
By Adam Goldschmidt
a hash table (hash map) is a data structure that implements an associative array abstract data type, a structure that can map keys to values.
If it smells like a Python dict, feels like a dict, and looks like one… well, it must be a dict. Absolutely! Oh, And a set too...
Huh?
Dictionaries and sets in Python are implemented using a hash table. It may sound daunting at first, but as we investigate further everything should be clear.

Objective
Throughout this article, we will discover how a dict is implemented in Python, and we will build our own implementation of (a simple) one. The article is divided into three parts, and building our custom dictionary takes place in the first two:
- Understanding what hash tables are and how to use them
- Diving into Python’s source code to better understand how dictionaries are implemented
- Exploring differences between the dictionary and other data structures such as lists and sets
What is a hash table?
A hash table is a structure that is designed to store a list of key-value pairs, without compromising on speed and efficiency of manipulating and searching the structure.
The effectiveness of the hash table is derived from the hash function — a function that computes the index of the key-value pair — Meaning we can quickly insert, search and remove elements since we know their index in the memory array.
The complexity begins when two of our keys hash to the same value. This scenario is called a hash collision. There are many different ways of handling a collision, but we will only cover Python’s way. We won’t go too deep with our hash table explanation for the sake of keeping this article beginner-friendly and Python-focused.
Let’s make sure we wrapped our head around the concept of hash tables before moving on. We will start by creating the skeletons for our very (very) simple custom dict consisting of only insertion and search methods, using some of Python's dunder methods. We will need to initialise the hash table with a list of a specific size, and enable subscription ([] sign) for it:
Now, our hash table list needs to hold specific structures, each one containing a key, a value and a hash:
Basic Example
A small company with 10 employees want to keep records containing their employees remaining sick days. We can use the following hash function, so everything can fit in the memory array:
length of the employee's name % TABLE_SIZE
Let’s define our hash function in the Entry class:
Now we can initialise a 10 element array in our table:
Wait! Let’s think it over. We most probably will tackle some hash collisions. If we only have 10 elements, it will be much harder for us to find an open space after a collision. Let’s decide that our table is going to have double the size — 20 elements! It will come handy in the future, I promise.
To quickly insert each employee, we will follow the logic:
array[length of the employee's name % 20] = employee_remaining_sick_days
So our insertion method will look like the following (no hash collision handling yet):
For searching, we basically do the same:
array[length of the employee's first name % 20]
We’re not done yet!
Python collision handling
Python uses a method called Open Addressing for handling collisions. It also resizes the hash tables when it reaches a certain size, but we won’t discuss that aspect. Open Addressing definition from Wikipedia:
In another strategy, called open addressing, all entry records are stored in the bucket array itself. When a new entry has to be inserted, the buckets are examined, starting with the hashed-to slot and proceeding in some probe sequence, until an unoccupied slot is found. When searching for an entry, the buckets are scanned in the same sequence, until either the target record is found, or an unused array slot is found, which indicates that there is no such key in the table.
Let’s examine the process of retrieving a value by key, by looking at Python source code (written in C):
- Calculate hash of
key - Calculate the
indexof the item byhash & maskwheremask = HASH_TABLE_SIZE-1(in simple terms - take N last bits from the hash bits):
i = (size_t)hash & mask;
- If empty, return
DKIX_EMPTYwhich translates eventually to aKeyError:
if (ix == DKIX_EMPTY) { *value_addr = NULL; return ix;}
- If not empty, compare keys & hashes and set
value_addraddress to the actual value address if equal:
if (ep->me_key == key) { *value_addr = ep->me_value; return ix;}
and:
if (dk == mp->ma_keys && ep->me_key == startkey) { if (cmp > 0) { *value_addr = ep->me_value; return ix; }}
- If not equal, use different bits of the hash (algorithm explained here) and go to step 3 again:
perturb >>= PERTURB_SHIFT;i = (i*5 + perturb + 1) & mask;
Here’s a diagram to illustrate the whole process:
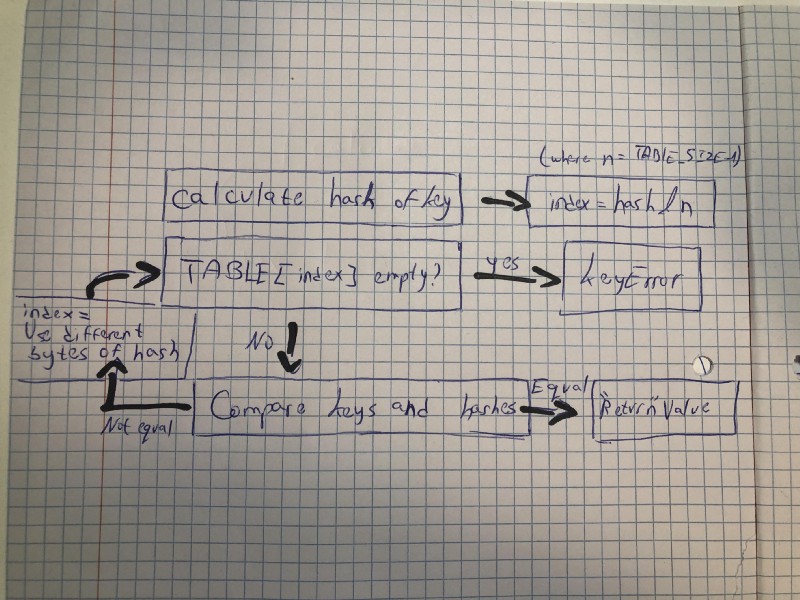
The insertion process is pretty similar — if the found slot is empty, the entry is being inserted, if it’s not empty then we compare the key and the hash — if equal, we replace the value, and if not we continue our quest of finding a new spot with the perturb algorithm.
Borrowing ideas from Python
We can borrow Python’s idea of comparing both keys and hashes of each entry to our entry object (replacing the previous method):
Our hash table still does not have any collision handling — let’s implement one! As we saw earlier, Python does it by comparing entries and then changing the mask of the bits, but we will do it by using a method called linear probing (which is a form of open addressing, explained above):
When the hash function causes a collision by mapping a new key to a cell of the hash table that is already occupied by another key, linear probing searches the table for the closest following free location and inserts the new key there.
So what we’re going to do is to move forward until we find an open space. If you recall, we implemented our table with double the size (20 elements and not 10) — This is where it comes handy. When we move forward, our search of an open space will be much quicker because there’s more room!
But we have a problem. What if someone evil tries to insert the 11th element? We need to raise an error (we won’t be dealing with table resizing in this article). We can keep a counter of filled entries in our table:
Now let’s implement the same in our searching method:
The full code can be found here.
Now the company can safely store sick days for each employee:
Python Set
Going back to the beginning of the article, set and dict in Python are implemented very similarly, with set using only key and hash inside each record, as can be seen in the source code:
typedef struct { PyObject *key; Py_hash_t hash; /* Cached hash code of the key */} setentry;
As opposed to [dict](https://github.com/python/cpython/blob/e42b705188271da108de42b55d9344642170aa2b/Objects/dict-common.h#L4), that holds a value:
typedef struct { /* Cached hash code of me_key. */ Py_hash_t me_hash; PyObject *me_key; PyObject *me_value; /* This field is only meaningful for combined tables */} PyDictKeyEntry;
Performance and Order
Time comparison
I think it’s now clear that a dict is much much faster than a list (and takes way more memory space), in terms of searching, inserting (at a specific place) and deleting. Let's validate that assumption with some code (I am running the code on a 2017 MacBook Pro):
And the following is the test code (once for the dict and once for the list, replacing d):
The results are, well, pretty much what we expected..
dict: 0.015382766723632812 seconds
list: 55.5544171333313 seconds

Order depends on insertion order
The order of the dict depends on the history of insertion. If we insert an entry with a specific hash, and afterwards an entry with the same hash, the second entry is going to end up in a different place then if we were to insert it first.
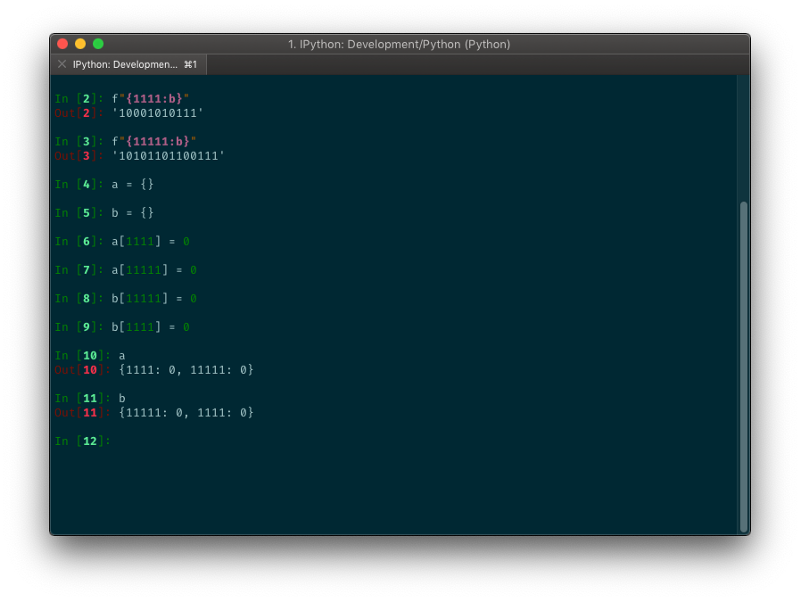
Before you go…
Thanks for reading! You can follow me on Medium for more of these articles, or on GitHub for discovering some cool repos :)
If you enjoyed this article, please hold down the clap button ? to help others find it. The longer you hold it, the more claps you give!
And do not hesitate to share your thoughts in the comments below, or correct me if I got something wrong.