epoch:02d}-{val_loss:.2f}.hdf5", monitor='val_loss', verbose=0, save_best_only=False, save_weights_only=False, mode='auto', period=1)
# Trainmodel.fit(X_train/255.0, Y_train, batch_size=32, epochs=15, verbose=1,validation_data=(X_test/255.0,Y_test/255.0), shuffle=True,callbacks=[checkpoint])
# serialize model to JSONmodel_json = model.to_json()with open("Model/model.json", "w") as json_file: json_file.write(model_json)
# serialize weights to HDF5model.save_weights("Model/model_weights.h5")print("Saved model to disk")
Now it’s time for testing! Here’s the way to load the model and trained weights from the stored JSON files and use the evaluation metric accuracy_score from sklearn.metrics .
# test.py
import numpy as npfrom keras.models import model_from_jsonfrom sklearn.metrics import accuracy_score
# dimensions of our imagesimage_size = 224 with open('Model/model.json', 'r') as f: model = model_from_json(f.read()) model.summary()model.load_weights('Model/model_weights.h5')
# loading the numpy test images (feel free to look at preprocessing)X_test=np.load("Numpy/test_set.npy")Y_test=np.load("Numpy/test_classes.npy")
# getting predictions and getting the maximum of predictions# since predictions are of form [0.01, 0.99, 0, 0] in Y_predict and # are of the form [0,1,0,0] in Y_testY_predict = model.predict(X_test) Y_predict = [np.argmax(r) for r in Y_predict]Y_test = [np.argmax(r) for r in Y_test]
print("##################")acc_score = accuracy_score(Y_test, Y_predict)print("Accuracy: "+str(acc_score))print("##################")
I got an accuracy of 97%. You may follow certain steps to improve accuracy like:
- hyperparameter tuning.
- using a different pretrained model like ResNet, VGG19, etc instead of VGG16.
The full code can be found here. I would love to hear your results in the comments section below.
Happy learning!