
By Emil Wallner
The current wave of deep learning took off five years ago. Exponential progress in computing power followed by a few success stories created the hype.
Deep learning is the technology that drives cars, beats humans at Atari games, and diagnoses cancer.

When I started learning deep learning I spent two weeks researching. I selected tools, compared cloud services, and researched online courses. In retrospect, I wish I could have built neural networks from day one. That’s what this article is set out to do.
You don’t need any prerequisites. Yet a basic understanding of Python, the command line, and Jupyter notebook will help.
Deep learning is a branch of machine learning. It’s proven to be an effective method to find patterns in raw data, such as an image or sound.
Say you want to make a classification of cat and dog images. Without specific programming, it first finds the edges in the pictures. Then it builds patterns from them. Next, it detects noses, tails, and paws. This enables the neural network to make the final classification of cats and dogs.
But, there are better machine learning algorithms for structured data. For example, if have you an ordered excel sheet with consumer data and you want to predict their next order. Then you can take a traditional approach and use simpler machine learning algorithms.
Core Logic
Imagine a machine with randomly adjusted cogwheels = ✱. The cogs are stacked in layers and they all impact each other. Initially, the machine does not work. The cogs are randomly adjusted and they all need to be tuned to give the correct output.
An engineer will then examine all the cogs and mark which cogs are causing the error. He starts with the last layer of cogs, the result of all errors combined. Once he knows the errors the last layer is causing, he works backward. This way he can calculate how much each cog is contributing to the error. We call this process back propagation.
The engineer then tunes each cog based on the error each made and runs the machine again. He keeps running the machine, calculates the errors and tunes each cog. He stays in this routine until the machine gives the correct output.
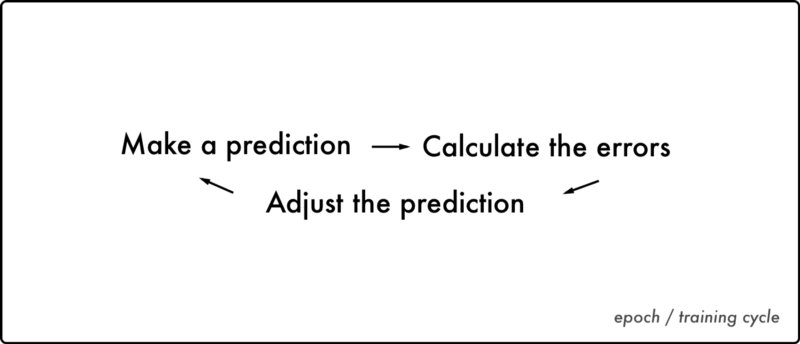
Neural networks operate in the same way. It knows the input and output and adjusts cogs to find the correlation between the two. Given an input, it tunes the cogs to predict the output. It then compares the predicted values with the real values.
To minimize the errors, the difference is between the predicted values and the real values. The neural network tunes the cogwheels. It tunes the cogs until the difference between the predicted and the real value is as low as possible.
Minimizing the error in an optimal way is gradient descent. The errors are calculated with the error / cost function.
A Shallow Artificial Neural Network
Many think of artificial neural networks as digital replicas of our neocortex. It’s not true.
We don’t know how enough about our brains to make that claim. It was a source of inspiration for Frank Rosenblatt, the inventors of neural networks.

Play with the Neural Network Simulator for one or two hours to get an intuition for it.
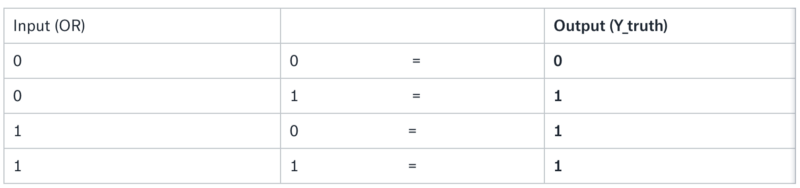
We’ll start by implementing a simple neural network to get to know the syntax in TFlearn. A classic 101 problem to start with is the OR operator. Although neural networks are better suited for other types of data, it’s a good problem to understand how it works.
All deep learning programs follow the same core logic:
- It starts with including libraries, then importing and cleaning the data. All the input are translated into digits, regardless if it’s images, audio or a sensory data.
These long lists of numbers are the input for our neural networks - Now design your neural network
Choose the type and amount of layer to have in your network - Then it enters the learning process.
It knows the input and output values and searches for the correlation between them - The final step gives you a prediction from your trained neural network.
Here is the code for our neural network:
Output
Training Step: 2000 | total loss: 0.00072 | time: 0.002s| SGD | epoch: 2000 | loss: 0.00072 -- iter: 4/4Testing OR operator0 or 0: [[ 0.04013482]]0 or 1: [[ 0.97487926]]1 or 0: [[ 0.97542077]]1 or 1: [[ 0.99997282]]
Line 1 The lines starting with # are comments
They are used to explain the code
Line 2 Include the TFlearn library
This allows us to use deep learning functions from Google’s Tensorflow
Line 5–6 Data from the table are stored in lists
The dot at the end of each number maps each integer into floats
It stores numbers with decimal values which make the calculations precise
Line 9 Initialize the neural net and specify the dimension or shape of our input data
Every OR operator comes in a pair and thus has the shape of 2
None is a default value and represents the batch size
Line 10: Our output layer.
The activation function maps the output in the layer between an interval
In our case, we use a Sigmoid function that maps the value between 0 and 1
Read more about Lines 9 and 10.
Line 11 Apply the regression
The optimizer chooses which algorithm to minimize the cost function
The learning rate decides how fast to modify the neural network, and the loss variable decides how to calculate the errors
Line 14 Selects which neural network to use
It’s also used to specify where to store the training logs
Line 15 Trains your neural network and model
Select your input data (OR) and the true labels (Y_truth)
Epochs determines how many times to run all your data through your neural network
If you set snapshot=True it would validate the model after each epoch
Line 18–22 Makes a prediction with your trained model
In our case, it returns the probability of returning True/1
Read more about lines 14–22.
Output labels The first result means that the combination [0.] & [0.] has a has a 4% probability of being true, and so on. Training step indicates how many batches you have trained.
Since the data can fit into one batch it’s the same as Epoch. If the data is too big for the memory you need to break down the training in chunks. The loss measures the sum of errors from each epoch.
SGD stands for Stochastic Gradient Descent and method to minimize the cost function.
Iter displays the current data index and the total amount of input items.
You can find the above logic and syntax in almost every TFlearn neural network. The best way to get a feel for the code is to modify it and create a couple of errors.
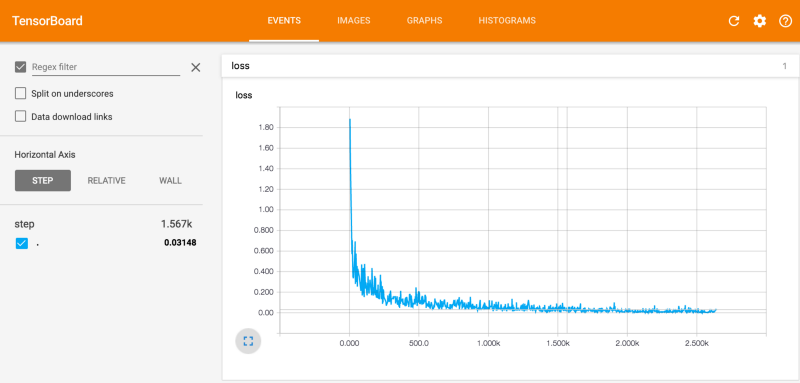
With [Tensorboard](TensorBoard: Visualizing Learning) you can visualize each experiment and build an intuition for how each parameter changes the training.
Here is a suggestion of some examples that you can run. I’d recommend playing with it for a couple of hours to get used to the environment and the TFlearn parameters.
Experiments
- Increase the training and epochs
- Try adding and changing a parameter to each function from the documentation
For exampleg = tflearn.fullyconnected(g, 1, activation=’sigmoid’)becomestflearn.fullyconnected(g, 1, activation=’sigmoid’, bias=False) - Add integers in the input data
- Change the shape in the input layer
- Change the activation function in the output layer
- Use a different method for gradient descent
- Change how the neural network calculates the cost
- Change the X and Y to AND and NOT logic operators
- Change the output data to XOR logic operators
For example swap the last Y_truth from [1.] to [0.]
You have to add a layer in your network for it to work - Make it learn faster
- Find a way to make each learning step take more than 0.1 second
Getting Started
Python combined with Tensorflow is the most common stack for deep learning.
TFlearn is a high-level framework that runs on-top of Tensorflow.
Another common framework is Keras. It’s a more robust library, but I find the TFlearn syntax cleaner and easier to understand.
They are both high-level frameworks that run on-top of Tensorflow.
You can run simple neural networks on your computer’s CPU. But most experiments will take several hours or even weeks to run. That’s why most use modern GPUs for deep learning, often through a cloud service.
The easiest solution for cloud GPUs is FloydHub. If you have basic command line skills, it shouldn’t take more than 5 minutes to set up FloydHub.
Use the FloydHub docs to install the floyd-cli command line tool. FloydHub also provides support on their Intercom chat if you get stuck at any point.
Let’s run your first neural network in FloydHub using TFlearn, Jupyter Notebook, and Tensorboard.
After installing and logging in to FloydHub, download the files you need for this guide.
Go to your terminal and type the following command:
git clone https://github.com/emilwallner/Deep-Learning-101.git
Open the folder and initiate FloydHub:
cd Deep-Learning-101floyd init 101
The FloydHub web dashboard will open in your browser, and you will be prompted to create a new FloydHub project called 101. Once that's done, go back to your terminal and run the same initcommand.
floyd init 101
Now you are ready to run your neural network job on FloydHub.
With the floyd runcommand, you can pass in various settings. In our case, we will want to:
- Mount a public dataset on FloydHub, which I’ve already uploaded.
At the data directory type--data emilwallner/datasets/cifar-10/1:data
You can explore this dataset (and many other public datasets) by viewing it on FloydHub - Use a cloud GPU with
--gpu - Enable Tensorboard with
--tensorboard - Run the job in Jupyter Notebook mode with
--mode jupyter
Okay, let’s run our job:
floyd run --data emilwallner/datasets/cifar-10/1:data --gpu --tensorboard --mode jupyter
Once it initiates Jupyter in your browser, click on the file named start-here.ipnyb.
start-here.ipnyb is a simple neural network to get to know the syntax in TFlearn. It learns the logic of the OR operator, explained in full later on.
In the menu row, click on Kernel > Restart & Run _A_ll. If you see the message, it’s working, then you are good to go.
Go to your FloydHub project to find the link for Tensorboard.
A Deep Neural Network
Deep learning are neural networks with more than one hidden layer. There are already plenty of detailed tutorials on how CNNs (Convolutional Neural Networks) work. You can find them here, here, and here.
So, we’ll focus on the high-level notions that you can apply to most neural networks.
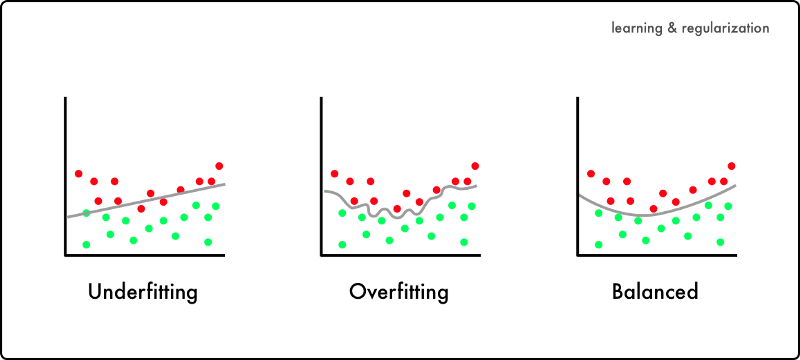
You want to train neural networks to make predictions on data it was not trained on. It needs an ability to generalize. It’s a balance between learning and forgetting.
You want it to learn to separate signal from noise. But also forget the signals that are only found in the training data.
If the neural network is not learning enough it’s underfitting. The opposite is overfitting. That’s when it has learned too much from the training data.
Regularization is the process to reduce overfitting by forgetting training specific signals.
To get an intuition for these concepts, we’ll be working with the CIFAR-10 dataset. It’s a dataset with 60k images in ten different categories, such as cars, trucks, and birds. The goal is to predict which of the ten categories a new image belongs to.
To get an intuition for these concepts, we’ll be working with the CIFAR-10 dataset. It’s a dataset with 60k images in ten different categories, such as cars, trucks, and birds. The goal is to predict which of the ten categories a new image belongs to.

Normally, we have to scrape the data, clean it and apply filters to the images. But to narrow it down, we’ll only focus on the neural networks. You can run the all the examples from the Jupyter notebook that in the installation section.
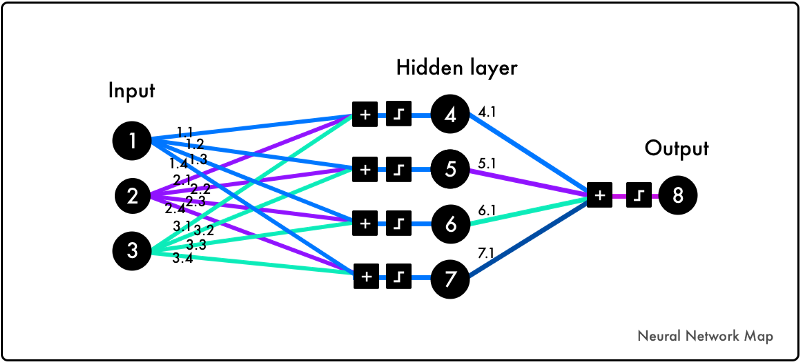
The input layer takes an image which has been mapped into digits. The output layer classifies the images into ten categories. The hidden layers are a mix of convolutional, pooling, and connected layers.
Choosing the amount of layers
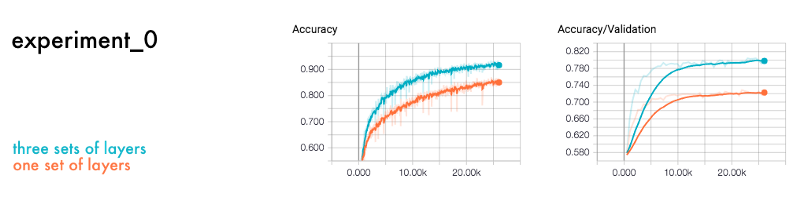
Let’s make a comparison with a neural network with one against three sets of layers. Each set includes a convolutional, pooling and connected layer.
The first two experiments are called [experiment-0-few-layers.ipynb](https://github.com/emilwallner/Deep-Learning-101/blob/master/experiment_0_few_layers.ipynb) and [experiment-0-three-layer-sets.ipynb](https://github.com/emilwallner/Deep-Learning-101/blob/master/experiment_0_three_layer_sets.ipynb).
You can run these notebooks by clicking Kernel > Restart & Run All in the menu bar. Then take a peek at the training log in Tensorboard. You’ll see that the one with many layers is ~15% more accurate. The layer with few layers is underfitting — it’s not learning enough.
You can run the same example from the folder you downloaded earlier, as well as the all the upcoming experiments.
Take a look at the Accuracy and Accuracy/Validation. It’s best practice in deep learning to split the dataset in two. One for the training the neural network and another for validating it. This way you can tell how well the neural network makes predictions on new data, or its ability to generalize.
This is how you can tell how well the neural network makes predictions on new data, or its ability to generalize.
As we can see, the accuracy of the training data is higher than the accuracy on the validation dataset. The neural network has included background noise and details that hinder it from predicting new images.
To deal with the overfitting you can punish complex functions and introduce noise into the neural network. Common regularization techniques to prevent this are dropout layers and punishing complex functions.
Dropout layers
We can compare the dropout regularization to the value of a democracy. Instead of having a few powerful neurons that decide the final outcome, they distribute the power.
The neural network is forced to learn several independent representations. When it makes the final prediction it then has several distinct patterns to learn from.
This is an example of a neural network with a dropout layer.
In this comparison, the neural networks are the same except that one has a dropout layer and the other one doesn’t.
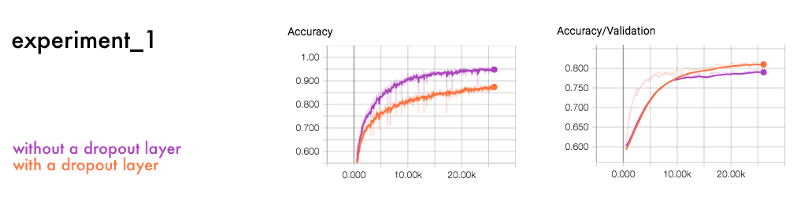
In each layer of the neural network, the neurons become dependent on each other. Some neurons gain more influence than others. The dropout layer randomly mutes different neurons. This way each neuron has to build a distinct contribution to the final output.
The second popular method to prevent overfitting is applying an L1 or L2 regularizer function on each layer.
L1 and L2 regularization
Say you want to describe a horse. If the description is too detailed, you exclude too many horses. But, if it’s too general you might include other animals. The L1 and L2 regularization helps the network to make this distinction.
If we make a similar comparison as the previous experiment we get a similar outcome.
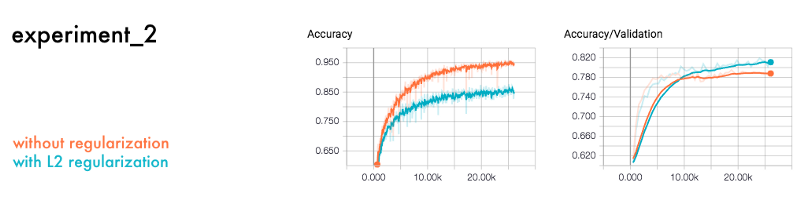
The neural network with regularization functions outperforms the one without them.
The regularization function L2 punishes functions that are too complex. It measures how much each function contributes to the final output. It then punishes the ones with large coefficients.
Batch size
Another core hyper parameter is batch size, the amount of data to use for each training step. Below is a comparison between a large and a small batch size.
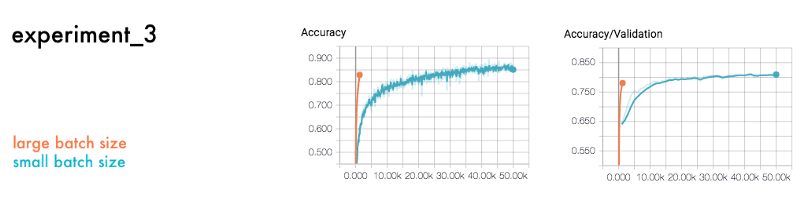
As we see in the result, a large batch size requires fewer cycles but has more accurate training steps. In comparison, a smaller batch size is more random but take more steps to compensate for it.
A large batch size requires fewer learning steps. But, you need more memory and time to compute each step.
Learning rate
The final experiment is a comparison between a network with small, medium, and large learning rates.
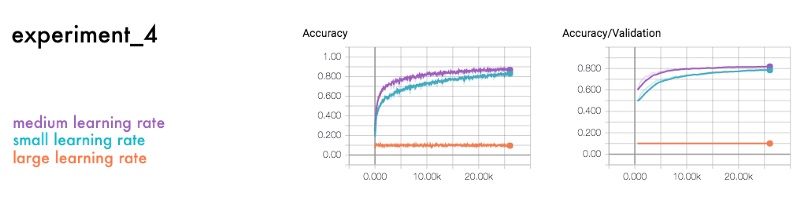
The learning rate is often considered one of the most important parameters due to its impact. It regulates how to adjust the change in prediction for each learning step. If the learning rate is too high or too low it might not converge, like the large learning rate above.
There is no fixed way of designing neural networks. A lot of it has to do with experimentation. Look at what others have done by adding layers, and tuning hyper parameters.
If you have access to a lot of computing power, you can create programs to design and tune the hyper parameters.
When you’re done running your job, you should spin down your cloud GPU instance by clicking Cancel in the FloydHub web dashboard for your job.
Next Steps
In TFlearn’s official example repo, you can get a feel for some of the best performing CNNs. Try copying some of the methods and improve the validation for the CIFAR-10 dataset. The best result so far is 96.53% (Graham, 2014).
It’s also worth learning the Python syntax and get familiar with the command line. This reduces unnecessary cognitive load so you can focus on deep learning notions. Start with Codecademy’s course on Python and then do the command line one. It should not take more than three days if you do it full-time.
Thanks to Ignacio Tonoli de Maussion, Per Harald Borgen, Jean-Luc Wingert, Sai Soundararaj, and Charlie Harrington for reading drafts of this. And gratitude towards the TFlearn community for the documentation and sample code.
About Emil Wallner
This the first part in a multi-part blog series as I learn deep learning. I’ve spent a decade exploring human learning. I working for Oxford’s business school, invested in education startups, and built an education technology business. Last year, I enrolled at Ecole 42 to apply my knowledge of human learning to machine learning.
You can follow along my learning journey on Twitter. If you have any questions/suggestions please leave a comment below or ping me on Medium.
This was first published as a community post on Floydhub’s blog.