
By Lak Lakshmanan
It can be extremely cost-effective (both in terms of storage and in terms of query time) to use nested fields rather than flatten out all your data. Nested, repeated fields are very powerful, but the SQL required to query them looks a bit unfamiliar. So, it’s worth spending a little time with STRUCT, UNNEST and ARRAY_AGG. Using these three in combination also makes some kinds of queries much, much easier to write.

Task
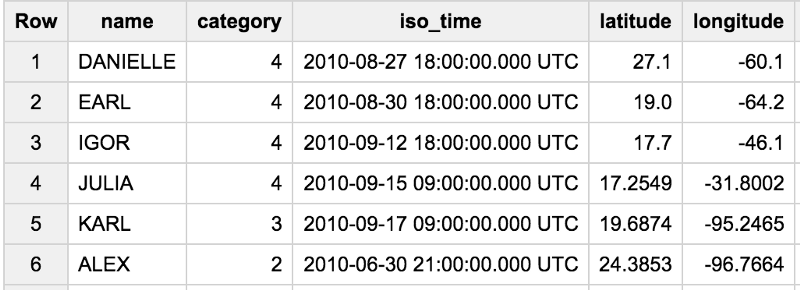
Let’s take a BigQuery table of tropical cyclones. Here’s a preview of the table:

The task is to find the maximum usa_sshs (better known as “category”) reached by each North American hurricane (basin=NA) of the 2010 season and the time at which the category was first reached. I want to be able to say something like “Hurricane Danielle reached Category 4 at 18:00 UTC on 2010–08–27 when it was at (27.1, -60.1)”.
Here’s the solution query. In this article, I will build it piece-by-piece.
Where’s the hurricane?
My first step was to create a history of hurricane locations. Essentially, I want to get to:
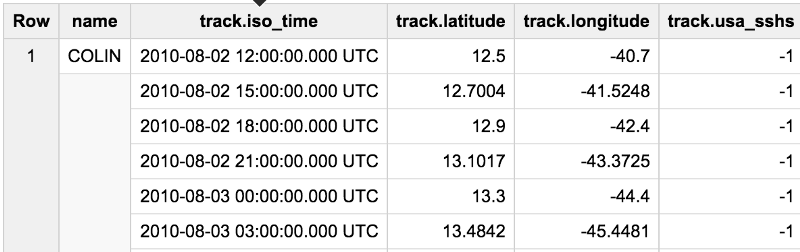
We can filter by basin and season:
#standardsqlWITH hurricanes AS (SELECT NAME, iso_time, latitude, longitude, usa_sshsFROM `bigquery-public-data.noaa_hurricanes.hurricanes`WHERE season = '2010' AND basin = 'NA')SELECT * from hurricanes LIMIT 5
But this gives us a jumble of rows that meet the necessary criteria. What we need is to get an ordered list of locations for each hurricane. Just adding a GROUP BY to the above query won’t work. (Why not? Try it out!)
This query, however, works:
#standardsqlWITH hurricanes AS (SELECT MIN(NAME) AS name, ARRAY_AGG(STRUCT(iso_time, latitude, longitude, usa_sshs) ORDER BY iso_time ASC) AS trackFROM `bigquery-public-data.noaa_hurricanes.hurricanes`WHERE season = '2010' AND basin = 'NA'GROUP BY sid)
SELECT * from hurricanes LIMIT 5
Let’s tease the query apart:
- We group by storm id, but when we group, we get a bunch of rows. Often what we’d do is to do an aggregation such as
SUM()orAVG()of the rows in the group to come down to just one value per row of the result set. - To retain all the rows in the group, use
ARRAY_AGG(). In this array, we don’t want just one field, we want four. So, I make the four fields (time, lat, lon, hurricane strength) a struct. The struct allows me to retain the element-by-element relationship between these four columns. - Order the array by time.
Maximum category
Now that we have each hurricane’s history, let’s find out the maximum category reached by the hurricane. What we want is:

Here’s the additional WITH:
WITH hurricanes AS ( ...),
cat_hurricane AS (SELECT name,track, (SELECT MAX(usa_sshs) FROM UNNEST(track)) AS categoryfrom hurricanesORDER BY category DESC)
SELECT * from cat_hurricane
Selecting the name from the hurricanes table is quite obvious. It’s just a column. But what does selecting track do? Because track is an array, you get the whole array.
To get a single row from the track array, we need to go through UNNEST(). When you call UNNEST(track), it makes a table, so the UNNEST() can only be used in the FROM clause of BigQuery. Once you understand that UNNEST(track) makes a table with four columns (the four columns in the STRUCT), you see that MAX(usa_sshs) simply computes the maximum strength reached by each hurricane.
Time at which maximum category is reached
How do we find the time at which the maximum category is reached? Essentially, find all the rows in the UNNEST(track) table for which the usa_sshs column is the maximum category and limit it to 1, to get the first row at which category is met:
SELECT name, category, (SELECT AS STRUCT iso_time, latitude, longitude FROM UNNEST(track) WHERE usa_sshs = category ORDER BY iso_time LIMIT 1).*FROM cat_hurricaneORDER BY category DESC, name ASC
Here’s the full query. Do play around with some variants to understand what is happening:
- Why do I have the
.*? Play around with the query to see what happens if I don’t include the.*? (Hint: it has to do with the name of the column). - What happens if I don’t do the
AS STRUCTabove? - What happens if I don’t do the
LIMIT 1?