
By Vitalii Akimov
Async generators are new in JavaScript. They are a remarkable extension. They provide a simple but very powerful tool for splitting programs into smaller parts, making sources easier to write, read, maintain and test.
The article shows this using an example. It implements a typical front-end component, namely drag and drop operations. The same technique is not limited to the front end It is hard to find where it cannot be applied. I use the same in two big compiler projects, and I’m very excited how much it simplifies there.
The final result is a toy, but most of the code there is usable in a real-world application. The only goal of the article is to show how to split the program into smaller independent parts using async generator functions. It is not an article about how to implement drag and drop.
There is transpiled demo of what we’ll get at the end of the day.
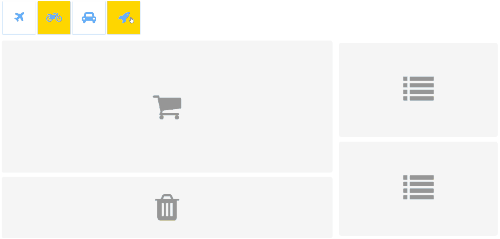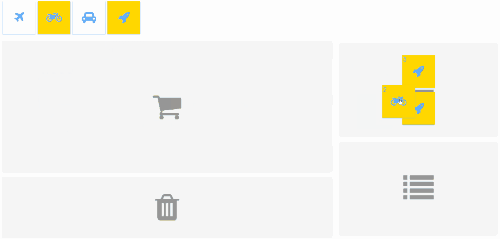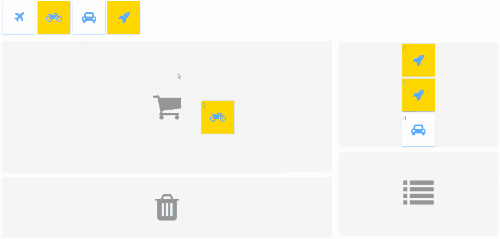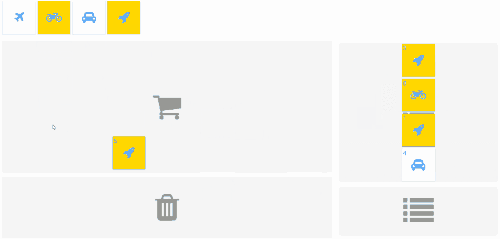
You can drag boxes from a palette in the top and drop into any of the gray areas. Each drop area has its specific actions. A few items can be selected. Yellow ones have inertial movement.
All the features are independent there. They are split into stages for each feature. They are simple to enable, disable, develop, test and debug separately. A few developers or teams could productively work on it in parallel.
I assume some the very basic knowledge of async generators (or at least of async functions and generators separately) and some fundamentals of HTML DOM (at least knowing what it is). There are no dependencies on third-party JavaScript libraries or frameworks, but the same technique may be used with any of them.
For the demo, let’s pretend we don’t know full requirements set and add new a feature only after we finish something and it works. Playing with already working software at intermediate stages typically boosts creativity. It is one of the main components of the agile software development core - better to write something not perfectly designed but working first. Then we can always improve it using refactoring after. Async generators will help.
At the beginning of any project, I don’t want to spend time on choosing the right framework, library or even an architecture. I don’t want to overdesign. With the help of async iterators, I can delay the hard decisions to a point with enough knowledge to make a choice. The earlier I take some option, the more chances there are for mistakes. Maybe I won’t need anything at all.
I’ll describe a couple of steps only. The other steps are small and can be read directly from code effortlessly. They are just a matter of working with DOM.
Async generators
All the samples share nano-framework sources. It is developed once, at the beginning and copy-pasted without any change. In the real project, these are separate modules, imported into other modules if needed. The framework does just one thing. It converts DOM events into async iterator elements.
Async iterators have the same next method like ECMAScript plain iterators, but they return a Promise resolving to Objects with value, done fields.
Async generators combine the functionality of async functions and generators. In the bodies of such functions, we can use await together with yield expressions, and they do exactly what these expressions do in async functions and generators, respectively. Namely they suspend execution control until the Promise in the await argument is resolved, and for yield outputs value and suspends until caller requests next value.
Here’s the nano-framework implementation, with the first version of business logic (monolithic for now):
It is a working sample, press Result there to see it in action. There are four elements you can drag within the page. The main components are send, produce and consume. The application subscribes to DOM events and redirects them into the framework using the send function. The function converts the arguments into elements of the async iterator returned by produce call. The iterator never ends and called at a module’s top level.
There is a for(;;) loop in produce. I know, it looks suspicious, you may even have it denied in your team code review checklist or event by some lint rule. For code readability we of course want the exit condition for loops to be obvious. But this loop should never exit, as it is supposed to be infinite. It doesn’t consume CPU cycles since most of the time it will sleep in await and yield expressions there.
There is also the consume function. It reads any async iterator in its argument, doing nothing with the elements, never returning. We need it to keep our framework running.
async function consume(input) {
for await(const i of input) {}
}
It is an async function (not generator), but it uses the new for-await-of statement, an extension of the for-of statement. It reads async iterators, rather than the original ECMAScript iterator, and awaits each element. Its simplified implementation could transpile the original consume code into something like this:
async function consume(input) {
const iter = input[Symbol.asyncIterator]()
for(let i;(i = await iter.next()).done;) {}
}
The main function is an entry point of the application’s business logic. The function is called between produce and consume in the module’s top level.
consume(main(produce()))
There is also a small share function. We need it to use the same iterator in a few for-await-of statements.
The first monolithic version of business logic is fully defined in main. It is a first dirty draft version, but the power of async generators is already visible. The application state (where we started dragging — x, y variables) is just simple local variables, encapsulated inside the function.
Besides data state, there is also execution control state. It is a kind of implicit local variable storing position where the generator is suspended (either on await or yield). Though the real magic begins when we start splitting the main.
Splitting
The most often used function combination is their composition: say for function f and g a composition of two functions is a => f(g(a)).
If we compose plain functions, the next one starts doing its job only after the former one exists. If they are running generators, their execution is interleaved.
 Function's composition
Function's composition
A few composed generator functions make a parallel pipeline. Like in any manufacturing process, say cars, splitting jobs into a few steps using an assembly line significantly increases productivity. Similarly, in the pipeline based on async generators, some function may send messages to the next using values its result iterator yields. The following function may do something application specific depending on a content of the message or pass it to the next stage.
These stage functions are the component of business logic. More formally they are any JavaScript function, taking an async iterator as its parameter and returning another async iterator as a result. In most cases, this will be an async generator function, but not necessarily.
There are many names commonly in use for such functions now. For example Middleware, Epic, etc., I like the name Transducer more and will use it in the article.
Transducers are free to do whatever they want with the input stream. Here are examples of what this can be:
- pass through the message to next step (with
yield i) - change something in it and pass next (
yield {…i,one:1}) - generate a new message (
yield {type:”two”,two:2}) - don’t yield anything at all thus filtering the message out
- buffer the messages in some array and output on some condition (
yield* buf), e.g., delaying drag start to avoid false response - do some async operations (
await query())
Transducers mostly listen for incoming messages on for-await-of loops. There may be a few such loops in a single transducer body. This utilizes execution control state to implement some business logic requirements.
Let’s see how it works. We'll split the monolithic main function from the above sample into two stages. One converts DOM events into drag and drop messages — makeDragMessages (types "dragstart", "dragging", "drop") and the other updates DOM positions — setPositions. The main function is just a composition of the two.
I split the program here because I want to insert some new message handlers between them. It's the same as when writing new software, I wouldn’t focus too much on how to split the code correctly before I understand why I needed this. It should satisfy some reasonable size constraint. They also must be separated on logically different features.
The main function there is actually a transducer too (takes an async iterable and returns an async iterable). It is an example of a transducer which is not an async generator itself. Some larger application may inject main from this module into other pipelines.
This is the final version of the nano-framework. Nothing is to be changed there regardless of what new features we add. The new features are function specified somewhere in the chain in main.
First features
Now back to making something new. Just dragging something on a page isn't enough. We have special message names for dragging ("dragstart", "dragging", "drop"). Next, transducers can use them instead of mouse/touch events. For example, we can add a keyboard support, changing nothing for this.
Let’s make a way to create new draggable items, some area where we can drag them from, and something to remove them. We’ll also flavor it with animation on dropping an item in the trash area or outside of any area.
First, everything starts with the palette transducer. It detects drag start on one of its elements, clones it into a new element, and replaces all the original dragging events after with the clone. It is absolutely transparent for all the next transducers. They know nothing about the palette. For them, this is like another drag operation of the existing element.
Next the assignOver transducer does nothing visible for the end-user, but it helps the next transducers. It detects HTML elements a user drags an item over and adds it to all messages using the over property. The information is used in the trash and validateOver transducers to decide if we need to remove the element or cancel the drag.
The transducers don’t do that themselves but rather send "remove" or "dragcancel" messages to be handled by something next. The cancel message is converted to "remove" by removeCancelled. And "remove"messages are finally handled in applyRemove by removing them from the DOM.
By introducing another message type, we can inject new features implementations in the middle without replacing anything in the original code. In this example it is animation. On "dragcancel" the item moves back to its original position, and on "remove" its size is reduced to zero. Disabling/enabling animation is just a matter of removing/inserting transducers at some specific position.
The animation will continue to work if something else generates "dragcancel" or "remove". We may stop thinking about where to apply it. Our business logic becomes more high level.
The animation implementation also utilizes async generators but not in the form of transducers. This is a function returning values from zero to one in animation frames with specified delay, which defaults to 200ms. And the caller function uses it in whatever way it likes. Check for the demo animRemove function in the fiddle above.
Many other animation options are simple to add. The values may be not linear but output with some spline function. Or it may be based not on delay but on velocity. This is not significant for functions invoking anim.
Multi-select
Now let’s add incrementally another feature. We start from scratch, from the nano-framework. We will merge all the steps in the end effortlessly. This way the code from the previous step will not interfere with the new development. It is much easier to debug and write tests for it. There are no unwanted dependencies as well.
The next feature is a multi-select. I highlight it here because it requires another higher order function combination. But at first, it looks straightforward to implement. The idea is to simulate drag messages for all selected elements when a user drags one of them.
Implementation is very simple but it breaks the next steps in the pipeline. Some transducers (like setPosition) expect an exact message sequence. For a single item, there should be "dragstart" followed by a few "dragging" and a "drop" in the end. This is no longer true.
A user drags a few elements at the same time. So there’ll be messages now for several elements simultaneously. There is only one start coordinate in setPosition x and y local variables. And its control flow is defined only for one element. After "dragstart" it is in the nested loop. It doesn’t recognize any next "dragstart" until exiting that loop on "drop".
The problem can be solved by resorting to storing state, including a control state, in some map for each element currently dragging. This would, of course, break all async generator advantages. I have also promised there are no changes to the nano-framework. So it is not the solution.
What we need here is to run transducers expecting to work with a single element in a kind of a separate thread. There is a byElement function for this. It multiplexes input into a few instances of a transducer passed as its argument. The instances are created by calling the transducer in the argument supplying its filtered source iterator. Each source for each instance outputs only messages with the same element field. The outputs of all the instances are merged back into one stream. All we need to do is to wrap transducers with byElement.
First, it converts DOM events into application-specific messages in makeSelectMessages. The second step adds a selection indicator and highlights selected items after selections ending in selectMark. Nothing is new in the first two. The third transducer checks if a user drags a highlighted item. If so, it gets all other highlighted items and generates drag and drop messages for each of them in propagateSelection. Next setPosition runs in a thread per each element.
Final result
After the multi-selection feature is implemented, it is done once and for all. The other features just automatically work with it. All we need to change is to add it to main and correctly wrap other transducers with byElement if needed. This may be done either in main or in a module where the transducers are imported from.
Here is the fiddle with the final demo with all the features merged:
All the transducers are in fact a very lightweight thread. Unlike real threads, they are deterministic but they use non-deterministic DOM events as a source. So they must be considered non-deterministic as well.
This makes all the typical problems of multi-threaded environments possible, unfortunately. These are racings, deadlocks, serializations, etc. Fortunately, they are simple to avoid. Just don’t use mutable shared data.
I violate this constraint in the demo by querying and updating the DOM tree. It doesn’t lead to problems here, but in the real application, it is something to care about. For fixing this, some initial stages may read everything needed from a DOM and pack it into messages. The final step may perform some DOM updates based on messages received. This may be some virtual DOM render, for example.
Communicating with the messages only allows isolating the thread even more. This may be a Web Worker, or even a remote server.
But again, I wouldn’t worry before it becomes a problem. Thanks to async iterators, the program is a set of small, isolated and self-contained components. It is straightforward to change anything when (if) there is any problem.
The technique is compatible with other design techniques. It will work for OOP or FP. Any classic design pattern applies. When the main function grows big, we can add some dependency injection to manage the pipeline, for example.
The technique reduces worry about the application’s architectures. Only write a specific transducer for each feature you need to implement. Abstract common parts into stand-alone transducers. Split it into a few if something else is to be done in the middle. Generalize some parts into abstract reusable combinators only when(if) you have enough knowledge for this.
Relation to other libraries
If you are familiar with node-streams or functional reactive libraries such as RxJS, you can probably already spot many similarities. The only difference is what interface is used for streams.
Transducers don’t need to be async generators. It is just a function taking a stream and returning another stream regardless of what interface the stream has. The same technique to split business logic may be applied to any other stream interfaces. Async generators just provide excellent syntax extension for them.
If you are familiar with Redux you may notice message handlers are very similar to middlewares or reducers composition. Async iterators can be converted into Redux middleware as well. Something like this, for example, is done in redux-observable library but for a different stream interface.
Though, this violates the Redux principles. There is no longer a single storage. Each async generator has its own encapsulated state. Even if it doesn’t use local variables the state is still there. It is the current control state and position in the code where the generator was suspended. The state is also not serializable.
The framework fits nicely with the Redux underlying patterns though, like Event Sourcing. We can have a specific kind of message propagating some global state diffs. And transducers can react accordingly, probably updating their local variables if needed.
The name, transducer, is typically associated with Clojure style transducers in the JavaScript world. Both are the same things on a higher level. They are again just transformers of stream objects with different interfaces. Though Clojure transducers transform stream consumers, async iterator transducers from this article transform stream producers. A bit more detail can be found here.
Extensions
I'm now working on a transpiler for embedding effects in JavaScript. It can handle ECMAScript async, generators and async generators function syntax extensions to overload default behavior.
In fact, the transpiled demo above was built with it. Unlike similar tools like regenerator, it is abstract. Any other effect can be seamlessly embedded in the language using a library implementing its abstract interface. This can significantly simplify JavaScript programs.
For example, possible applications are:
- faster standard effects,
- saving current execution to a file or DB and restore on a different server or recover after hardware failure,
- move control between front-end and back-end,
- on changing input data, re-execute only relevant part of the program, use transactions, apply logical programming techniques, even Redux principles for async generators may be recovered.
The compiler implementation itself uses the technique described in the article. It uses non-async generators since it doesn’t have any async message source. The approach significantly simplified the previous compiler version done with Visitors. It now has almost a hundred options. Their implementation is almost independent, and it is still simple to read and extend.