By Jack R. Scott
So, you’re probably thinking — is this just another hullabaloo GraphQL tutorial that is just going to say a lot of big words but not actually help me implement anything?
✋ The answer is no.
After reading many guides on how to build a GraphQL server, I realized that none of them completely got me to where I wanted to be. How frustrating.
It took me way longer than I expected to get up and running.
As such, I am dedicated to giving you a tutorial that actually goes beyond the basics and gives some insights into how to implement a server in the real world. That way everyone can enjoy the truly beautiful feeling of using GraphQL.
? How do you know this is legit?
Here is a working version of all code explained in this tutorial. Go ahead, clone it and try it out. I’ll also include another link to the repository at the bottom of this tutorial. Feel free to make pull requests or star the repo so that we can make it as good as possible!
? Side note.
GraphQL is super flexible. It can be implemented in a million different ways — hence why there is so much confusion. Everyone has their own opinion and method of building apps. This is mine. If you have constructive feedback which I can use to improve this tutorial — please share!
Alrighty, let’s do this!
A Little Bit of Context ?
Before I begin, it’s probably a good idea to give some context for the people who don’t already know. GraphQL was created in 2012 by Facebook (thanks again). It was developed as an alternative to the existing REST standard for structuring server queries.
? What is REST?
It’s this thing you get when you go to sleep… Gotcha ?
 Why does this human think he is funny?
Why does this human think he is funny?
Honestly, I want to keep this article as succinct as possible. So to help explain, here is a helpful link to an article which explains the REST concept. The reason Facebook created GraphQL as an alternative was because the REST standard had a few key problems:
- Fetching complex objects requires multiple calls to the server — laggy.
- You get more than you ask for. REST generally specifies the shape of the data on the server. Therefore you end up getting a bunch of data you don’t even use.
- It takes a lot of work to understand exactly what information you are getting back from the server — not very predictable.
At the time, Facebook had a ton of passionate developers who love testing cool new concepts. So they got some to start working on a new concept which later became GraphQL. They wanted to ask their servers for exactly what they wanted and know that they would get exactly that back. No fluff. ?
So… they created a new language that was designed specifically for server queries. This is why GraphQL is described as “A query language for your API”.

The above is an example of a GraphQL query, as well as an example JSON response. I would describe what’s happening… but it’s pretty self-explanatory.
I’m not going to go much further into “what is GraphQL” because there are plenty of great articles on that topic. However, if you would like some more info, here is an amazing article which gives you a great overview of the concepts and fundamentals of GraphQL.
Let’s move on!
Give Me the Code! ??
Okay okay… Geeh you’re demanding… I’m getting to the code. But before we start, we are going to need to create a new Node.js repository and install a few NPM dependencies.
? Hot tip: check out Parcel.js for an awesome application bundler which helps you get your development environment sorted in seconds (make sure to set your target to the node environment). Parcel is used by CodeSandbox.
P.s.: I am assuming you already know how to set up a Node.js repository. If you don’t, then the concepts in this article may be a little complex for you. You can still follow along to get a general understanding.
Our NPM dependencies:
Hang on… ? who is Apollo and why do we want his server?
Just to be clear, Apollo is not a person. It is a group of cutting-edge developers who are making awesome strides in the area of GraphQL. They have created a set of production-ready tools and code which is going to make our lives super easy to get started with setting up our GraphQL servers.
Awesome, now that our dependencies are installed, let’s begin by creating an index file as an entry point to our application.
? File: src/index.ts
I have added a number of comments in the code which will help explain what is going on in the file. Essentially we have created a server and given the server a schema which holds an “empty” type for our Queries (type Query) and an “empty” type for our Mutations (type Mutation).
- Empty means that it has no properties (yet).
Like I said before, I want to make sure this article is as succinct as possible. I am assuming you are a little familiar with how to write basic GraphQL schemas. But if you don’t know, here is a link to how basic schemas work.
Next, we are going to set up a database table for our users using mongoose. Our users will have a few basic properties which we can use to query for later on.
? File: src/common/users/user.model.ts
In the above file, we create a user model using mongoose. If you are unfamiliar with mongoose, it is an elegant wrapper which you can use to validate your data as it goes into your database. It also gives us some awesome powers such as virtuals properties, easy querying of data, and more.
So now we have a model which we can use to save and request data from our database, as well as a server which is running an empty GraphQL server. All we need to do is connect the two together!

To do this, we will create a file which will contain 2 things:
- A set of GraphQL types — which tells the client “what” we data we have
- A matching set of GraphQL resolver functions — which tells the server “how” to do the things that our types describe.
I am keeping these two code sections in the same file because it made life easier when I was developing.
? File: src/common/users/user.schema.ts
Holy moly! That’s a lot to take in… So let’s break it down, starting with our type definitions:
type User { ... }: this is a straight-forward GraphQL type. This is just telling us what the shape of the User is so that the client can query it correctly. You can find more here in the docs.input UserFilterInput { ... }: similar to a “type” object, an input defines the structure of a complex parameter i.e. something more complex than aString,ID,Int,FLoatorBoolean.extend type Query { ... }: so remember when we created our root query type back in the index file? Well, this is referring to that. We are extending that root query and defining the functionality we want to expose to our client. Why do we do it this way? Pfff… It’s not like I want to do it this way (it’s kind-of hacky)… Unfortunately, this was the best way to do it out of a number of poor alternatives. Feel free to give me a better suggestion.extend type Mutation { ... }: in the same way that we extend the root query, we are also extending the root mutation.
Now let’s digest what is happening in our user resolvers:
- Our resolver function names match the names of the fields in both the
Queryand theMutationin the type definitions. This helps Apollo know which functions do what. users: async (_, { filter = {} }) => { ... }: Well, isn’t this line a bit of a mouthful for devs who haven’t seen it before. Don’t worry, it is only stating that for the property users we are assigning an anonymous function which is using async / await to query the database and return some users. Simple ?. The arguments in the function match the arguments in the Apollo server docs which you can find here.await User.something(): This syntax is how we use mongoose to either get or save data to the database. It’s super simple once you get your head around it, you can find the docs on mongoose here.user.toGraph(): This is where most people will get confused. This “toGraph” function comes from our mongoose model file (find it in the model file where it saysuserSchema.method('toGraph', ...). The reason we need this function is that Mongoose doesn’t return a simple JavaScript object. Rather, it returns a complex object with some random properties that GraphQL doesn’t like. As such, by using thetoGraphmethod, we convert the complex object to a simple object that GraphQL can process.
? Wowzers! That was a brain overload.
Don’t worry if you don’t understand all the code straight away. You will be able to clone and experiment with the example repository to your computer once you have finished the tutorial.
Alrighty! Now let's patch it all together back in the index file…
? File: src/index.ts
All we needed to do was import our type definitions and resolvers, then we added them to our schema. If you go and start your application (hopefully you would have configured a start script i.e. npm start) you should see that your application will open on http://localhost:4000.
Troubleshooting: don’t forget to install and start your MongoDB database. Here is a link to an article which shows you how to do this, if you haven’t already.
When we navigate to the server in our browser, we will see that Apollo has given us a helpful little tool called a playground. We can use it to test out our GraphQL server. Below is an example of a few queries I tested on our API.
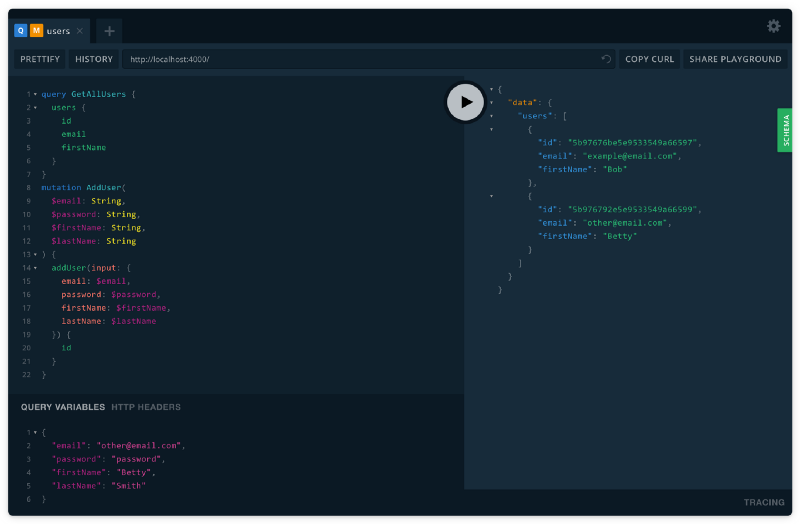
You may be wondering; what does
query GetAllUsersormutation AddUsermean?
Don’t worry, that is purely there to help you debug your application. They are just names by which you can identify your GraphQL requests. They add no extra functionality to the query or mutation. You can find more information on how to write queries and mutation here.
? Hey Jack, there is still one thing I’m still unsure of. What is the difference between Queries and Mutations?
Great question! I had a feeling you would ask. In order to truly understand this, we need to look at what is happening under the hood of our server. Many people suggest that Queries are the equivalent of a GET request. Mutations are for all others i.e. POST, PUT, PATCH, and DELETE but this isn’t exactly true.
Let’s look at an example of 2 requests to our GraphQL server from our Apollo GraphQL playground — which comes with Apollo Server straight out of the box.

As you can see, both the query and the mutation requests are POST requests. The reason for this is that they both have the ability to pass variables into their requests e.g. users (limit: $maxUsers) { ... }.
The real difference between the two is that:
- Queries are executed in parallel.
- Mutations are executed in series.
That way queries can be executed fast and mutations can be executed reliably. Thanks to Prisma for the help on that one.
⏰ Time to Take it Up a Level!
So we’ve done a pretty good job so far, we know how to:
- ✅ Create a basic server.
- ✅ Create a mongoose schema which validates our database data.
- ✅ Define our GraphQL data structure on the server using type definitions.
- ✅ Connect our mongoose schema to the GraphQL server using resolvers.
- ✅ Make some queries and mutations through the Apollo playground.
I’d say that’s a fair shake of the sauce bottle — Kevin ’07. But there are still a few things missing…
? What about when we have related database items, how do we deal with that?
It’s actually pretty simple, let’s do it!
First off, we will pretend that every user is related/attached to a single workspace. In this situation, we might want to request information from the workspace related to the user, at the same time that we ask for information about that user.
To do this, we first have to define a new mongoose model. We will use it to save and request workspaces from the database.
? File: src/common/workspace/workspace.model.ts
Similar to the way we created our users, we will also make a schema file for our workspaces so that they can be queried on their own as well.
? File: src/common/workspace/workspace.schema.ts
Sweet, now we just need to update the index file so it recognizes our workspace GraphQL schema and resolvers. Note: to merge resolvers, we need to use lodash’s merge function which deeply merges two objects together.
? File: src/index.ts
Once you’ve implemented the above code, you would be able to create and query workspace’s just like we did with our users! But that’s not much cooler than before. What will be really cool is when we query data about a workspace “through” the user object.
To do that, we can use a cool feature of mongoose which allows us to reference database items to each other (e.g. the workspace to the user). These references stored as special ObjectId types. Go ahead and update our User model so that it can save the id of a workspace to our users.
? File: src/common/user/user.model.ts
Lastly, we need to update our user’s schema file so that Apollo knows how to resolve our (nested) reference to the user’s workspace.
? File: src/common/user/user.schema.ts
Let’s take a look at the 2 main changes that we just made in the user schema file:
- The
type Usernow has 2 extra properties:workspaceId(which matches the Mongoose model) andworkspace(which will be where we put the workspace object when we query for it). - There is now a property called
Userin our resolvers. This is one of my personal favorite parts of GraphQL as it lets you resolve individual properties of a type. In the example above, we resolve theworkspaceproperty by taking the workspaceId of the user and then using Mongoose to fetch it from the database for us. This is just the same as we were doing for regular Query resolvers but this time it is a nested object.
Now, we can go back to our playground and start playing around with making and querying both users and workspace’s together.
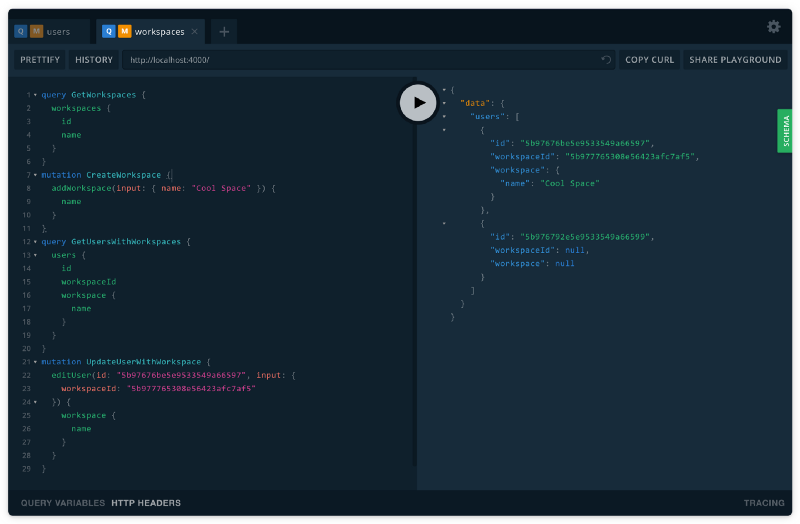
Hell yeah! We have the essentials covered for what you could turn into a fully working server.
? Holy moly! You’re up and running with GraphQL!

Authorization ?️
So currently, we have a pretty good GraphQL API. But there is still a problem: there are no restrictions on who can access our data! To fix this, we need to add authentication and authorization.
✋ Hang on… authentication and authorization are not the same?
This is a common misconception, but an important one to understand as it will help you build better APIs:
- Authentication refers to identifying the person who is requesting info i.e. working out which user is sending a request to the API.
- Authorization refers to the permissions available to that requestor i.e. which roles the user has and is that role sufficient enough to allow the request.
? So then, how do we implement that?
Another excellent question, you are a really curious person! Well, there are unfortunately many ways to do this depending on how you might want your app to work. For example:
- You might only want users to sign up with GitHub auth as opposed to signing up with email and password.
- You might have 3 different user roles as opposed to 100 fine grained user roles.
- There might be no users at all, you’re whole app could be anonymously used.
In any case, the way you implement authentication and authorization is up to you. But if you would like a guide on where to start, here is a link to an awesome article by Prisma which helps you get started on adding auth to your API.
To make it a little easier, I have also added some basic authentication to our demo repository which you can browse and check out. Feel free to improve the repository with a better auth example and submit a pull request!
? Hot damn! We managed to make a GraphQL server! Go you!

If you enjoyed this article, please give it a few claps (you can leave up to 50) or you can comment if you have any questions, I’ll do my best to answer! ?
Follow me on Twitter.
Thanks!
More posts by Jack Scott.