
By Anup Cowkur
In the last post, we learned about Purity, Side effects and Ordering. In this part, let’s talk about immutability and concurrency.
If you haven’t read part 1, please read it here:
Functional Programming for Android developers — Part 1
_Lately, I’ve been spending a lot of time learning Elixir — An awesome functional programming language that is friendly…_medium.com
Immutability
Immutability is the idea that a value once created can never be modified.
Let’s say I have an Car class like this:
Java
public final class Car { private String name; public Car(final String name) { this.name = name; } public void setName(final String name) { this.name = name; } public String getName() { return name; }}
Kotlin
class Car(var name: String?)
Since it has a setter in Java and is a mutable property in Kotlin, I can modify the name of the car after I’ve constructed it:
Java
Car car = new Car("BMW");car.setName("Audi");
Kotlin
val car = Car("BMW")car.name = "Audi"
This class is not immutable. It can be modified after creation.
Let’s make it immutable. In order to do that in Java, we have to:
- Make the name variable final.
- Remove the setter.
- Make the class final as well so that another class cannot extend it and modify it’s internals.
Java
public final class Car { private final String name; public Car(final String name) { this.name = name; } public String getName() { return name; }}
In Kotlin, we just have to make the name an immutable value.
Kotlin
class Car(val name: String)
Now if someone needs to create a new car, they need to initialize a new object. No one can modify our car once it’s created. This class is now immutable.
But what about the getName() getter in Java or the name accessor in Kotlin? It’s returning our name variable to the outside world right? What if someone were to modify the name value after getting a reference to it from this getter?
In Java, strings are immutable by default. Even if someone got a reference to our name string and were to modify it, they would get a copy of the name string and the original string would remain intact.
But what about things that are not immutable? A list perhaps? Let’s modify the Car class to have a list of people who drive it.
Java
public final class Car { private final List<String> listOfDrivers; public Car(final List<String> listOfDrivers) { this.listOfDrivers = listOfDrivers; } public List<String> getListOfDrivers() { return listOfDrivers; }}
In this case, someone can use the getListOfDrivers() method to get a reference to our internal list and modify it thus rendering our class mutable.
To make it immutable, we must pass a deep copy of the list in the getter that is separate from our list so that the new list can be safely modified by the caller. We must also make a deep copy of the list that is passed in to our constructor so that no one can modify it externally after the car is constructed.
A deep copy means that we copy all the dependent data recursively. For instance, if the list was a list of Driver objects instead of just plain strings, we’d have to copy each of the Driver objects too. Otherwise, we’d be making a new list with references to the original Driver objects which could be mutated. In our class, since the list is composed of immutable strings, we can make a deep copy like this:
Java
public final class Car { private final List<String> listOfDrivers; public Car(final List<String> listOfDrivers) { this.listOfDrivers = deepCopy(listOfDrivers); } public List<String> getListOfDrivers() { return deepCopy(listOfDrivers); } private List<String> deepCopy(List<String> oldList) { List<String> newList = new ArrayList<>(); for (String driver : oldList) { newList.add(driver); } return newList; }}
Now this class is truly immutable.
In Kotlin, we can simply declare the list immutable in our class definition itself and then it’s safe to use (unless you call it from Java and some other edge cases like that)
Kotlin
class Car(val listOfDrivers: List<String>)
Concurrency
Okay, so immutability is cool and all but why bother? As we talked about in part 1, pure functions allow us easy concurrency and if an object is immutable, it’s very easy to use in pure functions since you can’t modify it and cause side effects.
Let’s see an example. Suppose that we add a getNoOfDrivers() method in to our Car class in Java and we also make it mutable in both Kotlin and Java by allowing an external caller to modify the number of drivers variable like this:
Java
public class Car { private int noOfDrivers; public Car(final int noOfDrivers) { this.noOfDrivers = noOfDrivers; } public int getNoOfDrivers() { return noOfDrivers; } public void setNoOfDrivers(final int noOfDrivers) { this.noOfDrivers = noOfDrivers; }}
Kotlin
class Car(var noOfDrivers: Int)
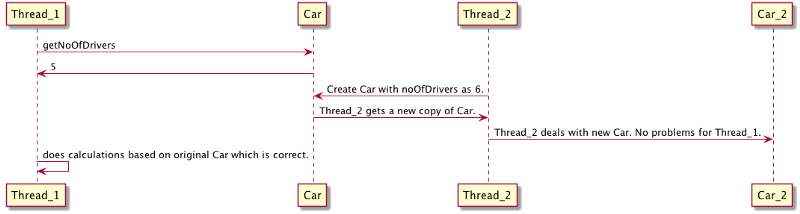
Suppose we share an instance of this Car class across 2 threads: _Thread1 and _Thread_2. Thread1 wants to do some calculation based on the number of drivers so it calls getNoOfDrivers() in Java or accesses the noOfDrivers property in Kotlin. Meanwhile _Thread2 comes in and modifies the noOfDrivers variable. _Thread1 does not know about this change and happily carries on with it’s calculations. These calculations would be wrong since the state of the world has been modified without by _Thread2 without _Thread1 knowing about them.
The following sequence diagram illustrates the issue:

This is a classic race condition known as the Read-Modify-Write problem. The traditional way to solve this is to use locks and mutexes so that only a single thread can operate on shared data at a time and let go of the lock once the operation is complete (In our case, _Thread1 would hold a lock on Car until it completes it’s calculation).
This type of lock-based resource management is notoriously hard to do safely and leads to concurrency bugs that are extremely difficult to analyze. Many programmers have lost their sanity to deadlocks and livelocks.
How would immutability fix this you say? Let’s make Car immutable again:
Java
public final class Car { private final int noOfDrivers; public Car(final int noOfDrivers) { this.noOfDrivers = noOfDrivers; } public int getNoOfDrivers() { return noOfDrivers; }}
Kotlin
class Car(val noOfDrivers: Int)
Now, _Thread1 can carry out it’s calculations without worry since it’s guaranteed that _Thread2 cannot modify the car object. If _Thread2 wants to modify Car, then it’ll create it’s own copy to do so and _Thread1 will be completely unaffected by it. No locks necessary.
Immutability ensures that shared data is thread-safe by default. Things that should not be modified cannot be modified.
What If we need to have global modifiable state?
To write real world applications, we need shared modifiable state in many instances. There might a genuine requirement to update noOfDrivers and have it reflect across the system. We’ll deal with situations like that by using state isolation and pushing side effects to the edges of our system when we talk about functional architectures in an upcoming chapter.
Persistent data structures
Immutable objects may be great, but if we use them without restraint, they will overload the garbage collector and cause performance issues. Functional programming also provides us specialized data structures to use immutability while minimizing object creation. These specialized data structures are known as Persistent Data Structures.
A persistent data structure always preserves the previous version of itself when it is modified. Such data structures are effectively immutable, as their operations do not (visibly) update the structure in-place, but instead always yield a new updated structure.
Let’s say we have the following strings that we want to store in memory: reborn, rebate, realize, realizes, relief, red, redder.
We can store them all separately but that would take more memory than we need. If we look closely, we can see that these strings have many characters in common and we could represent them in a single trie data structure like this (not all tries are persistent but tries are one of the tools we can use to implement persistent data structures) :
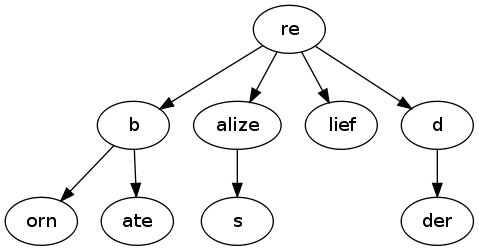 _source: [http://merrigrove.blogspot.in/2010/05/dictionary-trie.html](http://merrigrove.blogspot.in/2010/05/dictionary-trie.html" rel="noopener" target="blank" title=")
_source: [http://merrigrove.blogspot.in/2010/05/dictionary-trie.html](http://merrigrove.blogspot.in/2010/05/dictionary-trie.html" rel="noopener" target="blank" title=")
This is the basic idea behind how persistent data structures work. When a new string is to be added, we simply create a new node and link it in the appropriate place. If an object which is using this structure needs to delete a node, we simply stop referencing it from that object but the actual node is not deleted from memory thus preventing side effects. This ensures that other objects that are referencing this structure can continue to use it.
When no other object is referencing it, we can GC the whole structure to reclaim memory.
Persistent data structures in Java are not a radical idea. Clojure is a functional language that runs on the JVM and has an entire standard library of persistent data structures. You could directly use the Clojure’s standard lib in Android code but it has significant size and method count. A better alternative I’ve found is a library called PCollections. It has 427 methods and 48Kb dex size which makes it great for our purposes.
As an example, here’s how we’d create and use a persistent linked list using PCollections:
Java
ConsPStack<String> list = ConsPStack.empty();System.out.println(list); // []ConsPStack<String> list2 = list.plus("hello");System.out.println(list); // []System.out.println(list2); // [hello]ConsPStack<String> list3 = list2.plus("hi");System.out.println(list); // []System.out.println(list2); // [hello]System.out.println(list3); // [hi, hello]ConsPStack<String> list4 = list3.minus("hello");System.out.println(list); // []System.out.println(list2); // [hello]System.out.println(list3); // [hi, hello]System.out.println(list4); // [hi]
As we can see, none of the lists are modified in-place but a new copy is returned every time a modification is required.
PCollections has a bunch of standard persistent data structures implemented for various use cases and is worth exploring. They also play nice with Java’s standard collection library which is quite handy.
Kotlin comes with a standard library that already has immutable collections so if you’re using Kotlin, you’re good to go.
Persistent data structures are a vast subject and this section is only touching the tip of the iceberg. If you are interested in learning more about them, Chris Okasaki’s Purely Functional Data Structures comes highly recommended.
Summary
Immutability and Purity are a potent combo allowing us to write safe, concurrent programs. In the next part, we’ll learn about higher order functions and closures.
Read Next
Functional Programming for Android Developers — Part 3
_In the last post, we learned about immutability and concurrency. In this one, we’ll look at Higher Order Functions and…_medium.com
Extra credit
I did a whole talk on immutability and concurrency at Droidcon India. Enjoy!
If you liked this, click the ? below. I notice each one and I’m grateful for every one of them.
For more musings about programming, follow me so you’ll get notified when I write new posts.