
There are three types of storage options offered by most cloud providers: block storage, file storage, and object storage (often referred to as BLOB or Binary Large Object).
This tutorial will explain these types of storage, their real-world use cases, and some trade-offs.
What is Block Storage?
Imagine you have a large bookshelf with many shelves, and each shelf can hold a specific number of pages from a book.
Now, let's say you have a collection of books, but they are all different sizes. To efficiently store these books, you decide to divide them into smaller uniform pieces, called blocks, that fit nicely on the shelves.
Each shelf can only store 100 pages from a book. The Great Gatsby has about 200 pages, so each shelf can only store half the book. Therefore, this single book will be stored in two separate shelves as shown below, with half of the book in one location and the other in another location.
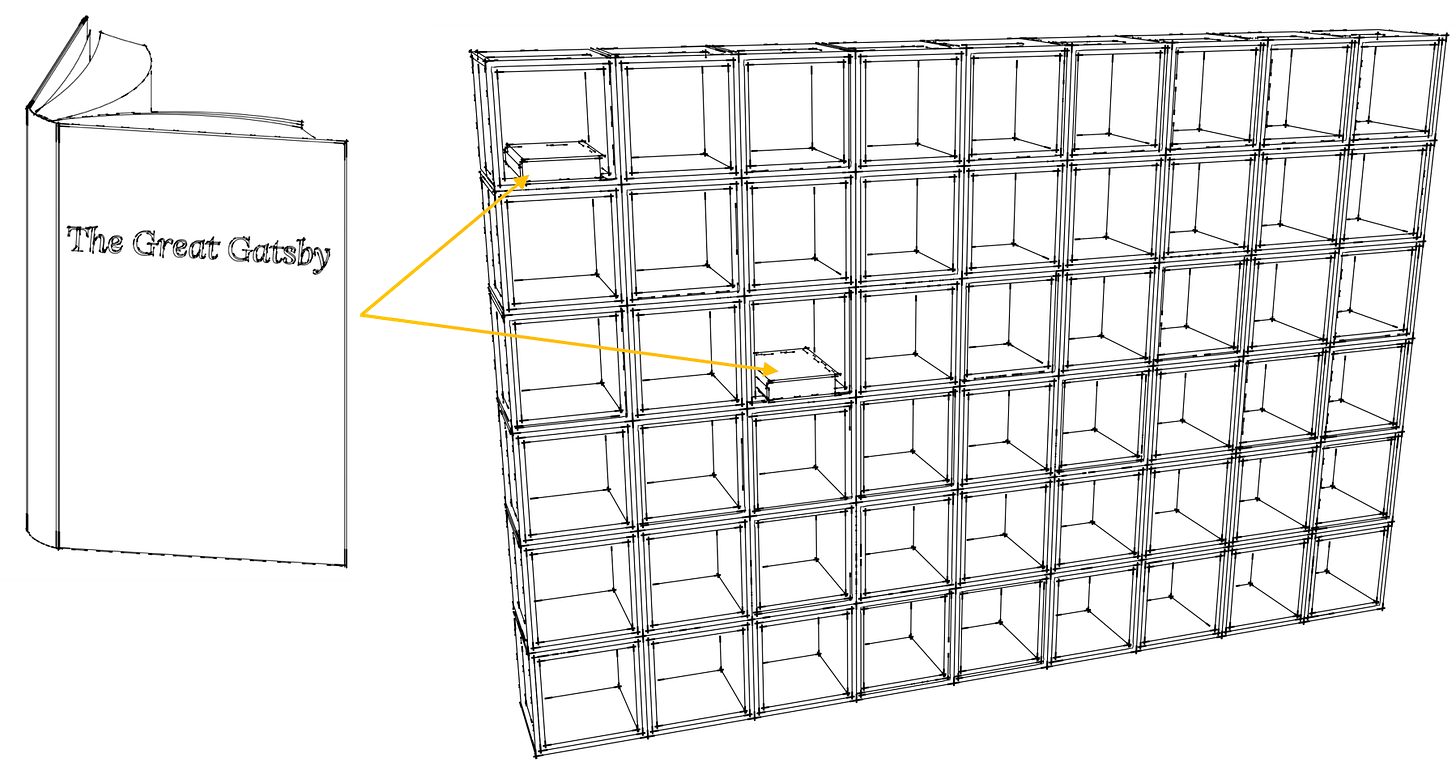
We have defined a block as the maximum number of pages that can be stored in a shelf. In this example, the block size is 100 pages.
With block storage, data is divided into fixed-size blocks, just like the pages of a book in our analogy. These blocks are usually several thousand bytes.
Each block is assigned a unique address, similar to the location of a specific book (or pages of a book) on a shelf. These addresses allow you to quickly find and access individual blocks of data without having to go through the entire storage.
When you want to store or retrieve data using block storage, you interact with the blocks directly. You can write new data to an empty block or overwrite existing data in a block. If you need to retrieve specific information, you can request the block by its unique address, and it will be returned to you.
Hard disk drives (HDD) and solid state drives (SSD) that are attached to a computer physically or via a network are examples of block storage devices.
The main cloud providers all have block storage options:
AWS – Elastic Block Storage (EBS)
GCP – Persistent Disks
Azure – Managed Disks
Block storage devices are usually only attached to a single instance. This is one way in which block storage differs from file storage, which I will explain in the next section.
Physically attached block storage is not persistent, meaning it only lasts as long as the instance is not terminated. Network attached block storage persists beyond the life of the instance.
Bringing back the analogy of storing a fixed number of pages from a book in a bookshelf, block storage will allow you to modify or retrieve specific pages without having to handle the entire book.
However, why would you ever need to do this? Isn’t it better to simply have the shelves store a book in its entirety?
For humans, this is certainly preferred. For computers, storing information in blocks has some advantages.
Since block storage presents raw blocks to the compute instance, the instance has flexibility over how the blocks are managed. This is ideal for applications that require high performance and low latency storage like databases, high performance computing applications and ETL (Extract Transform Load), among other applications.
Block storage devices are also used to store the operating system. They are also bootable. “Bootable” simply refers to the ability of a device to start or initiate the process of loading an operating system or software program when a computer is powered on or restarted.
A bootable device contains the necessary files and data that enable a computer to begin its startup sequence and load the operating system into the computer's memory.
What is File Storage?
Block storage is the lowest level abstraction of storage. It provides a low-level interface where you can read from or write to individual blocks of data. But it does not inherently understand the concept of files, directories, or the hierarchical structure typically associated with file systems.
File storage is an abstraction built on top of block storage. It introduces the concept of files, directories, and a hierarchical structure for organising and managing data.
With file storage, you can group related blocks of data together to form files and organise files within directories. This allows for a more intuitive way to access and manage data, as you can work with files and directories rather than dealing with individual blocks.
Using our bookshelf analogy, with file storage, all you interact with are files and their hierarchies, just like how a book store can organise their books in a structured way to make it easier for customers to find and browse through the selections. Books can be arranged alphabetically by author name, by genre, or a combination of both as shown below.
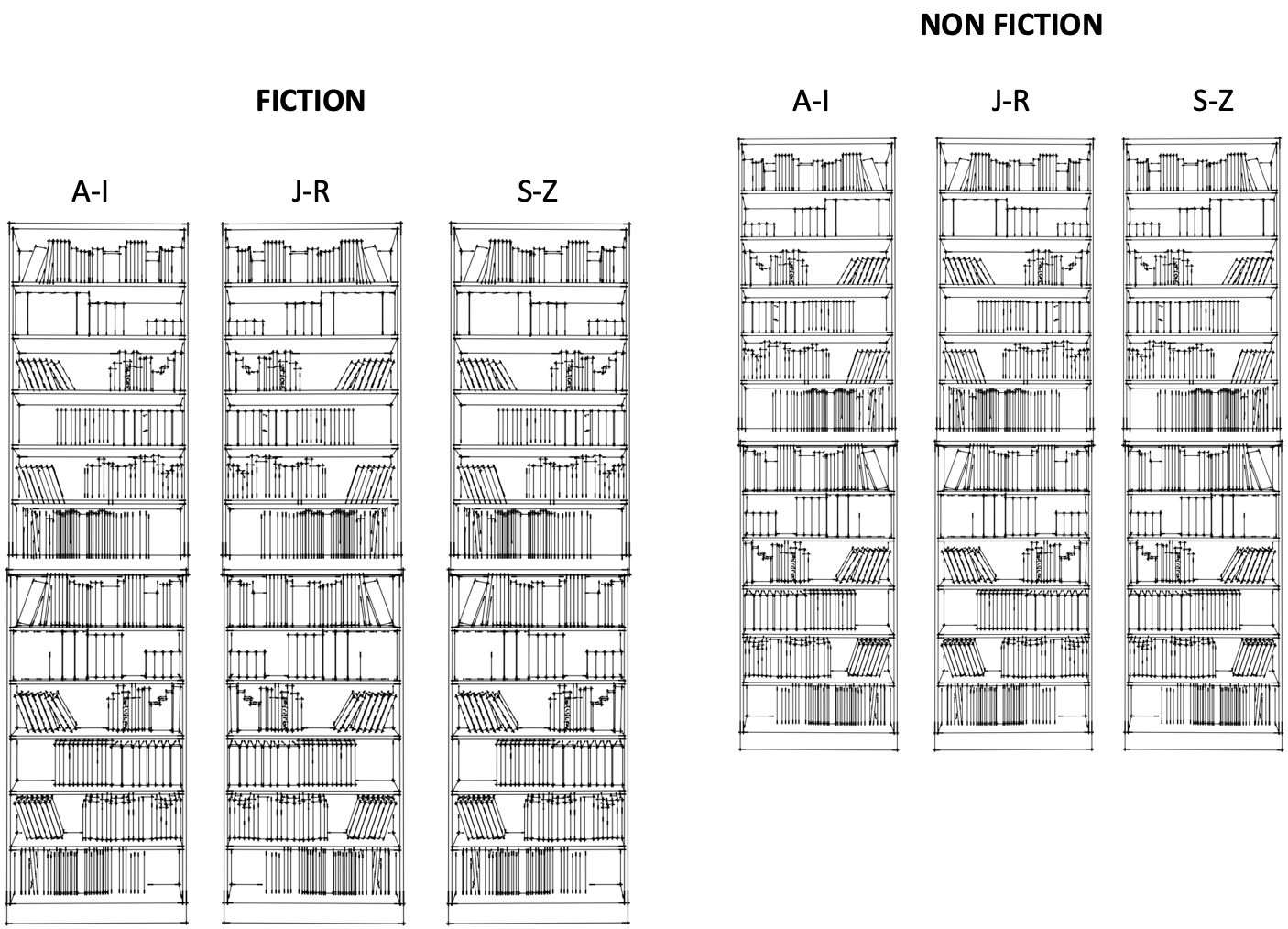
Books can also be further arranged by sub genres (science fiction, fantasy, mystery etc), bestsellers, new releases, books on sale, staff recommendations and children’s books.
Similarly with file storage, you have flexibility over the hierarchical structure which makes it easier for the users (humans or other applications) to access data.
This hierarchical file structure is just an abstraction. Behind the scenes, the operating system abstracts away the underlying block storage and instead gives the appearance of a file cabinet with a folder-like structure. This simplifies access to applications trying to read or write files on the disk.
Applications don’t need to know the underlying block address to retrieve the files, which makes it easier for the application to interact with the files. This ease of interaction comes with a performance cost, which is acceptable for some use cases.
The main cloud providers all have file storage options:
AWS – Elastic File Storage (EFS)
GCP – Cloud Filestore
Azure – Azure Files
Unlike block storage, multiple compute instances can be mounted on the same file storage device.
What is Object Storage?
This is the newest form of storage on the cloud. Object storage stores all data as objects in a flat structure. There is no hierarchy, unlike in file storage. But an artificial folder-like hierarchy is imparted to block storage to give it the appearance of having a structure.
Object storage is highly scalable. It can store multiple billions of objects. As of 2009, it stored 82 billion objects. It would not be a surprise if this has surpassed trillions of objects as of this writing in 2023.
Objects can be any file. It could be video, audio, image, text file, Excel file, word document, HTML, CSS, XML, JSON, and so on.
Object storage is highly durable – that is, there is a very low probability that any object stored there will be lost.
Object storage offered by cloud providers usually provides 99.999999999% durability over a year. This is colloquially referred to as 11 nines of durability.
Durability is defined as the probability of not losing an object. A storage system that has a durability of 99.999999999% has a 0.000000001% chance of losing a single object in a year. This means that even if you have a million objects stored in object storage, you are likely to only lose a single object in 100,000 years.
This is a remarkable level of durability that is not matched by the other storage systems.
Naturally, all these probabilities are meaningless if Earth is destroyed, since all the servers storing these objects currently reside on a single planet.
The main cloud providers all have object storage options:
AWS – S3
GCP – Cloud Storage
Azure – Azure Blob storage
Patterns & Anti-patterns – When to Use Each Storage Type
The table below summarises the trade-offs between the different storage types plus some use cases.
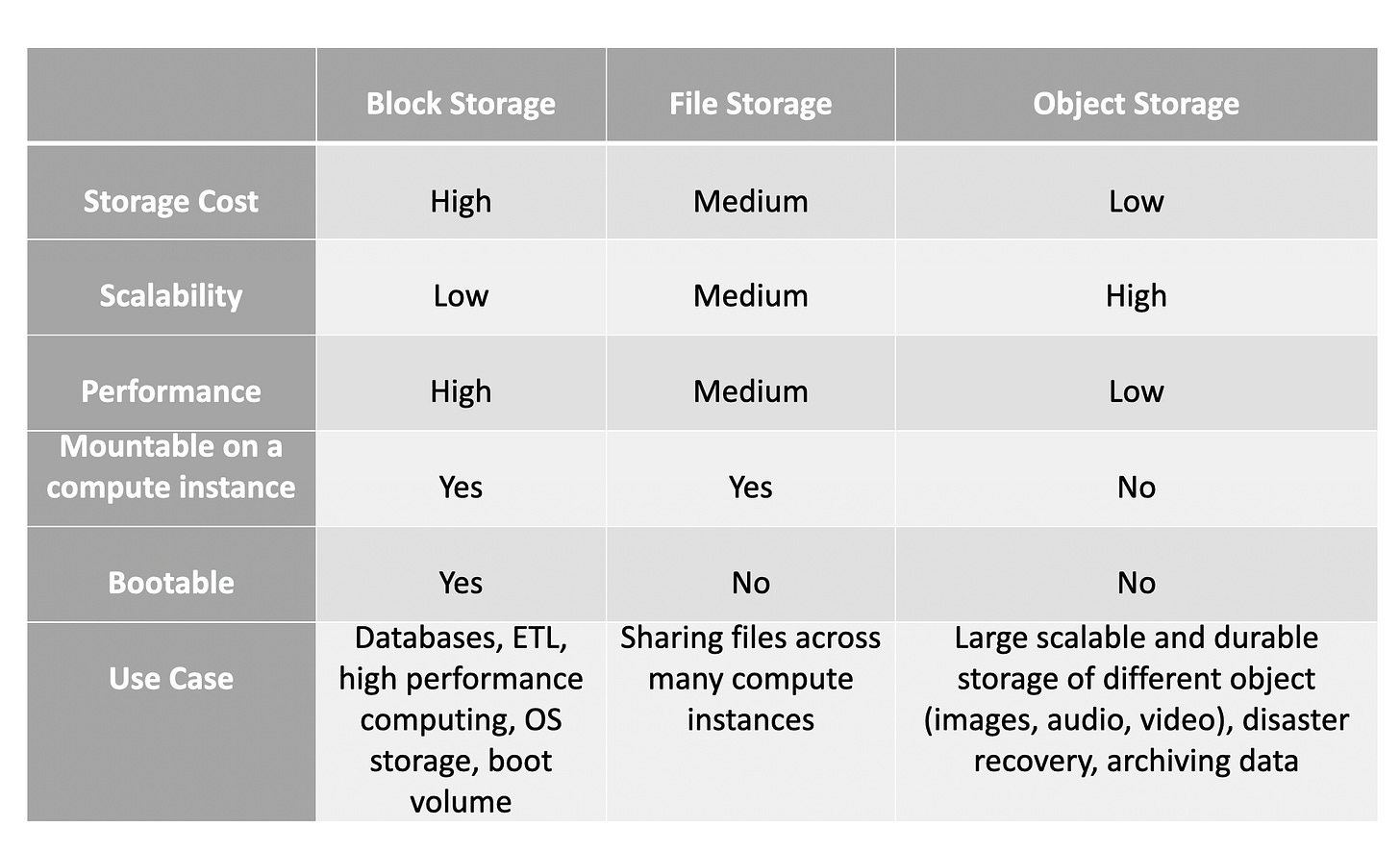
Note: "Mountable" refers to the capability of connecting or attaching a storage device or file system to a specific location in a computer's file system hierarchy.
When a storage device or file system is "mountable," it means that it can be integrated and made accessible to the operating system and applications running on the computer.
As you can see in the image above, some common use cases for each storage type are as follows:
Block storage: databases, ETL, high performance computing, OS storage, and boot volume
File storage: sharing files across many compute instances
Object storage: large, scalable, and durable storage of different objects (like images, audio, and video), disaster recovery, and archiving data.
Bringing it Together
Let’s imagine a simple scenario where you would need to use block, file, and object storage together.
Imagine you have been tasked with designing the cloud architecture for a law firm. You need to store a large number of evidence files in different formats (audio, video, image, text, Excel, JSON, and so on).
You need to processes these files, extract the useful information, and make it available for further processing by different people. You also need to make it available for direct use to a team of lawyers in different parts of the world.
From a high level, how could you design such a solution?
You can see how to do this in the image below:
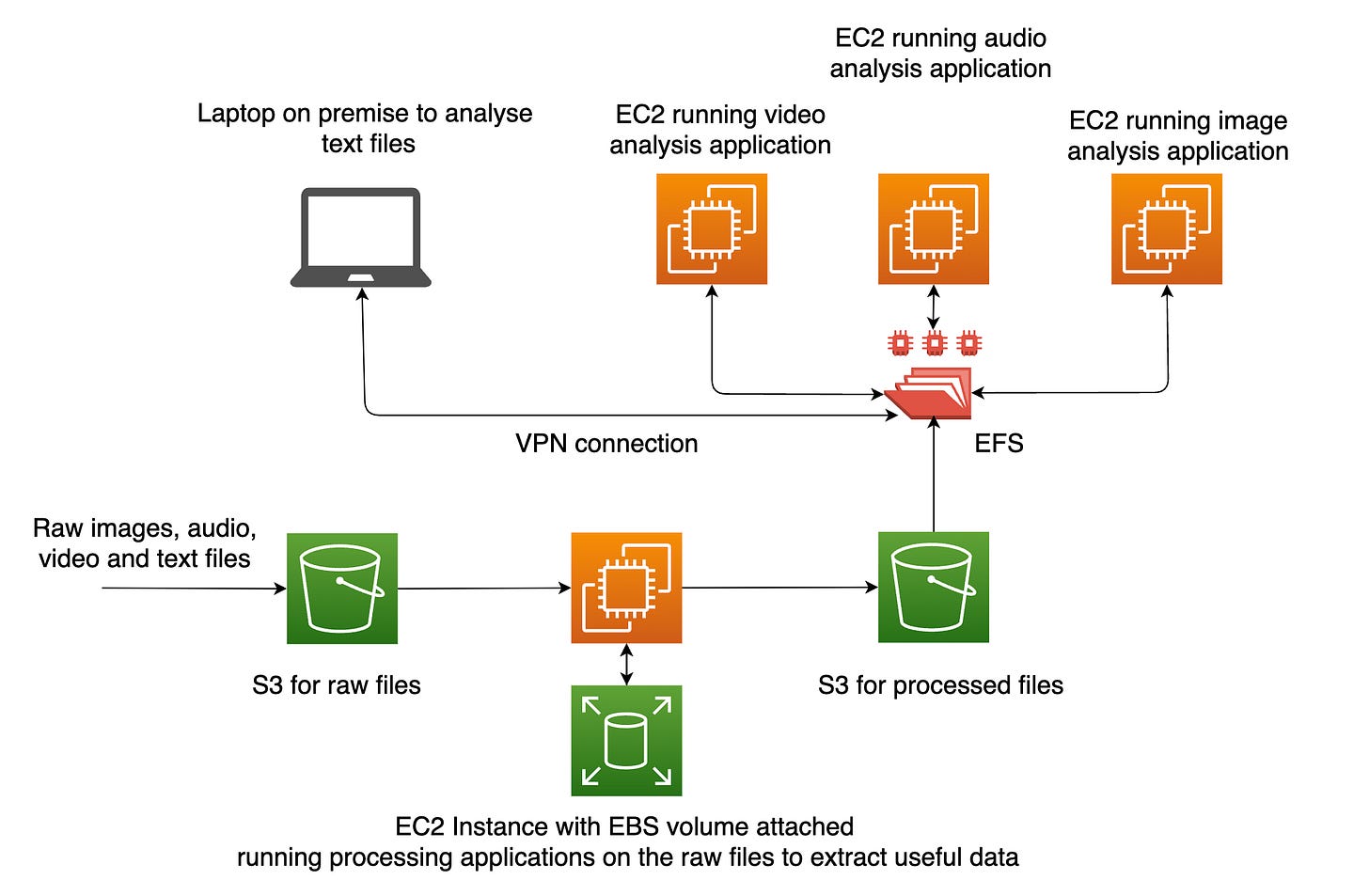
First, the raw files could be stored using either object storage or file storage. Object storage is preferable because it is lower cost. It is also ideal for low cost archival storage if you need to keep files for several years.
To process the files, you can run multiple applications on an EC2 instance that uses block storage. The other alternative is to use file storage.
Block storage is preferable because these processing tasks may include things like transcribing audio files, extracting text from images, improving and stabilising video files, a database that extracts data in JSON format and stores it in a relational database, and so on. These are all tasks that require higher performance, which is an ideal use case for block storage.
The processed files are then stored in S3 again before they are loaded into a file system with several instances mounted on it.
The up-to-date processed files must be available for further processing or for direct use by a team of lawyers. Block storage is not ideal here because block storage cannot be shared across multiple instances. Object storage is also not ideal because its not mountable (can’t be attached to a compute instance).
In this case, file storage is ideal because it has non of these constraints – it can be shared across multiple instances and it is mountable.
Summary
In summary, block storage is ideal for high performance applications. File storage is ideal for sharing files across multiple instances.
Like block storage, file storage is mountable – that is, it can be integrated and made accessible to the operating system and applications running on the instance.
Object storage is ideal for low cost durable and scalable storage where high performance is not important.
Thank you for reading!