By Jose Aguinaga
A few weeks ago I decided to build an application to find which programming languages I star the most in GitHub.
Why? Because lately I had been starring projects about Machine Learning, Data Science, and Artificial Intelligence. I wanted to see whether my increased interest would show up in my starred projects timeline in any way. And what better way to discover this by using a little bit of Data Science on its own?
The experiment consisted in obtaining the information from GitHub, cleaning it up, and displaying it in a visualization. To try it yourself, go to the following webpage.
What languages got the most GitHub stars in 2016?
_A streamgraph of github starred languages on 2016._starred.jjperezaguinaga.com
After trying it yourself, give me a moment to explain how it works and show you some interesting examples.
Retrieving and analyzing the data
For better or worse, GitHub doesn’t provide an easy way to consume this information. You need to go through all your starred projects on github.com, then click through many pages to find them all. Depending in how many repositories you have starred, it would take you a few minutes before you can see all the projects across a specific timespan.
The good news are that GitHub has a starring activity API, which I then used to write a JavaScript utility to fetch all my starred projects through the year. GitHub allows you to pass a flag to see the date when you first starred a project, which let me get only the projects I starred in 2016.
With the data retrieved, I proceeded to filter it based on the language GitHub has assigned to them. Ramda was particularly useful to map and reduce this data.
Then, to visualize this information, I decided to display the frequency of each repository programming language through a chart known as a streamgraph. Aggregating each language instance per month, I could see the increase and decrease of interest over time.
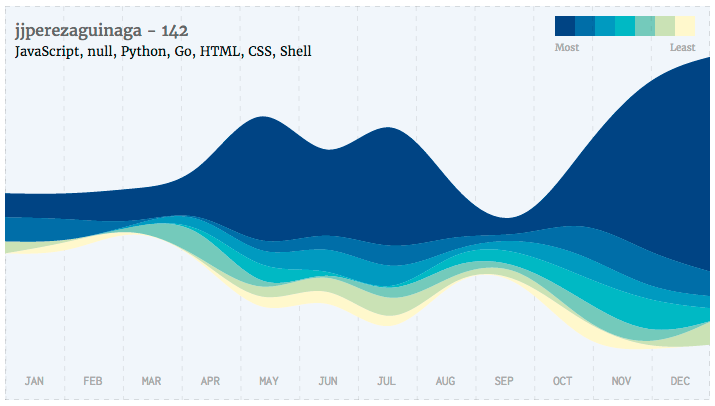
As we can see in the graph, I starred 142 projects in 2016. There were more than 15 languages across my starred repositories, but I’m only displaying the top 7, as the frequency per language drops after this number. The top language is JavaScript, which doesn’t surprise me, as I work as a Front-End Engineer on a daily basis.
The second and third programming languages are Python and Go, which most likely relate to projects about artificial intelligence / deep learning I mentioned earlier. Python made sense, since it was recently considered the most popular language for Machine Learning.
Everyone gets a graph.
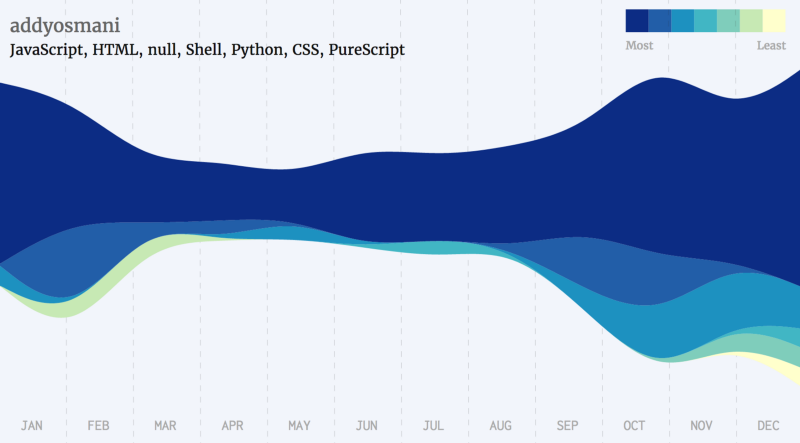
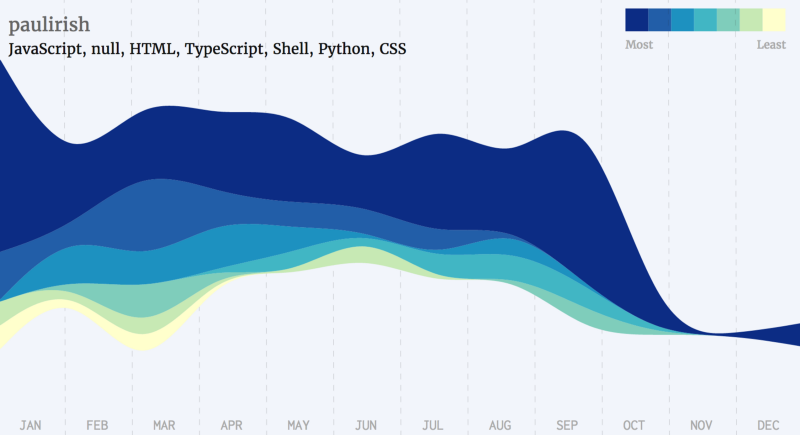
As part of the development of the tool, I tested the application with other developers. This produced a series of interesting graphs.
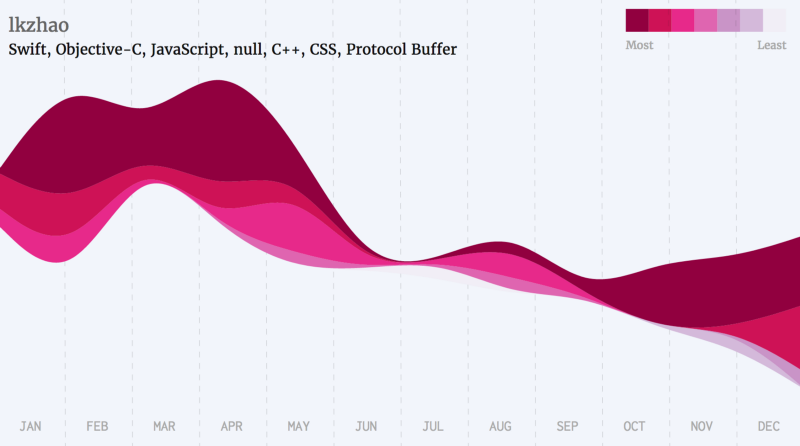
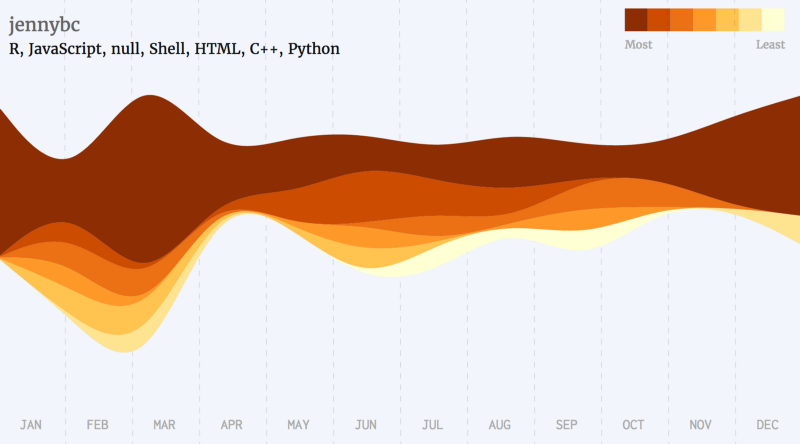
The following is a list of a few famous developers, grouped by the languages they’ve starred the most.
Javascript Developers
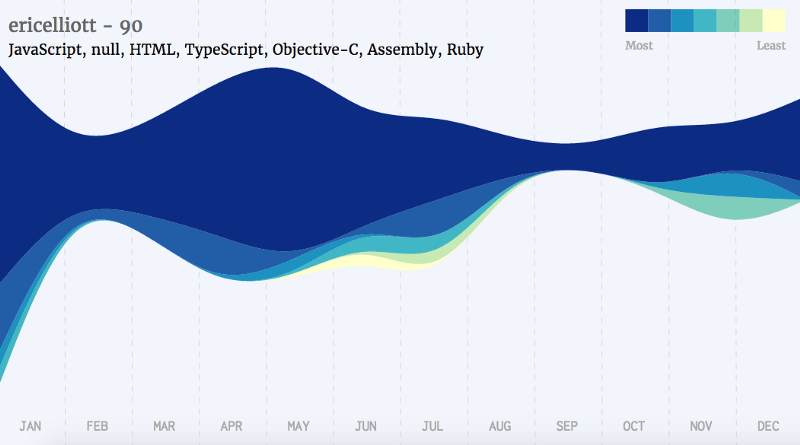
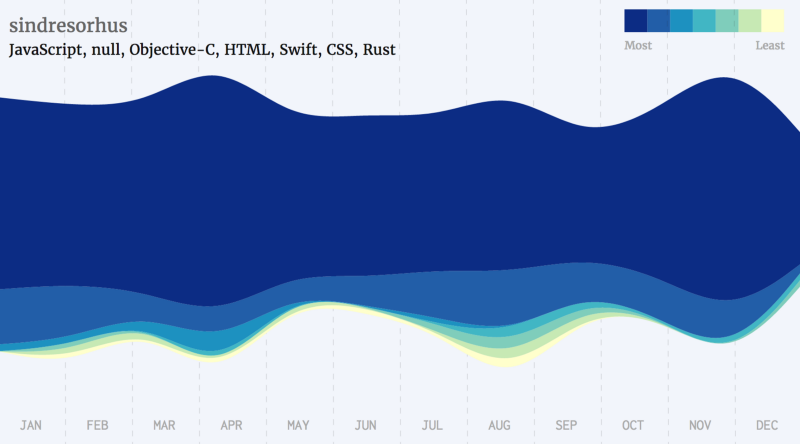
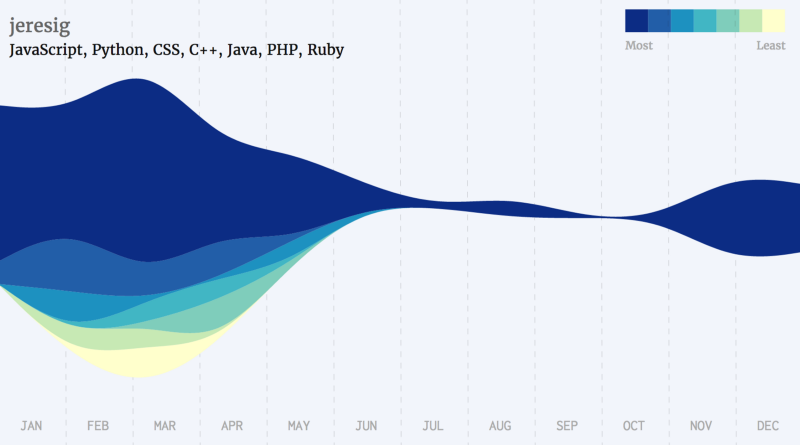
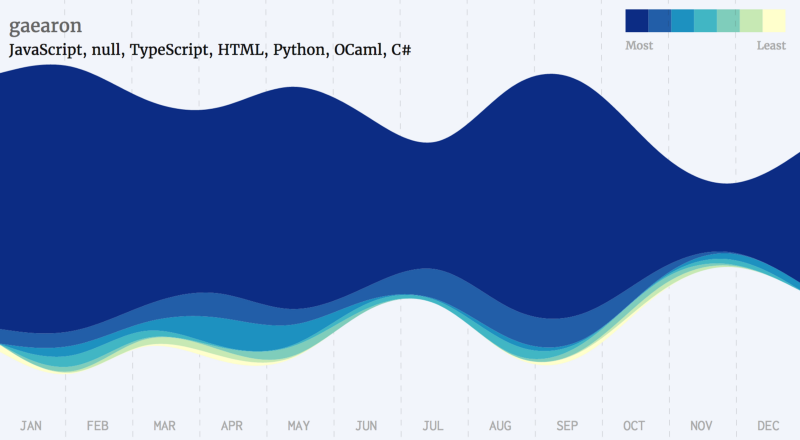
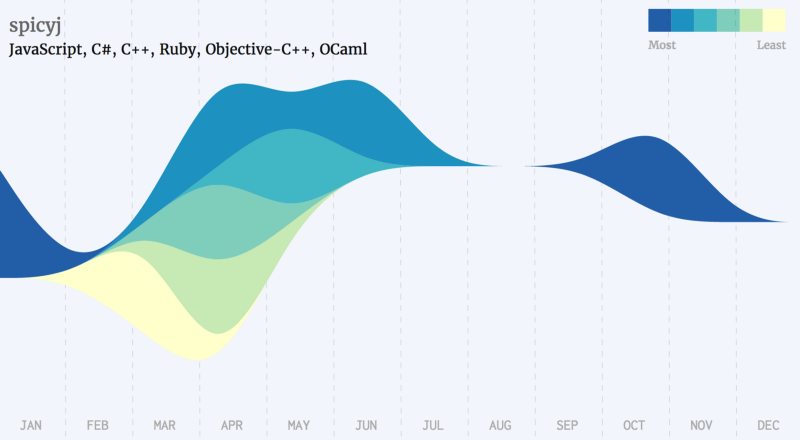
Golang Developers
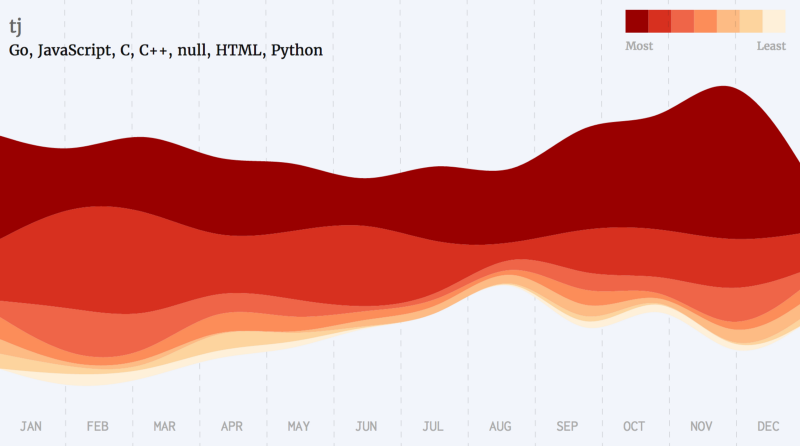
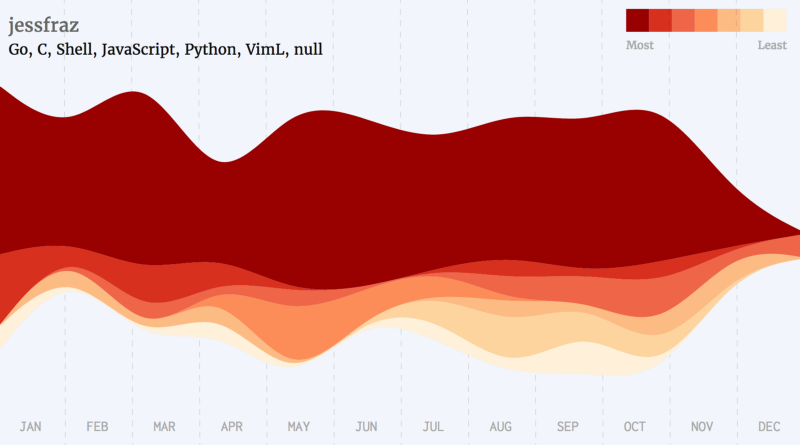
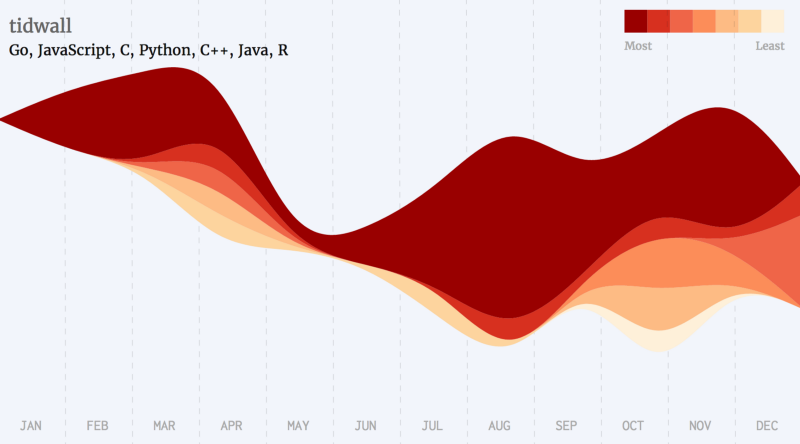
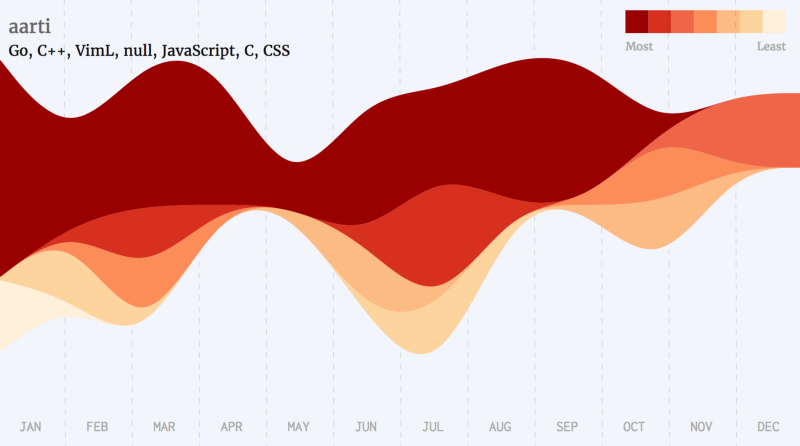
Python Developers
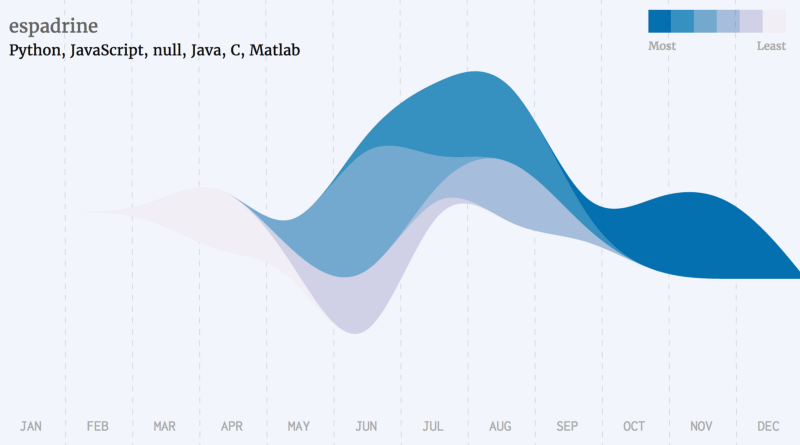
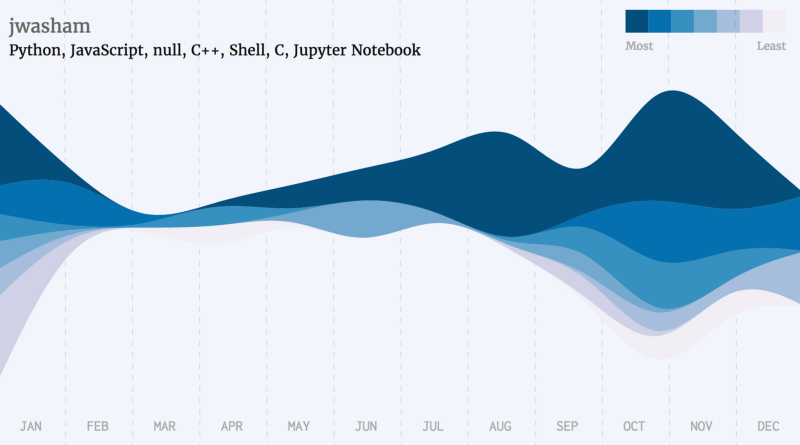
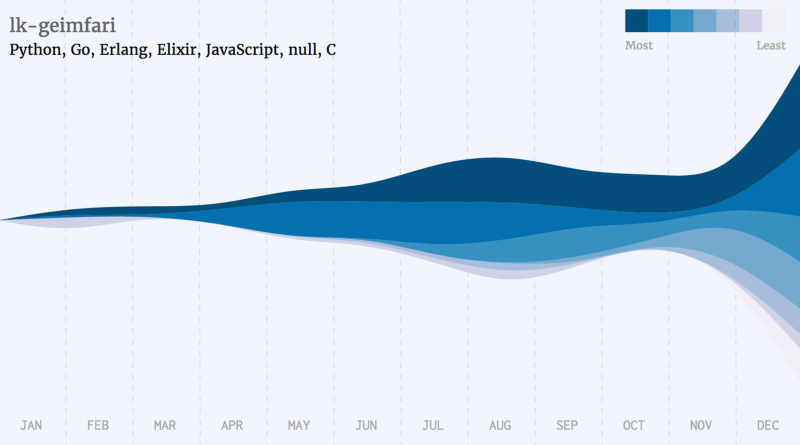
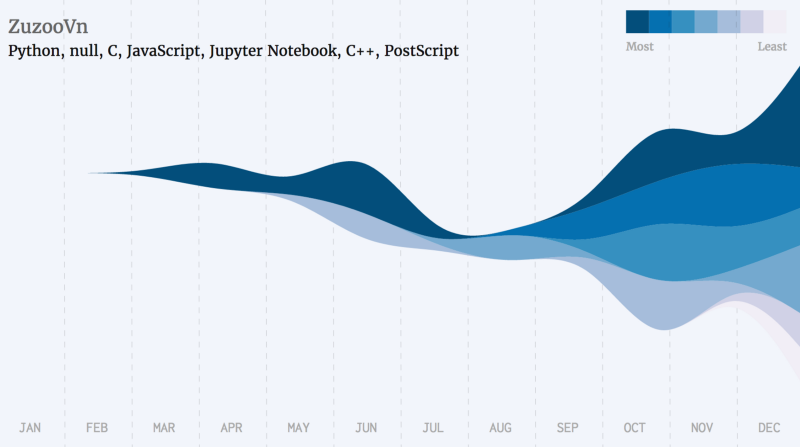
Swift,R
The thing about data
I had a lot of fun from this experiment, and learned two important lessons:
- Data can be beautiful. Not everything needs to have a deep meaning in order to be interesting. For instance, the cover for this article is the product of overlapping a series of streamgraphs from various datasets. I liked it so much I even copyrighted it.
- Our data identify us. Given enough starred projects, the chances of having two individuals with the exact same starred repositories at the exact same time are negligible*. Thus, if we analyze the starring patterns on a developer, we could identify them by seeing their data. This is an example of Behavioral Analytics, used in the past to identify users by mobile app usage.
By the end of this experiment, I’m was more interested in exploring the usages of Data Visualization and Machine Learning than before**. I’ll continue to expand my knowledge in the area to create more experiments like this in the future.
Please do try this at home
If you’re curious about the code, you can see it on Github.
jjperezaguinaga/github-patterns
_github-patterns - ? What languages got the most GitHub stars in 2016?g_ithub.com
Bear in mind the code is very dirty, so errors might occur (for example, the GitHub rate limit timeout error isn’t caught), so don’t take it as a reference for any real production projects. Feel free to change, expand or fork the code as you wish.
*Not negligible, but very unlikely. A person would need to star the same project at the same second to share the same pattern. There are 31557600 seconds in an astronomical year and are around 20M repositories in GitHub by the end of 2016, and around 5.8M active users in GitHub. You tell me what are the odds of two people with 10 starred projects to have the same pattern.
**Udacity released this weekend a new nanodegree about Deep Learning foundations. I’ve enrolled myself and will post an overview after I finish it.