

Interested in learning JavaScript? Get my ebook at jshandbook.com
This case study explains how I added the capability of working offline to the writesoftware.org website (which is based on Grav, a great PHP-based CMS for developers). I did this by introducing a set of technologies grouped under the name of Progressive Web Apps (in particular Service Workers and the Cache API).
There’s a lot to learn about this topic and the new browser APIs. I publish a lot of related content on my blog about frontend development, don’t miss it!
I will show the options I had available, and why I chose one approach over the others.
When we’re finished, we’ll be able to use our site on a mobile device or on a desktop browser — even when offline — like I’ve shown here:
 Notice the “Offline” option in the network throttling settings
Notice the “Offline” option in the network throttling settings
First approach: cache-first
I first approached the task by using a cache-first approach: when we intercept a fetch request in the Service Worker, we first check if we have it cached already. If not, we fetch it from the network.
This has the advantage of making the site blazing fast when loading pages already cached, even when online — in particular with slow networks and lie-fi. But it also introduces some complexity in managing updates to the cache when I ship new content.
This will not be the final solution I adopt, but it’s worth going through it for demonstration purposes.
I’ll go through a couple phases:
- I introduce a Service Worker and load it using a JS script
- When installing the Service Worker, I cache the site skeleton
- I intercept network requests going to additional links and cache them
Introducing a Service Worker
I add the Service Worker in a sw.js file in the site root. This gives it enough scope to work on all the site subfolders, and on the site home as well (more on Service Workers’ scope here). The SW at the moment is pretty basic, as it just logs any network request:
self.addEventListener('fetch', (event) => {
console.log(event.request)
})
I need to register the Service Worker, and I do this from a script that I include in every page:
window.addEventListener('load', () => {
if (!navigator.serviceWorker) {
return
}
navigator.serviceWorker.register('/sw.js', {
scope: '/'
}).then(() => {
//...ok
}).catch((err) => {
console.log('registration failed', err)
})
})
If Service Workers are available, we register the sw.js file, and the next time I refresh the page it should be working fine:
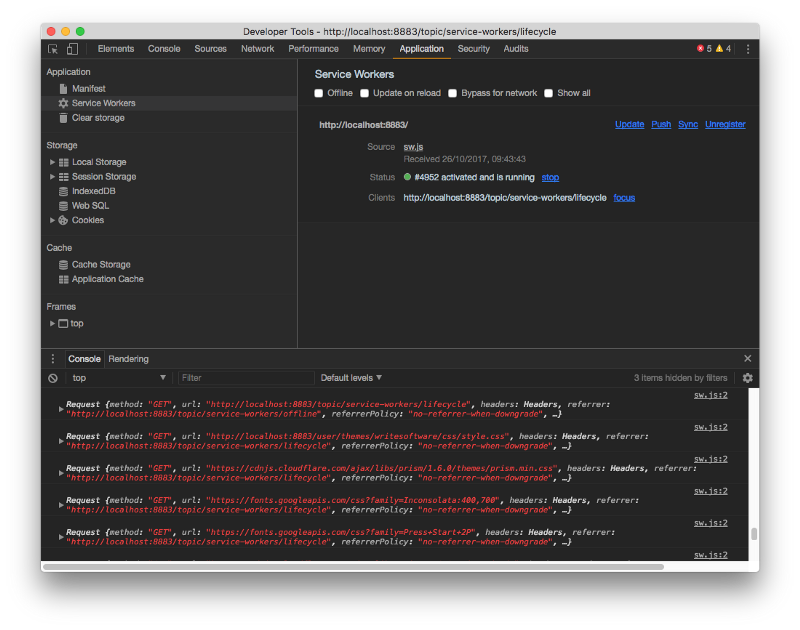
At this point, I need to do some heavy lifting on the site. First of all, I need to come up with a way to serve only the App Shell: a basic set of HTML + CSS and JS that will be always available and shown to the users, even when offline.
It’s basically a stripped-down version of the website, with a <div class="wrapper row" id="content-wrapper"></div> empty element, which we’ll fill with content later, available under the /shell route:
So the first time the user loads the site, the normal version of a page will be shown (full-HTML version), and the Service Worker is installed.
Now any other page that is clicked is intercepted by our Service Worker. Whenever a page is loaded, we load the shell first, and then we load a stripped-down version of the page, without the shell, just the content.
How?
We listen for the install event, which fires when the Service Worker is installed or updated. When this happens, we initialize the cache with the content of our shell: the basic HTML layout, plus some CSS, JS, and some external assets:
const cacheName = 'writesoftware-v1'
self.addEventListener('install', (event) => {
event.waitUntil(caches.open(cacheName).then(cache => cache.addAll([
'/shell',
'user/themes/writesoftware/favicon.ico',
'user/themes/writesoftware/css/style.css',
'user/themes/writesoftware/js/script.js',
'https://fonts.googleapis.com/css?family=Press+Start+2P',
'https://fonts.googleapis.com/css?family=Inconsolata:400,700',
'https://cdnjs.cloudflare.com/ajax/libs/prism/1.6.0/themes/prism.min.css',
'https://cdnjs.cloudflare.com/ajax/libs/prism/1.6.0/prism.min.js',
'https://cdn.jsdelivr.net/prism/1.6.0/components/prism-jsx.min.js'
])))
})
Then when we perform a fetch, we intercept requests to our pages, and fetch the shell from the Cache instead of going to the network.
If the URL belongs to Google Analytics or ConvertKit, I avoid using the local cache, and I fetch them without using CORS (since I am not allowed to access them through this method).
Then, if I’m requesting a local partial (just the content of a page, not the full page), I just issue a fetch request to get it.
If it’s not a partial, we return the shell, which is already cached when the Service Worker is first installed.
Once the fetch is done, I cache it.
self.addEventListener('fetch', (event) => {
const requestUrl = new URL(event.request.url)
if (requestUrl.href.startsWith('https://www.googletagmanager.com') ||
requestUrl.href.startsWith('https://www.google-analytics.com') ||
requestUrl.href.startsWith('https://assets.convertkit.com')) {
// don't cache, and no cors
event.respondWith(fetch(event.request.url, { mode: 'no-cors' }))
return
}
event.respondWith(caches.match(event.request)
.then((response) => {
if (response) { return response }
if (requestUrl.origin === location.origin) {
if (requestUrl.pathname.endsWith('?partial=true')) {
return fetch(requestUrl.pathname)
} else {
return caches.match('/shell')
}
return fetch(`${event.request.url}?partial=true`)
}
return fetch(event.request.url)
})
.then(response => caches.open(cacheName).then((cache) => {
cache.put(event.request.url, response.clone())
return response
}))
.catch((error) => {
console.error(error)
}))
})
Now I edit the script.js file to introduce an important feature: whenever a link is clicked on my pages, I intercept it and I issue a message to a Broadcast Channel.
Since Service Workers are currently only supported in Chrome, Firefox, and Opera, I can safely rely on the BroadcastChannel API for this.

First, I connect to the ws_navigation channel, and I attach a onmessage event handler on it. Whenever I receive an event, it’s a communication from the Service Worker with new content to show inside the App Shell. So I just look up the element with id content-wrapper and put the partial page content into it, effectively changing the page the user is seeing.
As soon as the Service Worker is registered, I issue a message to this channel with a fetchPartial task and a partial page URL to fetch. This is the content of the initial page load.
The shell is loaded immediately since it’s always cached. Soon after, the actual content is looked up, which might be cached as well.
window.addEventListener('load', () => {
if (!navigator.serviceWorker) { return }
const channel = new BroadcastChannel('ws_navigation')
channel.onmessage = (event) => {
if (document.getElementById('content-wrapper')) {
document.getElementById('content-wrapper').innerHTML = event.data.content
}
}
navigator.serviceWorker.register('/sw.js', {
scope: '/'
}).then(() => {
channel.postMessage({
task: 'fetchPartial',
url: `${window.location.pathname}?partial=true`
})
}).catch((err) => {
console.log('SW registration failed', err)
})
})
The missing bit is handing a click on the page. When a link is clicked, I intercept the event, halt it, and send a message to the Service Worker to fetch the partial with that URL.
When fetching a partial, I attach a ?partial=true query to tell my backend to only serve the content, not the shell.
window.addEventListener('load', () => {
//...
window.onclick = (e) => {
let node = e.target
while (node !== undefined && node !== null && node.localName !== 'a') {
node = node.parentNode
}
if (node !== undefined && node !== null) {
channel.postMessage({
task: 'fetchPartial',
url: `${node.href}?partial=true`
})
return false
}
return true
}
})
Now we just miss to handle this event. On the Service Worker side, I connect to the ws_navigation channel and listen for an event. I listen for the fetchPartial message task name, although I could simply avoid this condition check as this is the only event that’s being sent here. Note that messages in the Broadcast Channel API are not dispatched to the same page that’s originating them — they’re only dispatched between a page and a web worker.
I check if the URL is cached. If so, I just send it as a response message on the channel and return.
If it’s not cached, I fetch it, send it back as a message to the page, and then cache it for the next time it might be visited.
const channel = new BroadcastChannel('ws_navigation')
channel.onmessage = (event) => {
if (event.data.task === 'fetchPartial') {
caches
.match(event.data.url)
.then((response) => {
if (response) {
response.text().then((body) => {
channel.postMessage({ url: event.data.url, content: body })
})
return
}
fetch(event.data.url).then((fetchResponse) => {
const fetchResponseClone = fetchResponse.clone()
fetchResponse.text().then((body) => {
channel.postMessage({ url: event.data.url, content: body })
})
caches.open(cacheName).then((cache) => {
cache.put(event.data.url, fetchResponseClone)
})
})
})
.catch((error) => {
console.error(error)
})
}
}
We’re almost done.
Now the Service Worker is installed on the site as soon as a user visits. Subsequent page loads are handled dynamically through the Fetch API, not requiring a full page load. After the first visit, pages are cached and load incredibly fast, and — more importantly — then even load when offline!
And — all this is a progressive enhancement. Older browsers, and browsers that don’t support Service Workers, simply work as normal.
Now, hijacking the browser navigation poses a few problems:
- The URL must change when a new page is shown. The back button should work normally, and the browser history as well.
- The page title must change to reflect the new page title.
- We need to notify the Google Analytics API that a new page has been loaded to avoid missing an important metric such as the page views per visitor.
- The code snippets are not highlighted anymore when loading new content dynamically.
Let’s solve those challenges.
Fix URL, title, and back button with the History API
In addition to injecting the HTML of the partial in the message handler in script.js, we trigger the history.pushState() method:
channel.onmessage = (event) => {
if (document.getElementById('content-wrapper')) {
document.getElementById('content-wrapper').innerHTML = event.data.content
const url = event.data.url.replace('?partial=true', '')
history.pushState(null, null, url)
}
}
This is working, but the page title does not change in the browser UI. We need to fetch it somehow from the page. I decided to put a hidden span in the page content partial that keeps the page title. Then we can fetch it from the page using the DOM API, and set the document.title property:
channel.onmessage = (event) => {
if (document.getElementById('content-wrapper')) {
document.getElementById('content-wrapper').innerHTML = event.data.content
const url = event.data.url.replace('?partial=true', '')
if (document.getElementById('browser-page-title')) {
document.title = document.getElementById('browser-page-title').innerHTML
}
history.pushState(null, null, url)
}
}
Fix Google Analytics
Google Analytics works fine out of the box, but when loading a page dynamically, it can’t do miracles. We must use the API it provides to inform it of a new page load. Since I’m using the Global Site Tag (gtag.js ) tracking, I need to call:
gtag('config', 'UA-XXXXXX-XX', {'page_path': '/the-url'})
into the code above that handles changing page:
channel.onmessage = (event) => {
if (document.getElementById('content-wrapper')) {
document.getElementById('content-wrapper').innerHTML = event.data.content
const url = event.data.url.replace('?partial=true', '')
if (document.getElementById('browser-page-title')) {
document.title = document.getElementById('browser-page-title').innerHTML
}
history.pushState(null, null, url)
gtag('config', 'UA-XXXXXX-XX', {'page_path': url})
}
}
What if… the user is offline? Ideally, there should be a fetch event listener that caches any request going to Google Analytics and replays them as soon as I’m online again.
Thankfully there is a library that does exactly this, relying on IndexedDB to store the data. It’s been moved into Workbox, if you prefer to use that library to handle caching at a higher level.
Fix syntax highlighting
The last thing I need to fix on my page is the highlighting of the code snippets’ login. I use the Prism syntax highlighter and they make it very easy — I just need to add a call Prism.highlightAll() in my onmessage handler:
channel.onmessage = (event) => {
if (document.getElementById('content-wrapper')) {
document.getElementById('content-wrapper').innerHTML = event.data.content
const url = event.data.url.replace('?partial=true', '')
if (document.getElementById('browser-page-title')) {
document.title = document.getElementById('browser-page-title').innerHTML
}
history.pushState(null, null, url)
gtag('config', 'UA-XXXXXX-XX', {'page_path': url})
Prism.highlightAll()
}
}
The full code of script.js is:
window.addEventListener('load', () => {
if (!navigator.serviceWorker) { return }
const channel = new BroadcastChannel('ws_navigation')
channel.onmessage = (event) => {
if (document.getElementById('content-wrapper')) {
document.getElementById('content-wrapper').innerHTML = event.data.content
const url = event.data.url.replace('?partial=true', '')
if (document.getElementById('browser-page-title')) {
document.title = document.getElementById('browser-page-title').innerHTML
}
history.pushState(null, null, url)
gtag('config', 'UA-1739509-49', {'page_path': url})
Prism.highlightAll()
}
}
navigator.serviceWorker.register('/sw.js', {
scope: '/'
}).then(() => {
channel.postMessage({
task: 'fetchPartial',
url: `${window.location.pathname}?partial=true`
})
}).catch((err) => {
console.log('SW registration failed', err)
})
window.onclick = (e) => {
let node = e.target
while (node !== undefined && node !== null && node.localName !== 'a') {
node = node.parentNode
}
if (node !== undefined && node !== null) {
channel.postMessage({
task: 'fetchPartial',
url: `${node.href}?partial=true`
})
return false
}
return true
}
})
and sw.js:
const cacheName = 'writesoftware-v1'
self.addEventListener('install', (event) => {
event.waitUntil(caches.open(cacheName).then(cache => cache.addAll([
'/shell',
'user/themes/writesoftware/favicon.ico',
'user/themes/writesoftware/css/style.css',
'user/themes/writesoftware/js/script.js',
'user/themes/writesoftware/img/offline.gif',
'https://fonts.googleapis.com/css?family=Press+Start+2P',
'https://fonts.googleapis.com/css?family=Inconsolata:400,700',
'https://cdnjs.cloudflare.com/ajax/libs/prism/1.6.0/themes/prism.min.css',
'https://cdnjs.cloudflare.com/ajax/libs/prism/1.6.0/prism.min.js',
'https://cdn.jsdelivr.net/prism/1.6.0/components/prism-jsx.min.js'
])))
})
self.addEventListener('fetch', (event) => {
const requestUrl = new URL(event.request.url)
if (requestUrl.href.startsWith('https://www.googletagmanager.com') ||
requestUrl.href.startsWith('https://www.google-analytics.com') ||
requestUrl.href.startsWith('https://assets.convertkit.com')) {
// don't cache, and no cors
event.respondWith(fetch(event.request.url, { mode: 'no-cors' }))
return
}
event.respondWith(caches.match(event.request)
.then((response) => {
if (response) { return response }
if (requestUrl.origin === location.origin) {
if (requestUrl.pathname.endsWith('?partial=true')) {
return fetch(requestUrl.pathname)
} else {
return caches.match('/shell')
}
return fetch(`${event.request.url}?partial=true`)
}
return fetch(event.request.url)
})
.then(response => caches.open(cacheName).then((cache) => {
if (response) {
cache.put(event.request.url, response.clone())
}
return response
}))
.catch((error) => {
console.error(error)
}))
})
const channel = new BroadcastChannel('ws_navigation')
channel.onmessage = (event) => {
if (event.data.task === 'fetchPartial') {
caches
.match(event.data.url)
.then((response) => {
if (response) {
response.text().then((body) => {
channel.postMessage({ url: event.data.url, content: body })
})
return
}
fetch(event.data.url).then((fetchResponse) => {
const fetchResponseClone = fetchResponse.clone()
fetchResponse.text().then((body) => {
channel.postMessage({ url: event.data.url, content: body })
})
caches.open(cacheName).then((cache) => {
cache.put(event.data.url, fetchResponseClone)
})
})
})
.catch((error) => {
console.error(error)
})
}
}
Second approach: network-first, drop the app shell
While the first approach gave us a fully working app, I was a bit skeptical and worried about having a copy of a page cached for too long on the client. So I decided to try a network-first approach: when a user loads a page, it is fetched from the network first.
If the network call fails for some reason, I look up the page in the cache to see if we got it cached. Otherwise, I show the user a GIF if it’s totally offline, or another GIF if the page does not exist (I can reach it, but I got a 404 error).
As soon as we get a page, we cache it (not checking if we cached it previously or not, we just store the latest version).
As an experiment, I also got rid of the app shell altogether, because in my case I had no intentions of creating an installable app yet. Without an up-to-date Android device I could not really test-drive it, and I preferred to avoid throwing out stuff without proper testing.
To do this, I just stripped the app shell from the install Service Worker event. I relied on Service Workers and the Cache API to deliver just the plain pages of the site, without managing partial updates. I also dropped the /shell fetch hijacking when loading a full page. On the first page load there is no delay, but we still load partials when navigating to other pages later.
I still use script.js and sw.js to host the code, with script.js being the file that initializes the Service Worker, and also intercepts clicks on the client-side.
Here’s script.js :
const OFFLINE_GIF = '/user/themes/writesoftware/img/offline.gif'
const fetchPartial = (url) => {
fetch(`${url}?partial=true`)
.then((response) => {
response.text().then((body) => {
if (document.getElementById('content-wrapper')) {
document.getElementById('content-wrapper').innerHTML = body
if (document.getElementById('browser-page-title')) {
document.title = document.getElementById('browser-page-title').innerHTML
}
history.pushState(null, null, url)
gtag('config', 'UA-XXXXXX-XX', { page_path: url })
Prism.highlightAll()
}
})
})
.catch(() => {
if (document.getElementById('content-wrapper')) {
document.getElementById('content-wrapper').innerHTML = `<center><h2>Offline</h2><img src="${OFFLINE_GIF}" /></center>`
}
})
}
window.addEventListener('load', () => {
if (!navigator.serviceWorker) { return }
navigator.serviceWorker.register('/sw.js', {
scope: '/'
}).then(() => {
fetchPartial(window.location.pathname)
}).catch((err) => {
console.log('SW registration failed', err)
})
window.onclick = (e) => {
let node = e.target
while (node !== undefined && node !== null && node.localName !== 'a') {
node = node.parentNode
}
if (node !== undefined && node !== null) {
fetchPartial(node.href)
return false
}
return true
}
})
and here’s sw.js :
const CACHE_NAME = 'writesoftware-v1'
const OFFLINE_GIF = '/user/themes/writesoftware/img/offline.gif'
const PAGENOTFOUND_GIF = '/user/themes/writesoftware/img/pagenotfound.gif'
self.addEventListener('install', (event) => {
event.waitUntil(caches.open(CACHE_NAME).then(cache => cache.addAll([
'/user/themes/writesoftware/favicon.ico',
'/user/themes/writesoftware/css/style.css',
'/user/themes/writesoftware/js/script.js',
'/user/themes/writesoftware/img/offline.gif',
'/user/themes/writesoftware/img/pagenotfound.gif',
'https://fonts.googleapis.com/css?family=Press+Start+2P',
'https://fonts.googleapis.com/css?family=Inconsolata:400,700',
'https://cdnjs.cloudflare.com/ajax/libs/prism/1.6.0/themes/prism.min.css',
'https://cdnjs.cloudflare.com/ajax/libs/prism/1.6.0/prism.min.js',
'https://cdn.jsdelivr.net/prism/1.6.0/components/prism-jsx.min.js'
])))
})
self.addEventListener('fetch', (event) => {
if (event.request.method !== 'GET') return
if (event.request.headers.get('accept').indexOf('text/html') === -1) return
const requestUrl = new URL(event.request.url)
let options = {}
if (requestUrl.href.startsWith('https://www.googletagmanager.com') ||
requestUrl.href.startsWith('https://www.google-analytics.com') ||
requestUrl.href.startsWith('https://assets.convertkit.com')) {
// no cors
options = { mode: 'no-cors' }
}
event.respondWith(fetch(event.request, options)
.then((response) => {
if (response.status === 404) {
return fetch(PAGENOTFOUND_GIF)
}
const resClone = response.clone()
return caches.open(CACHE_NAME).then((cache) => {
cache.put(event.request.url, response)
return resClone
})
})
.catch(() => caches.open(CACHE_NAME).then(cache => cache.match(event.request.url)
.then((response) => {
if (response) {
return response
}
return fetch(OFFLINE_GIF)
})
.catch(() => fetch(OFFLINE_GIF)))))
Third approach: going simpler with no partials at all
As an experiment, I dropped the click interceptor that fetches partials, and I relied on Service Workers and the Cache API to just deliver the plain pages of the site, without managing partial updates:
script.js :
window.addEventListener('load', () => {
if (!navigator.serviceWorker) { return }
navigator.serviceWorker.register('/sw.js', {
scope: '/'
}).catch((err) => {
console.log('SW registration failed', err)
})
})
sw.js :
const CACHE_NAME = 'writesoftware-v1'
const OFFLINE_GIF = '/user/themes/writesoftware/img/offline.gif'
const PAGENOTFOUND_GIF = '/user/themes/writesoftware/img/pagenotfound.gif'
self.addEventListener('install', (event) => {
event.waitUntil(caches.open(CACHE_NAME).then(cache => cache.addAll([
'/user/themes/writesoftware/favicon.ico',
'/user/themes/writesoftware/css/style.css',
'/user/themes/writesoftware/js/script.js',
'/user/themes/writesoftware/img/offline.gif',
'/user/themes/writesoftware/img/pagenotfound.gif',
'https://fonts.googleapis.com/css?family=Press+Start+2P',
'https://fonts.googleapis.com/css?family=Inconsolata:400,700',
'https://cdnjs.cloudflare.com/ajax/libs/prism/1.6.0/themes/prism.min.css',
'https://cdnjs.cloudflare.com/ajax/libs/prism/1.6.0/prism.min.js',
'https://cdn.jsdelivr.net/prism/1.6.0/components/prism-jsx.min.js'
])))
})
self.addEventListener('fetch', (event) => {
if (event.request.method !== 'GET') return
if (event.request.headers.get('accept').indexOf('text/html') === -1) return
const requestUrl = new URL(event.request.url)
let options = {}
if (requestUrl.href.startsWith('https://www.googletagmanager.com') ||
requestUrl.href.startsWith('https://www.google-analytics.com') ||
requestUrl.href.startsWith('https://assets.convertkit.com')) {
// no cors
options = { mode: 'no-cors' }
}
event.respondWith(fetch(event.request, options)
.then((response) => {
if (response.status === 404) {
return fetch(PAGENOTFOUND_GIF)
}
const resClone = response.clone()
return caches.open(CACHE_NAME).then((cache) => {
cache.put(event.request.url, response)
return resClone
})
})
.catch(() => caches.open(CACHE_NAME).then(cache => cache.match(event.request.url)
.then((response) => {
return response || fetch(OFFLINE_GIF)
})
.catch(() => fetch(OFFLINE_GIF)))))
I think this is the bare bones example of adding offline capabilities to a website, while still keeping things simple. Any kind of website can add such Service Workers without too much complexity if that’s enough for you.
What I ended up implementing in my website
In the end, I didn’t think that this latest approach was enough to be viable. But I also ended up avoiding the App Shell, since I was not looking to create an installable app, and in my specific case it was complicating my navigation. I got by doing partial updates with fetch to avoid having to reload the entire page after the first from the server.
All with a network-first approach, to avoid having to deal with cache updates and versioning assets: after all, it still relies completely on client-side caching strategies that load cached pages from the disk, so I still benefit from caching without complicating my deployments.
Interested in learning JavaScript? Get my ebook at jshandbook.com