
By Peter Gleeson
Data science is an exciting, fast-moving field to become involved in. There’s no shortage of demand for talented, analytically-minded individuals. Companies of all sizes are hiring data scientists, and the role provides real value across a wide range of industries and applications.
Often, people’s first encounters with the field come through reading sci-fi headlines generated by major research organizations. Recent progress has raised the prospect of machine learning transforming the world as we know it within a generation.
However, outside of academia and research, data science is about much more besides headline topics such as deep learning and NLP.
Much of the commercial value of a data scientist comes from providing the clarity and insights that vast quantities of data can bring. The role can encompass everything from data engineering, to data analysis and reporting — with maybe some machine learning thrown in for good measure.
This is especially the case at a startup firm. Early and mid-stage companies’ data needs are typically far removed from the realm of neural networks and computer vision. (Unless, of course, these are core features of their product/service).
Rather, they need accurate analysis, reliable processes, and the ability to scale fast.
Therefore, the skills required for many advertised data science roles are broad and varied. Like any pursuit in life, much of the value comes from mastering the basics. The fabled 80:20 rule applies — approximately 80% of the value comes from 20% of the skillset.
Here’s an overview of some of the fundamental skills that any aspiring data scientist should master.
Start with statistics
The main attribute a data scientist brings to their company is the ability to distill insight from complexity. Key to achieving this is understanding how to uncover meaning from noisy data.
Statistical analysis is therefore an important skill to master. Stats lets you:
- Describe data, to provide a detailed picture to stakeholders
- Compare data and test hypotheses, to inform business decisions
- Identify trends and relationships that provide real predictive value
Statistics provides a powerful set of tools for making sense of commercial and operational data.
But be wary! The one thing worse than limited insights are misleading insights. This is why it is vital to understand the fundamentals of statistical analysis.
Fortunately, there are a few guiding principles you can follow.
Assess your assumptions
It’s very important to be aware of assumptions you make about your data.
Always be critical of provenance, and skeptical of results. Could there be an ‘uninteresting’ explanation for any observed trends in your data? How valid is your chosen stats test or methodology? Does your data meet all the underlying assumptions?
Knowing which findings are ‘interesting’ and worth reporting also depends upon your assumptions. An elementary case in point is judging whether it is more appropriate to report the mean or the median of a data set.
Often more important than knowing which approach to take, is knowing which not to. There are usually several ways to analyze a given set of data, but make sure to avoid common pitfalls.
For instance, multiple comparisons should always be corrected for. Under no circumstances should you seek to confirm a hypothesis using the same data used to generate it! You’d be surprised how easily this is done.
Distribution > Location
Whenever I talk about introductory statistics, I always make sure to emphasize a particular point: the distribution of a variable is usually at least as interesting/informative as its location. In fact, it is often more so.
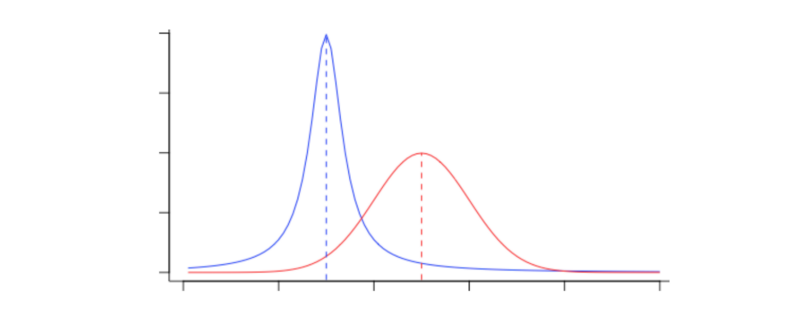
This is because the distribution of a variable usually contains information about the underlying generative (or sampling) processes.
For example, count data often follows a Poisson distribution, whereas a system exhibiting positive feedback (“reinforcement”) will tend to surface a power law distribution. Never rely on data being normally distributed without first checking carefully.
Secondly, understanding the distribution of the data is essential for knowing how to work with it! Many statistical tests and methods rely upon assumptions about how your data are distributed.
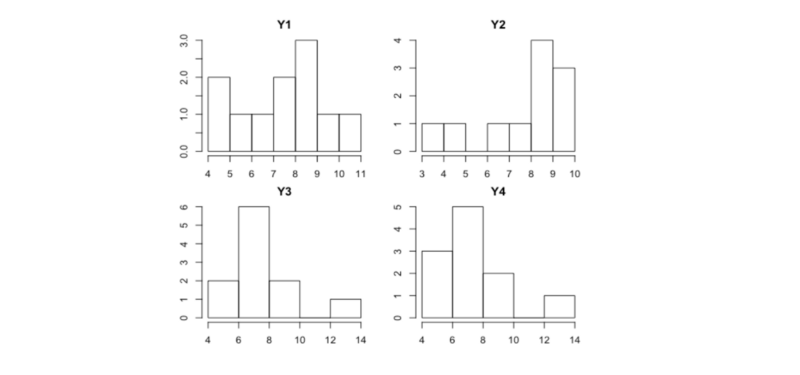
As a contrived example, always be sure to treat unimodal and bimodal data differently. They may have the same mean, but you’d lose a whole ton of important information if you disregard their distributions.
For a more interesting example that illustrates why you should always check your data before reporting summary statistics, take a look at Anscombe’s quartet:
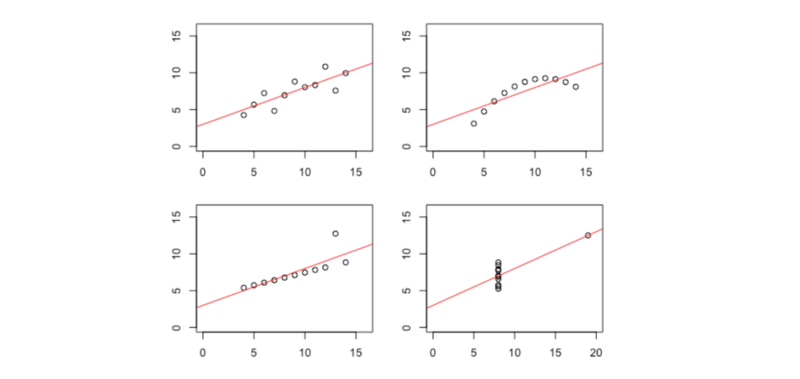
Each graph looks very distinctive, right? Yet each has identical summary statistics — including their means, variance and correlation coefficients. Plotting some of the distributions reveals them to be rather different.
Finally, the distribution of a variable determines the certainty you have about its true value. A ‘narrow’ distribution allows higher certainty, whereas a ‘wide’ distribution allows for less.
The variance about a mean is crucial to provide context. All too often, means with very wide confidence intervals are reported alongside means with very narrow confidence intervals. This can be misleading.
Suitable sampling
The reality is that sampling can be a pain point for commercially oriented data scientists, especially for those with a background in research or engineering.
In a research setting, you can fine-tune precisely designed experiments with many different factors and levels and control treatments. However, ‘live’ commercial conditions are often suboptimal from a data collection perspective. Every decision must be carefully weighed up against the risk of interrupting ‘business-as-usual’.
This requires data scientists to be inventive, yet realistic, with their approach to problem-solving.
A/B testing is a canonical example of an approach that illustrates how products and platforms can be optimized at a granular level without causing major disturbance to business-as-usual.
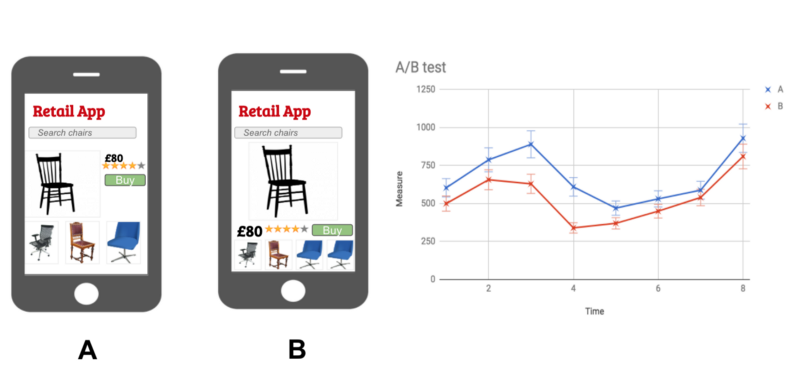
Bayesian methods may be useful for working with smaller data sets, if you have a reasonably informative set of priors to work from.
With any data you do collect, be sure to recognize its limitations.
Survey data is prone to sampling bias (often it is respondents with the strongest opinions who take the time to complete the survey). Time series and spatial data can be affected by autocorrelation. And last but not least, always watch out for multicollinearity when analyzing data from related sources.
Data Engineering
It’s something of a data science cliché, but the reality is that much of the data workflow is spent sourcing, cleaning and storing the raw data required for the more insightful upstream analysis.
Comparatively little time is actually spent implementing algorithms from scratch. Indeed, most statistical tools come with their inner workings wrapped up in neat R packages and Python modules.
The ‘extract-transform-load’ (ETL) process is critical to the success of any data science team. Larger organizations will have dedicated data engineers to meet their complex data infrastructure requirements, but younger companies will often depend upon their data scientists to possess strong, all-round data engineering skills of their own.
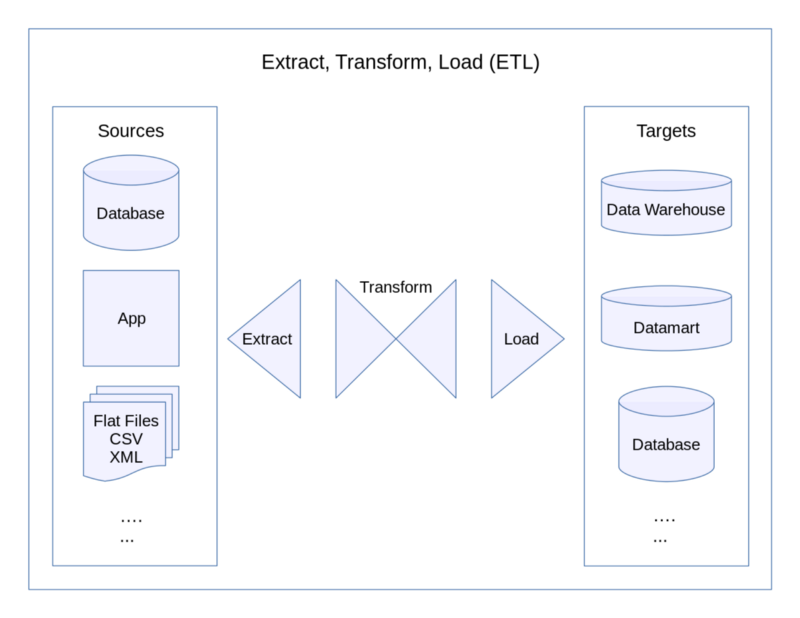
Programming in practice
Data science is highly inter-disciplinary. As well as advanced analytical skills and domain-specific knowledge, the role also necessitates solid programming skills.
There is no perfect answer to which programming languages an aspiring data scientist should learn to use. That said, at least one of Python and/or R will serve you very well.

Whichever language you opt for, aim to become familiar with all its features and the surrounding ecosystem. Browse the various packages and modules available to you, and set up your perfect IDE. Learn the APIs you’ll need to use for accessing your company’s core platforms and services.
Databases are an integral piece in the jigsaw of any data workflow. Be sure to master some dialect of SQL. The exact choice isn’t too important, because switching between them is a manageable process when necessary.
NoSQL databases (such as MongoDB) may also be worth learning about, if your company uses them.
Becoming a confident command line user will go a long way to boosting your day-to-day productivity. Even passing familiarity with simple bash scripting will get you off to a strong start when it comes to automating repetitive tasks.
Effective coding
A very important skill for aspiring data scientists to master is coding effectively. Reusability is key. It is worth taking the time (when it is available) to write code at a level of abstraction that enables it to be used more than once.
However, there is a balance to be struck between short and long-term priorities.
There’s no point taking twice as long to write an ad hoc script to be reusable if there’s no chance it’ll ever be relevant again. Yet every minute spent refactoring old code to be rerun is a minute that could have been saved previously.
Software engineering best practices are worth developing in order to write truly performant production code.
Version management tools such as Git make deploying and maintaining code much more streamlined. Task schedulers allow you to automate routine processes. Regular code reviews and agreed documentation standards will make life much easier for your team’s future selves.
In any line of tech specialization, there’s usually no need to reinvent the wheel. Data engineering is no exception. Frameworks such as Airflow make scheduling and monitoring ETL processes easier and more robust. For distributed data storage and processing, there are Apache Spark and Hadoop.

It isn’t essential for a beginner to learn these in great depth. Yet, having an awareness of the surrounding ecosystem and available tools is always an advantage.
Communicate clearly
Data science is a full stack discipline, with an important stakeholder-facing front end: the reporting layer.
The fact of the matter is simple — effective communication brings with it significant commercial value. With data science, there are four aspects to effective reporting.
- Accuracy
This is crucial, for obvious reasons. The skill here is knowing how to interpret your results, while being clear about any limitations or caveats that may apply. It’s important not to over or understate the relevance of any particular result. - Precision
This matters, because any ambiguity in your report could lead to misinterpretation of the findings. This may have negative consequences further down the line. - Concise
Keep your report as short as possible, but no shorter. A good format might provide some context for the main question, include a brief description of the data available, and give an overview of the ‘headline’ results and graphics. Extra detail can (and should) be included in an appendix. - Accessible
There’s a constant need to balance the technical accuracy of a report with the reality that most of its readers will be experts in their own respective fields, and not necessarily data science. There’s no easy, one-size-fits-all answer here. Frequent communication and feedback will help establish an appropriate equilibrium.
The Graphics Game
Powerful data visualizations will help you communicate complex results to stakeholders effectively. A well-designed graph or chart can reveal in a glance what several paragraphs of text would be required to explain.
There’s a wide range of free and paid-for visualization and dashboard building tools out there, including Plotly, Tableau, Chartio, d3.js and many others.
For quick mock-ups, sometimes you can’t beat good ol’ fashioned spreadsheet software such as Excel or Google Sheets. These will do the job as required, although lack the functionality of purpose-built visualization software.
When building dashboards and graphics, there are a number of guiding principles to consider. The underlying challenge is to maximize the information value of the visualization, without sacrificing ‘readability’.
An effective visualization reveals a high-level overview at a quick glance. More complex graphics may take a little longer for the viewer to digest, and should accordingly offer much greater information content.
If you only ever read one book about data visualization, then Edward Tufte’s classic The Visual Display of Quantitative Information is the outstanding choice.
Tufte single-handedly popularized and invented much of the field of data visualization. Widely used terms such as ‘chartjunk’ and ‘data density’ owe their origins to Tufte’s work. His concept of the ‘data-ink ratio’ remains influential over thirty years on.
The use of color, layout and interactivity will often make the difference between a good visualization and a high-quality, professional one.
Ultimately, creating a great data visualization touches upon skills more often associated with UX and graphic design than data science. Reading around these subjects in your free time is a great way to develop an awareness for what works and what doesn’t.
Be sure to check out sites such as bl.ocks.org for inspiration!
Data science requires a diverse skillset
There are four core skill areas in which you, as an aspiring data scientist, should focus on developing. They are:
- Statistics, including both the underlying theory and real world application.
- Programming, in at least one of Python or R, as well as SQL and using the command line
- Data engineering best practices
- Communicating your work effectively
Bonus! Learn constantly
If you have read this far and feel at all discouraged — rest assured. The main skill in such a fast-moving field is learning how to learn and relearn. No doubt new frameworks, tools and methods will emerge in coming years.
The exact skillset you learn now may need to be entirely updated within five to ten years. Expect this. By doing so, and being prepared, you can stay ahead of the game through continuous relearning.
You can never know everything, and the truth is — no one ever does. But, if you master the fundamentals, you’ll be in a position to pick up anything else on a need-to-know basis.
And that is arguably the key to success in any fast developing discipline.