
By Aditya
Have you ever noticed that, when you are writing code in a text editor like VS code, it recognizes things like unmatched braces? And it also sometimes warns you, with an irritating red highlight, about the incorrect syntax that you have written?
If not, then think about it. That is after all a piece of code. How can you write code for such a task? What would be the underlying logic behind it?
These are the kinds of questions that you will face if you have to write a compiler for a programming language. Writing a compiler is not an easy task. It is bulky job that demands a significant amount of time and effort.
In this article, we are not going to talk about how to build compilers. But we will talk about a concept that is a core component of the compiler: Context Free Grammars.
Introduction
All the questions we asked earlier represent a problem that is significant to compiler design called Syntax Analysis. As the name suggests, the challenge is to analyze the syntax and see if it is correct or not. This is where we use Context Free Grammars. A Context Free Grammar is a set of rules that define a language.
Here, I would like to draw a distinction between Context Free Grammars and grammars for natural languages like English.
Context Free Grammars or CFGs define a formal language. Formal languages work strictly under the defined rules and their sentences are not influenced by the context. And that's where it gets the name context free.
Languages such as English fall under the category of Informal Languages since they are affected by context. They have many other features which a CFG cannot describe.
Even though CFGs cannot describe the context in the natural languages, they can still define the syntax and structure of sentences in these languages. In fact, that is the reason why the CFGs were introduced in the first place.
In this article we will attempt to generate English sentences using CFGs. We will learn how to describe the sentence structure and write rules for it. To do this, we will use a JavaScript library called Tracery which will generate sentences on the basis of rules we defined for our grammar.
Before we dive into the code and start writing the rules for the grammar, let's just discuss some basic terms that we will use in our CFG.
Terminals: These are the characters that make up the actual content of the final sentence. These can include words or letters depending on which of these is used as the basic building block of a sentence.
In our case we will use words as the basic building blocks of our sentences. So our terminals will include words such as "to", "from", "the", "car", "spaceship", "kittens" and so on.
Non Terminals: These are also called variables. These act as a sub language within the language defined by the grammar. Non terminals are placeholders for the terminals. We can use non terminals to generate different patterns of terminal symbols.
In our case we will use these Non terminals to generate noun phrases, verb phrases, different nouns, adjectives, verbs and so on.
Start Symbol: a start symbol is a special non terminal that represents the initial string that will be generated by the grammar.
Now that we know the terminology let's start learning about the grammatical rules.
While writing grammar rules, we will start by defining the set of terminals and a start state. As we learned before, that start symbol is a non-terminal. This means it will belong to the set of non-terminals.
T: ("Monkey", "banana", "ate", "the")
S: Start state.
And the rules are:
S --> nounPhrase verbPhrase
nounPhrase --> adj nounPhrase | adj noun
verbPhrase --> verb nounPhrase
adjective --> the
noun --> Monkey | banana
verb --> ate
The above grammatical rules may seem somewhat cryptic at first. But if we look carefully, we can see a pattern that is being generated out of these rules.
A better way to think about the above rules is to visualise them in the form of a tree structure. In that tree we can put S in the root and nounPhrase and verbPhrase can be added as children of the root. We can proceed in the same way with nounPhrase and verbPhrase too. The tree will have terminals as its leaf nodes because that is where we end these derivations.
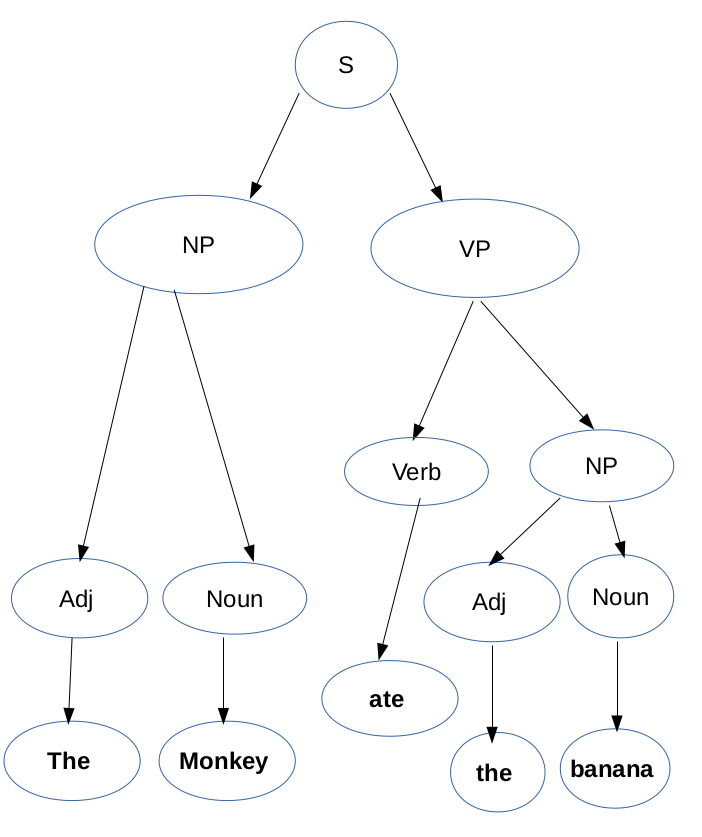
In the above image we can see that S (a nonterminal) derives two non terminals NP(nounPhrase) and VP(verbPhrase). In the case of NP, it has derived two non terminals, Adj and Noun.
If you look at the grammar, NP could also have chosen Adj and nounPhrase. While generating text, these choices are made randomly.
And finally the leaf nodes have terminals which are written in the bold text. So if you move from left to right, you can see that a sentence is formed.
The term often used for this tree is a Parse Tree. We can create another parse tree for a different sentence generated by this grammar in a similar way.
Now let's proceed further to the code. As I mentioned earlier, we will use a JavaScript library called Tracery for text generation using CFGs. We will also write some code in HTML and CSS for the front-end part.
The Code
Let's start by first getting the tracery library. You can clone the library from GitHub here. I have also left the link to the GitHub repository by galaxykate at the end of the article.
Before we use the library we will have to import it. We can do this simply in an HTML file like this.
<html>
<head>
<script src="tracery-master/js/vendor/jquery-1.11.2.min.js"></script>
<script src="tracery-master/tracery.js"></script>
<script src="tracery-master/js/grammars.js"></script>
<script src='app.js'></script>
</head>
</html>
I have added the cloned tracery file as a script in my HTML code. We will also have to add JQuery to our code because tracery depends on JQuery. Finally, I have added app.js which is the file where I will add rules for the grammar.
Once that is done, create a JavaScript file where we will define our grammar rules.
var rules = {
"start": ["#NP# #VP#."],
"NP": ["#Det# #N#", "#Det# #N# that #VP#", "#Det# #Adj# #N#"],
"VP": ["#Vtrans# #NP#", "#Vintr#"],
"Det": ["The", "This", "That"],
"N": ["John Keating", "Bob Harris", "Bruce Wayne", "John Constantine", "Tony Stark", "John Wick", "Sherlock Holmes", "King Leonidas"],
"Adj": ["cool", "lazy", "amazed", "sweet"],
"Vtrans": ["computes", "examines", "helps", "prefers", "sends", "plays with", "messes up with"],
"Vintr": ["coughs", "daydreams", "whines", "slobbers", "appears", "disappears", "exists", "cries", "laughs"]
}
Here you will notice that the syntax for defining rules is not much different from how we defined our grammar earlier. There are very minor differences such as the way non-terminals are defined between the hash symbols. And also the way in which different derivations are written. Instead of using the "|" symbol for separating them, here we will put all the different derivations as different elements of an array. Other than that, we will use the semicolons instead of arrows to represent the transition.
This new grammar is a little more complicated than the one we defined earlier. This one includes many other things such as Determiners, Transitive Verbs and Intransitive Verbs. We do this to make the generated text look more natural.
Let's now call the tracery function "createGrammar" to create the grammar we just defined.
let grammar = tracery.createGrammar(rules);
This function will take the rules object and generate a grammar on the basis of these rules. After creating the grammar, we now want to generate some end result from it. To do that we will use a function called "flatten".
let expansion = grammar.flatten('#start#');
It will generate a random sentence based on the rules that we defined earlier. But let's not stop there. Let's also build a user interface for it. There's not much we will have to do for that part – we just need a button and some basic styles for the interface.
In the same HTML file where we added the libraries we will add some elements.
<html>
<head>
<title>Weird Sentences</title>
<link rel="stylesheet" href="style.css"/>
<link href="https://fonts.googleapis.com/css?family=UnifrakturMaguntia&display=swap" rel="stylesheet">
<link href="https://fonts.googleapis.com/css?family=Harmattan&display=swap" rel="stylesheet">
<script src="tracery-master/js/vendor/jquery-1.11.2.min.js"></script>
<script src="tracery-master/tracery.js"></script>
<script src="tracery-master/js/grammars.js"></script>
<script src='app.js'></script>
</head>
<body>
<h1 id="h1">Weird Sentences</h1>
<button id="generate" onclick="generate()">Give me a Sentence!</button>
<div id="sentences">
</div>
</body>
</html>
And finally we will add some styles to it.
body {
text-align: center;
margin: 0;
font-family: 'Harmattan', sans-serif;
}
#h1 {
font-family: 'UnifrakturMaguntia', cursive;
font-size: 4em;
background-color: rgb(37, 146, 235);
color: white;
padding: .5em;
box-shadow: 1px 1px 1px 1px rgb(206, 204, 204);
}
#generate {
font-family: 'Harmattan', sans-serif;
font-size: 2em;
font-weight: bold;
padding: .5em;
margin: .5em;
box-shadow: 1px 1px 1px 1px rgb(206, 204, 204);
background-color: rgb(255, 0, 64);
color: white;
border: none;
border-radius: 2px;
outline: none;
}
#sentences p {
box-shadow: 1px 1px 1px 1px rgb(206, 204, 204);
margin: 2em;
margin-left: 15em;
margin-right: 15em;
padding: 2em;
border-radius: 2px;
font-size: 1.5em;
}
We will also have to add some more JavaScript to manipulate the interface.
let sentences = []
function generate() {
var data = {
"start": ["#NP# #VP#."],
"NP": ["#Det# #N#", "#Det# #N# that #VP#", "#Det# #Adj# #N#"],
"VP": ["#Vtrans# #NP#", "#Vintr#"],
"Det": ["The", "This", "That"],
"N": ["John Keating", "Bob Harris", "Bruce Wayne", "John Constantine", "Tony Stark", "John Wick", "Sherlock Holmes", "King Leonidas"],
"Adj": ["cool", "lazy", "amazed", "sweet"],
"Vtrans": ["computes", "examines", "helps", "prefers", "sends", "plays with", "messes up with"],
"Vintr": ["coughs", "daydreams", "whines", "slobbers", "appears", "disappears", "exists", "cries", "laughs"]
}
let grammar = tracery.createGrammar(data);
let expansion = grammar.flatten('#start#');
sentences.push(expansion);
printSentences(sentences);
}
function printSentences(sentences) {
let textBox = document.getElementById("sentences");
textBox.innerHTML = "";
for(let i=sentences.length-1; i>=0; i--) {
textBox.innerHTML += "<p>"+sentences[i]+"</p>"
}
}
Once you have finished writing the code, run your HTML file. It should look something like this.
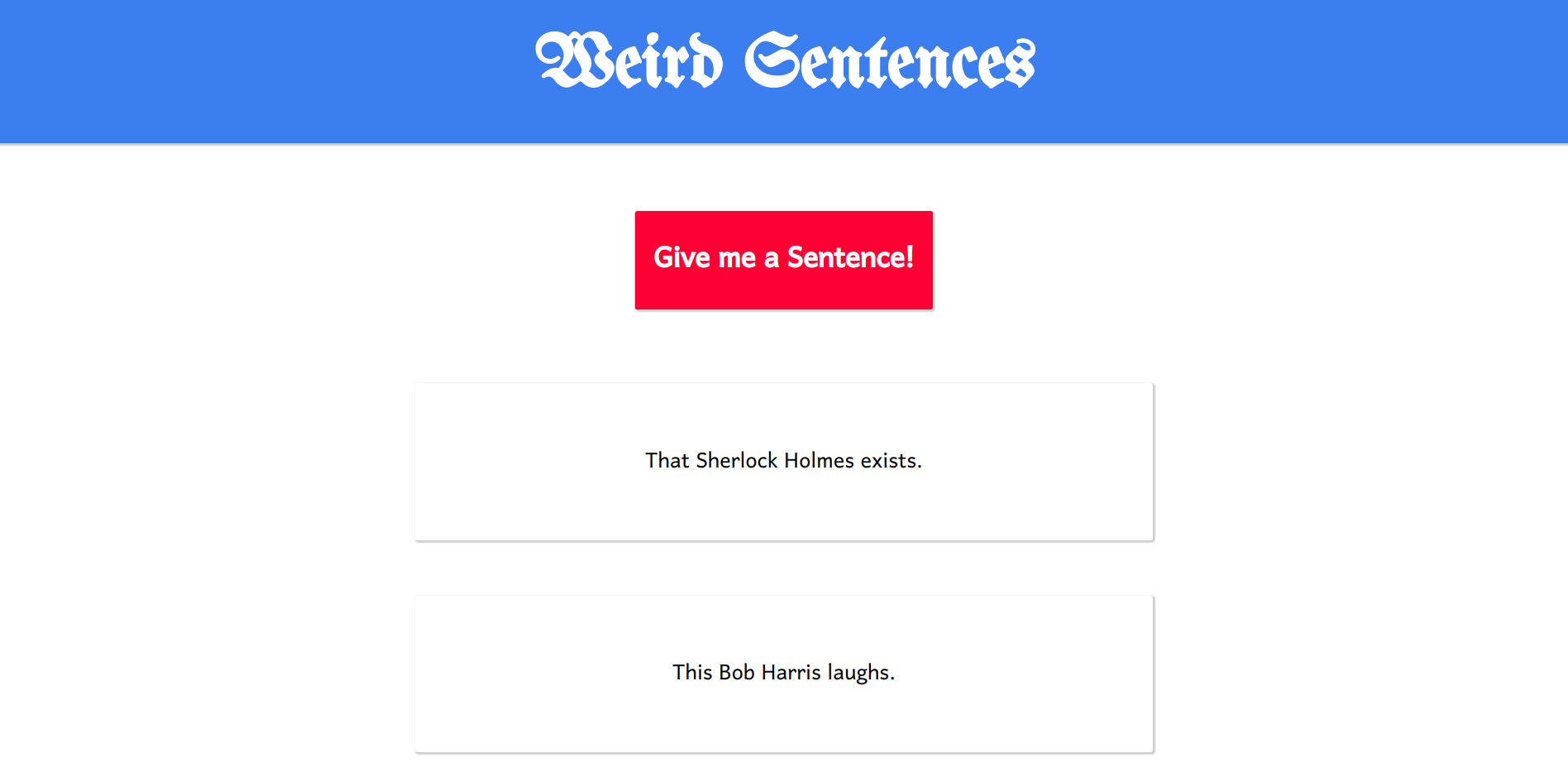
Every time you click the red button it will generate a sentence. Some of these sentences might not make any sense. This is because, as I said earlier, CFGs cannot describe the context and some other features that natural languages possess. It is used only to define the syntax and structure of the sentences.
You can check out the live version of this here.
Conclusion
If you have made it this far, I highly appreciate your resilience. It might be a new concept for some of you, and others might have learnt about it in their college courses. But still, Context Free Grammars have interesting applications that range widely from Computer Science to Linguistics.
I have tried my best to present the main ideas of CFGs here, but there is a lot more that you can learn about them. Here I have left links to some great resources:
- Context Free Grammars by Daniel Shiffman.
- Context Free Grammars Examples by Fullstack Academy
- Tracery by Galaxykate