
By Nikita Kozlov
Users love fast, responsive apps. They don’t want to hear about how API calls take time. They just want to see updates immediately. Right now. And we as a developers should strive to provide that. So how can we?
The solution: storing those changes locally, then synchronizing them with your servers from time to time. But this gets way more complex when things like connection latency is taken into account.
Let’s take Medium for example. Medium users can recommend an article to their followers by tapping a little green heart (there’s one on this page, too ?). By tapping the heart a second time, the user can stop recommending it.
The functionality is simple, but the edge cases cause lots of problems
I don’t know exactly what happens inside Medium’s app, but for simplicity, lets imagine that the first tap adds an item to the recommendation list, and the second one removes it.
Let’s see what kinds of problems this could cause for us if we decided to add similar functionality to our app:
- We should take into account that user can start tapping like crazy. This behavior could lead to a stream of events.
- Internet isn’t always fast. On a bad network connection, even simplest API calls could take several seconds to finish. During this time, the user could leave the current screen, then return.
- From time to time, API calls can fail, and our system needs to be able to recover from such situations.
- Users can have multiple devices with the same app, or they can use both the mobile app version and the corresponding website in tandem. In either case, we should have a policy for synchronizing data with our back end to update its state.
This isn’t a full list of the challenges we face, but these are the ones this article will focus on addressing.
Defining the problem

Before we start discussing implementation, lets define our acceptance criteria. The task is to develop a feature that allows the user to add and remove items from a certain list. The list is stored on our back end.
Implementation must fulfill the following requirements:
- The user interface reacts immediately to the user’s actions. The user wants to see the results of their actions immediately. If later we can’t synchronize those changes, we should notify our user, and roll back to the previous state.
- Interaction from multiple devices is supported. This doesn’t mean that we need to support changes in real time, but we do need to fetch the whole collection from time to time. Plus, our back end provides us with API endpoints for additions and removals, which we must use to support better synchronization.
- Integrity of the data is guaranteed. Whenever a synchronization call fails, our app should recover gracefully from errors.
Luckily, we don’t need to implement the whole feature, but rather develop a storage mechanism that will allow us to implement it. Let’s investigate different ways to meet these requirements.
The straight-forward approach
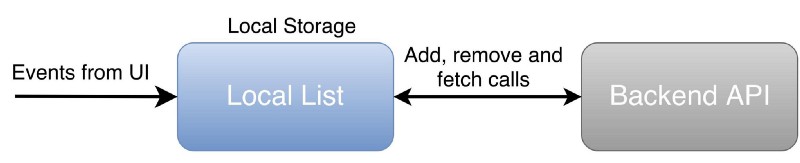
The first solution that comes to mind is to store a local copy of the list, then update it when the user makes a change.
Most of the problems with this approach are related to race conditions or API call failures, for example:
- Collisions between fetching and changing the list. Lets imagine that we started fetching items from our back end to update our local storage, and the user made a change before that operation finished. This would lead to a merge conflict between fetched list and the local one. So we need to distinguish, for example, between an item that wasn’t added yet and an item that was already removed from the web or another device.
- API call failure. Users can make lots of changes quickly, and they can also revert them quickly. For example, users can add an item to a list, then remove them, then add them back. If the first addition fails, then we should recover from it. In this case, we need to remove the item from the list. But that would ruin the integrity of our data, because the item should actually be on the list, since the last call we made was an addition and it wasn’t finished yet.
Even though there could be a way to make this approach work, I would argue that local storage should keep more information than just the final expected result. This will allow us to recover from all problems we may encounter.
Let’s keep history of everything the user does

Here’s a different approach: let’s keep the list we fetched from the API, as well as record everything the user has done. Every record would match an API call (“add” and “remove” respectively).
Once our API call finishes, we can update our local copy and remove the record from our history. When we want to synchronize the user’s browser with our back end, we just fetch the version of that list and replace our copy.
We no longer have any problems with API call failure, because we know the exact state before the call, and can just drop that record from the history without losing data integrity.
The main problem with this is performance. Every time we want to check whether a particular item is in the list, we need to go through all the records to calculate what our user should expect to see.
Of course, performance depends on the amount of interactions our user can do within a certain timeframe, and the way the data is stored. Plus keep in mind that premature optimization is the root of all evil, so if you don’t have this problem, then probably this is a way to go.
I think that this approach is great when user creates the content in the app, because it exposes lots of ways for handling synchronization issues. But our problem is simpler than that, so we should be able to make some optimizations and further increase performance.
The middle ground

It’s possible to have just enough information to recover from negative cases. Having two extra lists — one for ongoing additions, and one for ongoing removals — should be enough. To ensure data integrity, you would just need to apply a few rules:
- Lists with additions and removals have priority over the main list. For example, let’s say an item is in both the removals list and in the main list. When the browser checks to see whether the item is in the list, it should return false.
- One item can’t be in both lists at once. If the user made multiple actions on a single item, the latest change should have priority. For example, if the user added and then removed the item, as a result it should be in the list for removals. It doesn’t matter whether the item is in the main list or not.
- Only after the last API call for a certain item has finished can it be removed from the corresponding list. For example, the user could have added the item, removed it, then added it again before the first call is finished. In this case, the item would be in the list for additions. But it should be removed from there only after the second addition is finished. This can be achieved by assigning an ID to each entry in those lists. Later, after API call is finished, the entry would be removed using this ID.
- After every API call, the main list should be updated. The main list should reflect the actual state of the backend to the best of our knowledge. So in the case of consecutive addition and removal, even though from app side it would looks like item was not in the list, after the first call we should add it to the main list.
A few words about API call failures
There are different reasons why an API call can fail. Some of them temporary, some of them not. Some of them are fatal, and some of them are possible to recover from. Regardless of the solution, even failed requests should return some information about the cause of the problem.
I think that HTTP status codes are perfect for this. For example, if the status code is 504 Gateway Timeout, then retrying could be a good idea, but if it is 400 Bad Request, then most likely some client logic is wrong and simple retry logic won’t help. Some of them, like 401 Unauthorized, could require some user actions. 410 Gone or 404 Not Found during the removal call could mean that the user removed this item from a different device and most likely we can even tell user that the operation was successful, since user’s intention is fulfilled.
If for some reason your API doesn’t use proper HTTP status codes (I don’t even want to know why), it still should provide information regarding the cause of an issue. Otherwise, you could run into a weird issues. For example, if the call for removal failed because item is not in the list anymore, but we won’t have information about the cause, then the application would think that item is in the list until the next round of fetching the whole list.
Conclusion
The first solution was a simple list. It was fast, but handling negative cases was difficult.
In the second approach, we created a data structure that acts like a list, but persisted the records of all the changes made. This could handle negative cases, but it was much slower.
Our middle ground was a solution that — from outside — still acts like a list. But it allows us to balance performance and easily recovery from errors.
The issues mentioned in this article are only one side of the problem. The other is the amount of API calls made. If the user performs a lot of similar interactions, we can try to minimize the amount of API calls made. This optimization affects the structure of our local storage as well.
I will discuss this and propose additional solution to these issues in my next articles.
Thank you for you time reading this article. If you like it, don’t forget to click the ? below. You can also follow me on Twitter.