
By Radu Raicea
Medium has a large amount of content, a large number of users, and an almost overwhelming number of posts. When you try to find interesting users to interact with, you’re flooded with visual noise.
I define an interesting user as someone who is from your network, who is active, and who writes responses that are generally appreciated by the Medium community.
I was looking through the latest posts from users I follow to see who had responded to those users. I figured that if they responded to someone I’m following, they must have similar interests to mine.
The process was tedious. And that’s when I remembered the most valuable lesson I learned during my last internship:
Any tedious task can and should be automated.
I wanted my automation to do the following things:
- Get all the users from my “Followings” list
- Get the latest posts of each user
- Get all the responses to each post
- Filter out responses that are older than 30 days
- Filter out responses that have less than a minimum number of recommendations
- Get the username of the author of each response
Let’s start pokin’
I initially looked at Medium’s API, but found it limiting. It didn’t give me much to work with. I could only get information about my account, not on other users.
On top of that, the last change to Medium’s API was over a year ago. There was no sign of recent development.
I realized that I would have to rely on HTTP requests to get my data, so I started to poke around using my Chrome DevTools.
The first goal was to get my list of Followings.
I opened up my DevTools and went on the Network tab. I filtered out everything but XHR to see where Medium gets my list of Followings from. I hit the reload button on my profile page and got nothing interesting.
What if I clicked the Followings button on my profile? Bingo.
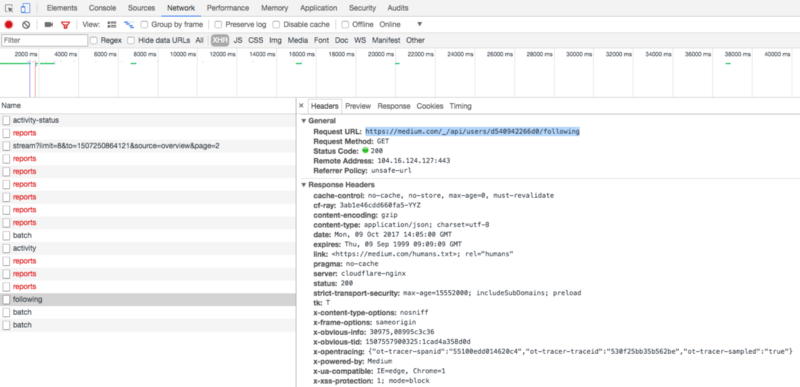
Inside the link, I found a very big JSON response. It was a well-formatted JSON, except for a string of characters at the beginning of the response: ])}while(1);</x>
I wrote a function to clean that up and turn the JSON into a Python dictionary.
import json
def clean_json_response(response): return json.loads(response.text.split('])}while(1);</x>')[1])
I had found an entry point. Let the coding begin.
Getting all the users from my Followings list
To query that endpoint, I needed my User ID (I know that I already had it, but this is for educational purposes).
While looking for a way to get a user’s ID, I found out that you can add ?format=json to most Medium URLs to get a JSON response from that page. I tried that out on my profile page.
Oh look, there’s the user ID.
])}while(1);</x>{"success":true,"payload":{"user":{"userId":"d540942266d0","name":"Radu Raicea","username":"Radu_Raicea",...
I wrote a function to pull the user ID from a given username. Again, I had to use clean_json_response to remove the unwanted characters at the beginning of the response.
I also made a constant called MEDIUM that contains the base for all the Medium URLs.
import requests
MEDIUM = 'https://medium.com'
def get_user_id(username):
print('Retrieving user ID...')
url = MEDIUM + '/@' + username + '?format=json' response = requests.get(url) response_dict = clean_json_response(response) return response_dict['payload']['user']['userId']
With the User ID, I queried the /_/api/users/<user_id>/following endpoint and got the list of usernames from my Followings list.
When I did it in DevTools, I noticed that the JSON response only had eight usernames. Weird.
After I clicked on “Show more people,” I saw what was missing. Medium uses pagination for the list of Followings.
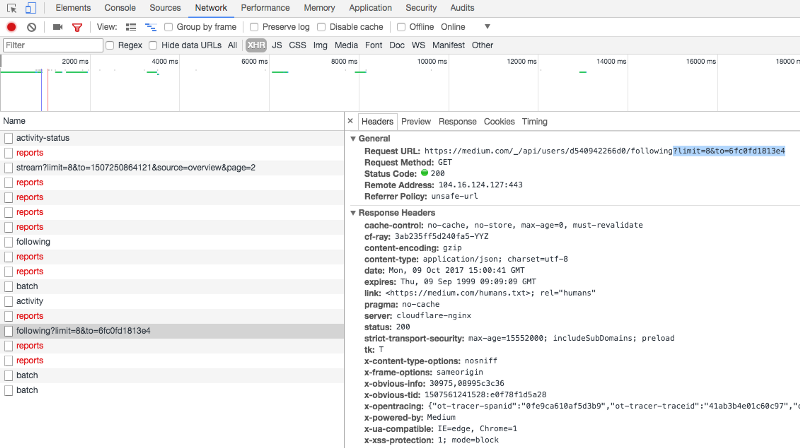
Pagination works by specifying a limit (elements per page) and to (first element of the next page). I had to find a way to get the ID of that next element.
At the end of the JSON response from /_/api/users/<user_id>/following, I saw an interesting key.
..."paging":{"path":"/_/api/users/d540942266d0/followers","next":{"limit":8,"to":"49260b62a26c"}}},"v":3,"b":"31039-15ed0e5"}
From here, writing a loop to get all the usernames from my Followings list was easy.
def get_list_of_followings(user_id):
print('Retrieving users from Followings...') next_id = False followings = []
while True:
if next_id: # If this is not the first page of the followings list url = MEDIUM + '/_/api/users/' + user_id + '/following?limit=8&to=' + next_id else: # If this is the first page of the followings list url = MEDIUM + '/_/api/users/' + user_id + '/following'
response = requests.get(url) response_dict = clean_json_response(response) payload = response_dict['payload']
for user in payload['value']: followings.append(user['username'])
try: # If the "to" key is missing, we've reached the end # of the list and an exception is thrown next_id = payload['paging']['next']['to'] except: break
return followings
Getting the latest posts from each user
Once I had the list of users I follow, I wanted to get their latest posts. I could do that with a request to [https://medium.com/@<username>/latest?forma](https://medium.com/@username/latest?format=json)t=json
I wrote a function that takes a list of usernames and returns a list of post IDs for the latest posts from all the usernames on the input list.
def get_list_of_latest_posts_ids(usernames):
print('Retrieving the latest posts...')
post_ids = []
for username in usernames: url = MEDIUM + '/@' + username + '/latest?format=json' response = requests.get(url) response_dict = clean_json_response(response)
try: posts = response_dict['payload']['references']['Post'] except: posts = []
if posts: for key in posts.keys(): post_ids.append(posts[key]['id'])
return post_ids
Getting all the responses from each post
With the list of posts, I extracted all the responses using https://medium.com/_/api/posts/<post_id>/responses
This function takes a list of post IDs and returns a list of responses.
def get_post_responses(posts):
print('Retrieving the post responses...')
responses = []
for post in posts: url = MEDIUM + '/_/api/posts/' + post + '/responses' response = requests.get(url) response_dict = clean_json_response(response) responses += response_dict['payload']['value']
return responses
Filtering the responses
At first, I wanted responses that had gotten a minimum number of claps. But I realized that this might not be a good representation of the community’s appreciation of the response: a user can give more than one clap for the same article.
Instead, I filtered by the number of recommendations. It measures the same thing as claps, but it doesn’t take duplicates into account.
I wanted the minimum to be dynamic, so I passed a variable named recommend_min around.
The following function takes a response and the recommend_min variable. It checks if the response meets that minimum.
def check_if_high_recommends(response, recommend_min): if response['virtuals']['recommends'] >= recommend_min: return True
I also wanted recent responses. I filtered out responses that were older than 30 days using this function.
from datetime import datetime, timedelta
def check_if_recent(response): limit_date = datetime.now() - timedelta(days=30) creation_epoch_time = response['createdAt'] / 1000 creation_date = datetime.fromtimestamp(creation_epoch_time)
if creation_date >= limit_date: return True
Getting the username of the author of each response
Once I had all the filtered responses, I grabbed all the authors’ user IDs using the following function.
def get_user_ids_from_responses(responses, recommend_min):
print('Retrieving user IDs from the responses...')
user_ids = []
for response in responses: recent = check_if_recent(response) high = check_if_high_recommends(response, recommend_min)
if recent and high: user_ids.append(response['creatorId'])
return user_ids
User IDs are useless when you’re trying to access someone’s profile. I made this next function query the /_/api/users/<user_id> endpoint to get the usernames.
def get_usernames(user_ids):
print('Retrieving usernames of interesting users...')
usernames = []
for user_id in user_ids: url = MEDIUM + '/_/api/users/' + user_id response = requests.get(url) response_dict = clean_json_response(response) payload = response_dict['payload']
usernames.append(payload['value']['username'])
return usernames
Putting it all together
After I finished all the functions, I created a pipeline to get my list of recommended users.
def get_interesting_users(username, recommend_min):
print('Looking for interesting users for %s...' % username)
user_id = get_user_id(username)
usernames = get_list_of_followings(user_id)
posts = get_list_of_latest_posts_ids(usernames)
responses = get_post_responses(posts)
users = get_user_ids_from_responses(responses, recommend_min)
return get_usernames(users)
The script was finally ready! To run it, you have to call the pipeline.
interesting_users = get_interesting_users('Radu_Raicea', 10)print(interesting_users)

Finally, I added an option to append the results to a CSV with a timestamp.
import csv
def list_to_csv(interesting_users_list): with open('recommended_users.csv', 'a') as file: writer = csv.writer(file)
now = datetime.now().strftime('%Y-%m-%d %H:%M:%S') interesting_users_list.insert(0, now) writer.writerow(interesting_users_list)
interesting_users = get_interesting_users('Radu_Raicea', 10)list_to_csv(interesting_users)
The project’s source code is on GitHub.
If you don’t know Python, go read TK’s Learning Python: From Zero to Hero.
If you have suggestions on other criteria that make users interesting, please write them below!
In summary…
- I made a Python script for Medium.
- The script returns a list of interesting users that are active and post interesting responses on the latest posts of people you are following.
- You can take users from the list and run the script with their username instead of yours.
Check out my primer on open source licenses and how to add them to your projects!
For more updates, follow me on Twitter.