

I’m a nomad and live out of one carry-on bag. This means that the total weight of all my worldly possessions must fall under airline cabin baggage weight limits — usually 10kg. On some smaller airlines, however, this weight limit drops to 7kg. Occasionally, I have to decide not to bring something with me to adjust to the smaller weight limit.
As a practical exercise, deciding what to leave behind (or get rid of altogether) entails laying out all my things and choosing which ones to keep. That decision is based on the item’s usefulness to me (its worth) and its weight.
 This is all my stuff, and my Minaal Carry-on bag.
This is all my stuff, and my Minaal Carry-on bag.
Being a programmer, I’m aware that decisions like this could be made more efficiently by a computer. It’s done so frequently and so ubiquitously, in fact, that many will recognize this scenario as the classic packing problem or knapsack problem. How do I go about telling a computer to put as many important items in my bag as possible while coming in at or under a weight limit of 7kg? With algorithms! Yay!
I’ll discuss two common approaches to solving the knapsack problem: one called a greedy algorithm, and another called dynamic programming (a little harder, but better, faster, stronger…).
Let’s get to it.
The set up
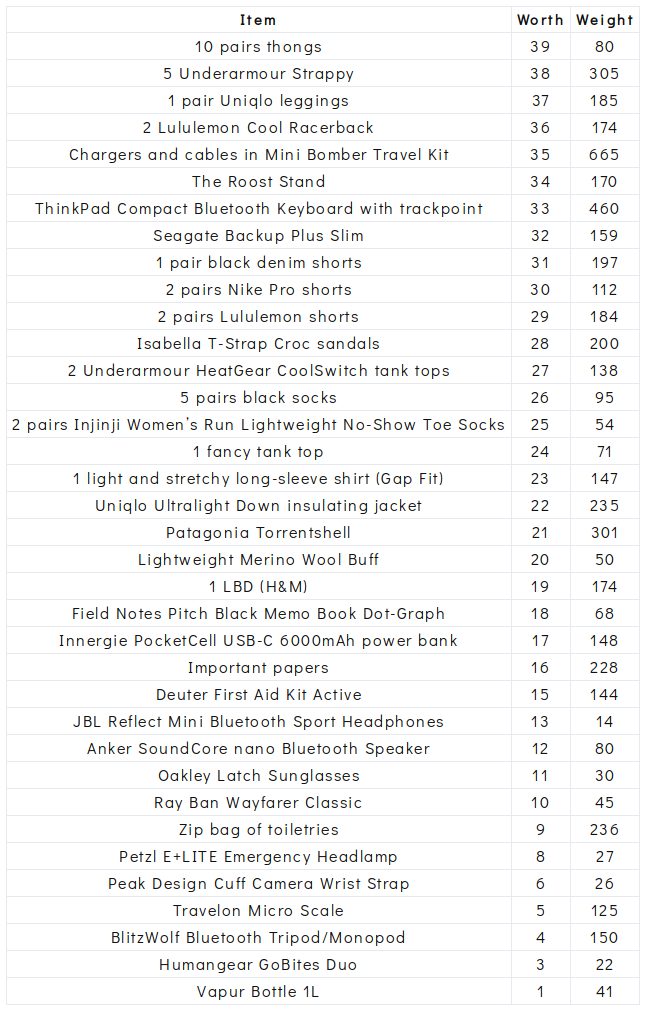
I prepared my data in the form of a CSV file with three columns: the item’s name (a string), a representation of its worth (an integer), and its weight in grams (an integer). There are 40 items in total. I represented worth by ranking each item from 40 to 1, with 40 being the most important and 1 equating with something like “why do I even have this again?” (If you’ve never listed out all your possessions and ranked them by order of how useful they are to you, I highly recommend you try it. It can be a very revealing exercise.)
Total weight of all items and bag: 9003g
Bag weight: 1415g
Airline limit: 7000g
Maximum weight of items I can pack: 5585g
Total possible worth of items: 820
The challenge: Pack as many items as the limit allows while maximizing the total worth.
Data structures
Reading in a file
Before we can begin thinking about how to solve the knapsack problem, we have to solve the problem of reading in and storing our data. Thankfully, the Go standard library’s io/ioutil package makes the first part straightforward.
package main
import (
"fmt"
"io/ioutil"
)
func check(e error) {
if e != nil {
panic(e)
}
}
func readItems(path string) {
dat, err := ioutil.ReadFile(path)
check(err)
fmt.Print(string(dat))
}
The ReadFile() function takes a file path and returns the file’s contents and an error (nil if the call is successful) so we’ve also created a check() function to handle any errors that might be returned. In a real-world application, we probably would want to do something more sophisticated than panic, but that’s not important right now.
Creating a struct
Now that we’ve got our data, we should probably do something with it. Since we’re working with real-life items and a real-life bag, let’s create some types to represent them and make it easier to conceptualize our program. A struct in Go is a typed collection of fields. Here are our two types:
type item struct {
name string
worth, weight int
}
type bag struct {
bagWeight, currItemsWeight, maxItemsWeight, totalWeight int
items []item
}
It is helpful to use field names that are very descriptive. You can see that the structs are set up just as we’ve described the things they represent. An item has a name (string), and a worth and weight (integers). A bag has several fields of type int representing its attributes, and also has the ability to hold items, represented in the struct as a slice of item type thingamabobbers.
Parsing and storing our data
Several comprehensive Go packages exist that we could use to parse our CSV data… but where’s the fun in that? Let’s go basic with some string splitting and a for loop. Here’s our updated readItems() function:
func readItems(path string) []item {
dat, err := ioutil.ReadFile(path)
check(err)
lines := strings.Split(string(dat), "\n")
itemList := make([]item, 0)
for i, v := range lines {
if i == 0 {
continue
}
s := strings.Split(v, ",")
newItemWorth, _ := strconv.Atoi(s[1])
newItemWeight, _ := strconv.Atoi(s[2])
newItem := item{name: s[0], worth: newItemWorth, weight: newItemWeight}
itemList = append(itemList, newItem)
}
return itemList
}
Using strings.Split, we split our dat on newlines. We then create an empty itemList to hold our items.
In our for loop, we skip the first line of our CSV file (the headers) then iterate over each line. We use strconv.Atoi (read “A to i”) to convert the values for each item’s worth and weight into integers. We then create a newItem with these field values and append it to the itemList. Finally, we return itemList.
Here’s what our set up looks like so far:
package main
import (
"io/ioutil"
"strconv"
"strings"
)
type item struct {
name string
worth, weight int
}
type bag struct {
bagWeight, currItemsWeight, maxItemsWeight, totalWeight, totalWorth int
items []item
}
func check(e error) {
if e != nil {
panic(e)
}
}
func readItems(path string) []item {
dat, err := ioutil.ReadFile(path)
check(err)
lines := strings.Split(string(dat), "\n")
itemList := make([]item, 0)
for i, v := range lines {
if i == 0 {
continue // skip the headers on the first line
}
s := strings.Split(v, ",")
newItemWorth, _ := strconv.Atoi(s[1])
newItemWeight, _ := strconv.Atoi(s[2])
newItem := item{name: s[0], worth: newItemWorth, weight: newItemWeight}
itemList = append(itemList, newItem)
}
return itemList
}
Now that we’ve got our data structures set up, let’s get packing (?) on the first approach.
Greedy algorithm
A greedy algorithm is the most straightforward approach to solving the knapsack problem, in that it is a one-pass algorithm that constructs a single final solution. At each stage of the problem, the greedy algorithm picks the option that is locally optimal, meaning it looks like the most suitable option right now. It does not revise its previous choices as it progresses through our data set.
Building our greedy algorithm
The steps of the algorithm we’ll use to solve our knapsack problem are:
- Sort items by worth, in descending order.
- Start with the highest worth item. Put items into the bag until the next item on the list cannot fit.
- Try to fill any remaining capacity with the next item on the list that can fit.
If you read my article about solving problems and making paella, you’ll know that I always start by figuring out what the next most important question is. In this case, there are three main operations we need to figure out how to do:
- Sort items by worth.
- Put an item in the bag.
- Check to see if the bag is full.
The first one is just a docs lookup away. Here’s how we sort a slice in Go:
sort.Slice(is, func(i, j int) bool {
return is[i].worth > is[j].worth
})
The sort.Slice() function orders our items according to the less function we provide. In this case, it will order the highest worth items before the lowest worth items.
Given that we don’t want to put an item in the bag if it doesn’t fit, we’ll complete the last two tasks in reverse. First, we’ll check to see if the item fits. If so, it goes in the bag.
func (b *bag) addItem(i item) error {
if b.currItemsWeight+i.weight <= b.maxItemsWeight {
b.currItemsWeight += i.weight
b.items = append(b.items, i)
return nil
}
return errors.New("could not fit item")
}
Notice the * in our first line there. That indicates that bag is a pointer receiver (as opposed to a value receiver). It’s a concept that can be slightly confusing if you’re new to Go. Here are some things to consider that might help you decide when to use a value receiver and when to use a pointer receiver. For the purposes of our addItem() function, this case applies:
If the method needs to mutate the receiver, the receiver must be a pointer.
Our use of a pointer receiver tells our function we want to operate on this specific bag in particular, not a new bag. It’s important because without it, every item would always fit in a newly created bag! A little detail like this can make the difference between code that works and code that keeps you up until 4am chugging Red Bull and muttering to yourself. (Go to bed on time even if your code doesn’t work — you’ll thank me later.)
Now that we’ve got our components, let’s put together our greedy algorithm:
func greedy(is []item, b bag) {
sort.Slice(is, func(i, j int) bool {
return is[i].worth > is[j].worth
})
for i := range is {
b.addItem(is[i])
}
b.totalWeight = b.bagWeight + b.currItemsWeight
for _, v := range b.items {
b.totalWorth += v.worth
}
}
Then in our main() function, we’ll create our bag, read in our data, and call our greedy algorithm. Here’s what it looks like, all set up and ready to go:
func main() {
minaal := bag{bagWeight: 1415, currItemsWeight: 0, maxItemsWeight: 5585}
itemList := readItems("objects.csv")
greedy(itemList, minaal)
}
Greedy algorithm results
So how does this algorithm do when it comes to efficiently packing our bag to maximize its total worth? Here’s the result:
Total weight of bag and items: 6987g
Total worth of packed items: 716
Here are the items our greedy algorithm chose, sorted by worth:
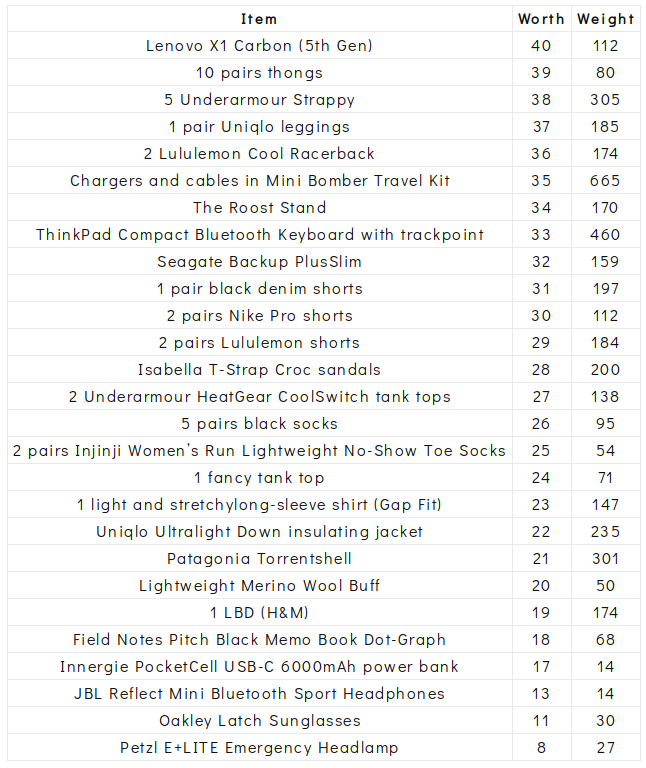 This is a screenshot because Medium doesn’t like tables.
This is a screenshot because Medium doesn’t like tables.
It’s clear that the greedy algorithm is a straightforward way to quickly find a feasible solution. For small data sets, it will probably be close to the optimal solution. The algorithm packed a total item worth of 716 (104 points less than the maximum possible value), while filling the bag with just 13g left over.
As we learned earlier, the greedy algorithm doesn’t improve upon the solution it returns. It simply adds the next highest worth item it can to the bag.
Let’s look at another method for solving the knapsack problem that will give us the optimal solution — the highest possible total worth under the weight limit.
Dynamic programming
The name “dynamic programming” can be a bit misleading. It’s not a style of programming, as the name might cause you to infer, but simply another approach.
Dynamic programming differs from the straightforward greedy algorithm in a few key ways. Firstly, a dynamic programming bag packing solution enumerates the entire solution space with all possibilities of item combinations that could be used to pack our bag. Where a greedy algorithm chooses the most optimal local solution, dynamic programming algorithms are able to find the most optimal global solution.
Secondly, dynamic programming uses memoization to store the results of previously computed operations and returns the cached result when the operation occurs again. This allows it to “remember” previous combinations. This takes less time than it would to re-compute the answer again.
Building our dynamic programming algorithm
To use dynamic programming to find the optimal recipe for packing our bag, we’ll need to:
- Create a matrix representing all subsets of the items (the solution space) with rows representing items and columns representing the bag’s remaining weight capacity
- Loop through the matrix and calculate the worth that can be obtained by each combination of items at each stage of the bag’s capacity
- Examine the completed matrix to determine which items to add to the bag in order to produce the maximum possible worth for the bag in total
It will be most helpful to visualize our solution space. Here’s a representation of what we’re building with our code:
 The empty knapsackian multiverse.
The empty knapsackian multiverse.
In Go, we can create this matrix as a slice of slices.
matrix := make([][]int, numItems+1) // rows representing items
for i := range matrix {
matrix[i] = make([]int, capacity+1) // columns representing grams of weight
}
We’ve padded the rows and columns by 1 so that the indicies match the item and weight numbers.
Now that we’ve created our matrix, we’ll fill it by looping over the rows and the columns:
// loop through table rows
for i := 1; i <= numItems; i++ {
// loop through table columns
for w := 1; w <= capacity; w++ {
// do stuff in each element
}
}
Then for each element, we’ll calculate the worth value to ascribe to it. We do this with code that represents the following process:
If the item at the index matching the current row fits within the weight capacity represented by the current column, take the maximum of either:
- The total worth of the items already in the bag or,
- The total worth of all the items in the bag except the item at the previous row index, plus the new item’s worth.
In other words, as our algorithm considers one of the items, we’re asking it to decide whether this item added to the bag would produce a higher total worth than the last item it added to the bag, at the bag’s current total weight. If this current item is a better choice, put it in — if not, leave it out.
Here’s the code that accomplishes this:
// if weight of item matching this index can fit at the current capacity column...
if is[i-1].weight <= w {
// worth of this subset without this item
valueOne := float64(matrix[i-1][w])
// worth of this subset without the previous item, and this item instead
valueTwo := float64(is[i-1].worth + matrix[i-1][w-is[i-1].weight])
// take maximum of either valueOne or valueTwo
matrix[i][w] = int(math.Max(valueOne, valueTwo))
// if the new worth is not more, carry over the previous worth
} else {
matrix[i][w] = matrix[i-1][w]
}
This process of comparing item combinations will continue until every item has been considered at every possible stage of the bag’s increasing total weight. When all the above have been considered, we’ll have enumerated the solution space — filled the matrix — with all possible total worth values.
We’ll have a big chart of numbers, and in the last column at the last row we’ll have our highest possible value.
 A strictly representative representation of the filled matrix.
A strictly representative representation of the filled matrix.
That’s great, but how do we find out which combination of items were put in the bag to achieve that worth?
Getting our optimized item list
To see which items combine to create our optimal packing list, we’ll need to examine our matrix in reverse to the way we created it. Since we know the highest possible value is in the last row in the last column, we’ll start there. To find the items, we:
- Get the value of the current cell
- Compare the value of the current cell to the value in the cell directly above it
- If the values differ, there was a change to the bag items. Find the next cell to examine by moving backwards through the columns according to the current item’s weight (find the value of the bag before this current item was added)
- If the values match, there was no change to the bag items. Move up to the cell in the row above and repeat
The nature of the action we’re trying to achieve lends itself well to a recursive function. If you recall from my previous article about making apple pie, recursive functions are simply functions that call themselves under certain conditions. Here’s what it looks like:
func checkItem(b *bag, i int, w int, is []item, matrix [][]int) {
if i <= 0 || w <= 0 {
return
}
pick := matrix[i][w]
if pick != matrix[i-1][w] {
b.addItem(is[i-1])
checkItem(b, i-1, w-is[i-1].weight, is, matrix)
} else {
checkItem(b, i-1, w, is, matrix)
}
}
Our checkItem() function calls itself if the condition we described in step 4 is true. If step 3 is true, it also calls itself, but with different arguments.
Recursive functions require a base case. In this example, we want the function to stop once we run out of values of worth to compare. Thus our base case is when either i or w are 0.
Here’s how the dynamic programming approach looks when it’s all put together:
func checkItem(b *bag, i int, w int, is []item, matrix [][]int) {
if i <= 0 || w <= 0 {
return
}
pick := matrix[i][w]
if pick != matrix[i-1][w] {
b.addItem(is[i-1])
checkItem(b, i-1, w-is[i-1].weight, is, matrix)
} else {
checkItem(b, i-1, w, is, matrix)
}
}
func dynamic(is []item, b *bag) *bag {
numItems := len(is) // number of items in knapsack
capacity := b.maxItemsWeight // capacity of knapsack
// create the empty matrix
matrix := make([][]int, numItems+1) // rows representing items
for i := range matrix {
matrix[i] = make([]int, capacity+1) // columns representing grams of weight
}
// loop through table rows
for i := 1; i <= numItems; i++ {
// loop through table columns
for w := 1; w <= capacity; w++ {
// if weight of item matching this index can fit at the current capacity column...
if is[i-1].weight <= w {
// worth of this subset without this item
valueOne := float64(matrix[i-1][w])
// worth of this subset without the previous item, and this item instead
valueTwo := float64(is[i-1].worth + matrix[i-1][w-is[i-1].weight])
// take maximum of either valueOne or valueTwo
matrix[i][w] = int(math.Max(valueOne, valueTwo))
// if the new worth is not more, carry over the previous worth
} else {
matrix[i][w] = matrix[i-1][w]
}
}
}
checkItem(b, numItems, capacity, is, matrix)
// add other statistics to the bag
b.totalWorth = matrix[numItems][capacity]
b.totalWeight = b.bagWeight + b.currItemsWeight
return b
}
Dynamic programming results
We expect that the dynamic programming approach will give us a more optimized solution than the greedy algorithm. So did it? Here are the results:
Total weight of bag and items: 6982g
Total worth of packed items: 757
Here are the items our dynamic programming algorithm chose, sorted by worth:
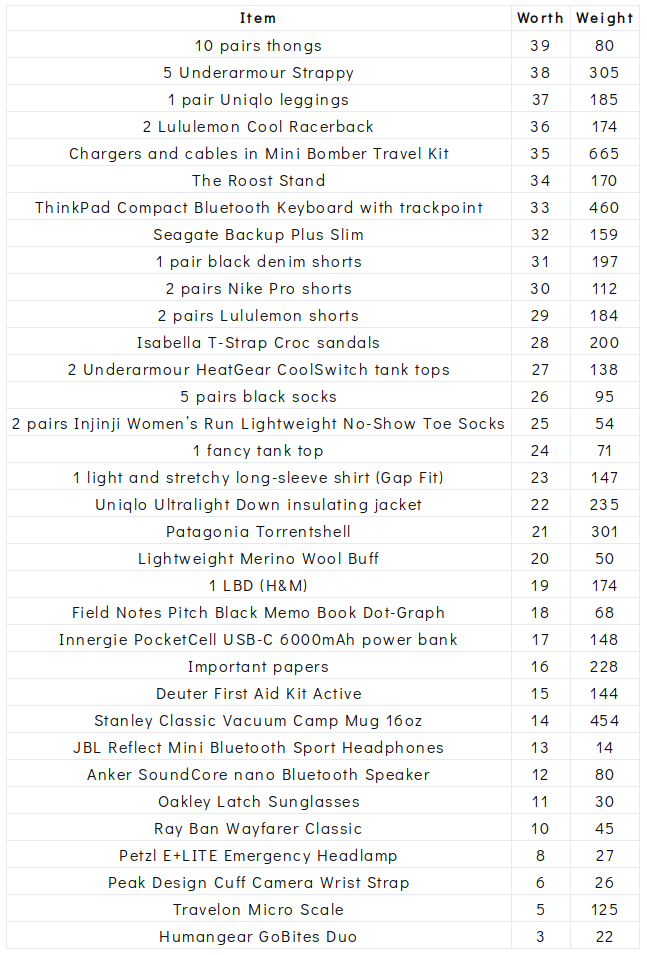
There’s an obvious improvement to our dynamic programming solution over what the greedy algorithm gave us. Our total worth of 757 is 41 points greater than the greedy algorithm’s solution of 716, and for a few grams less weight too!
Input sort order
While testing my dynamic programming solution, I implemented the Fisher-Yates shuffle algorithm on the input before passing it into my function, just to ensure that the answer wasn’t somehow dependent on the sort order of the input. Here’s what the shuffle looks like in Go:
rand.Seed(time.Now().UnixNano())
for i := range itemList {
j := rand.Intn(i + 1)
itemList[i], itemList[j] = itemList[j], itemList[i]
}
Of course I then realized that Go 1.10 now has a built-in shuffle. It works precisely the same way and looks like this:
rand.Shuffle(len(itemList), func(i, j int) {
itemList[i], itemList[j] = itemList[j], itemList[i]
})
So did the order in which the items were processed affect the outcome? Well…
Suddenly… a rogue weight appears!
As it turns out, in a way, the answer did depend on the order of the input. When I ran my dynamic programming algorithm several times, I sometimes saw a different total weight for the bag, though the total worth remained at 757. I initially thought this was a bug before examining the two sets of items that accompanied the two different total weight values. Everything was the same except for a few changes that collectively added up to a different item subset accounting for 14 of the 757 worth points.
In this case, there were two equally optimal solutions based only on the success metric of the highest total possible worth. Shuffling the input seemed to affect the placement of the items in the matrix and thus, the path that the checkItem() function took as it went through the matrix to find the chosen items. Since the success metric of having the highest possible worth was the same in both item sets, we don’t have a single unique solution - there’s two!
As an academic exercise, both these sets of items are correct answers. We may choose to optimize further by another metric, say, the total weight of all the items. The highest possible worth at the least possible weight could be seen as an ideal solution.
Here’s the second, lighter, dynamic programming result:
Total weight of bag and items: 6955g
Total worth of packed items: 757
Which approach is better?
Go benchmarking
The Go standard library’s testing package makes it straightforward for us to benchmark these two approaches. We can find out how long it takes each algorithm to run, and how much memory each uses. Here’s a simple main_test.go file:
package main
import (
"testing"
)
func Benchmark_greedy(b *testing.B) {
itemList := readItems("objects.csv")
for i := 0; i < b.N; i++ {
minaal := bag{bagWeight: 1415, currItemsWeight: 0, maxItemsWeight: 5585}
greedy(itemList, minaal)
}
}
func Benchmark_dynamic(b *testing.B) {
itemList := readItems("objects.csv")
for i := 0; i < b.N; i++ {
minaal := bag{bagWeight: 1415, currItemsWeight: 0, maxItemsWeight: 5585}
dynamic(itemList, &minaal)
}
}
We can run go test -bench=. -benchmem to see these results:
Benchmark_greedy-4 1000000 1619 ns/op 2128 B/op 9 allocs/op
Benchmark_dynamic-4 1000 1545322 ns/op 2020332 B/op 49 allocs/op
Greedy algorithm performance
After running the greedy algorithm 1,000,000 times, the speed of the algorithm was reliably measured to be 0.001619 milliseconds (translation: very fast). It required 2128 Bytes or 2-ish kilobytes of memory and 9 distinct memory allocations per iteration.
Dynamic programming performance
The dynamic programming algorithm was run 1,000 times. Its speed was measured to be 1.545322 milliseconds or 0.001545322 seconds (translation: still pretty fast). It required 2,020,332 Bytes or 2-ish Megabytes, and 49 distinct memory allocations per iteration.
The verdict
Part of choosing the right approach to solving any programming problem is taking into account the size of the input data set. In this case, it’s a small one. In this scenario, a one-pass greedy algorithm will always be faster and less resource-needy than dynamic programming, simply because it has fewer steps. Our greedy algorithm was almost two orders of magnitude faster and less memory-hungry than our dynamic programming algorithm.
Not having those extra steps, however, means that getting the best possible solution from the greedy algorithm is unlikely.
It’s clear that the dynamic programming algorithm gave us better numbers: a lower weight, and higher overall worth.
Greedy algorithm
- Total weight: 6987g
- Total worth: 716
Dynamic programming
- Total weight: 6955g
- Total worth: 757
Where dynamic programming on small data sets lacks in performance, it makes up in optimization. The question then becomes whether that additional optimization is worth the performance cost.
“Better,” of course, is a subjective judgement. If speed and low resource usage is our success metric, then the greedy algorithm is clearly better. If the total worth of items in the bag is our success metric, then dynamic programming is clearly better.
However, our scenario is a practical one, and only one of these algorithm designs returned an answer I’d choose. In optimizing for the overall greatest possible total worth of the items in the bag, the dynamic programming algorithm left out my highest-worth, but also heaviest, item: my laptop. The chargers and cables, Roost stand, and keyboard that were included aren’t much use without it.
Better algorithm design
There’s a simple way to alter the dynamic programming approach so that the laptop is always included: we can modify the data so that the worth of the laptop is greater than the sum of the worth of all the other items. (Try it out!)
Perhaps in re-designing the dynamic programming algorithm to be more practical, we might choose another success metric that better reflects an item’s importance, instead of a subjective worth value. There are many possible metrics we can use to represent the value of an item. Here are a few examples of a good proxy:
- Amount of time spent using the item
- Initial cost of purchasing the item
- Cost of replacement if the item were lost today
- Dollar value of the product of using the item
By the same token, the greedy algorithm’s results might be improved with the use of one of these alternate metrics.
On top of choosing an appropriate approach to solving the knapsack problem in general, it is helpful to design our algorithm in a way that translates the practicalities of a scenario into code.
There are many considerations for better algorithm design beyond the scope of this introductory post that I plan to cover (some of) in later articles. A future algorithm may very well decide my bag’s contents on the next trip, but we’re not quite there yet. Stay tuned!
Thanks for reading! I hope this article has given you a better idea of how these two common approaches work. If you’d like to learn more about how I live out of one carry-on bag, check out my nomad blog at herOneBag.com.
Have a really great day. :)