By Jannes Klaas
Last year, DeepMind’s AlphaGo beat Go world champion Lee Sedol 4–1. More than 200 million people watched as reinforcement learning (RL) took to the world stage. A few years earlier, DeepMind had made waves with a bot that could play Atari games. The company was soon acquired by Google.
Many researchers believe that RL is our best shot at creating artificial general intelligence. It is an exciting field, with many unsolved challenges and huge potential.
Although it can appear challenging at first, getting started in RL is actually not so difficult. In this article, we will create a simple bot with Keras that can play a game of Catch.
The game
 A prettier version of the game we will actually train on
A prettier version of the game we will actually train on
Catch is a very simple arcade game, which you might have played as a child. Fruits fall from the top of the screen, and the player has to catch them with a basket. For every fruit caught, the player scores a point. For every fruit lost, the player loses a point.
The goal here is to let the computer play Catch by itself. But we will not use the pretty game above. Instead, we will use a simplified version to make the task easier:
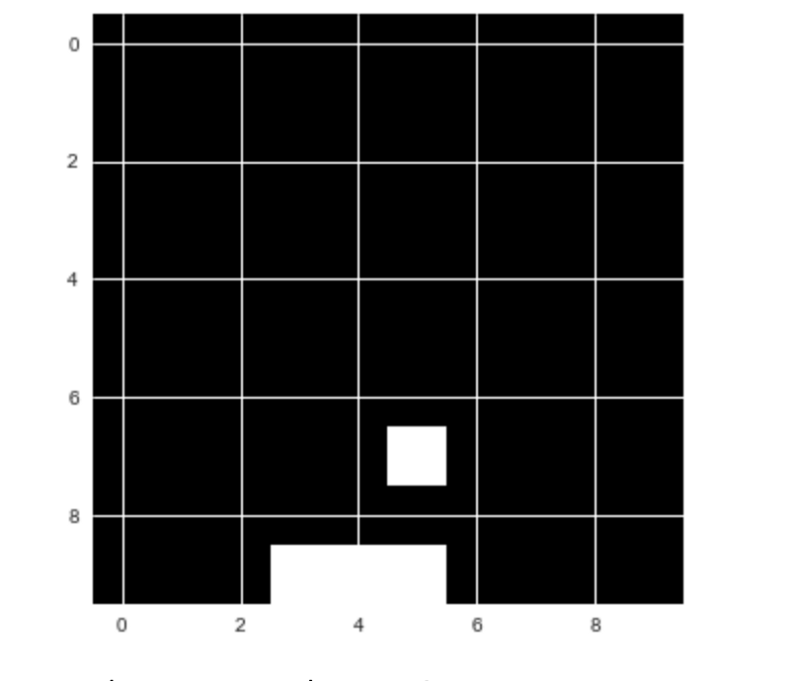 Our simplified catch game
Our simplified catch game
While playing Catch, the player decides between three possible actions. They can move the basket to the left, to the right, or stay put.
The basis for this decision is the current state of the game. In other words: the positions of the falling fruit and of the basket.
Our goal is to create a model, which, given the content of the game screen, chooses the action which leads to the highest score possible.
This task can be seen as a simple classification problem. We could ask expert human players to play the game many times and record their actions. Then, we could train a model to choose the ‘correct’ action that mirrors the expert players.
But this is not how humans learn. Humans can learn a game like Catch by themselves, without guidance. This is very useful. Imagine if you had to hire a bunch of experts to perform a task thousands of times every time you wanted to learn something as simple as Catch! It would be expensive and slow.
In reinforcement learning, the model trains from experience, rather than labeled data.
Deep reinforcement learning
Reinforcement learning is inspired by behavioral psychology.
Instead of providing the model with ‘correct’ actions, we provide it with rewards and punishments. The model receives information about the current state of the environment (e.g. the computer game screen). It then outputs an action, like a joystick movement. The environment reacts to this action and provides the next state, alongside with any rewards.

The model then learns to find actions that lead to maximum rewards.
There are many ways this can work in practice. Here, we are going to look at Q-Learning. Q-Learning made a splash when it was used to train a computer to play Atari games. Today, it is still a relevant concept. Most modern RL algorithms are some adaptation of Q-Learning.
Q-learning intuition
A good way to understand Q-learning is to compare playing Catch with playing chess.
In both games you are given a state, S. With chess, this is the positions of the figures on the board. In Catch, this is the location of the fruit and the basket.
The player then has to take an action, A. In chess, this is moving a figure. In Catch, this is to move the basket left or right, or remain in the current position.
As a result, there will be some reward R, and a new state S’.
The problem with both Catch and chess is that the rewards do not appear immediately after the action.
In Catch, you only earn rewards when the fruits hit the basket or fall on the floor, and in chess you only earn a reward when you win or lose the game. This means that rewards are sparsely distributed. Most of the time, R will be zero.
When there is a reward, it is not always a result of the action taken immediately before. Some action taken long before might have caused the victory. Figuring out which action is responsible for the reward is often referred to as the credit assignment problem.
Because rewards are delayed, good chess players do not choose their plays only by the immediate reward. Instead, they choose by the expected future reward.
For example, they do not only think about whether they can eliminate an opponent’s figure in the next move. They also consider how taking a certain action now will help them in the long run.
In Q-learning, we choose our action based on the highest expected future reward. We use a “Q-function” to calculate this. This is a math function that takes two arguments: the current state of the game, and a given action.
We can write this as: Q(state, action)
While in state S, we estimate the future reward for each possible action A. We assume that after we have taken action A and moved to the next state S’, everything works out perfectly.
The expected future reward Q(S,A) for a given a state S and action A is calculated as the immediate reward R, plus the expected future reward thereafter Q(S',A'). We assume the next action A' is optimal.
Because there is uncertainty about the future, we discount Q(S’,A’) by the factor gamma γ.
Q(S,A) = R + γ * max Q(S’,A’)
Good chess players are very good at estimating future rewards in their head. In other words, their Q-function Q(S,A) is very precise.
Most chess practice revolves around developing a better Q-function. Players peruse many old games to learn how specific moves played out in the past, and how likely a given action is to lead to victory.
But how can a machine estimate a good Q-function? This is where neural networks come into play.
Regression after all
When playing a game, we generate lots of “experiences”. These experiences consist of:
- the initial state,
S - the action taken,
A - the reward earned,
R - and the state that followed,
S’
These experiences are our training data. We can frame the problem of estimating Q(S,A) as a regression problem. To solve this, we can use a neural network.
Given an input vector consisting of S and A, the neural net is supposed to predict the value of Q(S,A) equal to the target: R + γ * max Q(S’,A’).
If we are good at predicting Q(S,A) for different states S and actions A, we have a good approximation of the Q-function. Note that we estimate Q(S’,A’) through the same neural net as Q(S,A).
The training process
Given a batch of experiences < S, A, R, S’ >, the training process then looks as follows:
- For each possible action
A’(left, right, stay), predict the expected future rewardQ(S’,A’)using the neural net - Choose the highest value of the three predictions as
max Q(S’,A’) - Calculate
r + γ * max Q(S’,A’). This is the target value for the neural net - Train the neural net using a loss function. This is a function that calculates how near or far the predicted value is from the target value. Here, we will use
0.5 * (predicted_Q(S,A) — target)²as the loss function.
During gameplay, all the experiences are stored in a replay memory. This acts like a simple buffer in which we store < S, A, R, S’ > pairs. The experience replay class also handles preparing the data for training. Check out the code below:
Defining the model
Now it is time to define the model that will learn a Q-function for Catch.
We are using Keras as a front end to Tensorflow. Our baseline model is a simple three-layer dense network.
Already, this model performs quite well on this simple version of Catch. Head over to GitHub for the full implementation. You can experiment with more complex models to see if you can get better performance.
Exploration
A final ingredient to Q-Learning is exploration.
Everyday life shows that sometimes you have to do something weird and/or random to find out whether there is something better than your daily trot.
The same goes for Q-Learning. Always choosing the best option means you might miss out on some unexplored paths. To avoid this, the learner will sometimes choose a random option, and not necessarily the best.
Now we can define the training method:
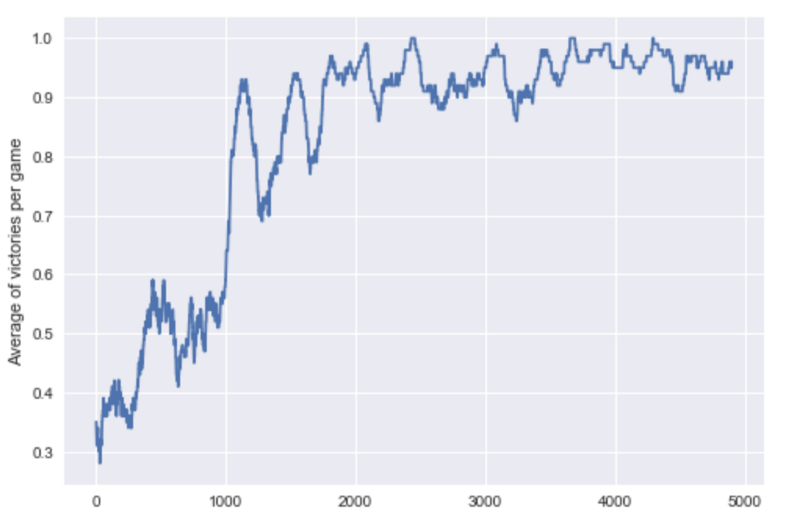
I let the game train for 5,000 epochs, and it does quite well now!
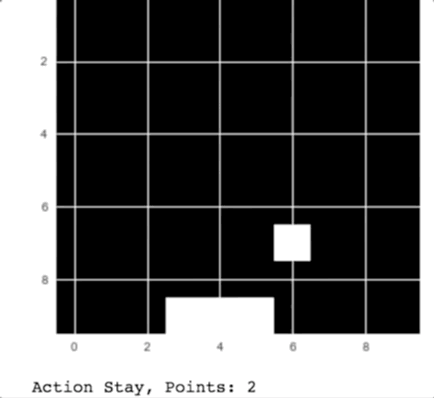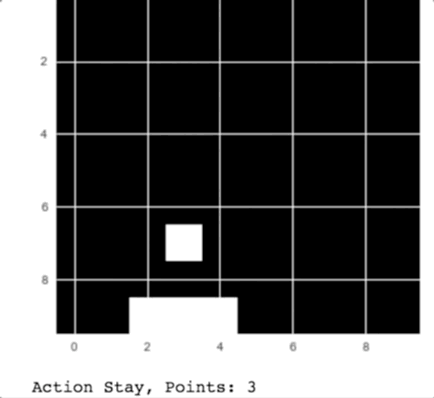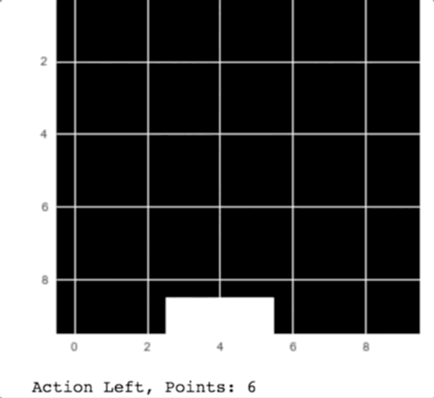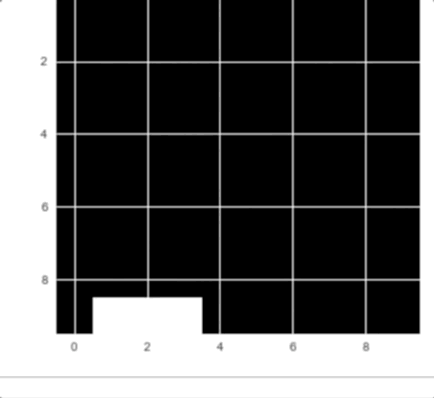 Our Catch player in action
Our Catch player in action
As you can see in the animation, the computer catches the apples falling from the sky.
To visualize how the model learned, I plotted the moving average of victories over the epochs:
Where to go from here
You now have gained a first overview and an intuition of RL. I recommend taking a look at the full code for this tutorial. You can experiment with it.
You might also want to check out Arthur Juliani’s series. If you’d like a more formal introduction, have a look at Stanford’s CS 234, Berkeley’s CS 294 or David Silver’s lectures from UCL.
A great way to practice your RL skills is OpenAI’s Gym, which offers a set of training environments with a standardized API.
Acknowledgements
This article builds upon Eder Santana’s simple RL example, from 2016. I refactored his code and added explanations in a notebook I wrote earlier in 2017. For readability on Medium, I only show the most relevant code here. Head over to the notebook or Eder’s original post for more.
About Jannes Klaas
This text is part of the Machine Learning in Financial Context course material, which helps economics and business students understand machine learning.
I spent a decade building software and am now on the journey bring ML to the financial world. I study at the Rotterdam School of Management and have done research with the Institute for Housing and Urban development studies.
You can follow me on Twitter. If you have any questions or suggestions please leave a comment or ping me on Medium.