
By Rocky Kev
I wanted to learn Python for a long time, but I could never find a reason. When my company had a bunch of daily reports that needed to be generated, I realized I had an opportunity to explore Python to cut out all the repetition.
This article is the result of a few weeks learning Python, playing around with the various libraries, and automating some of my tasks at work.
Now I want to share what Python is capable of.
Rather than give boring office related examples, let’s put them in a Game of Thrones frame!

Any excuse to nerd out about Game of Thrones
In this post, I will be implementing web automation with the Selenium library, web scraping with the BeautifulSoup library, and generating reports with the csv module — which is sort of simulating the whole Pandas/Data Science side of Python.
And like I mentioned before —all of the examples will be using Game of Thrones.
Some Quick Notes:
You shouldn’t need any Python experience to do this. I’ll explain the code, and you should have enough to get going.
I’m not a super-expert at Python. This is roughly a few weeks of Python experience. It was just enough to automate my work and create these examples.
Python is WELL DOCUMENTED. There are so many free guides to learning Python, like Automate the Boring Stuff, Python for Beginners, and the amazing Dataquest.io data science track. There’s even more links in the freeCodeCamp knowledge base.
Python, the best reptile-based computer language

Python is nowhere near as intimating. Honest.
For those unfamiliar with programming —
Python is a general purpose programming language which is strictly typed, interpreted, and known for its easy readability with great design principles.
– Via the Freecodecamp.com guide
According to Stack Overflow’s 2018 Developer Survey, Python is the language most developers are wanting to learn (and also one of the fastest growing major programming languages).
Python powers site like Reddit, Instagram and Dropbox. It’s also a really readable language that has a lot of powerful libraries.
Python is named after Monty Python, not the reptile. BUT — in spite of that, it’s still the most popular reptile-based programming language, beating Serpent, Gecko, Cobra and Raptor! (I had to research that joke!)
If you have some background in programming (say in JavaScript)—
Some things about Python:
- Python uses indentation vs curly brackets. Check the example below:

Via the JavaScript 101 slides, from Professor Mindy McAdams
Python uses class-based inheritance — so it’s more like C languages. where as can JavaScript can simulate classes.
Python is also strongly typed. No mix-matching. For example, if you add a string and an integer together, it’ll start complaining.
Let’s jump right into it!
I’ll be breaking this into 3 pieces.
Game of Thrones and Python #1: Web automation
Game of Thrones and Python #2: Web Scraping
Game of Thrones and Python #3: Generating reports with the CSV Module

Game of Thrones and Python #1 — Web Automation
One of the coolest things you can do with Python is web automation.
For example — you can write a Python script that:
Opens up a browser
Automatically visits a specific website
Logs you into that site
Goes to another part of that website
Finds the most recent blog post.
Opens that blog post.
Submits a comment that says, “Great writing! High five!”
And finally logs you out of that website
It might not seem so hard to do. That takes what…. 20 seconds?
But if you had to do that over and over again, it would drive you insane.
For example — what if you had a staging site that’s still in development with 100 blog posts, and you wanted to post a comment on every single page to test its functionality?
That’s 100 blog posts * 20 seconds = roughly 33 minutes
And what if there are MULTIPLE testing phases, and you had to repeat the test six more times?
Other use cases for web automation include:
You might want to automate account creations on your site.
You might want to run a bot from start to finish in your online course.
You might want to push 100 bots to submit a form on your site with a single script.
What we will be doing
For this part, we’ll be automating the process to logging into all of our favorite Game of Thrones fan sites.
Don’t you hate when you have to waste time logging into westeros.org, the /r/freefolk subreddit, winteriscoming.net and all your other fan sites?

Literally… THE WORST.
With this template, you can automatically log into various websites!
Now, for Game of Thrones!
The Code
You will need to install Python 3, Selenium, and the Firefox webdrivers to get started. If you want to follow along, check out my tutorial on How to automate form submissions with Python.
This one might get complicated. So I highly recommend sitting back and enjoying the ride.
## Game of Thrones easy login script
##
## Description: This code logs into all of your fan sites automatically
from selenium import webdriver
from selenium.webdriver.common.keys import Keys
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
from selenium.common.exceptions import TimeoutException
import time
driver = webdriver.Firefox()
driver.implicitly_wait(5)
## implicity_wait makes the bot wait 5 seconds before every action
## so the site content can load up
# Define the functions
def login_to_westeros (username, userpass):
## Open the login page
driver.get('https://asoiaf.westeros.org/index.php?/login/')
## Log the details
print(username + " is logging into westeros.")
## Find the fields and log into the account.
textfield_username = driver.find_element_by_id('auth')
textfield_username.clear()
textfield_username.send_keys(username)
textfield_email = driver.find_element_by_id('password')
textfield_email.clear()
textfield_email.send_keys(userpass)
submit_button = driver.find_element_by_id('elSignIn_submit')
submit_button.click()
## Log the details
print(username + " is logged in! -> westeros")
def login_to_reddit_freefolk (username, userpass):
## Open the login page
driver.get('https://www.reddit.com/login/?dest=https%3A%2F%2Fwww.reddit.com%2Fr%2Ffreefolk')
## Log the details
print(username + " is logging into /r/freefolk.")
## Find the fields and log into the account.
textfield_username = driver.find_element_by_id('loginUsername')
textfield_username.clear()
textfield_username.send_keys(username)
textfield_email = driver.find_element_by_id('loginPassword')
textfield_email.clear()
textfield_email.send_keys(userpass)
submit_button = driver.find_element_by_class_name('AnimatedForm__submitButton')
submit_button.click()
## Log the details
print(username + " is logged in! -> /r/freefolk.")
## Define the user and email combo.
login_to_westeros("gameofthronesfan86", PASSWORDHERE)
time.sleep(2)
driver.execute_script("window.open('');")
Window_List = driver.window_handles
driver.switch_to_window(Window_List[-1])
login_to_reddit_freefolk("MyManMance", PASSWORDHERE)
time.sleep(2)
driver.execute_script("window.open('');")
Window_List = driver.window_handles
driver.switch_to_window(Window_List[-1])
## wait for 2 seconds
time.sleep(2)
print("task complete")
Breaking the code down
To start, I’m importing the Selenium library to help with the heavy lifting.
I also imported the time library, so after each action, it will wait x seconds. Adding a wait allows the page to load.
from selenium import webdriver
from selenium.webdriver.common.keys import Keys
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
from selenium.common.exceptions import TimeoutException
import time
What is Selenium?
Selenium is the Python library we use for web automation. Selenium has developed an API so third-party authors can develop webdrivers to the communication to browsers. That way, the Selenium team can focus on their codebase, while another team can focus on the middleware.
For example:
The Chromium team made their own webdriver for Selenium called chromedriver.
The Firefox team made their own webdriver for Selenium called geckodriver.
The Opera team made their own webdriver for Selenium called operadriver.
driver = webdriver.Firefox()
driver.get('https://www.hbo.com/game-of-thrones')
driver.close()
In the code above, I’m asking Selenium to do things like “Set Firefox up as the browser of choice”, and “pass this link to Firefox”, and finally “Close Firefox”. I used the geckodriver to do that.
Logging into sites
To make it easier to read, I wrote a separate function to log into each site, to show the pattern that we are making.
def login_to_westeros (username, userpass):
## Log in
driver.get('https://asoiaf.westeros.org/index.php?/login/')
## Log the details
print(username + " is logging into westeros.")
## 2) Look for the login box on the page
textfield_username = driver.find_element_by_id('auth')
textfield_username.clear()
textfield_username.send_keys(username)
textfield_email = driver.find_element_by_id('password')
textfield_email.clear()
textfield_email.send_keys(userpass)
submit_button = driver.find_element_by_id('elSignIn_submit')
submit_button.click()
## Log the details
print(username + " is logged in! -> westeros")
If we break that down even more — each function has the following elements.
I’m telling Python to:
Visit a specific page.
driver.get('https://asoiaf.westeros.org/index.php?/login/')Look for the login box
Clear the text if there is any
Submit my variable
textfield_username = driver.find_element_by_id('auth')
textfield_username.clear()
textfield_username.send_keys(username)
- Look for the password box
Clear the text if there is any
Submit my variable
textfield_email = driver.find_element_by_id('password')
textfield_email.clear()
textfield_email.send_keys(userpass)
- Look for the submit button, and click it
submit_button = driver.find_element_by_id('elSignIn_submit')
submit_button.click()
As a note: each website has different ways to find the username/password and submit buttons. You’ll have to do a bit of searching for that.
How to find the login box and password box for any website
The Selenium Library has a bunch of handy ways to find elements on a webpage. Here are some of the ones I like to use.
find_element_by_id
find_element_by_name
find_element_by_xpath
find_element_by_class_name
For the whole list, visit the Selenium Python documentation for locating elements.
To use asoiaf.westeros.com as an example, when I inspect the elements — they all have IDs… which is GREAT! That makes my life easier.
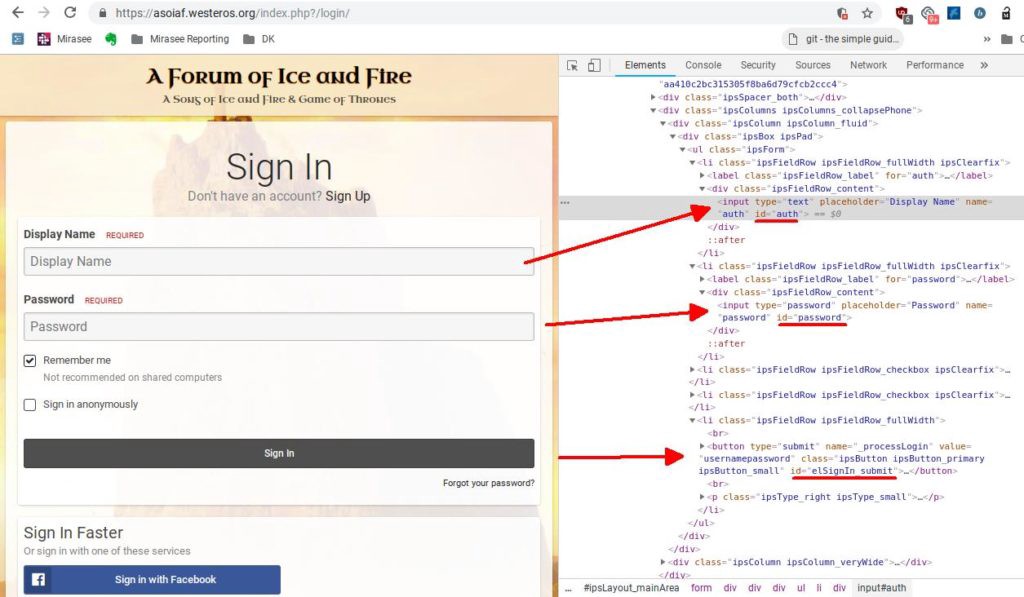
Inspect Element, and look for the code. That will give you clues on targeting.
Running the code
Here’s a short video of me running the code:
https://www.loom.com/share/87f0785c9c354c7282f7340c022c3291?sid=e55237cd-a693-4834-93bc-e14cb04ef147
Enjoying the ride
With web automation, you’re playing a game of ‘how can I get Selenium to find the element’. Once you find it, you can then manipulate it.
Game of Thrones and Python #2 — Web Scraping
In this piece, we will be exploring web-scrapping.
The big picture process is:
We’ll have Python visit a webpage.
We’ll then parse that webpage with BeautifulSoup.
You then set up the code to grab specific data.
For example: You might want to grab all the h1 tags. Or all the links. Or in our case, all of the images on a page.
Some other use cases for Web Scraping:
You can grab all the links on a web page.
You can grab all the post titles within a forum
You can use it to grab the daily NASDAQ Value without ever visiting the site.
You can use it to download all of the links within a website that doesn’t have a ‘Download All’.
In short, web scraping allows you to automatically grab web content through Python.
Overall, a very simple process. Except when it isn’t!
The challenge of Web Scraping for images
My goal was to turn my knowledge of web scraping content to grab images.
While web scraping for links, body text and headers is **very straightforward,**web scraping for images is significantly more complex. Let me explain.
As a web developer, hosting MULTIPLE full-sized images on a single webpage will slow the whole page down. Instead, use thumbnails and then only load the full-sized image when the thumbnail is clicked on.
For example: Imagine if we had twenty 1 megabyte images on our web page. Upon landing, a visitor would have to download 20 megabytes worth of images! The more common method is to make twenty 10kb thumbnail images. Now, your payload is only 200kb, or about 1/100 of the size!
So what does this have to do with web scraping images and this tutorial?
It means that it makes it pretty difficult to write a generic block of code that always works for every website. Websites implement all different ways to turn a thumbnail to a full-size image, which makes it a challenge to create a ‘one-size fits all’ model.
I’ll still teach what I learned. You’ll still gain a lot of skills from it. Just be aware that trying that code on other sites will require major modifications. Hurray for Zone of Proximal Development.
Python and Game of Thrones
The goal of this tutorial is that we’ll be gathering images of our favorite actors! Which will allow us to do weird things like make a Teenage Crush Actor Collage that we can hang in our bedroom (like so).

I was making this collage while my partner walked in. She then promptly walked out.
In order to gather those images, we’ll be using Python to do some web scraping. We’ll be using the BeautifulSoup library to visit a web page and grab all the image tags from it.
NOTE: In many website terms and conditions, they prohibit any web scraping of their data. Some develop APIs to allow you to tap into their data. Others do not. Additionally, try to be mindful that you are taking up their resources. So look to doing one request at a time rather than opening lots of connections in parallel and grinding their site to a halt.
The Code
# Import the libraries needed
import requests
import time
from bs4 import BeautifulSoup
# The URL to scrape
url = 'https://www.popsugar.com/celebrity/Kit-Harington-Rose-Leslie-Cutest-Pictures-42389549?stream_view=1#photo-42389576'
#url = 'https://www.bing.com/images/search?q=jon+snow&FORM=HDRSC2'
# Connecting
response = requests.get(url)
# Grab the HTML and using Beautiful
soup = BeautifulSoup (response.text, 'html.parser')
#A loop code to run through each link, and download it
for i in range(len(soup.findAll('img'))):
tag = soup.findAll('img')[i]
link = tag['src']
#skip it if it doesn't start with http
if "http" in full_link:
print("grabbed url: " + link)
filename = str(i) + '.jpg'
print("Download: " + filename)
r = requests.get(link)
open(filename, 'wb').write(r.content)
else:
print("grabbed url: " + link)
print("skip")
time.sleep(1)Breaking down the code
Having Python Visit the Webpage
We start by importing the libraries needed, and then storing the webpage link into a variable.
The Requests library is used to do all sorts of HTTP requests
The Time library is used to put a 1 second wait after each request. If we didn’t include that, the whole loop will fire off as fast as possible, which isn’t very friendly to the sites we are scraping from.
The BeautifulSoup Library is used to make exploring the DOM Tree easier.
Parse that webpage with BeautifulSoup
Next, we push our URL into BeautifulSoup.
Finding the content
Finally, we use a loop to grab the content.
It starts with a FOR loop. BeautifulSoup does some cool filtering, where my code asks BeautifulSoup find all the ‘img’ tags, and store it in a temporary array. Then, the len function asks for the length of the array.
#A loop code to run through each link, and download it
for i in range(len(soup.findAll('img'))):
So in human words, if the array held 51 items, the code will look like
For i in range(50):
Next, we’ll return back to our soup object, and do the real filtering.
tag = soup.findAll('img')[i]
link = tag['src']
Remember that we are in a For loop, so [i] represents a number.
So we are telling BeautifulSoup to findAll ‘img’ tags, store it in a temp array, and reference a specific index number based on where we are in the loop.
So instead of calling an array directly like allOfTheImages[10], we’re using soup.findAll(‘img’)[10], and then passing it to the tag variable.
The data in the tag variable will look something like:
<img src="smiley.gif" alt="Smiley face" height="42" width="42">
Which is why the next step is pulling out the ‘src’.

Downloading the Content
Finally — it’s the fun part!
We go to the final part of the loop, with downloading the content.
There’s a few odd design elements here that I want to point out.
The IF statement is actually a hack I made for other sites I was testing. There were times when I was grabbing images that was the part of the root site (like the favicon or the social media icons) that I didn’t want. So using the IF statement allowed me to ignore it.
I also forced all the images to be .jpg. I could have written another chunk of IF statements to check the datatype, and then append the correct filetype. But that was adding a significant chunk of code that made this tutorial longer.
I also added all the print commands. If you wanted to grab all the links of a webpage, or specific content — you can stop right here! You did it!
I also want to point out is the requests.get(link) and the open(filename, ‘wb’).write(r.content) code.
r = requests.get(link)
open(filename, 'wb').write(r.content)
How this works:
Requests gets the link.
Open is a default python function that opens or creates a file, gives it writing & binary mode access (since images are are just 1s and 0s), and writes the content of the link into that file.
#skip it if it doesn't start with http
if "http" in full_link:
print("grabbed url: " + link)
filename = str(i) + '.jpg'
print("Download: " + filename)
r = requests.get(link)
open(filename, 'wb').write(r.content)
else:
print("grabbed url: " + link)
print("skip")
time.sleep(1)
Web Scraping has a lot of useful features.
This code won’t work right out of the box for most sites with images, but it can serve as a foundation to how to grab images on different sites.
Game of Thrones and Python #3 — Generating reports and data
Gathering data is easy. Interpreting the data is difficult. Which is why there’s a huge surge of demand for data scientists who can make sense of this data. And data scientists use languages like R and Python to interpret it.
In this tutorial, we’ll be using the csv module, which will be enough to generate a report. If we were working with a huge dataset, one that’s like 50,000 rows or bigger, we’d have to tap into the Pandas library.
What we will be doing is downloading a CSV, having Python interpret the data, send a query based on what kind of question we want answered, and then have the answer print out to us.
Python VS basic spreadsheet functions
You might be wondering:
“Why should I use Python when I can easily just use spreadsheet functions like =SUM or =COUNT, or filter out the rows I don’t need manually?”
Like for all the other automation tricks in Part 1 and 2, you can definitely do this manually.
But imagine if you had to generate a new report every day.
For example: I build online courses. And we want a daily report of every student’s progress. How many students started today? How many students are active this week? How many students made it to Module 2? How many students submitted their Module 3 homework? How many students clicked on the completion button on mobile devices?
I can either spend 15 minutes sorting through the data to generate a report for my team. OR write Python code that does it daily.
Other use cases for using code instead of default spreadsheet functions:
You might be working with a huge set of data (huge like 50,000 rows and 20 columns)
You require multiple slices of filters and segmentation to get your answers.
You need to run the same query on a dataset that changes repeatedly
Generating Reports with Game of Thrones
Every year, Winteriscoming.net, a Game of Thrones news site, has their annual March Madness. Visitors would vote for their favorite characters, and winners move up the bracket and compete against another person. After 6 rounds of votes, a winner is declared.

This is 2018’s Thrones Madness
Since 2019’s votes are still happening, I grabbed all 6 rounds of 2018’s data and compiled them into a CSV file. To see how the poll looked like on winteriscoming.net, click here.
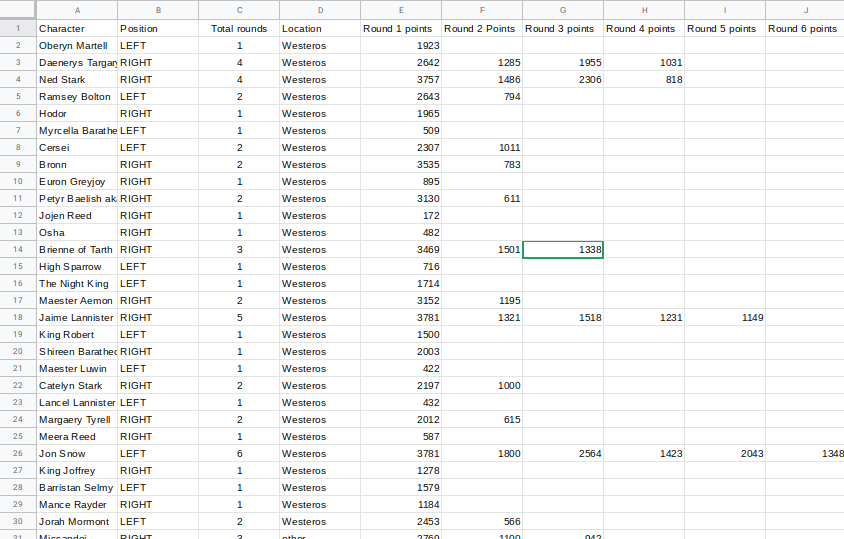
You can see the whole CSV as a Google Sheets file
I’ve also added some additional background data (like where they are from), to make the reporting a bit more interesting.
Asking Questions
In order to generate a report, we have to ask some questions.
By definition: A report’s primary duty is to ANSWER questions.
So let’s make them up right now.
Based on this dataset… here’s some questions.
Who won the popularity vote?
Who won based on averages?
Who is the most popular non-Westeros person? (characters not born in Westeros)
Before answering questions — let’s set up our Python code
To make it easier, I wrote the all the code, including revisions — in my new favorite online IDE, Repl.it.
import csv
# Import the data
f_csv = open('winter-is-coming-2018.csv')
headers = next(f_csv)
f_reader = csv.reader(f_csv)
file_data = list(f_reader)
# Make all blank cells into zeroes
# https://stackoverflow.com/questions/2862709/replacing-empty-csv-column-values-with-a-zero
for row in file_data:
for i, x in enumerate(row):
if len(x)< 1:
x = row[i] = 0
Here’s my process with the code.
I imported the csv module.
I imported the csv file, and turned it into a list type called file_data.
The way Python reads your file is by first passing the data to an object.
I removed the header, since it’ll fudge the data.
I then pass the object to a reader, and finally a list.
Note: I just realized I did it via the Python 2 way. There’s a cleaner way to do it in Python 3. Oh well. Still works.
- In order to sum up any totals, I made all blank cells become 0.
- This was one of those moments where found a Stack Overflow solution that was better than my original version.
With this set up, we can now loop through the list of data, and answer questions!
Question #1 — Who won the popularity vote?
The Spreadsheet method:
The easiest way would be to add up each cell, using a formula.
Using row 2 as an example, in a blank column, you can write the formula:
=sum(E2:J2)
You can then drag that formula for the other rows.
Then, sort it by total. And you have a winner!
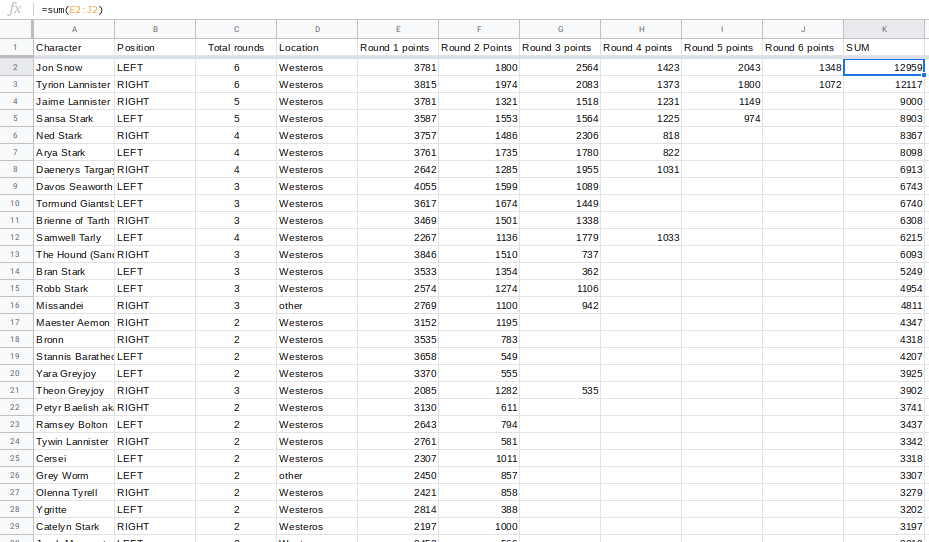
It’s Jon Snow — with 12959 points
## Include the code from above
# Push the data to a dictionary
total_score = {}
# Pass each character and their final score into total_score dictionary
for row in file_data:
total = (int(row[4]) +
int(row[5]) +
int(row[6]) +
int(row[7]) +
int(row[8]) +
int(row[9]) )
total_score[row[0]] = total
# Dictionaries aren't sortable by default, we'll have to borrow from these two classes.
# https://stackoverflow.com/questions/613183/how-do-i-sort-a-dictionary-by-value
from operator import itemgetter
from collections import OrderedDict
sorted_score = OrderedDict(sorted(total_score.items(), key=itemgetter(1) ,reverse=True))
# We get the name of the winner and their score
winner = list(sorted_score)[0] #jon snow
winner_score = sorted_score[winner] #score
print(winner + " with " + str(winner_score))
## RESULT => Jon Snow with 12959
The steps I took are:
The dataset is just one big list. By using a for loop, you can then access each row.
Within that for loop, I added each cell. (emulating the whole “=sum(E:J)” formula)
Since dictionaries aren’t exactly sortable, I had to import two classes to help me sort the dictionary by their values, from high to low.
Finally, I passed the winner, and the winner’s value as text.
To help understand that loop, I drew a diagram.
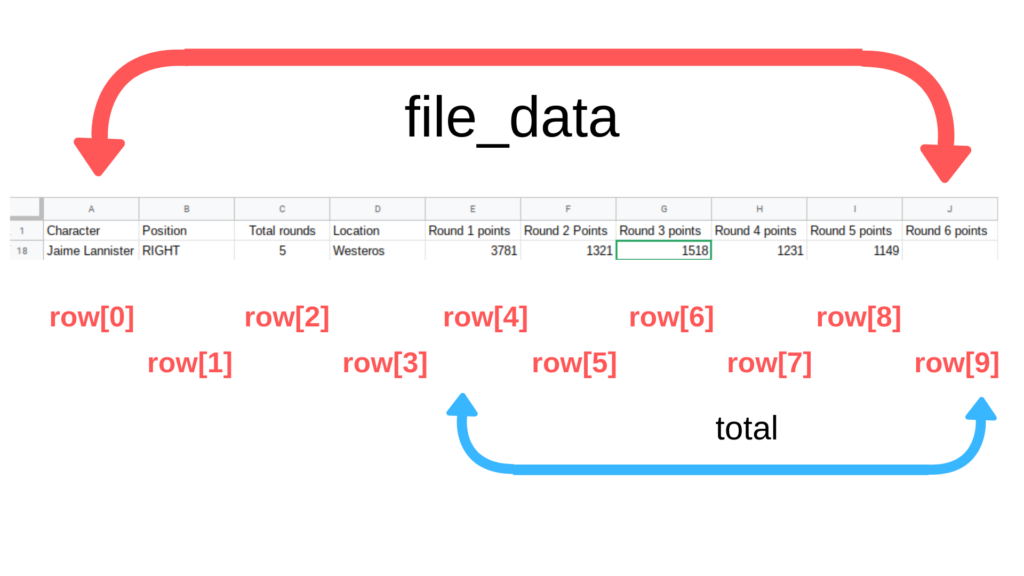
Overall, this process is a bit longer compared to the spreadsheet Method. But wait, it gets easier!

Congrats Jon, you’re the most popular character on GOT!
Question 2 — Who won based on averages?
You might have noticed that whoever proceeded farther in the rankings would obviously get more votes.
For example: If Jon Snow got 500 points in Round One and 1000 points in Round Two, he already beats The Mountain who only had 1000 points and never made it past his bracket.
So the next best thing is to sum the total, and then divide it based on how many rounds they participated in.
The Spreadsheet Method:
This is easy. In Column B is how many rounds they participated in. You would divide the rounds by the sum, and presto!
## OLD CODE FROM QUESTION 1
# Pass each character and their final score into total_score dictionary
for row in file_data:
total = (int(row[4]) +
int(row[5]) +
int(row[6]) +
int(row[7]) +
int(row[8]) +
int(row[9]) )
total_score[row[0]] = total
## NEW CODE
# Pass each character and their final score into total_score dictionary
for row in file_data:
total = (int(row[4]) +
int(row[5]) +
int(row[6]) +
int(row[7]) +
int(row[8]) +
int(row[9]) )
# NEW LINE - divide by how many rounds
new_total = total / int(row[2])
total_score[row[0]] = new_total
# RESULT => Davos Seaworth with 2247.6666666666665
Noticed the change? I just added one additional line.
That’s all it took to answer this question! NEXT!

On Average, Davos Seaworth has the most points.
Question 3 — Who is the most popular non-Westeros person?
With first two examples, it’s pretty easy to calculate the total with the default spreadsheet functions. For this question, things are a bit more complicated.
The Spreadsheet Method:
Assuming you already have the sum
You now have to filter it based on if they are Westeros/Other
Then sort by the sum

## OLD CODE FROM QUESTION 1
# Pass each character and their final score into total_score dictionary
for row in file_data:
total = (int(row[4]) +
int(row[5]) +
int(row[6]) +
int(row[7]) +
int(row[8]) +
int(row[9]) )
# NEW LINE - divide by how many rounds
new_total = total / int(row[2])
total_score[row[0]] = new_total
## NEW CODE
# Pass each character and their final score into total_score dictionary
for row in file_data:
# Add IF-THEN statement
if (row[3] == 'other'):
total = (int(row[4]) +
int(row[5]) +
int(row[6]) +
int(row[7]) +
int(row[8]) +
int(row[9]) )
else:
total = 0
total_score[row[0]] = total
# RESULT => Missandei with 4811
In Question 2, I added one line of code to answer that new question.
In Question 3, I added a IF-ELSE statement. If they are non-Westeros, then count their score. Else, give them a score of 0.

Whoa, huge upset! I was hoping it was Grey Worm!
Reviewing this:
While the spreadsheet Method doesn’t seem like a lot of steps, it sure is a lot more clicks. The Python method took a lot longer to set up, but each additional query involved changing a few lines of code.
Imagine if the stakeholder asked a dozen more questions.
For example:
How many points did characters whose names start with L have?
Or how many points did everyone in round 3 get who lived in Westeros?
Or if it was 640 GoT characters instead of just 64?
But also imagine this — you’re given a dataset that’s roughly 50 megabytes (Our Game of Thrones csv file was barely 50 kilobytes — roughly 1/1000 the size). A 50mb file that large would probably take Excel a few minutes to load. Additionally, it’s not unusual for Data Scientists to use datasets that are in the 10 gigabyte range!
Overall, as the data set scales, it’ll take longer and longer to process. And that’s where the power of Python comes in.
Conclusion
In Part 1, I covered web automation with the Selenium library. In Part 2, I covered web scraping with the BeautifulSoup library. And in Part 3, I covered generating reports with the csv module.
While I covered them in pieces — there’s also a synergy between them. Imagine if you had a project where you had to figure out who dies next in Game of Thrones based on the comments by the actors on the show. You might start with web scraping all of the actors’ names off of IMDB. You might use Selenium to automatically log into various social media platforms and search for their social media name. You might then compile all the data, and interpret it as a csv or, if it’s really huge, using the Pandas library.
We didn’t even get into Machine Learning, AI, Web Development, or the dozens of other things people use Python for.
Let this be a stepping stone into your Python journey!
🙏 Absolutely HUGE shout out to mJordan for proofing my work at the Puppies and Portfolios meetup. She is one of the most talented CSS developers I have ever met.
💻 If you like nerding out about course building, online education and the future of education — reach out to me on my Linkedin or Twitter.
👏 I’d appreciate a clap (or 50!) It really brings a smile to my face.