
By Ridham Tarpara
GraphQL has become a buzzword over the last few years after Facebook made it open-source. I have tried GraphQL with the Node.js, and I agree with all the buzz about the advantages and simplicity of GraphQL.
So what is GraphQL? This is what the official GraphQL definition says:
GraphQL is a query language for APIs and runtime for fulfilling those queries with your existing data. GraphQL provides a complete and understandable description of the data in your API, gives clients the power to ask for exactly what they need and nothing more, makes it easier to evolve APIs over time, and enables powerful developer tools.
I recently switched to Golang for a new project I’m working on (from Node.js) and I decided to try GraphQL with it. There are not many library options with Golang but I have tried it with Thunder, graphql, graphql-go, and gqlgen. And I have to say that gqlgen is winning among all the libraries I have tried.
gqlgen is still in beta with latest version 0.7.2 at the time of writing this article, and it’s rapidly evolving. You can find their road-map here. And now 99designs is officially sponsoring them, so we will see even better development speed for this awesome open source project. vektah and neelance are major contributors, and neelance also wrote graphql-go.
So let’s dive into the library semantics assuming you have basic GraphQL knowledge.
Highlights
As their headline states,
This is a library for quickly creating strictly typed GraphQL servers in Golang.
I think this is the most promising thing about the library: you will never see map[string]interface{} here, as it uses a strictly typed approach.
Apart from that, it uses a Schema first Approach: so you define your API using the graphql Schema Definition Language. This has its own powerful code generation tools which will auto-generate all of your GraphQL code and you will just need to implement the core logic of that interface method.
I have divided this article into two phases:
- The basics: Configuration, Mutations, Queries, and Subscription
- The advanced: Authentication, Dataloaders, and Query Complexity
Phase 1: The Basics - Configuration, Mutations, Queries, and Subscriptions
We will use a video publishing site as an example in which a user can publish a video, add screenshots, add a review, and get videos and related videos.
mkdir -p $GOPATH/src/github.com/ridhamtarpara/go-graphql-demo/
Create the following schema in the project root:
Here we have defined our basic models and one mutation to publish new videos, and one query to get all videos. You can read more about the graphql schema here. We have also defined one custom type (scalar), as by default graphql has only 5 scalar types that include Int, Float, String, Boolean and ID.
So if you want to use custom type, then you can define a custom scalar in schema.graphql (like we have defined Timestamp) and provide its definition in code. In gqlgen, you need to provide marshal and unmarshal methods for all custom scalars and map them to gqlgen.yml.
Another major change in gqlgen in the last version is that they have removed the dependency on compiled binaries. So add the following file to your project under scripts/gqlgen.go.
and initialize dep with:
dep init
Now it’s time to take advantage of the library’s codegen feature which generates all the boring (but interesting for a few) skeleton code.
go run scripts/gqlgen.go init
which will create the following files:
gqlgen.yml — Config file to control code generation.
generated.go — The generated code which you might not want to see.
models_gen.go — All the models for input and type of your provided schema.
resolver.go — You need to write your implementations.
server/server.go — entry point with an http.Handler to start the GraphQL server.
Let’s have a look at one of the generated models of the Video type:
Here, as you can see, ID is defined as a string and CreatedAt is also a string. Other related models are mapped accordingly, but in the real world you don’t want this — if you are using any SQL data type you want your ID field as int or int64, depending on your database.
For example I am using PostgreSQL for demo so of course I want ID as an int and CreatedAt as a time.Time. So we need to define our own model and instruct gqlgen to use our model instead of generating a new one.
and update gqlgen to use these models like this:
So, the focal point is the custom definitions for ID and Timestamp with the marshal and unmarshal methods and their mapping in a gqlgen.yml file. Now when the user provides a string as ID, UnmarshalID will convert a string into an int. While sending the response, MarshalID will convert int to string. The same goes for Timestamp or any other custom scalar you define.
Now it’s time to implement real logic. Open resolver.go and provide the definition to mutation and queries. The stubs are already auto-generated with a not implemented panic statement so let’s override that.
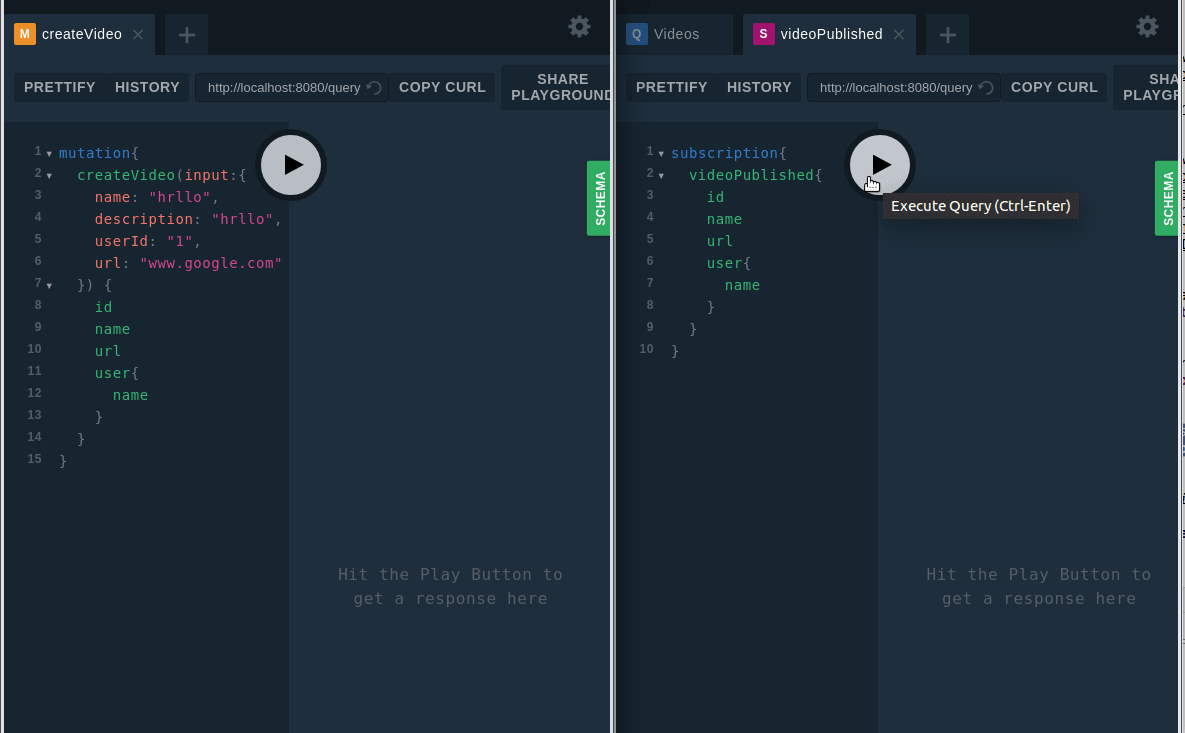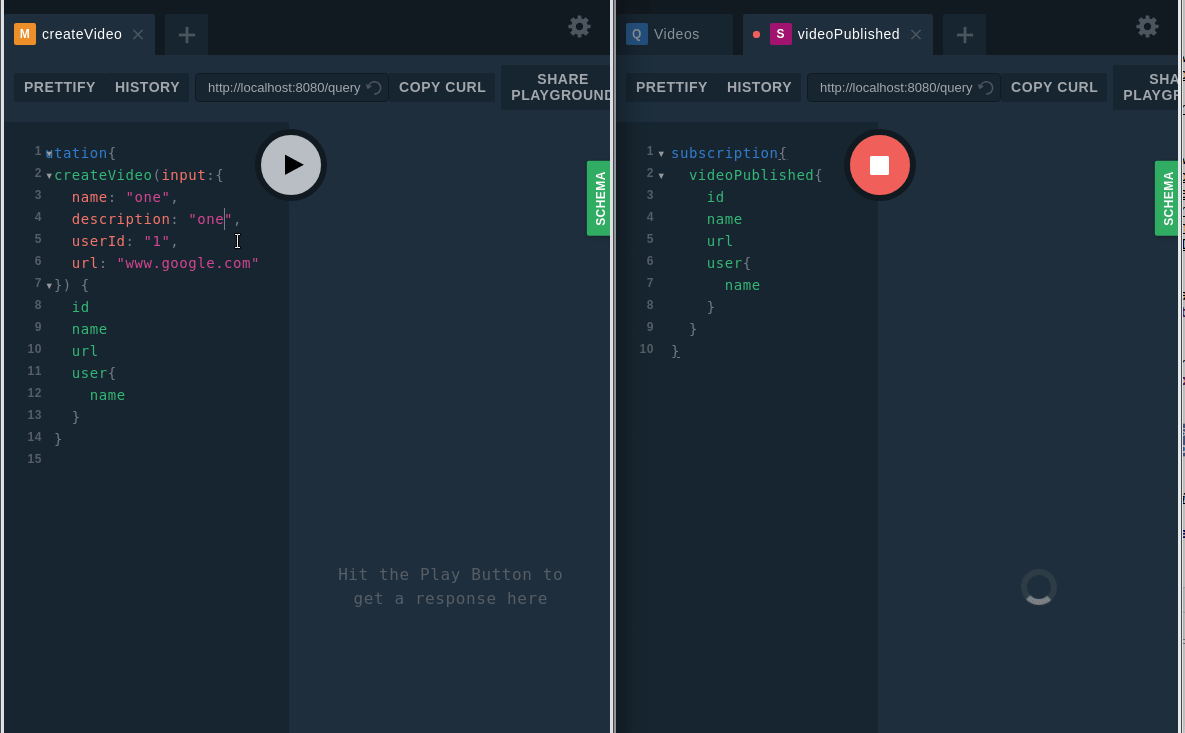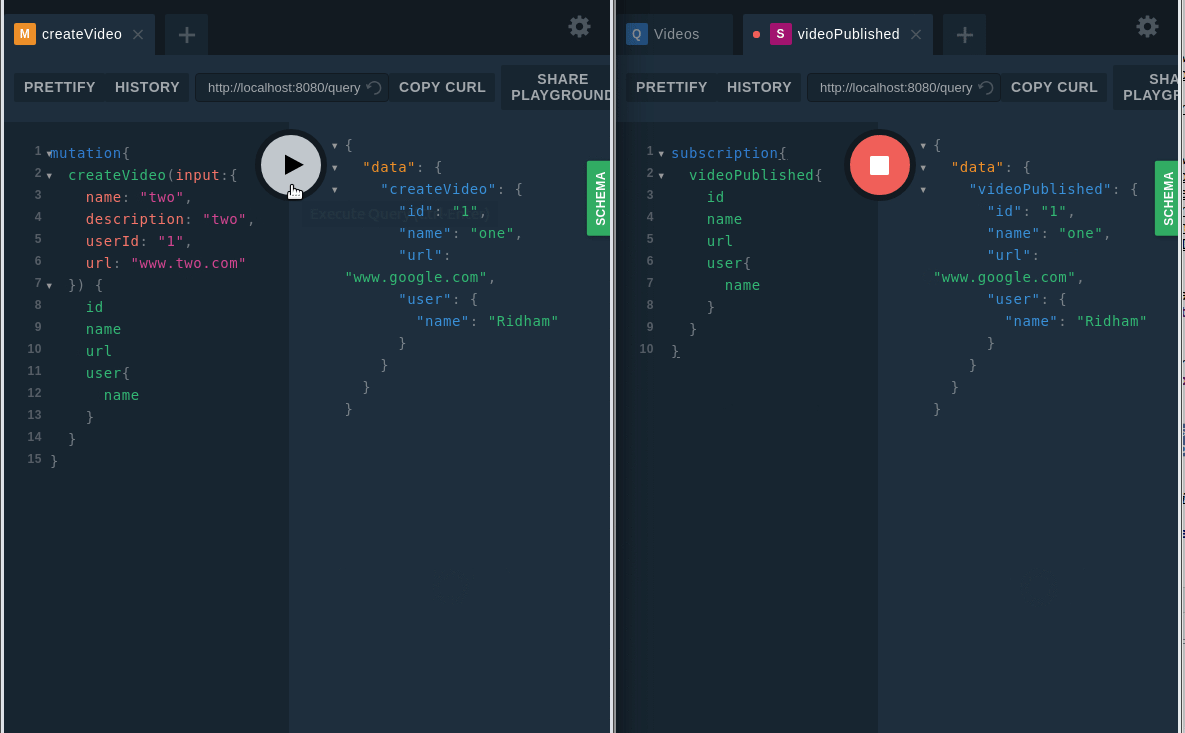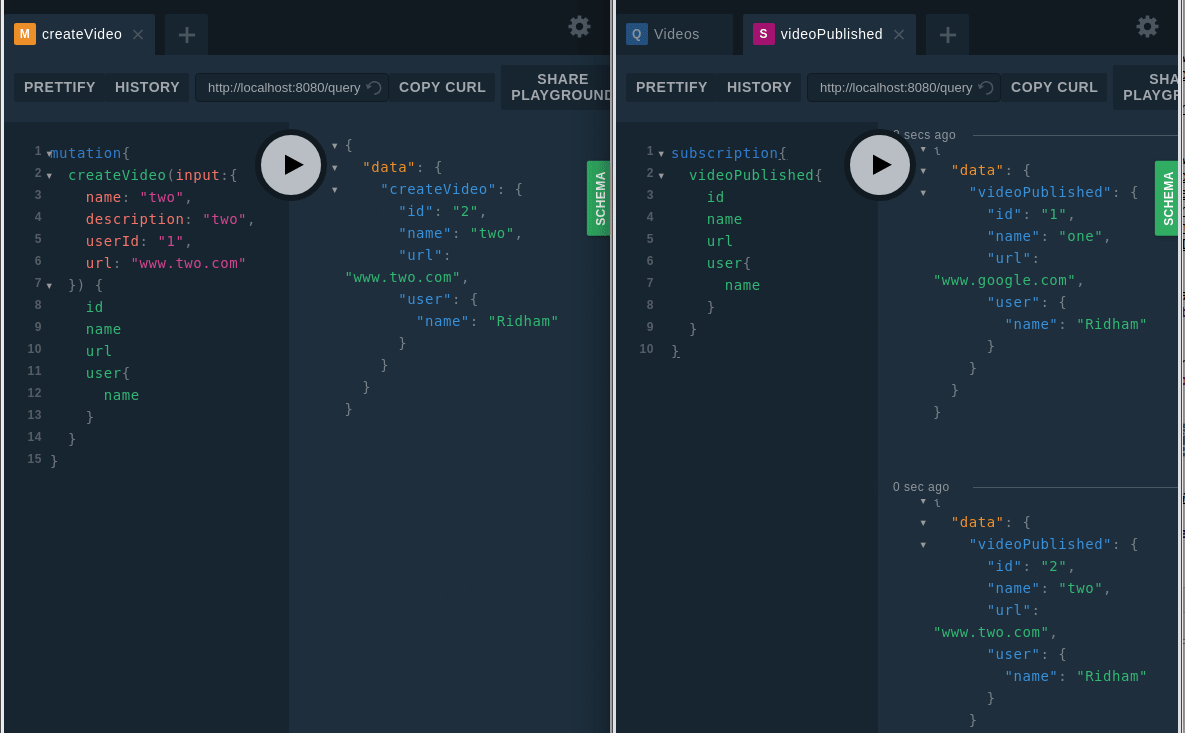
and hit the mutation:
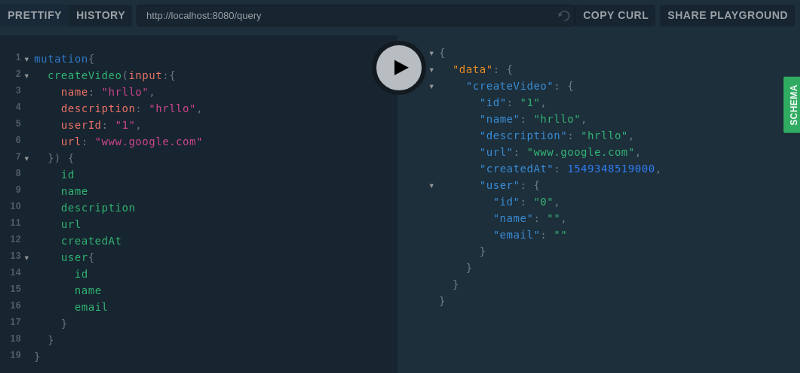 createVideo Mutation
createVideo Mutation
Ohh it worked….. but wait, why is my user empty ?? So here there is a similar concept like lazy and eager loading. As graphQL is extensible, you need to define which fields you want to populate eagerly and which ones lazily.
I have created this golden rule for my organization team working with gqlgen:
Don’t include the fields in a model which you want to load only when requested by the client.
For our use-case, I want to load Related Videos (and even users) only if a client asks for those fields. But as we have included those fields in the models, gqlgen will assume that you will provide those values while resolving video — so currently we are getting an empty struct.
Sometimes you need a certain type of data every time, so you don’t want to load it with another query. Rather you can use something like SQL joins to improve performance. For one use-case (not included in the article), I needed video metadata every time with the video which is stored in a different place. So if I loaded it when requested, I would need another query. But as I knew my requirements (that I need it everywhere on the client side), I preferred it to load eagerly to improve the performance.
So let’s rewrite the model and regenerate the gqlgen code. For the sake of simplicity, we will only define methods for the user.
So we have added UserID and removed User struct and regenerated the code:
go run scripts/gqlgen.go -v
This will generate the following interface methods to resolve the undefined structs and you need to define those in your resolver:
And here is our definition:
Now the result should look something like this:
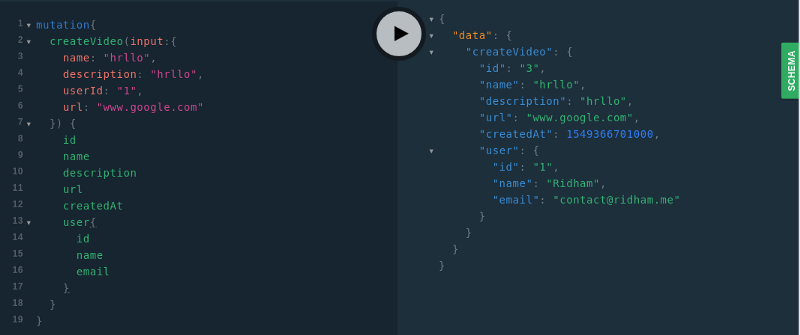
So this covers the very basics of graphql and should get you started. Try a few things with graphql and the power of Golang! But before that, let’s have a look at subscription which should be included in the scope of this article.
Subscriptions
Graphql provides subscription as an operation type which allows you to subscribe to real tile data in GraphQL. gqlgen provides web socket-based real-time subscription events.
You need to define your subscription in the schema.graphql file. Here we are subscribing to the video publishing event.
Regenerate the code by running: go run scripts/gqlgen.go -v.
As explained earlier, it will make one interface in generated.go which you need to implement in your resolver. In our case, it looks like this:
Now, you need to emit events when a new video is created. As you can see on line 23 we have done that.
And it’s time to test the subscription:
GraphQL comes with certain advantages, but everything that glitters is not gold. You need to take care of a few things like authorizations, query complexity, caching, N+1 query problem, rate limiting, and a few more issues — otherwise it will put you in performance jeopardy.
Phase 2: The advanced - Authentication, Dataloaders, and Query Complexity
Every time I read a tutorial like this, I feel like I know everything I need to know and can get my all problems solved.
But when I start working on things on my own, I usually end up getting an internal server error or never-ending requests or dead ends and I have to dig deep into that to carve my way out. Hopefully we can help prevent that here.
Let’s take a look at a few advanced concepts starting with basic authentication.
Authentication
In a REST API, you have a sort of authentication system and some out of the box authorizations on particular endpoints. But in GraphQL, only one endpoint is exposed so you can achieve this with schema directives.
You need to edit your schema.graphql as follows:
We have created an isAuthenticated directive and now we have applied that directive to createVideo subscription. After you regenerate code you need to give a definition of the directive. Currently, directives are implemented as struct methods instead of the interface so we have to give a definition.
I have updated the generated code of server.go and created a method to return graphql config for server.go as follows:
We have read the userId from the context. Looks strange right? How was userId inserted in the context and why in context? Ok, so gqlgen only provides you the request contexts at the implementation level, so you can not read any of the HTTP request data like headers or cookies in graphql resolvers or directives. Therefore, you need to add your middleware and fetch those data and put the data in your context.
So we need to define auth middleware to fetch auth data from the request and validate.
I haven’t defined any logic there, but instead I passed the userId as authorization for demo purposes. Then chain this middleware in server.go along with the new config loading method.
Now, the directive definition makes sense. Don’t handle unauthorized users in your middleware as it will be handled by your directive.
Demo time:
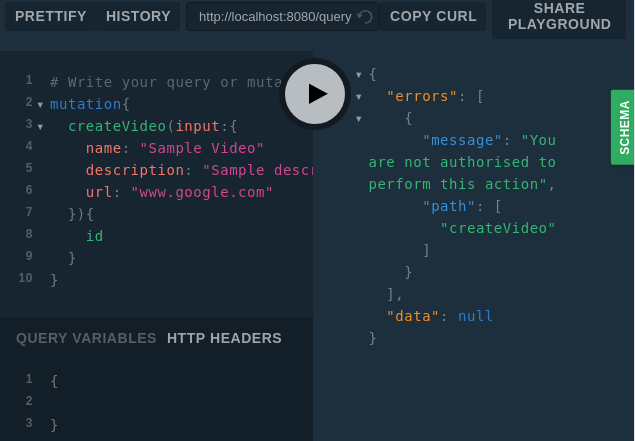
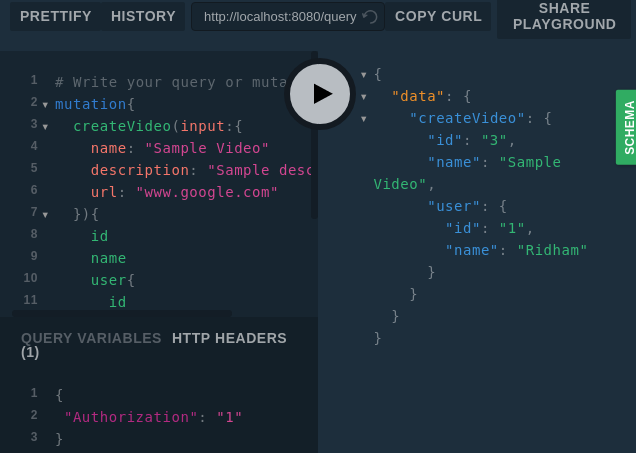
You can even pass arguments in the schema directives like this:
directive @hasRole(role: Role!) on FIELD_DEFINITIONenum Role { ADMIN USER }
Dataloaders
This all looks fancy, doesn’t it? You are loading data when needed. Clients have control of the data, there is no under-fetching and no over-fetching. But everything comes with a cost.
So what’s the cost here? Let’s take a look at the logs while fetching all the videos. We have 8 video entries and there are 5 users.
query{ Videos(limit: 10){ name user{ name } }}
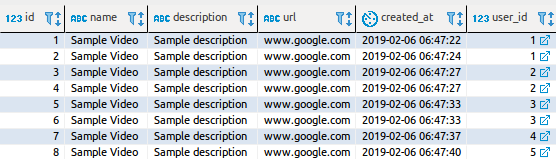
Query: Videos : SELECT id, name, description, url, created_at, user_id FROM videos ORDER BY created_at desc limit $1 offset $2Resolver: User : SELECT id, name, email FROM users where id = $1Resolver: User : SELECT id, name, email FROM users where id = $1Resolver: User : SELECT id, name, email FROM users where id = $1Resolver: User : SELECT id, name, email FROM users where id = $1Resolver: User : SELECT id, name, email FROM users where id = $1Resolver: User : SELECT id, name, email FROM users where id = $1Resolver: User : SELECT id, name, email FROM users where id = $1Resolver: User : SELECT id, name, email FROM users where id = $1

Why 9 queries (1 videos table and 8 users table)? It looks horrible. I was just about to have a heart attack when I thought about replacing our current REST API servers with this…but dataloaders came as a complete cure for it!
This is known as the N+1 problem, There will be one query to get all the data and for each data (N) there will be another database query.
This is a very serious issue in terms of performance and resources: although these queries are parallel, they will use your resources up.
We will use the dataloaden library from the author of gqlgen. It is a Go- generated library. We will generate the dataloader for the user first.
go get github.com/vektah/dataloadendataloaden github.com/ridhamtarpara/go-graphql-demo/api.User
This will generate a file userloader_gen.go which has methods like Fetch, LoadAll, and Prime.
Now, we need to define the Fetch method to get the result in bulk.
Here, we are waiting for 1ms for a user to load queries and we have kept a maximum batch of 100 queries. So now, instead of firing a query for each user, dataloader will wait for either 1 millisecond for 100 users before hitting the database. We need to change our user resolver logic to use dataloader instead of the previous query logic.
After this, my logs look like this for similar data:
Query: Videos : SELECT id, name, description, url, created_at, user_id FROM videos ORDER BY created_at desc limit $1 offset $2Dataloader: User : SELECT id, name, email from users WHERE id IN ($1, $2, $3, $4, $5)
Now only two queries are fired, so everyone is happy. The interesting thing is that only five user keys are given to query even though 8 videos are there. So dataloader removed duplicate entries.
Query Complexity

In GraphQL you are giving a powerful way for the client to fetch whatever they need, but this exposes you to the risk of denial of service attacks.
Let’s understand this through an example which we’ve been referring to for this whole article.
Now we have a related field in video type which returns related videos. And each related video is of the graphql video type so they all have related videos too…and this goes on.
Consider the following query to understand the severity of the situation:
{ Videos(limit: 10, offset: 0){ name url related(limit: 10, offset: 0){ name url related(limit: 10, offset: 0){ name url related(limit: 100, offset: 0){ name url } } } }}
If I add one more subobject or increase the limit to 100, then it will be millions of videos loading in one call. Perhaps (or rather definitely) this will make your database and service unresponsive.
gqlgen provides a way to define the maximum query complexity allowed in one call. You just need to add one line (Line 5 in the following snippet) in your graphql handler and define the maximum complexity (300 in our case).
gqlgen assigns fix complexity weight for each field so it will consider struct, array, and string all as equals. So for this query, complexity will be 12. But we know that nested fields weigh too much, so we need to tell gqlgen to calculate accordingly (in simple terms, use multiplication instead of just sum).
Just like directives, complexity is also defined as struct, so we have changed our config method accordingly.
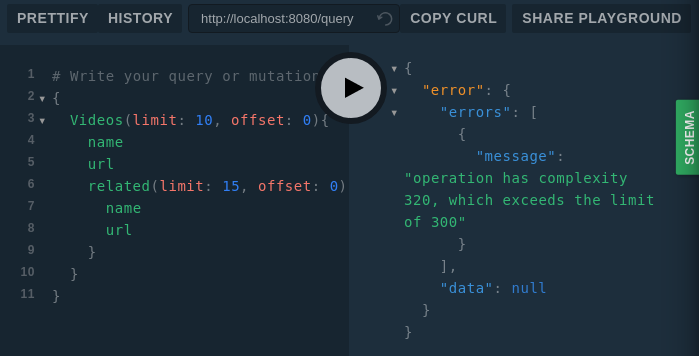
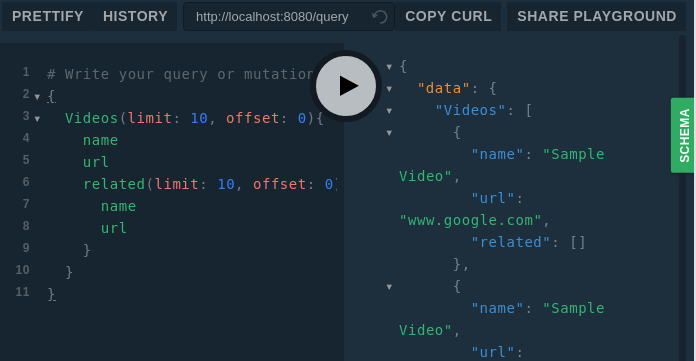
I haven’t defined the related method logic and just returned the empty array. So related is empty in the output, but this should give you a clear idea about how to use the query complexity.
Final Notes
This code is on Github. You can play around with it, and if you have any questions or concerns let me know in the comment section.
Thanks for reading! A few (hopefully 50) claps? are always appreciated. I write about JavaScript, the Go Language, DevOps, and Computer Science. Follow me and share this article if you like it.
Reach out to me on @Twitter @Linkedin. Visit www.ridham.me for more.