

Large language models (LLMs) are incredibly powerful general reasoning tools that are useful in a wide range of situations.
But working with LLMs presents challenges that are different from building traditional software:
- Calls tend to be long-running, and stream generated output as it becomes available.
- Instead of structured input (something like JSON) with fixed parameters, they take unstructured and arbitrary natural language as input. They are capable of “understanding” subtleties of that language.
- They are non-deterministic. You may get different outputs even with the same input.
LangChain is a popular framework for creating LLM-powered apps. It was built with these and other factors in mind, and provides a wide range of integrations with closed-source model providers (like OpenAI, Anthropic, and Google), open source models, and other third-party components like vectorstores.
This article will walk through the fundamentals of building with LLMs and LangChain’s Python library. The only requirement is basic familiarity with Python, – no machine learning experience needed!
You’ll learn about:
- Basic project setup
- Using Chat Models and other fundamental LangChain components
- Using LangChain Expression Language to create chains
- Streaming output as soon as it is generated
- Passing context to steer the model’s output (basic RAG concepts)
- Debugging and tracing the internals of your chains
Let’s dive in!
Project Setup
We recommend using a Jupyter notebook to run the code in this tutorial since it provides a clean, interactive environment. See this page for instructions on setting it up locally, or check out this Google Colab notebook for an in-browser experience.
The first thing you'll need to do is choose which Chat Model you want to use. If you've ever used an interface like ChatGPT before, the basic idea of a Chat Model will be familiar to you – the model takes messages as input, and returns messages as output. The difference is that we'll be doing it in code.
This guide defaults to Anthropic and their Claude 3 Chat Models, but LangChain also has a wide range of other integrations to choose from, including OpenAI models like GPT-4.
pip install langchain_core langchain_anthropic
If you’re working in a Jupyter notebook, you’ll need to prefix pip with a % symbol like this: %pip install langchain_core langchain_anthropic.
You’ll also need an Anthropic API key, which you can obtain here from their console. Once you have it, set as an environment variable named ANTHROPIC_API_KEY:
export ANTHROPIC_API_KEY="..."
You can also pass a key directly into the model if you prefer.
First steps
You can initialize your model like this:
from langchain_anthropic import ChatAnthropic
chat_model = ChatAnthropic(
model="claude-3-sonnet-20240229",
temperature=0
)
# If you prefer to pass your key explicitly
# chat_model = ChatAnthropic(
# model="claude-3-sonnet-20240229",
# temperature=0,
# api_key="YOUR_ANTHROPIC_API_KEY"
# )
The model parameter is a string that matches one of Anthropic’s supported models. At the time of writing, Claude 3 Sonnet strikes a good balance between speed, cost, and reasoning capability.
temperature is a measure of the amount of randomness the model uses to generate responses. For consistency, in this tutorial, we set it to 0 but you can experiment with higher values for creative use cases.
Now, let’s try running it:
chat_model.invoke("Tell me a joke about bears!")
Here’s the output:
AIMessage(content="Here's a bear joke for you:\\n\\nWhy did the bear dissolve in water?\\nBecause it was a polar bear!")
You can see that the output is something called an AIMessage. This is because Chat Models use Chat Messages as input and output.
Note: You were able to pass a simple string as input in the previous example because LangChain accepts a few forms of convenience shorthand that it automatically converts to the proper format. In this case, a single string is turned into an array with a single HumanMessage.
LangChain also contains abstractions for pure text-completion LLMs, which are string input and string output. But at the time of writing, the chat-tuned variants have overtaken LLMs in popularity. For example, GPT-4 and Claude 3 are both Chat Models.
To illustrate what’s going on, you can call the above with a more explicit list of messages:
from langchain_core.messages import HumanMessage
chat_model.invoke([
HumanMessage("Tell me a joke about bears!")
])
And you get a similar output:
AIMessage(content="Here's a bear joke for you:\\n\\nWhy did the bear bring a briefcase to work?\\nHe was a business bear!")
Prompt Templates
Models are useful on their own, but it’s often convenient to parameterize inputs so that you don’t repeat boilerplate. LangChain provides Prompt Templates for this purpose.
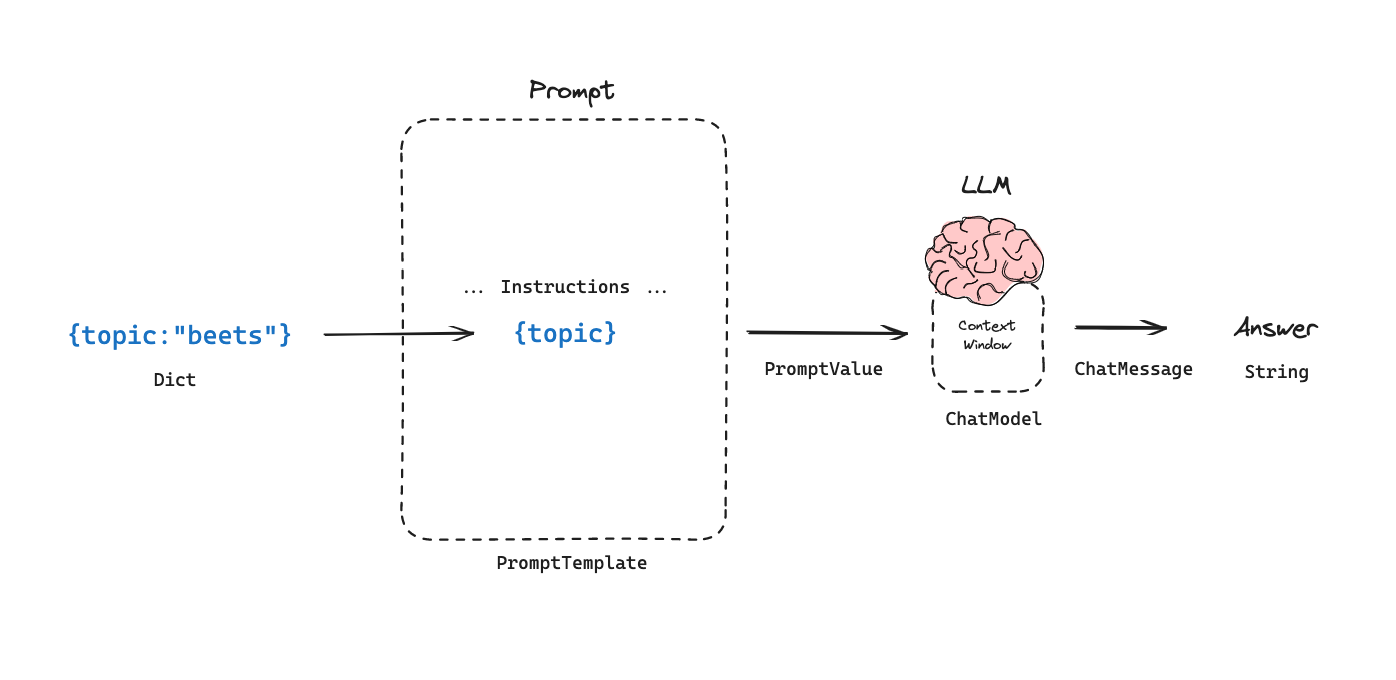 Prompt templates in LangChain
Prompt templates in LangChain
A simple example would be something like this:
from langchain_core.prompts import ChatPromptTemplate
joke_prompt = ChatPromptTemplate.from_messages([
("system", "You are a world class comedian."),
("human", "Tell me a joke about {topic}")
])
You can apply the templating using the same .invoke() method as with Chat Models:
joke_prompt.invoke({"topic": "beets"})
Here’s the result:
ChatPromptValue(messages=[
SystemMessage(content='You are a world class comedian.'),
HumanMessage(content='Tell me a joke about beets')
])
Let’s go over each step:
- You construct a prompt template consisting of templates for a
SystemMessageand aHumanMessageusingfrom_messages. - You can think of
SystemMessagesas meta-instructions that are not part of the current conversation, but purely guide input. - The prompt template contains
{topic}in curly braces. This denotes a required parameter named"topic". - You invoke the prompt template with a dict with a key named
"topic"and a value"beets". - The result contains the formatted messages.
Next, you'll learn how to use this prompt template with your Chat Model.
Chaining
You may have noticed that both the Prompt Template and Chat Model implement the .invoke() method. In LangChain terms, they are both instances of Runnables.
You can compose Runnables into “chains” using the pipe (|) operator where you .invoke() the next step with the output of the previous one. Here’s an example:
chain = joke_prompt | chat_model
The resulting chain is itself a Runnable and automatically implements .invoke() (as well as several other methods, as we’ll see later). This is the foundation of LangChain Expression Language (LCEL).
Let’s invoke this new chain:
chain.invoke({"topic": "beets"})
The chain returns a joke whose topic is beets:
AIMessage(content="Here's a beet joke for you:\\n\\nWhy did the beet blush? Because it saw the salad dressing!")
Now, let’s say you want to work with just the raw string output of the message. LangChain has a component called an Output Parser, which, as the name implies, is responsible for parsing the output of a model into a more accessible format. Since composed chains are also Runnable, you can again use the pipe operator:
from langchain_core.output_parsers import StrOutputParser
str_chain = chain | StrOutputParser()
# Equivalent to:
# str_chain = joke_prompt | chat_model | StrOutputParser()
Cool! Now let’s invoke it:
str_chain.invoke({"topic": "beets"})
And the result is now a string as we’d hoped:
"Here's a beet joke for you:\\n\\nWhy did the beet blush? Because it saw the salad dressing!"
You still pass {"topic": "beets"} as input to the new str_chain because the first Runnable in the sequence is still the Prompt Template you declared before.
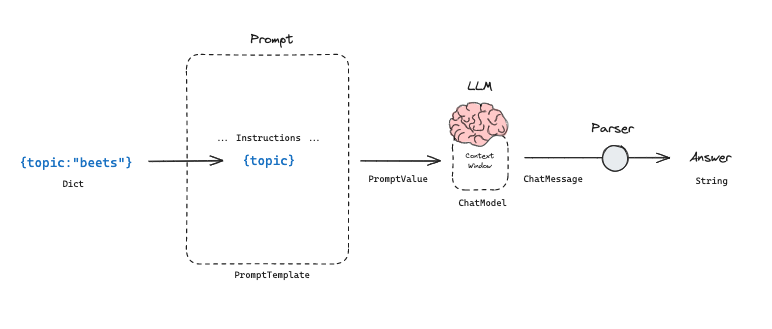 Prompt model and output parser
Prompt model and output parser
Streaming
One of the biggest advantages to composing chains with LCEL is the streaming experience.
All Runnables implement the .stream()method (and .astream() if you’re working in async environments), including chains. This method returns a generator that will yield output as soon as it’s available, which allows us to get output as quickly as possible.
While every Runnable implements .stream(), not all of them support multiple chunks. For example, if you call .stream() on a Prompt Template, it will just yield a single chunk with the same output as .invoke().
You can iterate over the output using for ... in syntax. Try it with the str_chain you just declared:
for chunk in str_chain.stream({"topic": "beets"}):
print(chunk, end="|")
And you get multiple strings as output (chunks are separated by a | character in the print function):
Here|'s| a| b|eet| joke| for| you|:|
Why| did| the| b|eet| bl|ush|?| Because| it| saw| the| sal|ad| d|ressing|!|
Chains composed like str_chain will start streaming as early as possible, which in this case is the Chat Model in the chain.
Some Output Parsers (like the StrOutputParser used here) and many LCEL Primitives are able to process streamed chunks from previous steps as they are generated – essentially acting as transform streams or passthroughs – and do not disrupt streaming.
How to Guide Generation with Context
LLMs are trained on large quantities of data and have some innate “knowledge” of various topics. Still, it’s common to pass the model private or more specific data as context when answering to glean useful information or insights. If you've heard the term "RAG", or "retrieval-augmented generation" before, this is the core principle behind it.
One of the simplest examples of this is telling the LLM what the current date is. Because LLMs are snapshots of when they are trained, they can’t natively determine the current time. Here’s an example:
chat_model = ChatAnthropic(model_name="claude-3-sonnet-20240229")
chat_model.invoke("What is the current date?")
The response:
AIMessage(content="Unfortunately, I don't actually have a concept of the current date and time. As an AI assistant without an integrated calendar, I don't have a dynamic sense of the present date. I can provide you with today's date based on when I was given my training data, but that may not reflect the actual current date you're asking about.")
Now, let’s see what happens when you give the model the current date as context:
from datetime import date
prompt = ChatPromptTemplate.from_messages([
("system", 'You know that the current date is "{current_date}".'),
("human", "{question}")
])
chain = prompt | chat_model | StrOutputParser()
chain.invoke({
"question": "What is the current date?",
"current_date": date.today()
})
And you can see, the model generates the current date:
"The current date is 2024-04-05."
Nice! Now, let's take it a step further. Language models are trained on vast quantities of data, but they don't know everything. Here's what happens if you directly ask the Chat Model a very specific question about a local restaurant:
chat_model.invoke(
"What was the Old Ship Saloon's total revenue in Q1 2023?"
)
The model doesn't know the answer natively, or even know which of the many Old Ship Saloons in the world we may be talking about:
AIMessage(content="I'm sorry, I don't have any specific financial data about the Old Ship Saloon's revenue in Q1 2023. As an AI assistant without access to the saloon's internal records, I don't have information about their future projected revenues. I can only provide responses based on factual information that has been provided to me.")
However, if we can give the model more context, we can guide it to come up with a good answer:
SOURCE = """
Old Ship Saloon 2023 quarterly revenue numbers:
Q1: $174782.38
Q2: $467372.38
Q3: $474773.38
Q4: $389289.23
"""
rag_prompt = ChatPromptTemplate.from_messages([
("system", 'You are a helpful assistant. Use the following context when responding:\n\n{context}.'),
("human", "{question}")
])
rag_chain = rag_prompt | chat_model | StrOutputParser()
rag_chain.invoke({
"question": "What was the Old Ship Saloon's total revenue in Q1 2023?",
"context": SOURCE
})
This time, here's the result:
"According to the provided context, the Old Ship Saloon's revenue in Q1 2023 was $174,782.38."
The result looks good! Note that augmenting generation with additional context is a very deep topic - in the real world, this would likely take the form of a longer financial document or portion of a document retrieved from some other data source. RAG is a powerful technique to answer questions over large quantities of information.
You can check out LangChain’s retrieval-augmented generation (RAG) docs to learn more.
Debugging
Because LLMs are non-deterministic, it becomes more and more important to see the internals of what’s going on as your chains get more complex.
LangChain has a set_debug() method that will return more granular logs of the chain internals: Let’s see it with the above example.
First, we'll need to install the main langchain package for the entrypoint to import the method:
%pip install langchain
Then add this code:
from langchain.globals import set_debug
set_debug(True)
from datetime import date
prompt = ChatPromptTemplate.from_messages([
("system", 'You know that the current date is "{current_date}".'),
("human", "{question}")
])
chain = prompt | chat_model | StrOutputParser()
chain.invoke({
"question": "What is the current date?",
"current_date": date.today()
})
There’s a lot more information!
[chain/start] [1:chain:RunnableSequence] Entering Chain run with input:
[inputs]
[chain/start] [1:chain:RunnableSequence > 2:prompt:ChatPromptTemplate] Entering Prompt run with input:
[inputs]
[chain/end] [1:chain:RunnableSequence > 2:prompt:ChatPromptTemplate] [1ms] Exiting Prompt run with output:
[outputs]
[llm/start] [1:chain:RunnableSequence > 3:llm:ChatAnthropic] Entering LLM run with input:
{
"prompts": [
"System: You know that the current date is \\"2024-04-05\\".\\nHuman: What is the current date?"
]
}
...
[chain/end] [1:chain:RunnableSequence] [885ms] Exiting Chain run with output:
{
"output": "The current date you provided is 2024-04-05."
}
You can see this guide for more information on debugging.
You can also use the astream_events() method to return this data. This is useful if you want to use intermediate steps in your application logic. Note that this is an async method, and requires an extra version flag since it’s still in beta:
# Turn off debug mode for clarity
set_debug(False)
stream = chain.astream_events({
"question": "What is the current date?",
"current_date": date.today()
}, version="v1")
async for event in stream:
print(event)
print("-----")
{'event': 'on_chain_start', 'run_id': '90785a49-987e-46bf-99ea-d3748d314759', 'name': 'RunnableSequence', 'tags': [], 'metadata': {}, 'data': {'input': {'question': 'What is the current date?', 'current_date': datetime.date(2024, 4, 5)}}}
-----
{'event': 'on_prompt_start', 'name': 'ChatPromptTemplate', 'run_id': '54b1f604-6b2a-48eb-8b4e-c57a66b4c5da', 'tags': ['seq:step:1'], 'metadata': {}, 'data': {'input': {'question': 'What is the current date?', 'current_date': datetime.date(2024, 4, 5)}}}
-----
{'event': 'on_prompt_end', 'name': 'ChatPromptTemplate', 'run_id': '54b1f604-6b2a-48eb-8b4e-c57a66b4c5da', 'tags': ['seq:step:1'], 'metadata': {}, 'data': {'input': {'question': 'What is the current date?', 'current_date': datetime.date(2024, 4, 5)}, 'output': ChatPromptValue(messages=[SystemMessage(content='You know that the current date is "2024-04-05".'), HumanMessage(content='What is the current date?')])}
-----
{'event': 'on_chat_model_start', 'name': 'ChatAnthropic', 'run_id': 'f5caa4c6-1b51-49dd-b304-e9b8e176623a', 'tags': ['seq:step:2'], 'metadata': {}, 'data': {'input': {'messages': [[SystemMessage(content='You know that the current date is "2024-04-05".'), HumanMessage(content='What is the current date?')]]}}}
-----
...
{'event': 'on_chain_end', 'name': 'RunnableSequence', 'run_id': '90785a49-987e-46bf-99ea-d3748d314759', 'tags': [], 'metadata': {}, 'data': {'output': 'The current date is 2024-04-05.'}}
-----
Finally, you can use an external service like LangSmith to add tracing. Here’s an example:
# Sign up at <https://smith.langchain.com/>
# Set environment variables
# import os
# os.environ["LANGCHAIN_TRACING_V2"] = "true"
# os.environ["LANGCHAIN_API_KEY"] = "YOUR_KEY"
# os.environ["LANGCHAIN_PROJECT"] = "YOUR_PROJECT"
chain.invoke({
"question": "What is the current date?",
"current_date": date.today()
})
"The current date is 2024-04-05."
LangSmith will capture the internals at each step, giving you a result like this.
You can also tweak prompts and rerun model calls in a playground. Due to the non-deterministic nature of LLMs, you can also tweak prompts and rerun model calls in a playground, as well as create datasets and test cases to evaluate changes to your app and catch regressions.
Thank you!
You’ve now learned the basics of:
- LangChain’s Chat Model, Prompt Template, and Output Parser components
- How to chain components together with streaming.
- Using outside information to guide model generation.
- How to debug the internals of your chains.
And if you want to learn more about Retrieval-Augmented Generation (RAG), here's a RAG from scratch course on freeCodeCamp's YouTube channel.
Check out the following for some good resources to continue your generative AI journey:
You can also follow LangChain on X (formerly Twitter) @LangChainAI for the latest news, or me @Hacubu.
Happy prompting!