
By Cole Murray
In my last tutorial, you learned how to create a facial recognition pipeline in Tensorflow with convolutional neural networks. In this tutorial, you’ll learn how a convolutional neural network (CNN) and Long Short Term Memory (LSTM) can be combined to create an image caption generator and generate captions for your own images.
Overview
- Introduction to Image Captioning Model Architecture
- Captions as a Search Problem
- Creating Captions in Tensorflow
Prerequisites
- Basic understanding of Convolutional Neural Networks
- Basic understanding of LSTM
- Basic understanding of Tensorflow
Introduction to image captioning model architecture
Combining a CNN and LSTM
In 2014, researchers from Google released a paper, Show And Tell: A Neural Image Caption Generator. At the time, this architecture was state-of-the-art on the MSCOCO dataset. It utilized a CNN + LSTM to take an image as input and output a caption.
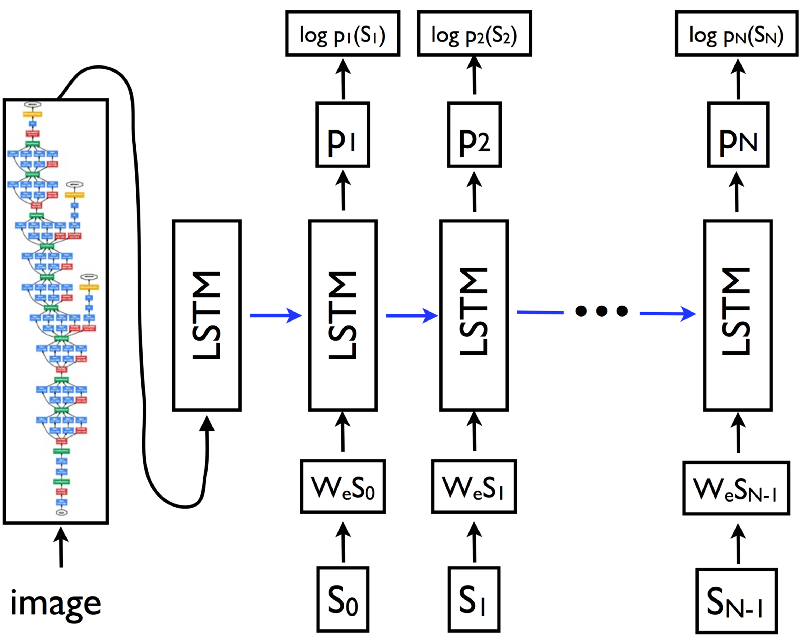 _A CNN-LSTM Image Caption Architecture [source](https://arxiv.org/pdf/1411.4555.pdf" rel="noopener" target="blank" title=")
_A CNN-LSTM Image Caption Architecture [source](https://arxiv.org/pdf/1411.4555.pdf" rel="noopener" target="blank" title=")
Using a CNN for image embedding
A convolutional neural network can be used to create a dense feature vector. This dense vector, also called an embedding, can be used as feature input into other algorithms or networks.
For an image caption model, this embedding becomes a dense representation of the image and will be used as the initial state of the LSTM.
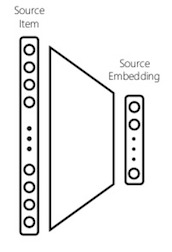 _Mapping input to embedding [source](https://www.slideshare.net/BhaskarMitra3/vectorland-brief-notes-from-using-text-embeddings-for-search" rel="noopener" target="blank" title=")
_Mapping input to embedding [source](https://www.slideshare.net/BhaskarMitra3/vectorland-brief-notes-from-using-text-embeddings-for-search" rel="noopener" target="blank" title=")
LSTM
An LSTM is a recurrent neural network architecture that is commonly used in problems with temporal dependences. It succeeds in being able to capture information about previous states to better inform the current prediction through its memory cell state.
An LSTM consists of three main components: a forget gate, input gate, and output gate. Each of these gates is responsible for altering updates to the cell’s memory state.
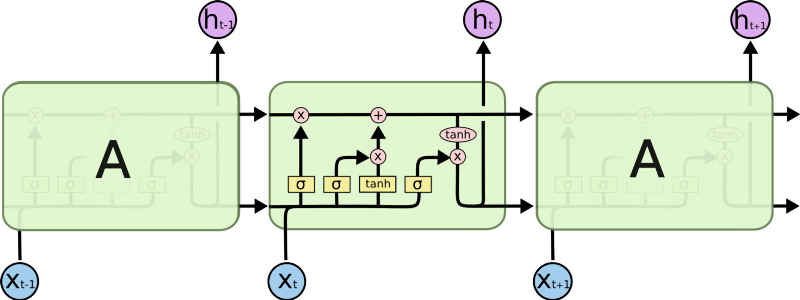 _An unrolled LSTM [source](https://colah.github.io/posts/2015-08-Understanding-LSTMs/" rel="noopener" target="blank" title=")
_An unrolled LSTM [source](https://colah.github.io/posts/2015-08-Understanding-LSTMs/" rel="noopener" target="blank" title=")
For a deeper understanding of LSTM’s, visit Chris Olah’s post.
Prediction with image as initial state
In a sentence language model, an LSTM is predicting the next word in a sentence. Similarly, in a character language model, an LSTM is trying to predict the next character, given the context of previously seen characters.
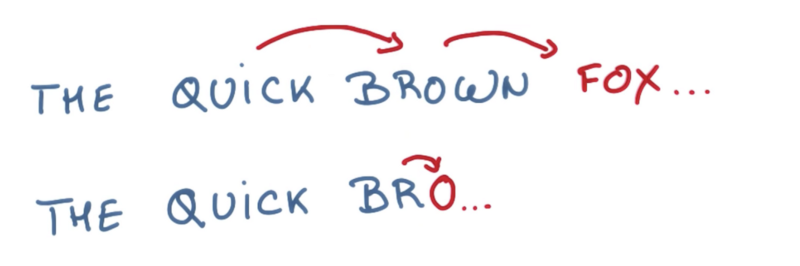 _Sentence and character model predictions [source](https://www.youtube.com/watch?v=UXW6Cs82UKo" rel="noopener" target="blank" title=")
_Sentence and character model predictions [source](https://www.youtube.com/watch?v=UXW6Cs82UKo" rel="noopener" target="blank" title=")
In an image caption model, you will create an embedding of the image. This embedding will then be fed as initial state into an LSTM. This becomes the first previous state to the language model, influencing the next predicted words.
At each time-step, the LSTM considers the previous cell state and outputs a prediction for the most probable next value in the sequence. This process is repeated until the end token is sampled, signaling the end of the caption.
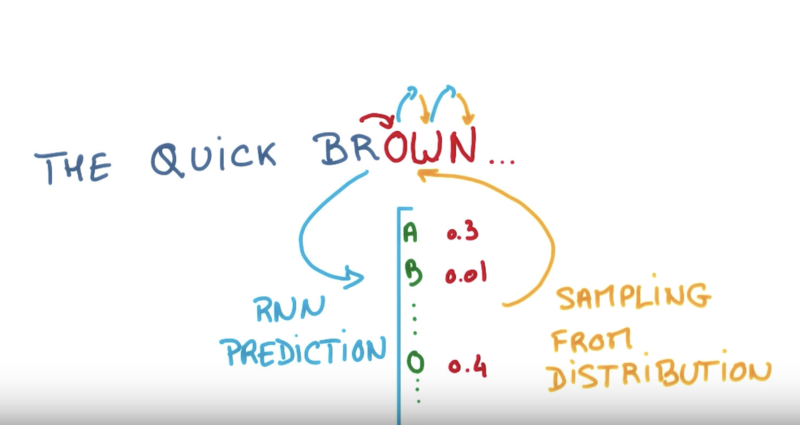 _Sampling characters from an LSTM. [source](https://www.youtube.com/watch?v=UXW6Cs82UKo" rel="noopener" target="blank" title=")
_Sampling characters from an LSTM. [source](https://www.youtube.com/watch?v=UXW6Cs82UKo" rel="noopener" target="blank" title=")
Captions as a search problem
Generating a caption can be viewed as a graph search problem. Here, the nodes are words. The edges are the probability of moving from one node to another. Finding the optimal path involves maximizing the total probability of a sentence.
Sampling and choosing the most probable next value is a greedy approach to generating a caption. It is computationally efficient, but can lead to a sub-optimal result.
Given all possible words, it would not be computationally/space efficient to calculate all possible sentences and determine the optimal sentence. This rules out using a search algorithm such as Depth First Search or Breadth First Search to find the optimal path.
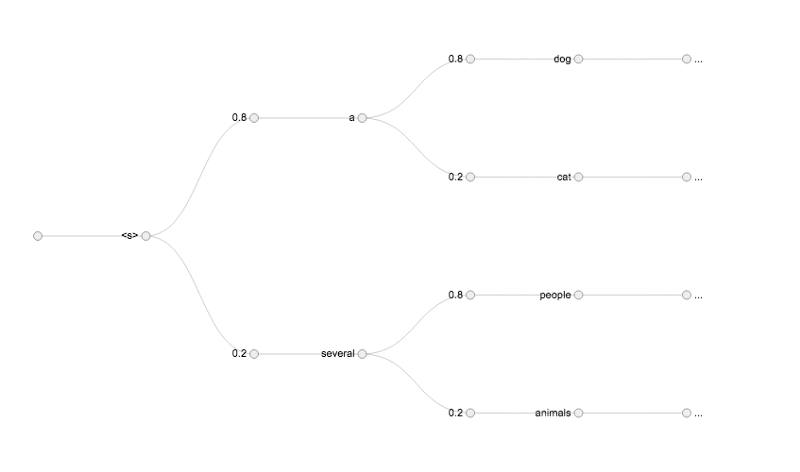 _[source](http://blog.murraycole.com/wp-content/uploads/2018/04/sentence_explore_graph.png.png" rel="noopener" target="blank" title=")
_[source](http://blog.murraycole.com/wp-content/uploads/2018/04/sentence_explore_graph.png.png" rel="noopener" target="blank" title=")
Beam Search
Beam search is a breadth-first search algorithm that explores the most promising nodes. It generates all possible next paths, keeping only the top N best candidates at each iteration.
As the number of nodes to expand from is fixed, this algorithm is space-efficient and allows more potential candidates than a best-first search.
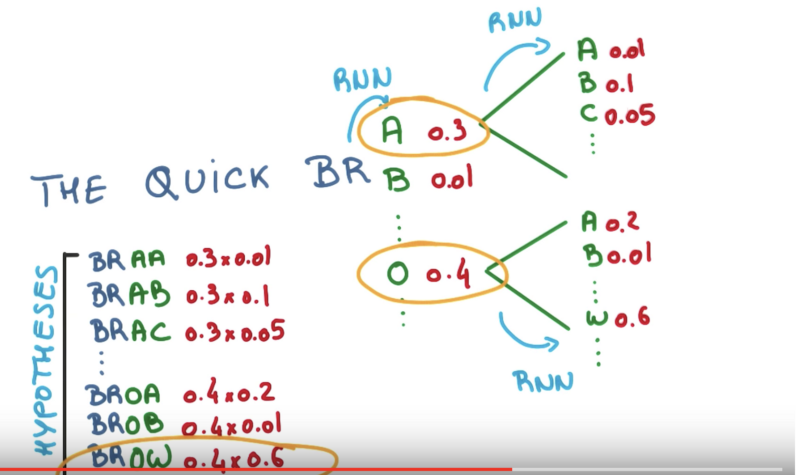 _Beam search for building a sentence. [source](https://www.youtube.com/watch?v=UXW6Cs82UKo" rel="noopener" target="blank" title=")
_Beam search for building a sentence. [source](https://www.youtube.com/watch?v=UXW6Cs82UKo" rel="noopener" target="blank" title=")
Review
Up to this point, you’ve learned about creating a model architecture to generate a sentence, given an image. This is done by utilizing a CNN to create a dense embedding and feeding this as initial state to an LSTM. Additionally, you’ve learned how to generate better sentences with beam search.
In the next section, you’ll learn to generate captions from a pre-trained model in Tensorflow.
Creating captions in Tensorflow
# Project Structure
├── Dockerfile├── bin│ └── download_model.py├── etc│ ├── show-and-tell-2M.zip│ ├── show-and-tell.pb│ └── word_counts.txt├── imgs│ └── trading_floor.jpg├── medium_show_and_tell_caption_generator│ ├── __init__.py│ ├── caption_generator.py│ ├── inference.py│ ├── model.py│ └── vocabulary.py└── requirements.txt
Environment setup
Here, you’ll use Docker to install Tensorflow.
Docker is a container platform that simplifies deployment. It solves the problem of installing software dependencies onto different server environments. If you are new to Docker, you can read more here. To install Docker, run:
curl https://get.docker.com | sh
After installing Docker, you’ll create two files. A requirements.txt for the Python dependencies and a Dockerfile to create your Docker environment.
To build this image, run:
$ docker build -t colemurray/medium-show-and-tell-caption-generator -f Dockerfile .
# On MBP, ~ 3mins# Image can be pulled from dockerhub below
If you would like to avoid building from source, the image can be pulled from dockerhub using:
docker pull colemurray/medium-show-and-tell-caption-generator # Recommended
Download the model
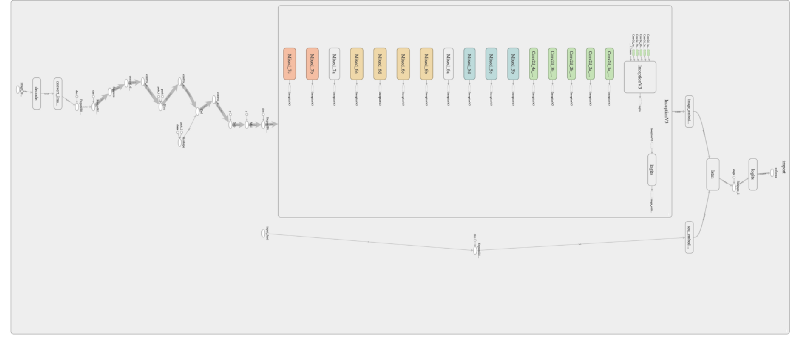 _Show and Tell Inference Architecture [source](http://blog.murraycole.com/wp-content/uploads/2018/04/show_and_tell_inception_expanded.png" rel="noopener" target="blank" title=")
_Show and Tell Inference Architecture [source](http://blog.murraycole.com/wp-content/uploads/2018/04/show_and_tell_inception_expanded.png" rel="noopener" target="blank" title=")
Below, you’ll download the model graph and pre-trained weights. These weights are from a training session on the MSCOCO dataset for 2MM iterations.
To download, run:
docker run -e PYTHONPATH=$PYTHONPATH:/opt/app -v $PWD:/opt/app \-it colemurray/medium-show-and-tell-caption-generator \python3 /opt/app/bin/download_model.py \--model-dir /opt/app/etc
Next, create a model class. This class is responsible for loading the graph, creating image embeddings, and running an inference step on the model.
Download the vocabulary
When training an LSTM, it is standard practice to tokenize the input. For a sentence model, this means mapping each unique word to a unique numeric id. This allows the model to utilize a softmax classifier for prediction.
Below, you’ll download the vocabulary used for the pre-trained model and create a class to load it into memory. Here, the line number represents the numeric id of the token.
# File structure# token num_of_occurrances
# on 213612# of 202290# the 196219# in 182598
curl -o etc/word_counts.txt https://raw.githubusercontent.com/ColeMurray/medium-show-and-tell-caption-generator/master/etc/word_counts.txt
To store this vocabulary in memory, you’ll create a class responsible for mapping words to ids.
Creating a caption generator
To generate captions, first you’ll create a caption generator. This caption generator utilizes beam search to improve the quality of sentences generated.
At each iteration, the generator passes the previous state of the LSTM (initial state is the image embedding) and previous sequence to generate the next softmax vector.
The top N most probable candidates are kept and utilized in the next inference step. This process continues until either the max sentence length is reached or all sentences have generated the end-of-sentence token.
Next, you’ll load the show and tell model and use it with the above caption generator to create candidate sentences. These sentences will be printed along with their log probability.
Results
To generate captions, you’ll need to pass in one or more images to the script.
docker run -v $PWD:/opt/app \-e PYTHONPATH=$PYTHONPATH:/opt/app \-it colemurray/medium-show-and-tell-caption-generator \python3 /opt/app/medium_show_and_tell_caption_generator/inference.py \--model_path /opt/app/etc/show-and-tell.pb \--input_files /opt/app/imgs/trading_floor.jpg \--vocab_file /opt/app/etc/word_counts.txt
You should see output:
Captions for image trading_floor.jpg: 0) a group of people sitting at tables in a room . (p=0.000306) 1) a group of people sitting around a table with laptops . (p=0.000140) 2) a group of people sitting at a table with laptops . (p=0.000069)
 Generated Caption: a group of people sitting around a table with laptops
Generated Caption: a group of people sitting around a table with laptops
Conclusion
In this tutorial, you learned:
- how a convolutional neural network and LSTM can be combined to generate captions to an image
- how to utilize the beam search algorithm to consider multiple captions and select the most probable sentence.
Complete code here.
Next Steps:
- Try with your own images
- Read the Show and Tell paper
- Create an API to serve captions
Call to Action:
If you enjoyed this tutorial, follow and recommend!
Interested in learning more about Deep Learning / Machine Learning? Check out my other tutorials:
- Deep Learning CNN’s in Tensorflow with GPUs
- Deep Learning with Keras on Google Compute Engine
- Recommendation Systems with Apache Spark on Google Compute Engine
Other places you can find me:
- Twitter: https://twitter.com/_ColeMurray