

In today's data-driven world, vast amounts of unstructured text data are generated every day. And to help handle all that data, Natural Language Processing (NLP) has emerged as a transformative technology.
NLP is a sub-field of artificial intelligence. It focuses on enabling machines to understand, interpret, and generate human language.
In this tutorial, we'll explore the fundamental concepts of NLP and we'll look at a particular implementation with spaCy. This will showcase its immense potential to revolutionize various industries.
Let's have a quick look at Natural Language Processing before we begin with spaCy.
What is Natural Language Processing?
NLP involves the intersection of linguistics, computer science, and machine learning. Its primary objective is to bridge the gap between human language and machine understanding.
NLP encompasses a wide range of tasks, including Text Classification, Named Entity Recognition (NER), Sentiment Analysis, and more.
Text Classification
This involves categorizing text into predefined classes or categories based on its content.
This has applications in sentiment analysis, spam detection, topic classification, and more.
Named Entity Recognition (NER)
This involves identifying and extracting named entities such as names, organizations, locations, and dates from text.
NER is crucial for information extraction, question answering systems, and recommendation engines.
Sentiment Analysis
This involves determining the sentiment or emotion expressed in a piece of text, whether it's positive, negative, or neutral.
Sentiment analysis is extensively used for brand monitoring, customer feedback analysis, and social media monitoring.
Challenges in Natural Language Processing
While NLP has made significant advancements, several challenges persist:
- Human language is inherently ambiguous, making it challenging sometimes for machines to accurately understand and interpret meaning.
- Different languages, dialects, slang, and cultural nuances add complexity to NLP tasks, requiring models to be language-specific and adaptable.
- Capturing contextual information and understanding the underlying semantics of text remains a significant challenge for NLP algorithms.
- NLP models heavily rely on training data, and biased or low-quality data can result in biased or inaccurate predictions, leading to potential ethical concerns.
What is spaCy?
In the world of Natural Language Processing (NLP), spaCy has emerged as a powerful and efficient library, revolutionizing the way developers and researchers work with text data.
spaCy is an open-source Python library designed specifically for NLP tasks such as part-of-speech tagging, named entity recognition, dependency parsing, and more.
It was developed with the goal of providing industrial-strength performance, while still being easy to use and integrate into existing workflows.
spaCy is built on the latest research and implements state-of-the-art techniques, making it an ideal choice for both beginners and experienced NLP practitioners.
Key Features of spaCy
Linguistic Annotations
spaCy provides a wide range of pre-trained models that can quickly analyze text and extract various linguistic features. These features include part-of-speech tags, named entities, syntactic dependencies, sentence boundaries, and more.
The pre-trained models are trained on large corpora and have high accuracy, allowing developers to focus on their specific NLP tasks without worrying about training models from scratch.
Tokenization and Sentence Segmentation
Tokenization is a crucial step in NLP that breaks down text into individual words or subwords. spaCy's tokenization algorithms are highly efficient and language-specific, allowing for accurate and customizable tokenization.
spaCy can also automatically segment text into sentences, making it easy to work with text data at a granular level.
Entity Recognition
Named Entity Recognition (NER) is the task of identifying and classifying named entities such as persons, organizations, locations, dates, and more.
spaCy's NER capabilities are exceptional, providing out-of-the-box support for multiple languages. It allows developers to train custom NER models using their own labeled data, enabling domain-specific entity recognition.
Dependency Parsing
Dependency parsing involves analyzing the grammatical structure of a sentence by determining the relationships between words.
spaCy's dependency parsing is based on efficient algorithms and achieves high accuracy. It provides a rich set of syntactic annotations, including the head of each word, the dependency label, and the subtree structure.
This information is invaluable for tasks like information extraction, question answering, and sentiment analysis.
Customization and Extensibility
One of spaCy's major strengths is its flexibility and extensibility. Developers can easily customize and fine-tune spaCy's models to adapt to specific domains or improve performance on specific tasks.
The library also provides a straightforward API for adding custom components, such as new tokenizers, entity recognizers, or syntactic parsers, making it a versatile tool for research and development.
Performance and Scalability
spaCy is known for its exceptional performance and scalability. The library is implemented in Cython, a programming language that compiles Python-like code into highly efficient C/C++ modules. This allows spaCy to process text data blazingly fast, making it suitable for large-scale NLP applications and real-time systems.
Named Entity Recognition Example in spaCy
Let's try to implement NER using spaCy.
I'll be using Google Colab. Google Colab is a hosted Jupyter Notebook service that requires no setup to use and provides free access to computing resources, including GPUs and TPUs.
You can use Kaggle instead or run it on your own computer if you'd like. Since spaCy is a pre-trained model, it does not required much computing power to get started.
But I'd advise that you setup Anaconda on your machine if you're working on Machine learning problems.
Navigate to https://colab.research.google.com and click on the "New Notebook" button.
 Google Colab Console
Google Colab Console
On the header, enter a name of your file. Ensure your file name ends with .pynb extension.
 Change file name and create a code block
Change file name and create a code block
Click on the "+ Code" button to create a code block.
By default, Google Colab is packed with some machine tools and Python libraries pre-installed. So, we don't have to worry about installations and getting our development environment ready.
But it doesn't come with the spacy library.
Run the following command inside the code block to install the spacy library.
!pip install -U spacy
 Install
Install spacy library
Choose whichever option you want and proceed. The major difference between each one of them is the amount of data it has been trained with.
- Small – en_core_web_sm
- Medium – en_core_web_md
- Large – en_core_web_lg
- Transformer – en_core_web_trf
Our next step is to download one of these models. Add a code block and choose any of the ones from the above list and run the following command. I'll be downloading the large model.
!python -m spacy download en_core_web_lg
 Download pre-trained model
Download pre-trained model
Add a code block and run the following command to load the model.
import spacy
nlp = spacy.load("en_core_web_lg")
Alright. We're all set.
Let's try to split entities from a sentence. Add a code block and run the following block of code:
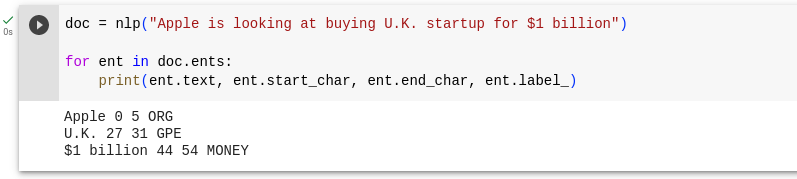
doc = nlp("Apple is looking at buying U.K. startup for $1 billion")
for ent in doc.ents:
print(ent.text, ent.start_char, ent.end_char, ent.label_)
In the above code, we're asking the spaCy model to find the entities from the sentence "Apple is looking at buying U.K. startup for $1 billion".
We're then iterating through each entity, and displaying the entity, start and end characters index in the sentence, and the entity label.
You should be seeing the following output:
 Named Entity Recognition example 1 from
Named Entity Recognition example 1 from spaCy
The above output describes that "Apple" is an entity and it is present from index 0 to index 5 in the given sentence and it is an Organisation (ORG).
If you're confused about the index, remember that it starts from 0. The first 5 characters in our given input text is "Apple". So, it is from 0 to 5.
Similarly it figures out "U.K." as an entity and describes it as a Geopolitical entity (GPE). It labels "$1 billion" as a Money (MONEY) entity.
Let's try a different sentence this time.
"Prime Minister of India Narendra Modi met US President Joe Biden at Washington DC".
Let's see what are the entities it finds out. Add a code block and run the following code:
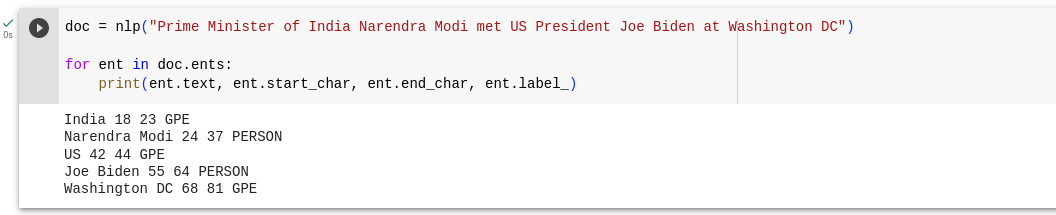
doc = nlp("Prime Minister of India Narendra Modi met US President Joe Biden at Washington DC")
for ent in doc.ents:
print(ent.text, ent.start_char, ent.end_char, ent.label_)
 Named Entity Recognition example 2 from
Named Entity Recognition example 2 from spaCy
That's awesome, isn't it?
It has identified "India", "US", and "Washington DC" as Geopolitical entities (GPE). It has also identified "Narendra Modi" and "Joe Biden" as Person entities (PERSON).
Try to input different sentences and play around with it. I'm sure you'll be amazed at its capabilities in identifying entities.
Conclusion
In this tutorial, we learnt about NLP with a simple implementation using the spaCy library.
Natural Language Processing holds immense potential to transform the way we interact with machines and analyze vast amounts of textual data. spaCy has become a go-to library for many NLP practitioners due to its powerful features, ease of use, and exceptional performance.
If you wish to learn more about NLP/Machine Learning, subscribe to my email newsletter (https://5minslearn.gogosoon.com/) and follow me on social media.