
By Aakash Jhawar
Social network analysis involves studying patterns in large real life networks that are comprised of millions of nodes. If you have a basic knowledge of graph theory.), you can perform these analyses.
The digital world has opened up a totally different way of creating relationships. It's also unleashed an ocean of data we can analyze to get a better understanding of human behavior.
Social media data refers to all of the raw insights and information collected from an individual's social media activity. We can create networks from these social media activities to get a better perception of that individual.
These networks can range widely and might include your Facebook friends, the products you recently purchased on Amazon, the tweets you liked or retweeted, your favorite food you ordered from Zomato, the search you made on Google, or the image you recently liked on Instagram.
Companies use these networks to classify their users into different groups. This helps them
- do market research
- generate leads
- better serve their customers
- find and share photos and videos
- discover and discuss trending content
- share information about services and restaurants
- connect with others around a shared interest or hobby
- and more.
The list is pretty much endless.
Before we get too into the weeds, let’s quickly break down the distinction between different components of a network.
 Communities in a Social Network
Communities in a Social Network
What is a Network?
A network is a web of interconnected personal relationships. For example, different individuals can communicate with one another in a social media group through a dynamic web of relationships.
A network is comprised of nodes (individual actors, people, or things within the network) and the ties, edges, or links (relationships or interactions) that connect them.
What is a group?
Reicher S. D. in The determination of collective behavior describes a group as a collection of individuals who consider themselves to be a group. Members of the same group have a set of shared beliefs and behaviors.
What is a community?
According to David W. McMillan (Sense of Community: A Definition and Theory), the community can be defined as the following:
_“Sense of Community is a feeling that members have of belonging, a feeling that members matter to one another and to the group, and a shared faith that members’ needs will be met through their commitment to be together.”_
Communities or sub-units are the sub-networks in a network that are highly interconnected nodes.
The community indicates the existence of internal structures that have special characteristics or play the same role in a network.
Highly connected groups of individuals or objects inside these networks are communities. It usually lies at the intersection point of the network and group.
Now that we have a clear idea of what a network, group, and community is, let’s dive deeper into how these networks are divided into small communities.
We will look at the popular Fast Unfolding Algorithm. Vincent C. Blondel and the co-authors of the paper compared this algorithm with other community detection algorithms. They discovered that this algorithm outperforms every other algorithm in large networks.
What is the Fast Unfolding Algorithm?
The Fast Unfolding Algorithm was used to identify language communities in a Belgian mobile phone network of 2.6 million customers.
It was also used to analyze a web graph of 118 million nodes and more than one billion links.
Identifying communities in such a huge network took only 152 minutes. So this algorithm is both fast and efficient.
How the algorithm works
The algorithm works in two phases:
Phase 1
- Assign a different community to each node in a network.
- Then, for each node, i considers node j and evaluates the gain in modularity by removing node i from its community and placing it in the community of j.
- The node i is placed in the community for which it gains max modularity, but gain should be positive. If the gain is negative, then the node i remains in the same community.
Phase 2
- The second phase of the algorithm consists in building a new network whose nodes are now the communities found during the first phase. So, we build nodes by merging all the nodes in the community as a single node.
- Weights of the link between the nodes are given by the sum of the weights of the links between nodes in the corresponding two communities.
- Link between nodes of the same community leads to self-loops for the community in the new network.
- Repeat Phase 1 until no further improvement can be achieved.
How Gain in Modularity is calculated
The Quality of Partition (Q) is measured by the Modularity (aka modularity of partition). Its a scalar value between -1 and 1, and measures the density of links inside communities as compared to links between communities.
The Gain in Modularity (∆Q) obtained by moving an isolated node i into a community C can easily be computed by:
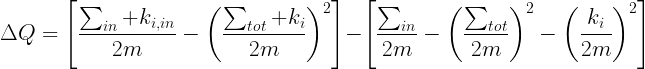
Σin is the sum of the weights of the links inside C.
Σtot is the sum of the weights of the links incident to nodes in C.
ki is the sum of the weights of the links from i to the node in C.
m is the sum of the weights of all the links in the network.
Gain in Modularity is evaluated by removing i from its community and then moving it into a neighboring community. If the gain is positive then that node is placed into the neighboring community.
 Working of Fast Unfolding Algorithm
Working of Fast Unfolding Algorithm
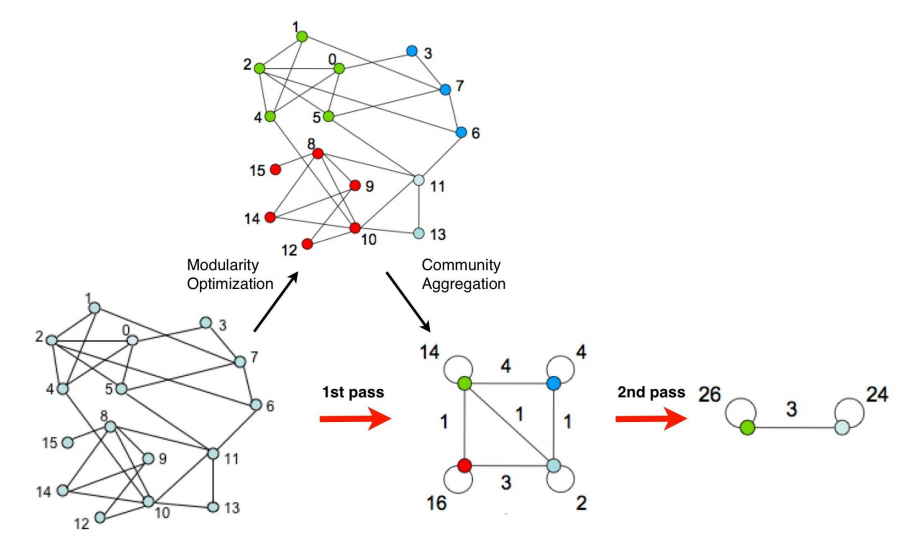
Dry run of the algorithm
In the network on the left (15 nodes), we first assign a unique community to each node. Then, we evaluate the Modularity of each node and reassign the community based on the gain. This is called Modularity Optimization.
In the next phase, we build nodes by merging all the nodes in that community into a single node. In the green community, we have a total of 5 nodes and there is a total of 7 edges between them.
So after Community Aggregation, the weight of the self-loop of the green node will be 14 (7 * 2 as it is a bidirectional link). Similarly, the weight of the self-loop of the red node will be 16, the blue node will be 4, and the light blue node will be 2.
The weight of the edge between green and the blue node will be 4 as there are a total of 4 edges between the green and blue community after Modularity Optimization.
In the next step, we re-evaluate the Modularity for the new nodes and do the same process again.
Finally, we get two communities, Green and Light Blue. The Green community has 26 self-loops as there are a total of 13 edges between the nodes of the green community. And we have 12 edges in the light blue community, a total of 24 self-loops.
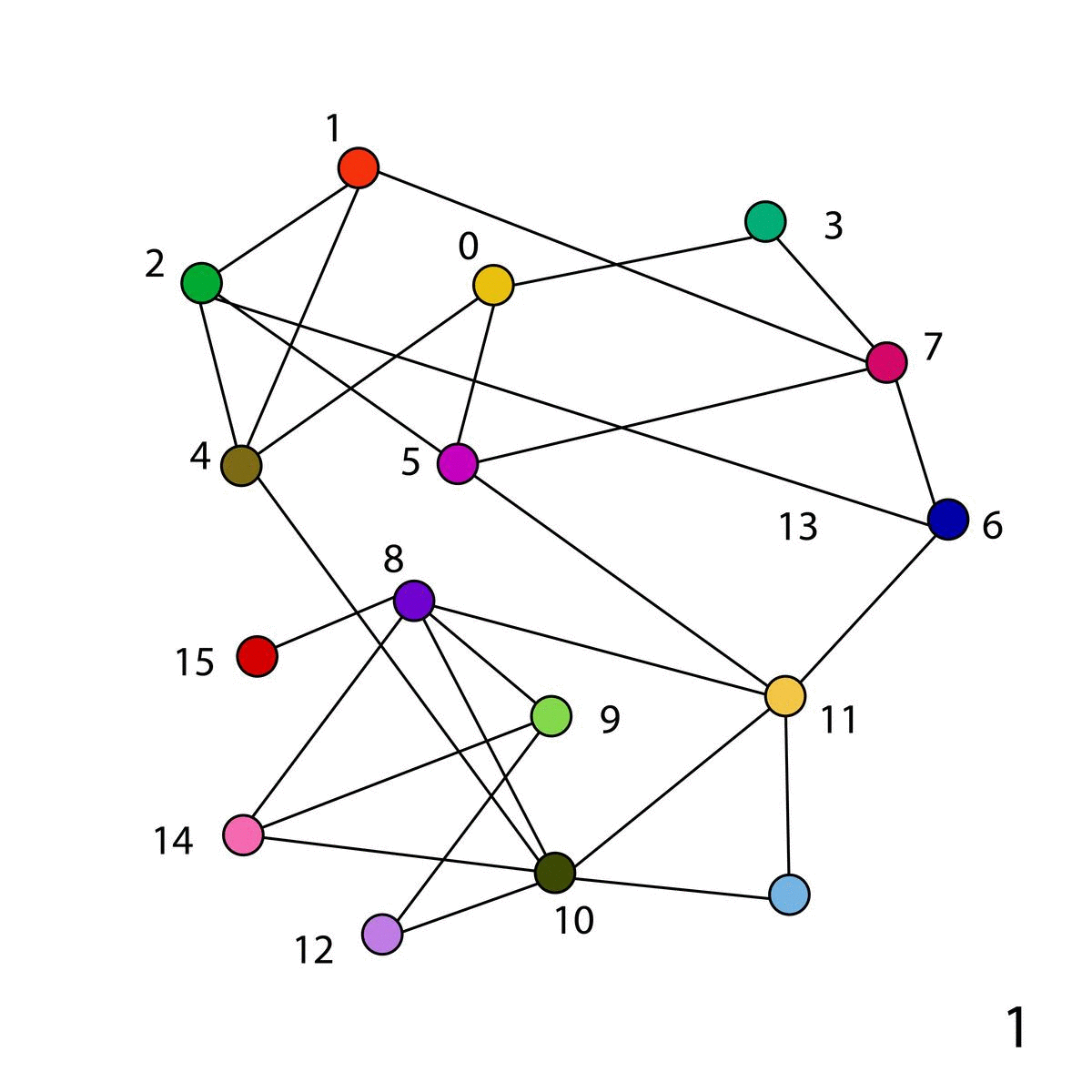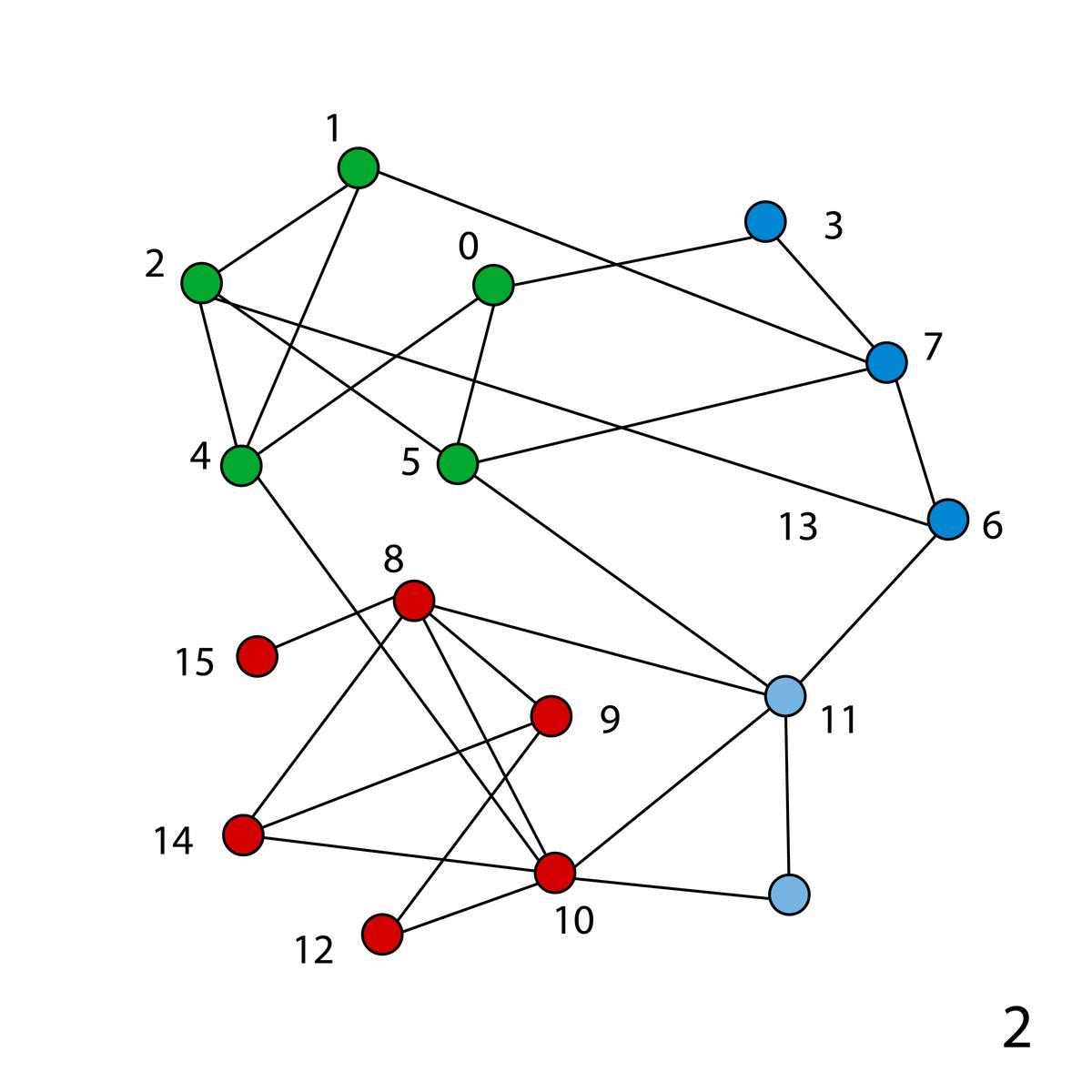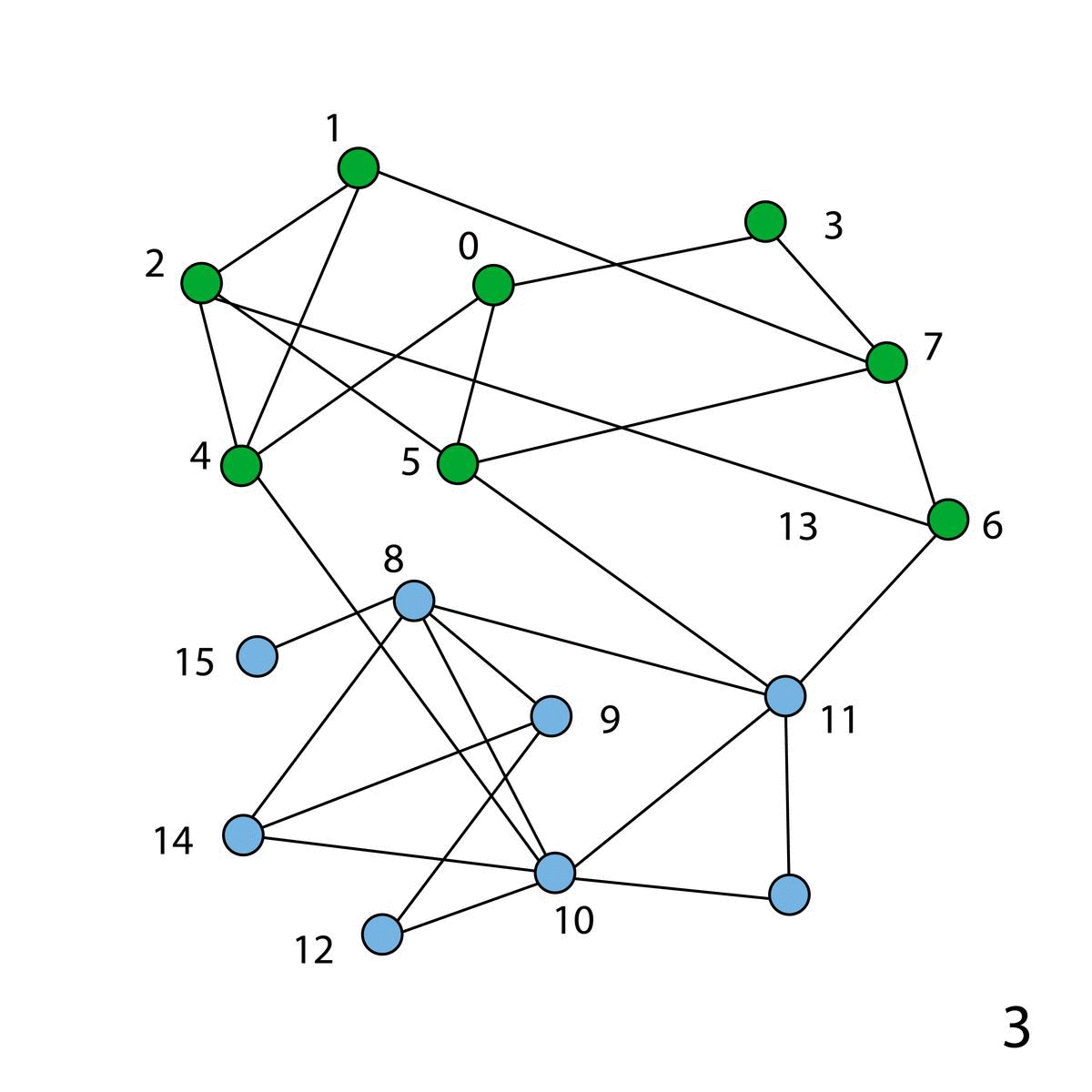 Community Detection in Network
Community Detection in Network
Advantages of the algorithm
- Its steps are intuitive and easy to implement and the outcome is unsupervised.
- The algorithm is extremely fast. Computer simulations on very huge modular networks suggest that its complexity is linear on the typical and sparse data. This might be because Gain in Modularity is easy to compute and the number of communities decreases drastically after just a few passes.
Limitations of the algorithm
- The modularity optimization fails to identify communities smaller than a certain scale. So, it causes a resolution limit on the community computed using a pure modularity optimization approach.
- For small networks, the probability that two separate communities can be merged by moving each node is very low.
Conclusion
If you’ve hung in there this long… thanks! I hope there’s been valuable information for you.
So now you know how the Fast Unfolding Algorithm works, and that it's extremely efficient to detect communities in very large networks.
The way it calculates Gain in Modularity makes the algorithm outperform every other algorithm out there. Drop me a note if you find it useful or have any follow-up questions.
Thanks for reading!