By Wenbin Fang
In this article, I’ll share my journey of building an API business, the technology behind it, and how to build your own API business in the future.
First, a little bit about the business I've built: Listen Notes is a podcast search engine that allows people to search nearly two million podcasts and more than 89 million episodes by people or topics. We also provide a podcast API for developers to use, which is called Listen API. It has become a core part of our business.
An accidental API business
I left my previous failed startup in September 2017. After a few days of tinkering, I picked up one of my fledgling side projects to polish the UI a bit.
That side project was Listen Notes, a podcast search engine website, which was just a single page React JS app running on three $10/month DigitalOcean droplets.
Little did I know a few years ago that my small, neglected side project would turn into the helpful business it has blossomed into.
 An early version of Listen Notes
An early version of Listen Notes
I continued to work on Listen Notes full-time and incorporated Listen Notes as a Delaware C-Corp in October 2017. One of my goals was to experience as many facets of business as possible, rather than just writing code behind the scenes.
My initial plan was as follows: (Don’t laugh at me!)
- Build a podcast search engine website and make some money from advertising, just like Google. Simple!
- If this Listen Notes thing doesn’t work in two or three months, then I’ll run out of cash, and I’ll go into credit card debt to keep going for one more month or so. If it still doesn’t work, then I’ll have to find a full-time job. Although Jeff Bezos’ parents invested $300,000 in early Amazon and Mark Zuckerberg’s parents loaned $100,000 to early Facebook, not every family is able to casually toss six figures of cash at web projects.
Then something happened.
On November 20, 2017, I got an email from the developer of a new podcast app, who asked if Listen Notes provided an API. He wanted to be able to search episodes in his app, but he didn’t want to build the entire backend.
I asked a few questions (for example, how would the endpoints look, what data fields did he need, how much was he willing to pay…). I got his answers. Everything was in an email thread within a couple days.
On November 30, 2017, I quickly implemented three endpoints (GET /search, GET /podcasts/{id}, and GET /episodes/{id}), which were basically three Django views.
I Googled “API gateway” or something like that and found a service called Mashape, which was an API marketplace that handled payment, user management, and API documentation.
So I put my three endpoints on Mashape and created two plans there: FREE and PRO. I emailed the developer back to tell him the API was ready to use.
 The email thread that prompted me to build Listen API
The email thread that prompted me to build Listen API
Then nothing happened. The podcast app developer didn’t use our API and instead phased out their project.
Eventually, I moved on to primarily focus on the development of listennotes.com. The API was basically in self-driving mode on the open web. Anyone who happened to discover our API could sign up, without talking to any human beings.
On January 14, 2018, I got my first paying user. A few more paying users arrived that same year.
 The email notification I received for my first paying user
The email notification I received for my first paying user
Wait, what is RapidAPI? Well, Mashape was acquired by a startup named RapidAPI. They didn’t rebrand Mashape to RapidAPI completely until mid-2018. Startups typically don’t do things in a clean and methodical way, which is totally understandable.
Then something happened.
There was an outage on the RapidAPI end on November 29, 2018.
 The email I sent to people in RapidAPI when the outage happened
The email I sent to people in RapidAPI when the outage happened
RapidAPI had performed a big backend upgrade around that time. As an engineer, I totally understand that outages happen, especially when making huge changes in the backend. But I felt helpless because their customer support didn’t reply to my email. Phone call didn't work, as expected.
Usually their customer support was very responsive. Perhaps it was the holiday season and people were on vacation.
So I used hunter.io to find work emails of individual RapidAPI employees, the CEO, as well as the CTO. The issue was finally resolved, many hours later. In other words, our API was completely unusable during those down hours. I felt very sorry for our paying users.
Then around mid-February 2019, RapidAPI had billing problems and failed to pay us a few thousand bucks. Our paying users paid RapidAPI first. RapidAPI took a 20% cut. Then they paid the remaining 80% (minus PayPal fees) to us.
After several back-and-forth emails and phone calls, we finally got our payment. It’s understandable. Again, startups make mistakes.
In late February 2019, I decided to build our own RapidAPI replacement, for a few reasons:
- Our API revenue became nontrivial. The 20% cut from RapidAPI was a bit too much for us.
- We wanted API requests to hit our own servers directly, thus lowering latency for our users.
- I didn’t want to feel helpless when RapidAPI had outages. Overall they did a good job running the service. But I wanted to control my own destiny.
- I wanted to contact my API users directly. Using RapidAPI, API providers like me didn’t have access to our users’ email addresses. It’s understandable. It’s like the “Uber for X” companies that don’t want workers and customers to bypass them and strike deals under the table. Marketplaces don’t want users to skip the middleman’s commission fees.
In addition, I vowed to do two things really well for our new API system:
- We must provide great customer service to our paying users.
- We will give customers a very stable & reliable backend service.
After 30 days of hard work, we launched Listen API v2 on March 27, 2019. The legacy API hosted on RapidAPI became Listen API v1, a version we won’t add new features to but don’t want to shut down because some apps are still using it as of December 2020!
We continue to improve our new Listen API v2 by adding new endpoints, new data fields, improving operational efficiency, as well as spiffing up the user dashboard and our internal tools.
Things are picking up speed gradually. I’ve been happy since then.
So, that’s the journey of Listen API so far.
Note: Although we decided to move on from RapidAPI, I still think it’s a great service. Startups all make mistakes in the early stage. They fix things and continue to improve their service, which is great!
The technology behind Listen API
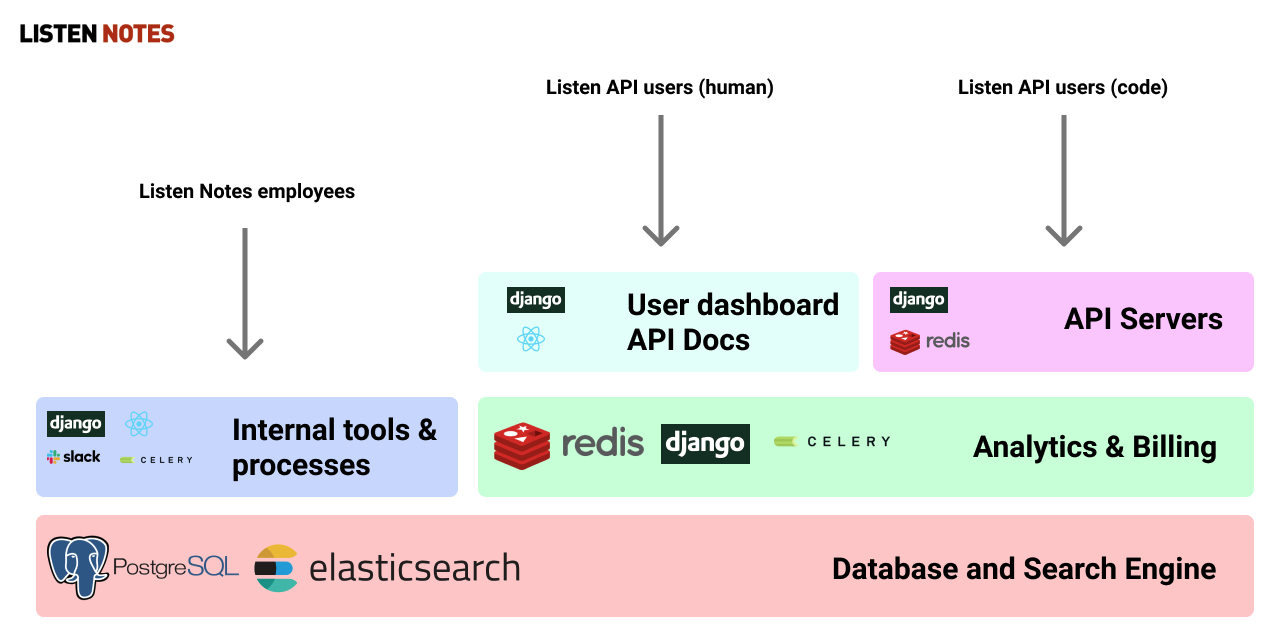
Developers can use our API to search podcasts and fetch detailed podcast-episode metadata. To make this whole thing work, we need to make sure a few core components are in place.
 Listen API's main components and the technologies used
Listen API's main components and the technologies used
Datastore and search engine
This is a shared component with our website. Therefore, I didn’t need to change anything in the datastore and search engine when building our API infrastructure.
We use Postgres as our main data store (for example, for podcast metadata, user accounts, and so on), and Elasticsearch as the search engine.
I wrote an old blog post with the details of the entire tech stack.
Internal tools and processes
If you’ve worked at any web companies, you probably know what I’m referring to here.
It’s rare for an Internet business to be 100% automatic. A company always needs to build tons of internal tools and set up manual processes to keep the service functional. That’s why companies like Retool have such a high valuation nowadays.
Companies are investing big money in internal tools that are invisible to end users:
 Percentage of team's time spent on internal tools. Credits: Retool
Percentage of team's time spent on internal tools. Credits: Retool
To start our API business, we needed to build (at least) two types of internal tools:
- For data operations: We needed the ability to keep the podcast metadata up-to-date, fix corrupted metadata, plus review and approve any changes made by users.
Additionally, we required a framework that handled new, rare edge cases of corrupted podcast data along the way. To some degree, building a software product means handling tons of edge cases for a very long period of time (like, years), rather than launching new features every day. - For user operations: We required the ability to suspend a bad user’s account, as well as immediately look up all information related to a specific user who contacted us for a specific issue.
Plus, we had to be able to quickly evaluate if “it’s our fault” (server-side errors) or “it’s their fault” (client-side errors) when users complained.
Internal tools are used by employees inside the company. Some of those tools are fully automated, such as cron jobs that perform scheduled tasks. But many tools should be used manually by human employees, for example when inputting a user’s ID number and clicking a button.
Most of our internal tools have ugly web UIs, with default Bootstrap styling :)
 A portion of our internal tool’s UI that allows us to suspend an API user’s account.
A portion of our internal tool’s UI that allows us to suspend an API user’s account.
Fortunately, our API shares many internal tools with the website. So we didn’t need to build too many new things here.
The analytics and billing system
The pricing model of an API is typically usage-based. Check out some real world examples:
- https://www.twilio.com/pricing
- https://sendgrid.com/pricing/
- https://cloud.google.com/maps-platform/pricing/
- https://www.microsoft.com/en-us/bing/apis/pricing
It’s a must to track how many requests a user uses in real-time. We use Redis to keep track of such stats and periodically dump into Postgres for persistent storage.
What happens if our Redis has an outage? We might temporarily lose some tracking stats. In this case, we have an internal tool to sync stats from raw Nginx logs.
We have to change billing plans without affecting existing users. For example, if we raise prices, existing users should still enjoy the benefit of the old plans. If it’s not done right, it’s easy to have inconsistent states across the board, and angry users getting charged the wrong billing plan!
Payment failures, a very common occurrence, must be handled gracefully. We can’t just suspend users right away. We need to be able to notify ourselves that “this user failed to pay” and notify the user that “you failed to pay.”
After a few retries, we suspend users manually — well, we could’ve automated this last step. But we don’t suspend users often nowadays, so it’s okay to do so manually. There’s no need to make everything perfect (at least for now).
We have a dashboard (God’s view) to see how many requests each individual user uses in the current billing cycle. And we are able to review raw logs for each user from a web UI, without manually pulling log files from S3.
Stripe and PayPal (via Braintree) are our payment processors. Most of our international users use PayPal.
Finally, putting all of these factors together, we can calculate the actual amount of money that a user should pay us in real-time, based on their usage. We run async tasks via Celery to charge due bills.
What happens if a user unsubscribes in the middle of a billing cycle? We charge them prorated rates, based on time and usage. Users don’t need to pay a full month’s fee in those instances.
API Servers
We run Django apps to serve API requests. Each endpoint is a simple Django view. A Django middleware verifies if a request is legit, then generates a log or rejects the request right away.
We cache response data per API key + unique URL in Redis. In general, our API performance is pretty good.
We use Nginx as a load balancer and provision multiple API servers. It’s straightforward to do rolling deployment here, with a bunch of sanity checks to ensure the API is functioning.
Generally speaking, the easy and robust deployment process increases my confidence to make incremental code changes often and to deploy frequently.
An API endpoint is RESTful and returns a JSON response, pretty standard nowadays.
User Dashboard and API Docs
Each API user can access a dashboard on our website to learn the amount of requests they’ve used in the current billing cycle and view recent raw logs. They can also update payment methods, create or reset new API keys, set up webhooks, and add coworkers to the same API account.
 Listen API's user dashboard
Listen API's user dashboard
API Docs is probably the most important UI for an API business. Therefore, many API companies employ a whole team of full-time engineers to build and maintain “merely” the API Docs page(s).
An API Docs page is not simply a full page of English words. It must show code snippets for different programming languages.
Users have to be able to run your code example directly from the page. You are required to design a repeatable process (no matter if it's automatic or manual) to keep the documentation in sync with your code. There are plenty of nuances.
We spent a lot of time and energy building and iterating multiple versions of our API Docs page. Following is the end result:

Initially, we tried a few open source solutions for the API documentation. It’s quite time-consuming to understand an open source project well enough to customize it. Ultimately, we decided that it would be faster to build the page from scratch rather than customizing an open source solution built by others.
Our API Docs page is basically a React JS single page app.
We codify all endpoints, response data schema, and example response in an OpenAPI spec. The React JS app of the API Docs page reads from our OpenAPI spec directly.
The side effect of using OpenAPI is that we can easily integrate with tools like Postman, because OpenAPI is a (relatively) widely adopted standard for API documentation nowadays.
Why Listen API works
Listen API has been a nice business for me so far.
But don’t expect me to share revenue numbers publicly :)
Some companies are doing this open startup thing, sharing every single business metric to the public, which is great.
But we shouldn’t blame the majority of companies (including my small company Listen Notes, Inc.) who don’t want to share business metrics publicly.
Not everyone is comfortable being naked in public, literally or figuratively.
Similarly, there’s lots of business advice (or cliches) that you don’t have to follow.
- You don’t have to find a cofounder - having a horrible cofounder is way worse than not having one.
- You don't have to reveal your revenue to public or do any "open startup" thing. No pressure. Don't feel guilty if you are not doing what other cool kids are doing. You run your own company. You make your own decisions.
- You don’t have to do XYZ that a Twitter VC philosopher urges you to do in a fortune-cookie-like tweet.
- You don't have to be 100% bootstrap nor 100% VC-backed. Many things are not completely one way or the other. Usually, there's middle ground.
- ...and the list goes on.
The bottom line is, not one is absolutely wrong or absolutely correct. Each individual's vision/knowledge is limited. Each person's preferences might be very different.
An API business may be too obscure to most people in the world, but I like my API business very much. People from big companies (like Apple, Amazon, or Microsoft) may examine my business and deem it “cute”. But I would consider it a success for me personally.
And success is relative. The key is to bring happiness to customers (by saving them time and money and helping them solve problems), myself (a professional achievement), and my family (by keeping the fridge full).
So why does the Listen API work?
Demand and MVP
I didn’t build a solution to find problems. It was the problem (a podcast app that wanted to add search functionality) that found us—and we built a very simple solution at first.
We didn’t spend months launching the API. We spent a couple of hours. It costs at least $100 per hour to hire a not-so-bad engineer in San Francisco, so the cost of launching this API MVP was approximately $200. Even if it were $2,000, I'd still think it was worthwhile.
Two reasons why we were able to launch an MVP quickly:
- The heavy lifting part of building a podcast database, search engine, and data operations tool was already done, because of our podcast search engine website.
- Mashape / RapidAPI existed to provide a plug-and-play solution for us to manage users and create paid plans without writing code on our end.
However, in hindsight, it’s actually very common for a commercial search engine to license their tech (via API or other ways). Some examples:
- Yahoo Search was powered by Google circa 2000, and is powered by Bing today.
- In the early days, Baidu's only business model was to put a web search on some Chinese portal sites
- Today, Bing provides a bunch of search APIs.
By launching an MVP fast, we were able to get feedback early, especially after getting the first paying user only a month or so after launch.
Good documentation
User feedback proves that our API Docs page plays an important role in customers' decisions to use our API. There must be a reason for API companies to employ a whole team of engineers “only” to maintain their documentation pages.
Great documentation builds trust.
Stable backend service
Stability is the essential base of an API business’ Maslow’s hierarchy of needs. If an API is not stable at all (for example, it has frequent outages or runs very very slowly), it can't be used.
However, it’s boring to perform work to improve backend stability. Most tasks to stabilize backend services are preventive, including extensive monitoring and alerting, the process to deploy code with confidence, end-to-end regression tests, and so on.
No news is good news.
No outages are great news.
We use Statuspage.io to hook up our Datadog metrics to build a status page: listennotesstatus.com.
 System status page of Listen Notes
System status page of Listen Notes
Here’s hoping that the status page will convince our prospective users to try out our API :)
Excellent customer service
We are all customers of someone else’s products and services. We have all been frustrated with poor customer service at some point in our lives. It’s obvious that great customer service goes a long way — RIP, Tony.
Many people are likely not aware that you have to pay AWS big money to access better customer service!
Our customers don’t only pay us for using our API, an online service. They also pay for being able to get high-quality customer assistance from real human beings. In our case, it’s me, the person who built this thing.
I use Superhuman to process emails promptly and efficiently. And I’ve got a ton of prewritten email templates to handle the most popular customer support tickets. Oftentimes I can reply to an email within 5 seconds, using CMD + K to select an email template.
Invest in internal tools and processes
For knowledge work, it’s possible that one single person (or a tiny team) can create 10x, 100x, or even 1,000x more value than a big team.
Let’s look at an extreme example: book publishing. It’s (almost) impossible to hire 10,000 good writers to collaborate on one book together and hope it’s “better” cohesively than Harry Potter, written by a single author.
JK Rowling, a single person, created way more value (in terms of measurable dollar amount and unmeasurable happiness, good times) than most companies with hundreds of employees in the world.
Eventually, the software business would grow in a similar way.
We already witnessed the 13-employee Instagram get acquired for $1B in 2012. When will we see a $1B+ software/internet company with 5 or fewer employees achieve the same feat?
Great internal tools and processes provide leverage to enable a tiny team to be super-efficient. This is easy to understand. We human beings already built a lot of tools to greatly extend our physical/mental limits, for example bikes and cars (versus walking), computers (versus manual calculation), and so on.
Given that it’s (almost) impossible to 100% automate an Internet business, we have to improve the efficiency of manual operations. It’s a great investment to increase human operators’ productivity.
Tidbits of running Listen API as a business
Here are some things I didn’t know before…
Anyone can sign up => Submit your application first
A few years ago, I noticed that certain APIs required me to submit an application first, describing my use case, before giving me an API key.
I didn’t understand the rationale back then.
After running my own API business, now I understand.
The Internet is huge. The world is gargantuan. There are good people and bad people. If the API you provide is useful, some folks will try to abuse your API.
That’s what happened when we initially allowed anyone to create an API account. We were seeing users creating dozens of accounts in order to get around the free quota limit.
Today, we require people to submit an application first. We get a notification via Slack. Then we use our internal tool to review and approve or reject the application. The applicant receives an automatic email. On our end, it’s two or three clicks to finish all these operations.
To assist our review process, we use a bunch of heuristics:
Did this user previously create multiple accounts?
Is this IP address a well-known spammer discoverable via stopforumspam.com? (hint: there's an API for that)
And so on…
Again, we are seeing new edge cases from time to time. Yet we are also learning how to handle those unique cases.
Ideal customers and interesting customers
Our best customers are mostly startup founders who have been in business for quite some time.
They can make decisions on their own. They understand the value we provide. They have the power to finalize purchase decisions. And they are competent enough to read our documentation autonomously and ask very few questions — or they don’t even talk to us at all.
On the other hand, people from well-funded VC-backed startups or huge companies (some of the biggest companies in the world) oftentimes ask for a discount or free trial, which we don’t have. Why? I don’t have a good answer here.
Of course, there are always exceptions.
Dev shops and coding bootcamps
Many of our users hire freelancers or dev shops overseas to build apps and websites.
Generally speaking, developers from dev shops are not as good as in-house developers. Although not 100% true, the chance is quite high.
In essence, a bunch of my customer support replies are to teach Computer Science 101 . Sometimes they sent code snippets in PHP (or a language that I don’t know) to ask us to debug it via email.
I understand that some of those developers from dev shops are fresh out of coding bootcamps (or the dev shop itself is a coding bootcamp). Most of the time I will Google for them and send them a StackOverflow link or something like that. But occasionally, if I was in a bad mood, I would not reply to the “help me debug my PHP code” emails from FREE users who don’t pay us.
Also, quite a few coding bootcamps use our API to teach students how to write code, which is great. In real-world web projects, you can’t avoid using third-party REST APIs. Teaching new programmers how to talk to a REST API is necessary.
API is a slow business
Usually it’ll take a user a few months to start paying us.
They need to add a big product feature or even build an entire app first. Then they need to do some marketing and get some traction. Finally, they pay, or they give up and shut down the app.
We definitely should think about how to help our users build product features fast.
Stripe is doing a great job in this area. They built a lot of nice UI components that developers can directly use without writing tons of code, like Checkout.
API is a stable business
Our churn rate is quite low. People spend many months building an app using our API, so it’s unlikely that they’ll switch to something else overnight.
I’m happy with that fact.
Meanwhile, I’m also very bullish on all the other API businesses out there, like Stripe, Plaid, and Twilio. (This isn’t investment advice, but look at the stock TWLO.)
Start with whales, then diversify
At the early stage, there might be a few user “whales” who account for a big portion or even most of the revenue.
Don’t panic.
Having revenue is still better than not having revenue at all.
We are not in a position to be picky at the early stage. We can diversify along the way.
I like reading S-1s.
It’s not uncommon to see some SaaS or API companies with a few whales when they went public. If they lost one or two such whales, their revenue would drop 10%, or even 20%+ immediately! Well, they are already a public company. No need to worry about them. They know what to do next.
Pricing is a work-in-progress
We are always experimenting with new pricing. Similar to building software projects in general, pricing is always a work in progress.
We allow old users to stick to the lower pricing they obtained when they signed up. Any future price changes won’t affect existing paying users.
I know that select pricing experts would warn me that I leave money on the table by this practice. But I feel thankful for customers who stand by us for so long. I want them to enjoy the low pricing as a benefit.
By the way, ProfitWell has great resources regarding pricing.
Haters / irrelevant critiques
You may have seen this theory: When you have haters, you’re doing something right.
There’s a similar quote from Zeng Guofan (one of the most important military leaders and politicians in the 19th century China):
不招人妒者皆庸才. “If no one envies you, then you are incompetent.”
Side note: You can find Zeng Guofan’s wisdom inside many airport bookstores in China. He would have been a great Twitter user and beat those Twitter VC philosophers if he were born in our time - it's hard to beat a historical Chinese figure in the game of fortune cookie :)
If your project is visible on the Internet and gets a bit of traction, some people will hate you for no particular reason.
Once you offer a paid service, you’ll never provide a price that is low enough to make everyone in the world happy. No, $1.00 USD is not cheap at all in many places in the world. People who are not your target users will complain about your pricing.
From my experience, it’s safe to ignore most critics, advice-givers, and suggestions from non-users. Sometimes people try to compare two things with similar names.
For example, if you search “podcast API” on Google, you’ll find a few other APIs with “podcast API” in their names. However, if you spend a few minutes skimming the documentation, you’ll find obvious differences. It’s like comparing two people with the same first name and family name who are two completely different individuals after all.
The only critiques or suggestions I care about are mostly from our users. I can see their API usage. I know they are expressing meaningful facts. So I listen to them.
So are you interested building an API business?
Nowadays, the “passion economy” or “creator economy” is hot.
Who are creators? Writers, podcasters, streamers…
Don’t forget that software developers are also creators!
If you already run a website or have some interesting data, you may start an API business as well.
Thanks for reading this long article :) Let me know what you think: wenbin@listennotes.com. And you can read more of my posts on my blog.