
By Jeff M Lowery
I’ve been working with GraphQL for a few months now, but only recently began using Apollo’s graphql-tools library. After learning a few idioms, I am able to mock up a functional API quickly. This is largely due to its low-code, declarative approach to type definitions.
Starting with their example
Apollo has an interactive LaunchPad web site, like the ones covered in my Swagger series. There are several example schemas you can use, and for this article I will use their Post and Authors schema. You can download or fork the code.
I will be rearranging the project folders. For this post I’ll download and store it in Github, so I can branch and modify the code through each step. Along the way, I’ll link the branches to this post.
The basics
- declaring schema types
In the Launchpad, you’ll see a typeDefs template literal:
const typeDefs = `
type Author {
id: Int!
firstName: String
lastName: String
posts: [Post] # the list of Posts by this author
}
type Post {
id: Int!
title: String
author: Author
votes: Int
}
# the schema allows the following query:
type Query {
posts: [Post]
author(id: Int!): Author
}
# this schema allows the following mutation:
type Mutation {
upvotePost (
postId: Int!
): Post
}
`;
There are two entities defined, Author and Post. In addition, there are two “magic” types: Query and Mutation. The Query type defines the root accessors. In this case, there’s an accessor to fetch all Posts, and another to fetch a single Author by ID.
Note there is no way to directly query for a list of authors or for a single post. It is possible to add such queries later.
- declaring resolvers
Resolvers provide the necessary logic to support the schema. They are written as a JavaScript object with keys that match the types defined in the schema. The resolver shown below operates against static data, which I’ll cover in a moment.
const resolvers = {
Query: {
posts: () => posts,
author: (_, { id }) => find(authors, { id: id }),
},
Mutation: {
upvotePost: (_, { postId }) => {
const post = find(posts, { id: postId });
if (!post) {
throw new Error(`Couldn't find post with id ${postId}`);
}
post.votes += 1;
return post;
},
},
Author: {
posts: (author) => filter(posts, { authorId: author.id }),
},
Post: {
author: (post) => find(authors, { id: post.authorId }),
},
};
To link schema and resolver together, we’ll create an executable schema instance:
export const schema = makeExecutableSchema({
typeDefs,
resolvers,
});
- the data source
For this simple example, the data comes from two arrays of objects defined as constants: **authors** and **posts**:
const authors = [
{ id: 1, firstName: 'Tom', lastName: 'Coleman' },
{ id: 2, firstName: 'Sashko', lastName: 'Stubailo' },
{ id: 3, firstName: 'Mikhail', lastName: 'Novikov' },
];
const posts = [
{ id: 1, authorId: 1, title: 'Introduction to GraphQL', votes: 2 },
{ id: 2, authorId: 2, title: 'Welcome to Meteor', votes: 3 },
{ id: 3, authorId: 2, title: 'Advanced GraphQL', votes: 1 },
{ id: 4, authorId: 3, title: 'Launchpad is Cool', votes: 7 },
];
- the server
You can serve up the executable schema through graphql_express, apollo_graphql_express, or graphql-server-express. We see that in this example.
The important bits are:
import { graphqlExpress, graphiqlExpress } from 'graphql-server-express';
import { schema, rootValue, context } from './schema';
const PORT = 3000;
const server = express();
server.use('/graphql', bodyParser.json(), graphqlExpress(request => ({
schema,
rootValue,
context: context(request.headers, process.env),
})));
server.use('/graphiql', graphiqlExpress({
endpointURL: '/graphql',
}));
server.listen(PORT, () => {
console.log(`GraphQL Server is now running on
http://localhost:${PORT}/graphql`);
console.log(`View GraphiQL at
http://localhost:${PORT}/graphiql`);
});
Note that there are two pieces of GraphQL middleware in use:
- graphqlExpress
the GraphQL server that handles queries and responses - graphiqlExpress
the interactive GraphQL web service that allows interactive queries through an HTML UI
Reorganizing
For large apps, we suggest splitting your GraphQL server code into 4 components: Schema, Resolvers, Models, and Connectors, which each handle a specific part of the work. (http://dev.apollodata.com/tools/graphql-tools/)
Putting each type of component in its own file makes sense. I’ll go one better and put each set of components in a its own “domain” folder.
Why domains?
Domains are a convenient way to split up a large system into areas of operation. Within each domain there may be subdomains. In general, subdomains have a bounded context. Within a bounded context the entity names, properties, and processes have precise meaning.
I find bounded contexts to be helpful during analysis, especially when talking to domain experts.
The fly in the ointment is that GraphQL types occupy a single namespace, so naming conflicts can exist. More on that later.
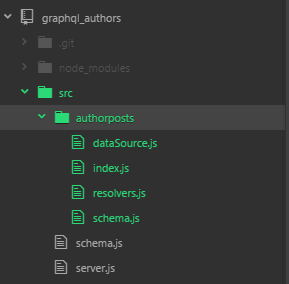
I’ll call this domain authorposts, and put the related components in the authorposts folder. Within that, I’ll create a file each for datasource, resolvers, and schema. Let’s also toss in an index.js file to simplify importing. The original schema and server files will remain in the root folder, but the schema.js code will be skeletal. The **find** and **filter** methods imported from lodash will be removed in favor of synonymous native ES6 methods. The resulting source is here.
The main schema file has become simpler. It provides skeletal structure for further extension by schemas in our domains.
import {
makeExecutableSchema
} from 'graphql-tools';
import {
schema as authorpostsSchema,
resolvers as authorpostsResolvers
} from './authorposts';
const baseSchema = [
`
type Query {
domain: String
}
type Mutation {
domain: String
}
schema {
query: Query,
mutation: Mutation
}`
]
// Put schema together into one array of schema strings and one map of resolvers, like makeExecutableSchema expects
const schema = [...baseSchema, ...authorpostsSchema]
const options = {
typeDefs: schema,
resolvers: {...authorPostResolvers}
}
const executableSchema = makeExecutableSchema(options);
export default executableSchema;
A domain schema is imported on lines 7–8, and the base schema on lines 11–23. You’ll note there is a domain property. This is arbitrary but GraphQL, or graphql-tools, insists that one property be defined.
The complete schema is constructed on line 26, and an executableSchema instance is created given the schema and resolvers defined so far on lines 28–33. This is what is imported by the server.js code, which is largely unchanged from the original.
There is a trick to splitting up a schema this way. Let’s take a look:
import {
authors,
posts
} from './dataSource';
const rootResolvers = {
Query: {
posts: () => posts,
author: (_, {
id
}) => authors.find(a => a.id === id)
},
Mutation: {
upvotePost: (_, {
postId
}) => {
const post = posts.find(p => p.id === postId);
if (!post) {
throw new Error(`Couldn't find post with id ${postId}`);
}
post.votes += 1;
return post;
}
},
Author: {
posts: (author) => posts.filter(p => p.authorId === author.id)
},
Post: {
author: (post) => authors.find(a => a.id === post.authorId)
}
};
export default rootResolvers;
const typeDefs = [
`
type Author {
id: Int!
firstName: String
lastName: String
posts: [Post] # the list of Posts by this author
}
type Post {
id: Int!
title: String
author: Author
votes: Int
}
# the schema allows the following query:
extend type Query {
posts: [Post]
author(id: Int!): Author
}
# this schema allows the following mutation:
extend type Mutation {
upvotePost (
postId: Int!
): Post
}
`
];
export default typeDefs;
The first listing, authorpostResolvers.js, is pretty much a cut’n’paste job from the original schema.js source from Apollo’s example. Yet in the authorpostSchema.js code, we extend the Query and Mutator definitions that are declared in the the base schema. If you don’t use the extend keyword, the executable schema builder will complain about two Query definitions.
Continuing…
This is a good start for organizing several schemas, one for each domain of interest (so long as you're mindful of the global namespace for types), but a complete schema, even for a single domain, can get huge. Fortunately, you can break down each schema even further, right down to the entity level, if necessary.
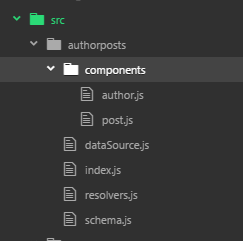
Here’s a modified directory structure, and listings of the new contents:
export default `
type Author {
id: Int!
firstName: String
lastName: String
posts: [Post] # the list of Posts by this author
}`
export default `
type Post {
id: Int!
title: String
author: Author
votes: Int
}`
import Author from './components/author'
import Post from './components/post'
const typeDefs =
`
# the schema allows the following query:
extend type Query {
posts: [Post]
author(id: Int!): Author
}
# this schema allows the following mutation:
extend type Mutation {
upvotePost (
postId: Int!
): Post
}
`;
export default [typeDefs, Author, Post];
We can achieve granularity by defining two component files, then importing them into a domain schema.
You don’t have to do one component per file. But you do want to be sure that the schema exports those components along with the schema itself as shown on line 20 of schema.js. Otherwise you’ll likely wind up missing a dependency further down the inclusion chain.
Multiple schemas and resolvers
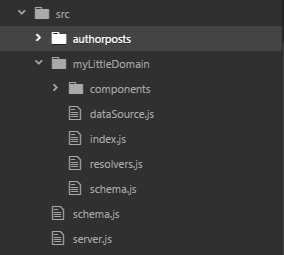
Adding a new schema for a new domain is simple. Create a new domain folder and add dataSource, resolvers, schema, and index.js files. You can also add an optional component folder with component type definitions.
const myLittleTypes = [{
id: 1,
description: 'This is good',
}, {
id: 2,
description: 'This is better',
}, {
id: 3,
description: 'This is the best!',
}];
export {
myLittleTypes
};
export default `
type MyLittleType {
id: Int!
description: String
}`
import {
myLittleTypes
} from './dataSource';
const rootResolvers = {
Query: {
myLittleType: (_, {
id
}) => myLittleTypes.find(t => t.id === id)
},
};
export default rootResolvers;
import MyLittleType from './components/myLittleType'
const typeDefs =
`
# the schema allows the following query:
extend type Query {
myLittleType(id: Int!): MyLittleType
}
`;
export default [typeDefs, MyLittleType];
Finally, the root schema.js file must combine the schemas and resolvers from both domains:
//...
import {
schema as myLittleTypoSchema,
resolvers as myLittleTypeResolvers
} from './myLittleDomain';
import {
merge
} from 'lodash';
//...
const schema = [...baseSchema, ...authorpostsSchema, ...myLittleTypoSchema]
const options = {
typeDefs: schema,
resolvers: merge(authorpostsResolvers, myLittleTypeResolvers)
}
Note that I had to include **lodash** merge here because of the need for a deep merge of the two resolvers imports.
Dealing with Namespace Collisions
If you are on a large project, you will encounter type name collisions. You might think that Account in one domain would mean the same as Account in another. Yet even if they do mean more or less similar things, chances are the properties and relationships will be different. So technically they are not the same type.
At the time of this writing, GraphQL uses a single namespace for types.
How to work around this? Facebook apparently uses a naming convention for their 10,000 types. As awkward as that seems, it works for them.
The Apollo graphql-tools stack appears to catch type name duplications. So you should be good there.
There is an ongoing discussion on whether to include namespaces in GraphQL. It isn’t a simple decision . I remember the complexities caused by the introduction of XML Namespaces 10 years ago.
Where to go from here?
This post only scratches the surface of how one might organize a large set of GraphQL schemas. The next post will be about mocking GraphQL resolvers, and how it’s possible to mix both real and mocked values in query responses.