
By Anmol Uppal
As programmers, we often have to trade-off between time and memory complexity. Managing one often means compromising on the other. It is hard to find the right sweet spot between them.
The problem becomes even more pressing for Android and iOS devices, which have relatively limited resources.
Let’s see how we can find this “sweet spot” using an example. Our example will be to develop a query that checks if a given word is present in the English dictionary or not.
The use case is very specific to text input applications (such as a mobile phone keyboard), but the concepts used in this article can be used in other areas as well.
Data structures often applied to this problem include:
- Set
- Trie
- HashMap
Among these data structures, Trie is specially tailored for spell-checking. The other data structures are generic, and can be applied to many data types. Let’s visualise how Trie works.
Understanding Trie
Say we have only four words in the dictionary, for example: “hello,” “world,” “he,” and “win.”
We can visualise a Trie for this dictionary as:
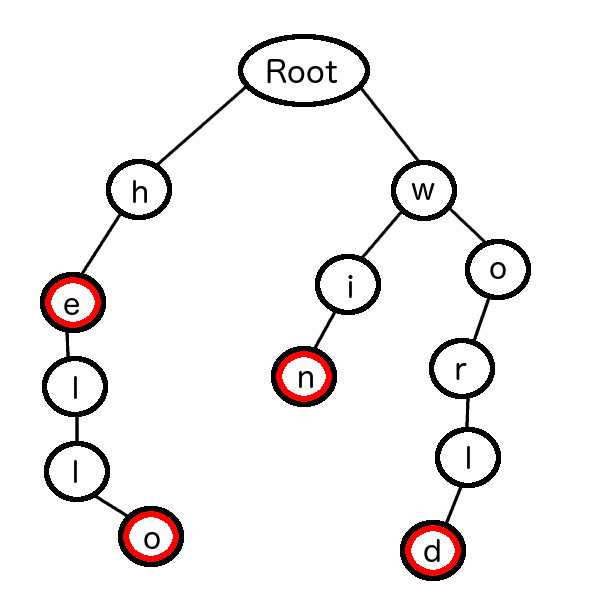
The red circles mark termination of a valid word. The Trie structure maintains a hierarchy of valid parent and child relationships. Each node contains at least these three fields:
TrieNode { char character; // a, b, c, d, ... y, z boolean isTerminal; // If this node ends in a valid word List<TrieNode> children; // List of children nodes.}
A detailed discussion for constructing Trie is not in the scope of this article, but we will briefly touch upon how a search is performed in Trie:
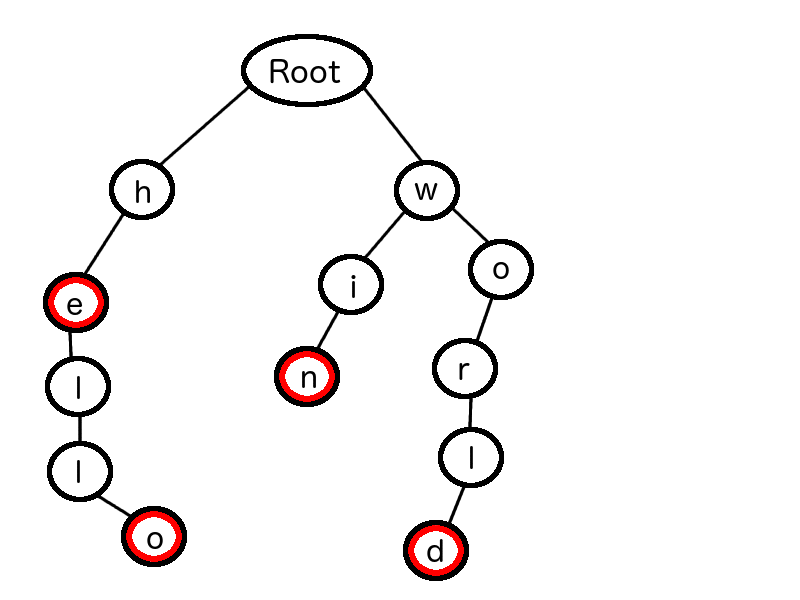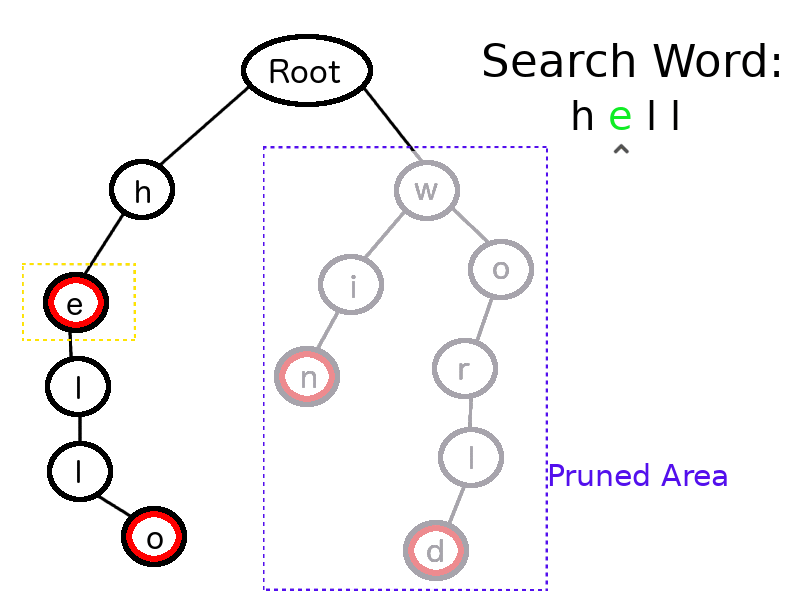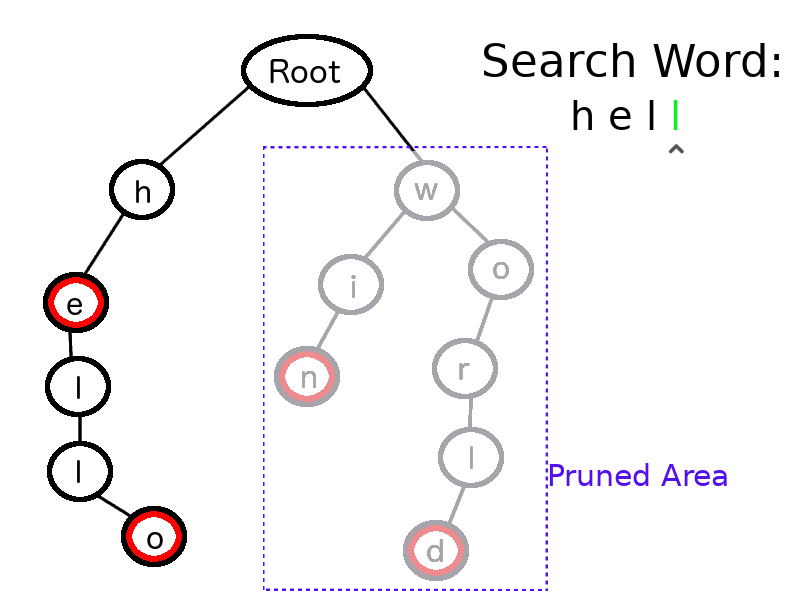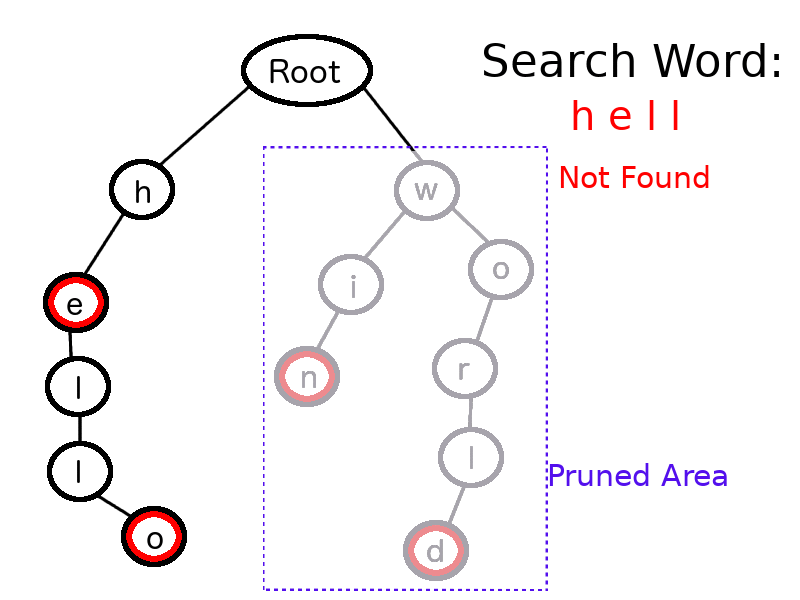
Let’s say in the above Trie (with just four valid words), we need to search if “hell” is a valid word.
We will start from the root node and take “h,” the first character of “hell,” then iterate over the root node’s children. If “h” is found, then we will iterate the children of “h,” and ignore the other children of the root node.
This process runs until we hit the last character of search word. For the last character, “l,” we also check that node’s isTerminal field. This is false in this case, as the valid words in this dictionary were “he,” “hello,” “win” and “world” only.
Introducing MagicDict
MagicDict takes advantage of language-specific properties which Trie has overlooked:
- All characters (a-z) can be imagined as a continuous integer range (0–26).
Since all possible children characters (a-z) for a given node can be realized as a contiguous integer range, we can use an array of Boolean values to represent children.
We will use a Boolean array of size 26, with all elements False as the initial value. We also need another array of 26 Boolean values to represent isTerminal as well.
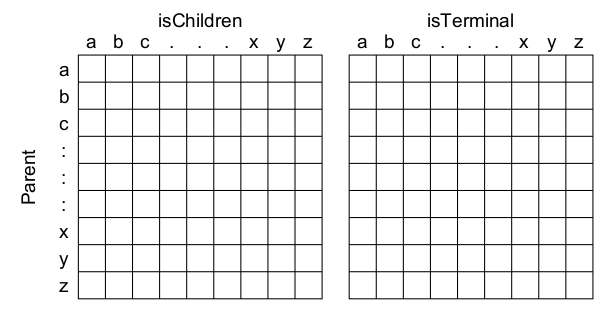
This single 2D array represents only 1 level of parent-child relationships. For the English language with 26 characters, the size of 2D array would be: 26 x 52.
We can stack them on one another. This means children of the 1st layer become the parent in 2nd layer, children of 2nd layer become the parent in 3rd… and so on. This forms a kind of chained structure, and the basic elements of MagicDict.
Insertion in MagicDict
We construct a stack of 2D layers, where the number of layers required to build the stack is longest_word_length — 1 .
For the previous set of words: “he,” “hello,” “win,” and “world,” longest_word_length equals 5. So, we need to reserve a stack size of 4.
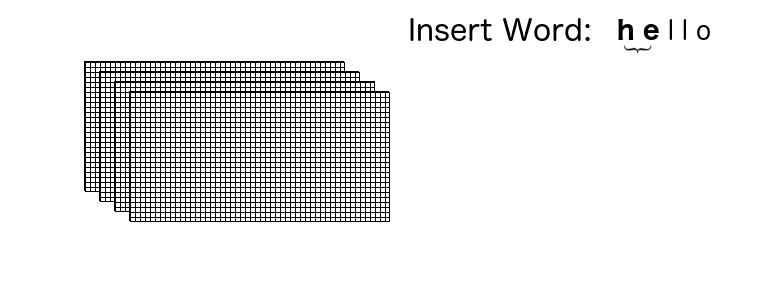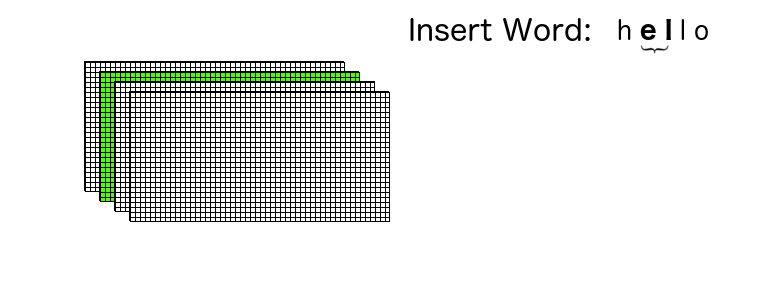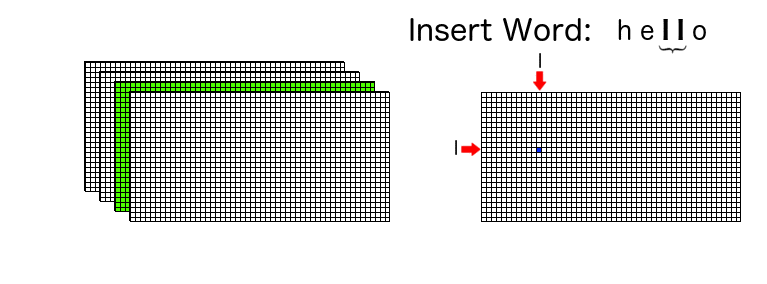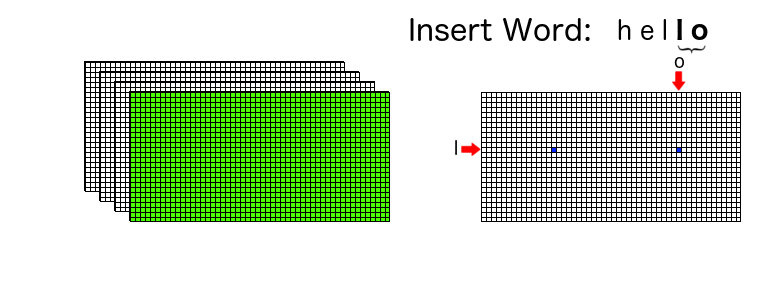
Say we want to insert “hello” in this data structure. We start with the first pair {“h” and “e”}, and turn on the corresponding isChildren boolean flag in layer 1.
Then we take the next pair {“e”, “l”}, similarly turning on the corresponding isChildren boolean flag in layer 2. This process is repeatd until we reach the terminating pair {“l” and “o”}, where we also turn on the corresponding isTerminal boolean flag.
The whole process can be visualized as shown:
Searching in MagicDict
Searching follows the same flow as insertion. The only difference is that in insertion, we change the bit values. But in case of searching, we only read values to check if the character sequence in the query word is valid.
Final Magic Touch
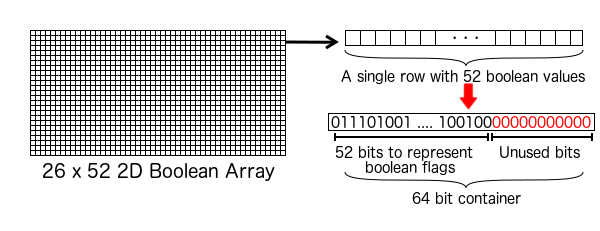
Now we have a data structure which stores n 2D arrays of size 26 x 52. Each 2D array stores 1352 boolean (true/false) values.
We also know the fact that Boolean values take at most 1 byte of memory (since the smallest addressable unit of memory is a byte). Consuming 1 byte to store a Boolean flag is not the ideal scenario.
What if we could find a data type large enough to hold the boolean flags of the 2D array as a contiguous bit pattern?
It turns out that there aren’t any! Primitive data types have 8-bit, 16-bit, 32-bit, 64-bit, 128-bit representations… but no primitive data type is large enough to store 1352 contiguous bits.
The closest available contiguous bit pattern seems to be 64-bit, which is also known as long in some languages. We replace the rows in our 2D array with a long value holding 64-bits.
For a dictionary with a maximum word length of 21, and each layer consuming 26 x 8 bytes, the total size of the data structure would be 4,160 bytes.
Benchmarking
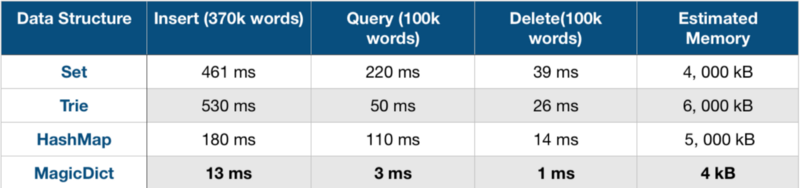
We analysed 370,000 English language words from this Github repo, and recorded time taken for:
- Insertion of 370,000 words
- Deletion of 100,000 words
- Querying of 100,000 words (50,000 existing words, 50,000 non-existing words
And we also looked at the estimated memory consumption of various data structures.
Final Thoughts
This initial model does not have extensive features. But, it could be extended to languages other than English by using larger data types.
The main takeaway from this data structure is the efficient usage of space, while improving on runtime performance too. This is nearer the “best-of-both-worlds” scenario.
For detailed information on how this Data Structure is implemented, you can check out the source code of MagicDict.