
By Mariya Yao
This popular internet meme demonstrates the alarming resemblance shared between chihuahuas and muffins. These images are commonly shared in presentations in the Artificial Intelligence (AI) industry (myself included).
But one question I haven’t seen anyone answer is just how good IS modern AI at removing the uncertainty of an image that could resemble a chihuahua or a muffin? For your entertainment and education, I’ll be investigating this question today.

Binary classification has been possible since the perceptron algorithm was invented in 1957. If you think AI is hyped now, the New York Times reported in 1958 that the invention was the beginning of a computer that would “be able to walk, talk, see, write, reproduce itself and be conscious of its existence.” While perceptron machines, like the Mark 1, were designed for image recognition, in reality they can only discern patterns that are linearly separable. This prevents them from learning the complex patterns found in most visual media.
No wonder the world was disillusioned and an AI winter ensued. Since then, multi-layer perceptions (popular in the 1980s) and convolutional neural networks (pioneered by Yann LeCun in 1998) have greatly outperformed single-layer perceptions in image recognition tasks.
With large labelled data sets like ImageNet and powerful GPU computing, more advanced neural network architectures like AlexNet, VGG, Inception, and ResNet have achieved state-of-the-art performance in computer vision.
Computer vision and image recognition APIs
If you’re a machine learning engineer, it’s easy to experiment with and fine-tune these models by using pre-trained models and weights in either Keras/Tensorflow or PyTorch. If you’re not comfortable tweaking neural networks on your own, you’re in luck. Virtually all the leading technology giants and promising startups claim to “democratize AI” by offering easy-to-use computer vision APIs.
Which one is the best? To answer this question, you’d have to clearly define your business goals, product use cases, test data sets, and metrics of success before you can compare the solutions against each other.
In lieu of a serious inquiry, we can at least get a high-level sense of the different behaviors of each platform by testing them with our toy problem of differentiating a chihuahua from a muffin.
Conducting the test
To do this, I split the canonical meme into 16 test images. Then I use open source code written by engineer Gaurav Oberoi to consolidate results from the different APIs. Each image is pushed through the six APIs listed above, which return high confidence labels as their predictions. The exceptions are Microsoft, which returns both labels and a caption, and Cloudsight, which uses human-AI hybrid technology to return only a single caption. This is why Cloudsight can return eerily accurate captions for complex images, but takes 10–20 times longer to process.
Below is an example of the output. To see the results of all 16 chihuahua versus muffin images, click here.
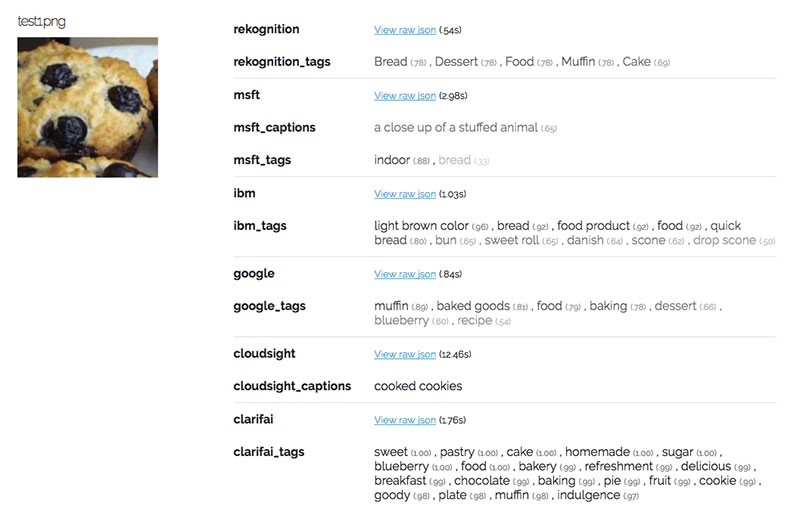
How well did the APIs do? Other than Microsoft, which confused this muffin for a stuffed animal, every other API recognized that the image was food. But there wasn’t an agreement about whether the food was bread, cake, cookies, or muffins. Google was the only API to successfully identify muffin as the label that is most probable.
Let’s look at a chihuahua example.
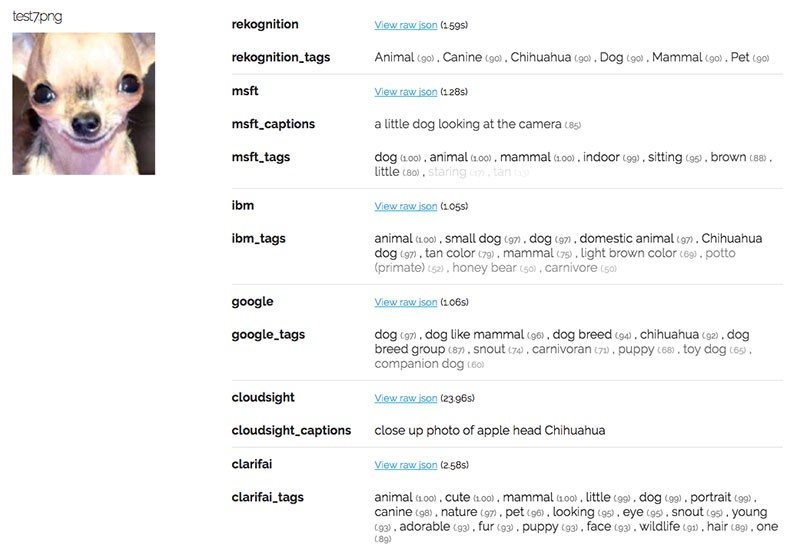
Again, the APIs did rather well. All of them realized that the image is a dog, although a few of them missed the exact breed.
There were definite failures, though. Microsoft returned a blatantly wrong caption three separate times, describing the muffin as either a stuffed animal or a teddy bear.
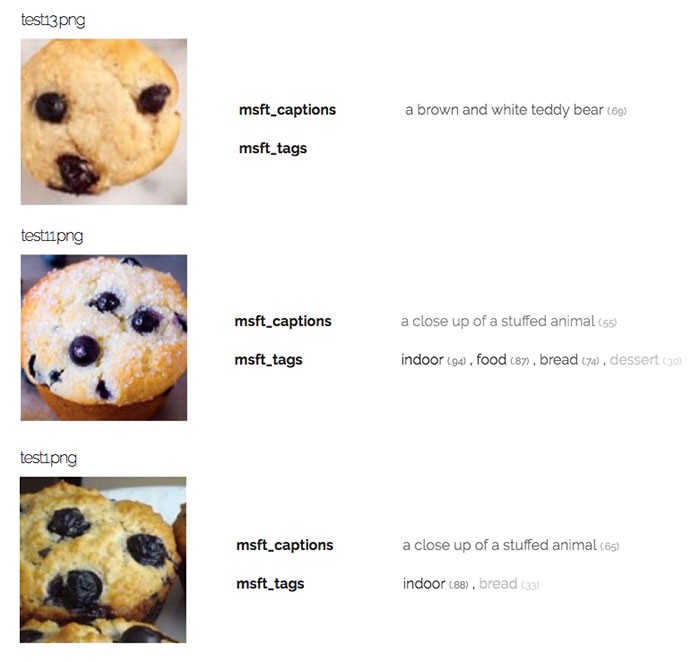
Google was the ultimate muffin identifier, returning “muffin” as its highest confidence label for 6 out of the 7 muffin images in the test set. The other APIs did not return “muffin” as the first label for any muffin picture, but instead returned less relevant labels like “bread”, “cookie”, or “cupcake.”
However, despite its string of successes, Google did fail on this specific muffin image, returning “snout” and “dog breed group” as predictions.

Even the world’s most advanced machine learning platforms are tripped up by our facetious chihuahua versus muffin challenge. A human toddler beats deep learning when it comes to figuring out what’s food and what’s Fido.
So which computer vision API is the best?
In order to find out the answer to this elusive mystery, you’ll have to head over to TOPBOTS to read the original article in full!