
By Ambreen Khan
What is Hugging Face 🤗?
If you are interested in Artificial Intelligence and Natural Language Processing, you have probably heard of Hugging Face – the company named after a cute emoji.
Hugging Face is not only a company, but also a platform that is transforming the fields of AI and NLP through open source and open science.
Hugging Face offers a platform called the Hugging Face Hub, where you can find and share thousands of AI models, datasets, and demo apps. The Hub is like the GitHub of AI, where you can collaborate with other machine learning enthusiasts and experts, and learn from their work and experience.
Hugging Face’s mission is to democratize good machine learning, one commit at a time. Whether you are a beginner or a professional, you can benefit from the amazing resources and tools that Hugging Face provides.
In this post, I'll guide you through the basics of Hugging Face. You'll learn how to create your Hugging Face account, set up your development environment, and use some of the pre-trained models that are available on the Hub. Let’s get started! 🚀
Here's what we'll cover:
- What can you do on the Hugging Face Platform?
- Hugging Face terminology
- How to get started with Hugging Face
- How to use pre-trained models in Hugging Face
- How to find the right pre-trained model
- What's next?
What Can You Do on the Hugging Face Platform?
Here are some of the awesome things you can do on Hugging Face:
Download and fine-tune existing Open Source models:
Why start from scratch when you can leverage the power of over 450k models that are already available on the Hugging Face model library?
You can easily download these models and fine-tune them on your own custom dataset with just a few lines of code. This way, you can save time and resources, and still get a model that suits your specific needs.
You can use these models to perform various tasks, such as:
- Natural language processing (for example, translation, summarization, and text generation)
- Audio-related functions (for example, automatic speech recognition, voice activity detection, and text-to-speech)
- Computer vision tasks (for example, depth estimation, image classification, and image-to-image processing),
- Multimodal models capable of handling diverse data types (text, images, audio) and producing multiple types of output.
Run Models directly from Hugging Face:
If you don’t want to set up these models on your own machines, you can simply use Hugging Face’s Transformer library to connect to these models, send requests, and receive outputs.
Add/create your own model:
If you have a brilliant idea for a new model, or you want to improve an existing one, you can also add/create your own model on Hugging Face.
The platform will host your model, and allow you to provide additional information, upload essential files, and manage different versions. You can also choose whether your models are public or private, so you can decide when or if you want to share them with the world.
Once your model is ready, you can access it directly from Hugging Face, send requests, and retrieve the outputs for integration into any applications you are developing.
Use existing datasets:
A good model needs a good dataset. Hugging Face provides a repository of over 90,000 datasets that you can use and feed into your models.
You can take an in-depth look inside the dataset using the dataset viewer. You can also contribute your own datasets to the repository, and help the machine learning community grow.
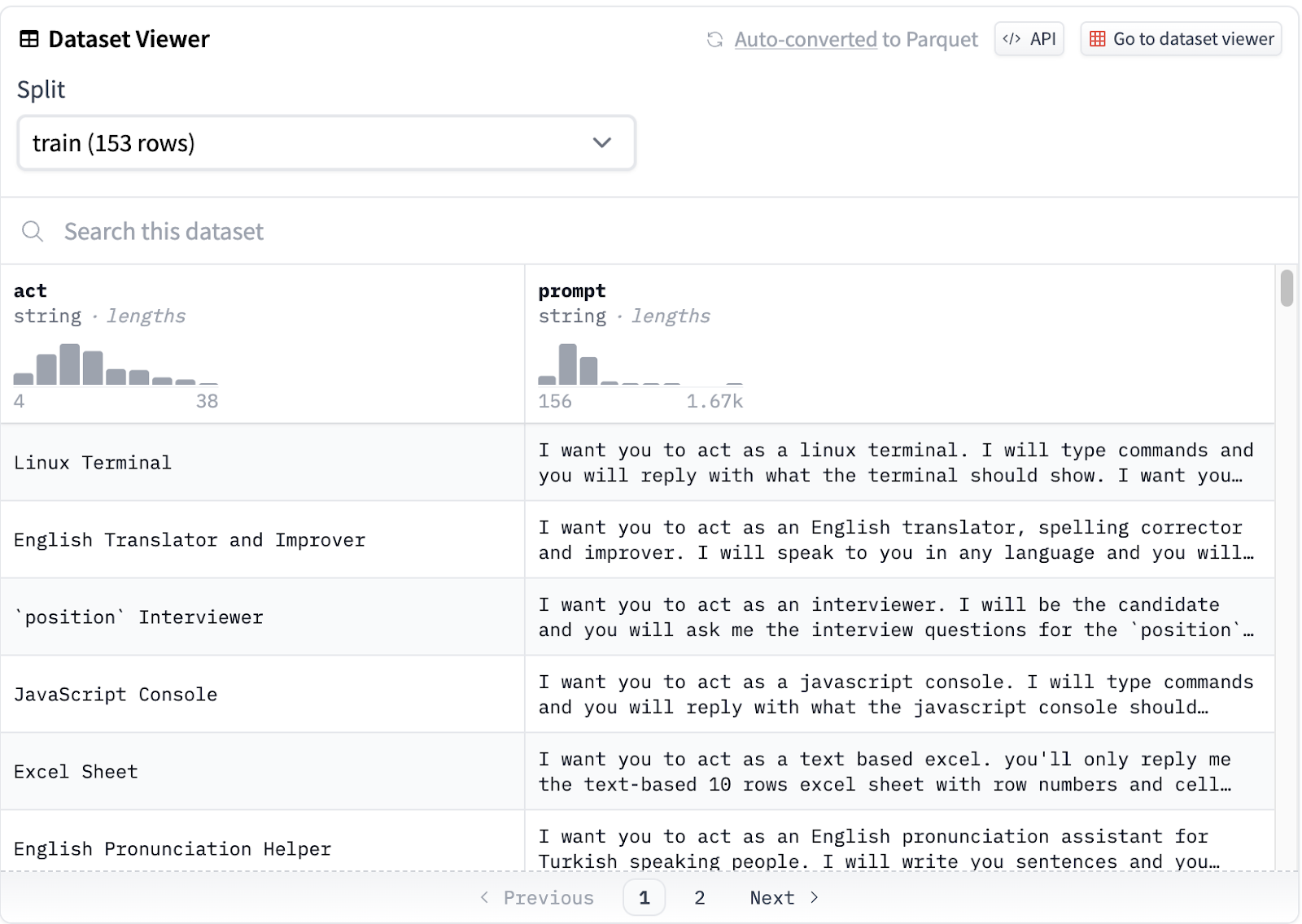
Create/browse demo apps (also known as Spaces):
Hugging Face’s Spaces are Git repositories that allow you to showcase your machine learning applications. You can also browse and try out the Spaces created by other users, and find inspiration for your next AI app.
With thousands of ML apps to choose from, you will never run out of fun and interesting things to do.
Here are a few cool Spaces you can check out:
- OpenAI's Whisper: Transcribe long-form microphone or audio inputs with the click of a button.
- AI Comic Factory: Create your own comic books.
- QR Code AI Art Generator: Generate beautiful QR codes using AI.
- Stable Video Diffusion (Img2Vid - XT): Generate 4s video from a single image.
- Video-LLaMA: Audio-Visual Language Model for Video Understanding.
Join or create an organization:
You can join or create your own organization on Hugging Face. This allows you to showcase your work and collaborate with other members from your university, lab, or company. You can also work on private datasets, models, and spaces with your organization.
Create a portfolio:
You can create a professional portfolio on Hugging Face to showcase your work and start building your reputation. This can help you land jobs related to AI model training, integration, and development.
Hugging Face provides the basic computing resources for running the demo app, including 16 GB of RAM, 2 CPU cores, and 50 GB of disk space for free. You can also upgrade your hardware for improved and faster performance with paid options.
Learn AI Skills:
Hugging Face is an excellent platform for learning AI skills. It offers a comprehensive set of tools and resources for training and using models. This includes demos, use cases, documentation, and tutorials that guide you through the entire process of using these tools and training models.
You can also learn from the experts and the community on Hugging Face, and improve your AI knowledge and skills.
Hugging Face Terminology
There are some terms you'll need to know to get the most out of working with Hugging Face.
Pretrained model: A model that has been trained on a large dataset for a specific task before being made available for use.
Inference: Inference is the process of using a trained model to make predictions or draw conclusions about new, unseen data based on the learned patterns from the training data.
Transformers: Transformers are models that can handle text-based tasks, such as translation, summarization, and text generation. They use a special architecture that relies on attention mechanisms to capture the relationships between words and sentences.
Tokenizer: A tokenizer is a process that breaks down text into smaller units called tokens. Tokens are usually words or subwords that can be used for natural language processing (NLP) tasks.
How to Get Started with Hugging Face
To get started with HuggingFace, you will need to set up an account and install the necessary libraries and dependencies. Don’t worry, it’s easy and fun!
Here are the steps you need to follow:
Create a Hugging Face Account
Signing up as a Community individual contributor is free of charge. You can also opt for a ‘Pro’ plan or a customized plan for Organizations if you need more features and resources.
Go to the Hugging Face website and click on “Sign Up” to create a free account.
Then enter your email address and a password. Click next and complete your profile and security check.
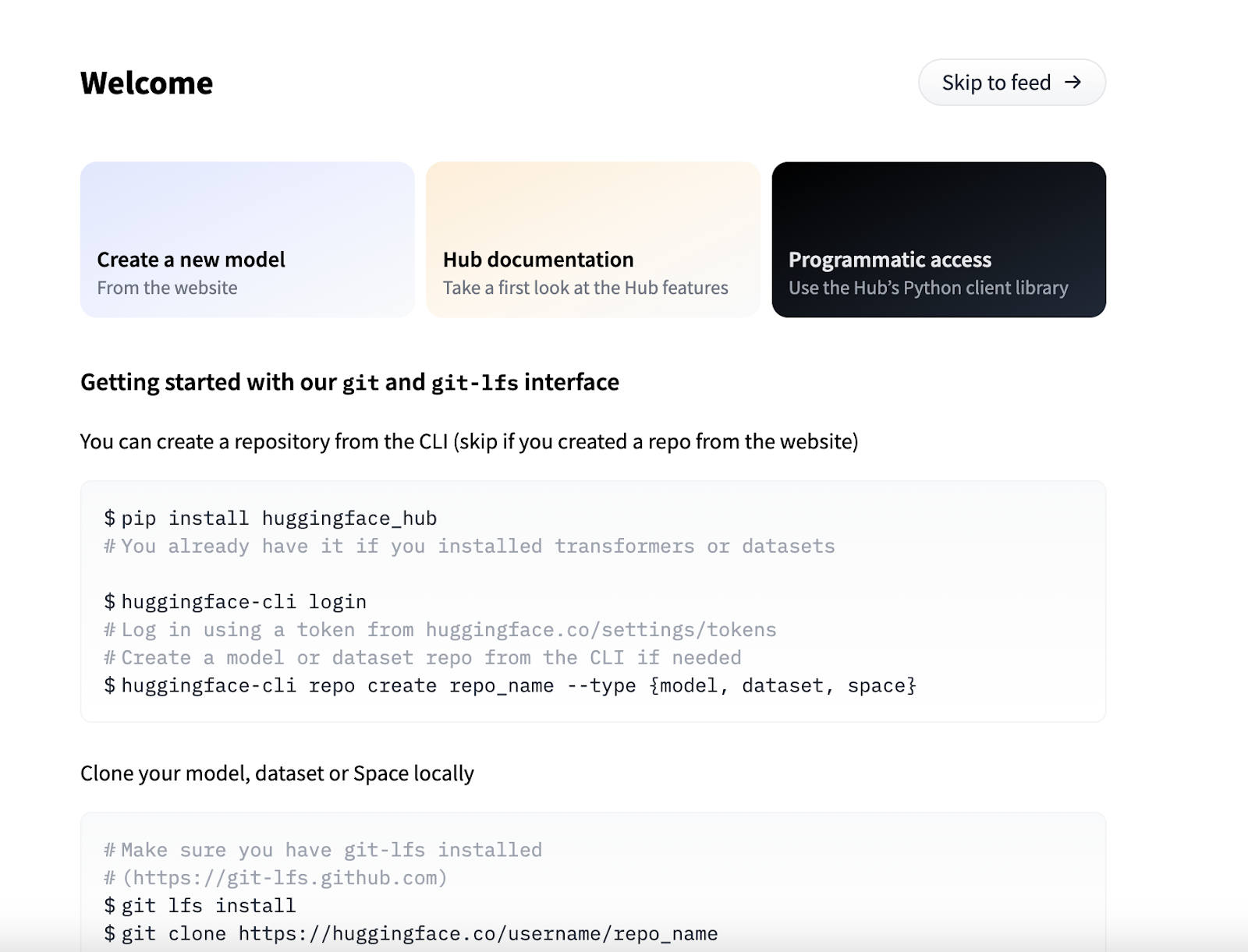
Congratulations, you are now a Hugging Face member! 🎉 You will be directed to the Hugging Face ‘Welcome’ page, where you can find more information and tips on how to use the platform.
As a bonus, you also get a Git-based hosted repository where you can create your Models, Datasets and Spaces. You can do this directly using the website or using the CLI. If you prefer the latter, you can check the detailed instructions on the ‘Welcome’ page under the ‘Programmatic access’ section.
Set Up Your Environment
Before you start using the Hugging Face hub programmatically, you will need to set up your environment.
Step 1: Install Python and Pip:
Make sure you have Python 3.8 or higher installed on your system. You will also need Pip, the package manager for Python, to install the Hugging Face libraries. If you don’t have Python, you can install it by following the instructions here.
Step 2: Install HuggingFace libraries:
Open a terminal or command prompt and run the following command to install the HuggingFace libraries:
pip install transformers
This will install the core Hugging Face library along with its dependencies. To have the full capability, you should also install the datasets and the tokenizers library.
pip install tokenizers, datasets
Step 3: Set up a development environment:
Choose a code editor or IDE of your choice, such as Jupyter Notebook, PyCharm, or Visual Studio Code. Create a new project directory and set up a virtual environment to isolate your project dependencies. You can find more information on how to do this here.
With these steps completed, you have successfully set up Hugging Face on your system and are ready to start exploring its features and capabilities. Let’s go! 🚀
How to Use Pre-Trained Models in Hugging Face
One of the best things about Hugging Face is that it gives you access to thousands of pre-trained models that can perform various tasks on different types of data. Whether you are working with text, vision, audio, or a combination of them, you can find a model that suits your needs.
Hugging Face has two main libraries that provide access to pre-trained models: Transformers and Diffusers. The Transformers library handles text-based tasks, such as translation, summarization, and text generation. Diffusers can handle image-based tasks, such as image synthesis, image editing, and image captioning.
You have already installed the transformers library during the environment setup. Let’s see how you can use it to work with pre-trained models.
Step 1: Visit the PyPI page
To learn more about the transformers library, you can visit its page on PyPI, the Python Package Index.
Go to PyPi and search for ‘transformers’. Click on the latest version of the transformers library displayed in the search result. You will see a brief introduction of the library, as well as some useful links and information.
Step 2: Download and use pre-trained models
The transformers library provides APIs to quickly download and use pre-trained models on a given text, fine-tune them on your own datasets, and then share them with the community on Hugging Face’s model hub.
Step 3: Use the pipeline() method
To use a pre-trained model on a given input, Hugging Face provides a pipeline() method, an easy-to-use API for performing a wide variety of tasks.
The pipeline() method makes it simple to use any model from the Hub for inference on any language, computer vision, speech, and multimodal tasks.
Let’s try to perform a task using the pipeline() method.
Task: Sentiment analysis:
Let’s use the pipeline() method to classify positive versus negative texts provided by the user:
from transformers import pipeline
# Load the pre-trained sentiment analysis model
sentiment_analysis = pipeline(
"sentiment-analysis", model="distilbert-base-uncased-finetuned-sst-2-english")
input_text = [
"It’s a great app, my biggest problem is the card readers regularly do not connect. Which is very poor customer service for us because we have to manually enter our customers debit cards, which takes time. This slows down our efficiency."
]
# Perform sentiment analysis on the input text
result = sentiment_analysis(input_text)
# Print the result
print(result)
The pipeline statement downloads and caches the pretrained model used by the pipeline, while the statement result = sentiment_analysis(input_text) evaluates it on the given text.
Output:
[{'label': 'NEGATIVE', 'score': 0.9996176958084106}]
Here, the answer is "NEGATIVE" with a confidence of 99.96%.
Task: Automatic speech recognition
Let’s try another task that involves speech recognition.
from transformers import pipeline
transcriber = pipeline(task="automatic-speech-recognition",
model="openai/whisper-small")
result = transcriber(
"https://huggingface.co/datasets/Narsil/asr_dummy/resolve/main/mlk.flac")
print(result)
Output:
{'text': ' I have a dream that one day this nation will rise up and live out the true meaning of its creed.'}
You can see how easy it is to get a pre-trained model up and running using Hugging Face's libraries.
How to find the right pre-trained model
But how can you find the right pre-trained model if you want to perform a specific task?
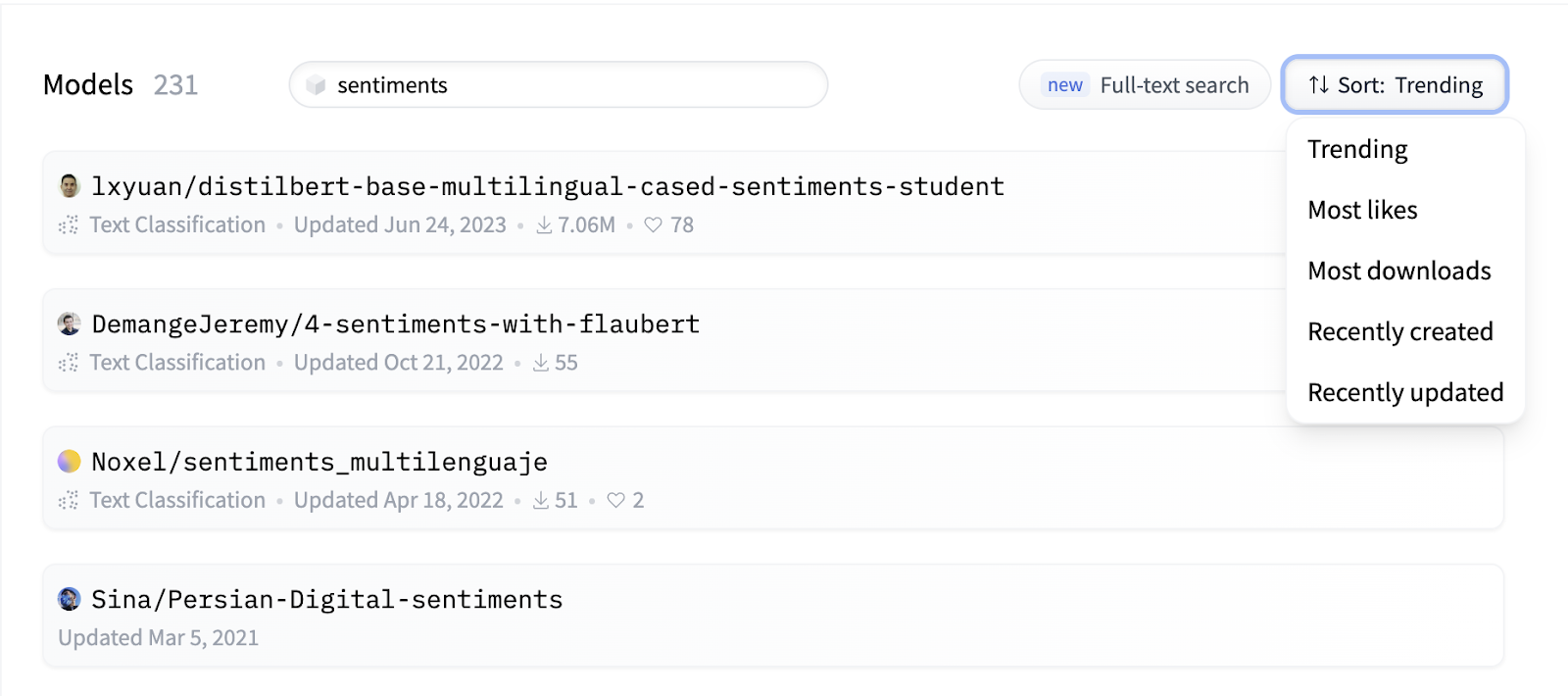
This is actually quite easy. You can browse the models on the Hugging Face website, and filter them by task, language, framework, and more. You can also search for models and datasets by keyword and sort them by trending, most likes, most downloads, or by recent updates.
Each model has a model card that contains important information, such as model details, inference example, training procedure, community interaction features, and link to the files. You can also try the model on the model card page by using the Inference API section.

You can also check the list of spaces that are using that particular model and further explore the spaces by clicking on the space link.
What's Next?
In this guide, you have learned the basics of Hugging Face, and how to use its libraries, models, datasets, and spaces. But there is so much more to discover and enjoy!
Here are some tips on how to make the most of Hugging Face:
- Dive into Hugging Face’s Spaces: Spaces are where the magic happens. You can find and try out thousands of machine learning applications created by the community, and see what’s trending and popular. You can also create your own spaces and showcase your work to the world.
- Explore the Hugging Face documentation and tutorials: If you want to learn more about the Hugging Face platform and its features, you can check out the documentation and tutorials. They provide detailed information and guidance on how to use the tools and resources that Hugging Face offers. You can also find information about common ML/AI tasks, such as text classification, image generation, and speech recognition, on the tasks page.
- Visit the learn section: If you are interested in acquiring new skills and knowledge in AI and NLP, you can visit the ‘learn’ page that displays courses from Hugging Face. Here, you can learn from the experts and the best practices in the field, and apply them to your own projects.
- Join the Hugging Face community: Machine learning is more fun when collaborating! You can join the Hugging Face community on platforms like GitHub, Discord, and Twitter to connect with other users and stay updated on the latest developments. You can also share your feedback, questions, and ideas with the community, and help Hugging Face grow and improve.
Hugging Face is not just a platform for AI and NLP – it's also a playground for your curiosity and creativity. You can experiment with new models, expand your AI knowledge, and enrich your AI toolkit with various tools and resources. So, keep learning, keep exploring. There is always something new and exciting to discover with Hugging Face. 😊