
By Wassim Chegham
Let’s explore some common Git commands, and dive into its internals to see what Git does when you run them.
But first, let’s talk about Git itself.
What is Git?
Put simply, Git is an open source distributed version control system. It was designed by Linus Torvalds, creator of the Linux kernel, to manage the source code of the kernel. So Git was designed from the start to be as fast and efficient as possible.
Git’s Principles
In other version control systems such as CVS, Subversion, and ClearCase, the server is centralized — there’s a clear separation between the server and clients.
When developers work on projects that use these systems, they first send a “checkout” request to the server, then retrieve a “snapshot” of the current version — usually the most recent one. Everyone has to go through the central server in order to work on the same project, sending “commits” or creating branches.
With Git, things are different. When you ask for a project, you clone it locally on to your machine.
In other words, Git copies all the project files to your hard drive, then allows you to work on the project autonomously. All operations run locally on your machine. You don’t even need a network connection, except to synchronize with the source code by “pushing” or “pulling.”
That’s what makes Git so quick.
With Git, you can:
- “commit” your changes
- change and create branches
- “merge” branches
- retrieve a “diff” or apply a “patch”
- recover different versions of any file
- access the change history of any file
And you can do all this without even being connected to Internet. Amazing, right?
An example workflow
Let’s take a web application generated with Yeoman (don’t worry if you’re unfamiliar with this tool — it does not matter).
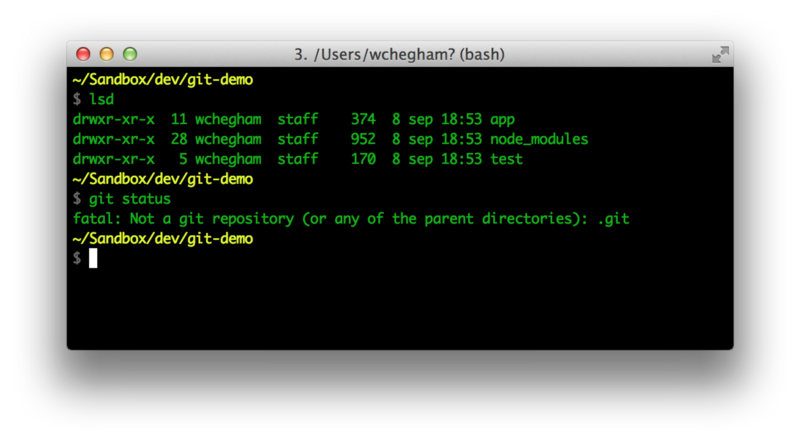
Once Yeoman scaffolds out the application, creating its file tree structure, run git status. Git will respond that the current directory is not a Git repository:
So you need to run the git init command in the root directory in order to initialize a Git repository.
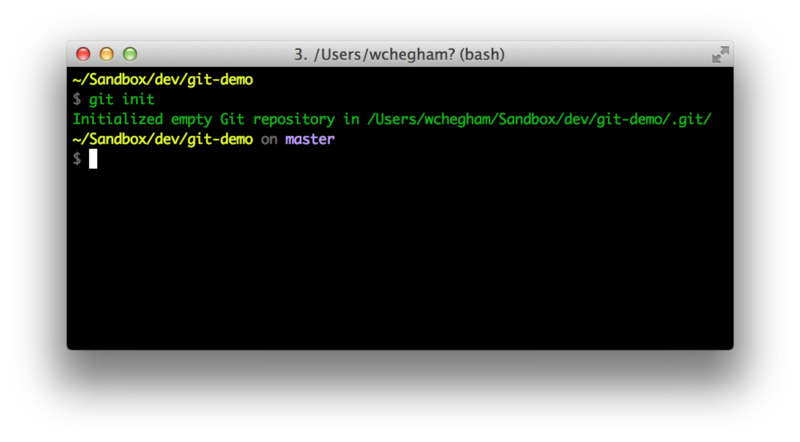
As you can see from the screen shot, we created an empty Git repository, and we are currently on its main branch — usually called “master.”
You can also notice that Git creates a .git folder at the root of the repo. This hidden directory is Git’s database. If you wish to make a backup of your project, simply make a tar.gz (or zip) of this directory.
Let’s run git status to see our status:
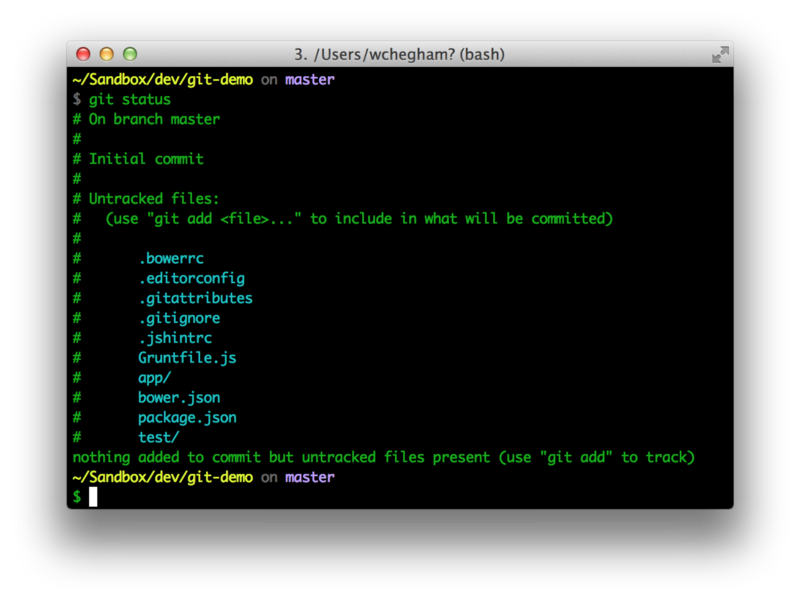
Git tells us that we haven’t added anything to our commit yet. So let us add the content of the current directory with the git add command:
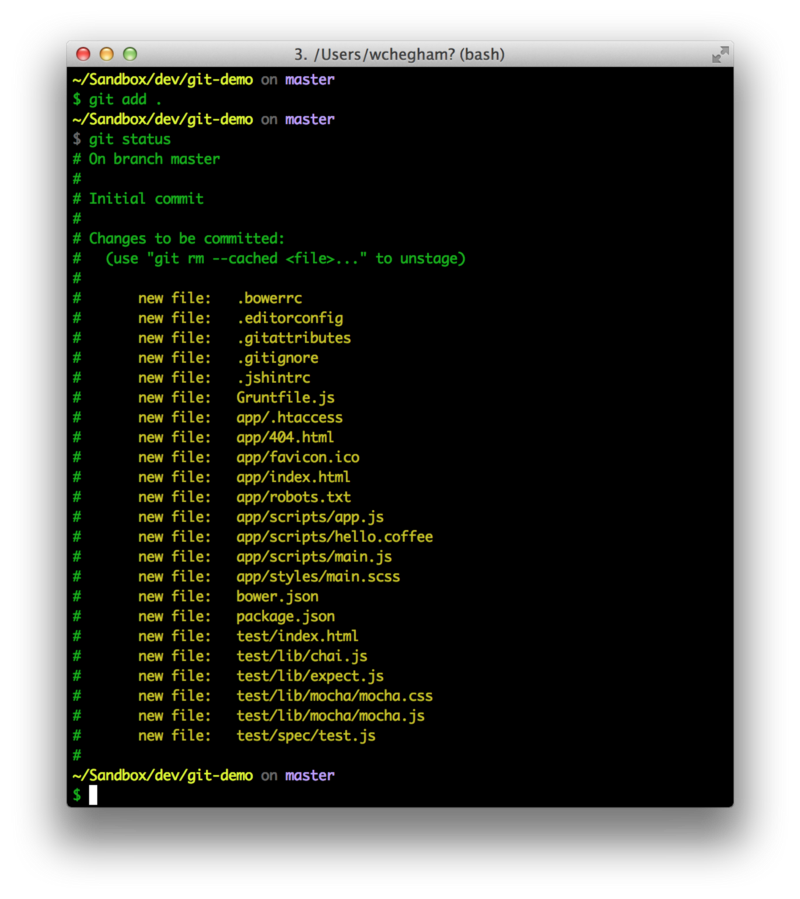
Before you commit your changes, you should check what you’re about to commit. To do that, run git diff:
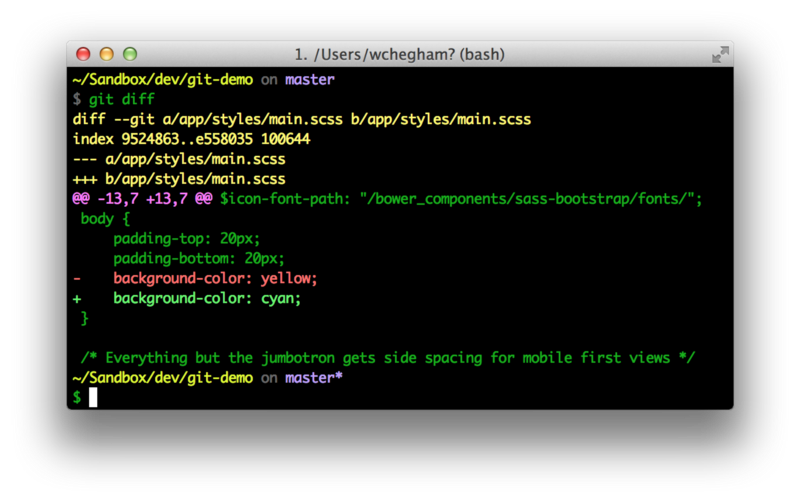
Git tells us that we have changes waiting to be committed. Let’s commit them using the command git commit -m “first commit”:
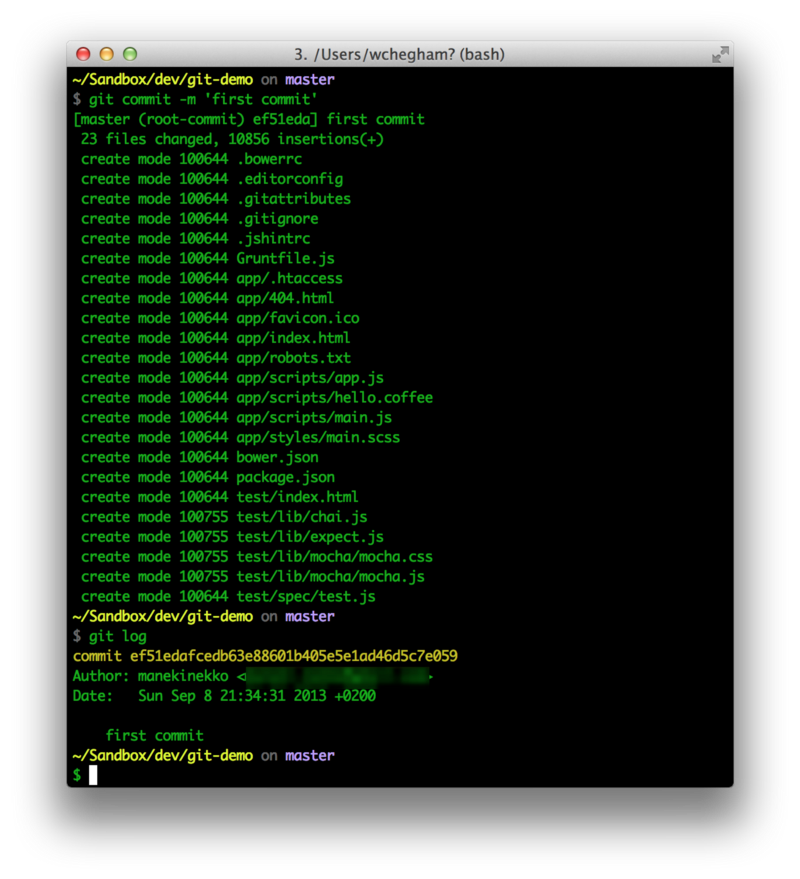
Now let’s see how Git allows us to work on different features at the same time by using multiple branches.
To illustrate this, we’ll open another terminal in the same directory, and run our application:
In order to create a new branch in Git, we use the verb “checkout” (with the -b flag):
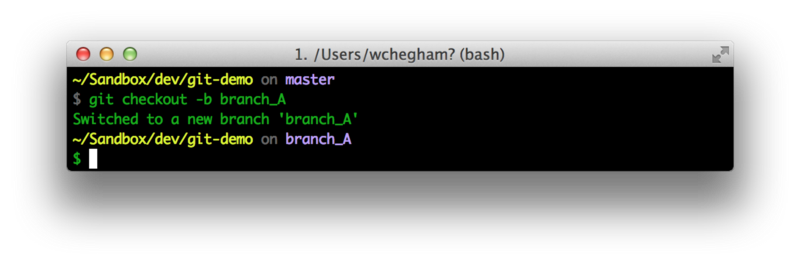
So we just created a new branch called “branch_A” and changed the current working context from the “master” branch to the “branch_A” branch.
Any changes we make will only affect the current branch. Let’s make some changes to the home page of our application, such as changing the background color:
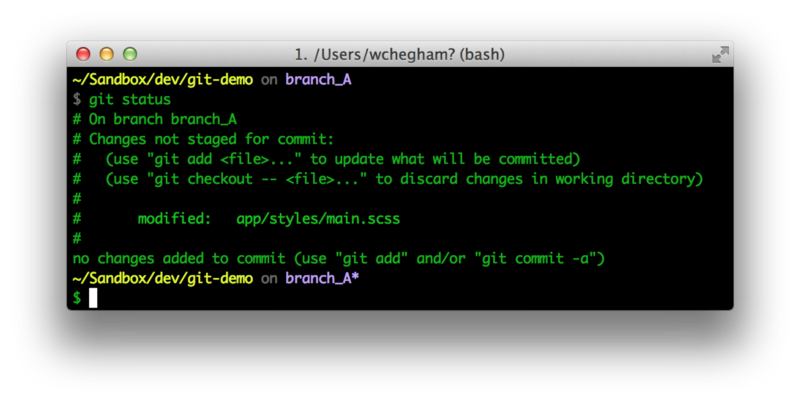
By running git status, we notice that we have some pending changes:
Let’s add this edited file and commit:
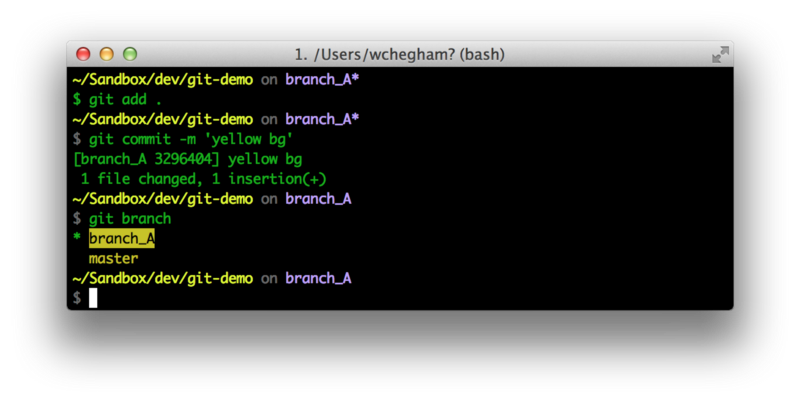
Using the git branch command, we can see what branch we’re in. To go back to the “master” branch, we can type git checkout master.
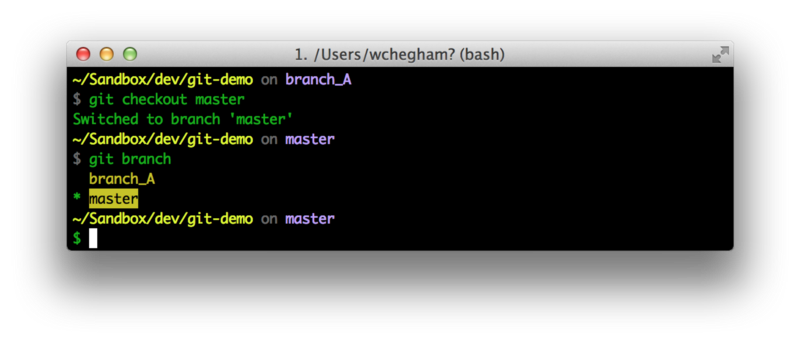
After switching branches, we can see that— in the terminal where we launched our application — that the content of the file we modified in the branch “branch_A” has been reloaded and replaced by that of the branch “master” file:
Please note that Git does not allow you to change your branch if you have pending changes. So if you really need to switch branches with pending changes, you can first ask Git to put aside those changes for you, using the git stash command:
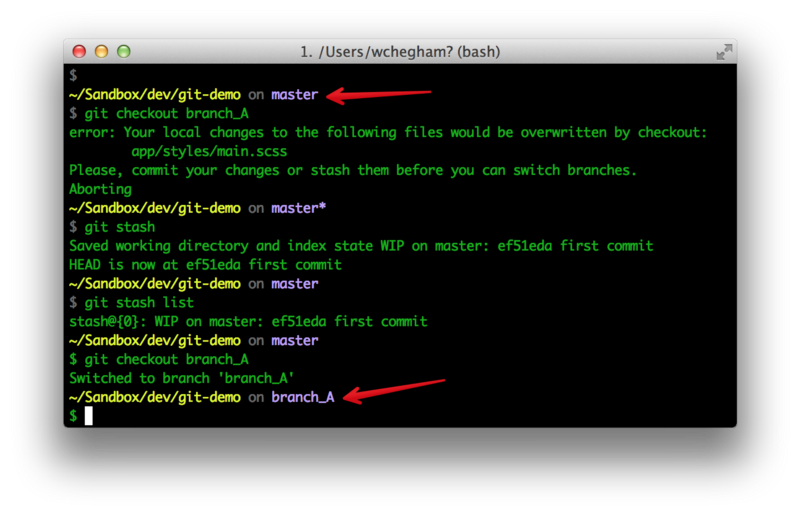
You then have the option of applying those changes later using:
$ git stash apply stash@{0}
This will apply the first backup — because you specified {0}.
When you’re working with several branches, at some point you will want to copy all the changes from one branch to another. Thankfully, Git has a git merge command that can do just that. Let’s merge branch_A into our current working branch, master:
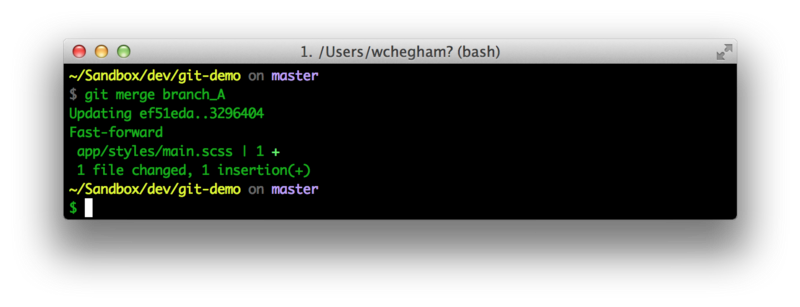
The good news: Git allows you to merge the same branch more than once. For example, imagine that you edit some files in branch_A, then merge them into “master.” Then you edit again branch_A again. Git does not prevent you from merging branch_A into master a second time.
Now let’s look at how Git does all this
Let’s assume that our project contains two files: BlogFactory.js and BlogController.js.
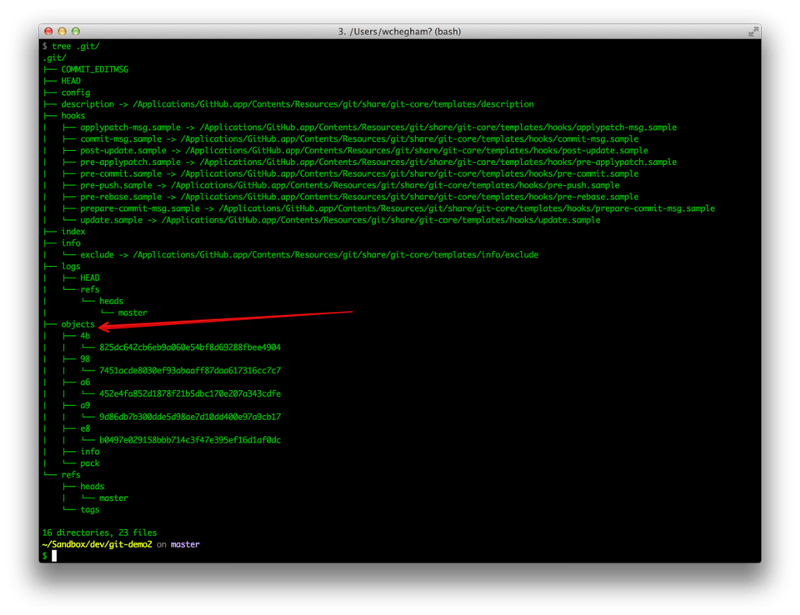
When we create our local repo with git clone or git init, Git initializes its database, and saves it in a hidden directory called .git:
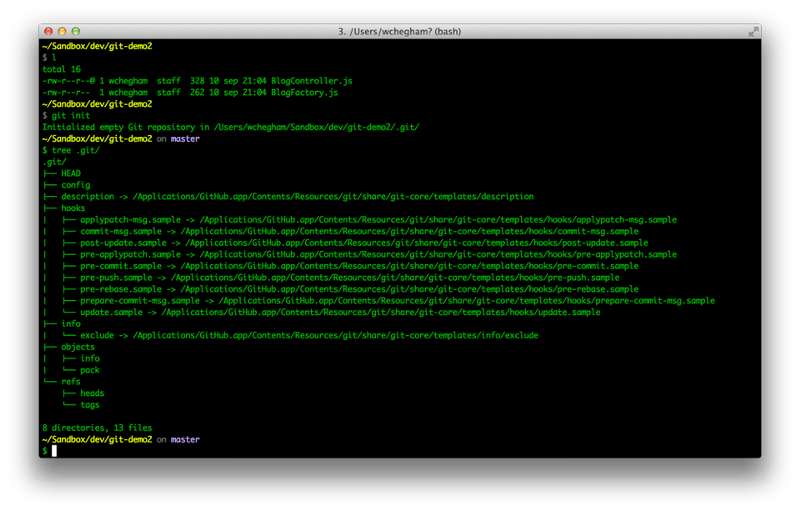
If we examine this folder, we see the presence of several subdirectories and files. The most interesting one are:
- HEAD: this file contains the path to the reference that indicates the current branch
- config: the repo configuration file
- objects: this is the directory that contains all the repo files, their content is encoded and compressed
- refs / heads: this directory contains a file per branch. Each file is named after a branch, and its content is the SHA1 of the last commit (as explained below)
When you create or edit files, you need to run:
$ git add BlogFactory.js BlogController.js
Or:
$ git add . # in order to add all unstagged files
This command tells Git that you want to add a snapshot of your files. So Git retrieves the current state of the contents of your files, then computes their checksums using SHA1, and creates an entry in its database. The key of this entry is the SHA1 hash, and its value is the raw contents of the file.
Yes, all the content!
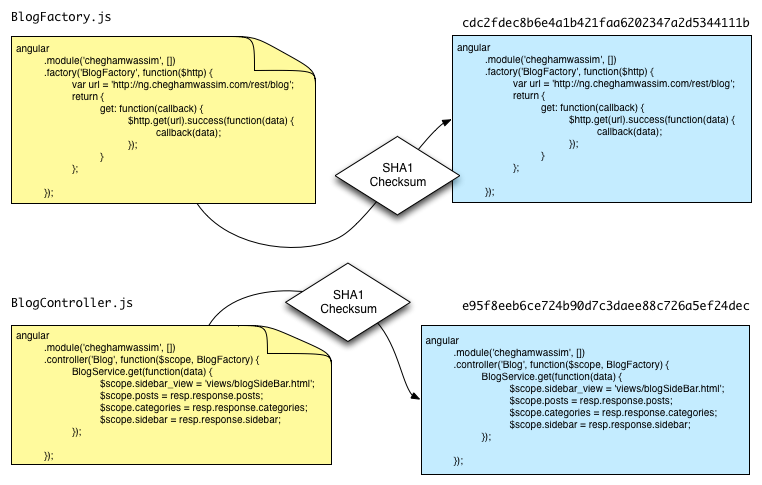
Then, as we said earlier, you need to commit these changes. To do that, you run the command:
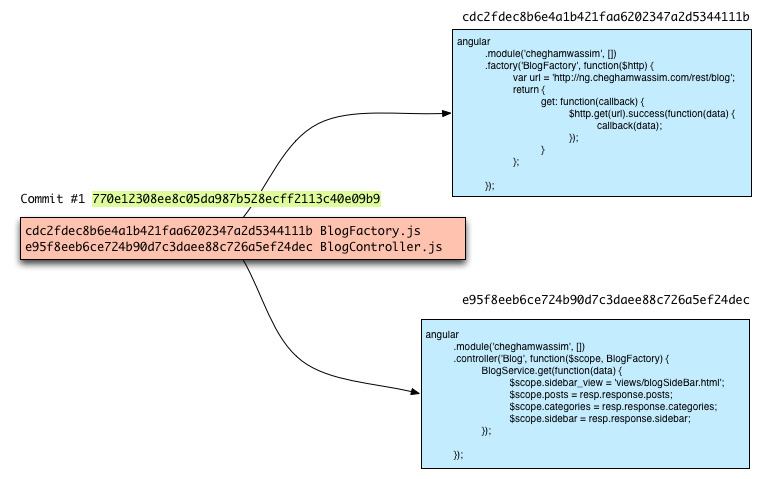
$ git commit -m "A very useful commit message"
At this point, Git records a sort of “manifest” representing the whole file structure tree, with each filename and its SHA1 key in its database. Then it calculates the checksum of this manifest, based on its contents. Then it links to the new commit.
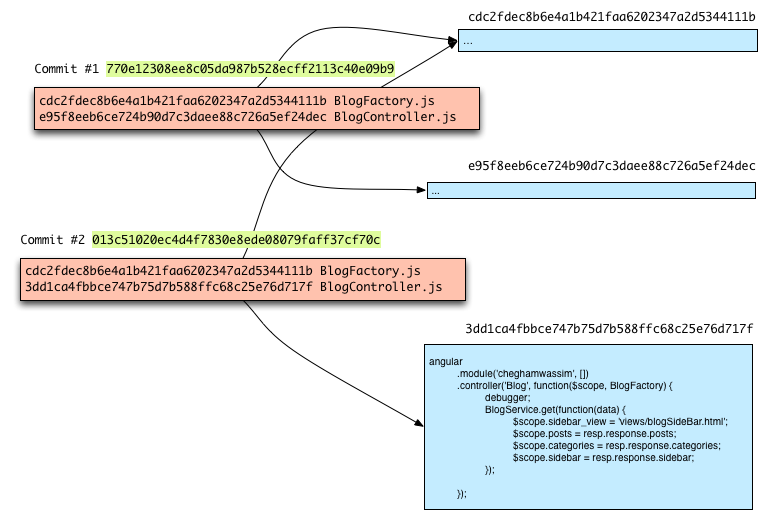
Now imagine that you have changed the BlogController.js file, and you redo a git add. Git performs the same process as before. It creates a new entry in its database, and because the file contents have changed, the SHA1 checksum has also changed.
Then, when you do a git commit, Git recreates a new manifest with the new entry SHA1:
Now suppose that you rename your file to MyBlogController.js for instance, and then commit your changes again. Git does not create a new entry in the database since the content—and the SHA1—have not changed:
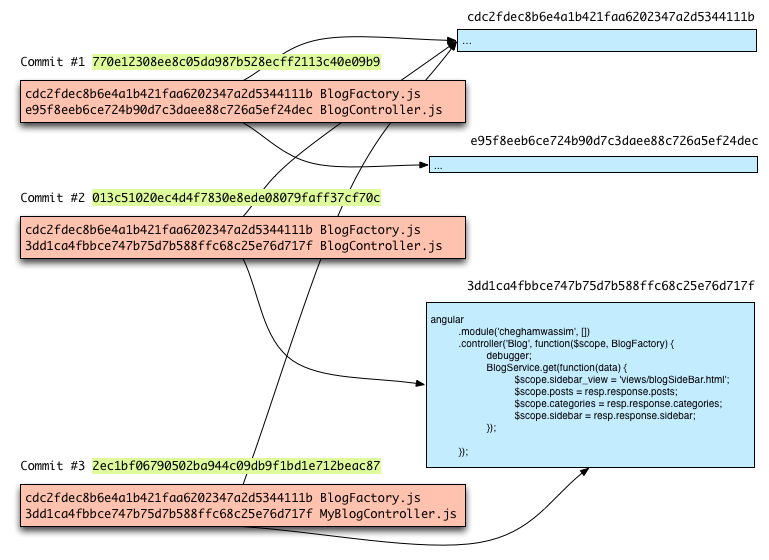
Here’s what’s actually happening in the Git database:
Git has stored the content of both committed files in the directory .git/ objects. Beside those committed files, Git also saves a file containing the details of the commit, and a manifest file as described above.
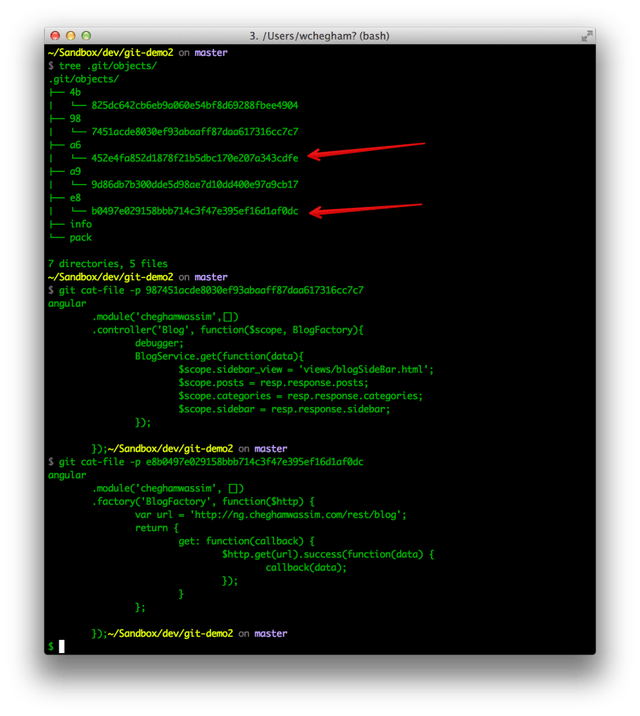
The Git command cat-file -p SHA1 is used to read the content of the stored objects. The SHA1 hash is composed of the first two bits of the directory objects/XX/ with another 38-bits forming the name of the object objects/XX/YY..YY. For example:
$ git cat-file -p 987451acde8030ef93abaaff87daa617316cc7c7
You can also enter the first 8 bits of the SHA1 (those actually are enough):
$ git cat-file -p 987451ac
Similarly, the content of the object storing the information of the commit looks like this:
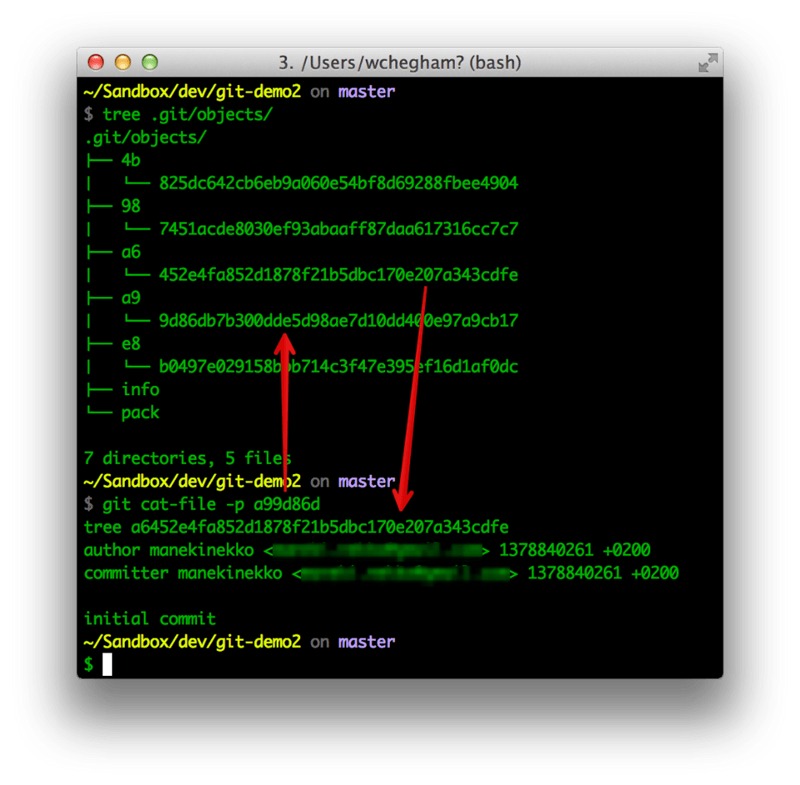
As you can see, the commit object file contains some information related to that commit, including the SHA1 of manifest (tree), which looks like this:
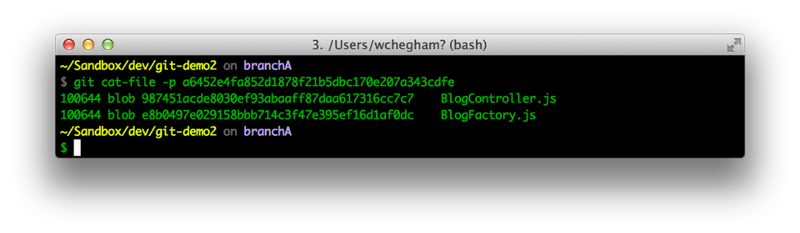
So as you may have guessed, Git does not really care about file names. It cares more about their content. Even if you copy a file, Git will not create a new entry in its database. It’s just a matter of content and SHA1 hashes.
And if you’re wondering: when I do a git push, what does Git really do? Well, Git computes the delta between the two files, compresses it, and then send it to the server. Git does not send the file’s entire content.
Resources
Here are some links that will help you continue your Git adventure:
Follow @manekinekko to learn more about the Web Platform.