
In this tutorial, we will explore concurrency in Python. We'll discuss Threads and Processes and how they're similar and different. You'll also learn about Multi-threading, Multi-processing, Asynchronous Programming, and Concurrency in general in Python.
Many tutorials discuss these concepts, but they can be challenging to grasp due to the lack of clear examples. I will guide you through the concepts and delve into the world of Concurrency in Python, providing straightforward explanations for better understanding.
Prerequisites
You should be familiar with Python coding and have a basic understanding of multi-threading.
Although I have provided non-multi-threading code examples to help those who are not acquainted with these concepts, if you already have knowledge in these areas, you'll be able to gain a deeper understanding.
Table of Contents
- Sequential Programming
- What Are Threads?
- What Are Processes?
- Threads vs Processes
- What is Multi-Threading?
- What is Multi-Processing?
- What is Asynchronous Programming?
- What is Concurrency?
- Global Interpreter Lock (GIL)
- How to Remove the Limitations of GIL
– Using another flavor of Python
– Multiprocessing module
– Asyncio - Summary
Sequential Programming
Don't be afraid when you see the word "Concurrency". Let's set it aside for now.
When you begin learning programming languages like Python or Java, your program usually runs in a sequence, starting from the top and going down.
For example:
a = 25
b = 30
def add(a, b):
print("Addition value: ", a+b)
def sub(a, b):
print("Subtraction Value: ", a-b)
add(a,b)
sub(a,b)
When you run the program above, your Python interpreter starts executing it line by line from top to bottom in a sequence. It starts from line a=25 and ends at the sub() function.
No matter how long your code is, Python executes it from the top. This way of executing code is also known as the top-to-bottom or sequential approach – or simply Sequential programming!
What Are Threads?
When you run your program, the Python interpreter creates a small program internally and instructs it to start running. This small program, created by the interpreter, is called a Thread. A thread is a small program that performs a certain task.
For any program or application, Python creates and instructs a thread to start execution. This thread is called the Main thread. It's important to note that the Main thread can also create multiple other threads if you tell it to do so.
That's correct! You can write a program to tell the Main thread to create multiple other threads that perform your tasks. So, a thread performs some work or a task (here main thread runs your program from top to bottom).
So you can create multiple tasks and assign one thread to perform one task. Or you can also create one thread and run multiple tasks – just like Python interpreter created Main thread and executed both the tasks add and sub in sequential order.
What Are Processes?
Imagine you own a company and have many tasks to do. To handle them, you will begin hiring people and assigning a task to each person.
Each person works independently on their task. They have their own set of tools and resources, and if one person finishes their task, it doesn't directly affect what the others are doing.
In the world of computers, each person doing a task is like a separate process. Processes are independent, have their own memory space, and don't directly share resources.
For instance, when you turn on your computer and begin opening a browser, notepad, and MS Office, you are essentially starting several processes. Each program you open, like the browser or notepad, is a separate process with its own memory. These processes are not connected to each other.
When you run a program, your operating system creates a process, assigns some memory to it, dedicates some CPU time, and executes the program within it. How the program functions within the process is determined by how it's designed. In essence, we can say that an application is a process.
Threads vs Processes
Now, that may seem confusing, right? But there is a small difference between threads and processes. Let me clarify it for you.
A process is like a single task performed by the operating system. It works on its own and has its own memory space.
A thread is like a smaller part of a task within a program. It handles small tasks. Threads are created within a process and are controlled by the program.
A program can create multiple threads and they can share resources, communicate with each other, but only within the same process.
To simplify, think of a browser as a process. Within this process, it can run single or multiple threads.
When you learn about concurrency in programming, you will see terms like "Multi-Threading", "Multi-Processing", "Asynchronous", and finally the big one "Concurrency". Don't let these terms intimidate you – the concepts are simpler than you think. And they're what you'll learn about next.
What is Multi-Threading?
Life is easier when you have a lot of workers to complete all the necessary tasks, isn't it? Similarly, if you have multiple threads, they help you divide all your program tasks into smaller parts.
Of course, if you have a lot of workers, then it can be tough to manage them, and it costs more. These are the advantages and disadvantages to multi-threading as well.
Using multiple threads to perform your tasks is called multi-threading.
Let's revisit the example:
a = 25
b = 30
def add(a, b):
print("Addition value: ", a+b)
def sub(a, b):
print("Subtraction Value: ", a-b)
add(a,b)
sub(a,b)
You can tell the Python interpreter to create two threads and execute the add() with thread-1 and sub() with thread-2. This is fine, but why would you want to do that?
Consider the sequential approach: the interpreter runs add() first, then sub(). Why wait for sub() while add() is running? In this case, addition and subtraction are entirely different and don't depend on each other, so why wait? Can't both functions run simultaneously?
This is where multiple threads come into play. If your tasks are independent and don't need to wait for one another to complete, then you have the privilege to run your tasks using multiple threads.
Note that whether you create one thread or more, your Python interpreter will create the main thread and handle the execution of your program. If you instruct your program to create 2 threads, the main thread will create them for you and assign which task needs to be done by each thread.
So, irrespective of whether you create a thread in your program or not, the main thread will be created, and it takes care of your program execution.
What is Multi-Processing?
From the name itself, you may be able to understand that multiprocessing means running multiple processes separately without sharing resources directly.
For instance, imagine two restaurants, each with its own chefs. The method one chef in Restaurant 1 uses to cook a dish doesn't affect or rely on Restaurant 2. They operate independently, even if you place the same order at both restaurants.
But you might be wondering: how do we talk about multitasking on a computer with one processor but many CPU cores?
In modern computers, some processors have multiple cores, and each core works like its own processor. If a processor has 4 cores, it can handle 4 tasks simultaneously by assigning each task to a different core. This means the CPU, memory, and storage resources are shared among these tasks without them relying on each other.
This approach to multitasking on multiple cores within one processor is known as Symmetric Multiprocessing.
If you have multiple processors, you can assign each task to a different processor to execute independently. This type of multi-processing is called Distributed Multi-processing.
I want to remind you that multi-threading occurs within a process. Simply put, multi-threading only happens within a process.
Let's gain a practical understanding of multiprocessing. I will be using the same example that we discussed in the Sequential Programming and Multi-threading sections, but this time using a multiprocessing version.
Just as you ran the program using threads, we will now run the program using processes.
from multiprocessing import Process
a = 25
b = 30
def add(a, b):
try:
print("Addition value: ", a + b)
time.sleep(10)
except Exception as e:
print(e)
def sub(a, b):
try:
print("Subtraction Value: ", a - b)
time.sleep(20)
except Exception as e:
print(e)
if __name__ == "__main__":
# Create two processes, one for add and one for sub
add_process = Process(target=add, args=(a, b))
sub_process = Process(target=sub, args=(a, b))
# Start the processes
add_process.start()
sub_process.start()
# Wait for both processes to finish
add_process.join()
sub_process.join()
We are using the multiprocessing module in this program to create 2 processes: add_process and sub_process. One process runs the add() function and another runs the sub() function, respectively.
We then start both the processes using the .start() method of both the process objects. After this, we are using the .join() method of the process objects to make the main thread wait until both processes complete.
Let's understand this in a bit more detail. I am running the program in a Windows operating system-based computer. Open the task manager application to view all the running processes in your operating system. For running your program, you have to use your Window's command prompt or cmd or your terminal in your Linux or Mac.
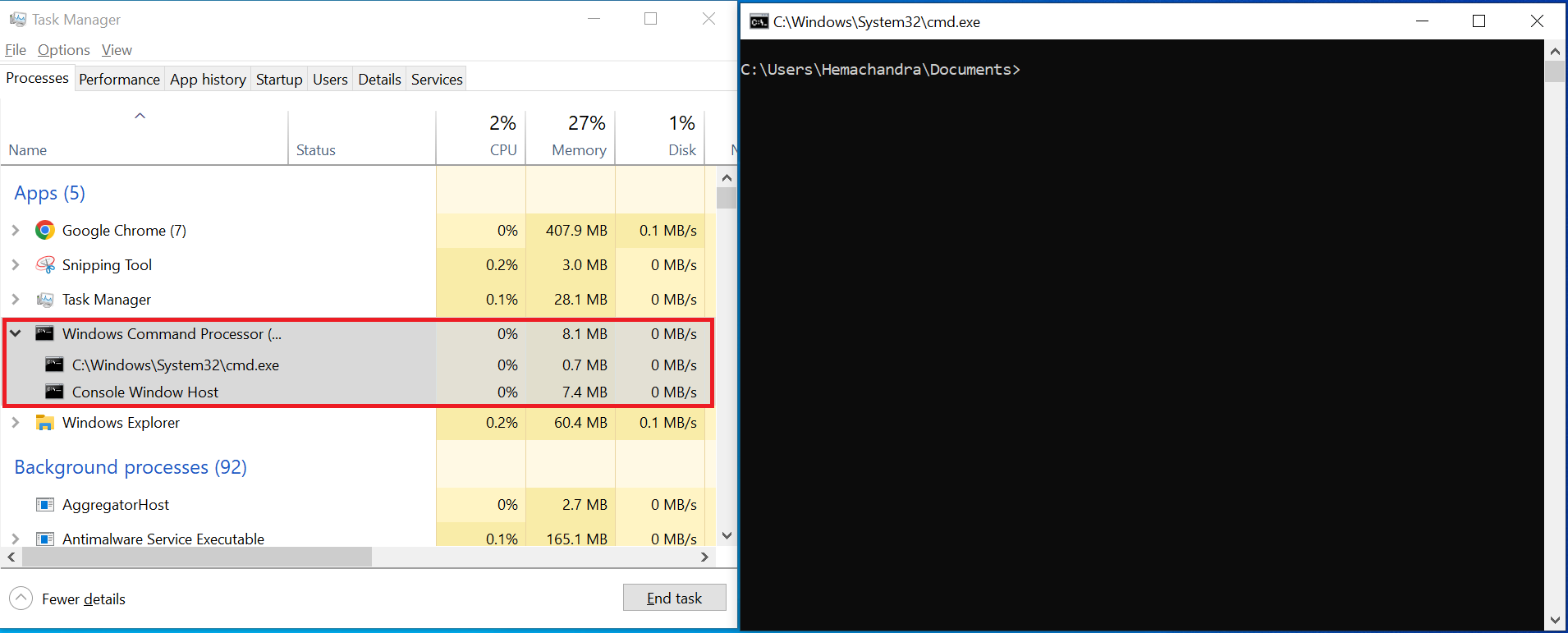 TaskManager and CMD
TaskManager and CMD
The image above shows task manager on the left and CMD on the right. You can easily see the Windows Command Processor, or CMD, running as a process in the task manager. You can also see that I am running Google Chrome and the Snipping Tool in the background, both of which are also listed in my Task Manager.
I am going to run the program now from CMD by executing the command python sample.py, where sample is the name of the program.
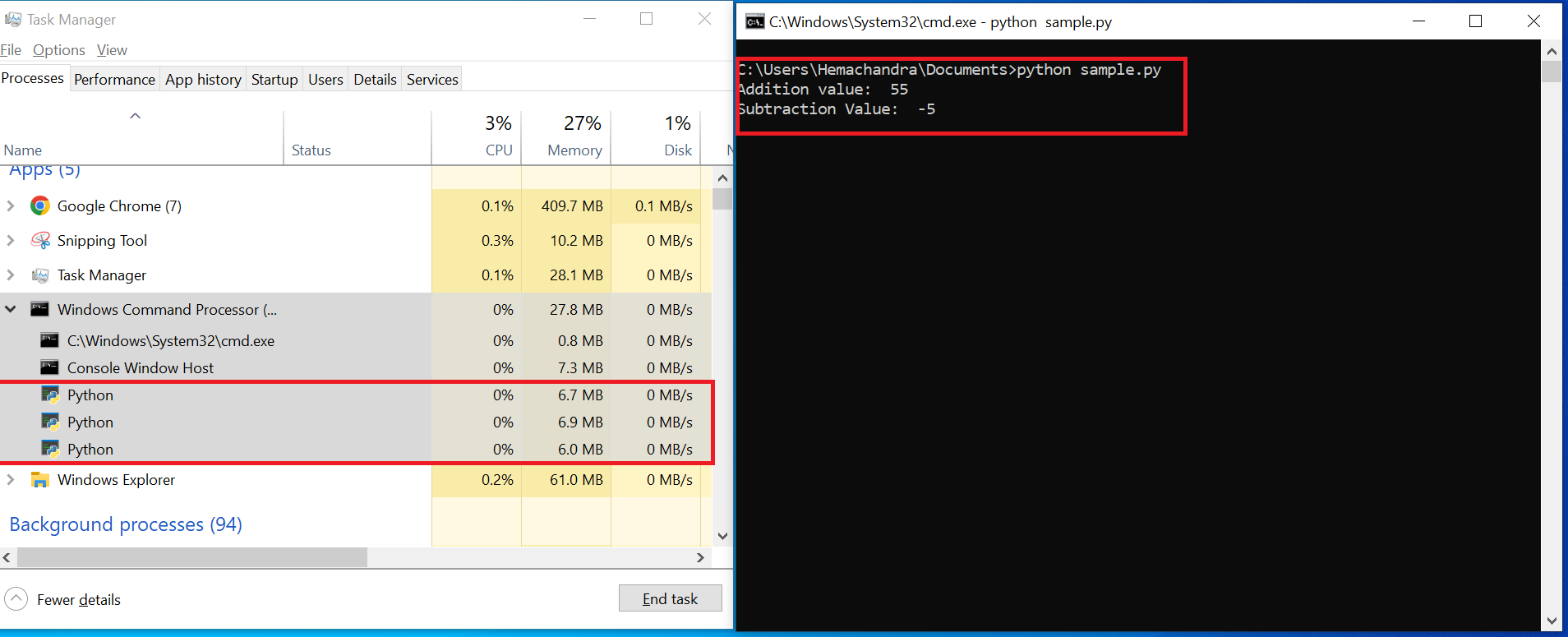 Running the sample.py in CMD
Running the sample.py in CMD
In the image above, I am running the program in CMD on the right. The program immediately printed the output of both the functions add() and sub(). The program is still running, because we used time.sleep() in both functions, which pauses the execution of the add_process for 10 seconds and sub_process for 20 seconds.
Setting the output aside, let's shift our focus to the Task Manager. If you expand the Windows Command Processor, you will find 3 Python processes running. Let's explore why there are three Python processes instead of two (add_process and sub_process).
Since we initiated the program via CMD, your Python application is triggered through the Windows Command Processor or CMD and is therefore listed under CMD. We already know that when you run a Python program, your Python interpreter starts the Main Thread, which manages the execution of the program.
This Main Thread is listed as one process. Then, as we are creating two processes within the program, they are listed as an additional two processes under the Windows Command Processor (as seen in the image above).
Note that both the processes are completely independent and don't share any resources. If you want to share anything between the processes then you have to implement special mechanisms like a Queue.
What is Asynchronous Programming?
Asynchronous programming is a specific approach to managing tasks that involves waiting for external operations to complete. It allows a program to continue executing other tasks while waiting for these operations to finish, rather than blocking until they complete.
Note: If you are not familiar with Multi-threaded coding in Python, you can skip to example-2.
Example 1:
Same example again, but this time the functions are executed using threads. add() is executed by thread-1 and sub() is executed by thread-2. Following is the threading version of the example:
import threading
import time
a = 25
b = 30
def add(a, b):
print("Inside add function\n")
print("Waiting for 20 seconds in add \n")
time.sleep(20)
print("Addition value:", a + b)
def sub(a, b):
print("Inside sub function\n")
print("Subtraction Value {}:".format(a - b))
print("Waiting for 10 seconds in sub\n")
time.sleep(10)
# Create threads for add and sub functions
add_thread = threading.Thread(target=add, args=(a, b))
sub_thread = threading.Thread(target=sub, args=(a, b))
# Start both threads
add_thread.start()
sub_thread.start()
# Wait for both threads to finish
add_thread.join()
sub_thread.join()
print("Complete")
We created add_thread and sub_thread and assigned the functions add and sub as target. If you run this program, you can see the following output:
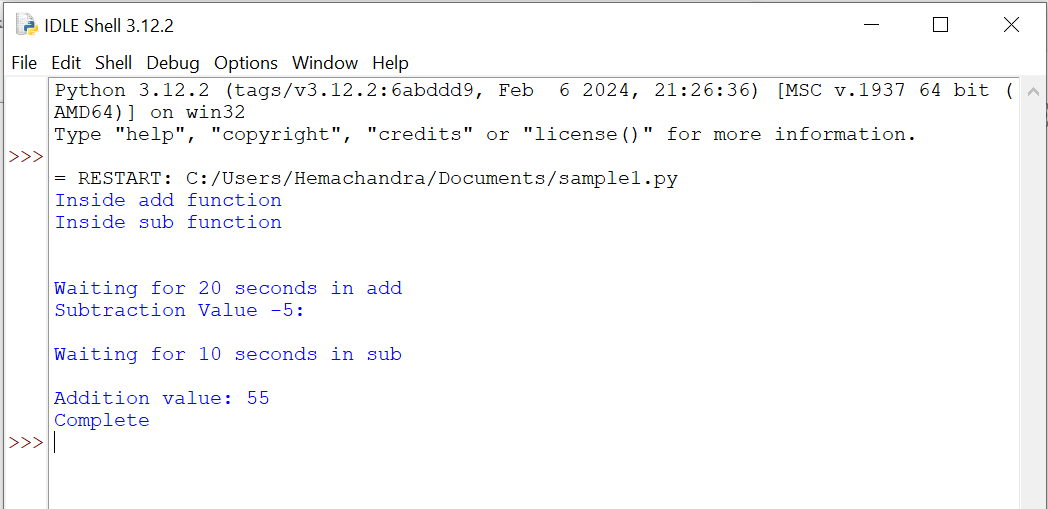 Program output
Program output
Let's breakdown the output:
- Both
addandsubfunctions are started using separate threads (add_threadandsub_thread). - The
addfunction prints "Inside add function" and then indicates that it is waiting for 20 seconds usingtime.sleep(20). - The
subfunction prints "Inside sub function" and "Subtraction Value -5:" (result of the subtraction operation), followed by a message that it is waiting for 10 seconds usingtime.sleep(10). - As the threads are running at the same time, the messages from both functions may appear interleaved, depending on the execution order of the threads.
- After the waiting periods, both threads print the results of their respective operations. The
addfunction prints "Addition value: 55," and thesubfunction prints nothing else. - Finally, the main program prints "Complete" once both threads have finished their execution.
While the add_thread() is waiting for 20 seconds, your sub_thread() has provided the result and started to sleep for 10 seconds. Meanwhile, add_thread completed its wait time, computed the addition value, and printed the result. So, while one thread is waiting, your second thread started executing, and while your second thread was waiting, your first thread started running.
This way of managing the tasks to execute simultaneously when one task is waiting for external resources is called Asynchronous programming.
The key point to note is that threads run simultaneously, allowing the program to perform tasks in parallel. The interleaved output demonstrates the asynchronous nature of threading, where different parts of the program can execute simultaneously.
Example 2:
Let's consider two tasks: Task 1 retrieves a list of employees from a company's database, and Task 2 retrieves a list of active projects by the same company. It's clear that these tasks are not connected or dependent on each other – they are independent tasks.
Let's write some sample code for these tasks:
def get_employees():
# connect to the database
# code to get employees list from database
return employees_list
def get_active_projects():
# connect to the database
# code to get the projects under development
return active_projects
# run task1
get_employees()
# run task2
get_active_projects()
Don't worry about the code inside the functions – we want to understand the concept here.
When you run the program above, the Python interpreter tells the main thread to execute the program step by step, starting from the top and going downwards.
First, it performs task-1, which let's say takes 2 seconds, and then it moves on to task-2, which let's say also takes 2 seconds. We know that these tasks are independent, so why should task-2 wait for task-1 to finish?
If there's a mechanism where I can tell the interpreter to start task-1 (getting a list of employees from the database), and while it waits for task-1 to complete, I can also instruct it to start task-2 (getting a list of active projects from the database), then I'm essentially executing both tasks almost simultaneously. This helps me reduce the total execution time of both tasks. This is another example of asynchronous programming.
Now it's clear. How do we do this? How do we ensure that task-2 runs while we're waiting for task-1 to get the list of employees from the database? We have many tools for that. Multithreading is one of them.
In the example above, you use two threads: thread-1 for task-1 and then immediately start thread-2 for task-2. Thread-2 doesn't have to wait for Thread-1 to finish.
You can also use concepts like async/await, callbacks, and promises in various programming languages to implement asynchronous programming. You can read more about those concepts in JavaScript here.
What is Concurrency?
Finally, we've arrived at concurrency!
You should now understand that multi-threading or multi-processing involves using several threads and processes to perform multiple tasks simultaneously to decrease the time it takes for a program or application to run.
But how does this occur? What goes on in the background? How does the processor ensure that the threads or processes run simultaneously?
Imagine you have two tasks: driving a car and making a phone call. You decide to do both at once. While driving, you start calling your friend using your cell phone and speaking.
You're doing these tasks simultaneously, but there's a small detail that's important: your brain quickly scans the road, checks for other cars, and ensures you're focused and steady. It spends about one millisecond here, then switches to speaking with your friend, which might take another millisecond, and then shifts back to driving every millisecond. It continuously switches between both tasks.
As the time spent on each task is very short (just one millisecond), you might think you're doing both tasks at the same time. But there's a very tiny difference in time for each task, which makes it seem like both tasks are being done simultaneously.
In a similar way, when there are two tasks being executed by either two threads or two processes, your processor switches between these tasks very quickly. It runs thread-1 for 1 millisecond, then saves its state and switches to thread-2, running it for another 1 millisecond. After saving the state of thread-2, it shifts back to thread-1 and runs it for another millisecond.
I'm using 1 millisecond as an example, but in reality, it happens even faster. The speed of switching depends on your processor.
As the switching between tasks is so fast, it gives the impression that both tasks are running simultaneously. But it's important to note that even if you ask for both thread-1 and thread-2 to run at the same time, your processor and operating system decide which one to prioritize first, how much time to allocate to each, and in what order to execute them.
In summary, it's like juggling multiple tasks simultaneously. You start one task, switch to another when needed, and keep cycling through them until everything is done. This concept is called concurrency.
"Concurrency is a concept of managing the progress of multiple tasks at the same time, even if they are not executing simultaneously."
How do you achieve this? Using multi-threading and multi-processing again!
By now, you may have understood that Concurrency and Asynchronous Programming are the core concepts, while multi-threading and multi-processing are implementations of these concepts.
Global Interpreter Lock (GIL)
The concepts of concurrency and asynchronous programming are the same, regardless of what programming language you use. But the implementation of these concepts does depend on the programming language you choose.
When it comes to multi-threading, Python behaves bit weird. Let's understand this with a small example.
In my childhood, my younger brother and I used to play computer games. My mother made a rule that my brother should play first for 30 min and then I could play second for 30 min. This rule was to make sure that no one messed up the game by trying to do things at the same time. So I would wait for 30 min until my turn came to play the game for 30 min.
In the world of computers, programs are like me and my brother trying to play the game. The Global Interpreter Lock (GIL) is like the rule that only allows one, either me or my brother (or thread), to play the game (or execute Python bytecode) at a time.
GIL is a rule that allows only one thread at a time to run the Python bytecode. Global Interpreter Lock is a lock that protects access to Python objects, preventing multiple threads from executing Python bytecode simultaneously in a single process. This means that even in a multi-threaded Python program, only one thread can execute Python bytecode at any given time.
As a result, this causes performance limitations of multi-threading in CPU-bound tasks. Note that CPU-bound tasks are the tasks that rely a lot on CPU rather than IO operations. Mathematical computations, compression and decompression of files, and compilation of programs by a program compiler are a few examples of CPU-bound tasks that use more CPU.
Let's look at an example:
import time
def count_up():
count = 0
for i in range(100000000):
count = count + i
def count_down():
count = 0
for i in range(100000000):
count = count + i
if __name__ == "__main__":
start_time = time.time()
count_up()
count_down()
end_time = time.time()
print(f"Time taken: {end_time - start_time} seconds")
In the above program, we are running the count_up() and count_down() functions sequentially one after the other. The count_up and count_down functions each iterate through a large range, calculating the cumulative sum of numbers. The output of the program is:
Time taken: 25.86127805709839 seconds
Let's write the same program using multi-threading as follows:
import threading
import time
def count_up():
count = 0
for i in range(100000000):
count = count + i
def count_down():
count = 0
for i in range(100000000):
count = count + i
if __name__ == "__main__":
start_time = time.time()
# Create two threads, each running a CPU-bound task
thread1 = threading.Thread(target=count_up)
thread2 = threading.Thread(target=count_down)
# Start both threads
thread1.start()
thread2.start()
# Wait for both threads to finish
thread1.join()
thread2.join()
end_time = time.time()
print(f"Time taken: {end_time - start_time} seconds")
Two threads thread1 and thread2 are created to run the count_up and count_down functions simultaneously. The program measures the time it takes for both threads to complete using the time module. The output of the program is:
Time taken: 24.498752117156982 seconds
Note that in your PC, the time taken for this program to complete can be different. If you observe, the output for the sequential and multi-threading versions of the program (25.8 seconds vs 24.98 seconds) there is not much difference between the time taken. This is because of GIL.
Global Interpreter Lock (GIL) in CPython, which allows only one thread to execute Python bytecode at a time, means that the execution time won't show a significant improvement compared to running the tasks sequentially.
This highlights the limitation of multithreading in Python for CPU-bound tasks due to GIL.
But it's worth noting that while the GIL prevents multiple threads from executing Python bytecode at the same time, it does not prevent threading altogether. Python threads can still be useful for I/O-bound tasks where threads spend most of their time waiting for external operations (like network or disk I/O) rather than performing CPU-intensive computations.
So how do you remove the limitations of GIL?
Use another flavor of Python
Python standard implementation is Cpython. This is the Python designed using the C language and is used most all over the world. To avoid GIL, we can use Jython (Python developed using Java), IronPython (Python developed using .NET), or PyPy (Python developed using Python).
You can check out the following resources for more info:
Use the multiprocessing module
Multiprocessing is a module that helps you take advantage of your multiple CPU cores for running your program in separate processes.
Each process has its own CPU core, memory, resources, and interpreter. Yes, every process has its own interpreter to run your Python code. If you have 4 CPU cores then you can run 4 processes, each having its own interpreter that executes your application in its own memory.
Let's write the program we discussed in the GIL concept using multi-processing as follows:
import multiprocessing
import time
def count_up():
count = 0
for i in range(100000000):
count = count + i
def count_down():
count = 0
for i in range(100000000):
count = count + i
if __name__ == "__main__":
start_time = time.time()
# Create two threads, each running a CPU-bound task
process1 = multiprocessing.Process(target=count_up)
process2 = multiprocessing.Process(target=count_down)
# Start both threads
process1.start()
process2.start()
# Wait for both threads to finish
process1.join()
process2.join()
end_time = time.time()
print(f"Time taken: {end_time - start_time} seconds")
The output for the program when you run it via your terminal or CMD is:
Time taken: 8.376060724258423 seconds
This represents a significant improvement in the time taken compared to techniques such as Sequential and Multi-threading (25.8 vs 24.4 vs 8.3 seconds). This illustrates how using multiprocessing can help reduce your CPU time.
Note that there will be overhead if you want to communicate between the processes. As a result, while multiprocessing can be effective for CPU-bound tasks, it may not be suitable for all scenarios, especially those involving frequent communication or large data transfers between processes.
Implement asynchronous programming!
If your program or application is not CPU bound heavy or depends more on CPU processing then using the asyncio module of Python, you can implement the concept of Asynchronous Programming (not waiting for task 1 to complete before starting task 2).
This module is mainly used in I/O operations. Asyncio allows you to write asynchronous code that cooperatively multitasks without relying on threads, which can help in situations where threads would otherwise be blocked waiting for I/O operations to complete.
By using asyncio, you can write non-blocking code that allows other tasks to run while waiting for I/O operations to finish, thus potentially improving overall concurrency and responsiveness of your application.
It's important to note that asyncio doesn't eliminate the GIL itself – rather, it provides an alternative concurrency model that can be more efficient for certain types of applications.
For CPU-bound tasks, asyncio may not provide the same performance benefits as multiprocessing or other parallelism techniques, as it still operates within the constraints of the GIL. In such cases, multiprocessing or other concurrency approaches may be more suitable.
Summary
In this article, you learned about the differences between Multi-threading, Multi-processing, Asynchronous Programming, and Concurrency. Let's review them briefly now:
Multi-threading:
- Definition: Multi-threading involves using multiple threads to execute tasks concurrently within a single process. Concurrently is nothing but the concept Concurrency here.
- Clarification: Threads share the same memory space, allowing them to communicate easily but requiring careful synchronization to avoid conflicts.
Multi-processing:
- Definition: Multi-processing involves using multiple processes to run your application or tasks. Each process has its own memory space and resources.
- Clarification: Processes are independent, and communication between them often requires inter-process communication (IPC) mechanisms. Each process operates in its own memory space.
Asynchronous Programming:
- Definition: Asynchronous programming is a programming concept that allows tasks to be executed separately from the main program flow. It doesn't necessarily imply concurrent execution.
- Clarification: Asynchronous tasks don't block the main program, enabling the program to continue its execution while waiting for the asynchronous tasks to complete. This is commonly used in I/O operations to improve efficiency.
Concurrency:
- Definition: Concurrency is a broader concept that refers to the ability of a system to execute multiple tasks in overlapping time intervals, that is switching between the tasks in specific intervals.
- Clarification: Concurrency doesn't guarantee simultaneous execution but rather focuses on efficiently managing multiple tasks by switching between them. It encompasses multi-threading, multi-processing, and asynchronous programming as ways to achieve concurrent execution.
I hope you now have a clear understanding of the concepts that may have seemed scary before. I understand it's mostly theoretical, but I want to ensure you grasp the concept well before diving into the practical aspect.
Until then, your friend here, Hemachandra, is signing off…
For more courses, you can visit my personal website.
Have a great day!