

These days, organizations are collecting large volumes of data from diverse sources. And their data teams need to harness the power of that data efficiently.
Both ETL (Extract, Transform, Load) and ELT (Extract, Load, Transform) pipelines play pivotal roles in integrating data from various sources into a centralized data repository.
But how do these data integration techniques differ, and which one is best suited for your needs? In this comprehensive guide, we'll take a closer look at ETL and ELT pipelines.
Understanding the workflow of ETL and ELT—along with factors such as data volume, scalability, and security—will help you choose the data integration approach that best aligns with your specific requirements.
ETL (Extract, Transform, Load) Pipelines
Let’s start by understanding the ETL process.
What Is ETL?
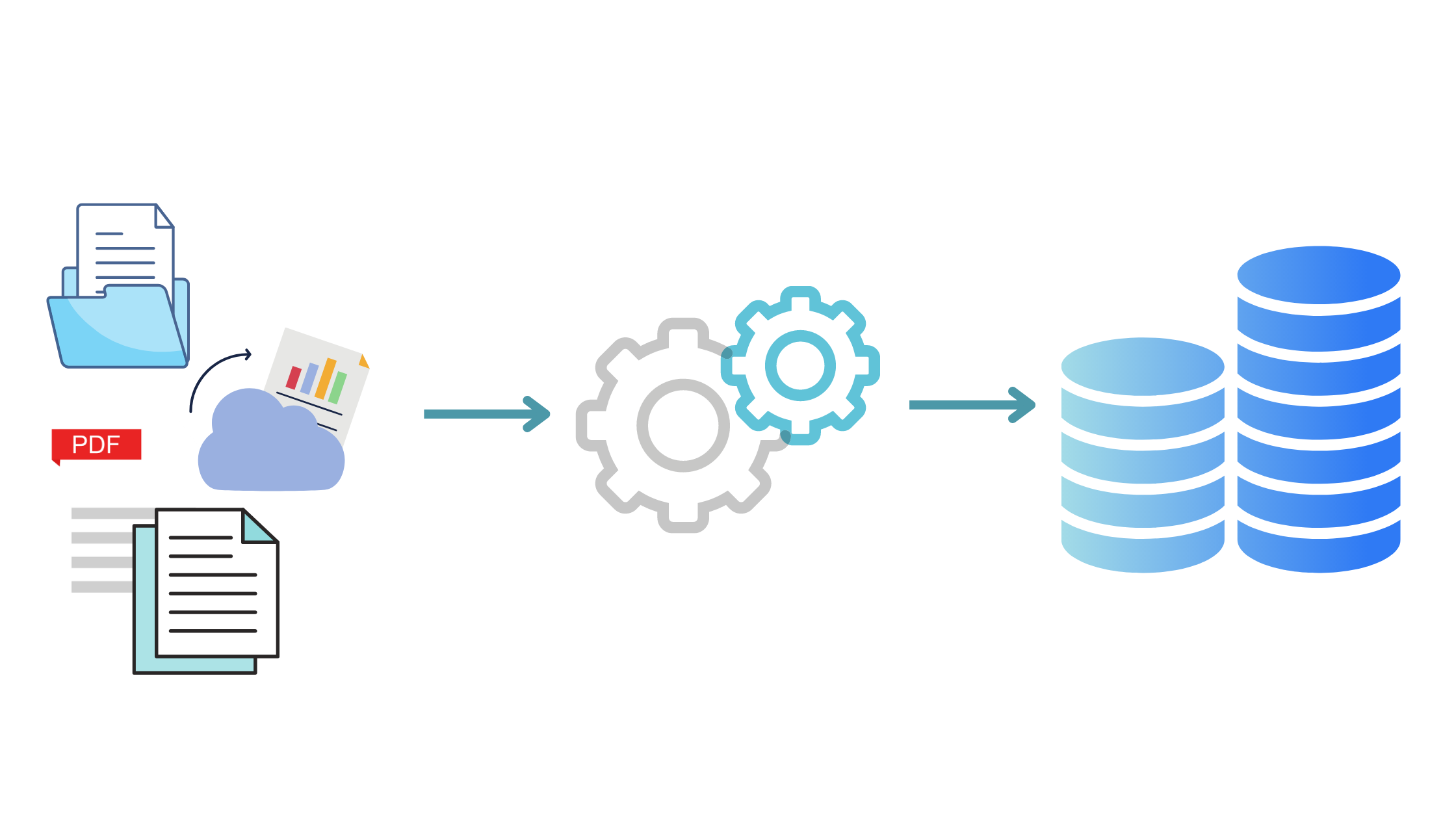 Image showing an Extract, Transform, Load pipeline
Image showing an Extract, Transform, Load pipeline
ETL stands for Extract, Transform, Load. It is a data integration process used to extract data from multiple sources, transform it into a consistent format, and then load it into a data warehouse for analysis and reporting purposes.
Here’s a breakdown of the steps in ETL:
Step 1 – Extraction
Data is extracted from various sources such as databases, APIs, flat files, or web services. This stage involves connecting to the source systems and pulling the required data.
Step 2 – Transformation
In this stage, the extracted data is transformed into a standardized format suitable for analysis. Transformations include data cleansing to remove duplicates or incorrect records, data enrichment by combining data from multiple sources, data aggregation, and applying business rules to create derived metrics.
Step 3 – Loading
Transformed data is loaded into the target data warehouse, which could be a relational database or a big data platform like Google BigQuery. The loading process should be optimized to ensure data integrity and performance.
ETL is commonly used in data migration between systems, data warehousing for business intelligence, reporting, and analysis.
Pros and Cons of ETL Pipelines
The following are some of the advantages of ETL pipelines:
- Data quality: ETL pipelines ensure data is cleansed and standardized before storage, leading to better data quality.
- Performance: By transforming data before loading, the data warehouse is optimized for querying and reporting.
- Security: Sensitive data can be masked or encrypted during the transformation process.
Here are some limitations of ETL pipelines:
- ETL pipelines are typically designed for batch processing, which may not be suitable for real-time data needs.
- Building and maintaining ETL pipelines can be complex, especially when dealing with numerous data sources and transformations.
ELT (Extract, Load, Transform) Pipelines
Next, let's go over ELT.
What Is ELT?
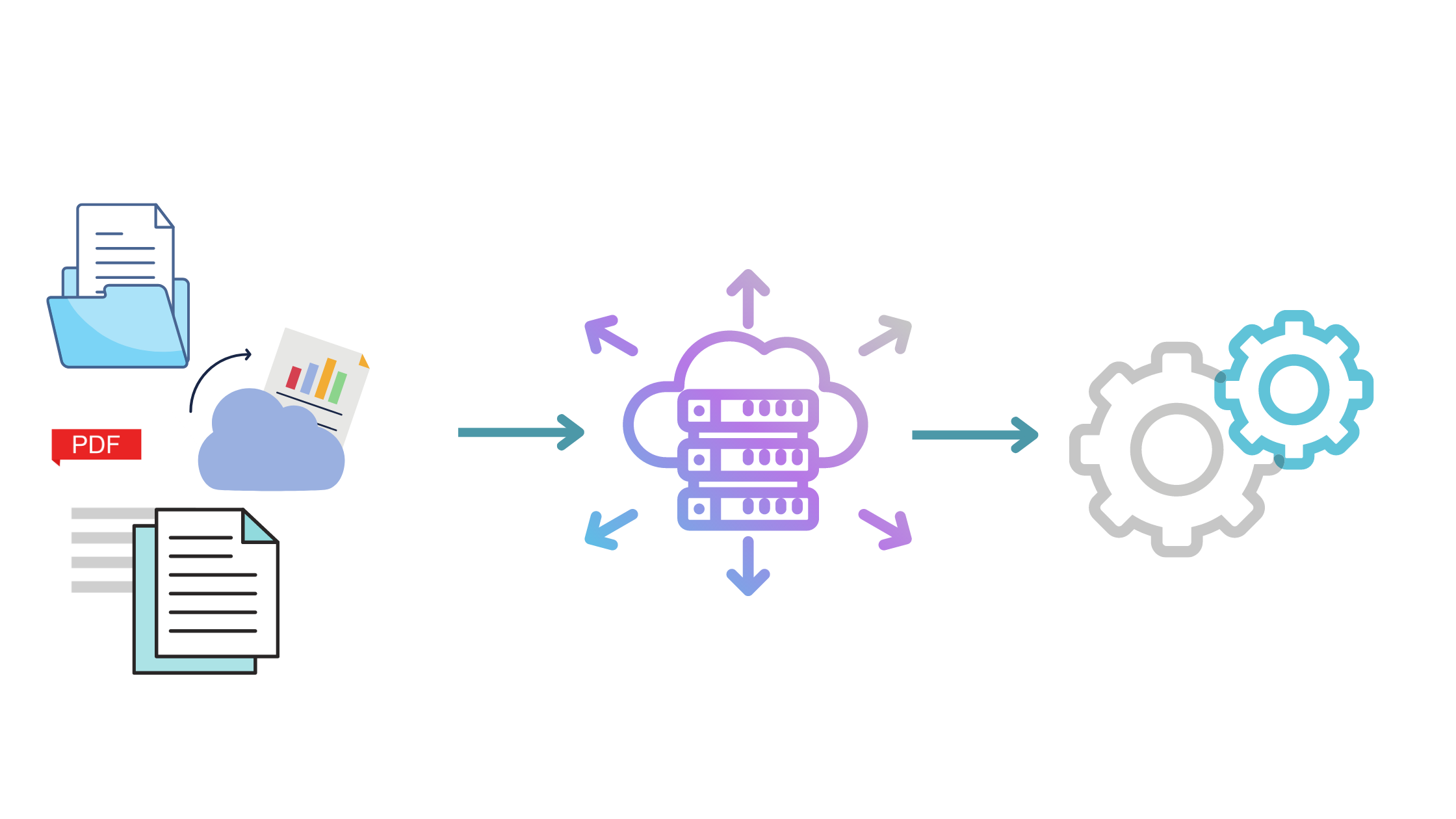 Image showing an Extract, Load, Transform pipeline
Image showing an Extract, Load, Transform pipeline
ELT stands for Extract, Load, Transform. Unlike ETL, ELT involves loading raw data into the data warehouse first and then performing transformations on the data within the data warehouse itself.
ELT has gained popularity with the emergence of cloud-based data warehouses, which can handle large volumes of data efficiently.
Here’s an overview of the steps in ELT:
Step 1 – Extraction
Similar to ETL, data is extracted from various sources using connectors or ingestion tools. The extracted data is loaded into the data warehouse in its raw form.
Step 2 – Loading
In the loading stage, raw data is ingested into the data warehouse, often using massively parallel processing (MPP) techniques, which can handle large-scale data ingestion efficiently.
Step 3 – Transformation
Once the data is inside the data warehouse, transformations are applied using SQL queries or specialized data processing tools. These transformations can be performed on-demand and on raw data, which allows for more flexibility in analysis.
Pros and Cons of ELT Pipelines
Some advantages of ELT pipelines include:
- Real-time analysis: With data loading occurring before transformation, ELT allows for near-real-time analysis of raw data.
- Cost-effectiveness: By leveraging cloud-based data warehouses, organizations can avoid the need for separate ETL servers, reducing infrastructure costs.
Some limitations of using ELT pipelines:
- Performing transformations on raw data within the data warehouse requires specialized skills and knowledge of the platform's processing capabilities.
- Data redundancy: In some cases, raw data and transformed data may coexist, leading to increased storage requirements.
How to Choose Between ETL and ELT – Factors to Consider
 Drawing of a woman choosing between different options
Drawing of a woman choosing between different options
When it comes to selecting the most suitable data integration approach for your organization, several features must be taken into account. So let's explore the key factors that can guide your decision-making process:
#1 – Data Volume and Complexity
ETL pipelines are well-suited for applications with moderate data volumes and complex transformation needs. The data extraction and transformation phases are performed before loading data into the warehouse, ensuring that only refined and processed data is stored.
ELT, on the other hand, is useful for large data sets, especially when dealing with raw or unstructured data. With data loading occurring first, ELT allows for greater flexibility in data exploration and analysis within the data warehouse.
So if your organization deals with massive volumes of raw or semi-structured data and requires real-time or near-real-time insights, ELT might be the better choice. But for applications where the data needs extensive cleansing and transformation before analysis, ETL might be more appropriate.
#2 – Data Storage and Infrastructure
ETL pipelines often require additional infrastructure, including staging areas and dedicated ETL servers. This ensures efficient data transformation before loading into the data warehouse.
ELT leverages the scalability and distributed computing capabilities of cloud-based data warehouses, eliminating the need for separate ETL infrastructure.
#3 – Performance and Scalability
ETL pipelines can be optimized for performance, as data transformation occurs before loading. This pre-processing allows for data cleansing, aggregation, and indexing, leading to faster query response times in the data warehouse.
ELT leverages the parallel processing capabilities of cloud-based data warehouses, enabling them to handle large data volumes with ease. So if you need scalability and real-time analysis of massive datasets, ELT can be a good choice.
#4 – Security and Compliance Requirements
ETL pipelines require data transformations before loading into the data warehouse. This provides opportunities to implement security measures like data masking or encryption before data storage.
ELT may require additional security measures within the data warehouse to protect sensitive raw data during analysis, as transformations occur after loading.
Conclusion
ETL pipelines help in optimizing data quality and performance through extensive pre-processing. This makes them ideal for applications with complex transformation needs.
On the other hand, ELT handles vast volumes of raw data and provides real-time or near-real-time analysis, leveraging the scalability of cloud-based data warehouses.
By factoring in data volume, complexity, infrastructure, performance, and security, you can make an informed decision that best aligns with your specific data integration requirements. Happy data integration!